Towards Intelligent Programing Systems for Modern Computing
|
|
|
- Magdalene Parks
- 5 years ago
- Views:
Transcription


1 Towards Intelligent Programing Systems for Modern Computing Xipeng Shen Computer Science, North Carolina State University

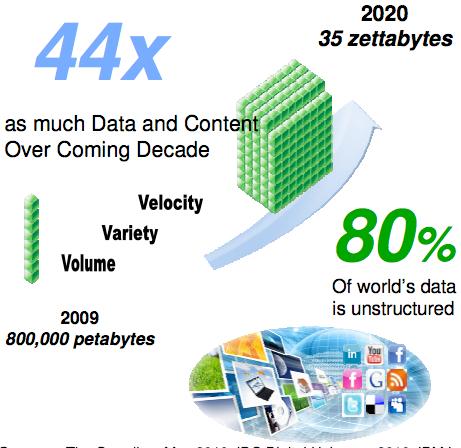



2 Unprecedented Scale 50X perf Y202X 1000 petaflops 20mw power 2X power! Y petaflops 10mw power sources: SciDAC, IBM 2




3 Heterogeneity becomes Norm Massively parallel accelerators are becoming ubiquitous. 3
4 Thesis To address the challenges in modern computing, one of the keys exists in making programming systems more intelligent. For advancing programming systems, right problem formulating goes a long way. 4
5 Modern Computing Application Data analytics, Machine learning, TOP Algorithmic optimizer for data analytics [VLDB 15,ICML 15] Infrastructure Data centers, Cloud, IoT, Architecture Heterogeneous parallel processors, Emerging complex memory, GStreamline+ PORPLE Memory optimization for GPU [ASPLOS 11, Micro 14, ICS 16] 5

6 Yufei Ding TOP: Enabling Algorithmic Optimizations for Distance-Related Problems Up to 100s X speedups. VLDB 2015, ICML
7 Learning Problem Role of Compiler ML Algorithm ML experts Implementation compiler co- design Execution Runtime system/architecture Can compilers optimize algorithms? 7
8 Why algorithm level? Reason 1: Large benefits: orders of magnitude speedups at no extra cost. Reason 2: Compiler may outsmart ML experts. Really? 8
9 Example K- Means Triangular Inequality: a- b d a+b d b X a C 2 C 1 9

10 K-Means NIPS 2012 SIAM 2010 ICML



11 K-NN SSDM 10 VisionInterface 10 IJCNN 11 11

12 P2P: Point-to-Point Shortest Path SIAM 05 ALENEX 04 12
13 Observations TI has led to many enhanced algorithms across problems and domains. Applying TI well is tricky, hence the many manual efforts and publications. Thoughts Can we have an abstraction to represent all the problems? Can we then generalize the TI optimizations into compiler- based transformations? 13
14 Abstract Distance Problem (Q, T, D, R, C) Constraints Relation Query Point Set Distance Target Point Set KNN KNN join ICP NBody KMeans Shortest Distance 14
15 Abstract Distance- Related Problem Essence & 7 Principles of TI Optimizations Our Analysis and Abstraction KNN KNN join ICP NBody KMeans Shortest Distance 15
16 Key Insights See VLDB 15 for details. Reuse through Landmarks Spatial & temporal reuses Elasticity through hierarchical landmarks Efficient bounds update through ghosts for iterative alg. Order of comparison q2 L q1 t1 q3 t2 t3 16

17 TOP Framework problem semantic TOP API Compiler building blocks Opt Lib Abstract Distance- Related Problem Essence & 7 Principles of TI Optimizations KNN KNN join ICP NBody KMeans Shortest Distance 17
; T = init(); changedflag = 1; while (changedflag){ N = TOP_findClosestTargets(1, S, T); TOP_update(T,")
18 Usage Systematic TOP API Basic algorithm description Compiler Ad hoc Staged program code TI Opt Lib Efficient execution TOP_defDistance(Euclidean); T = init(); changedflag = 1; while (changedflag){ N = TOP_findClosestTargets(1, S, T); TOP_update(T, &changedflag, N, S); } 18
19 K- Means (K=1024) Clustering results are same as original method s. Baseline: Classic K- means (16GB, 8- core Intel Ivy Bridge) Speedup (X) TOP Yinyang K-Means Code link in ICML 15 paper. 19
20 On K- Means Baseline: Classic K- means (16GB, 8- core) Speedup (X) TOP Yinyang K-Means XX 20
21 On All Benchmarks Speedups # distance calculations Speedups(X) by TOP version TOP Optimized Speedups(X) by manual version Manually Optimized TOP In TOP Optimized version Knn Knnjoin Kmeans ICP Nbody P2P Reference line Insight: 10 6 Knn The right abstraction Knnjoin and formulation turn a Kmeans ICP compiler into an automatic algorithm optimizer, Nbody P2P Reference line giving out large speedups In manual version Manually Optimized Average speedups: 50X vs 20X. Save at least 93% calculations. Intel i CPU and 8G memory 21
22 Modern Computing Application Data analytics, Machine learning, Infrastructure Data centers, Cloud, IoT, Architecture Heterogeneous parallel processors, Emerging complex memory, TOP Algorithmic optimizer for data analytics [VLDB 15,ICML 15] GStreamline+ PORPLE Memory optimization for GPU [ASPLOS 11, Micro 14, ICS 16] 22
 Bo")
")
 Overcome")
23 Zheng Zhang Rutgers Univ) Bo Wu Colorado Mines) Guoyang Chen (Qualcomm) Overcome GPU Limitations 23

")



24 Graphic Processing Unit (GPU) a SIMD group (warp) Massive parallelism Favorable computing power cost effectiveness energy efficiency Xipeng Shen xshen5@ncsu.edu 24
25 Challenges Scheduling Limitations Irregular Mem & Control Dyn Task Parallelism 25
26 Our Explorations Compiler-based software solutions 11/06 9/07 5/09 6/10 3/11 6/12 9/13 10/11 2/13 5/15 12/15 2/17 12/14 6/15 6/16 5/17 CUDA release LCPC talk by David Kirk IPDPS cross input adap. opt. ICS remove thread diverg. dyn. PACT treat synch. correct. GPU2CPU PPOPP mem coalesc. PACT NVM for GPU Micro PORPLE ICS SM centric ICS Multiview IPDPS Co- sched on Fused System Sweet KNN; VersaPipe; Lean DNN; ASPLOS GStreamline ICS syn. relax. & opt. GPU2CPU HotOS Co- run on Fused Micro Free Launch PPOPP EffiSha 26
27 Solutions Scheduling Limitations Irregular Mem & Control Dyn Task Parallelism SM- Centric & EffiSha [ics15,ppopp17] GStreamline & PORPLE [asplos11,micro14, ics16] FreeLaunch [micro15] Compiler-based software solutions Monday PPoPP Session 1 27
28 Dynamic Irregularities memory control flow (thread divergence) P[ ] = { 0, 5, 1, 1, 2, 7, 3, 4, 3, 5, 6, 2} 7} tid: tid: if (A[tid]) {...}... = A[P[tid]]; A[ ]: A[ ]: { a mem seg. for (i=0;i<a[tid]; i++) {...} Degrade throughput by up to (warp size - 1) times. (warp size = 32 in modern GPUs) Xipeng Shen xshen5@ncsu.edu 28
29 Solution 1: Thread-Data Remapping 4 trans/warp Irregularity in a warp: problematic; across warps: okey! { a mem seg. Principle of solution: Turn intra-warp irreg. into reg. or inter-warp irreg. 1 trans/warp { a mem seg. 29
30 Trans-1: Data Reordering original tid: = A[P[tid]]; P[ ] = {0,5,2,3,2,3,7,6} A[ ]: <redirection> <relocation> maintain mapping between threads & data values transformed... = A [Q[tid]]; A [ ]: Q[ ] = {0,1,2,3,2,3,6,7} tid: tid: thread ID; : a thread; : data access; : data relocation 30
31 Trans-2: Job Swapping Job = operations + data elements accessed original... = A[P[tid]]; A[ ]: P[ ] = {0,5,2,3,2,3,7,6} <redirection> tid: transformed newtid = Q[tid]; = A[P[newtid]]; Q[ ] = {0,4,2,3,1,5,6,7} tid: A[ ]: 31
![G-Streamline [ASPLOS 2011] First framework enabling runtime thread-data remapping.](/docs-images/96/129022976/images/32-0.jpg "CPU-GPU pipeline to hide transformation overhead. Kernel splitting to resolve dependences. 1.08 2.")
32 G-Streamline [ASPLOS 2011] First framework enabling runtime thread-data remapping. CPU-GPU pipeline to hide transformation overhead. Kernel splitting to resolve dependences X speedups 32

33 Solution 2: Data Placement Global memory Texture memory Shared memory Constant memory L1/L2 cache Read-only cache Texture cache Xipeng Shen 33
34 GPU Memory Global memory Texture memory Shared memory Constant memory L1/L2 cache Read-only cache Texture cache coalescing; cache hierarchy 2D/3D locality; texture cache; read-only on-chip; bank conflicts broadcasting; cached; read-only private/shared read-only data 2D/3D locality; read-only Xipeng Shen 34
 (Texture cache)????? A B C D Data in a program 3X performance difference Xipeng Shen xshen5@ncsu.")
35 Data Placement Problem Global memory Texture memory Shared memory Constant memory (L1/L2 cache) (Read-only cache) (Texture cache)????? A B C D Data in a program 3X performance difference Xipeng Shen xshen5@ncsu.edu 35
36 Data Placement Problem Properties: Machine dependent Changes across models/generations Input dependent Changes across runs Options: Manual efforts by programmers? Offline autotuning? Xipeng Shen 36
37 PORPLE in a Whole offline online architect/user microkernels org. program MSL (mem. spec. lang.) PORPLE-C (compiler) mem spec access patterns staged program PLACER (placing engine) online profile input desired placement efficient execution More details in our Micro 2014 paper. Xipeng Shen xshen5@ncsu.edu 37
38 Properties of PORPLE Good portability to new memory Just need new MSL spec Program adapts automatically Adaptivity to new program inputs On-the-fly placement with placement-agnostic code. Generality to regular & irregular programs Static analysis + lightweight online profiling Xipeng Shen xshen5@ncsu.edu 38



39 GPU Models K20c M2075 C1060



40 Potential for Future Memory Systems 3D Stacked Memory Persistent Memory DRAM (NUMA) Xipeng Shen 40


41 Final Takeaways Large potential of compilers for modern computing Right problem formulation is a key TOP An algorithmic optimizer. Up to 100x speedups. GStreamline PORPLE Portable solution to mem. complexity. Consistent speedups cross GPUs.
On-the-Fly Elimination of Dynamic Irregularities for GPU Computing
 On-the-Fly Elimination of Dynamic Irregularities for GPU Computing Eddy Z. Zhang, Yunlian Jiang, Ziyu Guo, Kai Tian, and Xipeng Shen Graphic Processing Units (GPU) 2 Graphic Processing Units (GPU) 2 Graphic
On-the-Fly Elimination of Dynamic Irregularities for GPU Computing Eddy Z. Zhang, Yunlian Jiang, Ziyu Guo, Kai Tian, and Xipeng Shen Graphic Processing Units (GPU) 2 Graphic Processing Units (GPU) 2 Graphic
Coherence-Free Multiview: Enabling Reference-Discerning Data Placement on GPU
 Coherence-Free Multiview: Enabling Reference-Discerning Data Placement on GPU Guoyang Chen, Xipeng Shen Computer Science Department, North Carolina State University 890 Oval Drive, Raleigh, NC, USA, 27695
Coherence-Free Multiview: Enabling Reference-Discerning Data Placement on GPU Guoyang Chen, Xipeng Shen Computer Science Department, North Carolina State University 890 Oval Drive, Raleigh, NC, USA, 27695
High-level Program Optimization for Data Analytics
 High-level Program Optimization for Data Analytics Yufei Ding North Carolina State University 1 Motivation: Faster Data Analytics Source: oracle, 2012 Source: SAS, 2013 2 Role of My Research Compiler Technology
High-level Program Optimization for Data Analytics Yufei Ding North Carolina State University 1 Motivation: Faster Data Analytics Source: oracle, 2012 Source: SAS, 2013 2 Role of My Research Compiler Technology
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
PORPLE: An Extensible Optimizer for Portable Data Placement on GPU
 PORPLE: An Extensible Optimizer for Portable Data Placement on GPU Guoyang Chen Department of Computer Science North Carolina State University Raleigh, NC, USA Email: gchen11@ncsu.edu Dong Li Oak Ridge
PORPLE: An Extensible Optimizer for Portable Data Placement on GPU Guoyang Chen Department of Computer Science North Carolina State University Raleigh, NC, USA Email: gchen11@ncsu.edu Dong Li Oak Ridge
LDetector: A low overhead data race detector for GPU programs
 LDetector: A low overhead data race detector for GPU programs 1 PENGCHENG LI CHEN DING XIAOYU HU TOLGA SOYATA UNIVERSITY OF ROCHESTER 1 Data races in GPU Introduction & Contribution Impact correctness
LDetector: A low overhead data race detector for GPU programs 1 PENGCHENG LI CHEN DING XIAOYU HU TOLGA SOYATA UNIVERSITY OF ROCHESTER 1 Data races in GPU Introduction & Contribution Impact correctness
Execution Strategy and Runtime Support for Regular and Irregular Applications on Emerging Parallel Architectures
 Execution Strategy and Runtime Support for Regular and Irregular Applications on Emerging Parallel Architectures Xin Huo Advisor: Gagan Agrawal Motivation - Architecture Challenges on GPU architecture
Execution Strategy and Runtime Support for Regular and Irregular Applications on Emerging Parallel Architectures Xin Huo Advisor: Gagan Agrawal Motivation - Architecture Challenges on GPU architecture
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
TOP: A Framework for Enabling Algorithmic Optimizations for Distance-Related Problems
 TOP: A Framework for Enabling Algorithmic Optimizations for Distance-Related Problems Yufei Ding, Xipeng Shen North Carolina State University {yding8,xshen5}@ncsu.edu Madanlal Musuvathi, Todd Mytkowicz
TOP: A Framework for Enabling Algorithmic Optimizations for Distance-Related Problems Yufei Ding, Xipeng Shen North Carolina State University {yding8,xshen5}@ncsu.edu Madanlal Musuvathi, Todd Mytkowicz
CS 314 Principles of Programming Languages
 CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Locality-Aware Software Throttling for Sparse Matrix Operation on GPUs
 Locality-Aware Software Throttling for Sparse Matrix Operation on GPUs Yanhao Chen 1, Ari B. Hayes 1, Chi Zhang 2, Timothy Salmon 1, Eddy Z. Zhang 1 1. Rutgers University 2. University of Pittsburgh Sparse
Locality-Aware Software Throttling for Sparse Matrix Operation on GPUs Yanhao Chen 1, Ari B. Hayes 1, Chi Zhang 2, Timothy Salmon 1, Eddy Z. Zhang 1 1. Rutgers University 2. University of Pittsburgh Sparse
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Practical Near-Data Processing for In-Memory Analytics Frameworks
 Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
Practical Near-Data Processing for In-Memory Analytics Frameworks Mingyu Gao, Grant Ayers, Christos Kozyrakis Stanford University http://mast.stanford.edu PACT Oct 19, 2015 Motivating Trends End of Dennard
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Parallelizing FPGA Technology Mapping using GPUs. Doris Chen Deshanand Singh Aug 31 st, 2010
 Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
Red Fox: An Execution Environment for Relational Query Processing on GPUs
 Red Fox: An Execution Environment for Relational Query Processing on GPUs Georgia Institute of Technology: Haicheng Wu, Ifrah Saeed, Sudhakar Yalamanchili LogicBlox Inc.: Daniel Zinn, Martin Bravenboer,
Red Fox: An Execution Environment for Relational Query Processing on GPUs Georgia Institute of Technology: Haicheng Wu, Ifrah Saeed, Sudhakar Yalamanchili LogicBlox Inc.: Daniel Zinn, Martin Bravenboer,
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC
 GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Cache Capacity Aware Thread Scheduling for Irregular Memory Access on Many-Core GPGPUs
 Cache Capacity Aware Thread Scheduling for Irregular Memory Access on Many-Core GPGPUs Hsien-Kai Kuo, Ta-Kan Yen, Bo-Cheng Charles Lai and Jing-Yang Jou Department of Electronics Engineering National Chiao
Cache Capacity Aware Thread Scheduling for Irregular Memory Access on Many-Core GPGPUs Hsien-Kai Kuo, Ta-Kan Yen, Bo-Cheng Charles Lai and Jing-Yang Jou Department of Electronics Engineering National Chiao
A Cross-Input Adaptive Framework for GPU Program Optimizations
 A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
A Cross-Input Adaptive Framework for GPU Program Optimizations Yixun Liu, Eddy Z. Zhang, Xipeng Shen Computer Science Department The College of William & Mary Outline GPU overview G-Adapt Framework Evaluation
Lecture 3: CUDA Programming & Compiler Front End
 CS 515 Programming Language and Compilers I Lecture 3: CUDA Programming & Compiler Front End Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/19/2017 1 Lecture 3A: GPU Programming 2 3 Review: Performance
CS 515 Programming Language and Compilers I Lecture 3: CUDA Programming & Compiler Front End Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/19/2017 1 Lecture 3A: GPU Programming 2 3 Review: Performance
Red Fox: An Execution Environment for Relational Query Processing on GPUs
 Red Fox: An Execution Environment for Relational Query Processing on GPUs Haicheng Wu 1, Gregory Diamos 2, Tim Sheard 3, Molham Aref 4, Sean Baxter 2, Michael Garland 2, Sudhakar Yalamanchili 1 1. Georgia
Red Fox: An Execution Environment for Relational Query Processing on GPUs Haicheng Wu 1, Gregory Diamos 2, Tim Sheard 3, Molham Aref 4, Sean Baxter 2, Michael Garland 2, Sudhakar Yalamanchili 1 1. Georgia
Rethinking Compilers in the Rise of Machine Learning and AI
 Rethinking Compilers in the Rise of Machine Learning and AI Xipeng Shen Computer Science, North Carolina State University The journey of a snowflake Born of a raindrop, laced by the breeze, a snowflake
Rethinking Compilers in the Rise of Machine Learning and AI Xipeng Shen Computer Science, North Carolina State University The journey of a snowflake Born of a raindrop, laced by the breeze, a snowflake
Object Support in an Array-based GPGPU Extension for Ruby
 Object Support in an Array-based GPGPU Extension for Ruby ARRAY 16 Matthias Springer, Hidehiko Masuhara Dept. of Mathematical and Computing Sciences, Tokyo Institute of Technology June 14, 2016 Object
Object Support in an Array-based GPGPU Extension for Ruby ARRAY 16 Matthias Springer, Hidehiko Masuhara Dept. of Mathematical and Computing Sciences, Tokyo Institute of Technology June 14, 2016 Object
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
An Execution Strategy and Optimized Runtime Support for Parallelizing Irregular Reductions on Modern GPUs
 An Execution Strategy and Optimized Runtime Support for Parallelizing Irregular Reductions on Modern GPUs Xin Huo, Vignesh T. Ravi, Wenjing Ma and Gagan Agrawal Department of Computer Science and Engineering
An Execution Strategy and Optimized Runtime Support for Parallelizing Irregular Reductions on Modern GPUs Xin Huo, Vignesh T. Ravi, Wenjing Ma and Gagan Agrawal Department of Computer Science and Engineering
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
AFOSR BRI: Codifying and Applying a Methodology for Manual Co-Design and Developing an Accelerated CFD Library
 AFOSR BRI: Codifying and Applying a Methodology for Manual Co-Design and Developing an Accelerated CFD Library Synergy@VT Collaborators: Paul Sathre, Sriram Chivukula, Kaixi Hou, Tom Scogland, Harold Trease,
AFOSR BRI: Codifying and Applying a Methodology for Manual Co-Design and Developing an Accelerated CFD Library Synergy@VT Collaborators: Paul Sathre, Sriram Chivukula, Kaixi Hou, Tom Scogland, Harold Trease,
gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood
 gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood (powerjg/morr)@cs.wisc.edu UW-Madison Computer Sciences 2012 gem5-gpu gem5 + GPGPU-Sim (v3.0.1) Flexible memory
gem5-gpu Extending gem5 for GPGPUs Jason Power, Marc Orr, Joel Hestness, Mark Hill, David Wood (powerjg/morr)@cs.wisc.edu UW-Madison Computer Sciences 2012 gem5-gpu gem5 + GPGPU-Sim (v3.0.1) Flexible memory
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
From Application to Technology OpenCL Application Processors Chung-Ho Chen
 From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
OpenMP Optimization and its Translation to OpenGL
 OpenMP Optimization and its Translation to OpenGL Santosh Kumar SITRC-Nashik, India Dr. V.M.Wadhai MAE-Pune, India Prasad S.Halgaonkar MITCOE-Pune, India Kiran P.Gaikwad GHRIEC-Pune, India ABSTRACT For
OpenMP Optimization and its Translation to OpenGL Santosh Kumar SITRC-Nashik, India Dr. V.M.Wadhai MAE-Pune, India Prasad S.Halgaonkar MITCOE-Pune, India Kiran P.Gaikwad GHRIEC-Pune, India ABSTRACT For
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
GPU Performance Nuggets
 GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
Performance Insights on Executing Non-Graphics Applications on CUDA on the NVIDIA GeForce 8800 GTX
 Performance Insights on Executing Non-Graphics Applications on CUDA on the NVIDIA GeForce 8800 GTX Wen-mei Hwu with David Kirk, Shane Ryoo, Christopher Rodrigues, John Stratton, Kuangwei Huang Overview
Performance Insights on Executing Non-Graphics Applications on CUDA on the NVIDIA GeForce 8800 GTX Wen-mei Hwu with David Kirk, Shane Ryoo, Christopher Rodrigues, John Stratton, Kuangwei Huang Overview
A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps
 A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps Nandita Vijaykumar Gennady Pekhimenko, Adwait Jog, Abhishek Bhowmick, Rachata Ausavarangnirun,
A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps Nandita Vijaykumar Gennady Pekhimenko, Adwait Jog, Abhishek Bhowmick, Rachata Ausavarangnirun,
LLVM for the future of Supercomputing
 LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
LLVM for the future of Supercomputing Hal Finkel hfinkel@anl.gov 2017-03-27 2017 European LLVM Developers' Meeting What is Supercomputing? Computing for large, tightly-coupled problems. Lots of computational
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION
 April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Accelerating Applications. the art of maximum performance computing James Spooner Maxeler VP of Acceleration
 Accelerating Applications the art of maximum performance computing James Spooner Maxeler VP of Acceleration Introduction The Process The Tools Case Studies Summary What do we mean by acceleration? How
Accelerating Applications the art of maximum performance computing James Spooner Maxeler VP of Acceleration Introduction The Process The Tools Case Studies Summary What do we mean by acceleration? How
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Duksu Kim. Professional Experience Senior researcher, KISTI High performance visualization
 Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Exploiting Inter-Warp Heterogeneity to Improve GPGPU Performance
 Exploiting Inter-Warp Heterogeneity to Improve GPGPU Performance Rachata Ausavarungnirun Saugata Ghose, Onur Kayiran, Gabriel H. Loh Chita Das, Mahmut Kandemir, Onur Mutlu Overview of This Talk Problem:
Exploiting Inter-Warp Heterogeneity to Improve GPGPU Performance Rachata Ausavarungnirun Saugata Ghose, Onur Kayiran, Gabriel H. Loh Chita Das, Mahmut Kandemir, Onur Mutlu Overview of This Talk Problem:
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Generalizations of the Theory and Deployment of Triangular Inequality for Compiler-Based Strength Reduction
 Generalizations of the Theory and Deployment of Triangular Inequality for Compiler-Based Strength Reduction Yufei Ding, Lin Ning, Hui Guan, Xipeng Shen North Carolina State University, United States {yding8,
Generalizations of the Theory and Deployment of Triangular Inequality for Compiler-Based Strength Reduction Yufei Ding, Lin Ning, Hui Guan, Xipeng Shen North Carolina State University, United States {yding8,
Efficient Computation of Radial Distribution Function on GPUs
 Efficient Computation of Radial Distribution Function on GPUs Yi-Cheng Tu * and Anand Kumar Department of Computer Science and Engineering University of South Florida, Tampa, Florida 2 Overview Introduction
Efficient Computation of Radial Distribution Function on GPUs Yi-Cheng Tu * and Anand Kumar Department of Computer Science and Engineering University of South Florida, Tampa, Florida 2 Overview Introduction
Basics of Performance Engineering
 ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
Computer Architecture Crash course
 Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Autotuning. John Cavazos. University of Delaware UNIVERSITY OF DELAWARE COMPUTER & INFORMATION SCIENCES DEPARTMENT
 Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
GPUfs: Integrating a file system with GPUs
 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Active thread Idle thread
 Active thread Idle thread") Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
Scale-Out Acceleration for Machine Learning
 Scale-Out Acceleration for Machine Learning Jongse Park Hardik Sharma Divya Mahajan Joon Kyung Kim Preston Olds Hadi Esmaeilzadeh Alternative Computing Technologies (ACT) Lab Georgia Institute of Technology
Scale-Out Acceleration for Machine Learning Jongse Park Hardik Sharma Divya Mahajan Joon Kyung Kim Preston Olds Hadi Esmaeilzadeh Alternative Computing Technologies (ACT) Lab Georgia Institute of Technology
Compiling for GPUs. Adarsh Yoga Madhav Ramesh
 Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Multipredicate Join Algorithms for Accelerating Relational Graph Processing on GPUs
 Multipredicate Join Algorithms for Accelerating Relational Graph Processing on GPUs Haicheng Wu 1, Daniel Zinn 2, Molham Aref 2, Sudhakar Yalamanchili 1 1. Georgia Institute of Technology 2. LogicBlox
Multipredicate Join Algorithms for Accelerating Relational Graph Processing on GPUs Haicheng Wu 1, Daniel Zinn 2, Molham Aref 2, Sudhakar Yalamanchili 1 1. Georgia Institute of Technology 2. LogicBlox
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Analyzing CUDA Workloads Using a Detailed GPU Simulator
 CS 3580 - Advanced Topics in Parallel Computing Analyzing CUDA Workloads Using a Detailed GPU Simulator Mohammad Hasanzadeh Mofrad University of Pittsburgh November 14, 2017 1 Article information Title:
CS 3580 - Advanced Topics in Parallel Computing Analyzing CUDA Workloads Using a Detailed GPU Simulator Mohammad Hasanzadeh Mofrad University of Pittsburgh November 14, 2017 1 Article information Title:
Accelerating Molecular Modeling Applications with Graphics Processors
 Accelerating Molecular Modeling Applications with Graphics Processors John Stone Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign Research/gpu/ SIAM Conference
Accelerating Molecular Modeling Applications with Graphics Processors John Stone Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign Research/gpu/ SIAM Conference
Accelerated Machine Learning Algorithms in Python
 Accelerated Machine Learning Algorithms in Python Patrick Reilly, Leiming Yu, David Kaeli reilly.pa@husky.neu.edu Northeastern University Computer Architecture Research Lab Outline Motivation and Goals
Accelerated Machine Learning Algorithms in Python Patrick Reilly, Leiming Yu, David Kaeli reilly.pa@husky.neu.edu Northeastern University Computer Architecture Research Lab Outline Motivation and Goals
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
GPU MEMORY BOOTCAMP III
 April 4-7, 2016 Silicon Valley GPU MEMORY BOOTCAMP III COLLABORATIVE ACCESS PATTERNS Tony Scudiero NVIDIA Devtech Fanatical Bandwidth Evangelist The Axioms of Modern Performance #1. Parallelism is mandatory
April 4-7, 2016 Silicon Valley GPU MEMORY BOOTCAMP III COLLABORATIVE ACCESS PATTERNS Tony Scudiero NVIDIA Devtech Fanatical Bandwidth Evangelist The Axioms of Modern Performance #1. Parallelism is mandatory
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Porting COSMO to Hybrid Architectures
 Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Fast Parallel Longest Common Subsequence with General Integer Scoring Support
 Fast Parallel Longest Common Subsequence with General Integer Scoring Support Adnan Ozsoy, Arun Chauhan, Martin Swany School of Informatics and Computing Indiana University, Bloomington, USA 1 Fast Parallel
Fast Parallel Longest Common Subsequence with General Integer Scoring Support Adnan Ozsoy, Arun Chauhan, Martin Swany School of Informatics and Computing Indiana University, Bloomington, USA 1 Fast Parallel
PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in ReRAM-based Main Memory
 Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS
 ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
ACCELERATING THE PRODUCTION OF SYNTHETIC SEISMOGRAMS BY A MULTICORE PROCESSOR CLUSTER WITH MULTIPLE GPUS Ferdinando Alessi Annalisa Massini Roberto Basili INGV Introduction The simulation of wave propagation
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
MRPB: Memory Request Priori1za1on for Massively Parallel Processors
 MRPB: Memory Request Priori1za1on for Massively Parallel Processors Wenhao Jia, Princeton University Kelly A. Shaw, University of Richmond Margaret Martonosi, Princeton University Benefits of GPU Caches
MRPB: Memory Request Priori1za1on for Massively Parallel Processors Wenhao Jia, Princeton University Kelly A. Shaw, University of Richmond Margaret Martonosi, Princeton University Benefits of GPU Caches
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code
 A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code Malik Khan, Protonu Basu, Gabe Rudy, Mary Hall, Chun Chen, Jacqueline Chame Mo:va:on Challenges to programming the GPU
A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code Malik Khan, Protonu Basu, Gabe Rudy, Mary Hall, Chun Chen, Jacqueline Chame Mo:va:on Challenges to programming the GPU
Big Data Systems on Future Hardware. Bingsheng He NUS Computing
 Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
arxiv: v2 [cs.dc] 2 May 2017
![arxiv: v2 [cs.dc] 2 May 2017](/thumbs/74/70261364.jpg "arxiv: v2 [cs.dc] 2 May 2017") High Performance Data Persistence in Non-Volatile Memory for Resilient High Performance Computing Yingchao Huang University of California, Merced yhuang46@ucmerced.edu Kai Wu University of California,
High Performance Data Persistence in Non-Volatile Memory for Resilient High Performance Computing Yingchao Huang University of California, Merced yhuang46@ucmerced.edu Kai Wu University of California,
Accelerator Spectrum
 Active/HardBD Panel Mohammad Sadoghi, Purdue University Sebastian Breß, German Research Center for Artificial Intelligence Vassilis J. Tsotras, University of California Riverside Accelerator Spectrum Commodity
Active/HardBD Panel Mohammad Sadoghi, Purdue University Sebastian Breß, German Research Center for Artificial Intelligence Vassilis J. Tsotras, University of California Riverside Accelerator Spectrum Commodity