CellSs Making it easier to program the Cell Broadband Engine processor
|
|
|
- Thomasine French
- 5 years ago
- Views:
Transcription
1 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat
2 Outline Motivation Architecture of the cell processor Challenges of Cell programming Cell Superscalar Pragma types CellSs compiler CellSs runtime behavior Reducing scheduling overhead Tracing, Scalability, and Performance
3 Motivation Current industry has moved to multicore designs. Increasing the performance of single core processors become difficult due to power consumption and heat dissipation Recent Berkley report mentioned that Current programming methodologies can t be used for more than 16 cores Intel research prototype (80 core) Current methods should be shifted to Maximize human productivity Programming models independent of the cores count Wide range of data types should be supported Task-, word-, and bit-level parallelism
 8 SPEs (Synergistic Processing Element) 256 KB Local Store 3.2 GHz (SP: 25.6 GFlops DP: 1.")
4 Architecture of the Cell Processor 1 PPE (Power Processing Element) 64-bit PowerPC 32 KB Instr/Data L1 Cache, 512 KB L2 Cache SMP (2 threads) 3.2 GHz (SP: 25.6 GFlops DP: 6.4 GFlops) 8 SPEs (Synergistic Processing Element) 256 KB Local Store 3.2 GHz (SP: 25.6 GFlops DP: 1.83 GFlops ) 128-bit Vector Registers EIB (Element Interconnect Bus) Interconnects PPE, SPEs, Memory, I/O Simultaneous Read/Write MIC (Memory Interface Controller) Interfaces to XDR Memory Theoritical B/W of 25.6 GB/s
5 Challenges of Cell Programming Local store is small (256 KB) and not coherent with main memory To execute on SPE, Data is needed to be transferred from main memory to local store using DMA. Efficient execution on SPE requires using vectorized code using single precision data.
6 Cell Superscalar (CellSs) Proposed as a programming model for the multicore Currently focused on the Cell BE. Based on simple annotations (pragmas) to a sequential code. Identify independent parts of the code (tasks) without collateral effects A source-to-source compiler is used to generate the code for both the PPE and SPEs Task dependency graph is built at runtime The runtime system tries to concurrently execute tasks without data dependency on different SPEs Data transfer between main memory and LS is handled by the system
7 Pragma types Initialization and finalization pragmas ccs start and css finish Indicate the beginning and end CellSs applications Task pragmas Before some functions Specify size of arrays and matrices Specify direction of parameters (input, output, and inout) Synchronization pragmas css wait is needed to access data generated by annotated functions

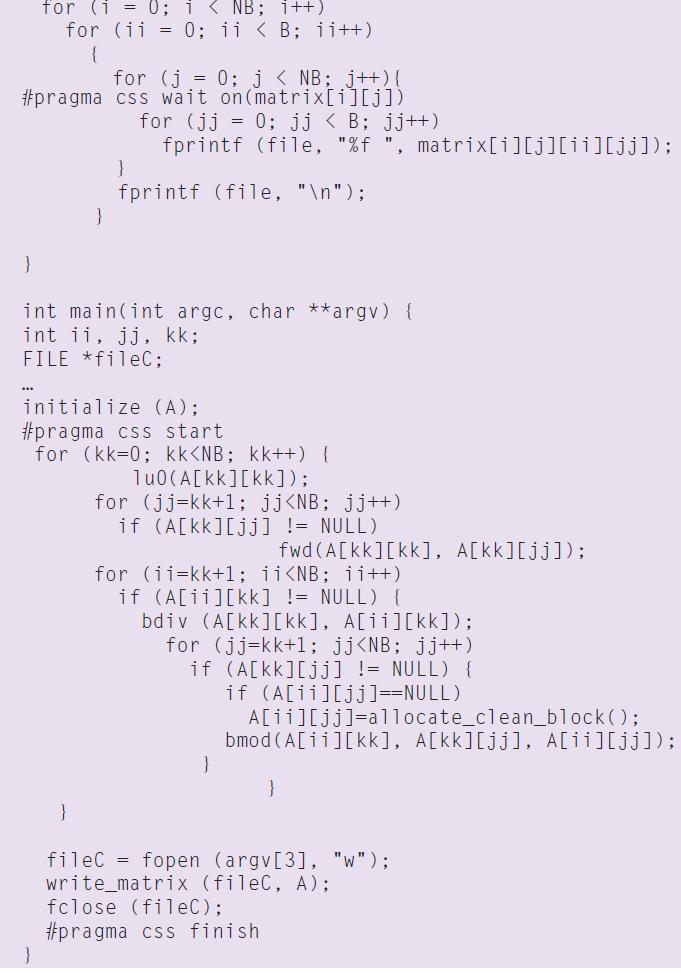
8 Example Sparse LU
9 CellSs Compiler A Source-to-source Generates two files: The main code: to be executed by PPE The task code: to be run by the SPEs In the beginning of the main code, the compiler inserts the following application calls to CellSs runtime Calls to initializing and finalizing functions Calls for registering annotated functions Calls to a CellSs runtime library primitive (css_addtask) wherever a call to one of the annotated functions is found An adapter function for each annotated function is generated These adapters are called from the task main code The two files are compiled with the GCC or the ibm xlc
10 CellSs runtime behavior - 1 CellSs application is called The main thread (master thread)runs on the PPE An additional thread (helper thread) also runs on the PPE In the initialization phase, the CellSs runtime starts as threads in the SPEs and start waiting for requests The master thread adds a task to a task graph whenever it calls the css_addtask An edge is added between tasks that have data dependency The master thread performs parameters renaming to remove WAW (write after write) and WAR (write after read)
11 CellSs runtime behavior - 2 Tasks with no data dependency can be scheduled by the helper thread to execute on SPEs When the task finishes, the task program notifies the helper thread which then Updates the task graph Schedule new tasks for execution in idle SPEs A data structure, called the task control buffer, stores all the infrormation required by the SPE: Task type identifier Initial address and size of each parameter

12 CellSs runtime
13 Reducing scheduling overhead Task are grouped into bundles that are scheduled to one SPE To group the tasks, the following heuristics are followed: Tasks forming a chain are grouped (one predecessor and one successor) Reduces data transfer Totally independent tasks are grouped For more general data dependence organizations, the scheduler tries to form chains To reduce the execution time of a bundle of tasks, double buffering is implemented

14 Scheduling heuristics

15 Double buffering in a task bundle
16 Tracing A tracing component has been embedded in the CellSs runtime It generates postmortem trace files of the application when the main program enters or exits any function of the CellSs library when an annotated function is called in the main program when a task is started or finished These traces can then be analyzed with the Paraver graphical user interface which allows doing performance analysis

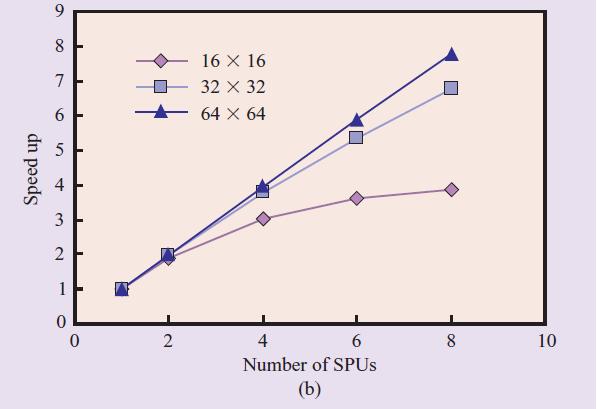
17 Scalability analysis Block matrix multiplication Each block 64 x 64 floats 16 x 16 blocks
18
 The reason for this behavior is that the master thread is busy adding tasks to the task dependency graph most of its time (88% of the time)")
19 Performance results In the paper, The higher performance is obtained with the kernel of the SDK and four SPEs (66.36 Gflops) The reason for this behavior is that the master thread is busy adding tasks to the task dependency graph most of its time (88% of the time) The Barcelona website shows better results!
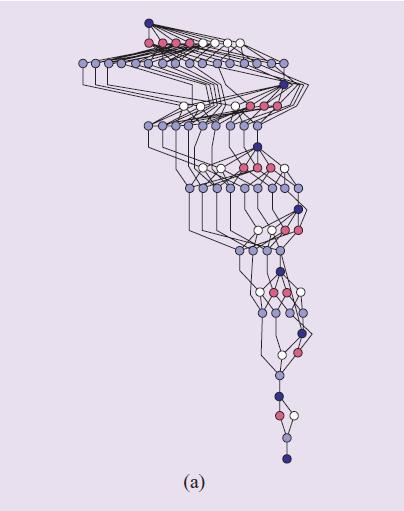
20 Sparse LU

21 Performance analysis using Paraver-1 Green flags: events Yellow lines: communications between SPE threads and the helper thread Blue: activity
 Brown: SPE")
22 Performance analysis using Paraver-2 Another view of Paraver Yellow : DMA transfer (SPE) Brown: SPE executing
23
24 Related work IBM Cell/B.E. OpenMP compiler Enable OpenMP model Optimization of scalar code execution autosmidization Overlap data transfer with computation IBM Roadrunner AMD Opteron processors are host elements and the Cell/BE. Blades are accelerator elements Accelerated Library Framework Based on work queues Supports (SPMD) programming style (Single program running on all accelerator elements at one time Provides interface to easily partition data across a set of parallel processors
25 Related work Sequoia Decompose of a program into tasks (like CellSs) Tasks can call themselves recursively The leaf task implementation RapidMind Provides a set of data types, control flow macros, reduction operations, and common functions that allow the runtime library to capture a representation of the SPE code Data types express SIMD easily The runtime extracts parallelism from those operations by vetcorizing the code and by splitting array and vector calculations on different SPEs
26 Conclusions The objective is to offer a simple and flexible programming model for parallel and heterogeneous architectures Using CellSs, Cell Applications can be written as sequential programs Scheduling is based on a task-dependency graph of annotated functions Scheduling is locality aware CellSs is different from OpenMP as the latter requires the programmer to explicitly indicates what is parallel and what is not. OpenMP is more appropriate for applications with parallelism at the loop level, while CellSs fits better for parallelism at the function level
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
Cell Processor and Playstation 3
 Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
Cell Processor and Playstation 3 Guillem Borrell i Nogueras February 24, 2009 Cell systems Bad news More bad news Good news Q&A IBM Blades QS21 Cell BE based. 8 SPE 460 Gflops Float 20 GFLops Double QS22
CellSs: a Programming Model for the Cell BE Architecture
 CellSs: a Programming Model for the Cell BE Architecture Pieter Bellens, Josep M. Perez, Rosa M. Badia and Jesus Labarta Barcelona Supercomputing Center and UPC Building Nexus II, Jordi Girona 29, Barcelona
CellSs: a Programming Model for the Cell BE Architecture Pieter Bellens, Josep M. Perez, Rosa M. Badia and Jesus Labarta Barcelona Supercomputing Center and UPC Building Nexus II, Jordi Girona 29, Barcelona
( ZIH ) Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems
 Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems") ( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
Evaluating the Portability of UPC to the Cell Broadband Engine
 Evaluating the Portability of UPC to the Cell Broadband Engine Dipl. Inform. Ruben Niederhagen JSC Cell Meeting CHAIR FOR OPERATING SYSTEMS Outline Introduction UPC Cell UPC on Cell Mapping Compiler and
Evaluating the Portability of UPC to the Cell Broadband Engine Dipl. Inform. Ruben Niederhagen JSC Cell Meeting CHAIR FOR OPERATING SYSTEMS Outline Introduction UPC Cell UPC on Cell Mapping Compiler and
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Parallel Exact Inference on the Cell Broadband Engine Processor
 Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, prasanna}@usc.edu University of Southern California http://ceng.usc.edu/~prasanna/ SC 08 Overview
Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, prasanna}@usc.edu University of Southern California http://ceng.usc.edu/~prasanna/ SC 08 Overview
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Accelerated Library Framework for Hybrid-x86
 Software Development Kit for Multicore Acceleration Version 3.0 Accelerated Library Framework for Hybrid-x86 Programmer s Guide and API Reference Version 1.0 DRAFT SC33-8406-00 Software Development Kit
Software Development Kit for Multicore Acceleration Version 3.0 Accelerated Library Framework for Hybrid-x86 Programmer s Guide and API Reference Version 1.0 DRAFT SC33-8406-00 Software Development Kit
Compilation for Heterogeneous Platforms
 Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Cell Broadband Engine. Spencer Dennis Nicholas Barlow
 Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor Objective: [to bring] supercomputer power to everyday life Bridge the gap between conventional CPU s and high performance GPU s History
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Task Superscalar: Using Processors as Functional Units
 Task Superscalar: Using Processors as Functional Units Yoav Etsion Alex Ramirez Rosa M. Badia Eduard Ayguade Jesus Labarta Mateo Valero HotPar, June 2010 Yoav Etsion Senior Researcher Parallel Programming
Task Superscalar: Using Processors as Functional Units Yoav Etsion Alex Ramirez Rosa M. Badia Eduard Ayguade Jesus Labarta Mateo Valero HotPar, June 2010 Yoav Etsion Senior Researcher Parallel Programming
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
Amir Khorsandi Spring 2012
 Introduction to Amir Khorsandi Spring 2012 History Motivation Architecture Software Environment Power of Parallel lprocessing Conclusion 5/7/2012 9:48 PM ٢ out of 37 5/7/2012 9:48 PM ٣ out of 37 IBM, SCEI/Sony,
Introduction to Amir Khorsandi Spring 2012 History Motivation Architecture Software Environment Power of Parallel lprocessing Conclusion 5/7/2012 9:48 PM ٢ out of 37 5/7/2012 9:48 PM ٣ out of 37 IBM, SCEI/Sony,
A Case for Hardware Task Management Support for the StarSS Programming Model
 A Case for Hardware Task Management Support for the StarSS Programming Model Cor Meenderinck Delft University of Technology Delft, the Netherlands cor@ce.et.tudelft.nl Ben Juurlink Technische Universität
A Case for Hardware Task Management Support for the StarSS Programming Model Cor Meenderinck Delft University of Technology Delft, the Netherlands cor@ce.et.tudelft.nl Ben Juurlink Technische Universität
Computer Engineering Mekelweg 4, 2628 CD Delft The Netherlands MSc THESIS
 Computer Engineering Mekelweg 4, 2628 CD Delft The Netherlands http://ce.et.tudelft.nl/ 2010 MSc THESIS Implementation of Nexus: Dynamic Hardware Management Support for Multicore Platforms Efrén Fernández
Computer Engineering Mekelweg 4, 2628 CD Delft The Netherlands http://ce.et.tudelft.nl/ 2010 MSc THESIS Implementation of Nexus: Dynamic Hardware Management Support for Multicore Platforms Efrén Fernández
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
High Performance Computing. University questions with solution
 High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Sony/Toshiba/IBM (STI) CELL Processor. Scientific Computing for Engineers: Spring 2008
 CELL Processor. Scientific Computing for Engineers: Spring 2008") Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
Technology Trends Presentation For Power Symposium
 Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
The Pennsylvania State University. The Graduate School. College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM
 The Pennsylvania State University The Graduate School College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM FOR THE IBM CELL BROADBAND ENGINE A Thesis in Computer Science and Engineering by
The Pennsylvania State University The Graduate School College of Engineering PFFTC: AN IMPROVED FAST FOURIER TRANSFORM FOR THE IBM CELL BROADBAND ENGINE A Thesis in Computer Science and Engineering by
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
A Streaming Computation Framework for the Cell Processor. Xin David Zhang
 A Streaming Computation Framework for the Cell Processor by Xin David Zhang Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the
A Streaming Computation Framework for the Cell Processor by Xin David Zhang Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the
The SARC Architecture
 The SARC Architecture Polo Regionale di Como of the Politecnico di Milano Advanced Computer Architecture Arlinda Imeri arlinda.imeri@mail.polimi.it 19-Jun-12 Advanced Computer Architecture - The SARC Architecture
The SARC Architecture Polo Regionale di Como of the Politecnico di Milano Advanced Computer Architecture Arlinda Imeri arlinda.imeri@mail.polimi.it 19-Jun-12 Advanced Computer Architecture - The SARC Architecture
QDP++/Chroma on IBM PowerXCell 8i Processor
 QDP++/Chroma on IBM PowerXCell 8i Processor Frank Winter (QCDSF Collaboration) frank.winter@desy.de University Regensburg NIC, DESY-Zeuthen STRONGnet 2010 Conference Hadron Physics in Lattice QCD Paphos,
QDP++/Chroma on IBM PowerXCell 8i Processor Frank Winter (QCDSF Collaboration) frank.winter@desy.de University Regensburg NIC, DESY-Zeuthen STRONGnet 2010 Conference Hadron Physics in Lattice QCD Paphos,
Multicore Challenge in Vector Pascal. P Cockshott, Y Gdura
 Multicore Challenge in Vector Pascal P Cockshott, Y Gdura N-body Problem Part 1 (Performance on Intel Nehalem ) Introduction Data Structures (1D and 2D layouts) Performance of single thread code Performance
Multicore Challenge in Vector Pascal P Cockshott, Y Gdura N-body Problem Part 1 (Performance on Intel Nehalem ) Introduction Data Structures (1D and 2D layouts) Performance of single thread code Performance
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP
 Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures
 A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
Cell Programming Maciej Cytowski (ICM) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany
 PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany") Cell Programming Maciej Cytowski (ICM) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany Agenda Introduction to technology Cell programming models SPE runtime management
Cell Programming Maciej Cytowski (ICM) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany Agenda Introduction to technology Cell programming models SPE runtime management
Performance Analysis of Cell Broadband Engine for High Memory Bandwidth Applications
 Performance Analysis of Cell Broadband Engine for High Memory Bandwidth Applications Daniel Jiménez-González, Xavier Martorell, Alex Ramírez Computer Architecture Department Universitat Politècnica de
Performance Analysis of Cell Broadband Engine for High Memory Bandwidth Applications Daniel Jiménez-González, Xavier Martorell, Alex Ramírez Computer Architecture Department Universitat Politècnica de
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
A Buffered-Mode MPI Implementation for the Cell BE Processor
 A Buffered-Mode MPI Implementation for the Cell BE Processor Arun Kumar 1, Ganapathy Senthilkumar 1, Murali Krishna 1, Naresh Jayam 1, Pallav K Baruah 1, Raghunath Sharma 1, Ashok Srinivasan 2, Shakti
A Buffered-Mode MPI Implementation for the Cell BE Processor Arun Kumar 1, Ganapathy Senthilkumar 1, Murali Krishna 1, Naresh Jayam 1, Pallav K Baruah 1, Raghunath Sharma 1, Ashok Srinivasan 2, Shakti
CISC 879 Software Support for Multicore Architectures Spring Student Presentation 6: April 8. Presenter: Pujan Kafle, Deephan Mohan
 CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
Parallel and Distributed Computing
 Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Towards Efficient Video Compression Using Scalable Vector Graphics on the Cell Broadband Engine
 Towards Efficient Video Compression Using Scalable Vector Graphics on the Cell Broadband Engine Andreea Sandu, Emil Slusanschi, Alin Murarasu, Andreea Serban, Alexandru Herisanu, Teodor Stoenescu University
Towards Efficient Video Compression Using Scalable Vector Graphics on the Cell Broadband Engine Andreea Sandu, Emil Slusanschi, Alin Murarasu, Andreea Serban, Alexandru Herisanu, Teodor Stoenescu University
Software Development Kit for Multicore Acceleration Version 3.0
 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
Scheduling of QR Factorization Algorithms on SMP and Multi-core Architectures
 Scheduling of Algorithms on SMP and Multi-core Architectures Gregorio Quintana-Ortí Enrique S. Quintana-Ortí Ernie Chan Robert A. van de Geijn Field G. Van Zee quintana@icc.uji.es Universidad Jaime I de
Scheduling of Algorithms on SMP and Multi-core Architectures Gregorio Quintana-Ortí Enrique S. Quintana-Ortí Ernie Chan Robert A. van de Geijn Field G. Van Zee quintana@icc.uji.es Universidad Jaime I de
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Portable Parallel Programming for Multicore Computing
 Portable Parallel Programming for Multicore Computing? Vivek Sarkar Rice University vsarkar@rice.edu FPU ISU ISU FPU IDU FXU FXU IDU IFU BXU U U IFU BXU L2 L2 L2 L3 D Acknowledgments Rice Habanero Multicore
Portable Parallel Programming for Multicore Computing? Vivek Sarkar Rice University vsarkar@rice.edu FPU ISU ISU FPU IDU FXU FXU IDU IFU BXU U U IFU BXU L2 L2 L2 L3 D Acknowledgments Rice Habanero Multicore
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
A parallel patch based algorithm for CT image denoising on the Cell Broadband Engine
 A parallel patch based algorithm for CT image denoising on the Cell Broadband Engine Dominik Bartuschat, Markus Stürmer, Harald Köstler and Ulrich Rüde Friedrich-Alexander Universität Erlangen-Nürnberg,Germany
A parallel patch based algorithm for CT image denoising on the Cell Broadband Engine Dominik Bartuschat, Markus Stürmer, Harald Köstler and Ulrich Rüde Friedrich-Alexander Universität Erlangen-Nürnberg,Germany
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Arquitecturas y Modelos de. Multicore
 Arquitecturas y Modelos de rogramacion para Multicore 17 Septiembre 2008 Castellón Eduard Ayguadé Alex Ramírez Opening statements * Some visionaries already predicted multicores 30 years ago And they have
Arquitecturas y Modelos de rogramacion para Multicore 17 Septiembre 2008 Castellón Eduard Ayguadé Alex Ramírez Opening statements * Some visionaries already predicted multicores 30 years ago And they have
Memory Architectures. Week 2, Lecture 1. Copyright 2009 by W. Feng. Based on material from Matthew Sottile.
 Week 2, Lecture 1 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. Directory-Based Coherence Idea Maintain pointers instead of simple states with each cache block. Ingredients Data owners
Week 2, Lecture 1 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. Directory-Based Coherence Idea Maintain pointers instead of simple states with each cache block. Ingredients Data owners
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
QDP++ on Cell BE WEI WANG. June 8, 2009
 QDP++ on Cell BE WEI WANG June 8, 2009 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2009 Abstract The Cell BE provides large peak floating point performance with
QDP++ on Cell BE WEI WANG June 8, 2009 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2009 Abstract The Cell BE provides large peak floating point performance with
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
MapReduce on the Cell Broadband Engine Architecture. Marc de Kruijf
 MapReduce on the Cell Broadband Engine Architecture Marc de Kruijf Overview Motivation MapReduce Cell BE Architecture Design Performance Analysis Implementation Status Future Work What is MapReduce? A
MapReduce on the Cell Broadband Engine Architecture Marc de Kruijf Overview Motivation MapReduce Cell BE Architecture Design Performance Analysis Implementation Status Future Work What is MapReduce? A
4. Shared Memory Parallel Architectures
 Master rogram (Laurea Magistrale) in Computer cience and Networking High erformance Computing ystems and Enabling latforms Marco Vanneschi 4. hared Memory arallel Architectures 4.4. Multicore Architectures
Master rogram (Laurea Magistrale) in Computer cience and Networking High erformance Computing ystems and Enabling latforms Marco Vanneschi 4. hared Memory arallel Architectures 4.4. Multicore Architectures
Halfway! Sequoia. A Point of View. Sequoia. First half of the course is over. Now start the second half. CS315B Lecture 9
 Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
Introduction to Computing and Systems Architecture
 Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Chap. 2 part 1. CIS*3090 Fall Fall 2016 CIS*3090 Parallel Programming 1
 Chap. 2 part 1 CIS*3090 Fall 2016 Fall 2016 CIS*3090 Parallel Programming 1 Provocative question (p30) How much do we need to know about the HW to write good par. prog.? Chap. gives HW background knowledge
Chap. 2 part 1 CIS*3090 Fall 2016 Fall 2016 CIS*3090 Parallel Programming 1 Provocative question (p30) How much do we need to know about the HW to write good par. prog.? Chap. gives HW background knowledge
Optimizing Assignment of Threads to SPEs on the Cell BE Processor
 Optimizing Assignment of Threads to SPEs on the Cell BE Processor T. Nagaraju P.K. Baruah Ashok Srinivasan Abstract The Cell is a heterogeneous multicore processor that has attracted much attention in
Optimizing Assignment of Threads to SPEs on the Cell BE Processor T. Nagaraju P.K. Baruah Ashok Srinivasan Abstract The Cell is a heterogeneous multicore processor that has attracted much attention in
OpenMPSuperscalar: Task-Parallel Simulation and Visualization of Crowds with Several CPUs and GPUs
 www.bsc.es OpenMPSuperscalar: Task-Parallel Simulation and Visualization of Crowds with Several CPUs and GPUs Hugo Pérez UPC-BSC Benjamin Hernandez Oak Ridge National Lab Isaac Rudomin BSC March 2015 OUTLINE
www.bsc.es OpenMPSuperscalar: Task-Parallel Simulation and Visualization of Crowds with Several CPUs and GPUs Hugo Pérez UPC-BSC Benjamin Hernandez Oak Ridge National Lab Isaac Rudomin BSC March 2015 OUTLINE
SciDAC CScADS Summer Workshop on Libraries and Algorithms for Petascale Applications
 Parallel Tiled Algorithms for Multicore Architectures Alfredo Buttari, Jack Dongarra, Jakub Kurzak and Julien Langou SciDAC CScADS Summer Workshop on Libraries and Algorithms for Petascale Applications
Parallel Tiled Algorithms for Multicore Architectures Alfredo Buttari, Jack Dongarra, Jakub Kurzak and Julien Langou SciDAC CScADS Summer Workshop on Libraries and Algorithms for Petascale Applications
Iuliana Bacivarov, Wolfgang Haid, Kai Huang, Lars Schor, and Lothar Thiele
 Iuliana Bacivarov, Wolfgang Haid, Kai Huang, Lars Schor, and Lothar Thiele ETH Zurich, Switzerland Efficient i Execution on MPSoC Efficiency regarding speed-up small memory footprint portability Distributed
Iuliana Bacivarov, Wolfgang Haid, Kai Huang, Lars Schor, and Lothar Thiele ETH Zurich, Switzerland Efficient i Execution on MPSoC Efficiency regarding speed-up small memory footprint portability Distributed
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Optimizing DMA Data Transfers for Embedded Multi-Cores
 Optimizing DMA Data Transfers for Embedded Multi-Cores Selma Saïdi Jury members: Oded Maler: Dir. de these Ahmed Bouajjani: President du Jury Luca Benini: Rapporteur Albert Cohen: Rapporteur Eric Flamand:
Optimizing DMA Data Transfers for Embedded Multi-Cores Selma Saïdi Jury members: Oded Maler: Dir. de these Ahmed Bouajjani: President du Jury Luca Benini: Rapporteur Albert Cohen: Rapporteur Eric Flamand:
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Cell Programming Tips & Techniques
 Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
Exploration of Cache Coherent CPU- FPGA Heterogeneous System
 Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
A Transport Kernel on the Cell Broadband Engine
 A Transport Kernel on the Cell Broadband Engine Paul Henning Los Alamos National Laboratory LA-UR 06-7280 Cell Chip Overview Cell Broadband Engine * (Cell BE) Developed under Sony-Toshiba-IBM efforts Current
A Transport Kernel on the Cell Broadband Engine Paul Henning Los Alamos National Laboratory LA-UR 06-7280 Cell Chip Overview Cell Broadband Engine * (Cell BE) Developed under Sony-Toshiba-IBM efforts Current
Optimizing JPEG2000 Still Image Encoding on the Cell Broadband Engine
 37th International Conference on Parallel Processing Optimizing JPEG2000 Still Image Encoding on the Cell Broadband Engine Seunghwa Kang David A. Bader Georgia Institute of Technology, Atlanta, GA 30332
37th International Conference on Parallel Processing Optimizing JPEG2000 Still Image Encoding on the Cell Broadband Engine Seunghwa Kang David A. Bader Georgia Institute of Technology, Atlanta, GA 30332
Binding Nested OpenMP Programs on Hierarchical Memory Architectures
 Binding Nested OpenMP Programs on Hierarchical Memory Architectures Dirk Schmidl, Christian Terboven, Dieter an Mey, and Martin Bücker {schmidl, terboven, anmey}@rz.rwth-aachen.de buecker@sc.rwth-aachen.de
Binding Nested OpenMP Programs on Hierarchical Memory Architectures Dirk Schmidl, Christian Terboven, Dieter an Mey, and Martin Bücker {schmidl, terboven, anmey}@rz.rwth-aachen.de buecker@sc.rwth-aachen.de
Reconstruction of Trees from Laser Scan Data and further Simulation Topics
 Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
Interconnection of Clusters of Various Architectures in Grid Systems
 Journal of Applied Computer Science & Mathematics, no. 12 (6) /2012, Suceava Interconnection of Clusters of Various Architectures in Grid Systems 1 Ovidiu GHERMAN, 2 Ioan UNGUREAN, 3 Ştefan G. PENTIUC
Journal of Applied Computer Science & Mathematics, no. 12 (6) /2012, Suceava Interconnection of Clusters of Various Architectures in Grid Systems 1 Ovidiu GHERMAN, 2 Ioan UNGUREAN, 3 Ştefan G. PENTIUC
Programming for Performance on the Cell BE processor & Experiences at SSSU. Sri Sathya Sai University
 Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Speculative Synchronization
 Speculative Synchronization José F. Martínez Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/martinez Problem 1: Conservative Parallelization No parallelization
Speculative Synchronization José F. Martínez Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/martinez Problem 1: Conservative Parallelization No parallelization
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
A Comparison of Programming Models for Multiprocessors with Explicitly Managed Memory Hierarchies
 A Comparison of Programming Models for Multiprocessors with Explicitly Managed Memory Hierarchies Scott Schneider Jae-Seung Yeom Benjamin Rose John C. Linford Adrian Sandu Dimitrios S. Nikolopoulos Department
A Comparison of Programming Models for Multiprocessors with Explicitly Managed Memory Hierarchies Scott Schneider Jae-Seung Yeom Benjamin Rose John C. Linford Adrian Sandu Dimitrios S. Nikolopoulos Department
Cell Broadband Engine Overview
 Cell Broadband Engine Overview Course Code: L1T1H1-02 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn An overview of Cell history Cell microprocessor highlights Hardware architecture
Cell Broadband Engine Overview Course Code: L1T1H1-02 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn An overview of Cell history Cell microprocessor highlights Hardware architecture
A Synchronous Mode MPI Implementation on the Cell BE Architecture
 A Synchronous Mode MPI Implementation on the Cell BE Architecture Murali Krishna 1, Arun Kumar 1, Naresh Jayam 1, Ganapathy Senthilkumar 1, Pallav K Baruah 1, Raghunath Sharma 1, Shakti Kapoor 2, Ashok
A Synchronous Mode MPI Implementation on the Cell BE Architecture Murali Krishna 1, Arun Kumar 1, Naresh Jayam 1, Ganapathy Senthilkumar 1, Pallav K Baruah 1, Raghunath Sharma 1, Shakti Kapoor 2, Ashok