Task-Graph-Based Parallelization of Modelica-Simulations. Tutorial on the Usage of the HPCOM-Module
|
|
|
- Gloria Paul
- 5 years ago
- Views:
Transcription

1 Task-Graph-Based Parallelization of Modelica-Simulations Tutorial on the Usage of the HPCOM-Module
2 2 Introduction
3 Prerequisites a multi-core cpu compilation stages can be retraced using: a text editor to display debug-output a browser to display html-files (for big models IE is good) a graph-editor to display graphml-files ( we recommend yed - ) 3
4 4 Technical Overview
5 Outline Modelica Transformation Process Task-Graph Generation Parallelization Approaches Clusterung and Scheduling Usage OpenModelica flags to retrace compilation stages are marked. 5


6 Modelica Transformation Process Modelica.Electrical.Spice3.Examples.CoupledInductors.mo +d=dumpdaelow Flattening: model gets parsed and instantiated in order to attain a flat model. 6
 7")
7 Modelica Transformation Process +d=graphml Dependencies among variables and equations are detected. A bipartite graph is set up. (+d=graphml) 7

8 Modelica Transformation Process +d=graphml +d=dumprepl ReplaceSimpleEquations to reduce system size: Alias-Variables are replaced, i.e. simple assignments like a=b; 8
9 Modelica Transformation Process +d=bltmatrixdump 9 Causalization: Matching / Index-Reduction / Tarjan s Algorithm: each variable is assigned to an equation if necessary, index is reduced (Panthelides) strongly connected components are identified (BLT-Matrix)
) y(t) = g(x(t), u(t)); Time Integration State-Derivatives")

10 Modelica Transformation Process Start Values States Evaluate Right- Hand-Side x t = f(x t, u(t)) y(t) = g(x(t), u(t)); Time Integration State-Derivatives Simulation: main-diagonal is traversed top down, blocks correspond to systems of equations computed state-derivatives are used for time integration scheme 10
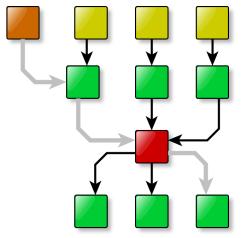
11 Task-Graph Generation +d=graphml 1-dimensional computation sequence 2-dimensional sequnce, task dependencies Task-Graph Generation: traverse BLT-matrix and assign dependencies between tasks (i.e. strongly-connected component) 11
12 Task-Graph Generation Task-Graph: used for parallelization of statederivative computation Scheduling: assign tasks to threads to distribute the workload among all threads information about execution costs and communication costs needed +d=hpcom remove the ablgebraic branches determine execution costs (estimation or measurements) benchmark communication costs 12
13 Task-Graph Generation Task-Graph: used for parallelization of state-derivative computation remove the ablgebraic branches Scheduling: assign tasks to threads to distribute the workload among all threads determine execution costs (estimation or measurements) benchmark communication costs +d=hpcom 13
14 Parallelization approaches Modelling Solver Compiler Transmission Line Modeling (TLM) multirate submodels / cosimulation parmodelica parallel: steps/iterations parallel solving of equation systems in integrator QSS BLT - parallelization parallel solving of equation systems in system equations 14


15 Clustering and Scheduling Clustering merge linear task sequence merge parent nodes 15

16 Clustering and Scheduling Level Scheduling 16
; } #pragma omp section { eqfunction_2(data); } } //Level 2 #pragma omp parallel sections { }}")
17 Clustering and Scheduling Level Scheduling and OpenMP-Code Level Level 2 4 static void solveode(data) { //Level 1 #pragma omp parallel sections { #pragma omp section { eqfunction_1(data); } #pragma omp section { eqfunction_2(data); } } //Level 2 #pragma omp parallel sections { }} 17

18 Clustering and Scheduling Thread-Scheduling (MCP) Modelica.Electrical.Machines.Examples.Synchronousinductionmachines.SMEE_LoadDump 18
19 Clustering and Scheduling Thread-Scheduling and pthreads-code Thread 1 Thread static void thread1ode(data) { //Function of thread1 while(1) { pthread_mutex_lock(&th_lock_0); eqfunction_1(data); SET_SPIN_LOCK(l23); eqfunction_3(data); pthread_mutex_unlock(&th_lock1_0); } } static void solveode(data) { INIT_SPIN_LOCK(l23,true); //pthread_spinlock_t INIT_LOCKS(); if(firstrun) CREATE_THREADS( ); //Start threads pthread_mutex_unlock(&th_lock_0); pthread_mutex_unlock(&th_lock_1); //"join" pthread_mutex_lock(&th_lock1_0); pthread_mutex_lock(&th_lock1_1); }
20 Influencing Factors domain specifics Mechanics: One big linear systems is the bottleneck Hydraulics: Even distribution of tasks 20
21 21 Usage of HPCOM-Parallelization



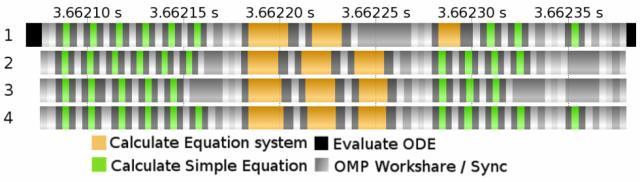

22 HPCOM - portfolio Task-Graph-Parallelization in HPC-OM Symbolic Task-Graph Conditioning Cost-Benchmarking & Estimation Task-Merging & Clustering Scheduling & Parallel Codegeneration Memory Optimization Profiling &Tracing 22
23 Usage of HPCOM-Parallelization Example: Modelica.Fluid.Examples.BranchingDynamicPipes.mo from Modelica Standard Library Modelica Scripting File: *.mos loadmodel(modelica,{"3.2.1"}); setdebugflags("hpcom,hpcomdump"); geterrorstring(); setcommandlineoptions("+n=4 +hpcomscheduler=list +hpcomcode=openmp"); geterrorstring(); simulate(modelica.fluid.examples.branchingdynamicpipes, stoptime=10.0); geterrorstring(); 23
24 Preparation Results: Critical Path successfully calculated Filter successfully applied. Merged 446 tasks. Using list Scheduler for the DAE system Using list Scheduler for the ODE system Using list Scheduler for the ZeroFunc system the number of locks: 577 the serialcosts: the parallelcosts: the cpcosts: The predicted SpeedUp with 4 processors is: 3.57 With a theoretical maximmum speedup of: Schedule created 24
Efficient Clustering and Scheduling for Task-Graph based Parallelization
 Center for Information Services and High Performance Computing TU Dresden Efficient Clustering and Scheduling for Task-Graph based Parallelization Marc Hartung 02. February 2015 E-Mail: marc.hartung@tu-dresden.de
Center for Information Services and High Performance Computing TU Dresden Efficient Clustering and Scheduling for Task-Graph based Parallelization Marc Hartung 02. February 2015 E-Mail: marc.hartung@tu-dresden.de
High-Performance-Computing meets OpenModelica: Achievements in the HPC-OM Project
 OpenModelica Workshop 2015 High-Performance-Computing meets OpenModelica: Achievements in the HPC-OM Project Linköping, 02/02/2015 HPC-OM www.hpc-om.de slide 2 Outline Outline 1. Parallelization Approaches
OpenModelica Workshop 2015 High-Performance-Computing meets OpenModelica: Achievements in the HPC-OM Project Linköping, 02/02/2015 HPC-OM www.hpc-om.de slide 2 Outline Outline 1. Parallelization Approaches
Equation based parallelization of Modelica models
 Marcus Walther Volker Waurich Christian Schubert Dr.-Ing. Ines Gubsch Dresden University of Technology {marcus.walther, volker.waurich, christian.schubert, ines.gubsch@tu-dresden.de Abstract In order to
Marcus Walther Volker Waurich Christian Schubert Dr.-Ing. Ines Gubsch Dresden University of Technology {marcus.walther, volker.waurich, christian.schubert, ines.gubsch@tu-dresden.de Abstract In order to
Dynamic Load Balancing in Parallelization of Equation-based Models
 Dynamic Load Balancing in Parallelization of Equation-based Models Mahder Gebremedhin Programing Environments Laboratory (PELAB), IDA Linköping University mahder.gebremedhin@liu.se Annual OpenModelica
Dynamic Load Balancing in Parallelization of Equation-based Models Mahder Gebremedhin Programing Environments Laboratory (PELAB), IDA Linköping University mahder.gebremedhin@liu.se Annual OpenModelica
Parallel Computing Using Modelica
 Parallel Computing Using Modelica Martin Sjölund, Mahder Gebremedhin, Kristian Stavåker, Peter Fritzson PELAB, Linköping University ModProd Feb 2012, Linköping University, Sweden What is Modelica? Equation-based
Parallel Computing Using Modelica Martin Sjölund, Mahder Gebremedhin, Kristian Stavåker, Peter Fritzson PELAB, Linköping University ModProd Feb 2012, Linköping University, Sweden What is Modelica? Equation-based
Design Approach for a Generic and Scalable Framework for Parallel FMU Simulations
 Center for Information Services and High Performance Computing TU Dresden Design Approach for a Generic and Scalable Framework for Parallel FMU Simulations Martin Flehmig, Marc Hartung, Marcus Walther
Center for Information Services and High Performance Computing TU Dresden Design Approach for a Generic and Scalable Framework for Parallel FMU Simulations Martin Flehmig, Marc Hartung, Marcus Walther
Simulation and Benchmarking of Modelica Models on Multi-core Architectures with Explicit Parallel Algorithmic Language Extensions
 Simulation and Benchmarking of Modelica Models on Multi-core Architectures with Explicit Parallel Algorithmic Language Extensions Afshin Hemmati Moghadam Mahder Gebremedhin Kristian Stavåker Peter Fritzson
Simulation and Benchmarking of Modelica Models on Multi-core Architectures with Explicit Parallel Algorithmic Language Extensions Afshin Hemmati Moghadam Mahder Gebremedhin Kristian Stavåker Peter Fritzson
OpenMP and more Deadlock 2/16/18
 OpenMP and more Deadlock 2/16/18 Administrivia HW due Tuesday Cache simulator (direct-mapped and FIFO) Steps to using threads for parallelism Move code for thread into a function Create a struct to hold
OpenMP and more Deadlock 2/16/18 Administrivia HW due Tuesday Cache simulator (direct-mapped and FIFO) Steps to using threads for parallelism Move code for thread into a function Create a struct to hold
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
OpenModelica Compiler (OMC) Overview
 Overview") OpenModelica Compiler (OMC) Overview, Adrian Pop, Peter Aronsson OpenModelica Course, 2006 11 06 1 OpenModelica Environment Architecture Eclipse Plugin Editor/Browser Emacs Editor/Browser Interactive session
OpenModelica Compiler (OMC) Overview, Adrian Pop, Peter Aronsson OpenModelica Course, 2006 11 06 1 OpenModelica Environment Architecture Eclipse Plugin Editor/Browser Emacs Editor/Browser Interactive session
OpenModelica Compiler (OMC) Overview
 Overview") OpenModelica Compiler (OMC) Overview, Adrian Pop, Peter Aronsson OpenModelica Course at INRIA, 2006 06 08 1 OpenModelica Environment Architecture Eclipse Plugin Editor/Browser Emacs Editor/Browser Interactive
OpenModelica Compiler (OMC) Overview, Adrian Pop, Peter Aronsson OpenModelica Course at INRIA, 2006 06 08 1 OpenModelica Environment Architecture Eclipse Plugin Editor/Browser Emacs Editor/Browser Interactive
Parallelism paradigms
 Parallelism paradigms Intro part of course in Parallel Image Analysis Elias Rudberg elias.rudberg@it.uu.se March 23, 2011 Outline 1 Parallelization strategies 2 Shared memory 3 Distributed memory 4 Parallelization
Parallelism paradigms Intro part of course in Parallel Image Analysis Elias Rudberg elias.rudberg@it.uu.se March 23, 2011 Outline 1 Parallelization strategies 2 Shared memory 3 Distributed memory 4 Parallelization
A Modular. OpenModelica. Compiler Backend
 Chair of Construction Machines and Conveying Technology OpenModelica Workshop 2011 A Modular OpenModelica Compiler Backend J. Frenkel W. Braun A. Pop M. Sjölund Outline 1. Introduction 2. Concept of Modular
Chair of Construction Machines and Conveying Technology OpenModelica Workshop 2011 A Modular OpenModelica Compiler Backend J. Frenkel W. Braun A. Pop M. Sjölund Outline 1. Introduction 2. Concept of Modular
Issues In Implementing The Primal-Dual Method for SDP. Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM
 Issues In Implementing The Primal-Dual Method for SDP Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM 87801 borchers@nmt.edu Outline 1. Cache and shared memory parallel computing concepts.
Issues In Implementing The Primal-Dual Method for SDP Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM 87801 borchers@nmt.edu Outline 1. Cache and shared memory parallel computing concepts.
Joe Hummel, PhD. Microsoft MVP Visual C++ Technical Staff: Pluralsight, LLC Professor: U. of Illinois, Chicago.
 Joe Hummel, PhD Microsoft MVP Visual C++ Technical Staff: Pluralsight, LLC Professor: U. of Illinois, Chicago email: joe@joehummel.net stuff: http://www.joehummel.net/downloads.html Async programming:
Joe Hummel, PhD Microsoft MVP Visual C++ Technical Staff: Pluralsight, LLC Professor: U. of Illinois, Chicago email: joe@joehummel.net stuff: http://www.joehummel.net/downloads.html Async programming:
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Open Compute Stack (OpenCS) Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,
 Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,") Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
1. Define algorithm complexity 2. What is called out of order in detail? 3. Define Hardware prefetching. 4. Define software prefetching. 5. Define wor
 CS6801-MULTICORE ARCHECTURES AND PROGRAMMING UN I 1. Difference between Symmetric Memory Architecture and Distributed Memory Architecture. 2. What is Vector Instruction? 3. What are the factor to increasing
CS6801-MULTICORE ARCHECTURES AND PROGRAMMING UN I 1. Difference between Symmetric Memory Architecture and Distributed Memory Architecture. 2. What is Vector Instruction? 3. What are the factor to increasing
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
A Strategy for Parallel Simulation of Declarative Object-Oriented Models of Generalized Physical Networks
 A trategy for Parallel imulation of Declarative Object-Oriented Models of Generalized Physical Networks Francesco Casella 1 1 Dipartimento di Elettronica, Informazione e Bioingegneria, Politecnico di Milano,
A trategy for Parallel imulation of Declarative Object-Oriented Models of Generalized Physical Networks Francesco Casella 1 1 Dipartimento di Elettronica, Informazione e Bioingegneria, Politecnico di Milano,
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallelising serial applications. Darryl Gove Compiler Performance Engineering
 Parallelising serial applications Darryl Gove Compiler Performance Engineering Topics Process Tools Expectations 2 Profile Compile with debug info > -g [C/Fortran] > -g0 [C++] > Enables mapping of disassembly
Parallelising serial applications Darryl Gove Compiler Performance Engineering Topics Process Tools Expectations 2 Profile Compile with debug info > -g [C/Fortran] > -g0 [C++] > Enables mapping of disassembly
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Chapter 18. Combining MPI and OpenMP
 Chapter 18 Combining MPI and OpenMP Outline Advantages of using both MPI and OpenMP Case Study: Conjugate gradient method Case Study: Jacobi method C+MPI vs. C+MPI+OpenMP Interconnection Network P P P
Chapter 18 Combining MPI and OpenMP Outline Advantages of using both MPI and OpenMP Case Study: Conjugate gradient method Case Study: Jacobi method C+MPI vs. C+MPI+OpenMP Interconnection Network P P P
Modelica Change Proposal MCP-0019 Flattening (In Development) Proposed Changes to the Modelica Language Specification Version 3.
 Proposed Changes to the Modelica Language Specification Version 3.") Modelica Change Proposal MCP-0019 Flattening (In Development) Proposed Changes to the Modelica Language Specification Version 3.3 Revision 1 Table of Contents Preface 3 Chapter 1 Introduction 3 Chapter
Modelica Change Proposal MCP-0019 Flattening (In Development) Proposed Changes to the Modelica Language Specification Version 3.3 Revision 1 Table of Contents Preface 3 Chapter 1 Introduction 3 Chapter
Scientific Programming in C XIV. Parallel programming
 Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
Using SPARK as a Solver for Modelica. Michael Wetter Philip Haves Michael A. Moshier Edward F. Sowell. July 30, 2008
 Using SPARK as a Solver for Modelica Michael Wetter Philip Haves Michael A. Moshier Edward F. Sowell July 30, 2008 1 Overview Overview of SPARK, Modelica, OpenModelica, Dymola Problem reduction SPARK integration
Using SPARK as a Solver for Modelica Michael Wetter Philip Haves Michael A. Moshier Edward F. Sowell July 30, 2008 1 Overview Overview of SPARK, Modelica, OpenModelica, Dymola Problem reduction SPARK integration
Concurrent Programming with OpenMP
 Concurrent Programming with OpenMP Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 11, 2012 CPD (DEI / IST) Parallel and Distributed
Concurrent Programming with OpenMP Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico October 11, 2012 CPD (DEI / IST) Parallel and Distributed
Introduction to Performance Tuning & Optimization Tools
 Introduction to Performance Tuning & Optimization Tools a[i] a[i+1] + a[i+2] a[i+3] b[i] b[i+1] b[i+2] b[i+3] = a[i]+b[i] a[i+1]+b[i+1] a[i+2]+b[i+2] a[i+3]+b[i+3] Ian A. Cosden, Ph.D. Manager, HPC Software
Introduction to Performance Tuning & Optimization Tools a[i] a[i+1] + a[i+2] a[i+3] b[i] b[i+1] b[i+2] b[i+3] = a[i]+b[i] a[i+1]+b[i+1] a[i+2]+b[i+2] a[i+3]+b[i+3] Ian A. Cosden, Ph.D. Manager, HPC Software
Overview: The OpenMP Programming Model
 Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Go Multicore Series:
 Go Multicore Series: Understanding Memory in a Multicore World, Part 2: Software Tools for Improving Cache Perf Joe Hummel, PhD http://www.joehummel.net/freescale.html FTF 2014: FTF-SDS-F0099 TM External
Go Multicore Series: Understanding Memory in a Multicore World, Part 2: Software Tools for Improving Cache Perf Joe Hummel, PhD http://www.joehummel.net/freescale.html FTF 2014: FTF-SDS-F0099 TM External
Agenda. Optimization Notice Copyright 2017, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
 Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
Agenda VTune Amplifier XE OpenMP* Analysis: answering on customers questions about performance in the same language a program was written in Concepts, metrics and technology inside VTune Amplifier XE OpenMP
INTRODUCING NVBIO: HIGH PERFORMANCE PRIMITIVES FOR COMPUTATIONAL GENOMICS. Jonathan Cohen, NVIDIA Nuno Subtil, NVIDIA Jacopo Pantaleoni, NVIDIA
 INTRODUCING NVBIO: HIGH PERFORMANCE PRIMITIVES FOR COMPUTATIONAL GENOMICS Jonathan Cohen, NVIDIA Nuno Subtil, NVIDIA Jacopo Pantaleoni, NVIDIA SEQUENCING AND MOORE S LAW Slide courtesy Illumina DRAM I/F
INTRODUCING NVBIO: HIGH PERFORMANCE PRIMITIVES FOR COMPUTATIONAL GENOMICS Jonathan Cohen, NVIDIA Nuno Subtil, NVIDIA Jacopo Pantaleoni, NVIDIA SEQUENCING AND MOORE S LAW Slide courtesy Illumina DRAM I/F
STUDYING OPENMP WITH VAMPIR
 STUDYING OPENMP WITH VAMPIR Case Studies Sparse Matrix Vector Multiplication Load Imbalances November 15, 2017 Studying OpenMP with Vampir 2 Sparse Matrix Vector Multiplication y 1 a 11 a n1 x 1 = y m
STUDYING OPENMP WITH VAMPIR Case Studies Sparse Matrix Vector Multiplication Load Imbalances November 15, 2017 Studying OpenMP with Vampir 2 Sparse Matrix Vector Multiplication y 1 a 11 a n1 x 1 = y m
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Parallel Programming
 Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CSE 4/521 Introduction to Operating Systems
 CSE 4/521 Introduction to Operating Systems Lecture 5 Threads (Overview, Multicore Programming, Multithreading Models, Thread Libraries, Implicit Threading, Operating- System Examples) Summer 2018 Overview
CSE 4/521 Introduction to Operating Systems Lecture 5 Threads (Overview, Multicore Programming, Multithreading Models, Thread Libraries, Implicit Threading, Operating- System Examples) Summer 2018 Overview
EE/CSCI 451 Introduction to Parallel and Distributed Computation. Discussion #4 2/3/2017 University of Southern California
 EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
Evolving HPCToolkit John Mellor-Crummey Department of Computer Science Rice University Scalable Tools Workshop 7 August 2017
 Evolving HPCToolkit John Mellor-Crummey Department of Computer Science Rice University http://hpctoolkit.org Scalable Tools Workshop 7 August 2017 HPCToolkit 1 HPCToolkit Workflow source code compile &
Evolving HPCToolkit John Mellor-Crummey Department of Computer Science Rice University http://hpctoolkit.org Scalable Tools Workshop 7 August 2017 HPCToolkit 1 HPCToolkit Workflow source code compile &
G(B)enchmark GraphBench: Towards a Universal Graph Benchmark. Khaled Ammar M. Tamer Özsu
enchmark GraphBench: Towards a Universal Graph Benchmark. Khaled Ammar M. Tamer Özsu") G(B)enchmark GraphBench: Towards a Universal Graph Benchmark Khaled Ammar M. Tamer Özsu Bioinformatics Software Engineering Social Network Gene Co-expression Protein Structure Program Flow Big Graphs o
G(B)enchmark GraphBench: Towards a Universal Graph Benchmark Khaled Ammar M. Tamer Özsu Bioinformatics Software Engineering Social Network Gene Co-expression Protein Structure Program Flow Big Graphs o
Minimal Equation Sets for Output Computation in Object-Oriented Models
 Minimal Equation Sets for Output Computation in Object-Oriented Models Vincenzo Manzoni Francesco Casella Dipartimento di Elettronica e Informazione, Politecnico di Milano Piazza Leonardo da Vinci 3, 033
Minimal Equation Sets for Output Computation in Object-Oriented Models Vincenzo Manzoni Francesco Casella Dipartimento di Elettronica e Informazione, Politecnico di Milano Piazza Leonardo da Vinci 3, 033
Introduction to OpenMP
 1 / 7 Introduction to OpenMP: Exercises and Handout Introduction to OpenMP Christian Terboven Center for Computing and Communication, RWTH Aachen University Seffenter Weg 23, 52074 Aachen, Germany Abstract
1 / 7 Introduction to OpenMP: Exercises and Handout Introduction to OpenMP Christian Terboven Center for Computing and Communication, RWTH Aachen University Seffenter Weg 23, 52074 Aachen, Germany Abstract
Fall CSE 633 Parallel Algorithms. Cellular Automata. Nils Wisiol 11/13/12
 Fall 2012 CSE 633 Parallel Algorithms Cellular Automata Nils Wisiol 11/13/12 Simple Automaton: Conway s Game of Life Simple Automaton: Conway s Game of Life John H. Conway Simple Automaton: Conway s Game
Fall 2012 CSE 633 Parallel Algorithms Cellular Automata Nils Wisiol 11/13/12 Simple Automaton: Conway s Game of Life Simple Automaton: Conway s Game of Life John H. Conway Simple Automaton: Conway s Game
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Automatic Parallelization of Mathematical Models Solved with Inlined Runge-Kutta Solvers
 Automatic Parallelization of Mathematical Models Solved with Inlined Runge-Kutta Solvers Håkan Lundvall and Peter Fritzson PELAB Programming Environment Lab, Dept. Computer Science Linköping University,
Automatic Parallelization of Mathematical Models Solved with Inlined Runge-Kutta Solvers Håkan Lundvall and Peter Fritzson PELAB Programming Environment Lab, Dept. Computer Science Linköping University,
OpenMP Tutorial. Dirk Schmidl. IT Center, RWTH Aachen University. Member of the HPC Group Christian Terboven
 OpenMP Tutorial Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de IT Center, RWTH Aachen University Head of the HPC Group terboven@itc.rwth-aachen.de 1 IWOMP
OpenMP Tutorial Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de IT Center, RWTH Aachen University Head of the HPC Group terboven@itc.rwth-aachen.de 1 IWOMP
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
Hybrid Model Parallel Programs
 Hybrid Model Parallel Programs Charlie Peck Intermediate Parallel Programming and Cluster Computing Workshop University of Oklahoma/OSCER, August, 2010 1 Well, How Did We Get Here? Almost all of the clusters
Hybrid Model Parallel Programs Charlie Peck Intermediate Parallel Programming and Cluster Computing Workshop University of Oklahoma/OSCER, August, 2010 1 Well, How Did We Get Here? Almost all of the clusters
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
Introduction to Programming Using Java (98-388)
") Introduction to Programming Using Java (98-388) Understand Java fundamentals Describe the use of main in a Java application Signature of main, why it is static; how to consume an instance of your own class;
Introduction to Programming Using Java (98-388) Understand Java fundamentals Describe the use of main in a Java application Signature of main, why it is static; how to consume an instance of your own class;
OpenMP Tutorial. Seung-Jai Min. School of Electrical and Computer Engineering Purdue University, West Lafayette, IN
 OpenMP Tutorial Seung-Jai Min (smin@purdue.edu) School of Electrical and Computer Engineering Purdue University, West Lafayette, IN 1 Parallel Programming Standards Thread Libraries - Win32 API / Posix
OpenMP Tutorial Seung-Jai Min (smin@purdue.edu) School of Electrical and Computer Engineering Purdue University, West Lafayette, IN 1 Parallel Programming Standards Thread Libraries - Win32 API / Posix
Shared Memory Programming With OpenMP Computer Lab Exercises
 Shared Memory Programming With OpenMP Computer Lab Exercises Advanced Computational Science II John Burkardt Department of Scientific Computing Florida State University http://people.sc.fsu.edu/ jburkardt/presentations/fsu
Shared Memory Programming With OpenMP Computer Lab Exercises Advanced Computational Science II John Burkardt Department of Scientific Computing Florida State University http://people.sc.fsu.edu/ jburkardt/presentations/fsu
A recipe for fast(er) processing of netcdf files with Python and custom C modules
 processing of netcdf files with Python and custom C modules") A recipe for fast(er) processing of netcdf files with Python and custom C modules Ramneek Maan Singh a, Geoff Podger a, Jonathan Yu a a CSIRO Land and Water Flagship, GPO Box 1666, Canberra ACT 2601 Email:
A recipe for fast(er) processing of netcdf files with Python and custom C modules Ramneek Maan Singh a, Geoff Podger a, Jonathan Yu a a CSIRO Land and Water Flagship, GPO Box 1666, Canberra ACT 2601 Email:
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ.
 An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
An innovative compilation tool-chain for embedded multi-core architectures M. Torquati, Computer Science Departmente, Univ. Of Pisa Italy 29/02/2012, Nuremberg, Germany ARTEMIS ARTEMIS Joint Joint Undertaking
Parallel Programming. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Concurrency, Thread. Dongkun Shin, SKKU
 Concurrency, Thread 1 Thread Classic view a single point of execution within a program a single PC where instructions are being fetched from and executed), Multi-threaded program Has more than one point
Concurrency, Thread 1 Thread Classic view a single point of execution within a program a single PC where instructions are being fetched from and executed), Multi-threaded program Has more than one point
Code Generators for Stencil Auto-tuning
 Code Generators for Stencil Auto-tuning Shoaib Kamil with Cy Chan, Sam Williams, Kaushik Datta, John Shalf, Katherine Yelick, Jim Demmel, Leonid Oliker Diagnosing Power/Performance Correctness Where this
Code Generators for Stencil Auto-tuning Shoaib Kamil with Cy Chan, Sam Williams, Kaushik Datta, John Shalf, Katherine Yelick, Jim Demmel, Leonid Oliker Diagnosing Power/Performance Correctness Where this
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Web Development I PRECISION EXAMS DESCRIPTION. EXAM INFORMATION Items
 PRECISION EXAMS Web Development I EXAM INFORMATION Items 43 Points 62 Prerequisites NONE Grade Level 9-12 Course Length ONE YEAR Career Cluster INFORMATION TECHNOLOGY Performance Standards INCLUDED Certificate
PRECISION EXAMS Web Development I EXAM INFORMATION Items 43 Points 62 Prerequisites NONE Grade Level 9-12 Course Length ONE YEAR Career Cluster INFORMATION TECHNOLOGY Performance Standards INCLUDED Certificate
COSC 6374 Parallel Computation. Parallel Design Patterns. Edgar Gabriel. Fall Design patterns
 COSC 6374 Parallel Computation Parallel Design Patterns Fall 2014 Design patterns A design pattern is a way of reusing abstract knowledge about a problem and its solution Patterns are devices that allow
COSC 6374 Parallel Computation Parallel Design Patterns Fall 2014 Design patterns A design pattern is a way of reusing abstract knowledge about a problem and its solution Patterns are devices that allow
Parallel Code Generation in MathModelica / An Object Oriented Component Based Simulation Environment
 Parallel Code Generation in MathModelica / An Object Oriented Component Based Simulation Environment Peter Aronsson, Peter Fritzson (petar,petfr)@ida.liu.se Dept. of Computer and Information Science, Linköping
Parallel Code Generation in MathModelica / An Object Oriented Component Based Simulation Environment Peter Aronsson, Peter Fritzson (petar,petfr)@ida.liu.se Dept. of Computer and Information Science, Linköping
Applying Multi-Core Model Checking to Hardware-Software Partitioning in Embedded Systems
 V Brazilian Symposium on Computing Systems Engineering Applying Multi-Core Model Checking to Hardware-Software Partitioning in Embedded Systems Alessandro Trindade, Hussama Ismail, and Lucas Cordeiro Foz
V Brazilian Symposium on Computing Systems Engineering Applying Multi-Core Model Checking to Hardware-Software Partitioning in Embedded Systems Alessandro Trindade, Hussama Ismail, and Lucas Cordeiro Foz
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
AUTOMATIC PARALLELIZATION OF OBJECT ORIENTED MODELS ACROSS METHOD AND SYSTEM
 AUTOMATIC PARALLELIZATION OF OBJECT ORIENTED MODELS ACROSS METHOD AND SYSTEM Håkan Lundvall and Peter Fritzson PELAB Programming Environment Lab, Dept. Computer Science Linköping University, S-581 83 Linköping,
AUTOMATIC PARALLELIZATION OF OBJECT ORIENTED MODELS ACROSS METHOD AND SYSTEM Håkan Lundvall and Peter Fritzson PELAB Programming Environment Lab, Dept. Computer Science Linköping University, S-581 83 Linköping,
Basic programming knowledge (arrays, looping, functions) Basic concept of parallel programming (in OpenMP)
 Basic concept of parallel programming (in OpenMP)") Parallel Sort Course Level: CS2 PDC Concepts Covered PDC Concept Concurrency Data Parallel Sequential Dependency Bloom Level C A A Programing Knowledge Prerequisites: Basic programming knowledge (arrays,
Parallel Sort Course Level: CS2 PDC Concepts Covered PDC Concept Concurrency Data Parallel Sequential Dependency Bloom Level C A A Programing Knowledge Prerequisites: Basic programming knowledge (arrays,
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP)
") HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
Data-intensive computing in radiative transfer modelling
 German Aerospace Center (DLR) Remote Sensing Technology Institute (IMF) Data-intensive computing in radiative transfer modelling Dmitry Efremenko Diego Loyola Adrian Doicu Thomas Trautmann Dmitry.Efremenko@dlr.de
German Aerospace Center (DLR) Remote Sensing Technology Institute (IMF) Data-intensive computing in radiative transfer modelling Dmitry Efremenko Diego Loyola Adrian Doicu Thomas Trautmann Dmitry.Efremenko@dlr.de
GPU-Accelerated Topology Optimization on Unstructured Meshes
 GPU-Accelerated Topology Optimization on Unstructured Meshes Tomás Zegard, Glaucio H. Paulino University of Illinois at Urbana-Champaign July 25, 2011 Tomás Zegard, Glaucio H. Paulino (UIUC) GPU TOP on
GPU-Accelerated Topology Optimization on Unstructured Meshes Tomás Zegard, Glaucio H. Paulino University of Illinois at Urbana-Champaign July 25, 2011 Tomás Zegard, Glaucio H. Paulino (UIUC) GPU TOP on
STUDYING OPENMP WITH VAMPIR & SCORE-P
 STUDYING OPENMP WITH VAMPIR & SCORE-P Score-P Measurement Infrastructure November 14, 2018 Studying OpenMP with Vampir & Score-P 2 November 14, 2018 Studying OpenMP with Vampir & Score-P 3 OpenMP Instrumentation
STUDYING OPENMP WITH VAMPIR & SCORE-P Score-P Measurement Infrastructure November 14, 2018 Studying OpenMP with Vampir & Score-P 2 November 14, 2018 Studying OpenMP with Vampir & Score-P 3 OpenMP Instrumentation
Parallel Computing. Lecture 16: OpenMP - IV
 CSCI-UA.0480-003 Parallel Computing Lecture 16: OpenMP - IV Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com PRODUCERS AND CONSUMERS Queues A natural data structure to use in many multithreaded
CSCI-UA.0480-003 Parallel Computing Lecture 16: OpenMP - IV Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com PRODUCERS AND CONSUMERS Queues A natural data structure to use in many multithreaded
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
CPS343 Parallel and High Performance Computing Project 1 Spring 2018
 CPS343 Parallel and High Performance Computing Project 1 Spring 2018 Assignment Write a program using OpenMP to compute the estimate of the dominant eigenvalue of a matrix Due: Wednesday March 21 The program
CPS343 Parallel and High Performance Computing Project 1 Spring 2018 Assignment Write a program using OpenMP to compute the estimate of the dominant eigenvalue of a matrix Due: Wednesday March 21 The program
Performance Issues in Parallelization Saman Amarasinghe Fall 2009
 Performance Issues in Parallelization Saman Amarasinghe Fall 2009 Today s Lecture Performance Issues of Parallelism Cilk provides a robust environment for parallelization It hides many issues and tries
Performance Issues in Parallelization Saman Amarasinghe Fall 2009 Today s Lecture Performance Issues of Parallelism Cilk provides a robust environment for parallelization It hides many issues and tries
The OpenModelica Modeling, Simulation, and Development Environment
 The OpenModelica Modeling, Simulation, and Development Environment Peter Fritzson, Peter Aronsson, Håkan Lundvall, Kaj Nyström, Adrian Pop, Levon Saldamli, David Broman PELAB Programming Environment Lab,
The OpenModelica Modeling, Simulation, and Development Environment Peter Fritzson, Peter Aronsson, Håkan Lundvall, Kaj Nyström, Adrian Pop, Levon Saldamli, David Broman PELAB Programming Environment Lab,
FMI Kit for Simulink version by Dassault Systèmes
 FMI Kit for Simulink version 2.4.0 by Dassault Systèmes April 2017 The information in this document is subject to change without notice. Copyright 1992-2017 by Dassault Systèmes AB. All rights reserved.
FMI Kit for Simulink version 2.4.0 by Dassault Systèmes April 2017 The information in this document is subject to change without notice. Copyright 1992-2017 by Dassault Systèmes AB. All rights reserved.
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Parallel Programming
 Parallel Programming OpenMP Dr. Hyrum D. Carroll November 22, 2016 Parallel Programming in a Nutshell Load balancing vs Communication This is the eternal problem in parallel computing. The basic approaches
Parallel Programming OpenMP Dr. Hyrum D. Carroll November 22, 2016 Parallel Programming in a Nutshell Load balancing vs Communication This is the eternal problem in parallel computing. The basic approaches
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks
 An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve OPENMP Standard multicore API for scientific computing Based on fork-join model: fork many threads, join and resume sequential thread Uses pragma:#pragma omp parallel Shared/private
CME 213 S PRING 2017 Eric Darve OPENMP Standard multicore API for scientific computing Based on fork-join model: fork many threads, join and resume sequential thread Uses pragma:#pragma omp parallel Shared/private
"Charting the Course to Your Success!" MOC A Developing High-performance Applications using Microsoft Windows HPC Server 2008
 Description Course Summary This course provides students with the knowledge and skills to develop high-performance computing (HPC) applications for Microsoft. Students learn about the product Microsoft,
Description Course Summary This course provides students with the knowledge and skills to develop high-performance computing (HPC) applications for Microsoft. Students learn about the product Microsoft,
Contributions to Parallel Simulation of Equation-Based Models on Graphics Processing Units
 Linköping Studies in Science and Technology Thesis No. 1507 Contributions to Parallel Simulation of Equation-Based Models on Graphics Processing Units by Kristian Stavåker Submitted to Linköping Institute
Linköping Studies in Science and Technology Thesis No. 1507 Contributions to Parallel Simulation of Equation-Based Models on Graphics Processing Units by Kristian Stavåker Submitted to Linköping Institute
Towards Approximate Computing: Programming with Relaxed Synchronization
 Towards Approximate Computing: Programming with Relaxed Synchronization Lakshminarayanan Renganarayana Vijayalakshmi Srinivasan Ravi Nair (presenting) Dan Prener IBM T.J. Watson Research Center October
Towards Approximate Computing: Programming with Relaxed Synchronization Lakshminarayanan Renganarayana Vijayalakshmi Srinivasan Ravi Nair (presenting) Dan Prener IBM T.J. Watson Research Center October
OpenMP Introduction. CS 590: High Performance Computing. OpenMP. A standard for shared-memory parallel programming. MP = multiprocessing
 CS 590: High Performance Computing OpenMP Introduction Fengguang Song Department of Computer Science IUPUI OpenMP A standard for shared-memory parallel programming. MP = multiprocessing Designed for systems
CS 590: High Performance Computing OpenMP Introduction Fengguang Song Department of Computer Science IUPUI OpenMP A standard for shared-memory parallel programming. MP = multiprocessing Designed for systems
Parallelization, OpenMP
 ~ Parallelization, OpenMP Scientific Computing Winter 2016/2017 Lecture 26 Jürgen Fuhrmann juergen.fuhrmann@wias-berlin.de made wit pandoc 1 / 18 Why parallelization? Computers became faster and faster
~ Parallelization, OpenMP Scientific Computing Winter 2016/2017 Lecture 26 Jürgen Fuhrmann juergen.fuhrmann@wias-berlin.de made wit pandoc 1 / 18 Why parallelization? Computers became faster and faster
Threads CS1372. Lecture 13. CS1372 Threads Fall / 10
 Threads CS1372 Lecture 13 CS1372 Threads Fall 2008 1 / 10 Threads 1 In order to implement concurrent algorithms, such as the parallel bubble sort discussed previously, we need some way to say that we want
Threads CS1372 Lecture 13 CS1372 Threads Fall 2008 1 / 10 Threads 1 In order to implement concurrent algorithms, such as the parallel bubble sort discussed previously, we need some way to say that we want
SQL Server Administration 10987: Performance Tuning and Optimizing SQL Databases. Upcoming Dates. Course Description.
 SQL Server Administration 10987: Performance Tuning and Optimizing SQL Databases Learn the high level architectural overview of SQL Server 2016 and explore SQL Server execution model, waits and queues
SQL Server Administration 10987: Performance Tuning and Optimizing SQL Databases Learn the high level architectural overview of SQL Server 2016 and explore SQL Server execution model, waits and queues
Quiz for Chapter 1 Computer Abstractions and Technology
 Date: Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Date: Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Chapter 4: Threads. Chapter 4: Threads
 Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples
Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples
From versatile analysis methods to interactive simulation with a motion platform based on SimulationX and FMI
 From versatile analysis methods to interactive simulation with a motion platform based on SimulationX and FMI SimulationX Tutorial, 8th Modelica Conference Dr. Ines Gubsch, IVMA, TUD Christian Schubert,
From versatile analysis methods to interactive simulation with a motion platform based on SimulationX and FMI SimulationX Tutorial, 8th Modelica Conference Dr. Ines Gubsch, IVMA, TUD Christian Schubert,
CS4961 Parallel Programming. Lecture 12: Advanced Synchronization (Pthreads) 10/4/11. Administrative. Mary Hall October 4, 2011
 10/4/11. Administrative. Mary Hall October 4, 2011") CS4961 Parallel Programming Lecture 12: Advanced Synchronization (Pthreads) Mary Hall October 4, 2011 Administrative Thursday s class Meet in WEB L130 to go over programming assignment Midterm on Thursday
CS4961 Parallel Programming Lecture 12: Advanced Synchronization (Pthreads) Mary Hall October 4, 2011 Administrative Thursday s class Meet in WEB L130 to go over programming assignment Midterm on Thursday
Shared Memory Programming With OpenMP Exercise Instructions
 Shared Memory Programming With OpenMP Exercise Instructions John Burkardt Interdisciplinary Center for Applied Mathematics & Information Technology Department Virginia Tech... Advanced Computational Science
Shared Memory Programming With OpenMP Exercise Instructions John Burkardt Interdisciplinary Center for Applied Mathematics & Information Technology Department Virginia Tech... Advanced Computational Science
Chapter 4: Multi-Threaded Programming
 Chapter 4: Multi-Threaded Programming Chapter 4: Threads 4.1 Overview 4.2 Multicore Programming 4.3 Multithreading Models 4.4 Thread Libraries Pthreads Win32 Threads Java Threads 4.5 Implicit Threading
Chapter 4: Multi-Threaded Programming Chapter 4: Threads 4.1 Overview 4.2 Multicore Programming 4.3 Multithreading Models 4.4 Thread Libraries Pthreads Win32 Threads Java Threads 4.5 Implicit Threading
OpenMP * Past, Present and Future
 OpenMP * Past, Present and Future Tim Mattson Intel Corporation Microprocessor Technology Labs timothy.g.mattson@intel.com * The name OpenMP is the property of the OpenMP Architecture Review Board. 1 OpenMP
OpenMP * Past, Present and Future Tim Mattson Intel Corporation Microprocessor Technology Labs timothy.g.mattson@intel.com * The name OpenMP is the property of the OpenMP Architecture Review Board. 1 OpenMP
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
OpenMP for next generation heterogeneous clusters
 OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
Morsel- Drive Parallelism: A NUMA- Aware Query Evaluation Framework for the Many- Core Age. Presented by Dennis Grishin
 Morsel- Drive Parallelism: A NUMA- Aware Query Evaluation Framework for the Many- Core Age Presented by Dennis Grishin What is the problem? Efficient computation requires distribution of processing between
Morsel- Drive Parallelism: A NUMA- Aware Query Evaluation Framework for the Many- Core Age Presented by Dennis Grishin What is the problem? Efficient computation requires distribution of processing between
OmpCloud: Bridging the Gap between OpenMP and Cloud Computing
 OmpCloud: Bridging the Gap between OpenMP and Cloud Computing Hervé Yviquel, Marcio Pereira and Guido Araújo University of Campinas (UNICAMP), Brazil A bit of background qguido Araujo, PhD Princeton University
OmpCloud: Bridging the Gap between OpenMP and Cloud Computing Hervé Yviquel, Marcio Pereira and Guido Araújo University of Campinas (UNICAMP), Brazil A bit of background qguido Araujo, PhD Princeton University
Multigrain Parallelism: Bridging Coarse- Grain Parallel Languages and Fine-Grain Event-Driven Multithreading
 Department of Electrical and Computer Engineering Computer Architecture and Parallel Systems Laboratory - CAPSL Multigrain Parallelism: Bridging Coarse- Grain Parallel Languages and Fine-Grain Event-Driven
Department of Electrical and Computer Engineering Computer Architecture and Parallel Systems Laboratory - CAPSL Multigrain Parallelism: Bridging Coarse- Grain Parallel Languages and Fine-Grain Event-Driven