ECE5610/CSC6220 Models of Parallel Computers. Recap: What is Parallel Computer?
|
|
|
- Roland Campbell
- 6 years ago
- Views:
Transcription
1 ECE5610/CSC6220 Models of Parallel Computers Professor Cheng-Zhong Xu Department of Electrical/Computer Engineering Wayne State University Recap: What is Parallel Computer? A parallel computer is a collection of processing elements that cooperate to solve large problems fast Some broad issues: Resource Allocation: how large a collection? how powerful are the elements? how much? Data access, Communication and Synchronization how do the elements cooperate and communicate? how are data transmitted between processors? what are the abstractions and primitives for cooperation? Performance and Scalability how does it all translate into performance? how does it scale? 2 1
2 Recap: WhyParallel Computing Application demands: Computer simulation becomes the third pillar, complementing the activities of theory and experimentation General -purpose computing: Video, Graphics, CAD, Database, etc Our insatiable need for computing cycles in challenge applications Technology Trends Number of transistors on chip growing rapidly Clock rates expected to go up only slowly Architecture Trends Instruction-level parallelism valuable but limited Coarser-level parallelism, as in MPs, the most viable approach Economics 3 Parallel Computing Models Historically (1970s - early 1990s), each parallel machine was unique, along with its programming model and language Throw away software & start over with each new kind of machine Dead Supercomputer Society: Nowadays we separate the programming model from the underlying parallel machine architecture. 3 or 4 dominant programming models This is still research 4 2
3 Parallel Model for Various Arch. Can now write portably correct code that runs on lots of machines Writing portably fast code requires tuning for the architecture Not always worth it sometimes programmer time is more important Challenge: design algorithms to make this tuning easy 5 Aspects of a parallel programming model Control how is parallelism created what order can operations happen in how do different threads of control synchronize Naming what data is private vs. shared how shared data is accessed (or communicated) Operations what are the basic operations what operations are atomic Cost how do we account for the cost of operations 6 3
4 A generic parallel architecture Network Mem Communication assist (CA) $ P Where is the physically located? 7 Parallel Programming Models Shared Address Space (SAS) Message Passing (MP) Data parallel (DP) 8 4
5 Simple example: Sum f(a[i]) from i=1 to i=n Parallel decomposition: Each evaluation of f and each partial sum is a task Assign n/p numbers to each of p processes each computes independent private results and partial sum one (or all) collects the p partial sums and computes the global sum Classes of Data: (Logically) Shared the original n numbers, the global sum (Logically) Private the individual function values what about the individual partial sums? 9 Programming Model 1: Shared Memory Program is a collection of threads of control. Can be created dynamically, mid-execution, in some languages Each thread has a set of private variables, e.g., local stack variables Also a set of shared variables, e.g., static variables, shared common blocks, or global heap. Threads communicate implicitly by writing and reading shared variables. Threads coordinate by synchronizing on shared variables y =..s... i: 2 i: 5 Private P0 P1 s Shared s =... Pn i:
6 SAS Code for Computing a Sum static int s = 0; Thread 1 for i = 0, n/2-1 s = s + f(a[i]) Thread 2 for i = n/2, n-1 s = s + f(a[i]) Problem: a race condition on variable s in the program A race condition or data race occurs when: - two processors (or two threads) access the same variable, and at least one does a write. - The accesses are concurrent (not synchronized) so they could happen simultaneously 11 SAS Code: Race Condition static int s = 0; Thread 1. compute f([a[i]) and put in reg0 reg1 = s reg1 = reg1 + reg0 s = reg Thread 2 compute f([a[i]) and put in reg0 reg1 = s reg1 = reg1 + reg s = reg1 36 Suppose s=27, f(a[i])=7 on Thread1 and =9 on Thread2 For this program to work, s should be 43 at the end but it may be 43, 34, or 36 The atomic operations are reads and writes 12 6
7 Synchronized SAS Code static int s = 0; static lock lk; Thread 1 Thread 2 local_s1= 0 for i = 0, n/2-1 local_s1 = local_s1 + f(a[i]) lock(lk); s = s + local_s1 unlock(lk); local_s2 = 0 for i = n/2, n-1 local_s2= local_s2 + f(a[i]) lock(lk); s = s +local_s2 unlock(lk); Since addition is associative, it s OK to rearrange order Most computation is on private variables - Sharing frequency is also reduced, which might improve speed - But there is still a race condition on the update of shared s - The race condition can be fixed by adding locks - Only one thread can hold a lock at a time; others wait for it 13 SAS Machine Architecture Any processor can directly reference any location Comm occurs implicitly as result of loads and stores SAS Programming model Similar to time-sharing on uniprocessors Except processes run on different processors Good throughput on multi-programmed workloads Naturally provided on wide range of platforms History dates to precursors of mainframes in early 60s Wide range of scale: few to hundreds of processors Popularly known as shared machines or model Ambiguous: may be physically distributed among processors 14 7


8 Example: Intel Pentium Pro Quad CPU Interrupt controller Bus interface 256-KB L 2 $ P-Pro module P-Pro module P-Pro module P-Pro bus (64-bit data, 36-bit address, 66 MHz) PCI bridge PCI bridge Memory controller PCI I/O cards PCI bus PCI bus MIU 1-, 2-, or 4-way interleaved DRAM All coherence and multiprocessing glue in processor module Highly integrated, targeted at high volume Low latency and bandwidth 15 Example: SUN Enterprise P $ P $ CPU/mem cards $ 2 $ 2 Mem ctrl Bus interface/switch Gigaplane bus (256 data, 41 address, 83 MHz) Bus interface I/O cards 100bT, SCSI SBUS SBUS SBUS 2 FiberChannel 16 cards of either type: processors +, or I/O All accessed over bus, so symmetric Higher bandwidth, higher latency bus 16 8
9 SAS Machine Model Processors all connected to a large shared Symmetric Multiprocessors (SMPs) Small scale: < 32 processors typically P1 P2 Pn c c c network 17 M M M Scaling Up Network Network $ $ $ M $ M $ M $ P P P P P P Dance hall Distributed Shared Dance-hall: bandwidth still scalable, but lower cost than crossbar latencies to uniform, but uniformly large (Uniform Memory Access) Distributed shared (DSM) or non-uniform access (NUMA) Construct shared address space out of simple message transactions across a general-purpose network 18 9

10 Distributed Shared Memory Memory is logically shared, but physically distributed Any processor can access any address in Cache lines (or pages) are passed around machine SGI Origin is a canonical example Scales to 100s Limitation is cache coherent protocols need to keep cached copies of the same address consistent P1 P2 Pn $ $ network $ 19 Example: Cray T3E External I/O P $ Mem Mem ctrl and NI XY Switch Z Scale up to 1024 processors, 480MB/s links Memory controller generates comm. request for nonlocal references No hardware mechanism for coherence (SGI Origin etc. provide this) 20 10
11 Shared Address Space Abstraction Virtual Address Space vs Physical Address Space Virtual address spaces for a collection of processes communicating via shared addresses Machine physical address space P n pr i vat e Load P n P 1 P 2 Common physical addresses P 0 St or e Shared portion of address space P 2 pr i vat e Private portion of address space P 1 pr i vat e P 0 pr i vat e Natural extension of uni-proc model: conventional mem operations for comm special atomic operations for synchronization OS uses shared to coordinate processes 21 Programming Model 2: Message Passing Program consists of a collection of named processes. Usually fixed at program startup time Thread of control plus local address space -- NO shared data. Logically shared data is partitioned over local processes. Processes communicate by explicit send/receive pairs Coordination is implicit in every communication event. Private y =..s... s: 12 i: 2 s: 14 i: 3 receive Pn,s s: 11 i: 1 P0 P1 send P1,s Pn Network 22 11
12 Computing s = A[1]+A[2] on each process First possible solution what could go wrong? Processor 1 xlocal = A[1] send xlocal, proc2 receive xremote, proc2 s = xlocal + xremote Processor 2 xlocal = A[2] send xlocal, proc1 receive xremote, proc1 s = xlocal + xremote If send/receive acts like the telephone system? synchronous comm The post office? asynchronous comm 23 Message Passing Architectures Complete processing node as building block, including I/O Communication via explicit I/O operations Processor/Memory/IO form a processing node cannot directly access another processor s. Each node has a network interface (NI) for all communication and synchronization. MP Programming model: directly access only private address space (local ), comm. via explicit messages (send/receive) P1 NI P2 NI Pn NI... interconnect 24 12


13 Example: IBM SP-2 Power 2 CPU IBM SP-2 node L 2 $ Memory bus General interconnection network formed from 8-port switches Memory controller 4-way interleaved DRAM MicroChannel bus NIC I/O i860 DMA NI DRAM Made out of essentially complete RS6000 workstations Network interface integrated in I/O bus (bw limited by I/O bus) 25 Example Intel Paragon i860 L 1 $ i860 L 1 $ Intel Paragon node Memory bus (64-bit, 50 MHz) Mem ctrl DMA Sandia s Intel Paragon XP/S-based Supercomputer 4-way interleaved DRAM Driver NI 2D grid network with processing node attached to every switch 8 bits, 175 MHz, bidirectional 26 13
14 Message-Passing Abstraction Process P Address X Local Process Address Space Send X, Q, t Match, Receive Y, P, t Process Q Address Y Local Process Address Space Send specifies buffer to be transmitted and receiving process Recv specifies sending process and application storage to receive into Memory to copy, but need to name processes Optional tag on send and matching rule on receive User process names local data and entities in process/tag space too In simplest form, the send/recv match achieves pairwise synch event Other variants too Many overheads: copying, buffer management, protection 27 DSM vs Message Passing P1 NI P2 NI Pn NI... interconnect High-level block diagram similar to distributed- SAS But comm. integrated at IO level, needn t be into system Like networks of workstations (clusters), but tighter integration Easier to build than scalable SAS MP model removed from basic hardware operations Library or OS intervention 28 14
15 Programming Model 3: Data Parallel Single thread of control consisting of parallel operations. Parallel operations applied to all (or a defined subset) of a data structure, usually an array Communication is implicit in parallel operators Elegant and easy to understand and reason about Coordination is implicit statements executed synchronously Similar to Matlab language for array operations Drawbacks: Not all problems fit this model Difficult to map onto coarse-grained machines A = array of all data fa = f(a) s = sum(fa) A: fa: s: f sum 29 SIMD Arch for DP Model Single Instruction Stream Multiple Data Stream (SIMD) A single control processor issues each instruction Array of many simple, cheap processsors with little each processor executes the same instruction Some processors may be turned off on some instructions Specialized and general communication, cheap global synchronization control processor P1 NI P1 NI P1 NI... P1 NI P1 NI interconnect 30 15
16 Application of Data Parallelism Each PE contains an employee record with his/her salary If salary > 100K then salary = salary *1.05 else salary = salary *1.10 Logically, the whole operation is a single step Some processors enabled for arithmetic operation, others disabled Other examples: Finite differences, linear algebra,... Document searching, graphics, image processing,... Some recent machines: Thinking Machines CM-1, CM-2 (and CM-5), Maspar MP-1 and MP-2. Built-in feature on modern CPU 31 Vector Machine for DP Model Vector architectures are based on a single processor Multiple functional units All performing the same operation Instructions may specific large amounts of parallelism (e.g., 64- way) but hardware executes only a subset in parallel Historically important Overtaken by MPPs in the 90s Re-emerging in recent years At a large scale in the Earth Simulator (NEC SX6) and Cray X1 At a small sale in SIMD media extensions to microprocessors SSE, SSE2 (Intel: Pentium/IA64) Altivec (IBM/Motorola/Apple: PowerPC) VIS (Sun: Sparc) Key idea: Compiler does some of the difficult work of finding parallelism, so the hardware doesn t have to 32 16
17 Vector Processors Vector instructions operate on a vector of elements These are specified as operations on vector registers r1 r3 r2 vr1 + + A supercomputer vector register holds ~32-64 elts The number of elements is larger than the amount of parallel hardware, called vector pipes or lanes, say 2-4 The hardware performs a full vector operation in vr3 #elements-per-vector-register / #pipes vr2 (logically, performs # elts adds in parallel) vr1 vr (actually, performs # pipes adds in parallel) 33 Cray X1 Node Cray X1 builds a larger virtual vector, called an MSP 4 SSPs (each a 2-pipe vector processor) make up an MSP Compiler will (try to) vectorize/parallelize across the MSP 12.8 Gflops (64 bit) 25.6 Gflops (32 bit) S V V S V V S V V S V V custom blocks 51 GB/s GB/s 2 MB Ecache 0.5 MB $ 0.5 MB $ 0.5 MB $ 0.5 MB $ At frequency of 400/800 MHz To local and network: 25.6 GB/s GB/s Figure source J. Levesque, Cray 34 17
 Shared caches (unusual on earlier vector machines) 4")
 35 Earth Simulator Architecture Parallel")
 Fast network (new crossbar switch) Rearranging commodity parts can t")
18 Cray X1: Parallel Vector Arch. Cray combines several technologies in the X Gflop/s Vector processors (MSP) Shared caches (unusual on earlier vector machines) 4 processor nodes sharing up to 64 GB of Single System Image to 4096 Processors Remote put/get between nodes (faster than MPI) 35 Earth Simulator Architecture Parallel Vector Architecture High speed (vector) processors High bandwidth (vector architecture) Fast network (new crossbar switch) Rearranging commodity parts can t match this performance 36 18

19 Clusters have Arrived 37 What s a Cluster? Collection of independent computer systems working together as if a single system. Coupled through a scalable, high bandwidth, low latency interconnect
 Tutorials and book Design standard to rally community!")
20 PC Clusters: Contributions of Beowulf An experiment in parallel computing systems Established vision of low cost, high end computing Demonstrated effectiveness of PC clusters for some (not all) classes of applications Provided networking software Conveyed findings to broad community (great PR) Tutorials and book Design standard to rally community! Standards beget: books, trained people, Open source SW Adapted from Gordon Bell, presentation at Salishan Clusters of SMPs SMPs are the fastest commodity machine, so use them as a building block for a larger machine with a network Common names: CLUMP = Cluster of SMPs Hierarchical machines, constellations Most modern machines look like this: Millennium, IBM SPs, (not the t3e)... What is the right programming model??? Treat machine as flat, always use message passing, even within SMP (simple, but ignores an important part of hierarchy). Shared within one SMP, but message passing outside of an SMP
 42")
21 Cluster of SMP Approach A supercomputer is a stretched high-end server Parallel system is built by assembling nodes that are modest size, commercial, SMP servers just put more of them together Image from LLNL 41 WSU CLUMP: Cluster of SMPs 30 UltraSPARCs 155Mb ATM 1Gb Ethernet 12 UltraSPARCs CPU CPU CPU Cache Cache Cache 4 UltraSPARCs MEMORY I/O Network Symmetric Multiprocessor (SMP) 42 21
22 Scalable Computing P E R F O R M A N C E + Q o S Administrative Barriers Individual Group Department Campus State National Globe Inter Planet Universe Personal Device SMPs or SuperComputers Local Cluster Enterprise Cluster/Grid Global Grid Inter Planet Grid Figure due to Rajkumar Buyya, University of Melbourne, Australia, 43 Computational/Data Grid Coordinated resource sharing and problem solving in dynamic, multi-institutional virtual organizations direct access to computers, sw, data, and other resources, rather than file exchange Such sharing rules defines a set of individuals and/or institutions, which form a virtual organization Examples of VOs: application service providers, storage service providers, cycle providers, etc Grid computing is to develop protocols, services, and tools for coordinated resource sharing and problem solving in VOs Security solutions for management of credentials and policies RM protocols and services for secure remote access Information query protocols and services for configuratin Data management, etc 44 22
23 Top 500 Supercomputers Listing of the 500 most powerful computers in the world - Yardstick: Rmax from LINPACK MPP benchmark Ax=b, dense problem performance Rate Size - Dense LU Factorization (dominated by matrix multiply) Updated twice a year SC xy in the States in November Meeting in Mannheim, Germany in June All data (and slides) available from Also measures N-1/2 (size required to get ½ speed) 45 GFlop/s Cray Y-MP (8) Fastest Computer Over Time Fujitsu VP-2600 TMC CM-2 (2048) Year In 1980 a computation that took 1 full year to complete can now be done in 1 month! 23
24 GFlop/s Cray Y-MP (8) Fastest Computer Over Time Fujitsu VP-2600 TMC CM-2 (2048) NEC SX-3 (4) Intel Paragon (6788) Fujitsu VPP-500 (140) TMC CM-5 (1024) Hitachi CP-PACS (2040) Year In 1980 a computation that took 1 full year to complete can now be done in 4 days! GFlop/s Cray Y-MP (8) Fastest Computer Over Time Fujitsu VP-2600 TMC CM-2 (2048) NEC SX-3 (4) TMC CM-5 (1024) Fujitsu VPP-500 (140) Intel Paragon (6788) Intel ASCI Red (9152) Hitachi CP-PACS (2040) ASCI White Pacific (7424) ASCI Blue Pacific SST (5808) In 1980 a computation that took 1 full year to complete can today be done in 1 hour! Intel ASCI Red Xeon (9632) SGI ASCI Blue Mountain (5040) Year 24
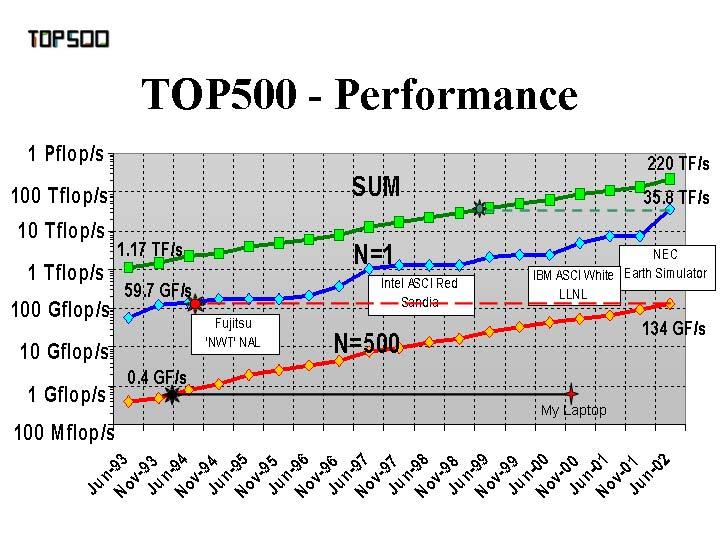

25

26 51 Speedup and Amdahl s Law 52 26
27 Speedup due to Enhancement Suppose a person wants to travel from city A to city B by city C. The routes from A to C are in mountains and the routes from C to B are in desert. The distances from A to C, and from C to B are 80 miles and 200 miles, respectively. From A to C, walk at speed of 4 mph From C to B, walk or drive (at speed of 100 mph) Question 1: How long will it take for the entire trip walking? Answer: 80/ /4 = 70 hours Question 2: How much faster from A to B by a car as opposed to walk? Answer: 70/ (80/ /100) = Speedup forumla ExTime(without E) Performance(with E) Speedup(E) = = ExTime(with E) Performance(without E) F F S Suppose that enhancement E accelerates a fraction F of the task by a factor S and the remainder of the task is unaffected then, Speedup(E) = ((1- F) ExTime(without E) = F + ) ExTime(without E) S 1 (1- F) + F S 1 1- F 54 27
28 Example Suppose an enhancement runs 10 times faster than the original machine, but is only usable 40% of the time. Question: what is the overall speedup? Answer: Fraction_enhance = 0.4 Speedup_enhanced = 10 Speedup_overall = 1/( /10) = Speedup due to parallel computing Suppose only part of an application seems parallel Amdahl s law Let f be the fraction of work done sequentially, so (1-f) is fraction parallelizable. n = number of processors. Speedup(n) = Time(1)/Time(n) <= 1/(f + (1-f)/n) <= 1/f Efficiency = Speedup/n Even if the parallel part speeds up perfectly, we may be limited by the sequential portion of code
29 Amdahl s Law Implications 57 Gustafson s Law Parallel processing is to solve larger programs in a fixed time Let s be the serial execution time, and p the execution time in parallel Scaled Speedup Factor: Suppose a serial section of 5% and 20 processors According to Amdahl s law, the speedup is According to Gustafson s law, the speedup is
30 Overhead of Parallelism Given enough parallel work, this is the most significant barrier to getting desired speedup. Parallelism overheads include: cost of starting a thread or process cost of communicating shared data cost of synchronizing extra (redundant) computation Each of these can be in the range of milliseconds (= millions of flops) on some systems Tradeoff: Algorithm needs sufficiently large units of work to run fast in parallel (i.e. large granularity), but not so large that there is not enough parallel work. 59 Parallel Programming Challenge Performance Tuning (Chemical Modeling) Speedup Vers. 12/94 Ve rs. 9 /9 4 Ve rs. 8 / Proces s ors 60 30
31 Summary Shared address space architecture and Programming model Symmetric Multiprocessor (SMP) Non-uniform architecture (NUMA), Distributed Shared Memory (DSA) Message passing architecture and programming model Data parallel architecture and programming model Convergence: Generic Architecture Speedup and Amdahl s law Network Mem Communication assist (CA) $ P 61 31
Learning Curve for Parallel Applications. 500 Fastest Computers
 Learning Curve for arallel Applications ABER molecular dynamics simulation program Starting point was vector code for Cray-1 145 FLO on Cray90, 406 for final version on 128-processor aragon, 891 on 128-processor
Learning Curve for arallel Applications ABER molecular dynamics simulation program Starting point was vector code for Cray-1 145 FLO on Cray90, 406 for final version on 128-processor aragon, 891 on 128-processor
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Number of processing elements (PEs). Computing power of each element. Amount of physical memory used. Data access, Communication and Synchronization
. Computing power of each element. Amount of physical memory used. Data access, Communication and Synchronization") Parallel Computer Architecture A parallel computer is a collection of processing elements that cooperate to solve large problems fast Broad issues involved: Resource Allocation: Number of processing elements
Parallel Computer Architecture A parallel computer is a collection of processing elements that cooperate to solve large problems fast Broad issues involved: Resource Allocation: Number of processing elements
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
Parallel Programming Models and Architecture
 Parallel Programming Models and Architecture CS 740 September 18, 2013 Seth Goldstein Carnegie Mellon University History Historically, parallel architectures tied to programming models Divergent architectures,
Parallel Programming Models and Architecture CS 740 September 18, 2013 Seth Goldstein Carnegie Mellon University History Historically, parallel architectures tied to programming models Divergent architectures,
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
Three basic multiprocessing issues
 Three basic multiprocessing issues 1. artitioning. The sequential program must be partitioned into subprogram units or tasks. This is done either by the programmer or by the compiler. 2. Scheduling. Associated
Three basic multiprocessing issues 1. artitioning. The sequential program must be partitioned into subprogram units or tasks. This is done either by the programmer or by the compiler. 2. Scheduling. Associated
Chapter 2: Computer-System Structures. Hmm this looks like a Computer System?
 Chapter 2: Computer-System Structures Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure of a computer system and understanding
Chapter 2: Computer-System Structures Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure of a computer system and understanding
Uniprocessor Computer Architecture Example: Cray T3E
 Chapter 2: Computer-System Structures MP Example: Intel Pentium Pro Quad Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure
Chapter 2: Computer-System Structures MP Example: Intel Pentium Pro Quad Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure
ECE 669 Parallel Computer Architecture
 ECE 669 arallel Computer Architecture Lecture 2 Architectural erspective Overview Increasingly attractive Economics, technology, architecture, application demand Increasingly central and mainstream arallelism
ECE 669 arallel Computer Architecture Lecture 2 Architectural erspective Overview Increasingly attractive Economics, technology, architecture, application demand Increasingly central and mainstream arallelism
Evolution and Convergence of Parallel Architectures
 History Evolution and Convergence of arallel Architectures Historically, parallel architectures tied to programming models Divergent architectures, with no predictable pattern of growth. Todd C. owry CS
History Evolution and Convergence of arallel Architectures Historically, parallel architectures tied to programming models Divergent architectures, with no predictable pattern of growth. Todd C. owry CS
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Instructor: Dr. Song Jiang The ECE Department sjiang@eng.wayne.edu http://www.ece.eng.wayne.edu/~sjiang/ece5610-fall-14/ece5610.htm Lecture:
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Instructor: Dr. Song Jiang The ECE Department sjiang@eng.wayne.edu http://www.ece.eng.wayne.edu/~sjiang/ece5610-fall-14/ece5610.htm Lecture:
Lecture 3: Intro to parallel machines and models
 Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
Convergence of Parallel Architectures
 History Historically, parallel architectures tied to programming models Divergent architectures, with no predictable pattern of growth. Systolic Arrays Dataflow Application Software System Software Architecture
History Historically, parallel architectures tied to programming models Divergent architectures, with no predictable pattern of growth. Systolic Arrays Dataflow Application Software System Software Architecture
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
Processor Architecture and Interconnect
 Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Processor Architecture and Interconnect What is Parallelism? Parallel processing is a term used to denote simultaneous computation in CPU for the purpose of measuring its computation speeds. Parallel Processing
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Conventional Computer Architecture. Abstraction
 Conventional Computer Architecture Conventional = Sequential or Single Processor Single Processor Abstraction Conventional computer architecture has two aspects: 1 The definition of critical abstraction
Conventional Computer Architecture Conventional = Sequential or Single Processor Single Processor Abstraction Conventional computer architecture has two aspects: 1 The definition of critical abstraction
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Presentation of the 16th List
 Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) Introduction (Chapter 1)
 Introduction (Chapter 1)") CS/ECE 757: Advanced Computer Architecture II (arallel Computer Architecture) Introduction (Chapter 1) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived from work by Sarita
CS/ECE 757: Advanced Computer Architecture II (arallel Computer Architecture) Introduction (Chapter 1) Copyright 2001 Mark D. Hill University of Wisconsin-Madison Slides are derived from work by Sarita
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Introduction to Parallel Processing
 Introduction to Parallel Processing Parallel Computer Architecture: Definition & Broad issues involved A Generic Parallel Computer Architecture The Need And Feasibility of Parallel Computing Scientific
Introduction to Parallel Processing Parallel Computer Architecture: Definition & Broad issues involved A Generic Parallel Computer Architecture The Need And Feasibility of Parallel Computing Scientific
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
What is a parallel computer?
 7.5 credit points Power 2 CPU L 2 $ IBM SP-2 node Instructor: Sally A. McKee General interconnection network formed from 8-port switches Memory bus Memory 4-way interleaved controller DRAM MicroChannel
7.5 credit points Power 2 CPU L 2 $ IBM SP-2 node Instructor: Sally A. McKee General interconnection network formed from 8-port switches Memory bus Memory 4-way interleaved controller DRAM MicroChannel
Chapter 7. Multicores, Multiprocessors, and Clusters. Goal: connecting multiple computers to get higher performance
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
CMSC 611: Advanced. Parallel Systems
 CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
The Cache-Coherence Problem
 The -Coherence Problem Lecture 12 (Chapter 6) 1 Outline Bus-based multiprocessors The cache-coherence problem Peterson s algorithm Coherence vs. consistency Shared vs. Distributed Memory What is the difference
The -Coherence Problem Lecture 12 (Chapter 6) 1 Outline Bus-based multiprocessors The cache-coherence problem Peterson s algorithm Coherence vs. consistency Shared vs. Distributed Memory What is the difference
Intro to Multiprocessors
 The Big Picture: Where are We Now? Intro to Multiprocessors Output Output Datapath Input Input Datapath [dapted from Computer Organization and Design, Patterson & Hennessy, 2005] Multiprocessor multiple
The Big Picture: Where are We Now? Intro to Multiprocessors Output Output Datapath Input Input Datapath [dapted from Computer Organization and Design, Patterson & Hennessy, 2005] Multiprocessor multiple
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
3/24/2014 BIT 325 PARALLEL PROCESSING ASSESSMENT. Lecture Notes:
 BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
BIT 325 PARALLEL PROCESSING ASSESSMENT CA 40% TESTS 30% PRESENTATIONS 10% EXAM 60% CLASS TIME TABLE SYLLUBUS & RECOMMENDED BOOKS Parallel processing Overview Clarification of parallel machines Some General
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Scalable Distributed Memory Machines
 Scalable Distributed Memory Machines Goal: Parallel machines that can be scaled to hundreds or thousands of processors. Design Choices: Custom-designed or commodity nodes? Network scalability. Capability
Scalable Distributed Memory Machines Goal: Parallel machines that can be scaled to hundreds or thousands of processors. Design Choices: Custom-designed or commodity nodes? Network scalability. Capability
COMP Parallel Computing. SMM (1) Memory Hierarchies and Shared Memory
 Memory Hierarchies and Shared Memory") COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
Parallel Computer Architectures. Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam
 Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Three parallel-programming models
 Three parallel-programming models Shared-memory programming is like using a bulletin board where you can communicate with colleagues. essage-passing is like communicating via e-mail or telephone calls.
Three parallel-programming models Shared-memory programming is like using a bulletin board where you can communicate with colleagues. essage-passing is like communicating via e-mail or telephone calls.
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Dheeraj Bhardwaj May 12, 2003
 HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core. Prof. Onur Mutlu Carnegie Mellon University
 18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Introduction to Parallel Processing
 Introduction to Parallel Processing Parallel Computer Architecture: Definition & Broad issues involved A Generic Parallel Computer Architecture The Need And Feasibility of Parallel Computing Scientific
Introduction to Parallel Processing Parallel Computer Architecture: Definition & Broad issues involved A Generic Parallel Computer Architecture The Need And Feasibility of Parallel Computing Scientific
CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c/su05 CS61C : Machine Structures Lecture #28: Parallel Computing 2005-08-09 CS61C L28 Parallel Computing (1) Andy Carle Scientific Computing Traditional Science 1) Produce
inst.eecs.berkeley.edu/~cs61c/su05 CS61C : Machine Structures Lecture #28: Parallel Computing 2005-08-09 CS61C L28 Parallel Computing (1) Andy Carle Scientific Computing Traditional Science 1) Produce
CS61C : Machine Structures
 CS61C L28 Parallel Computing (1) inst.eecs.berkeley.edu/~cs61c/su05 CS61C : Machine Structures Lecture #28: Parallel Computing 2005-08-09 Andy Carle Scientific Computing Traditional Science 1) Produce
CS61C L28 Parallel Computing (1) inst.eecs.berkeley.edu/~cs61c/su05 CS61C : Machine Structures Lecture #28: Parallel Computing 2005-08-09 Andy Carle Scientific Computing Traditional Science 1) Produce
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Parallel Architecture Fundamentals
 arallel Architecture Fundamentals Topics CS 740 September 22, 2003 What is arallel Architecture? Why arallel Architecture? Evolution and Convergence of arallel Architectures Fundamental Design Issues What
arallel Architecture Fundamentals Topics CS 740 September 22, 2003 What is arallel Architecture? Why arallel Architecture? Evolution and Convergence of arallel Architectures Fundamental Design Issues What
Parallel Computer Architecture Spring Shared Memory Multiprocessors Memory Coherence
 Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
Parallel Computer Architecture Spring 2018 Shared Memory Multiprocessors Memory Coherence Nikos Bellas Computer and Communications Engineering Department University of Thessaly Parallel Computer Architecture
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Snoop-Based Multiprocessor Design III: Case Studies
 Snoop-Based Multiprocessor Design III: Case Studies Todd C. Mowry CS 41 March, Case Studies of Bus-based Machines SGI Challenge, with Powerpath SUN Enterprise, with Gigaplane Take very different positions
Snoop-Based Multiprocessor Design III: Case Studies Todd C. Mowry CS 41 March, Case Studies of Bus-based Machines SGI Challenge, with Powerpath SUN Enterprise, with Gigaplane Take very different positions
BİL 542 Parallel Computing
 BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
BİL 542 Parallel Computing 1 Chapter 1 Parallel Programming 2 Why Use Parallel Computing? Main Reasons: Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion,
NOW Handout Page 1 NO! Today s Goal: CS 258 Parallel Computer Architecture. What will you get out of CS258? Will it be worthwhile?
 Today s Goal: CS 258 Parallel Computer Architecture Introduce you to Parallel Computer Architecture Answer your questions about CS 258 Provide you a sense of the trends that shape the field CS 258, Spring
Today s Goal: CS 258 Parallel Computer Architecture Introduce you to Parallel Computer Architecture Answer your questions about CS 258 Provide you a sense of the trends that shape the field CS 258, Spring
CSC 447: Parallel Programming for Multi- Core and Cluster Systems
 CSC 447: Parallel Programming for Multi- Core and Cluster Systems Why Parallel Computing? Haidar M. Harmanani Spring 2017 Definitions What is parallel? Webster: An arrangement or state that permits several
CSC 447: Parallel Programming for Multi- Core and Cluster Systems Why Parallel Computing? Haidar M. Harmanani Spring 2017 Definitions What is parallel? Webster: An arrangement or state that permits several
Why Multiprocessors?
 Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Start Voyager: Message Passing and DSM on SMP Clusters
 HPCS 97 --1 Start Voyager: Message Passing and DSM on SMP Clusters Laboratory for Computer Science Massachusetts Institute of Technology Massively Parallel Processors Shared Memory Cache-coherent KSR HP-Convex
HPCS 97 --1 Start Voyager: Message Passing and DSM on SMP Clusters Laboratory for Computer Science Massachusetts Institute of Technology Massively Parallel Processors Shared Memory Cache-coherent KSR HP-Convex
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 27 Course Wrap Up What is Parallel Architecture? A parallel computer is a collection of processing elements that cooperate to solve large problems fast Some
ECE 669 Parallel Computer Architecture Lecture 27 Course Wrap Up What is Parallel Architecture? A parallel computer is a collection of processing elements that cooperate to solve large problems fast Some
What is Parallel Computing?
 What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
What is Parallel Computing? Parallel Computing is several processing elements working simultaneously to solve a problem faster. 1/33 What is Parallel Computing? Parallel Computing is several processing
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Chapter 5. Thread-Level Parallelism
 Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Chapter 5 Thread-Level Parallelism Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Progress Towards Multiprocessors + Rate of speed growth in uniprocessors saturated
Clusters of SMP s. Sean Peisert
 Clusters of SMP s Sean Peisert What s Being Discussed Today SMP s Cluters of SMP s Programming Models/Languages Relevance to Commodity Computing Relevance to Supercomputing SMP s Symmetric Multiprocessors
Clusters of SMP s Sean Peisert What s Being Discussed Today SMP s Cluters of SMP s Programming Models/Languages Relevance to Commodity Computing Relevance to Supercomputing SMP s Symmetric Multiprocessors
Parallel Computer Architecture
 Parallel Computer Architecture What is Parallel Architecture? A parallel computer is a collection of processing elements that cooperate to solve large problems fast Some broad issues: Resource Allocation:»
Parallel Computer Architecture What is Parallel Architecture? A parallel computer is a collection of processing elements that cooperate to solve large problems fast Some broad issues: Resource Allocation:»
Parallel and High Performance Computing CSE 745
 Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction