CMSC 611: Advanced Computer Architecture
|
|
|
- Hilary Harrington
- 5 years ago
- Views:
Transcription
1 CMSC 611: Advanced Computer Architecture Instruction Level Parallelism Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
2 Floating-Point Pipeline Impractical for FP ops to complete in one clock (complex logic and/or very long clock cycle) More complex hazards Structural Data
3 7-stage pipelined FP multiply Multi-cycle FP Pipeline Integer ALU Non-pipelined DIV operation stalling the whole pipeline for 24 cycles 3-stage pipelined FP addition MULTD IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB IF ID A1 A2 A3 A4 MEM WB IF ID EX MEM WB IF ID EX MEM WB Example: blue indicate where data is needed and red when result is available
4 Multi-cycle FP: EX Phase Latency: cycles between instruction that produces result and instruction that uses it Since most operations consume their operands at the beginning of the EX stage, latency is usually number of the stages of the EX an instruction uses Long latency increases the frequency of RAW hazards Initiation (Repeat) interval: cycles between issuing two operations of a given type Functional unit Latency Initiation interval Integer ALU 0 1 Data memory (integer and FP loads) 1 1 FP add 3 1 FP multiply (also integer multiply) 6 1 FP divide (also integer divide) 24 25
5 FP Pipeline Challenges Non-pipelined divide causes structural hazards Number of register writes required in a cycle can be larger than 1 WAW hazards are possible Instructions no longer reach WB in order WAR hazards are NOT possible Register reads are still taking place during the ID stage Instructions can complete out of order Complicates exceptions Longer latency makes RAW stalls more frequent Clock cycle number Instruction F4, 0(R2) IF ID EX MEM WB MULTD F0, F4, F6 IF ID stall M1 M2 M3 M4 M5 M6 M7 MEM WB F2, F0, F8 IF stall ID stall stall stall stall stall stall A1 A2 A3 A4 MEM WB 0(R2), F2 IF stall stall stall stall stall stall ID EX stall stall stall MEM Example of RAW hazard caused by the long latency
6 Structural Hazard Clock cycle number Instruction MULTD F0, F4, F6 IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB IF ID EX MEM WB IF ID EX MEM WB F2, F4, F6 IF ID A1 A2 A3 A4 MEM WB IF ID EX MEM WB IF ID EX MEM WB F2, 0(R2) IF ID EX MEM WB At cycle 10, MULTD, and instructions all in MEM At cycle 11, MULTD, and instructions all in WB Additional write ports are not cost effective since they are rarely used Instead Detect at ID and stall Detect at MEM or WB and stall
7 WAW Data Hazards Instruction Clock cycle number MULTD F0, F4, F6 IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB IF ID EX MEM WB IF ID EX MEM WB F2, F4, F6 IF ID A1 A2 A3 A4 MEM WB IF ID EX MEM WB F2, 0(R2) IF ID EX MEM WB. IF ID EX MEM WB WAW hazards can be corrected by either: Stalling the latter instruction at MEM until it is safe Preventing the first instruction from overwriting the register Correcting at cycle 11 OK unless intervening RAW/use of F2 WAW hazards can be detected at the ID stage Convert 1st instruction to no-op WAW hazards are generally very rare, designers usually go with the simplest solution
8 Detecting Hazards Hazards among FP instructions & and combined FP and integer instructions Separate int & fp register files limits latter to FP load and store instructions Assuming all checks are to be performed in the ID phase: Check for structural hazards: Wait if the functional unit is busy (Divides in our case) Make sure the register write port is available when needed Check for a RAW data hazard Requires knowledge of latency and initiation interval to decide when to forward and when to stall Check for a WAW data hazard Write completion has to be estimated at the ID stage to check with other instructions in the pipeline Data hazard detection and forwarding logic from values stored between the stages
9 Maintaining Precise Exceptions Pipelining FP instructions can cause outof-order completion Exceptions also a problem: DIVF ADDF SUBF F0, F2, F4 F10, F10, F8 F12, F12, F14 No data hazards What if DIVF exception occurs after ADDF writes F10?
10 Four FP Exception Solutions 1. Settle for imprecise exceptions Some supercomputers still uses this approach IEEE floating point standard requires precise exceptions Some machine offer slow precise and fast imprecise exceptions 2. Buffer the results of all operations until previous instructions complete Complex and expensive design (many comparators and large MUX) History or future register file
11 Four FP Exception Solutions 3. Allow imprecise exceptions and get the handler to clean up any miss Save PC + state about the interrupting instruction and all out-of-order completed instructions The trap handler will consider the state modification caused by finished instructions and prepare machine to resume correctly Issues: consider the following example Instruction1: Long running, eventual exception Instructions 2 (n-1) : Instructions that do not complete Instruction n : An instruction that is finished The compiler can simplify the problem by grouping FP instructions so that the trap does not have to worry about unrelated instructions
12 Four FP Exception Solutions 4. Allow instruction issue to continue only if previous instruction are guaranteed to cause no exceptions: Mainly applied in the execution phase Used on MIPS R4000 and Intel Pentium
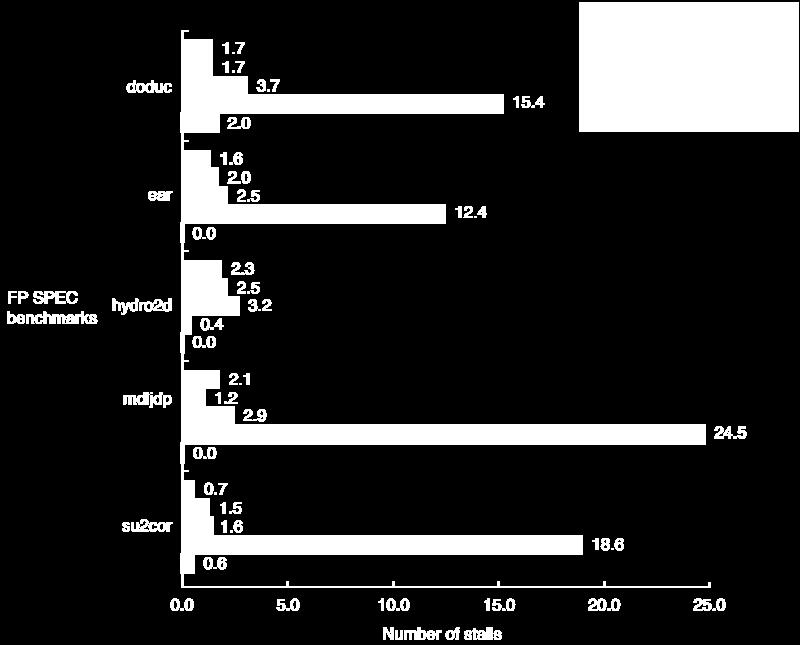
13 Stalls/Instruction, FP Pipeline
 contains several errors in either graph or data.")
14 More FP Pipeline Performance This figure (A.36 in the book) contains several errors in either graph or data. Only take-home: result stalls are most common by far
15 Instruction Level Parallelism (ILP) Overlap the execution of unrelated instructions Both instruction pipelining and ILP enhance instruction throughput not the execution time of the individual instruction Potential of IPL within a basic block is very limited in gcc 17% of instructions are control transfer meaning on average 5 instructions per branch
16 Loops: Simple & Common for (i=1; i<=1000; i=i+1) x[i] = x[i] + y[i]; Techniques like loop unrolling convert loop-level parallelism into instruction-level parallelism statically by the compiler dynamically by hardware Loop-level parallelism can also be exploited using vector processing IPL feasibility is mainly hindered by data and control dependence among the basic blocks Level of parallelism is limited by instruction latencies
17 Major Assumptions Basic MIPS integer pipeline Branches with one delay cycle Functional units are fully pipelined or replicated (as many times as the pipeline depth) An operation of any type can be issued on every clock cycle and there are no structural hazard Instruction producing result Instruction using results Latency in clock cycles FP ALU op Another FP ALU op 3 FP ALU op Store Double 2 Load Double FP ALU op 1 Load Double Store Double 0
![Motivating Example for (i=1000; i>0; i=i-1) x[i] = x[i] + s;](/docs-images/96/127723006/images/18-1.jpg "Standard Pipeline execution Loop: stall F0,x(R1) F4,F0,F2 stall")
 ;F0=vector element F4,F0,F2 ;add scalar from F2")

,f4 Sophisticated compiler")
18 Motivating Example for (i=1000; i>0; i=i-1) x[i] = x[i] + s; Standard Pipeline execution Loop: stall F0,x(R1) F4,F0,F2 stall stall SUBI stall BNEZ stall x(r1),f4 R1,R1,8 R1,Loop Loop: F0,x(R1) ;F0=vector element F4,F0,F2 ;add scalar from F2 x(r1),f4 ;store result SUBI R1,R1,8 ;decrement pointer (DW) BNEZ R1,Loop ;branch R1!=zero Smart compiler Loop: SUBI F0,x(R1) R1,R1,8 F4,F0,F2 stall BNEZ ;F4 latency R1,Loop x+8(r1),f4 Sophisticated compiler optimization reduced execution time from 10 cycles to only 6 cycles

19 Loop Unrolling Loop: SUBI BNEZ F0,x(R1) F4,F0,F2 x(r1),f4 R1,R1,8 R1,Loop 6 cycles, but only 3 are loop body Loop unrolling limits overhead at the expense of a larger code Eliminates branch delays Enable effective scheduling Use of different registers needed to limit data hazard Replicate loop body 4 times, will need cleanup phase if loop iteration is not a multiple of 4 Loop: SUBI BNEZ F0,x(R1) F4,F0,F2 x(r1),f4 ;drop SUBI & BNEZ F6,x-8(R1) F8,F6,F2 x-8(r1),f8 ;drop again F10,x-16(R1) F12,F10,F2 x-16(r1),f12;drop again F14,x-24(R1) F16,F14,F2 x-24(r1),f16 R1,R1,#32 ;alter to 4*8 R1,LOOP
 F12,F10,F2 x-16(r1),f12 F14,x-24(R1) F16,F14,F2 x-24(r1),f16 R1,R1,#32 R1,LOOP Loop unrolling exposes more computation that can be scheduled to minimize")
,f4 instructions is the 9 10 x-8(r1),f8 key for for 11 SUBI R1,R1,#32 detecting and 12 x+16(r1),f12 performing the transformation 13 BNEZ R1,LOOP")
20 Scheduling Unrolled Loops Cycle 1 Loop: SUBI 27 BNEZ 28 stall Instruction F0,x(R1) F4,F0,F2 x(r1),f4 F6,x-8(R1) F8,F6,F2 x-8(r1),f8 F10,x-16(R1) F12,F10,F2 x-16(r1),f12 F14,x-24(R1) F16,F14,F2 x-24(r1),f16 R1,R1,#32 R1,LOOP Loop unrolling exposes more computation that can be scheduled to minimize the pipeline stalls Cycle Instruction 1 Loop: F0,x(R1) 2 F6,x-8(R1) 3 F10,x-16(R1) 4 F14,x-24(R1) 5 F4,F0,F2 6 F8,F6,F2 Understanding 7 F12,F10,F2 dependence 8 F16,F14,F among x(r1),f4 instructions is the 9 10 x-8(r1),f8 key for for 11 SUBI R1,R1,#32 detecting and 12 x+16(r1),f12 performing the transformation 13 BNEZ R1,LOOP 14 x+8(r1),f1
21 Inter-instruction Dependence Determining how one instruction depends on another is critical not only to the scheduling process but also to determining how much parallelism exists If two instructions are parallel they can execute simultaneously in the pipeline without causing stalls (assuming there is not structural hazard) Two instructions that are dependent are not parallel and their execution cannot be reordered
22 Dependence Classifications Data dependence (RAW) Transitive: i! j! k = i! k Easy to determine for registers, hard for memory Does 100(R4) = 20(R6)? From different loop iterations, does 20(R6) = 20(R6)? Name dependence (register/memory reuse) Anti-dependence (WAR): Instruction j writes a register or memory location that instruction i reads from and instruction i is executed first Output dependence (WAW): Instructions i and j write the same register or memory location; instruction ordering must be preserved Control dependence, caused by conditional branching
,f4 R1,R1,#32 R1,Loop Loop: Register renaming SUBI BNEZ F0,x(R1) F4,F0,F2 x(r1),f4 F6,x-8(R1) F8,F6,F2 x-8(r1),f8 F10,x-16(R1) F12,F10,F2 x-16(r1),f12")
 = 20(R6)? Compiler needs to know that R1 does not change! 0(R1)! -8(R1)! -16(R1)!")
23 Example: Name Dependence Loop: SUBI BNEZ F0,x(R1) F4,F0,F2 x(r1),f4 F0,x-8(R1) F4,F0,F2 x-8(r1),f4 F0,x-16(R1) F4,F0,F2 x-16(r1),f4 F0,x-24(R1) F4,F0,F2 x-24(r1),f4 R1,R1,#32 R1,Loop Loop: Register renaming SUBI BNEZ F0,x(R1) F4,F0,F2 x(r1),f4 F6,x-8(R1) F8,F6,F2 x-8(r1),f8 F10,x-16(R1) F12,F10,F2 x-16(r1),f12 F14,x-24(R1) F16,F14,F2 x-24(r1),f16 R1,R1,#32 R1,LOOP Again Name Dependencies are Hard for Memory Accesses Does 100(R4) = 20(R6)? From different loop iterations, does 20(R6) = 20(R6)? Compiler needs to know that R1 does not change! 0(R1)! -8(R1)! -16(R1)! -24(R1) and thus no dependencies between some loads and stores so they could be moved
Floating Point/Multicycle Pipelining in DLX
 Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
Lecture 6 MIPS R4000 and Instruction Level Parallelism. Computer Architectures S
 Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Instruction-Level Parallelism (ILP)
") Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2018 Static Instruction Scheduling 1 Techniques to reduce stalls CPI = Ideal CPI + Structural stalls per instruction + RAW stalls per instruction + WAR stalls per
CS425 Computer Systems Architecture Fall 2018 Static Instruction Scheduling 1 Techniques to reduce stalls CPI = Ideal CPI + Structural stalls per instruction + RAW stalls per instruction + WAR stalls per
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism
 ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
EEC 581 Computer Architecture. Lec 4 Instruction Level Parallelism
 EEC 581 Computer Architecture Lec 4 Instruction Level Parallelism Chansu Yu Electrical and Computer Engineering Cleveland State University Acknowledgement Part of class notes are from David Patterson Electrical
EEC 581 Computer Architecture Lec 4 Instruction Level Parallelism Chansu Yu Electrical and Computer Engineering Cleveland State University Acknowledgement Part of class notes are from David Patterson Electrical
What is ILP? Instruction Level Parallelism. Where do we find ILP? How do we expose ILP?
 What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
Review: Evaluating Branch Alternatives. Lecture 3: Introduction to Advanced Pipelining. Review: Evaluating Branch Prediction
 Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Review: Evaluating Branch Alternatives Lecture 3: Introduction to Advanced Pipelining Two part solution: Determine branch taken or not sooner, AND Compute taken branch address earlier Pipeline speedup
Lecture 4: Introduction to Advanced Pipelining
 Lecture 4: Introduction to Advanced Pipelining Prepared by: Professor David A. Patterson Computer Science 252, Fall 1996 Edited and presented by : Prof. Kurt Keutzer Computer Science 252, Spring 2000 KK
Lecture 4: Introduction to Advanced Pipelining Prepared by: Professor David A. Patterson Computer Science 252, Fall 1996 Edited and presented by : Prof. Kurt Keutzer Computer Science 252, Spring 2000 KK
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Compiler Optimizations. Lecture 7 Overview of Superscalar Techniques. Memory Allocation by Compilers. Compiler Structure. Register allocation
 Lecture 7 Overview of Superscalar Techniques CprE 581 Computer Systems Architecture, Fall 2013 Reading: Textbook, Ch. 3 Complexity-Effective Superscalar Processors, PhD Thesis by Subbarao Palacharla, Ch.1
Lecture 7 Overview of Superscalar Techniques CprE 581 Computer Systems Architecture, Fall 2013 Reading: Textbook, Ch. 3 Complexity-Effective Superscalar Processors, PhD Thesis by Subbarao Palacharla, Ch.1
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 10 Compiler Techniques / VLIW Israel Koren ECE568/Koren Part.10.1 FP Loop Example Add a scalar
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 10 Compiler Techniques / VLIW Israel Koren ECE568/Koren Part.10.1 FP Loop Example Add a scalar
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
CPE 631 Lecture 09: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 09: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 09: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Lecture: Pipeline Wrap-Up and Static ILP
 Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Administrivia. CMSC 411 Computer Systems Architecture Lecture 14 Instruction Level Parallelism (cont.) Control Dependencies
 Control Dependencies") Administrivia CMSC 411 Computer Systems Architecture Lecture 14 Instruction Level Parallelism (cont.) HW #3, on memory hierarchy, due Tuesday Continue reading Chapter 3 of H&P Alan Sussman als@cs.umd.edu
Administrivia CMSC 411 Computer Systems Architecture Lecture 14 Instruction Level Parallelism (cont.) HW #3, on memory hierarchy, due Tuesday Continue reading Chapter 3 of H&P Alan Sussman als@cs.umd.edu
Advanced Pipelining and Instruction- Level Parallelism 4
 4 Advanced Pipelining and Instruction- Level Parallelism 4 Who s first? America. Who s second? Sir, there is no second. Dialog between two observers of the sailing race later named The America s Cup and
4 Advanced Pipelining and Instruction- Level Parallelism 4 Who s first? America. Who s second? Sir, there is no second. Dialog between two observers of the sailing race later named The America s Cup and
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Multicycle ALU Operations 2/28/2011. Diversified Pipelines The Path Toward Superscalar Processors. Limitations of Our Simple 5 stage Pipeline
 //11 Limitations of Our Simple stage Pipeline Diversified Pipelines The Path Toward Superscalar Processors HPCA, Spring 11 Assumes single cycle EX stage for all instructions This is not feasible for Complex
//11 Limitations of Our Simple stage Pipeline Diversified Pipelines The Path Toward Superscalar Processors HPCA, Spring 11 Assumes single cycle EX stage for all instructions This is not feasible for Complex
COSC4201. Prof. Mokhtar Aboelaze York University
 COSC4201 Chapter 3 Multi Cycle Operations Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RTI) 1 Multicycle Operations More than one function unit, each
COSC4201 Chapter 3 Multi Cycle Operations Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RTI) 1 Multicycle Operations More than one function unit, each
Lecture 7: Pipelining Contd. More pipelining complications: Interrupts and Exceptions
 Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
ELE 818 * ADVANCED COMPUTER ARCHITECTURES * MIDTERM TEST *
 ELE 818 * ADVANCED COMPUTER ARCHITECTURES * MIDTERM TEST * SAMPLE 1 Section: Simple pipeline for integer operations For all following questions we assume that: a) Pipeline contains 5 stages: IF, ID, EX,
ELE 818 * ADVANCED COMPUTER ARCHITECTURES * MIDTERM TEST * SAMPLE 1 Section: Simple pipeline for integer operations For all following questions we assume that: a) Pipeline contains 5 stages: IF, ID, EX,
Complications with long instructions. CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. How slow is slow?
 Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
4DM4 Sample Problems for Midterm Tuesday, Oct. 22, 2013
 4DM4 Sample Problems for Midterm -2013 Tuesday, Oct. 22, 2013 Hello Class For the 4DM4 midterm on Monday, Oct. 28, we won t cover the lab. material, i.e., VHDL or the switch or the Network- on- Chips,
4DM4 Sample Problems for Midterm -2013 Tuesday, Oct. 22, 2013 Hello Class For the 4DM4 midterm on Monday, Oct. 28, we won t cover the lab. material, i.e., VHDL or the switch or the Network- on- Chips,
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Instruction Level Parallelism. Taken from
 Instruction Level Parallelism Taken from http://www.cs.utsa.edu/~dj/cs3853/lecture5.ppt Outline ILP Compiler techniques to increase ILP Loop Unrolling Static Branch Prediction Dynamic Branch Prediction
Instruction Level Parallelism Taken from http://www.cs.utsa.edu/~dj/cs3853/lecture5.ppt Outline ILP Compiler techniques to increase ILP Loop Unrolling Static Branch Prediction Dynamic Branch Prediction
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Advanced Computer Architecture CMSC 611 Homework 3. Due in class Oct 17 th, 2012
 Advanced Computer Architecture CMSC 611 Homework 3 Due in class Oct 17 th, 2012 (Show your work to receive partial credit) 1) For the following code snippet list the data dependencies and rewrite the code
Advanced Computer Architecture CMSC 611 Homework 3 Due in class Oct 17 th, 2012 (Show your work to receive partial credit) 1) For the following code snippet list the data dependencies and rewrite the code
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Lecture 15: Instruc.on Level Parallelism -- Introduc.on, Compiler Techniques, and Advanced Branch Predic.on
 Lecture 15: Instruc.on Level Parallelism -- Introduc.on, Compiler Techniques, and Advanced Branch Predic.on CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong
Lecture 15: Instruc.on Level Parallelism -- Introduc.on, Compiler Techniques, and Advanced Branch Predic.on CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong
Administrivia. CMSC 411 Computer Systems Architecture Lecture 6. When do MIPS exceptions occur? Review: Exceptions. Answers to HW #1 posted
 Administrivia CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining (cont.) Alan Sussman als@cs.umd.edu as@csu dedu Answers to HW #1 posted password protected, with instructions sent via email
Administrivia CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining (cont.) Alan Sussman als@cs.umd.edu as@csu dedu Answers to HW #1 posted password protected, with instructions sent via email
NOW Handout Page 1. Review from Last Time. CSE 820 Graduate Computer Architecture. Lec 7 Instruction Level Parallelism. Recall from Pipelining Review
 Review from Last Time CSE 820 Graduate Computer Architecture Lec 7 Instruction Level Parallelism Based on slides by David Patterson 4 papers: All about where to draw line between HW and SW IBM set foundations
Review from Last Time CSE 820 Graduate Computer Architecture Lec 7 Instruction Level Parallelism Based on slides by David Patterson 4 papers: All about where to draw line between HW and SW IBM set foundations
Instruction Level Parallelism (ILP)
") Instruction Level Parallelism (ILP) Pipelining supports a limited sense of ILP e.g. overlapped instructions, out of order completion and issue, bypass logic, etc. Remember Pipeline CPI = Ideal Pipeline
Instruction Level Parallelism (ILP) Pipelining supports a limited sense of ILP e.g. overlapped instructions, out of order completion and issue, bypass logic, etc. Remember Pipeline CPI = Ideal Pipeline
Review: Compiler techniques for parallelism Loop unrolling Ÿ Multiple iterations of loop in software:
 CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
CS152 Computer Architecture and Engineering Lecture 17 Dynamic Scheduling: Tomasulo March 20, 2001 John Kubiatowicz (http.cs.berkeley.edu/~kubitron) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar, VLIW. CPE 631 Session 19 Exploiting ILP with SW Approaches
 Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Session xploiting ILP with SW Approaches lectrical and Computer ngineering University of Alabama in Huntsville Outline Review: Basic Pipeline Scheduling and Loop Unrolling Multiple Issue: Superscalar,
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Computer Science 246 Computer Architecture
 Computer Architecture Spring 2009 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Compiler ILP Static ILP Overview Have discussed methods to extract ILP from hardware Why can t some of these
Computer Architecture Spring 2009 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Compiler ILP Static ILP Overview Have discussed methods to extract ILP from hardware Why can t some of these
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Chapter 3. Pipelining. EE511 In-Cheol Park, KAIST
 Chapter 3. Pipelining EE511 In-Cheol Park, KAIST Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup
Chapter 3. Pipelining EE511 In-Cheol Park, KAIST Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. Complications With Long Instructions
 CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
CS252 Graduate Computer Architecture Lecture 5. Interrupt Controller CPU. Interrupts, Software Scheduling around Hazards February 1 st, 2012
 CS252 Graduate Computer Architecture Lecture 5 Interrupts, Software Scheduling around Hazards February 1 st, 2012 John Kubiatowicz Electrical Engineering and Computer Sciences University of California,
CS252 Graduate Computer Architecture Lecture 5 Interrupts, Software Scheduling around Hazards February 1 st, 2012 John Kubiatowicz Electrical Engineering and Computer Sciences University of California,
Page 1. Recall from Pipelining Review. Lecture 15: Instruction Level Parallelism and Dynamic Execution
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 15: Instruction Level Parallelism and Dynamic Execution March 11, 2002 Prof. David E. Culler Computer Science 252 Spring 2002
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
NOW Handout Page 1. Outline. Csci 211 Computer System Architecture. Lec 4 Instruction Level Parallelism. Instruction Level Parallelism
 Outline Csci 211 Computer System Architecture Lec 4 Instruction Level Parallelism Xiuzhen Cheng Department of Computer Sciences The George Washington University ILP Compiler techniques to increase ILP
Outline Csci 211 Computer System Architecture Lec 4 Instruction Level Parallelism Xiuzhen Cheng Department of Computer Sciences The George Washington University ILP Compiler techniques to increase ILP
CISC 662 Graduate Computer Architecture. Lecture 10 - ILP 3
 CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 10 - ILP 3 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW. Computer Architectures S
 Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Lecture 8 Dynamic Branch Prediction, Superscalar and VLIW Computer Architectures 521480S Dynamic Branch Prediction Performance = ƒ(accuracy, cost of misprediction) Branch History Table (BHT) is simplest
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
CSE 502 Graduate Computer Architecture. Lec 8-10 Instruction Level Parallelism
 CSE 502 Graduate Computer Architecture Lec 8-10 Instruction Level Parallelism Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
CSE 502 Graduate Computer Architecture Lec 8-10 Instruction Level Parallelism Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from David Patterson,
COSC4201 Instruction Level Parallelism Dynamic Scheduling
 COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
COSC4201 Instruction Level Parallelism Dynamic Scheduling Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Outline Data dependence and hazards Exposing parallelism
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Pipelining. Principles of pipelining. Simple pipelining. Structural Hazards. Data Hazards. Control Hazards. Interrupts. Multicycle operations
 Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
Slide Set 8. for ENCM 501 in Winter Steve Norman, PhD, PEng
 Slide Set 8 for ENCM 501 in Winter 2018 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary March 2018 ENCM 501 Winter 2018 Slide Set 8 slide
Slide Set 8 for ENCM 501 in Winter 2018 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary March 2018 ENCM 501 Winter 2018 Slide Set 8 slide
COSC 6385 Computer Architecture - Pipelining (II)
") COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
Lecture: Static ILP. Topics: compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2)
") Lecture: Static ILP Topics: compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Static vs Dynamic Scheduling Arguments against dynamic scheduling: requires complex structures
Lecture: Static ILP Topics: compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Static vs Dynamic Scheduling Arguments against dynamic scheduling: requires complex structures
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
CS252 Graduate Computer Architecture Lecture 6. Recall: Software Pipelining Example
 CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CS252 Graduate Computer Architecture Lecture 6 Tomasulo, Implicit Register Renaming, Loop-Level Parallelism Extraction Explicit Register Renaming John Kubiatowicz Electrical Engineering and Computer Sciences
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Updated Exercises by Diana Franklin
 C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Superscalar Architectures: Part 2
 Superscalar Architectures: Part 2 Dynamic (Out-of-Order) Scheduling Lecture 3.2 August 23 rd, 2017 Jae W. Lee (jaewlee@snu.ac.kr) Computer Science and Engineering Seoul NaMonal University Download this
Superscalar Architectures: Part 2 Dynamic (Out-of-Order) Scheduling Lecture 3.2 August 23 rd, 2017 Jae W. Lee (jaewlee@snu.ac.kr) Computer Science and Engineering Seoul NaMonal University Download this
Graduate Computer Architecture. Chapter 3. Instruction Level Parallelism and Its Dynamic Exploitation
 Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Graduate Computer Architecture Chapter 3 Instruction Level Parallelism and Its Dynamic Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques Scoreboarding (Appendix A.8) Tomasulo
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Instruction Frequency CPI. Load-store 55% 5. Arithmetic 30% 4. Branch 15% 4
 PROBLEM 1: An application running on a 1GHz pipelined processor has the following instruction mix: Instruction Frequency CPI Load-store 55% 5 Arithmetic 30% 4 Branch 15% 4 a) Determine the overall CPI
PROBLEM 1: An application running on a 1GHz pipelined processor has the following instruction mix: Instruction Frequency CPI Load-store 55% 5 Arithmetic 30% 4 Branch 15% 4 a) Determine the overall CPI
Execution/Effective address
 Pipelined RC 69 Pipelined RC Instruction Fetch IR mem[pc] NPC PC+4 Instruction Decode/Operands fetch A Regs[rs]; B regs[rt]; Imm sign extended immediate field Execution/Effective address Memory Ref ALUOutput
Pipelined RC 69 Pipelined RC Instruction Fetch IR mem[pc] NPC PC+4 Instruction Decode/Operands fetch A Regs[rs]; B regs[rt]; Imm sign extended immediate field Execution/Effective address Memory Ref ALUOutput
Computer Systems Architecture I. CSE 560M Lecture 5 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Background: Pipelining Basics. Instruction Scheduling. Pipelining Details. Idealized Instruction Data-Path. Last week Register allocation
 Instruction Scheduling Last week Register allocation Background: Pipelining Basics Idea Begin executing an instruction before completing the previous one Today Instruction scheduling The problem: Pipelined
Instruction Scheduling Last week Register allocation Background: Pipelining Basics Idea Begin executing an instruction before completing the previous one Today Instruction scheduling The problem: Pipelined
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
ESE 545 Computer Architecture Instruction-Level Parallelism (ILP) and Static & Dynamic Instruction Scheduling Instruction level parallelism
 and Static & Dynamic Instruction Scheduling Instruction level parallelism") Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP) and Static & Dynamic Instruction Scheduling 1 Outline ILP Compiler techniques to increase ILP Loop Unrolling Static
Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP) and Static & Dynamic Instruction Scheduling 1 Outline ILP Compiler techniques to increase ILP Loop Unrolling Static
Chapter 4 The Processor (Part 4)
") Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
Lecture 4: Advanced Pipelines. Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10)
") Lecture 4: Advanced Pipelines Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10) 1 Hazards Structural hazards: different instructions in different stages (or the same stage)
Lecture 4: Advanced Pipelines Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10) 1 Hazards Structural hazards: different instructions in different stages (or the same stage)
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University