Improving Performance of Machine Learning Workloads
|
|
|
- Timothy Kelley
- 5 years ago
- Views:
Transcription






1 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California, Merced
2 Outline Running machine learning workloads on CPU Running machine learning workloads on GPU Recent new hardware to run machine learning workloads Google TPU NVIDIA Volta
3 Running Machine Learning Workloads on CPU
4 Running ML on CPU: performance improvement tips Code vectorization for SIMD vector instructions Ensure that all the key primitives, such as convolution, matrix multiplication, and batch normalization are vectorized to the latest SIMD instructions NUMA performance problem Improve data locality and avoid data access bottleneck Manage thread-level parallelism Improve system throughput

 vectors of integers and floats One operation produces multiple results An example")
5 SIMD (Single Instruction Multiple Data) vector instructions in a nutshell What are these instructions? Extension of the ISA Data types and instructions for parallel computation on short (2-16) vectors of integers and floats One operation produces multiple results An example //a, b and c are integer arrays Vectorization not enabled Vectorization enabled
6 Evolution of Intel vector instructions MMX: Multimedia Extensions (1996) SSE: Streaming SIMD Extensions AVX: Advanced Vector Extension (2010) Intel Xeon Phi (co-processor): 512 bit wide SIMD vector SIMD architectures can exploit significant data-level parallelism for: matrix-oriented scientific computing media-oriented image and sound processors SIMD is more energy efficient than MIMD Only needs to fetch one instruction per data operation Makes SIMD attractive for personal mobile devices SIMD allows programmer to continue to think sequentially
7 Obstacles to vectorization Non-contiguous Memory Accesses
8 Obstacles to vectorization Data dependencies Read after write Write after read The above loop cannot be vectorized The above loop can be vectorized
9 Obstacles to vectorization The loop trip count is not known at entry to the loop at runtime Data-dependent exit condition
10 Obstacles to vectorization Not straight-line code There is control flow
 a[i]= b[i-1] + b[i] +")
11 Code transformation to enable vectorization An example: dimension-lifted Transformation (DLT) a[i]= b[i-1] + b[i] + b[i+1]
12 NUMA performance problem NUMA = Non-uniform memory access Figure courtesy:
13 NUMA performance problem Two different common NUMA memory-allocation policies First-touch Memory is allocated on the same node as the thread that first accesses the memory Interleave Distributes memory allocations equally on all nodes regardless of which threads access it Good for memory allocation balance

14 NUMA performance problem: locality and congestion No one policy is best for all applications NUMA effects beyond the remote-access penalty can indeed severely affect performance e.g., streamcluster Figure courtesy:

15 NUMA performance problem: locality and congestion For streamcluster, the first-touch policy creates sever congestion The average memory latency with the first-touch policy is more than double the latency of the interleave policy Figure courtesy:

16 Manage thread-level parallelism Many machine learning frameworks are based on finegrained operations e.g., tensorflow, caffe2, theano, MXNet, and CNTK An example from inception_v3 Figure courtesy: tensorflow github
17 Execution time (s) Manage thread-level parallelism Intra-op parallelism Using maximum number of threads does not necessarily lead to best performance conv2d_backprop_filter Number of threads
18 Performance (s) Manage thread-level parallelism Inter-op parallelism Co-run multiple operations to improve system throughput 5% performance loss Number of threads
19 Running Machine Learning Workloads on GPU
20 Running ML on GPU: performance improvement tips Optimize memory usage for maximum bandwidth Maximize occupancy to hide latency Control flow divergence
21 Optimize memory usage: basic strategies Processing data is cheaper than moving it around Especially for GPUs as they devote many more transistors to ALUs than memory And will be increasingly so The less memory bound a kernel is, the better it will scale with future GPUs So you want to: Maximize use of low-latency, high-bandwidth memory Optimize memory access patterns to maximize bandwidth Leverage parallelism to hide memory latency by overlapping memory accesses with computation as much as possible Kernels with high arithmetic intensity (ratio of math to memory transactions) Sometimes recompute data rather than cache it
22 Minimize CPU GPU data transfers CPU GPU memory bandwidth much lower than GPU memory bandwidth Minimize CPU GPU data transfers by moving more code from CPU to GPU Even if that means running kernels with low parallelism computations Intermediate data structures can be allocated, operated on, and deallocated without ever copying them to CPU memory Group data transfers One large transfer much better than many small ones Kernel fusion
23 Optimize memory access patterns Effective bandwidth can vary by an order of magnitude depending on access pattern Optimize access patterns to get: Coalesced global memory accesses Shared memory accesses with no or few bank conflicts Cache-efficient texture memory accesses

24 Coalesced global memory accesses Memory coalescing refers to combining multiple memory accesses into a single transaction An example: 32 consecutive threads access 32 consecutive words Sequential and aligned access: Coalesced memory accesses

25 Coalesced global memory accesses Aligned but non-sequential access Coalesced memory accesses
26 Coalesced global memory accesses Unaligned Memory Access Non-coalesced memory accesses

27 Bank conflicts on shared memory

28 Bank conflicts on shared memory

29 Cache-efficient texture memory accesses Read-only object Texture fetches are cached Optimized for 2D locality Addressable as 1D, 2D or 3D Out-of-bounds address handling (Wrap, clamp)
30 Maximize occupancy to hide latency Sources of latency: Global memory access: cycle latency Read-after-write register dependency Instruction s result can only be read 11 cycles later Latency blocks dependent instructions in the same thread, but instructions in other threads are not blocked Hide latency by running as many threads per multiprocessor as possible! Choose execution configuration to maximize occupancy = (# of active warps) / (maximum #of active warps)
31 Maximize occupancy to hide latency occupancy = (# of active warps) / (maximum #of active warps) Remember: resources are allocated for the entire block Resource are finite Utilizing too many resources per thread may limit the occupancy Potential occupancy limiters Register usage Shared memory usage Block size
32 Occupancy limiters: registers Register usage: compile with --ptxas-options=-v Fermi has 32K registers per SM Fermi can have up to 48 active warps per SM (1536 threads) Example 1 Kernel uses 20 registers per thread (+1 implicit) Active threads = 32K/21 = 1560 threads > 1536 thus an occupancy of 1 Example 2 Kernel uses 63 registers per thread (+1 implicit) Active threads = 32K/64 = 512 threads 512/1536 =.3333 occupancy
33 Occupancy limiters: registers Use maxrregcount=n flag to nvcc to control register usage N = desired maximum registers / kernel At some point spilling into local memory may occur Reduces performance -- local memory is slow Check for LMEM usage Compiler output nvcc option: Xptxas, v, abi=no Will print the number of lmem bytes for each kernel Profiler: e.g, CUPTI
34 Occupancy limiters: shared memory Shared memory usage: compile with --ptxas-options=-v Reports shared memory per block Fermi has either 16K or 48K shared memory Example 1, 48K shared memory Kernel uses 32 bytes of shared memory per thread 48K/32 = 1536 threads occupancy=1 Example 2, 16K shared memory Kernel uses 32 bytes of shared memory per thread 16K/32 = 512 threads occupancy=.3333 Don t use too much shared memory Choose L1/Shared config appropriately.

35 Occupancy limiter: block size Each SM can have up to 8 active blocks A small block size will limit the total number of threads
36 Control flow instructions Main performance concern with branching is divergence Avoid divergence when branch condition is a function of thread ID Example with divergence: If (threadidx.x > 2) { } Branch granularity < warp size Example without divergence: If (threadidx.x / WARP_SIZE > 2) { } Branch granularity is a whole multiple of warp size

37 Control flow instructions New change to SIMT model in Volta reduces the negative impact of control flow divergence a little Old model New model
38 Google Tensorflow Processing Unit (TPU)

39 Motivation for TPU

40 Tensor Processing Unit (TPU)
41 TPU is simple It has none of the sophisticated microarchitectural features Cache, branch prediction, out-of-order execution, multiprocessing, speculative prefetching, address coalescing, multithreading, context switching It uses less transistors and consumes less energy than regular CPU Aims to improve the average case but not the 99thpercentile case
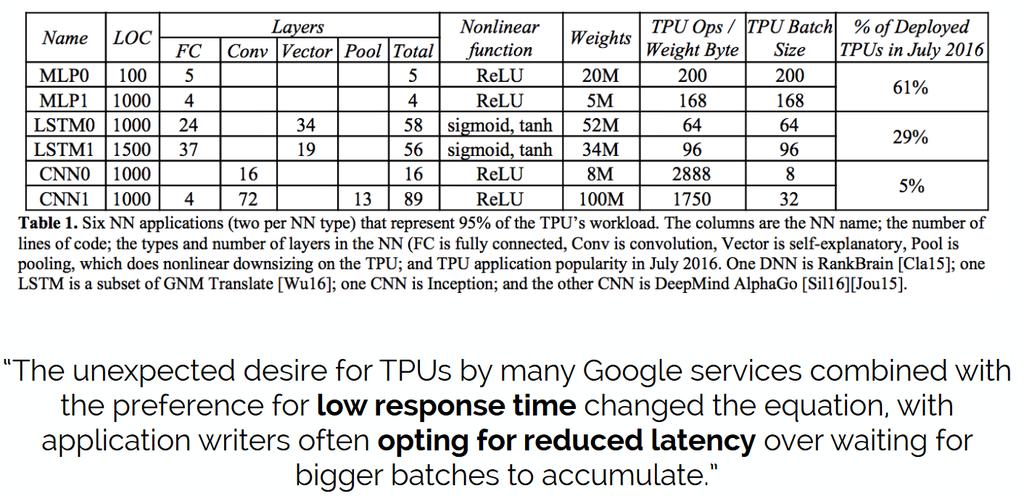
42 Application testbed

43 Patterson Discussion Fallacy: NN inference applications in data centers value throughput as much as response time. 10ms in ms in Fallacy: The K80 GPU architecture is a good match to NN inference GPU is a high thoughput architecture that relies on high-bandwidth memory and thousands of threads Pitfall: Architects have neglected important NN tasks
44 Patterson Discussion Pitfall: For NN hardware, Inferences Per Second (IPS) is an inaccurate summary performance metric. IPS is more of a function of NN than of the underlying hardware For example, the TPU runs the 4-layer MLP at 360,000 IPS but the 89-layer CNN at only 4,700 IPS Fallacy: The K80 GPU results would be much better if boost mode were enabled Improvement in performance/watt is only 1.1x Fallacy: After two years of software tuning, the only path left to increase TPU performance is hardware upgrades.

45 NVIDIA s Rebuttal to the TPU


46 NVIDIA New GPU for Machine Learning: Volta GV100 GPU Figure courtesy: Nividia Volta architecture white paper

47 Key features New tensor cores Eight tensor cores per streaming multiprocessor Each tensor core performs 64 floating point FMA operations per clock Each tensor core operatates on 4x4 matrix, and performs D= A x B + C
48 Key features NVLink 2.0 High bandwidth between CPU and GPU and between GPU and GPU: 300GB/s CPU to regular main memory bandwidth on Intel Xeon Phil (knights landing): ~90 GB/s High-bandwidth memory Memory stacks located on the same physical package as GPU 900GB/s, 1.5x delivered memory bandwidth versus Pascal GP100 (the last version) CPU to high bandwidth memory on Intel Xeon Phil (Knights Landing): ~ GB/s

49 Key features Multi-Process Service Allow multiple applications to simultaneously share GPU execution resources Permitting many individual inference jobs to be submitted concurrently to GPU and improve overall GPU utilization
50 Key features Maximum Performance and Maximum Efficiency Modes A not-to-exceed power cap can be set Cooperative Groups and New Cooperative Launch APIs Pascal and Volta include support for new cooperative launch APIs that support synchronization amongst CUDA thread blocks
51 References A Guide to Vectorization with Intel C++ Compilers, TPU slides on ISCA 17 NVIDIA white paper (NVIDIA Tesla V100 GPU architecture) B. Wilkinson, GPU Memories, ITCS 6/8010 CUDA programming, UNC-Charlotte, 2011 Justin Luitjens and Steven Rennich, CUDA Warps and Occupancy, GPU Computing Webinar, July 12, 2011
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Advanced CUDA Programming. Dr. Timo Stich
 Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU
 NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
GPU Profiling and Optimization. Scott Grauer-Gray
 GPU Profiling and Optimization Scott Grauer-Gray Benefits of GPU Programming "Free" speedup with new architectures More cores in new architecture Improved features such as L1 and L2 cache Increased shared/local
GPU Profiling and Optimization Scott Grauer-Gray Benefits of GPU Programming "Free" speedup with new architectures More cores in new architecture Improved features such as L1 and L2 cache Increased shared/local
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
From Shader Code to a Teraflop: How GPU Shader Cores Work. Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian)
") From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary
 Optimizing CUDA Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary NVIDIA Corporation 2009 2 Optimize Algorithms for the GPU Maximize
Optimizing CUDA Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary NVIDIA Corporation 2009 2 Optimize Algorithms for the GPU Maximize
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Lecture 7. Using Shared Memory Performance programming and the memory hierarchy
 Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Tuning CUDA Applications for Fermi. Version 1.2
 Tuning CUDA Applications for Fermi Version 1.2 7/21/2010 Next-Generation CUDA Compute Architecture Fermi is NVIDIA s next-generation CUDA compute architecture. The Fermi whitepaper [1] gives a detailed
Tuning CUDA Applications for Fermi Version 1.2 7/21/2010 Next-Generation CUDA Compute Architecture Fermi is NVIDIA s next-generation CUDA compute architecture. The Fermi whitepaper [1] gives a detailed
Analysis Report. Number of Multiprocessors 3 Multiprocessor Clock Rate Concurrent Kernel Max IPC 6 Threads per Warp 32 Global Memory Bandwidth
 Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
From Shader Code to a Teraflop: How Shader Cores Work
 From Shader Code to a Teraflop: How Shader Cores Work Kayvon Fatahalian Stanford University This talk 1. Three major ideas that make GPU processing cores run fast 2. Closer look at real GPU designs NVIDIA
From Shader Code to a Teraflop: How Shader Cores Work Kayvon Fatahalian Stanford University This talk 1. Three major ideas that make GPU processing cores run fast 2. Closer look at real GPU designs NVIDIA
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Optimizing CUDA NVIDIA Corporation 2009 U. Melbourne GPU Computing Workshop 27/5/2009 1
 Optimizing CUDA 1 Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary 2 Optimize Algorithms for the GPU Maximize independent parallelism
Optimizing CUDA 1 Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary 2 Optimize Algorithms for the GPU Maximize independent parallelism
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
Profiling & Tuning Applica1ons. CUDA Course July István Reguly
 Profiling & Tuning Applica1ons CUDA Course July 21-25 István Reguly Introduc1on Why is my applica1on running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA,
Profiling & Tuning Applica1ons CUDA Course July 21-25 István Reguly Introduc1on Why is my applica1on running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA,
State-of-the-art in Heterogeneous Computing
 State-of-the-art in Heterogeneous Computing Guest Lecture NTNU Trond Hagen, Research Manager SINTEF, Department of Applied Mathematics 1 Overview Introduction GPU Programming Strategies Trends: Heterogeneous
State-of-the-art in Heterogeneous Computing Guest Lecture NTNU Trond Hagen, Research Manager SINTEF, Department of Applied Mathematics 1 Overview Introduction GPU Programming Strategies Trends: Heterogeneous
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
PERFORMANCE ANALYSIS AND DEBUGGING FOR VOLTA. Felix Schmitt 11 th Parallel Tools Workshop September 11-12, 2017
 PERFORMANCE ANALYSIS AND DEBUGGING FOR VOLTA Felix Schmitt 11 th Parallel Tools Workshop September 11-12, 2017 INTRODUCING TESLA V100 Volta Architecture Improved NVLink & HBM2 Volta MPS Improved SIMT Model
PERFORMANCE ANALYSIS AND DEBUGGING FOR VOLTA Felix Schmitt 11 th Parallel Tools Workshop September 11-12, 2017 INTRODUCING TESLA V100 Volta Architecture Improved NVLink & HBM2 Volta MPS Improved SIMT Model
Advanced CUDA Optimizing to Get 20x Performance. Brent Oster
 Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Performance Optimization Part II: Locality, Communication, and Contention
 Lecture 7: Performance Optimization Part II: Locality, Communication, and Contention Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Beth Rowley Nobody s Fault but Mine
Lecture 7: Performance Optimization Part II: Locality, Communication, and Contention Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Beth Rowley Nobody s Fault but Mine
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Analysis-Driven Optimization Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Performance Optimization Process Use appropriate performance metric for each kernel For example,
Analysis-Driven Optimization Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Performance Optimization Process Use appropriate performance metric for each kernel For example,
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 7. Overlap Using Shared Memory Performance programming the memory hierarchy
 Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
Profiling & Tuning Applications. CUDA Course István Reguly
 Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES. Stephen Jones, GTC 2017
 CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
Advanced CUDA Optimizing to Get 20x Performance
 Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011
 Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Performance Optimization Process
 Analysis-Driven Optimization (GTC 2010) Paulius Micikevicius NVIDIA Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for a bandwidth-bound
Analysis-Driven Optimization (GTC 2010) Paulius Micikevicius NVIDIA Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for a bandwidth-bound
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics