IN5050: Programming heterogeneous multi-core processors SIMD (and SIMT)
|
|
|
- Aldous Allen
- 5 years ago
- Views:
Transcription





1 : Programming heterogeneous multi-core processors SIMD (and SIMT) single scull: one is fast quad scull: many are faster
2 Types of Parallel Processing/Computing? Bit-level parallelism 4-bit à 8-bit à 16-bit à 32-bit à 64-bit à Instruction level parallelism classic RISC pipeline (fetch, decode, execute, memory, write back) IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB

3 Types of Parallel Processing/Computing? Task parallelism Different operations are performed concurrently Task parallelism is achieved when the processors execute different threads (or processes) on the same or different data Examples: Scheduling on a multicore


4 Types of Parallel Processing/Computing? Data parallelism Distribution of data across different parallel computing nodes Data parallelism is achieved when each processor performs the same task on different pieces of the data Examples? for each element a perform the same (set of) instruction(s) on a end When should we not use data parallelism?

5 Flynn's taxonomy Single instruction Multiple instruction Single data Multiple data
6 Vector processors A vector processor (or array processor) CPU that implements an instruction set containing instructions that operate on one-dimensional arrays (vectors) Example systems: Cray-1 (1976) IBM 4096 bits registers (64x64-bit floats) POWER with ViVA (Virtual Vector Architecture) 128 bits registers Cell SPE 128 bit registers SUN UltraSPARC with VIS 64-bit registers NEC SX-6/SX-9 (2008) with 72x 4096 bit registers Intel ARM
7 Vector processors People use vector processing in many areas Scientific computing Multimedia Processing (compression, graphics, image processing, ) Standard benchmark kernels (Matrix Multiply, FFT, Convolution, Sort) Lossy Compression (JPEG, MPEG video and audio) Lossless Compression (Zero removal, RLE, Differencing, LZW) Cryptography (RSA, DES/IDEA, SHA/MD5) Speech and handwriting recognition Operating systems (memcpy, memset, parity, ) Networking (checksum, ) Databases (hash/join, data mining, updates) Instruction sets: MMX SSE AVX AltiVec 3DNow! NEON
8 Vector Instruction sets MMX MMX is officially a meaningless initialism trademarked by Intel; unofficially, MultiMedia extension Multiple Math extension Matrix Math extension Introduced on the Pentium with MMX Technology in SIMD computation processes multiple data in parallel with a single instruction, resulting in significant performance improvement; MMX gives 2 x 32-bit computations at once. MMX defined 8 new 64-bit integer registers (mm0 ~ mm7), which were aliases for the existing x87 FPU registers reusing 64 (out of 80) bits in the floating point registers. 3DNow! was the AMD extension of MMX (closed down in 2010).
9 Vector Instruction sets SSE Streaming SIMD Extensions (SSE) SIMD; 4 simultaneous 32-bit computations Altivec has same size (128-bit), has some more advanced instructions, but has seem to lose the performance battle SSE defines 8 new 128-bit registers (xmm0 ~ xmm7) for single-precision floating-point computations. Since each register is 128-bit long, we can store total 4 of 32-bit floating-point numbers (1-bit sign, 8-bit exponent, 23-bit mantissa/fraction). Single or packed scalar operations: SS vs PS
 and Skylake-SP.")
10 Vector Instruction sets AVX Advanced Vector Extensions (AVX) SIMD; 8 simultaneous 32-bit computations AVX-215 AVX SSE A new-256 bit instruction set extension to SSE 16-registers available in x86-64 Registers renamed from XMM i to YMM i Yet a proposed extension is AXV-512 A 512-bit extension to the 256-bit XMM supported in Intel's Xeon Phi x200 (Knights Landing) and Skylake-SP. Will be in future Intel CPUs for desktop (Ice Lake)

11 Vector Instruction sets NEON Also known as Advanced SIMD Extensions. Introduced by ARM in 2004 to accelerate media and signal processing NEON can for example execute MP3 decoding on CPUs running at 10 MHz 128-bit SIMD Extension for the ARMv7 & ARMv8. Data types can be: signed/unsigned 8-bit, 16-bit, 32-bit or 64-bit. More next week home exam!




12 SIMD: Why not just auto-magical? Why should I bother? Libraries, frameworks and compiler optimizations can do the work for me True but lot of performance at stake! simplified 4 cores can potentially give a 4x speedup AVX-512 can potentially give an 8x speedup Combined, 32x!! optimizers are good, but sometimes fail to meet your needs! learn invaluable understanding of the best use of vectorization!

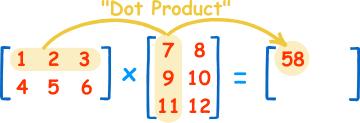
13 Vector Multiplication using SSE (and AVX)
14 Element-wise Vector Multiplication Find element-wise product of 2 vectors: a 1 a 2 a 3 a 4 a 5 a 6 a n * * * * * * * b 1 b 2 b 3 b 4 b 5 b 6 b n = = = = = = = a 1 *b 1 a 2 *b 2 a 3 *b 3 a 4 *b 4 a 5 *b 5 a 6 *b 6 a n *b n void vec_eltwise_product(vec_t* a, vec_t* b, vec_t* c) { size_t i; for (i = 0; i < a->size; i++) { c->data[i] = a->data[i] * b->data[i];
15 Element-wise Vector Multiplication Unroll loop void vec_eltwise_product(vec_t* a, vec_t* b, vec_t* c) { size_t i; for (i = 0; i < a->size; i++) { c->data[i] = a->data[i] * b->data[i]; SSE can take 4 x 32-bit operations in parallel using the 128-bit registers à unroll loop to a 4-element operation void vec_eltwise_product_unrolled(vec_t* a, vec_t* b, vec_t* c) { void vec_eltwise_product(vec_t* a, vec_t* b, vec_t* c) size_t { i; for (i = 0; size_t i < a->size; i; i+=4) { c->data[i+0] for (i = 0; = i a->data[i+0] < a->size; i++) * b->data[i+0]; { c->data[i+1] c->data[i] = a->data[i+1] = a->data[i] * b->data[i+1]; * b->data[i]; c->data[i+2] = a->data[i+2] * b->data[i+2]; c->data[i+3] = a->data[i+3] * b->data[i+3];
16 Element-wise Vector Multiplication Use SSE assembly instructions: void vec_eltwise_product_unrolled(vec_t* a, vec_t* b, vec_t* c) { size_t i; for (i = 0; i < a->size; i+=4) { c->data[i+0] = a->data[i+0] * b->data[i+0]; c->data[i+1] = a->data[i+1] * b->data[i+1]; c->data[i+2] = a->data[i+2] * b->data[i+2]; c->data[i+3] = a->data[i+3] * b->data[i+3]; operations on these 4 elements can be performed in parallel void vec_eltwise_product_unrolled(vec_t* a, vec_t* b, vec_t* c) { ; void vec_eltwise_product_unrolled (a, b, c) size_t i; for (i = 0; i < a->size; i+=4) { MOVUPS (Move Unaligned Packed Single-Precision Floating- Point Values) moves four packed single-precision floating-point numbers from the source operand (second operand) to the destination operand (first operand) MULPS (Packed Single-Precision Floating-Point Multiply) performs a SIMD multiply of the four packed single-precision floating-point values from the source operand (second operand) and the destination operand (first operand), and stores the packed single-precision floating-point results in the destination operand. vec_eltwise_product_sse: pushall mov ebp, esp mov edi, [ebp+12] ; a mov ebx, [ebp+16] ; b mov eax, [ebp+20] ; c c->data[i+0] = a->data[i+0] * b->data[i+0]; mov c->data[i+1] = a->data[i+1] * b->data[i+1]; c->data[i+2] = a->data[i+2] * b->data[i+2]; c->data[i+3] = a->data[i+3] * b->data[i+3]; ecx, SIZE_OF_VECTOR ; counting i down shr ecx, 2 ; use 4-increment of i xor esi, esi ; array index = 0 for-loop: movups xmm1, [edi + esi] ; read in a movups xmm2, [ebx + esi] ; read in b mulps xmm1, xmm2 ; multiply movups [eax + esi], xmm1 ; result back in c add esi, 4 ; next 4 elemens loop for-loop exit: popall ret LOOP decrements ECX and jumps to the address specified by arg unless decrementing ECX caused its value to become zero.
17 Element-wise Vector Multiplication Use SSE intrinsic functions: intrinsic SSE functions exist, e.g., for gcc on Intel Linux: ; void vec_eltwise_product_unrolled (a, b, c) vec_eltwise_product_sse: pushall mov ebp, esp mov edi, [ebp+12] ; a mov ebx, [ebp+16] ; b mov eax, [ebp+20] ; c dst = _mm_loadu_ps(src) src1 = _mm_mul_ps(src1, src2) mov ecx, SIZE_OF_VECTOR ; counting i down shr ecx, 2 ; use 4-increment of i xor esi, esi ; array index = 0 for-loop: movups xmm1, [edi + esi] ; read in a movups xmm2, [ebx + esi] ; read in b mulps xmm1, xmm2 ; multiply movups [eax + esi], xmm1 ; result back in c add esi, 4 ; next 4 elemens loop for-loop exit: popall ret src1 = _mm_add_ps(src1, src2) which can be used without any (large/noticeable) performance loss à movups dst, src à mulps src1, src2 à addps src1, src2 ; void vec_eltwise_product_unrolled (a, b, c) void vec_eltwise_product_sse(vec_t* a, vec_t* b, vec_t* c) { size_t i; m128 va; vec_eltwise_product_sse: pushall mov ebp, esp mov edi, [ebp+12] ; a mov ebx, [ebp+16] ; b mov eax, [ebp+20] ; c m128 vb; m128 vc; for (i = 0; i < a->size; i+= 4) { mov ecx, SIZE_OF_VECTOR ; counting i down shr ecx, 2 ; use 4-increment of i xor esi, esi ; array index = 0 for-loop: movups va xmm1, = _mm_loadu_ps(&a->data[i]); [edi + esi] ; read in a movups xmm2, [ebx + esi] ; read in b mulps vb xmm1, = _mm_loadu_ps(&b->data[i]); xmm2 ; multiply movups [eax + esi], xmm1 ; result back in c add vc esi, = _mm_mul_ps(va, 4 ; next vb); 4 elemens loop for-loop _mm_storeu_ps(&c->data[i], vc); exit: popall ret
18 Element-wise Vector Multiplication Use SSE intrinsic functions: ; void vec_eltwise_product_unrolled (a, b, c) vec_eltwise_product_sse: pushall mov ebp, esp mov edi, [ebp+12] ; a mov ebx, [ebp+16] ; b mov eax, [ebp+20] ; c mov ecx, SIZE_OF_VECTOR ; counting i down shr ecx, 2 ; use 4-increment of i xor esi, esi ; array index = 0 for-loop: movups xmm1, [edi + esi] ; read in a movups xmm2, [ebx + esi] ; read in b mulps xmm1, xmm2 ; multiply movups [eax + esi], xmm1 ; result back in c add esi, 4 ; next 4 elemens loop for-loop exit: popall ret void vec_eltwise_product_sse(vec_t* a, vec_t* b, vec_t* c) { size_t i; m128 va; m128 vb; m128 vc; for (i = 0; i < a->size; i+= 4) { va = _mm_loadu_ps(&a->data[i]); vb = _mm_loadu_ps(&b->data[i]); vc = _mm_mul_ps(va, vb); _mm_storeu_ps(&c->data[i], vc);
 void vec_eltwise_product_sse(vec_t* a, vec_t* b, vec_t* c) { size_t i; m128 va; m128 vb; m128 vc; for (i = 0; i < a->size;")
![i+= 4) { va = _mm_loadu_ps(&a->data[i]); vb = _mm_loadu_ps(&b->data[i]); vc = _mm_mul_ps(va, vb); _mm_storeu_ps(&c->data[i], vc); void vec_eltwise_product_sse(vec_t* a, vec_t* b, vec_t* c) { size_t](/docs-images/94/118739349/images/19-1.jpg "i; à m256 va; m128 va; à m256 vb; m128 vb; à m256 vc; m128 vc; à i += 8; for (i = 0; i < a->size; i+= 4) { à va = _mm256_loadu_ps(&a->data[i]); va = _mm_loadu_ps(&a->data[i]); à vb")
19 Element-wise Vector Multiplication SSE vs AVX (Advanced Vector Extensions) AVX is similar to SSE, but has twice the width of the registers: 256 bit renamed registers (now 16) from XMM i to YMM i available from Intel's Sandy Bridge and AMD's Bulldozer prosessors (2011) void vec_eltwise_product_sse(vec_t* a, vec_t* b, vec_t* c) { size_t i; m128 va; m128 vb; m128 vc; for (i = 0; i < a->size; i+= 4) { va = _mm_loadu_ps(&a->data[i]); vb = _mm_loadu_ps(&b->data[i]); vc = _mm_mul_ps(va, vb); _mm_storeu_ps(&c->data[i], vc); void vec_eltwise_product_sse(vec_t* a, vec_t* b, vec_t* c) { size_t i; à m256 va; m128 va; à m256 vb; m128 vb; à m256 vc; m128 vc; à i += 8; for (i = 0; i < a->size; i+= 4) { à va = _mm256_loadu_ps(&a->data[i]); va = _mm_loadu_ps(&a->data[i]); à vb _mm256_loadu_ps(&b->data[i]); vb = _mm_loadu_ps(&b->data[i]); à vc _mm256_mul_ps(va, vb); vc = _mm_mul_ps(va, vb); à _mm256_storeu_ps(&c->data[i], vc); _mm_storeu_ps(&c->data[i], vc);

20 Matrix multiplication using SSE
21 Matrix Multiplication
22 Matrix Multiplication - C #include <stdio.h> float elts[4][4] = {1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4; float vin[4] = {1,2,3,4; float vout[4]; void main(void) { vout[0] = elts[0][0] * vin[0] + elts[0][1] * vin[1] + elts[0][2] * vin[2] + elts[0][3] * vin[3]; vout[1] = elts[1][0] * vin[0] + elts[1][1] * vin[1] + elts[1][2] * vin[2] + elts[1][3] * vin[3]; vout[2] = elts[2][0] * vin[0] + elts[2][1] * vin[1] + elts[2][2] * vin[2] + elts[2][3] * vin[3]; vout[3] = elts[3][0] * vin[0] + elts[3][1] * vin[1] + elts[3][2] * vin[2] + elts[3][3] * vin[3]; printf("%f %f %f %f\n", vout[0], vout[1], vout[2], vout[3]);
23 Matrix Multiplication SSE #include <stdio.h> float elts[4][4] = {1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4; float vin[4] = {1,2,3,4; float vout[4]; void main(void) { Efficient multiplication, MULPS a, b = [A0*B0, A1*B1, A2*B2, A3*B3] but no efficient way to do the horizontal add: HADDPS a, b = [B0+B1, B2+B3, A0+A1, A2+A3] vout[0] = elts[0][0] * vin[0] + elts[0][1] * vin[1] + after (first row) multiplication we have x = [1, 2, 3, 4], add: 1. y = mm_hadd_ps(x, x) = [1+2, 3+4, 1+2, 3+4] 2. z = mm_hadd_ps(y, y) = [ , , , ] elts[0][2] * vin[2] + elts[0][3] * vin[3]; 3. move Z0 to destination register vout[1] = elts[1][0] * vin[0] + elts[1][1] * vin[1] + elts[1][2] * vin[2] + elts[1][3] * vin[3]; vout[2] = elts[2][0] * vin[0] + elts[2][1] * vin[1] elts[2][2] * vin[2] + elts[2][3] * vin[3]; vout[3] = elts[3][0] * vin[0] + elts[3][1] * vin[1] + elts[3][2] * vin[2] + elts[3][3] * vin[3]; printf("%f %f %f %f\n", vout[0], vout[1], vout[2], vout[3]);
24 Matrix Multiplication SSE Assuming elts in a COLUMN-MAJOR order: a b c d e f g h i j k l m n o p a e i n b f j n c g k o d h l p

25 Matrix Multiplication SSE Store elts in column-major order transpose using unpack low/high-order data elements: Assuming elts in a COLUMN-MAJOR order: a b c d e f g h i j k l m n o p <load matrix into IO,..I3 m128i registers > /* Interleave values */ m128i T0 = _mm_unpacklo_epi32(i0, I1); m128i T1 = _mm_unpacklo_epi32(i2, I3); m128i T2 = _mm_unpackhi_epi32(i0, I1); m128i T3 = _mm_unpackhi_epi32(i2, I3); /* Assigning transposed values back into I[0-3] */ O0 = _mm_unpacklo_epi64(t0, T1); O1 = _mm_unpackhi_epi64(t0, T1); O2 = _mm_unpacklo_epi64(t2, T3); O3 = _mm_unpackhi_epi64(t2, T3); a e i n b f j n c g k o d h l p m128i _mm_unpacklo_epi32 ( m128i a, m128i b); Interleaves the lower 2 signed or unsigned 32-bit integers in a with the lower 2 signed or unsigned 32-bit integers in b. m128i _mm_unpackhi_epi32 ( m128i a, m128i b); Interleaves the upper 2 signed or unsigned 32-bit integers in a with the upper 2 signed or unsigned 32-bit integers in b. m128i _mm_unpackhi/lo_epi64 ( m128i a, m128i b); Interleaves the upper / lower signed or unsigned 64-bit integers in a with the upper signed or unsigned 64-bit integers in b.
26 Matrix Multiplication SSE asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20] movups xmm7, [edx + 0x30] // load v into xmm0. movups xmm0, [esi] // we'll store the final result in xmm2; initialize it // to zero xorps xmm2, xmm2 // broadcast x into xmm1, multiply it by the first // column i of j the k matrix l (xmm4), and add it to the total movups xmm1, xmm0 shufps m n xmm1, o xmm1, p 0x00 mulps xmm1, xmm4 addps xmm2, xmm1 // repeat a e the i process n b f for j y, n z and c g w k o d h l p movups xmm1, xmm0 shufps xmm1, xmm1, 0x55 mulps xmm1, xmm5 addps xmm2, xmm1 movups shufps mulps addps movups shufps mulps addps Assuming elts in a COLUMN-MAJOR order: a b c d e f g h xmm1, xmm0 xmm1, xmm1, 0xAA xmm1, xmm6 xmm2, xmm1 xmm1, xmm0 xmm1, xmm1, 0xFF xmm1, xmm7 xmm2, xmm1 // write the results to vout movups [edi], xmm2
27 Matrix Multiplication SSE asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20] movups xmm7, [edx + 0x30] // load v into xmm0. movups xmm0, [esi] // we'll store the final result in xmm2; initialize it // to zero xorps xmm2, xmm2 // broadcast x into xmm1, multiply it by the first // column of the matrix (xmm4), and add it to the total movups xmm1, xmm0 shufps xmm1, xmm1, 0x00 mulps xmm1, xmm4 addps xmm2, xmm1 // repeat the process for y, z and w movups xmm1, xmm0 shufps xmm1, xmm1, 0x55 mulps xmm1, xmm5 addps xmm2, xmm1 movups shufps mulps addps movups shufps mulps addps xmm1, xmm0 xmm1, xmm1, 0xAA xmm1, xmm6 xmm2, xmm1 xmm1, xmm0 xmm1, xmm1, 0xFF xmm1, xmm7 xmm2, xmm1 // write the results to vout movups [edi], xmm2
![Matrix Multiplication SSE asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20]](/docs-images/94/118739349/images/28-0.jpg "movups xmm7, [edx + 0x30] // load v into xmm0.")
28 Matrix Multiplication SSE asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20] movups xmm7, [edx + 0x30] // load v into xmm0. movups xmm0, [esi] // we'll store the final result in xmm2; initialize it // to zero xorps xmm2, xmm2 // broadcast x into xmm1, multiply it by the first // column of the matrix (xmm4), and add it to the total movups xmm1, xmm0 shufps xmm1, xmm1, 0x00 mulps xmm1, xmm4 addps xmm2, xmm1 // repeat the process for y, z and w movups xmm1, xmm0 shufps xmm1, xmm1, 0x55 mulps xmm1, xmm5 addps xmm2, xmm1 movups shufps mulps addps movups shufps mulps addps xmm1, xmm0 xmm1, xmm1, 0xAA xmm1, xmm6 xmm2, xmm1 xmm1, xmm0 xmm1, xmm1, 0xFF xmm1, xmm7 xmm2, xmm1 // write the results to vout movups [edi], xmm2
29 Matrix Multiplication SSE asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20] movups xmm7, [edx + 0x30] // load v into xmm0. movups xmm0, [esi] // we'll store the final result in xmm2; initialize it // to zero xorps xmm2, xmm2 // broadcast x into xmm1, multiply it by the first // column of the matrix (xmm4), and add it to the total movups xmm1, xmm0 shufps xmm1, xmm1, 0x00 mulps xmm1, xmm4 addps xmm2, xmm1 // repeat the process for y, z and w movups xmm1, xmm0 shufps xmm1, xmm1, 0x55 mulps xmm1, xmm5 addps xmm2, xmm1 movups shufps mulps addps movups shufps mulps addps xmm1, xmm0 xmm1, xmm1, 0xAA xmm1, xmm6 xmm2, xmm1 xmm1, xmm0 xmm1, xmm1, 0xFF xmm1, xmm7 xmm2, xmm1 // write the results to vout movups [edi], xmm2
30 Matrix Multiplication SSE asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20] movups xmm7, [edx + 0x30] // load v into xmm0. movups xmm0, [esi] // we'll store the final result in xmm2; initialize it // to zero xorps xmm2, xmm2 // broadcast x into xmm1, multiply it by the first // column of the matrix (xmm4), and add it to the total movups xmm1, xmm0 shufps xmm1, xmm1, 0x00 mulps xmm1, xmm4 addps xmm2, xmm1 // repeat the process for y, z and w movups xmm1, xmm0 shufps xmm1, xmm1, 0x55 mulps xmm1, xmm5 addps xmm2, xmm1 movups shufps mulps addps movups shufps mulps addps xmm1, xmm0 xmm1, xmm1, 0xAA xmm1, xmm6 xmm2, xmm1 xmm1, xmm0 xmm1, xmm1, 0xFF xmm1, xmm7 xmm2, xmm1 // write the results to vout movups [edi], xmm2
31 Matrix Multiplication SSE xmm0 - VIN: xmm1: xmm2 - result: xmm4: xmm5: xmm6: xmm7: asm { mov mov esi, VIN edi, VOUT // load columns of (transposed) matrix into xmm4-7 mov edx, ELTS movups xmm4, [edx] movups xmm5, [edx + 0x10] movups xmm6, [edx + 0x20] movups xmm7, [edx + 0x30] // load v into xmm0. movups xmm0, [esi] // we'll store the final result in xmm2; initialize it // to zero xorps xmm2, xmm2 // broadcast x into xmm1, multiply it by the first // column of the matrix (xmm4), and add it to the total movups xmm1, xmm0 shufps xmm1, xmm1, 0x00 mulps xmm1, xmm4 addps xmm2, xmm1 // repeat the process for y, z and w movups xmm1, xmm0 shufps xmm1, xmm1, 0x55 mulps xmm1, xmm5 addps xmm2, xmm1 movups shufps mulps addps movups shufps mulps addps xmm1, xmm0 xmm1, xmm1, 0xAA xmm1, xmm6 xmm2, xmm1 xmm1, xmm0 xmm1, xmm1, 0xFF xmm1, xmm7 xmm2, xmm1 // write the results to vout movups [edi], xmm
32 Changing picture brightness using SSE

33 Brightness make_brighter Make a simple program that change the brightness of a picture by adding a brightness value between -128 and 127 to each pixel. A positive value makes the picture brighter, a negative value darker. Assume it is a one byte pixel in gray scale, or a YUV picture where you operate on the Y-part only (luma - brightness).
34 Brightness main <.. includes..> int main (int argc, char *argv[]) { <... more variables... > unsigned char *bw_image; int image_len, bright_value; < open input and output files > bright_value = atoi( argv[ ] ); /* a value between -128 and 127 */ image_len = atoi( argv[ ] ) * atoi( argv[ ] ); /* picture width x picture height */ bw_image = (unsigned char *) malloc(image_len + 15); /* +15 to allow 16-byte alignment */ if ((((long)bw_image) % 16)!= 0) bw_image += 16 - ((long)bw_image % 16); /* align */ < read picture to into memory with first pixel at "bw_image" > if (bright_value!=0 ) brightness( bw_image, image_len, bright_value ); < write picture back to file > < free memory, close descriptors >
35 Brightness Naïve C void brightness (unsigned char *buffer, int len, int v) { int t, new_pixel_value; if (v > 0) { for (t = 0; t < len; t++) { /* make brighter */ new_pixel_value = buffer[t] + v; if (new_pixel_value > 255) new_pixel_value = 255; buffer[t] = new_pixel_value; else { for (t = 0; t < len; t++) { /* make darker */ new_pixel_value = buffer[t] + v; if (new_pixel_value < 0) new_pixel_value = 0; buffer[t] = new_pixel_value; What is the potential for parallelization using SSE-vectors?
![Brightness SSE ASM ; void brightness_sse_asm(unsigned char *image, int len, int v) brightness_sse_asm: pushall mov ebp, esp mov edi, [ebp+12] ; unsigned char *image mov ecx, [ebp+16] ; int len mov](/docs-images/94/118739349/images/36-0.jpg "eax, [ebp+20] ; int v in [-128, 127] test eax, 0x80000000 ; check if v is negative jz bright_not_neg xor al, 255 ; make al abs(v) inc al ; add 1 bright_not_neg: shr ecx, 4 ; len = len / 16 (shift")
36 Brightness SSE ASM ; void brightness_sse_asm(unsigned char *image, int len, int v) brightness_sse_asm: pushall mov ebp, esp mov edi, [ebp+12] ; unsigned char *image mov ecx, [ebp+16] ; int len mov eax, [ebp+20] ; int v in [-128, 127] test eax, 0x ; check if v is negative jz bright_not_neg xor al, 255 ; make al abs(v) inc al ; add 1 bright_not_neg: shr ecx, 4 ; len = len / 16 (shift right 4) PINSRW (Packed Insert Word) moves the lower word in a 32- bit integer register or 16-bit word from memory into one of the 8 word locations in destination MMX/SSE register. The insertion is done in such a way that the 7 other words from the destination register are left untouched. mov ah, al ; xmm1=(v,v,v,v,v,v,v,v,v,v,v,v,v,v,v,v) pinsrw xmm1, ax, 0 ; Packed Insert Word pinsrw xmm1, ax, 1 pinsrw xmm1, ax, 2 ;; Fewer instructions ALTERNATIVE pinsrw xmm1, ax, 3 ;; using shufps pinsrw xmm1, ax, 4 move ah, al pinsrw xmm1, ax, 5 pinsrw xmm1, ax, 0 pinsrw xmm1, ax, 6 pinsrw xmm1, ax, 1 pinsrw xmm1, ax, 7 shufps xmm1, xmm1, 0x00 test eax, 0xff ; if v was negative, jnz dark_loop ; make darker bright_loop: movdqa xmm0, [edi] ; move aligned double quadword paddusb xmm0, xmm1 ; packed add unsigned movdqa [edi], xmm0 MOVDQA (move aligned double) Moves a double quadword from the source operand (second operand) to the destination operand (first operand). PADDUSB (Packed Add Unsigned with Saturation) instruction adds packed unsigned byte integers. When an individual byte result is beyond the range of an unsigned byte integer (that is, greater than 0xFF), the saturated value of 0xFF is written to the destination operand. add edi, 16 ; ptr = ptr + 16 loop bright_loop ; while (count>0) jmp exit dark_loop: movdqa xmm0, [edi] psubusb xmm0, xmm1 movdqa [edi], xmm0 add edi, 16 loop dark_loop exit: popall ret ; ptr=ptr+16 ; while (count>0) PSUBUSB (Packed Subtract Unsigned with Saturation) instruction subtracts packed unsigned byte integers. When an individual byte result is less than zero (a negative value), the saturated value of 0x00 is written to the destination operand.
37 Brightness SSE Intrinsics void brightness_sse (unsigned char *buffer, int len, int v) { m128 pixel_vector; m128 value_vector; int t; if (v > 0) { < make v char > value_vector = _mm_set1_epi8( v ); /* PINSRW, SHUFPS, etc..*/ for (t = 0; t < len; t += 16) { pixel_vector = ( int128 *)(buffer+t); /* MOVDQA */ pixel_vector = _mm_adds_epi8(pixel_vector, value_vector); /* PADDUSB */ *(( m128 *)(buffer+t)) = pixel_vector; /* MOVDQA */ else { % (v <= 0) v=-v; < make v char > value_vector = _mm_set1_epi8(v); for (t = 0; t < len; t += 16) { pixel_vector = ( int128 *)(buffer+t); /* MOVDQA */ pixel_vector = _mm_subs_epi8(pixel_vector, value_vector); /* PSUBUSB */ *(( m128 *)(buffer+t)) = pixel_vector; /* MOVDQA */
; /* PINSRW, SHUFPS, etc.")
(buffer+t)) = pixel_vector; /* MOVDQA */ else { % (v <= 0) v=-v; < make v char > value_vector = _mm_set1_epi8(v); for (t = 0; t < len; t += 16) { pixel_vector = ( int128")
38 Brightness SSE Intrinsics void brightness_sse (unsigned char *buffer, int len, int v) { m128 pixel_vector; m128 value_vector; int t; if (v > 0) { < make v char > value_vector = _mm_set1_epi8( v ); /* PINSRW, SHUFPS, etc..*/ for (t = 0; t < len; t += 16) { pixel_vector = ( int128 *)(buffer+t); /* MOVDQA */ pixel_vector = _mm_adds_epi8(pixel_vector, value_vector); /* PADDUSB */ *(( m128 *)(buffer+t)) = pixel_vector; /* MOVDQA */ else { % (v <= 0) v=-v; < make v char > value_vector = _mm_set1_epi8(v); for (t = 0; t < len; t += 16) { pixel_vector = ( int128 *)(buffer+t); /* MOVDQA */ pixel_vector = _mm_subs_epi8(pixel_vector, value_vector); /* PSUBUSB */ *(( m128 *)(buffer+t)) = pixel_vector; /* MOVDQA */

39 SIMT single instruction multiple threads


 operations vs. 1000+ threads?) SIMT easier code?")
40 SIMT Single Instruction Multiple Threads (SIMT) SIMD + multithreading Nvidia's CUDA GPU microarchitecture introduced the SIMT execution model where multiple independent threads execute concurrently using a single instruction Flexibility: SIMD < SIMT < SIM SIMT is more flexible in SIMD in three areas: Single instruction, multiple register sets Single instruction, multiple addresses Single instruction, multiple flow path Performance: SIMD > SIMT > SIM Less flexibility usually means higher performance However, massive parallelism in SIMT? (2-16x (64x) operations vs threads?) SIMT easier code? Now: CUDA = SIMD? SIMT? MIMD? MIMT?

41


42 Summary Vector instructions (or intrinsic functions) can be used for SIMD operations single operation on multiple data elements SIMT is more or less SIMD + multithreading Tomorrow, video coding and a practical example using SSE/AVX Next week, ARM and NEON (to be used in your home exam)
43 Some SSE/AVX Resources SSE instructions: Intrinsics:
INF5063: Programming heterogeneous multi-core processors. Introduction. Håkon Kvale Stensland. August 25 th, 2015
 : Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 25 th, 2015 Overview Course topic and scope Background for the use and parallel processing using heterogeneous
: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 25 th, 2015 Overview Course topic and scope Background for the use and parallel processing using heterogeneous
Dan Stafford, Justine Bonnot
 Dan Stafford, Justine Bonnot Background Applications Timeline MMX 3DNow! Streaming SIMD Extension SSE SSE2 SSE3 and SSSE3 SSE4 Advanced Vector Extension AVX AVX2 AVX-512 Compiling with x86 Vector Processing
Dan Stafford, Justine Bonnot Background Applications Timeline MMX 3DNow! Streaming SIMD Extension SSE SSE2 SSE3 and SSSE3 SSE4 Advanced Vector Extension AVX AVX2 AVX-512 Compiling with x86 Vector Processing
Using MMX Instructions to Perform Simple Vector Operations
 Using MMX Instructions to Perform Simple Vector Operations Information for Developers and ISVs From Intel Developer Services www.intel.com/ids Information in this document is provided in connection with
Using MMX Instructions to Perform Simple Vector Operations Information for Developers and ISVs From Intel Developer Services www.intel.com/ids Information in this document is provided in connection with
SWAR: MMX, SSE, SSE 2 Multiplatform Programming
 SWAR: MMX, SSE, SSE 2 Multiplatform Programming Relatore: dott. Matteo Roffilli roffilli@csr.unibo.it 1 What s SWAR? SWAR = SIMD Within A Register SIMD = Single Instruction Multiple Data MMX,SSE,SSE2,Power3DNow
SWAR: MMX, SSE, SSE 2 Multiplatform Programming Relatore: dott. Matteo Roffilli roffilli@csr.unibo.it 1 What s SWAR? SWAR = SIMD Within A Register SIMD = Single Instruction Multiple Data MMX,SSE,SSE2,Power3DNow
administrivia today start assembly probably won t finish all these slides Assignment 4 due tomorrow any questions?
 administrivia today start assembly probably won t finish all these slides Assignment 4 due tomorrow any questions? exam on Wednesday today s material not on the exam 1 Assembly Assembly is programming
administrivia today start assembly probably won t finish all these slides Assignment 4 due tomorrow any questions? exam on Wednesday today s material not on the exam 1 Assembly Assembly is programming
Intel SIMD architecture. Computer Organization and Assembly Languages Yung-Yu Chuang
 Intel SIMD architecture Computer Organization and Assembly Languages g Yung-Yu Chuang Overview SIMD MMX architectures MMX instructions examples SSE/SSE2 SIMD instructions are probably the best place to
Intel SIMD architecture Computer Organization and Assembly Languages g Yung-Yu Chuang Overview SIMD MMX architectures MMX instructions examples SSE/SSE2 SIMD instructions are probably the best place to
Intel SIMD architecture. Computer Organization and Assembly Languages Yung-Yu Chuang 2006/12/25
 Intel SIMD architecture Computer Organization and Assembly Languages Yung-Yu Chuang 2006/12/25 Reference Intel MMX for Multimedia PCs, CACM, Jan. 1997 Chapter 11 The MMX Instruction Set, The Art of Assembly
Intel SIMD architecture Computer Organization and Assembly Languages Yung-Yu Chuang 2006/12/25 Reference Intel MMX for Multimedia PCs, CACM, Jan. 1997 Chapter 11 The MMX Instruction Set, The Art of Assembly
CS165 Computer Security. Understanding low-level program execution Oct 1 st, 2015
 CS165 Computer Security Understanding low-level program execution Oct 1 st, 2015 A computer lets you make more mistakes faster than any invention in human history - with the possible exceptions of handguns
CS165 Computer Security Understanding low-level program execution Oct 1 st, 2015 A computer lets you make more mistakes faster than any invention in human history - with the possible exceptions of handguns
CS802 Parallel Processing Class Notes
 CS802 Parallel Processing Class Notes MMX Technology Instructor: Dr. Chang N. Zhang Winter Semester, 2006 Intel MMX TM Technology Chapter 1: Introduction to MMX technology 1.1 Features of the MMX Technology
CS802 Parallel Processing Class Notes MMX Technology Instructor: Dr. Chang N. Zhang Winter Semester, 2006 Intel MMX TM Technology Chapter 1: Introduction to MMX technology 1.1 Features of the MMX Technology
Masterpraktikum Scientific Computing
 Masterpraktikum Scientific Computing High-Performance Computing Michael Bader Alexander Heinecke Technische Universität München, Germany Outline Logins Levels of Parallelism Single Processor Systems Von-Neumann-Principle
Masterpraktikum Scientific Computing High-Performance Computing Michael Bader Alexander Heinecke Technische Universität München, Germany Outline Logins Levels of Parallelism Single Processor Systems Von-Neumann-Principle
CSC 2400: Computer Systems. Towards the Hardware: Machine-Level Representation of Programs
 CSC 2400: Computer Systems Towards the Hardware: Machine-Level Representation of Programs Towards the Hardware High-level language (Java) High-level language (C) assembly language machine language (IA-32)
CSC 2400: Computer Systems Towards the Hardware: Machine-Level Representation of Programs Towards the Hardware High-level language (Java) High-level language (C) assembly language machine language (IA-32)
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
Review: Parallelism - The Challenge. Agenda 7/14/2011
 7/14/2011 CS 61C: Great Ideas in Computer Architecture (Machine Structures) The Flynn Taxonomy, Data Level Parallelism Instructor: Michael Greenbaum Summer 2011 -- Lecture #15 1 Review: Parallelism - The
7/14/2011 CS 61C: Great Ideas in Computer Architecture (Machine Structures) The Flynn Taxonomy, Data Level Parallelism Instructor: Michael Greenbaum Summer 2011 -- Lecture #15 1 Review: Parallelism - The
OpenCL Vectorising Features. Andreas Beckmann
 Mitglied der Helmholtz-Gemeinschaft OpenCL Vectorising Features Andreas Beckmann Levels of Vectorisation vector units, SIMD devices width, instructions SMX, SP cores Cus, PEs vector operations within kernels
Mitglied der Helmholtz-Gemeinschaft OpenCL Vectorising Features Andreas Beckmann Levels of Vectorisation vector units, SIMD devices width, instructions SMX, SP cores Cus, PEs vector operations within kernels
SIMD Programming CS 240A, 2017
 SIMD Programming CS 240A, 2017 1 Flynn* Taxonomy, 1966 In 2013, SIMD and MIMD most common parallelism in architectures usually both in same system! Most common parallel processing programming style: Single
SIMD Programming CS 240A, 2017 1 Flynn* Taxonomy, 1966 In 2013, SIMD and MIMD most common parallelism in architectures usually both in same system! Most common parallel processing programming style: Single
CSC 8400: Computer Systems. Machine-Level Representation of Programs
 CSC 8400: Computer Systems Machine-Level Representation of Programs Towards the Hardware High-level language (Java) High-level language (C) assembly language machine language (IA-32) 1 Compilation Stages
CSC 8400: Computer Systems Machine-Level Representation of Programs Towards the Hardware High-level language (Java) High-level language (C) assembly language machine language (IA-32) 1 Compilation Stages
Computer Labs: Profiling and Optimization
 Computer Labs: Profiling and Optimization 2 o MIEIC Pedro F. Souto (pfs@fe.up.pt) December 15, 2010 Optimization Speed matters, and it depends mostly on the right choice of Data structures Algorithms If
Computer Labs: Profiling and Optimization 2 o MIEIC Pedro F. Souto (pfs@fe.up.pt) December 15, 2010 Optimization Speed matters, and it depends mostly on the right choice of Data structures Algorithms If
CS24: INTRODUCTION TO COMPUTING SYSTEMS. Spring 2018 Lecture 4
 CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2018 Lecture 4 LAST TIME Enhanced our processor design in several ways Added branching support Allows programs where work is proportional to the input values
CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2018 Lecture 4 LAST TIME Enhanced our processor design in several ways Added branching support Allows programs where work is proportional to the input values
Practical Malware Analysis
 Practical Malware Analysis Ch 4: A Crash Course in x86 Disassembly Revised 1-16-7 Basic Techniques Basic static analysis Looks at malware from the outside Basic dynamic analysis Only shows you how the
Practical Malware Analysis Ch 4: A Crash Course in x86 Disassembly Revised 1-16-7 Basic Techniques Basic static analysis Looks at malware from the outside Basic dynamic analysis Only shows you how the
History of the Intel 80x86
 Intel s IA-32 Architecture Cptr280 Dr Curtis Nelson History of the Intel 80x86 1971 - Intel invents the microprocessor, the 4004 1975-8080 introduced 8-bit microprocessor 1978-8086 introduced 16 bit microprocessor
Intel s IA-32 Architecture Cptr280 Dr Curtis Nelson History of the Intel 80x86 1971 - Intel invents the microprocessor, the 4004 1975-8080 introduced 8-bit microprocessor 1978-8086 introduced 16 bit microprocessor
Review of Last Lecture. CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions. Great Idea #4: Parallelism.
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 1 Review of Last Lecture Amdahl s Law limits benefits of parallelization Request Level Parallelism
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 1 Review of Last Lecture Amdahl s Law limits benefits of parallelization Request Level Parallelism
Memory Models. Registers
 Memory Models Most machines have a single linear address space at the ISA level, extending from address 0 up to some maximum, often 2 32 1 bytes or 2 64 1 bytes. Some machines have separate address spaces
Memory Models Most machines have a single linear address space at the ISA level, extending from address 0 up to some maximum, often 2 32 1 bytes or 2 64 1 bytes. Some machines have separate address spaces
High Performance Computing and Programming 2015 Lab 6 SIMD and Vectorization
 High Performance Computing and Programming 2015 Lab 6 SIMD and Vectorization 1 Introduction The purpose of this lab assignment is to give some experience in using SIMD instructions on x86 and getting compiler
High Performance Computing and Programming 2015 Lab 6 SIMD and Vectorization 1 Introduction The purpose of this lab assignment is to give some experience in using SIMD instructions on x86 and getting compiler
CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 3/08/2013 Spring 2013 Lecture #19 1 Review of Last Lecture Amdahl s Law limits benefits
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Instructor: Justin Hsia 3/08/2013 Spring 2013 Lecture #19 1 Review of Last Lecture Amdahl s Law limits benefits
Flynn Taxonomy Data-Level Parallelism
 ecture 27 Computer Science 61C Spring 2017 March 22nd, 2017 Flynn Taxonomy Data-Level Parallelism 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
ecture 27 Computer Science 61C Spring 2017 March 22nd, 2017 Flynn Taxonomy Data-Level Parallelism 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
Assembly Language for Intel-Based Computers, 4 th Edition. Chapter 2: IA-32 Processor Architecture Included elements of the IA-64 bit
 Assembly Language for Intel-Based Computers, 4 th Edition Kip R. Irvine Chapter 2: IA-32 Processor Architecture Included elements of the IA-64 bit Slides prepared by Kip R. Irvine Revision date: 09/25/2002
Assembly Language for Intel-Based Computers, 4 th Edition Kip R. Irvine Chapter 2: IA-32 Processor Architecture Included elements of the IA-64 bit Slides prepared by Kip R. Irvine Revision date: 09/25/2002
SOEN228, Winter Revision 1.2 Date: October 25,
 SOEN228, Winter 2003 Revision 1.2 Date: October 25, 2003 1 Contents Flags Mnemonics Basic I/O Exercises Overview of sample programs 2 Flag Register The flag register stores the condition flags that retain
SOEN228, Winter 2003 Revision 1.2 Date: October 25, 2003 1 Contents Flags Mnemonics Basic I/O Exercises Overview of sample programs 2 Flag Register The flag register stores the condition flags that retain
2.7 Supporting Procedures in hardware. Why procedures or functions? Procedure calls
 2.7 Supporting Procedures in hardware Why procedures or functions? Procedure calls Caller: Callee: Proc save registers save more registers set up parameters do function call procedure set up results get
2.7 Supporting Procedures in hardware Why procedures or functions? Procedure calls Caller: Callee: Proc save registers save more registers set up parameters do function call procedure set up results get
Reverse Engineering II: Basics. Gergely Erdélyi Senior Antivirus Researcher
 Reverse Engineering II: Basics Gergely Erdélyi Senior Antivirus Researcher Agenda Very basics Intel x86 crash course Basics of C Binary Numbers Binary Numbers 1 Binary Numbers 1 0 1 1 Binary Numbers 1
Reverse Engineering II: Basics Gergely Erdélyi Senior Antivirus Researcher Agenda Very basics Intel x86 crash course Basics of C Binary Numbers Binary Numbers 1 Binary Numbers 1 0 1 1 Binary Numbers 1
Introduction to IA-32. Jo, Heeseung
 Introduction to IA-32 Jo, Heeseung IA-32 Processors Evolutionary design Starting in 1978 with 8086 Added more features as time goes on Still support old features, although obsolete Totally dominate computer
Introduction to IA-32 Jo, Heeseung IA-32 Processors Evolutionary design Starting in 1978 with 8086 Added more features as time goes on Still support old features, although obsolete Totally dominate computer
Computer System Architecture
 CSC 203 1.5 Computer System Architecture Department of Statistics and Computer Science University of Sri Jayewardenepura Instruction Set Architecture (ISA) Level 2 Introduction 3 Instruction Set Architecture
CSC 203 1.5 Computer System Architecture Department of Statistics and Computer Science University of Sri Jayewardenepura Instruction Set Architecture (ISA) Level 2 Introduction 3 Instruction Set Architecture
CS 61C: Great Ideas in Computer Architecture. The Flynn Taxonomy, Intel SIMD Instructions
 CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Guest Lecturer: Alan Christopher 3/08/2014 Spring 2014 -- Lecture #19 1 Neuromorphic Chips Researchers at IBM and
CS 61C: Great Ideas in Computer Architecture The Flynn Taxonomy, Intel SIMD Instructions Guest Lecturer: Alan Christopher 3/08/2014 Spring 2014 -- Lecture #19 1 Neuromorphic Chips Researchers at IBM and
INTRODUCTION TO IA-32. Jo, Heeseung
 INTRODUCTION TO IA-32 Jo, Heeseung IA-32 PROCESSORS Evolutionary design Starting in 1978 with 8086 Added more features as time goes on Still support old features, although obsolete Totally dominate computer
INTRODUCTION TO IA-32 Jo, Heeseung IA-32 PROCESSORS Evolutionary design Starting in 1978 with 8086 Added more features as time goes on Still support old features, although obsolete Totally dominate computer
Reverse Engineering II: The Basics
 Reverse Engineering II: The Basics Gergely Erdélyi Senior Manager, Anti-malware Research Protecting the irreplaceable f-secure.com Binary Numbers 1 0 1 1 - Nibble B 1 0 1 1 1 1 0 1 - Byte B D 1 0 1 1 1
Reverse Engineering II: The Basics Gergely Erdélyi Senior Manager, Anti-malware Research Protecting the irreplaceable f-secure.com Binary Numbers 1 0 1 1 - Nibble B 1 0 1 1 1 1 0 1 - Byte B D 1 0 1 1 1
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5
 EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
CS4961 Parallel Programming. Lecture 7: Introduction to SIMD 09/14/2010. Homework 2, Due Friday, Sept. 10, 11:59 PM. Mary Hall September 14, 2010
 Parallel Programming Lecture 7: Introduction to SIMD Mary Hall September 14, 2010 Homework 2, Due Friday, Sept. 10, 11:59 PM To submit your homework: - Submit a PDF file - Use the handin program on the
Parallel Programming Lecture 7: Introduction to SIMD Mary Hall September 14, 2010 Homework 2, Due Friday, Sept. 10, 11:59 PM To submit your homework: - Submit a PDF file - Use the handin program on the
Compiler Construction D7011E
 Compiler Construction D7011E Lecture 8: Introduction to code generation Viktor Leijon Slides largely by Johan Nordlander with material generously provided by Mark P. Jones. 1 What is a Compiler? Compilers
Compiler Construction D7011E Lecture 8: Introduction to code generation Viktor Leijon Slides largely by Johan Nordlander with material generously provided by Mark P. Jones. 1 What is a Compiler? Compilers
CS Bootcamp x86-64 Autumn 2015
 The x86-64 instruction set architecture (ISA) is used by most laptop and desktop processors. We will be embedding assembly into some of our C++ code to explore programming in assembly language. Depending
The x86-64 instruction set architecture (ISA) is used by most laptop and desktop processors. We will be embedding assembly into some of our C++ code to explore programming in assembly language. Depending
W4118: PC Hardware and x86. Junfeng Yang
 W4118: PC Hardware and x86 Junfeng Yang A PC How to make it do something useful? 2 Outline PC organization x86 instruction set gcc calling conventions PC emulation 3 PC board 4 PC organization One or more
W4118: PC Hardware and x86 Junfeng Yang A PC How to make it do something useful? 2 Outline PC organization x86 instruction set gcc calling conventions PC emulation 3 PC board 4 PC organization One or more
Name: CMSC 313 Fall 2001 Computer Organization & Assembly Language Programming Exam 1. Question Points I. /34 II. /30 III.
 CMSC 313 Fall 2001 Computer Organization & Assembly Language Programming Exam 1 Name: Question Points I. /34 II. /30 III. /36 TOTAL: /100 Instructions: 1. This is a closed-book, closed-notes exam. 2. You
CMSC 313 Fall 2001 Computer Organization & Assembly Language Programming Exam 1 Name: Question Points I. /34 II. /30 III. /36 TOTAL: /100 Instructions: 1. This is a closed-book, closed-notes exam. 2. You
CS241 Computer Organization Spring Introduction to Assembly
 CS241 Computer Organization Spring 2015 Introduction to Assembly 2-05 2015 Outline! Rounding floats: round-to-even! Introduction to Assembly (IA32) move instruction (mov) memory address computation arithmetic
CS241 Computer Organization Spring 2015 Introduction to Assembly 2-05 2015 Outline! Rounding floats: round-to-even! Introduction to Assembly (IA32) move instruction (mov) memory address computation arithmetic
Optimizing Memory Bandwidth
 Optimizing Memory Bandwidth Don t settle for just a byte or two. Grab a whole fistful of cache. Mike Wall Member of Technical Staff Developer Performance Team Advanced Micro Devices, Inc. make PC performance
Optimizing Memory Bandwidth Don t settle for just a byte or two. Grab a whole fistful of cache. Mike Wall Member of Technical Staff Developer Performance Team Advanced Micro Devices, Inc. make PC performance
CNIT 127: Exploit Development. Ch 1: Before you begin. Updated
 CNIT 127: Exploit Development Ch 1: Before you begin Updated 1-14-16 Basic Concepts Vulnerability A flaw in a system that allows an attacker to do something the designer did not intend, such as Denial
CNIT 127: Exploit Development Ch 1: Before you begin Updated 1-14-16 Basic Concepts Vulnerability A flaw in a system that allows an attacker to do something the designer did not intend, such as Denial
Complex Instruction Set Computer (CISC)
") Introduction ti to IA-32 IA-32 Processors Evolutionary design Starting in 1978 with 886 Added more features as time goes on Still support old features, although obsolete Totally dominate computer market
Introduction ti to IA-32 IA-32 Processors Evolutionary design Starting in 1978 with 886 Added more features as time goes on Still support old features, although obsolete Totally dominate computer market
Lab 3. The Art of Assembly Language (II)
") Lab. The Art of Assembly Language (II) Dan Bruce, David Clark and Héctor D. Menéndez Department of Computer Science University College London October 2, 2017 License Creative Commons Share Alike Modified
Lab. The Art of Assembly Language (II) Dan Bruce, David Clark and Héctor D. Menéndez Department of Computer Science University College London October 2, 2017 License Creative Commons Share Alike Modified
What is a Compiler? Compiler Construction SMD163. Why Translation is Needed: Know your Target: Lecture 8: Introduction to code generation
 Compiler Construction SMD163 Lecture 8: Introduction to code generation Viktor Leijon & Peter Jonsson with slides by Johan Nordlander Contains material generously provided by Mark P. Jones What is a Compiler?
Compiler Construction SMD163 Lecture 8: Introduction to code generation Viktor Leijon & Peter Jonsson with slides by Johan Nordlander Contains material generously provided by Mark P. Jones What is a Compiler?
System calls and assembler
 System calls and assembler Michal Sojka sojkam1@fel.cvut.cz ČVUT, FEL License: CC-BY-SA 4.0 System calls (repetition from lectures) A way for normal applications to invoke operating system (OS) kernel's
System calls and assembler Michal Sojka sojkam1@fel.cvut.cz ČVUT, FEL License: CC-BY-SA 4.0 System calls (repetition from lectures) A way for normal applications to invoke operating system (OS) kernel's
SIMD: Data parallel execution
 ERLANGEN REGIONAL COMPUTING CENTER SIMD: Data parallel execution J. Eitzinger HLRS, 15.6.2018 CPU Stored Program Computer: Base setting Memory for (int j=0; j
ERLANGEN REGIONAL COMPUTING CENTER SIMD: Data parallel execution J. Eitzinger HLRS, 15.6.2018 CPU Stored Program Computer: Base setting Memory for (int j=0; j
Using MMX Instructions to Implement Viterbi Decoding
 Using MMX Instructions to Implement Viterbi Decoding Information for Developers and ISVs From Intel Developer Services www.intel.com/ids Information in this document is provided in connection with Intel
Using MMX Instructions to Implement Viterbi Decoding Information for Developers and ISVs From Intel Developer Services www.intel.com/ids Information in this document is provided in connection with Intel
POLITECNICO DI MILANO. Advanced Topics on Heterogeneous System Architectures! Multiprocessors
 POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! SeminarRoom, Bld 20! 30 November, 2017! Antonio Miele! Marco Santambrogio! Politecnico
POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! SeminarRoom, Bld 20! 30 November, 2017! Antonio Miele! Marco Santambrogio! Politecnico
CSE P 501 Compilers. x86 Lite for Compiler Writers Hal Perkins Autumn /25/ Hal Perkins & UW CSE J-1
 CSE P 501 Compilers x86 Lite for Compiler Writers Hal Perkins Autumn 2011 10/25/2011 2002-11 Hal Perkins & UW CSE J-1 Agenda Learn/review x86 architecture Core 32-bit part only for now Ignore crufty, backward-compatible
CSE P 501 Compilers x86 Lite for Compiler Writers Hal Perkins Autumn 2011 10/25/2011 2002-11 Hal Perkins & UW CSE J-1 Agenda Learn/review x86 architecture Core 32-bit part only for now Ignore crufty, backward-compatible
Using MMX Instructions to Compute the AbsoluteDifference in Motion Estimation
 Using MMX Instructions to Compute the AbsoluteDifference in Motion Estimation Information for Developers and ISVs From Intel Developer Services www.intel.com/ids Information in this document is provided
Using MMX Instructions to Compute the AbsoluteDifference in Motion Estimation Information for Developers and ISVs From Intel Developer Services www.intel.com/ids Information in this document is provided
Compiling for Nehalem (the Intel Core Microarchitecture, Intel Xeon 5500 processor family and the Intel Core i7 processor)
") Compiling for Nehalem (the Intel Core Microarchitecture, Intel Xeon 5500 processor family and the Intel Core i7 processor) Martyn Corden Developer Products Division Software & Services Group Intel Corporation
Compiling for Nehalem (the Intel Core Microarchitecture, Intel Xeon 5500 processor family and the Intel Core i7 processor) Martyn Corden Developer Products Division Software & Services Group Intel Corporation
last time out-of-order execution and instruction queues the data flow model idea
 1 last time 2 out-of-order execution and instruction queues the data flow model idea graph of operations linked by depedencies latency bound need to finish longest dependency chain multiple accumulators
1 last time 2 out-of-order execution and instruction queues the data flow model idea graph of operations linked by depedencies latency bound need to finish longest dependency chain multiple accumulators
Program Exploitation Intro
 Program Exploitation Intro x86 Assembly 04//2018 Security 1 Univeristà Ca Foscari, Venezia What is Program Exploitation "Making a program do something unexpected and not planned" The right bugs can be
Program Exploitation Intro x86 Assembly 04//2018 Security 1 Univeristà Ca Foscari, Venezia What is Program Exploitation "Making a program do something unexpected and not planned" The right bugs can be
Towards the Hardware"
 CSC 2400: Computer Systems Towards the Hardware Chapter 2 Towards the Hardware High-level language (Java) High-level language (C) assembly language machine language (IA-32) 1 High-Level Language Make programming
CSC 2400: Computer Systems Towards the Hardware Chapter 2 Towards the Hardware High-level language (Java) High-level language (C) assembly language machine language (IA-32) 1 High-Level Language Make programming
Computer Architecture and Assembly Language. Practical Session 5
 Computer Architecture and Assembly Language Practical Session 5 Addressing Mode - "memory address calculation mode" An addressing mode specifies how to calculate the effective memory address of an operand.
Computer Architecture and Assembly Language Practical Session 5 Addressing Mode - "memory address calculation mode" An addressing mode specifies how to calculate the effective memory address of an operand.
X86 Addressing Modes Chapter 3" Review: Instructions to Recognize"
 X86 Addressing Modes Chapter 3" Review: Instructions to Recognize" 1 Arithmetic Instructions (1)! Two Operand Instructions" ADD Dest, Src Dest = Dest + Src SUB Dest, Src Dest = Dest - Src MUL Dest, Src
X86 Addressing Modes Chapter 3" Review: Instructions to Recognize" 1 Arithmetic Instructions (1)! Two Operand Instructions" ADD Dest, Src Dest = Dest + Src SUB Dest, Src Dest = Dest - Src MUL Dest, Src
SSE and SSE2. Timothy A. Chagnon 18 September All images from Intel 64 and IA 32 Architectures Software Developer's Manuals
 SSE and SSE2 Timothy A. Chagnon 18 September 2007 All images from Intel 64 and IA 32 Architectures Software Developer's Manuals Overview SSE: Streaming SIMD (Single Instruction Multiple Data) Extensions
SSE and SSE2 Timothy A. Chagnon 18 September 2007 All images from Intel 64 and IA 32 Architectures Software Developer's Manuals Overview SSE: Streaming SIMD (Single Instruction Multiple Data) Extensions
Lecture 25: Interrupt Handling and Multi-Data Processing. Spring 2018 Jason Tang
 Lecture 25: Interrupt Handling and Multi-Data Processing Spring 2018 Jason Tang 1 Topics Interrupt handling Vector processing Multi-data processing 2 I/O Communication Software needs to know when: I/O
Lecture 25: Interrupt Handling and Multi-Data Processing Spring 2018 Jason Tang 1 Topics Interrupt handling Vector processing Multi-data processing 2 I/O Communication Software needs to know when: I/O
Computer Labs: Profiling and Optimization
 Computer Labs: Profiling and Optimization 2 o MIEIC Pedro F. Souto (pfs@fe.up.pt) December 18, 2011 Contents Optimization and Profiling Optimization Coding in assembly memcpy Algorithms Further Reading
Computer Labs: Profiling and Optimization 2 o MIEIC Pedro F. Souto (pfs@fe.up.pt) December 18, 2011 Contents Optimization and Profiling Optimization Coding in assembly memcpy Algorithms Further Reading
6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU
 1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
CS 31: Intro to Systems ISAs and Assembly. Martin Gagné Swarthmore College February 7, 2017
 CS 31: Intro to Systems ISAs and Assembly Martin Gagné Swarthmore College February 7, 2017 ANNOUNCEMENT All labs will meet in SCI 252 (the robot lab) tomorrow. Overview How to directly interact with hardware
CS 31: Intro to Systems ISAs and Assembly Martin Gagné Swarthmore College February 7, 2017 ANNOUNCEMENT All labs will meet in SCI 252 (the robot lab) tomorrow. Overview How to directly interact with hardware
Overview of the MIPS Architecture: Part I. CS 161: Lecture 0 1/24/17
 Overview of the MIPS Architecture: Part I CS 161: Lecture 0 1/24/17 Looking Behind the Curtain of Software The OS sits between hardware and user-level software, providing: Isolation (e.g., to give each
Overview of the MIPS Architecture: Part I CS 161: Lecture 0 1/24/17 Looking Behind the Curtain of Software The OS sits between hardware and user-level software, providing: Isolation (e.g., to give each
Datapoint 2200 IA-32. main memory. components. implemented by Intel in the Nicholas FitzRoy-Dale
 Datapoint 2200 IA-32 Nicholas FitzRoy-Dale At the forefront of the computer revolution - Intel Difficult to explain and impossible to love - Hennessy and Patterson! Released 1970! 2K shift register main
Datapoint 2200 IA-32 Nicholas FitzRoy-Dale At the forefront of the computer revolution - Intel Difficult to explain and impossible to love - Hennessy and Patterson! Released 1970! 2K shift register main
Vector Processors. Kavitha Chandrasekar Sreesudhan Ramkumar
 Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
CSE351 Spring 2018, Midterm Exam April 27, 2018
 CSE351 Spring 2018, Midterm Exam April 27, 2018 Please do not turn the page until 11:30. Last Name: First Name: Student ID Number: Name of person to your left: Name of person to your right: Signature indicating:
CSE351 Spring 2018, Midterm Exam April 27, 2018 Please do not turn the page until 11:30. Last Name: First Name: Student ID Number: Name of person to your left: Name of person to your right: Signature indicating:
Reverse Engineering II: The Basics
 Reverse Engineering II: The Basics This document is only to be distributed to teachers and students of the Malware Analysis and Antivirus Technologies course and should only be used in accordance with
Reverse Engineering II: The Basics This document is only to be distributed to teachers and students of the Malware Analysis and Antivirus Technologies course and should only be used in accordance with
CPS104 Recitation: Assembly Programming
 CPS104 Recitation: Assembly Programming Alexandru Duțu 1 Facts OS kernel and embedded software engineers use assembly for some parts of their code some OSes had their entire GUIs written in assembly in
CPS104 Recitation: Assembly Programming Alexandru Duțu 1 Facts OS kernel and embedded software engineers use assembly for some parts of their code some OSes had their entire GUIs written in assembly in
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-11: 80x86 Architecture
 ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-11: 80x86 Architecture 1 The 80x86 architecture processors popular since its application in IBM PC (personal computer). 2 First Four generations
ADVANCED PROCESSOR ARCHITECTURES AND MEMORY ORGANISATION Lesson-11: 80x86 Architecture 1 The 80x86 architecture processors popular since its application in IBM PC (personal computer). 2 First Four generations
High Performance Computing. Classes of computing SISD. Computation Consists of :
 High Performance Computing! Introduction to classes of computing! SISD! MISD! SIMD! Conclusion Classes of computing Computation Consists of :! Sequential Instructions (operation)! Sequential dataset We
High Performance Computing! Introduction to classes of computing! SISD! MISD! SIMD! Conclusion Classes of computing Computation Consists of :! Sequential Instructions (operation)! Sequential dataset We
Dr. Ramesh K. Karne Department of Computer and Information Sciences, Towson University, Towson, MD /12/2014 Slide 1
 Dr. Ramesh K. Karne Department of Computer and Information Sciences, Towson University, Towson, MD 21252 rkarne@towson.edu 11/12/2014 Slide 1 Intel x86 Aseembly Language Assembly Language Assembly Language
Dr. Ramesh K. Karne Department of Computer and Information Sciences, Towson University, Towson, MD 21252 rkarne@towson.edu 11/12/2014 Slide 1 Intel x86 Aseembly Language Assembly Language Assembly Language
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Credits and Disclaimers
 Credits and Disclaimers 1 The examples and discussion in the following slides have been adapted from a variety of sources, including: Chapter 3 of Computer Systems 2 nd Edition by Bryant and O'Hallaron
Credits and Disclaimers 1 The examples and discussion in the following slides have been adapted from a variety of sources, including: Chapter 3 of Computer Systems 2 nd Edition by Bryant and O'Hallaron
Compiler construction. x86 architecture. This lecture. Lecture 6: Code generation for x86. x86: assembly for a real machine.
 This lecture Compiler construction Lecture 6: Code generation for x86 Magnus Myreen Spring 2018 Chalmers University of Technology Gothenburg University x86 architecture s Some x86 instructions From LLVM
This lecture Compiler construction Lecture 6: Code generation for x86 Magnus Myreen Spring 2018 Chalmers University of Technology Gothenburg University x86 architecture s Some x86 instructions From LLVM
Registers. Ray Seyfarth. September 8, Bit Intel Assembly Language c 2011 Ray Seyfarth
 Registers Ray Seyfarth September 8, 2011 Outline 1 Register basics 2 Moving a constant into a register 3 Moving a value from memory into a register 4 Moving values from a register into memory 5 Moving
Registers Ray Seyfarth September 8, 2011 Outline 1 Register basics 2 Moving a constant into a register 3 Moving a value from memory into a register 4 Moving values from a register into memory 5 Moving
Assembly Language. Lecture 2 - x86 Processor Architecture. Ahmed Sallam
 Assembly Language Lecture 2 - x86 Processor Architecture Ahmed Sallam Introduction to the course Outcomes of Lecture 1 Always check the course website Don t forget the deadline rule!! Motivations for studying
Assembly Language Lecture 2 - x86 Processor Architecture Ahmed Sallam Introduction to the course Outcomes of Lecture 1 Always check the course website Don t forget the deadline rule!! Motivations for studying
Low-Level Essentials for Understanding Security Problems Aurélien Francillon
 Low-Level Essentials for Understanding Security Problems Aurélien Francillon francill@eurecom.fr Computer Architecture The modern computer architecture is based on Von Neumann Two main parts: CPU (Central
Low-Level Essentials for Understanding Security Problems Aurélien Francillon francill@eurecom.fr Computer Architecture The modern computer architecture is based on Von Neumann Two main parts: CPU (Central
Figure 1: 128-bit registers introduced by SSE. 128 bits. xmm0 xmm1 xmm2 xmm3 xmm4 xmm5 xmm6 xmm7
 SE205 - TD1 Énoncé General Instructions You can download all source files from: https://se205.wp.mines-telecom.fr/td1/ SIMD-like Data-Level Parallelism Modern processors often come with instruction set
SE205 - TD1 Énoncé General Instructions You can download all source files from: https://se205.wp.mines-telecom.fr/td1/ SIMD-like Data-Level Parallelism Modern processors often come with instruction set
CS241 Computer Organization Spring 2015 IA
 CS241 Computer Organization Spring 2015 IA-32 2-10 2015 Outline! Review HW#3 and Quiz#1! More on Assembly (IA32) move instruction (mov) memory address computation arithmetic & logic instructions (add,
CS241 Computer Organization Spring 2015 IA-32 2-10 2015 Outline! Review HW#3 and Quiz#1! More on Assembly (IA32) move instruction (mov) memory address computation arithmetic & logic instructions (add,
Sarah Knepper. Intel Math Kernel Library (Intel MKL) 25 May 2018, iwapt 2018
 25 May 2018, iwapt 2018") Sarah Knepper Intel Math Kernel Library (Intel MKL) 25 May 2018, iwapt 2018 Outline Motivation Problem statement and solutions Simple example Performance comparison 2 Motivation Partial differential equations
Sarah Knepper Intel Math Kernel Library (Intel MKL) 25 May 2018, iwapt 2018 Outline Motivation Problem statement and solutions Simple example Performance comparison 2 Motivation Partial differential equations
1 Overview of the AMD64 Architecture
 24592 Rev. 3.1 March 25 1 Overview of the AMD64 Architecture 1.1 Introduction The AMD64 architecture is a simple yet powerful 64-bit, backward-compatible extension of the industry-standard (legacy) x86
24592 Rev. 3.1 March 25 1 Overview of the AMD64 Architecture 1.1 Introduction The AMD64 architecture is a simple yet powerful 64-bit, backward-compatible extension of the industry-standard (legacy) x86
Chapter 2. lw $s1,100($s2) $s1 = Memory[$s2+100] sw $s1,100($s2) Memory[$s2+100] = $s1
![Chapter 2. lw $s1,100($s2) $s1 = Memory[$s2+100] sw $s1,100($s2) Memory[$s2+100] = $s1](/thumbs/81/83896246.jpg "Chapter 2. lw $s1,100($s2) $s1 = Memory[$s2+100] sw $s1,100($s2) Memory[$s2+100] = $s1") Chapter 2 1 MIPS Instructions Instruction Meaning add $s1,$s2,$s3 $s1 = $s2 + $s3 sub $s1,$s2,$s3 $s1 = $s2 $s3 addi $s1,$s2,4 $s1 = $s2 + 4 ori $s1,$s2,4 $s2 = $s2 4 lw $s1,100($s2) $s1 = Memory[$s2+100]
Chapter 2 1 MIPS Instructions Instruction Meaning add $s1,$s2,$s3 $s1 = $s2 + $s3 sub $s1,$s2,$s3 $s1 = $s2 $s3 addi $s1,$s2,4 $s1 = $s2 + 4 ori $s1,$s2,4 $s2 = $s2 4 lw $s1,100($s2) $s1 = Memory[$s2+100]
Assembly Language for Intel-Based Computers, 4 th Edition. Chapter 2: IA-32 Processor Architecture. Chapter Overview.
 Assembly Language for Intel-Based Computers, 4 th Edition Kip R. Irvine Chapter 2: IA-32 Processor Architecture Slides prepared by Kip R. Irvine Revision date: 09/25/2002 Chapter corrections (Web) Printing
Assembly Language for Intel-Based Computers, 4 th Edition Kip R. Irvine Chapter 2: IA-32 Processor Architecture Slides prepared by Kip R. Irvine Revision date: 09/25/2002 Chapter corrections (Web) Printing
Parallel computing and GPU introduction
 國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
國立台灣大學 National Taiwan University Parallel computing and GPU introduction 黃子桓 tzhuan@gmail.com Agenda Parallel computing GPU introduction Interconnection networks Parallel benchmark Parallel programming
CS412/CS413. Introduction to Compilers Tim Teitelbaum. Lecture 21: Generating Pentium Code 10 March 08
 CS412/CS413 Introduction to Compilers Tim Teitelbaum Lecture 21: Generating Pentium Code 10 March 08 CS 412/413 Spring 2008 Introduction to Compilers 1 Simple Code Generation Three-address code makes it
CS412/CS413 Introduction to Compilers Tim Teitelbaum Lecture 21: Generating Pentium Code 10 March 08 CS 412/413 Spring 2008 Introduction to Compilers 1 Simple Code Generation Three-address code makes it
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 22 Title: and Extended
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 22 Title: and Extended
Module 3 Instruction Set Architecture (ISA)
") Module 3 Instruction Set Architecture (ISA) I S A L E V E L E L E M E N T S O F I N S T R U C T I O N S I N S T R U C T I O N S T Y P E S N U M B E R O F A D D R E S S E S R E G I S T E R S T Y P E S O
Module 3 Instruction Set Architecture (ISA) I S A L E V E L E L E M E N T S O F I N S T R U C T I O N S I N S T R U C T I O N S T Y P E S N U M B E R O F A D D R E S S E S R E G I S T E R S T Y P E S O
Machine and Assembly Language Principles
 Machine and Assembly Language Principles Assembly language instruction is synonymous with a machine instruction. Therefore, need to understand machine instructions and on what they operate - the architecture.
Machine and Assembly Language Principles Assembly language instruction is synonymous with a machine instruction. Therefore, need to understand machine instructions and on what they operate - the architecture.
CMSC 313 COMPUTER ORGANIZATION & ASSEMBLY LANGUAGE PROGRAMMING LECTURE 03, SPRING 2013
 CMSC 313 COMPUTER ORGANIZATION & ASSEMBLY LANGUAGE PROGRAMMING LECTURE 03, SPRING 2013 TOPICS TODAY Moore s Law Evolution of Intel CPUs IA-32 Basic Execution Environment IA-32 General Purpose Registers
CMSC 313 COMPUTER ORGANIZATION & ASSEMBLY LANGUAGE PROGRAMMING LECTURE 03, SPRING 2013 TOPICS TODAY Moore s Law Evolution of Intel CPUs IA-32 Basic Execution Environment IA-32 General Purpose Registers
CO Computer Architecture and Programming Languages CAPL. Lecture 13 & 14
 CO20-320241 Computer Architecture and Programming Languages CAPL Lecture 13 & 14 Dr. Kinga Lipskoch Fall 2017 Frame Pointer (1) The stack is also used to store variables that are local to function, but
CO20-320241 Computer Architecture and Programming Languages CAPL Lecture 13 & 14 Dr. Kinga Lipskoch Fall 2017 Frame Pointer (1) The stack is also used to store variables that are local to function, but
CS 261 Fall Mike Lam, Professor. x86-64 Data Structures and Misc. Topics
 CS 261 Fall 2017 Mike Lam, Professor x86-64 Data Structures and Misc. Topics Topics Homogeneous data structures Arrays Nested / multidimensional arrays Heterogeneous data structures Structs / records Unions
CS 261 Fall 2017 Mike Lam, Professor x86-64 Data Structures and Misc. Topics Topics Homogeneous data structures Arrays Nested / multidimensional arrays Heterogeneous data structures Structs / records Unions
Lecture 15 Intel Manual, Vol. 1, Chapter 3. Fri, Mar 6, Hampden-Sydney College. The x86 Architecture. Robb T. Koether. Overview of the x86
 Lecture 15 Intel Manual, Vol. 1, Chapter 3 Hampden-Sydney College Fri, Mar 6, 2009 Outline 1 2 Overview See the reference IA-32 Intel Software Developer s Manual Volume 1: Basic, Chapter 3. Instructions
Lecture 15 Intel Manual, Vol. 1, Chapter 3 Hampden-Sydney College Fri, Mar 6, 2009 Outline 1 2 Overview See the reference IA-32 Intel Software Developer s Manual Volume 1: Basic, Chapter 3. Instructions
Instruction Set Progression. from MMX Technology through Streaming SIMD Extensions 2
 Instruction Set Progression from MMX Technology through Streaming SIMD Extensions 2 This article summarizes the progression of change to the instruction set in the Intel IA-32 architecture, from MMX technology
Instruction Set Progression from MMX Technology through Streaming SIMD Extensions 2 This article summarizes the progression of change to the instruction set in the Intel IA-32 architecture, from MMX technology
complement) Multiply Unsigned: MUL (all operands are nonnegative) AX = BH * AL IMUL BH IMUL CX (DX,AX) = CX * AX Arithmetic MUL DWORD PTR [0x10]
![complement) Multiply Unsigned: MUL (all operands are nonnegative) AX = BH * AL IMUL BH IMUL CX (DX,AX) = CX * AX Arithmetic MUL DWORD PTR [0x10]](/thumbs/76/72989659.jpg "complement) Multiply Unsigned: MUL (all operands are nonnegative) AX = BH * AL IMUL BH IMUL CX (DX,AX) = CX * AX Arithmetic MUL DWORD PTR [0x10]") The following pages contain references for use during the exam: tables containing the x86 instruction set (covered so far) and condition codes. You do not need to submit these pages when you finish your
The following pages contain references for use during the exam: tables containing the x86 instruction set (covered so far) and condition codes. You do not need to submit these pages when you finish your
ADDRESSING MODES. Operands specify the data to be used by an instruction
 ADDRESSING MODES Operands specify the data to be used by an instruction An addressing mode refers to the way in which the data is specified by an operand 1. An operand is said to be direct when it specifies
ADDRESSING MODES Operands specify the data to be used by an instruction An addressing mode refers to the way in which the data is specified by an operand 1. An operand is said to be direct when it specifies
Assembly level Programming. 198:211 Computer Architecture. (recall) Von Neumann Architecture. Simplified hardware view. Lecture 10 Fall 2012
 Von Neumann Architecture. Simplified hardware view. Lecture 10 Fall 2012") 19:211 Computer Architecture Lecture 10 Fall 20 Topics:Chapter 3 Assembly Language 3.2 Register Transfer 3. ALU 3.5 Assembly level Programming We are now familiar with high level programming languages
19:211 Computer Architecture Lecture 10 Fall 20 Topics:Chapter 3 Assembly Language 3.2 Register Transfer 3. ALU 3.5 Assembly level Programming We are now familiar with high level programming languages
CSCI 192 Engineering Programming 2. Assembly Language
 CSCI 192 Engineering Programming 2 Week 5 Assembly Language Lecturer: Dr. Markus Hagenbuchner Slides by: Igor Kharitonenko and Markus Hagenbuchner Room 3.220 markus@uow.edu.au UOW 2010 24/08/2010 1 C Compilation
CSCI 192 Engineering Programming 2 Week 5 Assembly Language Lecturer: Dr. Markus Hagenbuchner Slides by: Igor Kharitonenko and Markus Hagenbuchner Room 3.220 markus@uow.edu.au UOW 2010 24/08/2010 1 C Compilation
Using Intel Streaming SIMD Extensions for 3D Geometry Processing
 Using Intel Streaming SIMD Extensions for 3D Geometry Processing Wan-Chun Ma, Chia-Lin Yang Dept. of Computer Science and Information Engineering National Taiwan University firebird@cmlab.csie.ntu.edu.tw,
Using Intel Streaming SIMD Extensions for 3D Geometry Processing Wan-Chun Ma, Chia-Lin Yang Dept. of Computer Science and Information Engineering National Taiwan University firebird@cmlab.csie.ntu.edu.tw,