The OmpSs programming model and its runtime support
|
|
|
- Nathaniel Hudson
- 6 years ago
- Views:
Transcription

1 The OmpSs programming model and its runtime support Jesús Labarta BSC RoMoL 2016 Barcelona, March 12 th

2 Vision The multicore and memory revolution ISA leak Plethora of architectures Heterogeneity Memory hierarchies The power wall made us go multicore and the ISA interface to leak our world is shaking Applications Applications Complexity + + variability = = Divergence between our mental models and actual system behavior ISA / API 2
3 The programming revolution An age changing revolution From the latency age I need something I need it now!!! Performance dominated by latency in a broad sense At all levels: sequential and parallel Memory and communication, control flow, synchronizations to the throughput age Ability to instantiate lots of work and avoid stalling for specific requests I need this and this and that and as long as it keeps coming I am ok (Much broader interpretation than just GPU computing!!) Performance dominated by overall availability/balance of resources 3











4 Vision in the programming revolution Need to decouple again Application logic Arch. independent Applications PM: High-level, clean, abstract interface Power to the runtime General purpose Task based Single address space Programming language ISA / API Reuse architectural ideas under new constraints 4
5 Co s opportunities and challenges Co-design : features in one level to support/adapt to other levels Holistic design/optimization Multilevel Multidirectional Fundamentals Dynamic Co-ordination between dynamic resource management levels Co-nvergence of sectors HPC. Embedded, Big data/analytics 5






6 Vision in the programming/architecture revolution Back to the future Application logic Arch. independent Applications PM: High-level, clean, abstract interface Architecture aware runtime Runtime aware architecture Mateos chips!!! Programmer Engine interface Flexibility in execution engine design 6 6
7 STARSS 7
8 The StarSs family of programming models Key concept Sequential task based program on single address/name space + directionality annotations Happens to execute parallel: Automatic run time computation of dependencies between tasks Differentiation of StarSs Dependences: Tasks instantiated but not ready. Order IS defined Lookahead Avoid stalling the main control flow when a computation depending on previous tasks is reached Possibility to see the future searching for further potential concurrency Dependences built from data access specification Locality aware Without defining new concepts Homogenizing heterogeneity Device specific tasks but homogeneous program logic 8



9 History / Strategy COMPSs ~2007 COMPSs ServiceSs ~2010 COMPSs ServiceSs PyCOMPSs ~2013 CellSs ~2006 GPUSs ~2009 PERMPAR ~1994 GridSs ~2002 SMPSs V1 ~2007 StarSs ~2008 SMPSs V2 ~2009 Parascope ~1992 NANOS ~1996 OmpSs ~2008 Forerunner of OpenMP OpenMP
10 OmpSs in one slide Minimalist set of concepts extending OpenMP relaxing StarSs funtional model #pragma omp task [ in (array_spec...)] [ out (...)] [ inout (...)] \ [ concurrent ( )] [commutative(...)] [ priority(p) ] [ label(...) ] \ [ shared(...)][private(...)][firstprivate(...)][default(...)][untied][final][if (expression)] [reduction(identfier : list)] {code block or function} #pragma omp taskwait [ on (...) ][noflush] #pragma omp for [ shared(...)][private(...)][firstprivate(...)][schedule_clause] {for_loop} #pragma omp taskloop [grainsize( ) ] [nogroup] [ in (...)] {for_loop} #pragma omp target device ({ smp opencl cuda }) \ [ implements ( function_name )] \ [ copy_deps no_copy_deps ] [ copy_in ( array_spec,...)] [ copy_out (...)] [ copy_inout (...)] } \ [ndrange (dim, )] [shmem(...) ] A. Duran, et al, Extending the OpenMP Tasking Model to Allow Dependent Tasks IWOMP 2008, LNCS & IJPP E. Ayguade, et al, A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures IWOMP 2009 & IJPP 10
![Adapting comcurrency to dynamic environment Sequential file processing Automatically achieve asynchronous I/O typedef struct {int size, char buff[maxsize]} buf_t; but_t *p[nbuf]; int j=0,](/docs-images/72/66383896/images/11-1.jpg "total_records=0; int main() { while(!")
11 Adapting comcurrency to dynamic environment Sequential file processing Automatically achieve asynchronous I/O typedef struct {int size, char buff[maxsize]} buf_t; but_t *p[nbuf]; int j=0, total_records=0; int main() { while(!end_trace) { buf_t **pb=&p[j%nbuf]; j++; #pragma omp task inout(infile) out(*pb, end_trace) \ priority(10) { *pb= malloc(sizeof(buf_t)); Read (infile, *pb, &end_trace); } } } #pragma omp task inout(*pb) Process (*pb); #pragma omp task inout (outfile, *pb, total_records)\ priority(10) { int records; } Write (outfile, *pb, &records); total_records += records; free (*pb); #pragma omp taskwait on (&end_trace) 11







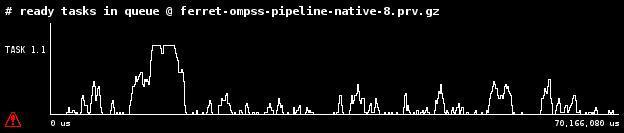




12 optimized Direct PARSEC benchmark ported to OmpSs Initial port from pthreads to OmpSs and optimization Bodytrack Ferret D. Chasapis et al, Exploring the Impact of Task Parallelism Beyond the HPC Domain.. 12
13 Task reductions Task reductions OmpSs While-loops, recursions On its way to OpenMP 5.0 while (node) { #pragma omp task \ reduction(+: res) res += node->value; node = node->next; } #pragma omp task inout(res) printf( value: %d\n, res); #pragma omp taskwait OpenMP #pragma omp parallel { #pragma omp single { #pragma omp taskgroup \ reduction(+: res) \ firstprivate (node) { while (node) { #pragma omp task \ in_reduction(+: res) res += node->value; node = node->next; } printf( value: %d\n, res); } } } Ciesko, J., et al. Task-Parallel Reductions in OpenMP and OmpSs, IWOMP 2014 Ciesko, J., et al. Towards task-parallel reductions in OpenMP, IWOMP
14 Task reductions Array reductions Typical pattern: reductions on large arrays with indirection Implementation Privatization becomes inefficient when scaling cores and data size Atomics can introduce significant overhead PIBOR Proposal: Privatization with in-lined block-ordered reductions Save footprint Trade processor cycles for locality for (auto t : tasks){ #pragma task \ reduction (+:v[0:size]) \ private (j) for (auto i : taskiters) { j= f(i); v[j] += expression; } } #pragma taskwait C++11 Ciesko, J., et al. Boosting Irregular Array Reductions through In-lined Block-ordering on Fast Processors, HPEC15 14
15 Programmability improvements Frequent pattern: Different instantiations of same task requiring different number of dependences imply code replication (peeling, switch, ) E.g. number of neighbors in a domain decomposition Multidependences Syntax to specify a dynamic number of directionality clauses #pragma omp task in({v[neigh.n[j]], j=0:neigh.size()}) //task code May require the pre-computation of some connectivity information Often already there in many codes Frequently an invariant information (not required by the proposal but if it is the case the overhead of its computation is amortized over multiple uses) 15
16 Homogenizing Heterogeneity ISA heterogeneity Single address space program executes in several non coherent address spaces Copy clauses: ensure sequentially consistent copy accessible in the address space where task is going to be executed Requires precise specification of data accessed (e.g. array sections) Runtime offloads data and computation and manages consistency Kernel based programming Separation of iteration space identification and loop body #pragma omp target device ({ smp opencl cuda }) \ [ copy_deps no_copy_deps ] [ copy_in ( array_spec,...)] [ copy_out (...)] [ copy_inout (...)] } \ [ implements ( function_name )] \ [shmem(...) ] \ [ndrange (dim, g_array, l_array)] #pragma omp taskwait [ on (...) ][noflush] 16
17 Homogenizing Heterogeneity #pragma omp target device(opencl) ndrange(1,size,128) copy_deps implements (calculate_forces) #pragma omp task out([size] out) in([npart] part) kernel void calculate_force_opencl(int size, float time, int npart, global Part* part, global Part* out, int gid); #pragma omp target device(cuda) ndrange(1,size,128) copy_deps implements (calculate_forces) #pragma omp task out([size] out) in([npart] part) global void calculate_force_cuda(int size, float time, int npar, Part* part, Particle *out, int gid); #pragma omp target device(smp) copy_deps #pragma omp task out([size] out) in([npart] part) void calculate_forces(int size, float time, int npart, Part* part, Particle *out, int gid); void Particle_array_calculate_forces(Particle* input, Particle *output, int npart, float time) { for (int i = 0; i < npart; i += BS ) calculate_forces(bs, time, npart, input, &output[i], i); } 17



18 MACC (Mercurium ACcelerator Compiler) OpenMP 4.0 accelerator directives compiler Generates OmpSs code + CUDA kernels (for Intel & Power8 + GPUs) Propose clauses that improve kernel performance Extended semantics Change in mentality minor details make a difference Dynamic parallelism Type of device Ensure availability G. Ozen et al, On the roles of the programmer, the compiler and the runtime system when facing accelerators in OpenMP 4.0 IWOMP 2014 Specific device DO transfer G. Ozen et al, Multiple Target Work-sharing support for the OpenMP Accelerator Model submitted 18



19 Integration of MPI and OmpSs Taskifying MPI calls V. Marjanovic, et al, Overlapping Communication and Computation by using a Hybrid MPI/SMPSs Approach ICS 2010 Opportunity Overlap between phases Grid and frequency domain Provide laxity for communications Tolerate poorer communication Migrate load balance issue Flexibility for DLB Huge flexibility for changing behavior with minimal syntactic changes physics IFS weather code kernel. ECMRWF ffts 19

 pack")

20 Hybrid Amdahl s law A fairly gad message for programmers Significant non parallelized part MPI calls + pack/unpack MAXW-DGTD 1 thread/process for () pack irecv isend wait all sends for () test unpack 2 thread/process MPI + OmpSs: Hope for lazy programmers 20







21 MPI offload CASE/REPSOL FWI Reverse offload 21




22 DSLs Support multicores, accelerators and distributed systems CASE/REPSOL Repsolver CASE/CS cooperation A. Fernandez et al, A Data Flow Language to Develop High Performance Computing DSLs Submitted 22
23 OmpSs Other features and characteristics Contiguous / strided dependence detection and data management Nesting/recursion Multiple implementations for a given task CUDA, OpenCL Cluster Dynamic load balance between MPI processes in one node Resilience Commitment Continuous development and use since 2004 Pushing ideas into the OpenMP standard Dependences v 4.0 Priority v 4.5 Developer Positioning: efforts in OmpSs will not be lost. Used in projects and applications Undertaken significant efforts to port real large scale applications: DEEP Scalapack, PLASMA, SPECFEM3D, LBC, CPMD PSC, PEPC, LS1 Mardyn, Asynchronous algorithms, Microbenchmarks YALES2, EUTERPE, SPECFEM3D, MP2C, BigDFT, QuantumESPRESSO, PEPC, SMMP, ProFASI, COSMO, BQCD NEURON, ipic3d, ECHAM/MESSy, AVBP, TurboRVB, Seismic G8_ECS CGPOP, NICAM (planed) Consolider project (Spanish ministry) MRGENESIS BSC initiatives and collaborations: GROMACS, GADGET, WRF, but NOT only for «scientific computing» Plagiarism detection Histograms, sorting, (FhI FIRST) Trace browsing Paraver (BSC) Clustering algorithms G-means (BSC) Image processing Tracking (USAF) Embedded and consumer H.264 (TUBerlin), A. Duran, et al, Extending the OpenMP Tasking Model to Allow Dependent Tasks IWOMP 2008, LNCS & IJPP E. Ayguade, et al, A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures IWOMP 2009 & IJPP 23
24 COMPILER AND RUNTIME 24
 Recognize pragmas and transforms original program to call Nanox++")

25 The Mercurium Compiler Mercurium Source-to-source compiler (supports OpenMP and OmpSs extensions) Recognize pragmas and transforms original program to call Nanox++ Supports Fortran, C and C++ languages (backends: gcc, icc, nvcc, ) Supports complex scenarios Ex: Single program with MPI, OpenMP, CUDA and OpenCL kernels 25
 and data transfer between them Target specific features http://pm.bsc.")
26 The NANOS++ Runtime Nanos++ Common execution runtime (C, C++ and Fortran) Task creation, dependence management, resilience, Task scheduling (FIFO, DF, BF, Cilk, Priority, Socket, affinity, ) Data management: Unified directory/cache architecture Transparently manages separate address spaces (host, device, cluster) and data transfer between them Target specific features 26






27 Criticality-awareness in heterogeneous architectures Heterogeneous multicores ARM big.little 4 A-15@2GHz; 4A-7@1.4GHz Tasksim simulator: cores; 2-4x Runtime approximation of critical path Implementable, small overhead that pay off Approximation is enough Higher benefits the more cores, the more big cores, the higher performance ratio K. Chronaki et al, Criticality-Aware Dynamic Task Scheduling for Heterogeneous Architectures. ICS







28 FPGAs Just another heterogeneous device Zynq 28
29 Managing separate address spaces Cluster master A software device manages its individual address space: Manages local space at device (logical and physical) Translate main address space device address Implements transfers Packing if needed Device/network specific transfer APIs (i.e. GASNet, CUDA copies, MPI, ) A productive alternative for programs requiring very large footprints Omics Graph analytics J. Bueno et al, Productive Programming of GPU Clusters with OmpSs, IPDPS2012 J. Bueno et al, Implementing OmpSs Support for Regions of Data in Architectures with Multiple Address Spaces, ICS

 Overlap")



30 Device management mechanisms Improvements in runtime mechanisms Use of multiple streams High asynchrony and overlap (transfers and kernels) Overlap kernels Take overheads out of the critical path Improvement in schedulers Late binding of locality aware decisions Propagate priorities Nbody Cholesky J. Planas et al, AMA: Asynchronous Management of Accelerators for Task-based Programming Models. ICCS
 R. Al-Omairy et al, Dense Matrix Computations on NUMA Architectures with Distance-Aware Work Stealing.")
31 Scheduling Locality aware scheduling Affinity to core/node/device can be computed based on pragmas and knowledge of where was data Following dependences reduces data movement Interaction between locality and load balance (work-stealing) R. Al-Omairy et al, Dense Matrix Computations on NUMA Architectures with Distance-Aware Work Stealing. SuperFRI 2015 Some reasonable criteria Task instantiation order is typically a fair criteria Honor previous scheduling decisions when using nesting Ensure a minimum amount of resources Prioritize continuation of a father task in a taskwait when synchronization fulfilled 31
 Runtime in control (sees what happens and the")
 LeWI: A Runtime Balancing Algorithm for Nested Parallelism. M.Garcia et al.")
32 Dynamic Load Balancing Dynamically shift cores between processes in node Enabled by application malleability (task based) Runtime in control (sees what happens and the future) Would greatly benefit from OS support (handoff scheduling, fast context switching) LeWI: A Runtime Balancing Algorithm for Nested Parallelism. M.Garcia et al. ICPP09 32
33 Others Real time Memory association changes Runtime reengineering OMPT Tareador Debugging - HLRS 33
34 CONCLUSION 34




35 The importance of Language Transport / integrate information Experience Good predictor Structures mind H. sapiens low larynx Neanderthal high larynx Details Very simple/small/subtle differences very important impact 35

36 What is important? Asynchrony/dataflow Data access based specification and runtime awareness Malleability Not to fly blind Dynamic 36
37 The real parallel programming revolution is in the mindset of programmers is to rely on the (runtime) system We all have to learn about data flow, overall potential concurrency, malleability, 37
38 38 38
39 THANKS 39
From the latency to the throughput age
 www.bsc.es From the latency to the throughput age Jesús Labarta BSC Keynote @ IWOMP 2016 Nara, October 7 th 2016 1 Vision The multicore and memory revolution ISA leak Plethora of architectures Heterogeneity
www.bsc.es From the latency to the throughput age Jesús Labarta BSC Keynote @ IWOMP 2016 Nara, October 7 th 2016 1 Vision The multicore and memory revolution ISA leak Plethora of architectures Heterogeneity
OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel
 www.bsc.es OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel Guray Ozen guray.ozen@bsc.es Exascale in BSC Marenostrum 4 (13.7 Petaflops ) General purpose cluster (3400
www.bsc.es OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel Guray Ozen guray.ozen@bsc.es Exascale in BSC Marenostrum 4 (13.7 Petaflops ) General purpose cluster (3400
From the latency to the throughput age. Prof. Jesús Labarta Director Computer Science Dept (BSC) UPC
 UPC") From the latency to the throughput age Prof. Jesús Labarta Director Computer Science Dept (BSC) UPC ETP4HPC Post-H2020 HPC Vision Frankfurt, June 24 th 2018 To exascale... and beyond 2 Vision The multicore
From the latency to the throughput age Prof. Jesús Labarta Director Computer Science Dept (BSC) UPC ETP4HPC Post-H2020 HPC Vision Frankfurt, June 24 th 2018 To exascale... and beyond 2 Vision The multicore
Hybridizing MPI and tasking: The MPI+OmpSs experience. Jesús Labarta BSC CS Dept. Director
 Hybridizing MPI and tasking: The MPI+OmpSs experience Jesús Labarta BSC CS Dept. Director Russian Supercomputing Days Moscow, September 25th, 2017 MPI + X Why hybrid? MPI is here to stay A lot of HPC applications
Hybridizing MPI and tasking: The MPI+OmpSs experience Jesús Labarta BSC CS Dept. Director Russian Supercomputing Days Moscow, September 25th, 2017 MPI + X Why hybrid? MPI is here to stay A lot of HPC applications
OmpSs Fundamentals. ISC 2017: OpenSuCo. Xavier Teruel
 OmpSs Fundamentals ISC 2017: OpenSuCo Xavier Teruel Outline OmpSs brief introduction OmpSs overview and influence in OpenMP Execution model and parallelization approaches Memory model and target copies
OmpSs Fundamentals ISC 2017: OpenSuCo Xavier Teruel Outline OmpSs brief introduction OmpSs overview and influence in OpenMP Execution model and parallelization approaches Memory model and target copies
POP CoE: Understanding applications and how to prepare for exascale
 POP CoE: Understanding applications and how to prepare for exascale Jesus Labarta (BSC) EU H2020 Center of Excellence (CoE) Lecce, May 17 th 2018 5 th ENES HPC workshop POP objective Promote methodologies
POP CoE: Understanding applications and how to prepare for exascale Jesus Labarta (BSC) EU H2020 Center of Excellence (CoE) Lecce, May 17 th 2018 5 th ENES HPC workshop POP objective Promote methodologies
OpenMPSuperscalar: Task-Parallel Simulation and Visualization of Crowds with Several CPUs and GPUs
 www.bsc.es OpenMPSuperscalar: Task-Parallel Simulation and Visualization of Crowds with Several CPUs and GPUs Hugo Pérez UPC-BSC Benjamin Hernandez Oak Ridge National Lab Isaac Rudomin BSC March 2015 OUTLINE
www.bsc.es OpenMPSuperscalar: Task-Parallel Simulation and Visualization of Crowds with Several CPUs and GPUs Hugo Pérez UPC-BSC Benjamin Hernandez Oak Ridge National Lab Isaac Rudomin BSC March 2015 OUTLINE
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
Tutorial OmpSs: Overlapping communication and computation
 www.bsc.es Tutorial OmpSs: Overlapping communication and computation PATC course Parallel Programming Workshop Rosa M Badia, Xavier Martorell PATC 2013, 18 October 2013 Tutorial OmpSs Agenda 10:00 11:00
www.bsc.es Tutorial OmpSs: Overlapping communication and computation PATC course Parallel Programming Workshop Rosa M Badia, Xavier Martorell PATC 2013, 18 October 2013 Tutorial OmpSs Agenda 10:00 11:00
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Exploring Dynamic Parallelism on OpenMP
 www.bsc.es Exploring Dynamic Parallelism on OpenMP Guray Ozen, Eduard Ayguadé, Jesús Labarta WACCPD @ SC 15 Guray Ozen - Exploring Dynamic Parallelism in OpenMP Austin, Texas 2015 MACC: MACC: Introduction
www.bsc.es Exploring Dynamic Parallelism on OpenMP Guray Ozen, Eduard Ayguadé, Jesús Labarta WACCPD @ SC 15 Guray Ozen - Exploring Dynamic Parallelism in OpenMP Austin, Texas 2015 MACC: MACC: Introduction
OmpSs Specification. BSC Programming Models
 OmpSs Specification BSC Programming Models March 30, 2017 CONTENTS 1 Introduction to OmpSs 3 1.1 Reference implementation........................................ 3 1.2 A bit of history..............................................
OmpSs Specification BSC Programming Models March 30, 2017 CONTENTS 1 Introduction to OmpSs 3 1.1 Reference implementation........................................ 3 1.2 A bit of history..............................................
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Performance Tools (Paraver/Dimemas)
") www.bsc.es Performance Tools (Paraver/Dimemas) Jesús Labarta, Judit Gimenez BSC Enes workshop on exascale techs. Hamburg, March 18 th 2014 Our Tools! Since 1991! Based on traces! Open Source http://www.bsc.es/paraver!
www.bsc.es Performance Tools (Paraver/Dimemas) Jesús Labarta, Judit Gimenez BSC Enes workshop on exascale techs. Hamburg, March 18 th 2014 Our Tools! Since 1991! Based on traces! Open Source http://www.bsc.es/paraver!
Towards task-parallel reductions in OpenMP
 www.bsc.es Towards task-parallel reductions in OpenMP J. Ciesko, S. Mateo, X. Teruel, X. Martorell, E. Ayguadé, J. Labarta, A. Duran, B. De Supinski, S. Olivier, K. Li, A. Eichenberger IWOMP - Aachen,
www.bsc.es Towards task-parallel reductions in OpenMP J. Ciesko, S. Mateo, X. Teruel, X. Martorell, E. Ayguadé, J. Labarta, A. Duran, B. De Supinski, S. Olivier, K. Li, A. Eichenberger IWOMP - Aachen,
OpenMP 4.0/4.5. Mark Bull, EPCC
 OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures
 A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming with
 Programming with OmpSs@CUDA/OpenCL Xavier Martorell, Rosa M. Badia Computer Sciences Research Dept. BSC PATC Parallel Programming Workshop July 1-2, 2015 Agenda Motivation Leveraging OpenCL and CUDA Examples
Programming with OmpSs@CUDA/OpenCL Xavier Martorell, Rosa M. Badia Computer Sciences Research Dept. BSC PATC Parallel Programming Workshop July 1-2, 2015 Agenda Motivation Leveraging OpenCL and CUDA Examples
Design and Development of support for GPU Unified Memory in OMPSS
 Design and Development of support for GPU Unified Memory in OMPSS Master in Innovation and Research in Informatics (MIRI) High Performance Computing (HPC) Facultat d Informàtica de Barcelona (FIB) Universitat
Design and Development of support for GPU Unified Memory in OMPSS Master in Innovation and Research in Informatics (MIRI) High Performance Computing (HPC) Facultat d Informàtica de Barcelona (FIB) Universitat
Task-parallel reductions in OpenMP and OmpSs
 Task-parallel reductions in OpenMP and OmpSs Jan Ciesko 1 Sergi Mateo 1 Xavier Teruel 1 Vicenç Beltran 1 Xavier Martorell 1,2 1 Barcelona Supercomputing Center 2 Universitat Politècnica de Catalunya {jan.ciesko,sergi.mateo,xavier.teruel,
Task-parallel reductions in OpenMP and OmpSs Jan Ciesko 1 Sergi Mateo 1 Xavier Teruel 1 Vicenç Beltran 1 Xavier Martorell 1,2 1 Barcelona Supercomputing Center 2 Universitat Politècnica de Catalunya {jan.ciesko,sergi.mateo,xavier.teruel,
OpenMP 4.0. Mark Bull, EPCC
 OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
Hardware Hetergeneous Task Scheduling for Task-based Programming Models
 www.bsc.es Hardware Hetergeneous Task Scheduling for Task-based Programming Models Xubin Tan OpenMPCon 2018 Advisors: Carlos Álvarez, Daniel Jiménez-González Agenda > Background, Motivation > Picos++ accelerated
www.bsc.es Hardware Hetergeneous Task Scheduling for Task-based Programming Models Xubin Tan OpenMPCon 2018 Advisors: Carlos Álvarez, Daniel Jiménez-González Agenda > Background, Motivation > Picos++ accelerated
The Mont-Blanc project Updates from the Barcelona Supercomputing Center
 montblanc-project.eu @MontBlanc_EU The Mont-Blanc project Updates from the Barcelona Supercomputing Center Filippo Mantovani This project has received funding from the European Union's Horizon 2020 research
montblanc-project.eu @MontBlanc_EU The Mont-Blanc project Updates from the Barcelona Supercomputing Center Filippo Mantovani This project has received funding from the European Union's Horizon 2020 research
Task-based programming models to support hierarchical algorithms
 www.bsc.es Task-based programming models to support hierarchical algorithms Rosa M BadiaBarcelona Supercomputing Center SHAXC 2016, KAUST, 11 May 2016 Outline BSC Overview of superscalar programming model
www.bsc.es Task-based programming models to support hierarchical algorithms Rosa M BadiaBarcelona Supercomputing Center SHAXC 2016, KAUST, 11 May 2016 Outline BSC Overview of superscalar programming model
ALYA Multi-Physics System on GPUs: Offloading Large-Scale Computational Mechanics Problems
 www.bsc.es ALYA Multi-Physics System on GPUs: Offloading Large-Scale Computational Mechanics Problems Vishal Mehta Engineer, Barcelona Supercomputing Center vishal.mehta@bsc.es Training BSC/UPC GPU Centre
www.bsc.es ALYA Multi-Physics System on GPUs: Offloading Large-Scale Computational Mechanics Problems Vishal Mehta Engineer, Barcelona Supercomputing Center vishal.mehta@bsc.es Training BSC/UPC GPU Centre
Asynchronous Task Creation for Task-Based Parallel Programming Runtimes
 Asynchronous Task Creation for Task-Based Parallel Programming Runtimes Jaume Bosch (jbosch@bsc.es), Xubin Tan, Carlos Álvarez, Daniel Jiménez, Xavier Martorell and Eduard Ayguadé Barcelona, Sept. 24,
Asynchronous Task Creation for Task-Based Parallel Programming Runtimes Jaume Bosch (jbosch@bsc.es), Xubin Tan, Carlos Álvarez, Daniel Jiménez, Xavier Martorell and Eduard Ayguadé Barcelona, Sept. 24,
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
Introduction to Runtime Systems
 Introduction to Runtime Systems Towards Portability of Performance ST RM Static Optimizations Runtime Methods Team Storm Olivier Aumage Inria LaBRI, in cooperation with La Maison de la Simulation Contents
Introduction to Runtime Systems Towards Portability of Performance ST RM Static Optimizations Runtime Methods Team Storm Olivier Aumage Inria LaBRI, in cooperation with La Maison de la Simulation Contents
StarPU: a runtime system for multigpu multicore machines
 StarPU: a runtime system for multigpu multicore machines Raymond Namyst RUNTIME group, INRIA Bordeaux Journées du Groupe Calcul Lyon, November 2010 The RUNTIME Team High Performance Runtime Systems for
StarPU: a runtime system for multigpu multicore machines Raymond Namyst RUNTIME group, INRIA Bordeaux Journées du Groupe Calcul Lyon, November 2010 The RUNTIME Team High Performance Runtime Systems for
Barcelona Supercomputing Center
 www.bsc.es Barcelona Supercomputing Center Centro Nacional de Supercomputación EMIT 2016. Barcelona June 2 nd, 2016 Barcelona Supercomputing Center Centro Nacional de Supercomputación BSC-CNS objectives:
www.bsc.es Barcelona Supercomputing Center Centro Nacional de Supercomputación EMIT 2016. Barcelona June 2 nd, 2016 Barcelona Supercomputing Center Centro Nacional de Supercomputación BSC-CNS objectives:
The Mont-Blanc Project
 http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
Task Superscalar: Using Processors as Functional Units
 Task Superscalar: Using Processors as Functional Units Yoav Etsion Alex Ramirez Rosa M. Badia Eduard Ayguade Jesus Labarta Mateo Valero HotPar, June 2010 Yoav Etsion Senior Researcher Parallel Programming
Task Superscalar: Using Processors as Functional Units Yoav Etsion Alex Ramirez Rosa M. Badia Eduard Ayguade Jesus Labarta Mateo Valero HotPar, June 2010 Yoav Etsion Senior Researcher Parallel Programming
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
OpenMP tasking model for Ada: safety and correctness
 www.bsc.es www.cister.isep.ipp.pt OpenMP tasking model for Ada: safety and correctness Sara Royuela, Xavier Martorell, Eduardo Quiñones and Luis Miguel Pinho Vienna (Austria) June 12-16, 2017 Parallel
www.bsc.es www.cister.isep.ipp.pt OpenMP tasking model for Ada: safety and correctness Sara Royuela, Xavier Martorell, Eduardo Quiñones and Luis Miguel Pinho Vienna (Austria) June 12-16, 2017 Parallel
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
HSA Foundation! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room (Bld 20)! 15 December, 2017!
! 15 December, 2017!") Advanced Topics on Heterogeneous System Architectures HSA Foundation! Politecnico di Milano! Seminar Room (Bld 20)! 15 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Advanced Topics on Heterogeneous System Architectures HSA Foundation! Politecnico di Milano! Seminar Room (Bld 20)! 15 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Experiences with Achieving Portability across Heterogeneous Architectures
 Experiences with Achieving Portability across Heterogeneous Architectures Lukasz G. Szafaryn +, Todd Gamblin ++, Bronis R. de Supinski ++ and Kevin Skadron + + University of Virginia ++ Lawrence Livermore
Experiences with Achieving Portability across Heterogeneous Architectures Lukasz G. Szafaryn +, Todd Gamblin ++, Bronis R. de Supinski ++ and Kevin Skadron + + University of Virginia ++ Lawrence Livermore
Fundamentals of OmpSs
 www.bsc.es Fundamentals of OmpSs Tasks and Dependences Xavier Teruel New York, June 2013 AGENDA: Fundamentals of OmpSs Tasking and Synchronization Data Sharing Attributes Dependence Model Other Tasking
www.bsc.es Fundamentals of OmpSs Tasks and Dependences Xavier Teruel New York, June 2013 AGENDA: Fundamentals of OmpSs Tasking and Synchronization Data Sharing Attributes Dependence Model Other Tasking
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO
 F. Bodin, CTO") How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing
 Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Shared memory programming model OpenMP TMA4280 Introduction to Supercomputing NTNU, IMF February 16. 2018 1 Recap: Distributed memory programming model Parallelism with MPI. An MPI execution is started
Make the Most of OpenMP Tasking. Sergi Mateo Bellido Compiler engineer
 Make the Most of OpenMP Tasking Sergi Mateo Bellido Compiler engineer 14/11/2017 Outline Intro Data-sharing clauses Cutoff clauses Scheduling clauses 2 Intro: what s a task? A task is a piece of code &
Make the Most of OpenMP Tasking Sergi Mateo Bellido Compiler engineer 14/11/2017 Outline Intro Data-sharing clauses Cutoff clauses Scheduling clauses 2 Intro: what s a task? A task is a piece of code &
ECE 574 Cluster Computing Lecture 10
 ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
OpenMP API Version 5.0
 OpenMP API Version 5.0 (or: Pretty Cool & New OpenMP Stuff) Michael Klemm Chief Executive Officer OpenMP Architecture Review Board michael.klemm@openmp.org Architecture Review Board The mission of the
OpenMP API Version 5.0 (or: Pretty Cool & New OpenMP Stuff) Michael Klemm Chief Executive Officer OpenMP Architecture Review Board michael.klemm@openmp.org Architecture Review Board The mission of the
Design Decisions for a Source-2-Source Compiler
 Design Decisions for a Source-2-Source Compiler Roger Ferrer, Sara Royuela, Diego Caballero, Alejandro Duran, Xavier Martorell and Eduard Ayguadé Barcelona Supercomputing Center and Universitat Politècnica
Design Decisions for a Source-2-Source Compiler Roger Ferrer, Sara Royuela, Diego Caballero, Alejandro Duran, Xavier Martorell and Eduard Ayguadé Barcelona Supercomputing Center and Universitat Politècnica
Parallel Programming. Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops
 Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
OpenCL TM & OpenMP Offload on Sitara TM AM57x Processors
 OpenCL TM & OpenMP Offload on Sitara TM AM57x Processors 1 Agenda OpenCL Overview of Platform, Execution and Memory models Mapping these models to AM57x Overview of OpenMP Offload Model Compare and contrast
OpenCL TM & OpenMP Offload on Sitara TM AM57x Processors 1 Agenda OpenCL Overview of Platform, Execution and Memory models Mapping these models to AM57x Overview of OpenMP Offload Model Compare and contrast
Exploiting Task-Parallelism on GPU Clusters via OmpSs and rcuda Virtualization
 Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
OpenMP Tasking Model Unstructured parallelism
 www.bsc.es OpenMP Tasking Model Unstructured parallelism Xavier Teruel and Xavier Martorell What is a task in OpenMP? Tasks are work units whose execution may be deferred or it can be executed immediately!!!
www.bsc.es OpenMP Tasking Model Unstructured parallelism Xavier Teruel and Xavier Martorell What is a task in OpenMP? Tasks are work units whose execution may be deferred or it can be executed immediately!!!
Turing Architecture and CUDA 10 New Features. Minseok Lee, Developer Technology Engineer, NVIDIA
 Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
! XKaapi : a runtime for highly parallel (OpenMP) application
 application") XKaapi : a runtime for highly parallel (OpenMP) application Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble C2S@Exa 10-11/07/2014 Agenda - context - objective - task model and execution
XKaapi : a runtime for highly parallel (OpenMP) application Thierry Gautier thierry.gautier@inrialpes.fr MOAIS, INRIA, Grenoble C2S@Exa 10-11/07/2014 Agenda - context - objective - task model and execution
HSA foundation! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room A. Alario! 23 November, 2015!
 Advanced Topics on Heterogeneous System Architectures HSA foundation! Politecnico di Milano! Seminar Room A. Alario! 23 November, 2015! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Advanced Topics on Heterogeneous System Architectures HSA foundation! Politecnico di Milano! Seminar Room A. Alario! 23 November, 2015! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model
 www.bsc.es Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model HPC Knowledge Meeting'15 George S. Markomanolis, Jesus Labarta, Oriol Jorba University of Barcelona, Barcelona,
www.bsc.es Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model HPC Knowledge Meeting'15 George S. Markomanolis, Jesus Labarta, Oriol Jorba University of Barcelona, Barcelona,
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP)
") HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Towards a codelet-based runtime for exascale computing. Chris Lauderdale ET International, Inc.
 Towards a codelet-based runtime for exascale computing Chris Lauderdale ET International, Inc. What will be covered Slide 2 of 24 Problems & motivation Codelet runtime overview Codelets & complexes Dealing
Towards a codelet-based runtime for exascale computing Chris Lauderdale ET International, Inc. What will be covered Slide 2 of 24 Problems & motivation Codelet runtime overview Codelets & complexes Dealing
ET International HPC Runtime Software. ET International Rishi Khan SC 11. Copyright 2011 ET International, Inc.
 HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
Session 4: Parallel Programming with OpenMP
 Session 4: Parallel Programming with OpenMP Xavier Martorell Barcelona Supercomputing Center Agenda Agenda 10:00-11:00 OpenMP fundamentals, parallel regions 11:00-11:30 Worksharing constructs 11:30-12:00
Session 4: Parallel Programming with OpenMP Xavier Martorell Barcelona Supercomputing Center Agenda Agenda 10:00-11:00 OpenMP fundamentals, parallel regions 11:00-11:30 Worksharing constructs 11:30-12:00
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
PATC Training. OmpSs and GPUs support. Xavier Martorell Programming Models / Computer Science Dept. BSC
 PATC Training OmpSs and GPUs support Xavier Martorell Programming Models / Computer Science Dept. BSC May 23 rd -24 th, 2012 Outline Motivation OmpSs Examples BlackScholes Perlin noise Julia Set Hands-on
PATC Training OmpSs and GPUs support Xavier Martorell Programming Models / Computer Science Dept. BSC May 23 rd -24 th, 2012 Outline Motivation OmpSs Examples BlackScholes Perlin noise Julia Set Hands-on
TaskGenX: A Hardware-Software Proposal for Accelerating Task Parallelism
 TaskGenX: A Hardware-Software Proposal for Accelerating Task Parallelism Kallia Chronaki, Marc Casas, Miquel Moreto, Jaume Bosch, Rosa M. Badia Barcelona Supercomputing Center, Artificial Intelligence
TaskGenX: A Hardware-Software Proposal for Accelerating Task Parallelism Kallia Chronaki, Marc Casas, Miquel Moreto, Jaume Bosch, Rosa M. Badia Barcelona Supercomputing Center, Artificial Intelligence
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Overview: The OpenMP Programming Model
 Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Hybrid OmpSs OmpSs, MPI and GPUs Guillermo Miranda
 www.bsc.es Hybrid OmpSs OmpSs, MPI and GPUs Guillermo Miranda guillermo.miranda@bsc.es Trondheim, 3 October 2013 Outline OmpSs Programming Model StarSs Comparison with OpenMP Heterogeneity (OpenCL and
www.bsc.es Hybrid OmpSs OmpSs, MPI and GPUs Guillermo Miranda guillermo.miranda@bsc.es Trondheim, 3 October 2013 Outline OmpSs Programming Model StarSs Comparison with OpenMP Heterogeneity (OpenCL and
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Lecture 16: Recapitulations. Lecture 16: Recapitulations p. 1
 Lecture 16: Recapitulations Lecture 16: Recapitulations p. 1 Parallel computing and programming in general Parallel computing a form of parallel processing by utilizing multiple computing units concurrently
Lecture 16: Recapitulations Lecture 16: Recapitulations p. 1 Parallel computing and programming in general Parallel computing a form of parallel processing by utilizing multiple computing units concurrently
15-418, Spring 2008 OpenMP: A Short Introduction
 15-418, Spring 2008 OpenMP: A Short Introduction This is a short introduction to OpenMP, an API (Application Program Interface) that supports multithreaded, shared address space (aka shared memory) parallelism.
15-418, Spring 2008 OpenMP: A Short Introduction This is a short introduction to OpenMP, an API (Application Program Interface) that supports multithreaded, shared address space (aka shared memory) parallelism.
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Advanced Message-Passing Interface (MPI)
") Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Parallel Hybrid Computing Stéphane Bihan, CAPS
 Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
Advanced OpenMP. Lecture 11: OpenMP 4.0
 Advanced OpenMP Lecture 11: OpenMP 4.0 OpenMP 4.0 Version 4.0 was released in July 2013 Starting to make an appearance in production compilers What s new in 4.0 User defined reductions Construct cancellation
Advanced OpenMP Lecture 11: OpenMP 4.0 OpenMP 4.0 Version 4.0 was released in July 2013 Starting to make an appearance in production compilers What s new in 4.0 User defined reductions Construct cancellation
OpenMP: Open Multiprocessing
 OpenMP: Open Multiprocessing Erik Schnetter May 20-22, 2013, IHPC 2013, Iowa City 2,500 BC: Military Invents Parallelism Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to
OpenMP: Open Multiprocessing Erik Schnetter May 20-22, 2013, IHPC 2013, Iowa City 2,500 BC: Military Invents Parallelism Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to
Butterfly effect of porting scientific applications to ARM-based platforms
 montblanc-project.eu @MontBlanc_EU Butterfly effect of porting scientific applications to ARM-based platforms Filippo Mantovani September 12 th, 2017 This project has received funding from the European
montblanc-project.eu @MontBlanc_EU Butterfly effect of porting scientific applications to ARM-based platforms Filippo Mantovani September 12 th, 2017 This project has received funding from the European
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
What is DARMA? DARMA is a C++ abstraction layer for asynchronous many-task (AMT) runtimes.
 runtimes.") DARMA Janine C. Bennett, Jonathan Lifflander, David S. Hollman, Jeremiah Wilke, Hemanth Kolla, Aram Markosyan, Nicole Slattengren, Robert L. Clay (PM) PSAAP-WEST February 22, 2017 Sandia National Laboratories
DARMA Janine C. Bennett, Jonathan Lifflander, David S. Hollman, Jeremiah Wilke, Hemanth Kolla, Aram Markosyan, Nicole Slattengren, Robert L. Clay (PM) PSAAP-WEST February 22, 2017 Sandia National Laboratories
COMP4510 Introduction to Parallel Computation. Shared Memory and OpenMP. Outline (cont d) Shared Memory and OpenMP
 Shared Memory and OpenMP") COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
COMP4510 Introduction to Parallel Computation Shared Memory and OpenMP Thanks to Jon Aronsson (UofM HPC consultant) for some of the material in these notes. Outline (cont d) Shared Memory and OpenMP Including
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators
 Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 17 Shared-memory Programming 1 Outline n OpenMP n Shared-memory model n Parallel for loops n Declaring private variables n Critical
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 17 Shared-memory Programming 1 Outline n OpenMP n Shared-memory model n Parallel for loops n Declaring private variables n Critical
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CLICK TO EDIT MASTER TITLE STYLE. Click to edit Master text styles. Second level Third level Fourth level Fifth level
 CLICK TO EDIT MASTER TITLE STYLE Second level THE HETEROGENEOUS SYSTEM ARCHITECTURE ITS (NOT) ALL ABOUT THE GPU PAUL BLINZER, FELLOW, HSA SYSTEM SOFTWARE, AMD SYSTEM ARCHITECTURE WORKGROUP CHAIR, HSA FOUNDATION
CLICK TO EDIT MASTER TITLE STYLE Second level THE HETEROGENEOUS SYSTEM ARCHITECTURE ITS (NOT) ALL ABOUT THE GPU PAUL BLINZER, FELLOW, HSA SYSTEM SOFTWARE, AMD SYSTEM ARCHITECTURE WORKGROUP CHAIR, HSA FOUNDATION
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
The Parallel Boost Graph Library spawn(active Pebbles)
") The Parallel Boost Graph Library spawn(active Pebbles) Nicholas Edmonds and Andrew Lumsdaine Center for Research in Extreme Scale Technologies Indiana University Origins Boost Graph Library (1999) Generic
The Parallel Boost Graph Library spawn(active Pebbles) Nicholas Edmonds and Andrew Lumsdaine Center for Research in Extreme Scale Technologies Indiana University Origins Boost Graph Library (1999) Generic