Introduction to MPI+OpenMP hybrid programming. SuperComputing Applications and Innovation Department
|
|
|
- Maud Rose
- 5 years ago
- Views:
Transcription
1 Introduction to MPI+OpenMP hybrid programming SuperComputing Applications and Innovation Department
2 Basic concepts
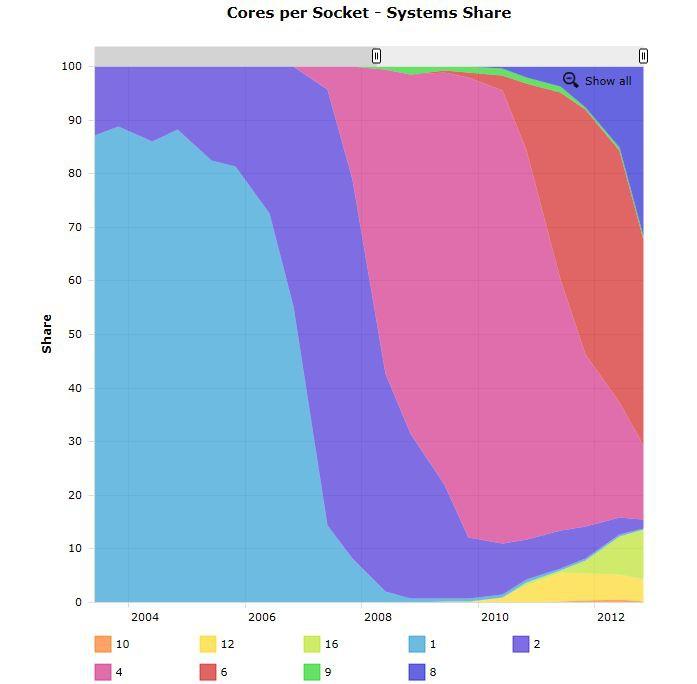
3 Architectural trend
4 Architectural trend In a nutshell: memory per core decreases memory bandwidth per core decreases number of cores per socket increases single core clock frequency decreases Programming model should follow the new kind of architectures available on the market: what is the most suitable model for this kind of machines?
5 Programming models Distributed parallel computers rely on MPI strong consolidated standard enforce the scalability (depending on the algorithm) up to a very large number of tasks but... is it enough when memory is such small amount on each node? Example: Bluegene/Q has 16GB per node and 16 cores. Can you imagine to put there more than 16MPI (tasks), i.e. less than 1GB per core?
6 Programming models On the other side, OpenMP is a standard for shared memory systems Pthreads execution models is a lower-level alternative, but OpenMP is often a better choice for HPC programming OpenMP is robust, clear and sufficiently easy to implement but depending on the implementation, typically the scaling on the number of threads is much less effective than the scaling on number of MPI tasks Putting together MPI with OpenMP could permit to exploit the features of the new architectures, mixing these paradigms

7 Hybrid model: MPI+OpenMP In a single node you can exploit a shared memory parallelism using OpenMP Across the nodes you can use MPI to scale up Example: on a Bluegene/Q machine you can put 1 MPI task on each node and 16 OpenMP threads. If the scalability on threads is good enough, you can use all the node memory.
8 MPI vs OpenMP Pure MPI Pro: High scalability High portability No false sharing Scalability out-of-node Pure MPI Con: Hard to develop and debug. Explicit communications Coarse granularity Hard to ensure load balancing
9 MPI vs OpenMP Pure MPI Pro: High scalability High portability No false sharing Scalability out-of-node Pure MPI Con: Hard to develop and debug. Explicit communications Coarse granularity Hard to ensure load balancing Pure OpenMP Pro: Easy to deploy (often) Low latency Implicit communications Coarse and fine granularity Dynamic Load balancing Pure OpenMP Con: Only on shared memory machines Intranode scalability Possible data placement problem Undefined thread ordering
10 MPI+OpenMP Conceptually simple and elegant Suitable for multicore/multinodes architectures Two-level hierarchical parallelism In principle, you can alleviate problems related to the scalability of MPI, reducing the number of tasks and network flooding
11 Increasing granularity OpenMP introduces fine granularity parallelism Loop-based parallelism Task construct (OpenMP 3.0): powerful and flexible Load balancing can be dynamic or scheduled All the work is in charge to the compiler No explicit data movement
12 Two level parallelism Using a hybrid approach means to balance the hierarchy between MPI tasks and thread. MPI in most cases (but not always) occupy the upper level respect to OpenMP usually you assign n threads per MPI task, not m MPI tasks per thread The choice about the number of threads per MPI task strongly depends on the kind of application, algorithm or kernel. (this number can change inside the application) There's no golden rule. More often this decision is taken a-posteriori after benchmarks on a given machine/architecture
13 Saving MPI tasks Using a hybrid approach MPI+OpenMP can lower the number of MPI tasks used by the application. Memory footprint can be alleviated by a reduction of replicated data on MPI level Speed-up limited due algorithmic issues can be solved (because you're reducing the amount of communication)
14 Reality is bitter In real scenarios, mixing MPI and OpenMP, sometimes, can make your code slower If you exceed with the number of OpenMP threads you can encounter problems with locking of resources Sometimes threads can stay in a idle state (spin) for a long time Problems with cache coherency and false sharing Difficulties in the management of variables scope
15 Cache coherency and false sharing It is a side effects of the cache-line granularity of cache coherence implemented in shared memory systems. The cache coherency implementation keep track of the status of cache lines by appending state bits to indicate whether data on cache line is still valid or outdated. Once the cache line is modified, cache coherence notifies other caches holding a copy of the same line that its line is invalid. If data from that line is needed, a new updated copy must to be fetched.
 for (int i=0; i<n; i++) a[i] =")
16 False sharing #pragma omp parallel for shared(a) schedule(static,1) for (int i=0; i<n; i++) a[i] = i;
17 Let's start The most simple recipe is: start from a serial code and make it a MPI-parallel code implement for each of the MPI task a OpenMP-based parallelization Nothing prevents to implement a MPI parallelization inside a OpenMP parallel region in this case, you should take care of the thread-safety To start, we will assume that only the master thread is allowed to communicate with others MPI tasks
18 A simple hybrid code (correct?) call MPI_INIT (ierr) call MPI_COMM_RANK ( ) call MPI_COMM_SIZE ( ) some computation and MPI communication call OMP_SET_NUM_THREADS(4)!$OMP PARALLEL!$OMP DO do i=1,n computation enddo!$omp END DO!$OMP END PARALLEL some computation and MPI communication call MPI_FINALIZE (ierr)
19 Master-only approach Advantages: Simplest hybrid parallelization (easy to understand and to manage) No message passing inside a SMP node Disadvantages: All other threads are sleeping during MPI communications Thread-safe MPI is required
20 MPI_Init_thread support MPI_INIT_THREAD (required, provided, ierr) IN: required, desired level of thread support (integer). OUT: provided, provided level (integer). provided may be less than required. Four levels are supported: MPI_THREAD_SINGLE: Only one thread will run. Equals to MPI_INIT. MPI_THREAD_FUNNELED: processes may be multithreaded, but only the main thread can make MPI calls (MPI calls are delegated to main thread) MPI_THREAD_SERIALIZED: processes could be multi-threaded More than one thread can make MPI calls, but only one at a time. MPI_THREAD_MULTIPLE: multiple threads can make MPI calls, with no restrictions.
21 MPI_Init_thread The various implementations differ in levels of thread-safety If your application allows multiple threads to make MPI calls simultaneously, without MPI_THREAD_MULTIPLE, is not thread-safe Using OpenMPI, you have to use enable-mpi-threads at configure time to activate all levels see more later Higher level corresponds to higher thread-safety. Use the required safety needs.
22 MPI_THREAD_SINGLE There are no additional user thread in the system E.g., there are no OpenMP parallel regions MPI_Init_thread with MPI_THREAD_SINGLE is fully equivalent to MPI_Init int main(int argc, char ** argv) { int buf[100]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); for (i = 0; i < 100; i++) compute(buf[i]); /* Do MPI stuff */ MPI_Finalize(); return 0; }

23 MPI_THREAD_FUNNELED It adds the possibility to make MPI calls inside a parallel region, but only the master thread is allowed to do so All MPI calls are made by the master thread The programmer must guarantee that!
24 MPI_THREAD_FUNNELED int main(int argc, char ** argv) { int buf[100], provided; MPI_Init_thread(&argc, &argv, MPI_THREAD_FUNNELED, &provided); if (provided < MPI_THREAD_FUNNELED) MPI_Abort(MPI_COMM_WORLD,1); #pragma omp parallel for for (i = 0; i < 100; i++) compute(buf[i]); /* Do MPI stuff */ MPI_Finalize(); return 0; }
25 MPI_THREAD_FUNNELED MPI function calls can be: outside a parallel region or in a parallel region, enclosed in omp master clause There is no synchronization at the end of a omp master region, so a barrier is needed before and after to ensure that data buffers are available before/after the MPI communication!$omp BARRIER!$OMP MASTER call MPI_Xxx(...)!$OMP END MASTER!$OMP BARRIER #pragma omp barrier #pragma omp master MPI_Xxx(...); #pragma omp barrier
26 MPI_THREAD_SERIALIZED Multiple threads may make MPI calls, but only one at a time: MPI calls are not made concurrently from two distinct threads. MPI calls are ''serialized'' The programmer must guarantee that!
27 MPI_THREAD_SERIALIZED int main(int argc, char ** argv) { int buf[100], provided; MPI_Init_thread(&argc, &argv, MPI_THREAD_SERIALIZED, &provided); if (provided < MPI_THREAD_SERIALIZED) MPI_Abort(MPI_COMM_WORLD,1); #pragma omp parallel for for (i = 0; i < 100; i++) { compute(buf[i]); #pragma omp critical /* Do MPI stuff */ } MPI_Finalize(); Return 0; }
28 MPI_THREAD_SERIALIZED MPI calls can be outside parallel regions, or inside, but enclosed in a omp single region (it enforces the serialization) or omp critical or... Again, a starting barrier may be needed to ensure data consistency But at the end of omp single there is an automatic barrier Unless nowait is specified!$omp BARRIER!$OMP SINGLE call MPI_Xxx(...)!$OMP END SINGLE #pragma omp barrier #pragma omp single MPI_Xxx(...);

29 MPI_THREAD_MULTIPLE It is the most flexible mode, but also the most complicate one Any thread is allowed to perform MPI communications, without any restrictions.
30 MPI_THREAD_MULTIPLE int main(int argc, char ** argv) { int buf[100], provided; MPI_Init_thread(&argc, &argv, MPI_THREAD_MULTIPLE, &provided); if (provided < MPI_THREAD_MULTIPLE) MPI_Abort(MPI_COMM_WORLD,1); #pragma omp parallel for for (i = 0; i < 100; i++) { compute(buf[i]); /* Do MPI stuff */ } MPI_Finalize(); return 0; }
31 Specs of MPI_THREAD_MULTIPLE Ordering: when multiple threads make MPI calls concurrently the outcome will be as if the calls executed sequentially in some (any) order Ordering is maintained within each thread User must ensure that collective operations on the same communicator windows or file handle are correctly ordered among threads E.g. cannot call a broadcast on one thread and a reduce on another thread on the same communicator It is the user's responsibility to prevent races when threads in the same application post conflicting MPI calls E.g. accessing an info object from one thread and freeing it from another thread Blocking: Blocking MPI calls will block only the calling thread and will not prevent other threads from running or executing MPI functions
32 Ordering in MPI_THREAD_MULTIPLE Incorrect example with collectives P0 and P1 can have different ordering of Bcase on Barrier Here the user must use some kind of synchronization to ensure that either thread 1 or thread 2 gets scheduled first on both processes Otherwise a broadcast may get matched with a barrier on the same communicator, which is not allowed in MPI Process 0 Process 1 Thread 0 MPI_Bcast(comm) MPI_Bcast(comm) Thread 1 MPI_Barrier(comm) MPI_Barrier(comm)
33 Ordering in MPI_THREAD_MULTIPLE Incorrect example with object Management The user has to make sure that one thread is not using an object while another thread is freeing it This is essentially an ordering issue; the object might get freed before it is used Process 0 Process 1 Thread 0 MPI_Bcast(comm) MPI_Bcast(comm) Thread 1 MPI_Comm_free(comm) MPI_Comm_free(comm)
34 Blocking in MPI_THREAD_MULTIPLE Correct example with point-to-point An implementation must ensure that the example below never deadlocks for any ordering of thread execution That means the implementation cannot simply acquire a thread lock and block within an MPI function. It must release the lock to allow other threads to make progress Process 0 Process 1 Thread 0 MPI_Recv(src=1) MPI_Recv(src=0) Thread 1 MPI_Send(dst=1) MPI_Send(dst=0)
35 Comparison to pure MPI Funneled All threads but the master are sleeping during MPI communications Only one thread may not be able to lead up to max inter-node bandwidth Pure MPI Each CPU can lead up max inter-node bandwidth Hints: overlap as much as possible communications and computations
36 Overlap communications and computations In order to overlap communications with computations, the first step is using MPI_THREAD_FUNNELED mode While the master threads (a master thread for each MPI rank) are exchanging data, the other threads performs computation The tricky part is separating code that can run before or after the data exchanged are available!$omp PARALLEL if (thread_id==0) then call MPI_xxx( ) else do some computation endif!$omp END PARALLEL
 There is no non-blocking (no longer the case in MPI 3.")
37 MPI collective hybridization MPI collectives are highly optimized Several point-to-point communication in one operations They can hide from the programmer a huge volume of transfer (MPI_Alltoall generates almost 1 million point-topoint messages using 1024 cores) There is no non-blocking (no longer the case in MPI 3.0)
38 MPI collective hybridization Better scalability by a reduction of both the number of MPI messages and the number of process. Tipically: for all-to-all communications, the number of transfers decrease by a factor #threads^2 the length of messages increases by a factor #threads Allow to overlap communication and computation.

39 MPI collective hybridization Restrictions: In MPI_THREAD_MULTIPLE mode is forbidden at any given time two threads each do a collective call on the same communicator (MPI_COMM_WORLD) 2 threads calling each a MPI_Allreduce may produce wrong results Use different communicators for each collective call Do collective calls only on 1 thread per process (MPI_THREAD_SERIALIZED mode should be fine)
40 Multithreaded libraries Introduction of OpenMP into existing MPI codes includes OpenMP drawbacks (synchronization, overhead, quality of compiler and runtime ) A good choice (whenever possible) is to include into the MPI code a multithreaded, optimized library suitable for the application. BLAS, LAPACK, MKL (Intel), FFTW are well known multithreaded libraries available in the HPC ecosystem. Some libraries create their own threads: must be called outside our omp parallel regions Otherwise, check how much the the library is thread-safe, if at least can be called by the master thread of your omp region (MPI_THREAD_FUNNELED) Look carefully at the doc of your library, e.g.
41 BGQ benchmark example Up to 64 hardware threads per process are available on bgq (SMT) Huge simulation, 30000x30000 points. Stopped after 100 iterations only for timing purposes. Number of threads / processes MPI+OpenMP (TOT= 64 MPI, 1PPN) MPI_THREAD_MULTIPLE version Elapsed time (sec.) MPI ONLY (TOT= 1024 MPI, 16,32,64 ppn Elapsed time (sec.) N.A N.A N.A
42 Conclusions Better scalability by a reduction of both the number of MPI messages and the number of processes involved in collective communications and by a better load balancing. Better adequacy to the architecture of modern supercomputers while MPI is only a flat approach. Optimization of the total memory consumption (through the OpenMP shared-memory approach, savings in replicated data in the MPI processes and in the used memory by the MPI library itself). Reduction of the footprint memory when the size of some data structures depends directly on the number of MPI processes. It can remove algorithmic limitations (maximum decomposition in one direction for example).
43 Conclusions / 2 Applications that can benefit from hybrid approach: Codes having limited MPI scalability (through the use of MPI_Alltoall for example). Codes requiring dynamic load balancing Codes limited by memory size and having many replicated data between MPI processes or having data structures that depends on the number of processes. Inefficient MPI implementation library for intra-node communication. Codes working on problems of fine-grained parallelism or on a mixture of fine and coarse-grain parallelism. Codes limited by the scalability of their algorithms.
44 Conclusions / 3 Hybrid programming is complex and requires high level of expertise. Both MPI and OpenMP performances are needed (Amdhal s law apply separately to the two approaches). Savings in performances are not guaranteed (extra additional costs).
45 PGAS programming model PGAS: Partitioned Global Address Space a programming model somehow alternative to MPI and OpenMP models but possibly mixable Tries to combine SPMD (MPI) power with data referencing semantics of shared memory systems MPI Library ; OpenMP Annotations ; PGAS Language PGAS is the basis of Unified Parallel C and Coarray Fortran UPC: Unified Parallel C CAF: Coarray Fortran, included in Fortran 2008 standard. Implementation available on common compilers (check also A promising approach...
46 A touch of CAF program Hello_World implicit none integer :: i! Local variable character(len=20) :: name[*]! scalar coarray, one "name" for each image.! Note: "name" is the local variable while "name[<index>]" accesses the! variable in a specific image; "name[this_image()]" is the same as "name".! Interact with the user on Image 1; execution for all others pass by. if (this_image() == 1) then write(*,'(a)',advance='no') 'Enter your name: ' read(*,'(a)') name! Distribute information to other images do i = 2, num_images() name[i] = name end do end if sync all! Barrier to make sure the data have arrived.! I/O from all images, executing in any order, but! each record written is intact. write(*,'(3a,i0)') 'Hello ',trim(name), & ' from image ', this_image() end program Hello_world
47 Implementations and cluster usage notes
48 MPI implementations and thread support An implementation is not required to support levels higher than MPI_THREAD_SINGLE, that is, an implementation is not required to be thread safe Most MPI implementations support a very low default thread support Usually no support (MPI_THREAD_SINGLE) And probably MPI_THREAD_FUNNELED (even if not explicitly) Which (usually) is ok for cases where MPI communications are called outside of OMP parallel regions (where MPI_THREAD_FUNNELED would be strictly required) Implementations with thread support are more complicated, error-prone and sometimes slower Checking the MPI_Init_thread provided support is a good programming practice
49 MPI implementations: check thread support required = MPI_THREAD_MULTIPLE; ierr = MPI_Init_thread(&argc,&argv,required,&provided); if(required!= provided) { if(rank == 0) { fprintf(stderr,"incompatible MPI thread support\n"); fprintf(stderr,"required,provided: %d %d\n", required,provided); } ierr = MPI_Finalize(); exit(-1); } call MPI_Init_thread(required, provided, ierr) if(provided /= required) then if(rank == 0) then print*,'attention! incompatible MPI thread support' print*,'thread support required, provided: ',required, provided endif call MPI_Finalize(ierr); STOP endif
50 MPI implementations and thread support / 2 Beware: the lack of thread support may result in subtle errors (not always clear) OpenMPI (1.8.3): when compiling OpenMPI there is a configure option to specify: --enable-mpi-thread-multiple [Enable MPI_THREAD_MULTIPLE support (default: disabled)] IntelMPI (5.0.2): both thread safe/non-thread safe versions are available: Specify the option -mt_mpi when compiling your program to link the thread safe version of the Intel(R) MPI Library E.g. mpif90 -mt_mpi -qopenmp main.f90
51 MPI and resource allocation The problem: how to distribute and control the resource allocation and usage (MPI processes/omp threads) within a resource manager How to use all the allocated resources: if n cores per node have been allocated how to run my program using all of that cores Not less, maximize performance Not more, do not interact with jobs of other users How to use at its best the resource optimal mapping between MPI processes/omp threads and physical cores
52 MPI and resource allocation / 2 Most MPI implementations allow a tight integration with resource managers in order to ease the usage of the requested resources The integration may enforce some constraints or just give hints to the programmer Strict: only the requested physical resources can be used by my job Soft: the programmer may use resources not explicitly allocated but only forcing the default settings
53 Cineca Marconi: PBSPro and MPI Cineca Marconi cluster assign resources using PBSProfessional 13 Strict mode is guaranteed through cgroups (control groups, a feature of Linux kernel which limits, isolate the usage of resources CPU, memory, I/O, network, etc.. - of a process group). The processes can utilize only the resources assigned by the scheduler (minimizing the interaction with other jobs simultaneously running) OpenMPI and IntelMPI implementations available, both supporting PBS integration module load autoload openmpi/ gnu module load autoload openmpi/ threadmultiple--gnu module load autoload intelmpi/2017--binary
54 Review on PBS select option -lselect=<n_chunks>:ncpus:<n_cores>:mpiprocs:<n_mpi> Beware: n_chunks usually means n_nodes but this is not guaranteed provided that two or more chunks of n_cores can be allocated on a single node mpiprocs must be well understood, let us examine the file $PBS_NODEFILE created by PBS listing the allocated resources for some example cases 6 MPI processes per chunk (node) and 6 cores reserved:useful for pure MPI runs select=4 ncpus=6 mpiprocs=6 node007 node003 node001 node015 node007 node003 node001 node015 node007 node003 node001 node015 node007 node003 node001 node015 node007 node003 node001 node015 node007 node003 node001 node015
55 Review on PBS select option / 2 1 MPI process per chunk (node), but 6 cores reserved, useful for hybrid case (OMP_NUM_THREADS=6) select=4 ncpus=6 mpiprocs=1 node007 node003 node001 node015 2 MPI processes per chunk (node), but 6 cores reserved, again for hybrid cases (OMP_NUM_THREADS=3) select=4 ncpus=6 mpiprocs=2 node007 node003 node001 node015 node007 node003 node001 node015
56 OpenMPI and IntelMPI Resource allocation is not aware of the MPI implementation which will be used But MPI implementations give a different meaning and enforce different constraints We will discuss OpenMPI and IntelMPI implementations Basically, mpirun <executable> runs MPI processes taken from $PBS_NODEFILE But... IntelMPI allows to run a number of MPI processes even larger than the requested mpiprocs (I.e.the number of lines of the file $PBS_NODEFILE) But if the PBS strict mode is active, the user will use only the reserved cores If the number of MPI processes is larger than ncpus, we are experimenting the so called oversubscribing OpenMPI imposes mpiprocs as the upper limit for the number of MPI processes which can be run Since mpiprocs<ncpus, no oversubscribing is possible
57 OpenMPI and IntelMPI It is possible to modify how the $PBS_NODEFILE is interpreted by mpirun OpenMPI: -npernode <n> With -npernode it is possible to specify how many MPI processes to run on each node IntelMPI has the options : -perhost <n> -ppn <n> but these do not work at least on our installations Since IntelMPI allows to run more processes than mpiprocs declared to PBS, you can specify mpiprocs=1 and then launch more processes which will be allocated roundrobin
58 OpenMPI and IntelMPI It is also possible to completely override the $PBS_NODEFILE manually imposing a MPI machine file Some limitations still apply IntelMPI: -machine {name} -machinefile {name} OpenMPI -machinefile {machinefile} --machinefile {machinefile} -hostname {machinefile}
59 Where is my job running? It may seem a silly question but it is not How to check which resources have been allocated for my job qstat -n1 <job_id> (for completed jobs add the -x flag) qstat -f <job_id> grep exec_host (for completed jobs add the -x flag) Cat $PBS_NODEFILE (during the job execution, to be run by the master assigned node, e.g. in the batch script) How to check where am I actually running? Yes, it may be different from the previous point mpirun <mpirun options> hostname change the source code calling MPI_Get_processor_name Am I really using all the requested cores? See more later
60 NUMA architectures Many current architectures used on HPC clusters are NUMA Non-uniform memory access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than non-local memory (memory local to another processor or memory shared between processors) How to optimize my code and my run? Numactl Linux command to control NUMA policy for processes or shared memory OpenMPI thread assignment MPI process assignement
61 OpenMP thread assignment Intel compiler: set KMP_AFFINITY to compact/scatter (other options available) Specifying compact assigns the OpenMP* thread <n>+1 to a free thread context as close as possible to the thread context where the <n> OpenMP* thread was placed. Specifying scatter distributes the threads as evenly as possible across the entire system. scatter is the opposite of compact add the modifier verbose to have a list of the mapping (threads vs core). For example: export KMP_AFFINITY=verbose,compact More info at: GCC OpenMP uses the lower level variable GOMP_CPU_AFFINITY. For example, GOMP_CPU_AFFINITY=" :2"
62 OpenMP thread assignment / 2 OpenMP v4.5 provides OMP_PLACES and OMP_PROC_BIND (it's standard!) OMP_PLACES: Specifies on which CPUs the threads should be placed. The thread placement can be either specified using an abstract name or by an explicit list of the places. Allowed abstract names: threads, cores and sockets OMP_PROC_BIND: specifies whether theads may be moved between CPUs. If set to TRUE, OpenMP theads should not be moved; if set to FALSE they may be moved. Use a comma separated list with the values MASTER, CLOSE and SPREAD to specify the thread affinity policy for the corresponding nesting level. More from OpenMP recent standards Thread assignment can be crucial for manycore architectures (Intel PHI)
63 OpenMP thread assignment / 4 Example (on a machine with 2 10-core sockets): export OMP_PLACES=cores; export OMP_PROC_BIND= master export OMP_PROC_BIND= close export OMP_PROC_BIND= spread t0 -> c0 t0 -> c0 t0 -> c0 t1 -> c0 t1 -> c1 t1 -> c10 t2 -> c0 t2 -> c2 t2 -> c1 t3 -> c0 t3 -> c3 t3 -> c11
64 MPI process mapping/binding OpenMPI: tuning possible via options of mpirun main reference: beware: mpirun automatically binds processes as of the start of the v1.8 series. Two binding patterns are used in the absence of any further directives: Bind to core: when the number of processes is <= 2 Bind to socket: when the number of processes is > 2 more intuitive syntax still works but deprecated -npernode <n> / -npersocket <n>
65 MPI process mapping-binding / 2 But --map-by function is more complete and can reproduce the above cases --map-by ppr:<n>:node / --map-by ppr:<n>:socket For process binding: --bind-to <node/socket/core/...> To order processes (rank in round-robin fashion according to the specified object) --rank-by <foo> --report-bindings: useful option to see what is happening wrt bindings mpirun --map-by ppr:1:socket --rank-by socket --bind-to socket --report-bindings -np $PROCS./bin/$PROGRAM
66 MPI process mapping-binding / 3 If your application uses threads, then you probably want to ensure that you are either not bound at all (by specifying --bind-to none), or bound to multiple cores using an appropriate binding level or specific number of processing elements per application process. mpirun --map-by ppr:1:socket:pe=10 --rank-by socket --bind-to socket --report-bindings <PROGRAM> (hybrid, 1 process per socket, 10 threads per process) mpirun --map-by ppr:2:socket:pe=5 --rank-by socket --bind-to socket --report-bindings <PROGRAM> r0 -> c0-4 r1 -> c10-14 r2 -> c5-9 r3 -> c15-19
67 MPI process mapping-binding / 4 IntelMPI: tuning possible via environment variables main reference: I_MPI_PIN: turn on/off process pinning. Default is on I_MPI_PIN_MODE: choose the pinning method I_MPI_PIN_PROCESSOR_LIST: one-to-one pinning, define a processor subset and the mapping rules for MPI processes within this subset. I_MPI_PIN_DOMAIN: one-to-many pinning, control process pinning for hybrid Intel MPI Library applications mpirun -print-rank-map to know the process binding or activate I_MPI_DEBUG=5
, domain size is equal to OMP_NUM_THREADS auto, domain size is n_procs/n_ranks Explicit domain mask e.g.")
68 MPI process mapping-binding / 5 I_MPI_PIN_DOMAIN defines the logical processor in each domain If present, it overrides I_MPI_PROCESSOR_LIST Different ways to define the domains are allowed Multi-core shape: core, socket, node, Explicit shape: omp (recommended for hybrid jobs), domain size is equal to OMP_NUM_THREADS auto, domain size is n_procs/n_ranks Explicit domain mask e.g. [0xfc00, 0x3ff] (to understand convert to binary [ , ]) E.g. mpirun -np 1 -env I_MPI_PIN_DOMAIN omp -env I_MPI_PIN_DEBUG 5./a.out
69 References MPI documents OpenMP specifications SuperComputing 2015: Intel & GNU compilers
Lecture 36: MPI, Hybrid Programming, and Shared Memory. William Gropp
 Lecture 36: MPI, Hybrid Programming, and Shared Memory William Gropp www.cs.illinois.edu/~wgropp Thanks to This material based on the SC14 Tutorial presented by Pavan Balaji William Gropp Torsten Hoefler
Lecture 36: MPI, Hybrid Programming, and Shared Memory William Gropp www.cs.illinois.edu/~wgropp Thanks to This material based on the SC14 Tutorial presented by Pavan Balaji William Gropp Torsten Hoefler
Hybrid MPI/OpenMP parallelization. Recall: MPI uses processes for parallelism. Each process has its own, separate address space.
 Hybrid MPI/OpenMP parallelization Recall: MPI uses processes for parallelism. Each process has its own, separate address space. Thread parallelism (such as OpenMP or Pthreads) can provide additional parallelism
Hybrid MPI/OpenMP parallelization Recall: MPI uses processes for parallelism. Each process has its own, separate address space. Thread parallelism (such as OpenMP or Pthreads) can provide additional parallelism
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
MPI & OpenMP Mixed Hybrid Programming
 MPI & OpenMP Mixed Hybrid Programming Berk ONAT İTÜ Bilişim Enstitüsü 22 Haziran 2012 Outline Introduc/on Share & Distributed Memory Programming MPI & OpenMP Advantages/Disadvantages MPI vs. OpenMP Why
MPI & OpenMP Mixed Hybrid Programming Berk ONAT İTÜ Bilişim Enstitüsü 22 Haziran 2012 Outline Introduc/on Share & Distributed Memory Programming MPI & OpenMP Advantages/Disadvantages MPI vs. OpenMP Why
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
[Potentially] Your first parallel application
![[Potentially] Your first parallel application](/thumbs/71/65941908.jpg "[Potentially] Your first parallel application") [Potentially] Your first parallel application Compute the smallest element in an array as fast as possible small = array[0]; for( i = 0; i < N; i++) if( array[i] < small ) ) small = array[i] 64-bit Intel
[Potentially] Your first parallel application Compute the smallest element in an array as fast as possible small = array[0]; for( i = 0; i < N; i++) if( array[i] < small ) ) small = array[i] 64-bit Intel
MPI and OpenMP. Mark Bull EPCC, University of Edinburgh
 1 MPI and OpenMP Mark Bull EPCC, University of Edinburgh markb@epcc.ed.ac.uk 2 Overview Motivation Potential advantages of MPI + OpenMP Problems with MPI + OpenMP Styles of MPI + OpenMP programming MPI
1 MPI and OpenMP Mark Bull EPCC, University of Edinburgh markb@epcc.ed.ac.uk 2 Overview Motivation Potential advantages of MPI + OpenMP Problems with MPI + OpenMP Styles of MPI + OpenMP programming MPI
Hybrid MPI and OpenMP Parallel Programming
 Hybrid MPI and OpenMP Parallel Programming Jemmy Hu SHARCNET HPTC Consultant July 8, 2015 Objectives difference between message passing and shared memory models (MPI, OpenMP) why or why not hybrid? a common
Hybrid MPI and OpenMP Parallel Programming Jemmy Hu SHARCNET HPTC Consultant July 8, 2015 Objectives difference between message passing and shared memory models (MPI, OpenMP) why or why not hybrid? a common
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
JURECA Tuning for the platform
 JURECA Tuning for the platform Usage of ParaStation MPI 2017-11-23 Outline ParaStation MPI Compiling your program Running your program Tuning parameters Resources 2 ParaStation MPI Based on MPICH (3.2)
JURECA Tuning for the platform Usage of ParaStation MPI 2017-11-23 Outline ParaStation MPI Compiling your program Running your program Tuning parameters Resources 2 ParaStation MPI Based on MPICH (3.2)
Multicore Performance and Tools. Part 1: Topology, affinity, clock speed
 Multicore Performance and Tools Part 1: Topology, affinity, clock speed Tools for Node-level Performance Engineering Gather Node Information hwloc, likwid-topology, likwid-powermeter Affinity control and
Multicore Performance and Tools Part 1: Topology, affinity, clock speed Tools for Node-level Performance Engineering Gather Node Information hwloc, likwid-topology, likwid-powermeter Affinity control and
Hybrid Computing. Lars Koesterke. University of Porto, Portugal May 28-29, 2009
 Hybrid Computing Lars Koesterke University of Porto, Portugal May 28-29, 29 Why Hybrid? Eliminates domain decomposition at node Automatic coherency at node Lower memory latency and data movement within
Hybrid Computing Lars Koesterke University of Porto, Portugal May 28-29, 29 Why Hybrid? Eliminates domain decomposition at node Automatic coherency at node Lower memory latency and data movement within
Shared Memory programming paradigm: openmp
 IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
Advanced MPI Programming
 Advanced MPI Programming Latestslidesandcodeexamplesareavailableat www.mcs.anl.gov/~thakur/sc13-mpi-tutorial Pavan%Balaji% Argonne'Na*onal'Laboratory' Email:'balaji@mcs.anl.gov' Web:'www.mcs.anl.gov/~balaji'
Advanced MPI Programming Latestslidesandcodeexamplesareavailableat www.mcs.anl.gov/~thakur/sc13-mpi-tutorial Pavan%Balaji% Argonne'Na*onal'Laboratory' Email:'balaji@mcs.anl.gov' Web:'www.mcs.anl.gov/~balaji'
Performance Considerations: Hardware Architecture
 Performance Considerations: Hardware Architecture John Zollweg Parallel Optimization and Scientific Visualization for Ranger March 13, 29 based on material developed by Kent Milfeld, TACC www.cac.cornell.edu
Performance Considerations: Hardware Architecture John Zollweg Parallel Optimization and Scientific Visualization for Ranger March 13, 29 based on material developed by Kent Milfeld, TACC www.cac.cornell.edu
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Introduction to MPI+OpenMP hybrid programming. Fabio Affinito SuperComputing Applications and Innovation Department
 Introduction to MPI+OpenMP hybrid programming Fabio Affinito f.affinito@cineca.it SuperComputing Applications and Innovation Department Architectural trend Architectural trend Architectural trend In a
Introduction to MPI+OpenMP hybrid programming Fabio Affinito f.affinito@cineca.it SuperComputing Applications and Innovation Department Architectural trend Architectural trend Architectural trend In a
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Issues in Developing a Thread-Safe MPI Implementation. William Gropp Rajeev Thakur Mathematics and Computer Science Division
 Issues in Developing a Thread-Safe MPI Implementation William Gropp Rajeev Thakur Mathematics and Computer Science Division MPI and Threads MPI describes parallelism between processes MPI-1 (the specification)
Issues in Developing a Thread-Safe MPI Implementation William Gropp Rajeev Thakur Mathematics and Computer Science Division MPI and Threads MPI describes parallelism between processes MPI-1 (the specification)
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing
 Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
A short overview of parallel paradigms. Fabio Affinito, SCAI
 A short overview of parallel paradigms Fabio Affinito, SCAI Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase
A short overview of parallel paradigms Fabio Affinito, SCAI Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase
Practical Introduction to
 1 2 Outline of the workshop Practical Introduction to What is ScaleMP? When do we need it? How do we run codes on the ScaleMP node on the ScaleMP Guillimin cluster? How to run programs efficiently on ScaleMP?
1 2 Outline of the workshop Practical Introduction to What is ScaleMP? When do we need it? How do we run codes on the ScaleMP node on the ScaleMP Guillimin cluster? How to run programs efficiently on ScaleMP?
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Message Passing with MPI
 Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Lecture 14: Mixed MPI-OpenMP programming. Lecture 14: Mixed MPI-OpenMP programming p. 1
 Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Lecture 14: Mixed MPI-OpenMP programming Lecture 14: Mixed MPI-OpenMP programming p. 1 Overview Motivations for mixed MPI-OpenMP programming Advantages and disadvantages The example of the Jacobi method
Parallel Programming
 Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
New Programming Paradigms: Partitioned Global Address Space Languages
 Raul E. Silvera -- IBM Canada Lab rauls@ca.ibm.com ECMWF Briefing - April 2010 New Programming Paradigms: Partitioned Global Address Space Languages 2009 IBM Corporation Outline Overview of the PGAS programming
Raul E. Silvera -- IBM Canada Lab rauls@ca.ibm.com ECMWF Briefing - April 2010 New Programming Paradigms: Partitioned Global Address Space Languages 2009 IBM Corporation Outline Overview of the PGAS programming
Using MPI+OpenMP for current and future architectures
 Using MPI+OpenMP for current and future architectures September 24th, 2018 OpenMPCon 2018 Oscar Hernandez Yun (Helen) He Barbara Chapman DOE s Office of Science Computation User Facilities DOE is leader
Using MPI+OpenMP for current and future architectures September 24th, 2018 OpenMPCon 2018 Oscar Hernandez Yun (Helen) He Barbara Chapman DOE s Office of Science Computation User Facilities DOE is leader
OpenMP Algoritmi e Calcolo Parallelo. Daniele Loiacono
 OpenMP Algoritmi e Calcolo Parallelo References Useful references Using OpenMP: Portable Shared Memory Parallel Programming, Barbara Chapman, Gabriele Jost and Ruud van der Pas OpenMP.org http://openmp.org/
OpenMP Algoritmi e Calcolo Parallelo References Useful references Using OpenMP: Portable Shared Memory Parallel Programming, Barbara Chapman, Gabriele Jost and Ruud van der Pas OpenMP.org http://openmp.org/
CMSC 714 Lecture 4 OpenMP and UPC. Chau-Wen Tseng (from A. Sussman)
") CMSC 714 Lecture 4 OpenMP and UPC Chau-Wen Tseng (from A. Sussman) Programming Model Overview Message passing (MPI, PVM) Separate address spaces Explicit messages to access shared data Send / receive (MPI
CMSC 714 Lecture 4 OpenMP and UPC Chau-Wen Tseng (from A. Sussman) Programming Model Overview Message passing (MPI, PVM) Separate address spaces Explicit messages to access shared data Send / receive (MPI
OpenMP 4.0/4.5. Mark Bull, EPCC
 OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Introduction to OpenMP
 Introduction to OpenMP Lecture 9: Performance tuning Sources of overhead There are 6 main causes of poor performance in shared memory parallel programs: sequential code communication load imbalance synchronisation
Introduction to OpenMP Lecture 9: Performance tuning Sources of overhead There are 6 main causes of poor performance in shared memory parallel programs: sequential code communication load imbalance synchronisation
NUMA-aware OpenMP Programming
 NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
A Lightweight OpenMP Runtime
 Alexandre Eichenberger - Kevin O Brien 6/26/ A Lightweight OpenMP Runtime -- OpenMP for Exascale Architectures -- T.J. Watson, IBM Research Goals Thread-rich computing environments are becoming more prevalent
Alexandre Eichenberger - Kevin O Brien 6/26/ A Lightweight OpenMP Runtime -- OpenMP for Exascale Architectures -- T.J. Watson, IBM Research Goals Thread-rich computing environments are becoming more prevalent
Best Practice Guide for Writing MPI + OmpSs Interoperable Programs. Version 1.0, 3 rd April 2017
 Best Practice Guide for Writing MPI + OmpSs Interoperable Programs Version 1.0, 3 rd April 2017 Copyright INTERTWinE Consortium 2017 Table of Contents 1 INTRODUCTION... 1 1.1 PURPOSE... 1 1.2 GLOSSARY
Best Practice Guide for Writing MPI + OmpSs Interoperable Programs Version 1.0, 3 rd April 2017 Copyright INTERTWinE Consortium 2017 Table of Contents 1 INTRODUCTION... 1 1.1 PURPOSE... 1 1.2 GLOSSARY
Topics. Introduction. Shared Memory Parallelization. Example. Lecture 11. OpenMP Execution Model Fork-Join model 5/15/2012. Introduction OpenMP
 Topics Lecture 11 Introduction OpenMP Some Examples Library functions Environment variables 1 2 Introduction Shared Memory Parallelization OpenMP is: a standard for parallel programming in C, C++, and
Topics Lecture 11 Introduction OpenMP Some Examples Library functions Environment variables 1 2 Introduction Shared Memory Parallelization OpenMP is: a standard for parallel programming in C, C++, and
Parallel Programming. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007
 HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
COMP528: Multi-core and Multi-Processor Computing
 COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
Hybrid Programming: MPI+OpenMP. Piero Lanucara SuperComputing Applications and Innovation Department
 Hybrid Programming: MPI+OpenMP Piero Lanucara p.lanucara@cineca.it SuperComputing Applications and Innovation Department Architectural Trend Top 500 historical view: clusters (and MPP) dominates HPC arena
Hybrid Programming: MPI+OpenMP Piero Lanucara p.lanucara@cineca.it SuperComputing Applications and Innovation Department Architectural Trend Top 500 historical view: clusters (and MPP) dominates HPC arena
Code Parallelization
 Code Parallelization a guided walk-through m.cestari@cineca.it f.salvadore@cineca.it Summer School ed. 2015 Code Parallelization two stages to write a parallel code problem domain algorithm program domain
Code Parallelization a guided walk-through m.cestari@cineca.it f.salvadore@cineca.it Summer School ed. 2015 Code Parallelization two stages to write a parallel code problem domain algorithm program domain
Getting Performance from OpenMP Programs on NUMA Architectures
 Getting Performance from OpenMP Programs on NUMA Architectures Christian Terboven, RWTH Aachen University terboven@itc.rwth-aachen.de EU H2020 Centre of Excellence (CoE) 1 October 2015 31 March 2018 Grant
Getting Performance from OpenMP Programs on NUMA Architectures Christian Terboven, RWTH Aachen University terboven@itc.rwth-aachen.de EU H2020 Centre of Excellence (CoE) 1 October 2015 31 March 2018 Grant
Issues in Developing a Thread-Safe MPI Implementation. William Gropp Rajeev Thakur
 Issues in Developing a Thread-Safe MPI Implementation William Gropp Rajeev Thakur Why MPI and Threads Applications need more computing power than any one processor can provide Parallel computing (proof
Issues in Developing a Thread-Safe MPI Implementation William Gropp Rajeev Thakur Why MPI and Threads Applications need more computing power than any one processor can provide Parallel computing (proof
Lecture V: Introduction to parallel programming with Fortran coarrays
 Lecture V: Introduction to parallel programming with Fortran coarrays What is parallel computing? Serial computing Single processing unit (core) is used for solving a problem One task processed at a time
Lecture V: Introduction to parallel programming with Fortran coarrays What is parallel computing? Serial computing Single processing unit (core) is used for solving a problem One task processed at a time
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
MPI 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Advanced Job Launching. mapping applications to hardware
 Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
OpenMP 4.0. Mark Bull, EPCC
 OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
Hybrid programming with MPI and OpenMP On the way to exascale
 Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Institut du Développement et des Ressources en Informatique Scientifique www.idris.fr Hybrid programming with MPI and OpenMP On the way to exascale 1 Trends of hardware evolution Main problematic : how
Implementation of Parallelization
 Implementation of Parallelization OpenMP, PThreads and MPI Jascha Schewtschenko Institute of Cosmology and Gravitation, University of Portsmouth May 9, 2018 JAS (ICG, Portsmouth) Implementation of Parallelization
Implementation of Parallelization OpenMP, PThreads and MPI Jascha Schewtschenko Institute of Cosmology and Gravitation, University of Portsmouth May 9, 2018 JAS (ICG, Portsmouth) Implementation of Parallelization
OpenMP Programming. Prof. Thomas Sterling. High Performance Computing: Concepts, Methods & Means
 High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
Parallel Computing. Lecture 17: OpenMP Last Touch
 CSCI-UA.0480-003 Parallel Computing Lecture 17: OpenMP Last Touch Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Some slides from here are adopted from: Yun (Helen) He and Chris Ding
CSCI-UA.0480-003 Parallel Computing Lecture 17: OpenMP Last Touch Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Some slides from here are adopted from: Yun (Helen) He and Chris Ding
Elementary Parallel Programming with Examples. Reinhold Bader (LRZ) Georg Hager (RRZE)
 Georg Hager (RRZE)") Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
No Time to Read This Book?
 Chapter 1 No Time to Read This Book? We know what it feels like to be under pressure. Try out a few quick and proven optimization stunts described below. They may provide a good enough performance gain
Chapter 1 No Time to Read This Book? We know what it feels like to be under pressure. Try out a few quick and proven optimization stunts described below. They may provide a good enough performance gain
Intel Parallel Studio XE Cluster Edition - Intel MPI - Intel Traceanalyzer & Collector
 Intel Parallel Studio XE Cluster Edition - Intel MPI - Intel Traceanalyzer & Collector A brief Introduction to MPI 2 What is MPI? Message Passing Interface Explicit parallel model All parallelism is explicit:
Intel Parallel Studio XE Cluster Edition - Intel MPI - Intel Traceanalyzer & Collector A brief Introduction to MPI 2 What is MPI? Message Passing Interface Explicit parallel model All parallelism is explicit:
30 Nov Dec Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy
 Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Introduction to PICO Parallel & Production Enviroment
 Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
EE/CSCI 451 Introduction to Parallel and Distributed Computation. Discussion #4 2/3/2017 University of Southern California
 EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
Introduction to MPI. Ekpe Okorafor. School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014
 Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Chip Multiprocessors COMP Lecture 9 - OpenMP & MPI
 Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Holland Computing Center Kickstart MPI Intro
 Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing
 TMA4280 Introduction to Supercomputing") The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
Introduction to OpenMP
 Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Cluster Computing. Performance and Debugging Issues in OpenMP. Topics. Factors impacting performance. Scalable Speedup
 Topics Scalable Speedup and Data Locality Parallelizing Sequential Programs Breaking data dependencies Avoiding synchronization overheads Performance and Debugging Issues in OpenMP Achieving Cache and
Topics Scalable Speedup and Data Locality Parallelizing Sequential Programs Breaking data dependencies Avoiding synchronization overheads Performance and Debugging Issues in OpenMP Achieving Cache and
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Review of previous examinations TMA4280 Introduction to Supercomputing
 Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Introduction to OpenMP
 Introduction to OpenMP Le Yan HPC Consultant User Services Goals Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Discuss briefly the
Introduction to OpenMP Le Yan HPC Consultant User Services Goals Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Discuss briefly the
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
PRACE Autumn School Basic Programming Models
 PRACE Autumn School 2010 Basic Programming Models Basic Programming Models - Outline Introduction Key concepts Architectures Programming models Programming languages Compilers Operating system & libraries
PRACE Autumn School 2010 Basic Programming Models Basic Programming Models - Outline Introduction Key concepts Architectures Programming models Programming languages Compilers Operating system & libraries
Advanced Message-Passing Interface (MPI)
") Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Introduction to Standard OpenMP 3.1
 Introduction to Standard OpenMP 3.1 Massimiliano Culpo - m.culpo@cineca.it Gian Franco Marras - g.marras@cineca.it CINECA - SuperComputing Applications and Innovation Department 1 / 59 Outline 1 Introduction
Introduction to Standard OpenMP 3.1 Massimiliano Culpo - m.culpo@cineca.it Gian Franco Marras - g.marras@cineca.it CINECA - SuperComputing Applications and Innovation Department 1 / 59 Outline 1 Introduction
OpenMP 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 OpenMP 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
OpenMP 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Parallel Programming
 Parallel Programming OpenMP Dr. Hyrum D. Carroll November 22, 2016 Parallel Programming in a Nutshell Load balancing vs Communication This is the eternal problem in parallel computing. The basic approaches
Parallel Programming OpenMP Dr. Hyrum D. Carroll November 22, 2016 Parallel Programming in a Nutshell Load balancing vs Communication This is the eternal problem in parallel computing. The basic approaches
COSC 6374 Parallel Computation. Introduction to OpenMP(I) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel)
 Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel)") COSC 6374 Parallel Computation Introduction to OpenMP(I) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2014 Introduction Threads vs. processes Recap of
COSC 6374 Parallel Computation Introduction to OpenMP(I) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2014 Introduction Threads vs. processes Recap of
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
CS 5220: Shared memory programming. David Bindel
 CS 5220: Shared memory programming David Bindel 2017-09-26 1 Message passing pain Common message passing pattern Logical global structure Local representation per processor Local data may have redundancy
CS 5220: Shared memory programming David Bindel 2017-09-26 1 Message passing pain Common message passing pattern Logical global structure Local representation per processor Local data may have redundancy
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Introduction to OpenMP
 1 Introduction to OpenMP NTNU-IT HPC Section John Floan Notur: NTNU HPC http://www.notur.no/ www.hpc.ntnu.no/ Name, title of the presentation 2 Plan for the day Introduction to OpenMP and parallel programming
1 Introduction to OpenMP NTNU-IT HPC Section John Floan Notur: NTNU HPC http://www.notur.no/ www.hpc.ntnu.no/ Name, title of the presentation 2 Plan for the day Introduction to OpenMP and parallel programming
ECE 574 Cluster Computing Lecture 10
 ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
Introduction to parallel computing concepts and technics
 Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Introduction to OpenMP
 1.1 Minimal SPMD Introduction to OpenMP Simple SPMD etc. N.M. Maclaren Computing Service nmm1@cam.ac.uk ext. 34761 August 2011 SPMD proper is a superset of SIMD, and we are now going to cover some of the
1.1 Minimal SPMD Introduction to OpenMP Simple SPMD etc. N.M. Maclaren Computing Service nmm1@cam.ac.uk ext. 34761 August 2011 SPMD proper is a superset of SIMD, and we are now going to cover some of the
Allows program to be incrementally parallelized
 Basic OpenMP What is OpenMP An open standard for shared memory programming in C/C+ + and Fortran supported by Intel, Gnu, Microsoft, Apple, IBM, HP and others Compiler directives and library support OpenMP
Basic OpenMP What is OpenMP An open standard for shared memory programming in C/C+ + and Fortran supported by Intel, Gnu, Microsoft, Apple, IBM, HP and others Compiler directives and library support OpenMP
Symmetric Computing. ISC 2015 July John Cazes Texas Advanced Computing Center
 Symmetric Computing ISC 2015 July 2015 John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required:
Symmetric Computing ISC 2015 July 2015 John Cazes Texas Advanced Computing Center Symmetric Computing Run MPI tasks on both MIC and host Also called heterogeneous computing Two executables are required:
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Parallel Programming with OpenMP. CS240A, T. Yang
 Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
OpenMP 4. CSCI 4850/5850 High-Performance Computing Spring 2018
 OpenMP 4 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
OpenMP 4 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Parallel Processing Top manufacturer of multiprocessing video & imaging solutions.
 1 of 10 3/3/2005 10:51 AM Linux Magazine March 2004 C++ Parallel Increase application performance without changing your source code. Parallel Processing Top manufacturer of multiprocessing video & imaging
1 of 10 3/3/2005 10:51 AM Linux Magazine March 2004 C++ Parallel Increase application performance without changing your source code. Parallel Processing Top manufacturer of multiprocessing video & imaging
Introduction to Parallel Programming
 Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
Introduction to Parallel Programming Linda Woodard CAC 19 May 2010 Introduction to Parallel Computing on Ranger 5/18/2010 www.cac.cornell.edu 1 y What is Parallel Programming? Using more than one processor
CINES MPI. Johanne Charpentier & Gabriel Hautreux
 Training @ CINES MPI Johanne Charpentier & Gabriel Hautreux charpentier@cines.fr hautreux@cines.fr Clusters Architecture OpenMP MPI Hybrid MPI+OpenMP MPI Message Passing Interface 1. Introduction 2. MPI
Training @ CINES MPI Johanne Charpentier & Gabriel Hautreux charpentier@cines.fr hautreux@cines.fr Clusters Architecture OpenMP MPI Hybrid MPI+OpenMP MPI Message Passing Interface 1. Introduction 2. MPI