character :: buffer(100) integer :: position real :: a, b integer :: n position = 0 call MPI_PACK(a, 1, MPI_REAL, buffer, 100, & position, MPI_COMM_WO
|
|
|
- Marjory Ferguson
- 6 years ago
- Views:
Transcription

1
2

3

4

5

6

7
8
9

10

11
12
13
14
15

16

17
18
19
20
21

22

23
24
25
26
27

28
29

30
31
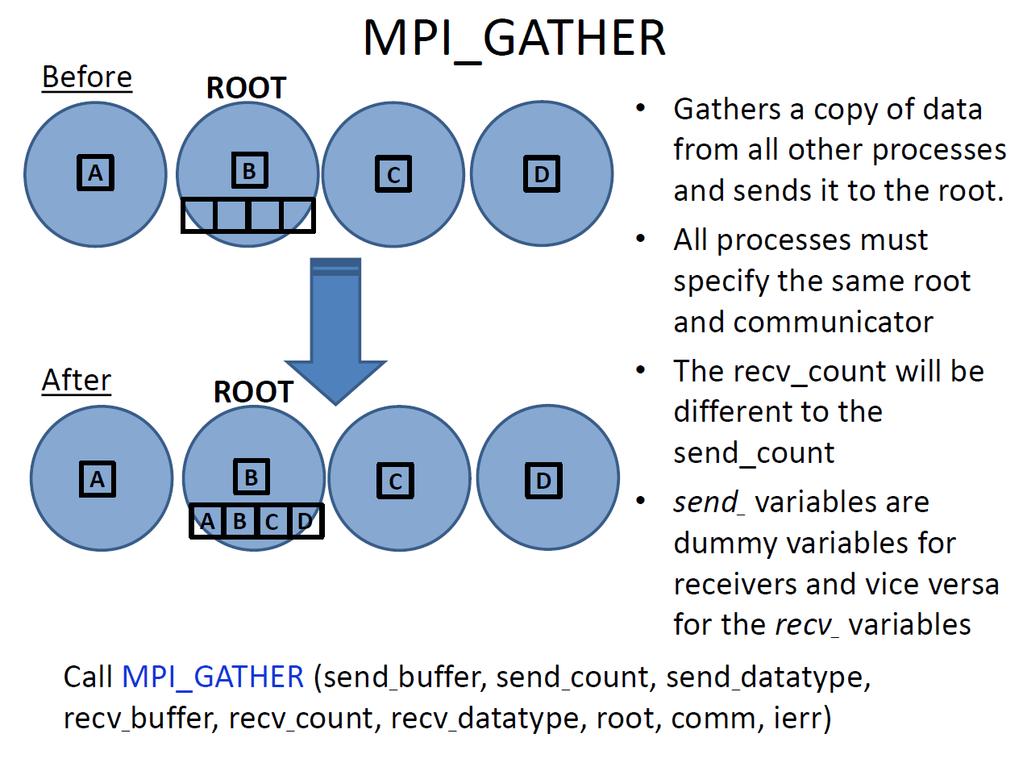
32

33
34

35

36
37
38 MPI_PACK and MPI_UNPACK Each communication incurs a latency penalty so it is best to group communications together Requires data to be contiguous in memory with no gaps between variables This is true for arrays (i.e. a[1:10] ) Not true when we mix many different variables (i.e. a, b, c) Use MPI_PACK to combine different data types into contiguous memory for sending Use MPI_UNPACK to unpack the data back into non-contiguous memory after being received
39 character :: buffer(100) integer :: position real :: a, b integer :: n position = 0 call MPI_PACK(a, 1, MPI_REAL, buffer, 100, & position, MPI_COMM_WORLD, ierr) call MPI_PACK(b, 1, MPI_REAL, buffer, 100, & position, MPI_COMM_WORLD, ierr) call MPI_PACK(n, 2, MPI_INTEGER, buffer, 100, & position, MPI_COMM_WORLD, ierr) Position variable is incremented after each step, recording where we are in the buffer: Now send the data: a a a a b b b b call MPI_BCAST(buffer, 100, MPI_PACKED, 0, MPI_COMM_WORLD, ierr) n n
40 On the receiving processors, receive the data: character :: buffer(100) call MPI_BCAST(buffer, 100, MPI_PACKED, 0, MPI_COMM_WORLD, ierr) Reset position to zero (start of buffer) position = 0 call MPI_UNPACK(buffer, 100, position, a, 1, & MPI_REAL, MPI_COMM_WORLD, ierr) call MPI_UNPACK(buffer, 100, position, b, 1, & MPI_REAL, MPI_COMM_WORLD, ierr) call MPI_UNPACK(buffer, 100, position, n, 2, & MPI_INTEGER, MPI_COMM_WORLD, ierr) Again position variable is automatically incremented after each step, recording where we are in the buffer
41 Groups and new communicators Sometimes we want to use global reduction operations but only on a subset of the processes in MPI_COMM_WORLD Can break up the processes within the MPI_COMM_WORLD communicator into sub groups Allocate the processors within the new group to a new communicator Include processes in new groups using: MPI_GROUP_INCL(group handle, size of new group, ranks of processes in new group, new group formed, ierr) Then create a new communicator with: MPI_COMM_CREATE(communicator, mpi group which is a subset of the communicator, new communicator, ierr) Each process within the new communicator now has a unique rank within that communicator different to the one it is allocated in MPI_COMM_WORLD. Find its new rank within the group using MPI_GROUP_RANK or within the world using MPI_COMM_RANK Remove processors from a group using MPI_GROUP_EXCL
42 program group include 'mpif.h' integer, parameter :: NPROCS = 8 integer rank, new_rank, sendbuf, recvbuf, numtasks, ierr integer orig_group, new_group, new_comm Integer ranks1 = /0, 1, 2, 3/, ranks2 = /4, 5, 6, 7/ call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr) if (numtasks.ne. NPROCS) then print *, 'Must specify MPROCS= ',NPROCS,' Terminating.' call MPI_FINALIZE(ierr) stop Endif Sample Output: rank= 7 newrank= 3 recvbuf= 22 rank= 0 newrank= 0 recvbuf= 6 rank= 1 newrank= 1 recvbuf= 6 rank= 2 newrank= 2 recvbuf= 6 rank= 6 newrank= 2 recvbuf= 22 rank= 3 newrank= 3 recvbuf= 6 rank= 4 newrank= 0 recvbuf= 22 rank= 5 newrank= 1 recvbuf= 22 sendbuf = rank! Extract the original group handle call MPI_COMM_GROUP(MPI_COMM_WORLD, orig_group, ierr)! Divide tasks into two distinct groups based upon rank if (rank.lt. NPROCS/2) then call MPI_GROUP_INCL(orig_group, NPROCS/2, ranks1, & new_group, ierr) else call MPI_GROUP_INCL(orig_group, NPROCS/2, ranks2, & new_group, ierr) Endif call MPI_COMM_CREATE(MPI_COMM_WORLD, new_group, & new_comm, ierr) call MPI_ALLREDUCE(sendbuf, recvbuf, 1, MPI_INTEGER, & MPI_SUM, new_comm, ierr) call MPI_GROUP_RANK(new_group, new_rank, ierr) print *, 'rank= ',rank,' newrank= ',new_rank,' recvbuf= ', recvbuf call MPI_FINALIZE(ierr) end

43
44

45
46
47
48 -lmpi
49 mpi_selector MPI needs configuring on labserv or some libraries may not be visible. Use the mpi-selector menu command > mpi-selector 1. mvapich 2. openmpi >1 User or system wide settings (u/s) >u Overwrite old settings? > yes
50 Numerical Practical Exercise Parallelisation In order to demonstrate some of the basics of parallelisation, we will be parallelising your simple 1D Hydro code from the Hydrodynamics lecture. Remember that the flow of the code is as follows: 1. Set the initial conditions. 2. Begin the evolutionary timestep: a) Calculate the global minimum time step. b) Update the boundary Guardcells. c) Evolve the Hydrodynamic variables using the upwind advection scheme. d) Update the boundary Guardcells 3. If we have passed the maximum time, then output the resulting data to file. We now need to perform the following steps to parallelise the code. 1. Initialize MPI, determine the rank of the current processor and determine how many processes are running 2. Split the 400 cell (x = 0-1.) computational domain between the number of processes so that each CPU has to work on a roughly equal number of cells. (If you run on an odd number of processes, e.g. 3, it would be easiest to first change the number of cells to one which is divisible by that number)
51 3. Once the domain is divided amongst the CPUs you should set the initial conditions on each block. If you passed the x coordinates to the initial conditions subroutine in your original code then this will not change. 4. We now need to perform a global reduction operation after the local time step has been found in order to obtain the global minimum time step (we cannot evolve each block with a different time step). 5. You should update both the left and right guardcells of the local block stored on each processor at steps (a) and (d) above. This is best done with a collective communication. 6. The solving of the hydrodynamical equations with the upwind advection scheme should be the same and thus does not need changing (apart from the array indices which we loop between, i.e. before we looped between n=2 and N_Total-1, now we loop between n=2 and N_local-1) 7. Once we have reached the maximum time then we can output the data in the correct order. The data should be written in serial (i.e. just by the Master Processor), you should see what happens if you try to get all of the processors to write in parallel!
52 You should send the data to the Master Processor for the serial write using as a series of point-to-point operations. A single collective communication would not be possible for very large simulations, why? You may need to add a tag to each message so that you can ensure that you then write the data out in the correct order from the correct processors. The Report You should include a copy of your code (you can easily check it as it should produce the same results as for the standard non-parallelised hydro code). The report should briefly outline the parallelisation strategy and answer the questions posed above: What happens when you try and perform an unstructured parallel write and therefore why do we perform a serial write? Why is point-to-point communication necessary in most applications when you write the data out?
53
Introduction to MPI Part II Collective Communications and communicators
 Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES
 INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 24 november 2017 a.marani@cineca.it WHAT ARE COMMUNICATORS? Many users are familiar with
INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 24 november 2017 a.marani@cineca.it WHAT ARE COMMUNICATORS? Many users are familiar with
Introduction to MPI part II. Fabio AFFINITO
 Introduction to MPI part II Fabio AFFINITO (f.affinito@cineca.it) Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or
Introduction to MPI part II Fabio AFFINITO (f.affinito@cineca.it) Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or
AMath 483/583 Lecture 21
 AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced
: Message-Passing Interface (MPI) advanced") 1 / 32 CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
1 / 32 CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
AMath 483/583 Lecture 18 May 6, 2011
 AMath 483/583 Lecture 18 May 6, 2011 Today: MPI concepts Communicators, broadcast, reduce Next week: MPI send and receive Iterative methods Read: Class notes and references $CLASSHG/codes/mpi MPI Message
AMath 483/583 Lecture 18 May 6, 2011 Today: MPI concepts Communicators, broadcast, reduce Next week: MPI send and receive Iterative methods Read: Class notes and references $CLASSHG/codes/mpi MPI Message
Lecture 6: Message Passing Interface
 Lecture 6: Message Passing Interface Introduction The basics of MPI Some simple problems More advanced functions of MPI A few more examples CA463D Lecture Notes (Martin Crane 2013) 50 When is Parallel
Lecture 6: Message Passing Interface Introduction The basics of MPI Some simple problems More advanced functions of MPI A few more examples CA463D Lecture Notes (Martin Crane 2013) 50 When is Parallel
Parallel Programming Using Basic MPI. Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center
 05 Parallel Programming Using Basic MPI Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple
05 Parallel Programming Using Basic MPI Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple
Parallelization. Tianhe-1A, 2.45 Pentaflops/s, 224 Terabytes RAM. Nigel Mitchell
 Parallelization Tianhe-1A, 2.45 Pentaflops/s, 224 Terabytes RAM Nigel Mitchell Outline Pros and Cons of parallelization Shared memory vs. cluster computing MPI as a tool for sending and receiving messages
Parallelization Tianhe-1A, 2.45 Pentaflops/s, 224 Terabytes RAM Nigel Mitchell Outline Pros and Cons of parallelization Shared memory vs. cluster computing MPI as a tool for sending and receiving messages
Message Passing Interface
 MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
MPI MESSAGE PASSING INTERFACE
 MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
Recap of Parallelism & MPI
 Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
INTRODUCTION TO MPI COLLECTIVE COMMUNICATIONS AND COMMUNICATORS. Introduction to Parallel Computing with MPI and OpenMP
 INTRODUCTION TO MPI COLLECTIVE COMMUNICATIONS AND COMMUNICATORS Introduction to Parallel Computing with MPI and OpenMP Part I: Collective communications WHAT ARE COLLECTIVE COMMUNICATIONS? Communications
INTRODUCTION TO MPI COLLECTIVE COMMUNICATIONS AND COMMUNICATORS Introduction to Parallel Computing with MPI and OpenMP Part I: Collective communications WHAT ARE COLLECTIVE COMMUNICATIONS? Communications
Collective Communication: Gather. MPI - v Operations. Collective Communication: Gather. MPI_Gather. root WORKS A OK
 Collective Communication: Gather MPI - v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective Communication: Gather MPI - v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Introduction to MPI. Ricardo Fonseca. https://sites.google.com/view/rafonseca2017/
 Introduction to MPI Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Distributed Memory Programming (MPI) Message Passing Model Initializing and terminating programs Point to point
Introduction to MPI Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Distributed Memory Programming (MPI) Message Passing Model Initializing and terminating programs Point to point
MPI - v Operations. Collective Communication: Gather
 MPI - v Operations Based on notes by Dr. David Cronk Innovative Computing Lab University of Tennessee Cluster Computing 1 Collective Communication: Gather A Gather operation has data from all processes
MPI - v Operations Based on notes by Dr. David Cronk Innovative Computing Lab University of Tennessee Cluster Computing 1 Collective Communication: Gather A Gather operation has data from all processes
MPI introduction - exercises -
 MPI introduction - exercises - Paolo Ramieri, Maurizio Cremonesi May 2016 Startup notes Access the server and go on scratch partition: ssh a08tra49@login.galileo.cineca.it cd $CINECA_SCRATCH Create a job
MPI introduction - exercises - Paolo Ramieri, Maurizio Cremonesi May 2016 Startup notes Access the server and go on scratch partition: ssh a08tra49@login.galileo.cineca.it cd $CINECA_SCRATCH Create a job
An introduction to MPI
 An introduction to MPI C MPI is a Library for Message-Passing Not built in to compiler Function calls that can be made from any compiler, many languages Just link to it Wrappers: mpicc, mpif77 Fortran
An introduction to MPI C MPI is a Library for Message-Passing Not built in to compiler Function calls that can be made from any compiler, many languages Just link to it Wrappers: mpicc, mpif77 Fortran
Parallel Programming, MPI Lecture 2
 Parallel Programming, MPI Lecture 2 Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction and Review The Von Neumann Computer Kinds of Parallel
Parallel Programming, MPI Lecture 2 Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction and Review The Von Neumann Computer Kinds of Parallel
MPI: Message Passing Interface An Introduction. S. Lakshmivarahan School of Computer Science
 MPI: Message Passing Interface An Introduction S. Lakshmivarahan School of Computer Science MPI: A specification for message passing libraries designed to be a standard for distributed memory message passing,
MPI: Message Passing Interface An Introduction S. Lakshmivarahan School of Computer Science MPI: A specification for message passing libraries designed to be a standard for distributed memory message passing,
Practical Introduction to Message-Passing Interface (MPI)
") 1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
HPC Parallel Programing Multi-node Computation with MPI - I
 HPC Parallel Programing Multi-node Computation with MPI - I Parallelization and Optimization Group TATA Consultancy Services, Sahyadri Park Pune, India TCS all rights reserved April 29, 2013 Copyright
HPC Parallel Programing Multi-node Computation with MPI - I Parallelization and Optimization Group TATA Consultancy Services, Sahyadri Park Pune, India TCS all rights reserved April 29, 2013 Copyright
Parallel Programming using MPI. Supercomputing group CINECA
 Parallel Programming using MPI Supercomputing group CINECA Contents Programming with message passing Introduction to message passing and MPI Basic MPI programs MPI Communicators Send and Receive function
Parallel Programming using MPI Supercomputing group CINECA Contents Programming with message passing Introduction to message passing and MPI Basic MPI programs MPI Communicators Send and Receive function
Non-Blocking Communications
 Non-Blocking Communications Deadlock 1 5 2 3 4 Communicator 0 2 Completion The mode of a communication determines when its constituent operations complete. - i.e. synchronous / asynchronous The form of
Non-Blocking Communications Deadlock 1 5 2 3 4 Communicator 0 2 Completion The mode of a communication determines when its constituent operations complete. - i.e. synchronous / asynchronous The form of
Message Passing Programming. Designing MPI Applications
 Message Passing Programming Designing MPI Applications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Message Passing Programming Designing MPI Applications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Practical stuff! ü OpenMP
 Practical stuff! REALITY: Ways of actually get stuff done in HPC: Ø Message Passing (send, receive, broadcast,...) Ø Shared memory (load, store, lock, unlock) ü MPI Ø Transparent (compiler works magic)
Practical stuff! REALITY: Ways of actually get stuff done in HPC: Ø Message Passing (send, receive, broadcast,...) Ø Shared memory (load, store, lock, unlock) ü MPI Ø Transparent (compiler works magic)
IPM Workshop on High Performance Computing (HPC08) IPM School of Physics Workshop on High Perfomance Computing/HPC08
 IPM School of Physics Workshop on High Perfomance Computing/HPC08") IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
What is Point-to-Point Comm.?
 0 What is Point-to-Point Comm.? Collective Communication MPI_Reduce, MPI_Scatter/Gather etc. Communications with all processes in the communicator Application Area BEM, Spectral Method, MD: global interactions
0 What is Point-to-Point Comm.? Collective Communication MPI_Reduce, MPI_Scatter/Gather etc. Communications with all processes in the communicator Application Area BEM, Spectral Method, MD: global interactions
MPI Tutorial. Shao-Ching Huang. IDRE High Performance Computing Workshop
 MPI Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop 2013-02-13 Distributed Memory Each CPU has its own (local) memory This needs to be fast for parallel scalability (e.g. Infiniband,
MPI Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop 2013-02-13 Distributed Memory Each CPU has its own (local) memory This needs to be fast for parallel scalability (e.g. Infiniband,
Parallel Programming Basic MPI. Timothy H. Kaiser, Ph.D.
 Parallel Programming Basic MPI Timothy H. Kaiser, Ph.D. tkaiser@mines.edu Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple send and receive program Examples
Parallel Programming Basic MPI Timothy H. Kaiser, Ph.D. tkaiser@mines.edu Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple send and receive program Examples
Introduction to Parallel Programming with MPI
 Introduction to Parallel Programming with MPI PICASso Tutorial October 25-26, 2006 Stéphane Ethier (ethier@pppl.gov) Computational Plasma Physics Group Princeton Plasma Physics Lab Why Parallel Computing?
Introduction to Parallel Programming with MPI PICASso Tutorial October 25-26, 2006 Stéphane Ethier (ethier@pppl.gov) Computational Plasma Physics Group Princeton Plasma Physics Lab Why Parallel Computing?
Non-Blocking Communications
 Non-Blocking Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Non-Blocking Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Programming with MPI Collectives
 Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Report S1 Fortran. Kengo Nakajima Information Technology Center
 Report S1 Fortran Kengo Nakajima Information Technology Center Technical & Scientific Computing II (4820-1028) Seminar on Computer Science II (4810-1205) Problem S1-1 Report S1 Read local files /a1.0~a1.3,
Report S1 Fortran Kengo Nakajima Information Technology Center Technical & Scientific Computing II (4820-1028) Seminar on Computer Science II (4810-1205) Problem S1-1 Report S1 Read local files /a1.0~a1.3,
Message-Passing and MPI Programming
 Message-Passing and MPI Programming More on Collectives N.M. Maclaren Computing Service nmm1@cam.ac.uk ext. 34761 July 2010 5.1 Introduction There are two important facilities we have not covered yet;
Message-Passing and MPI Programming More on Collectives N.M. Maclaren Computing Service nmm1@cam.ac.uk ext. 34761 July 2010 5.1 Introduction There are two important facilities we have not covered yet;
A short overview of parallel paradigms. Fabio Affinito, SCAI
 A short overview of parallel paradigms Fabio Affinito, SCAI Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase
A short overview of parallel paradigms Fabio Affinito, SCAI Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase
Lecture 9: MPI continued
 Lecture 9: MPI continued David Bindel 27 Sep 2011 Logistics Matrix multiply is done! Still have to run. Small HW 2 will be up before lecture on Thursday, due next Tuesday. Project 2 will be posted next
Lecture 9: MPI continued David Bindel 27 Sep 2011 Logistics Matrix multiply is done! Still have to run. Small HW 2 will be up before lecture on Thursday, due next Tuesday. Project 2 will be posted next
Introduction to parallel computing with MPI
 Introduction to parallel computing with MPI Sergiy Bubin Department of Physics Nazarbayev University Distributed Memory Environment image credit: LLNL Hybrid Memory Environment Most modern clusters and
Introduction to parallel computing with MPI Sergiy Bubin Department of Physics Nazarbayev University Distributed Memory Environment image credit: LLNL Hybrid Memory Environment Most modern clusters and
Collective Communication: Gatherv. MPI v Operations. root
 Collective Communication: Gather MPI v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective Communication: Gather MPI v Operations A Gather operation has data from all processes collected, or gathered, at a central process, referred to as the root Even the root process contributes
Collective communications
 Lecture 9 Collective communications Introduction Collective communication involves all the processes in a communicator We will consider: Broadcast Reduce Gather Scatter Reason for use: convenience and
Lecture 9 Collective communications Introduction Collective communication involves all the processes in a communicator We will consider: Broadcast Reduce Gather Scatter Reason for use: convenience and
Introduction to MPI HPC Workshop: Parallel Programming. Alexander B. Pacheco
 Introduction to MPI 2018 HPC Workshop: Parallel Programming Alexander B. Pacheco Research Computing July 17-18, 2018 Distributed Memory Model Each process has its own address space Data is local to each
Introduction to MPI 2018 HPC Workshop: Parallel Programming Alexander B. Pacheco Research Computing July 17-18, 2018 Distributed Memory Model Each process has its own address space Data is local to each
ECE 563 Midterm 1 Spring 2015
 ECE 563 Midterm 1 Spring 215 To make it easy not to cheat, this exam is open book and open notes. Please print and sign your name below. By doing so you signify that you have not received or given any
ECE 563 Midterm 1 Spring 215 To make it easy not to cheat, this exam is open book and open notes. Please print and sign your name below. By doing so you signify that you have not received or given any
MPI Casestudy: Parallel Image Processing
 MPI Casestudy: Parallel Image Processing David Henty 1 Introduction The aim of this exercise is to write a complete MPI parallel program that does a very basic form of image processing. We will start by
MPI Casestudy: Parallel Image Processing David Henty 1 Introduction The aim of this exercise is to write a complete MPI parallel program that does a very basic form of image processing. We will start by
Parallel Programming Basic MPI. Timothy H. Kaiser, Ph.D.
 Parallel Programming Basic MPI Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Talk Overview Background on MPI Documentation Hello world in MPI Some differences between mpi4py and normal MPI Basic communications
Parallel Programming Basic MPI Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Talk Overview Background on MPI Documentation Hello world in MPI Some differences between mpi4py and normal MPI Basic communications
Introduction to MPI Programming Part 2
 Introduction to MPI Programming Part 2 Outline Collective communication Derived data types Collective Communication Collective communications involves all processes in a communicator One to all, all to
Introduction to MPI Programming Part 2 Outline Collective communication Derived data types Collective Communication Collective communications involves all processes in a communicator One to all, all to
Introduction to MPI. SHARCNET MPI Lecture Series: Part I of II. Paul Preney, OCT, M.Sc., B.Ed., B.Sc.
 Introduction to MPI SHARCNET MPI Lecture Series: Part I of II Paul Preney, OCT, M.Sc., B.Ed., B.Sc. preney@sharcnet.ca School of Computer Science University of Windsor Windsor, Ontario, Canada Copyright
Introduction to MPI SHARCNET MPI Lecture Series: Part I of II Paul Preney, OCT, M.Sc., B.Ed., B.Sc. preney@sharcnet.ca School of Computer Science University of Windsor Windsor, Ontario, Canada Copyright
Distributed Memory Programming With MPI (3)
") Distributed Memory Programming With MPI (3) 2014 Spring Jinkyu Jeong (jinkyu@skku.edu) 1 Roadmap Hello World in MPI program Basic APIs of MPI Example program The Trapezoidal Rule in MPI. Collective communication.
Distributed Memory Programming With MPI (3) 2014 Spring Jinkyu Jeong (jinkyu@skku.edu) 1 Roadmap Hello World in MPI program Basic APIs of MPI Example program The Trapezoidal Rule in MPI. Collective communication.
Fabio AFFINITO.
 Introduction to Message Passing Interface Fabio AFFINITO Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or a group)
Introduction to Message Passing Interface Fabio AFFINITO Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or a group)
MPI, Part 3. Scientific Computing Course, Part 3
 MPI, Part 3 Scientific Computing Course, Part 3 Non-blocking communications Diffusion: Had to Global Domain wait for communications to compute Could not compute end points without guardcell data All work
MPI, Part 3 Scientific Computing Course, Part 3 Non-blocking communications Diffusion: Had to Global Domain wait for communications to compute Could not compute end points without guardcell data All work
MPI Program Structure
 MPI Program Structure Handles MPI communicator MPI_COMM_WORLD Header files MPI function format Initializing MPI Communicator size Process rank Exiting MPI 1 Handles MPI controls its own internal data structures
MPI Program Structure Handles MPI communicator MPI_COMM_WORLD Header files MPI function format Initializing MPI Communicator size Process rank Exiting MPI 1 Handles MPI controls its own internal data structures
CS 179: GPU Programming. Lecture 14: Inter-process Communication
 CS 179: GPU Programming Lecture 14: Inter-process Communication The Problem What if we want to use GPUs across a distributed system? GPU cluster, CSIRO Distributed System A collection of computers Each
CS 179: GPU Programming Lecture 14: Inter-process Communication The Problem What if we want to use GPUs across a distributed system? GPU cluster, CSIRO Distributed System A collection of computers Each
MPI Lab. How to split a problem across multiple processors Broadcasting input to other nodes Using MPI_Reduce to accumulate partial sums
 MPI Lab Parallelization (Calculating π in parallel) How to split a problem across multiple processors Broadcasting input to other nodes Using MPI_Reduce to accumulate partial sums Sharing Data Across Processors
MPI Lab Parallelization (Calculating π in parallel) How to split a problem across multiple processors Broadcasting input to other nodes Using MPI_Reduce to accumulate partial sums Sharing Data Across Processors
Introduction to MPI. Ritu Arora Texas Advanced Computing Center June 17,
 Introduction to MPI Ritu Arora Texas Advanced Computing Center June 17, 2014 Email: rauta@tacc.utexas.edu 1 Course Objectives & Assumptions Objectives Teach basics of MPI-Programming Share information
Introduction to MPI Ritu Arora Texas Advanced Computing Center June 17, 2014 Email: rauta@tacc.utexas.edu 1 Course Objectives & Assumptions Objectives Teach basics of MPI-Programming Share information
Review of MPI Part 2
 Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
Parallel programming with MPI Part I -Introduction and Point-to-Point Communications
 Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, A. Marani, Supercomputing Applications and Innovation (SCAI), CINECA 23 February 2016 MPI course 2016 Contents
Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, A. Marani, Supercomputing Applications and Innovation (SCAI), CINECA 23 February 2016 MPI course 2016 Contents
Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste
 Università di Trieste") Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Parallel programming with MPI Part I -Introduction and Point-to-Point
 Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, Supercomputing Applications and Innovation (SCAI), CINECA 1 Contents Introduction to message passing and
Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, Supercomputing Applications and Innovation (SCAI), CINECA 1 Contents Introduction to message passing and
MPI Derived Datatypes
 MPI Derived Datatypes Francesco Salvadore f.salvadore@cineca.it SuperComputing Applications and Innovation Department 1 Derived datatypes What are? MPI Derived datatypes are datatypes that are built from
MPI Derived Datatypes Francesco Salvadore f.salvadore@cineca.it SuperComputing Applications and Innovation Department 1 Derived datatypes What are? MPI Derived datatypes are datatypes that are built from
Week 3: MPI. Day 02 :: Message passing, point-to-point and collective communications
 Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Topics. Lecture 7. Review. Other MPI collective functions. Collective Communication (cont d) MPI Programming (III)
 MPI Programming (III)") Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
MPI, Part 2. Scientific Computing Course, Part 3
 MPI, Part 2 Scientific Computing Course, Part 3 Something new: Sendrecv A blocking send and receive built in together Lets them happen simultaneously Can automatically pair the sends/recvs! dest, source
MPI, Part 2 Scientific Computing Course, Part 3 Something new: Sendrecv A blocking send and receive built in together Lets them happen simultaneously Can automatically pair the sends/recvs! dest, source
Paul Burton April 2015 An Introduction to MPI Programming
 Paul Burton April 2015 Topics Introduction Initialising MPI & basic concepts Compiling and running a parallel program on the Cray Practical : Hello World MPI program Synchronisation Practical Data types
Paul Burton April 2015 Topics Introduction Initialising MPI & basic concepts Compiling and running a parallel program on the Cray Practical : Hello World MPI program Synchronisation Practical Data types
MPI. (message passing, MIMD)
") MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
Message-Passing and MPI Programming
 Message-Passing and MPI Programming 5.1 Introduction More on Datatypes and Collectives N.M. Maclaren nmm1@cam.ac.uk July 2010 There are a few important facilities we have not covered yet; they are less
Message-Passing and MPI Programming 5.1 Introduction More on Datatypes and Collectives N.M. Maclaren nmm1@cam.ac.uk July 2010 There are a few important facilities we have not covered yet; they are less
Collective Communications
 Collective Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Collective Communications Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Using MPI
 Parallel Programming Using MPI Short Course on HPC 15th February 2019 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, Indian Institute of Science When Parallel Computing Helps? Want to speed up your calculation
Parallel Programming Using MPI Short Course on HPC 15th February 2019 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, Indian Institute of Science When Parallel Computing Helps? Want to speed up your calculation
Introduction to MPI. Ekpe Okorafor. School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014
 Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Data parallelism. [ any app performing the *same* operation across a data stream ]
![Data parallelism. [ any app performing the *same* operation across a data stream ]](/thumbs/88/115717710.jpg "Data parallelism. [ any app performing the *same* operation across a data stream ]") Data parallelism [ any app performing the *same* operation across a data stream ] Contrast stretching: Version Cores Time (secs) Speedup while (step < NumSteps &&!converged) { step++; diffs = 0; foreach
Data parallelism [ any app performing the *same* operation across a data stream ] Contrast stretching: Version Cores Time (secs) Speedup while (step < NumSteps &&!converged) { step++; diffs = 0; foreach
Practical Course Scientific Computing and Visualization
 July 5, 2006 Page 1 of 21 1. Parallelization Architecture our target architecture: MIMD distributed address space machines program1 data1 program2 data2 program program3 data data3.. program(data) program1(data1)
July 5, 2006 Page 1 of 21 1. Parallelization Architecture our target architecture: MIMD distributed address space machines program1 data1 program2 data2 program program3 data data3.. program(data) program1(data1)
Version Control for Fun and Profit
 Version Control for Fun and Profit Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 30/11/2017 Version control 30/11/2017
Version Control for Fun and Profit Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 30/11/2017 Version control 30/11/2017
MPI Workshop - III. Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3
 MPI Workshop - III Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3 Schedule 4Course Map 4Fix environments to run MPI codes 4CartesianTopology! MPI_Cart_create! MPI_
MPI Workshop - III Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3 Schedule 4Course Map 4Fix environments to run MPI codes 4CartesianTopology! MPI_Cart_create! MPI_
A message contains a number of elements of some particular datatype. MPI datatypes:
 Messages Messages A message contains a number of elements of some particular datatype. MPI datatypes: Basic types. Derived types. Derived types can be built up from basic types. C types are different from
Messages Messages A message contains a number of elements of some particular datatype. MPI datatypes: Basic types. Derived types. Derived types can be built up from basic types. C types are different from
L14 Supercomputing - Part 2
 Geophysical Computing L14-1 L14 Supercomputing - Part 2 1. MPI Code Structure Writing parallel code can be done in either C or Fortran. The Message Passing Interface (MPI) is just a set of subroutines
Geophysical Computing L14-1 L14 Supercomputing - Part 2 1. MPI Code Structure Writing parallel code can be done in either C or Fortran. The Message Passing Interface (MPI) is just a set of subroutines
Introduction to MPI: Lecture 1
 Introduction to MPI: Lecture 1 Jun Ni, Ph.D. M.E. Associate Professor Department of Radiology Carver College of Medicine Information Technology Services The University of Iowa Learning MPI by Examples:
Introduction to MPI: Lecture 1 Jun Ni, Ph.D. M.E. Associate Professor Department of Radiology Carver College of Medicine Information Technology Services The University of Iowa Learning MPI by Examples:
東京大学情報基盤中心准教授片桐孝洋 Takahiro Katagiri, Associate Professor, Information Technology Center, The University of Tokyo
 Overview of MPI 東京大学情報基盤中心准教授片桐孝洋 Takahiro Katagiri, Associate Professor, Information Technology Center, The University of Tokyo 台大数学科学中心科学計算冬季学校 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction
Overview of MPI 東京大学情報基盤中心准教授片桐孝洋 Takahiro Katagiri, Associate Professor, Information Technology Center, The University of Tokyo 台大数学科学中心科学計算冬季学校 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing
 TMA4280 Introduction to Supercomputing") The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
Message passing. Week 3: MPI. Day 02 :: Message passing, point-to-point and collective communications. What is MPI?
 Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Week 3: MPI Day 02 :: Message passing, point-to-point and collective communications Message passing What is MPI? A message-passing interface standard MPI-1.0: 1993 MPI-1.1: 1995 MPI-2.0: 1997 (backward-compatible
Introduction to Parallel Programming Message Passing Interface Practical Session Part I
 Introduction to Parallel Programming Message Passing Interface Practical Session Part I T. Streit, H.-J. Pflug streit@rz.rwth-aachen.de October 28, 2008 1 1. Examples We provide codes of the theoretical
Introduction to Parallel Programming Message Passing Interface Practical Session Part I T. Streit, H.-J. Pflug streit@rz.rwth-aachen.de October 28, 2008 1 1. Examples We provide codes of the theoretical
MA471. Lecture 5. Collective MPI Communication
 MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
Outline. Communication modes MPI Message Passing Interface Standard
 MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
An Elementary Introduction to MPI Fortran Programming
 An Elementary Introduction to MPI Fortran Programming Wenqiang Feng Abstract This note is a summary of my MATH 578 course in University of Tennessee at Knoxville. You can download and distribute it. Please
An Elementary Introduction to MPI Fortran Programming Wenqiang Feng Abstract This note is a summary of my MATH 578 course in University of Tennessee at Knoxville. You can download and distribute it. Please
Slides prepared by : Farzana Rahman 1
 Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Holland Computing Center Kickstart MPI Intro
 Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Parallel I/O. and split communicators. David Henty, Fiona Ried, Gavin J. Pringle
 Parallel I/O and split communicators David Henty, Fiona Ried, Gavin J. Pringle Dr Gavin J. Pringle Applications Consultant gavin@epcc.ed.ac.uk +44 131 650 6709 4x4 array on 2x2 Process Grid Parallel IO
Parallel I/O and split communicators David Henty, Fiona Ried, Gavin J. Pringle Dr Gavin J. Pringle Applications Consultant gavin@epcc.ed.ac.uk +44 131 650 6709 4x4 array on 2x2 Process Grid Parallel IO
Overview of MPI 國家理論中心數學組 高效能計算 短期課程. 名古屋大学情報基盤中心教授片桐孝洋 Takahiro Katagiri, Professor, Information Technology Center, Nagoya University
 Overview of MPI 名古屋大学情報基盤中心教授片桐孝洋 Takahiro Katagiri, Professor, Information Technology Center, Nagoya University 國家理論中心數學組 高效能計算 短期課程 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction Operations
Overview of MPI 名古屋大学情報基盤中心教授片桐孝洋 Takahiro Katagiri, Professor, Information Technology Center, Nagoya University 國家理論中心數學組 高效能計算 短期課程 1 Agenda 1. Features of MPI 2. Basic MPI Functions 3. Reduction Operations
Message Passing Programming. MPI Users Guide in FORTRAN
 INTRODUTION 2 Message Passing Programming MPI Users Guide in FORTRAN I N T R O D U T I O N T O M E S S A G E PA S S I N G P R O G R A M M I N G MPI User Guide in FORTRAN Dr Peter S. Pacheco Department
INTRODUTION 2 Message Passing Programming MPI Users Guide in FORTRAN I N T R O D U T I O N T O M E S S A G E PA S S I N G P R O G R A M M I N G MPI User Guide in FORTRAN Dr Peter S. Pacheco Department
lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar cd mpibasic_lab/pi cd mpibasic_lab/decomp1d
 MPI Lab Getting Started Login to ranger.tacc.utexas.edu Untar the lab source code lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar Part 1: Getting Started with simple parallel coding hello mpi-world
MPI Lab Getting Started Login to ranger.tacc.utexas.edu Untar the lab source code lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar Part 1: Getting Started with simple parallel coding hello mpi-world
MPI introduction - exercises -
 MPI introduction - exercises - Introduction to Parallel Computing with MPI and OpenMP P. Ramieri May 2015 Hello world! (Fortran) As an ice breaking activity try to compile and run the Helloprogram, either
MPI introduction - exercises - Introduction to Parallel Computing with MPI and OpenMP P. Ramieri May 2015 Hello world! (Fortran) As an ice breaking activity try to compile and run the Helloprogram, either
Elementary Parallel Programming with Examples. Reinhold Bader (LRZ) Georg Hager (RRZE)
 Georg Hager (RRZE)") Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
Elementary Parallel Programming with Examples Reinhold Bader (LRZ) Georg Hager (RRZE) Two Paradigms for Parallel Programming Hardware Designs Distributed Memory M Message Passing explicit programming required
First day. Basics of parallel programming. RIKEN CCS HPC Summer School Hiroya Matsuba, RIKEN CCS
 First day Basics of parallel programming RIKEN CCS HPC Summer School Hiroya Matsuba, RIKEN CCS Today s schedule: Basics of parallel programming 7/22 AM: Lecture Goals Understand the design of typical parallel
First day Basics of parallel programming RIKEN CCS HPC Summer School Hiroya Matsuba, RIKEN CCS Today s schedule: Basics of parallel programming 7/22 AM: Lecture Goals Understand the design of typical parallel
High Performance Computing Course Notes Message Passing Programming I
 High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming I Message Passing Programming Message Passing is the most widely used parallel programming model Message passing works
High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming I Message Passing Programming Message Passing is the most widely used parallel programming model Message passing works
Advanced Message-Passing Interface (MPI)
") Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
Outline of the workshop 2 Advanced Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Morning: Advanced MPI Revision More on Collectives More on Point-to-Point
INTRODUCTION. Message Passing Programming
 INTRODUTION Message Passing Programming INTRODUTION TO MESSAGE PASSING PROGRAMMING MPI User Guide in FORTRAN Dr Peter S. Pacheco Department of Mathematics University of San Francisco San Francisco, A 94117
INTRODUTION Message Passing Programming INTRODUTION TO MESSAGE PASSING PROGRAMMING MPI User Guide in FORTRAN Dr Peter S. Pacheco Department of Mathematics University of San Francisco San Francisco, A 94117
Introduction to MPI. Jerome Vienne Texas Advanced Computing Center January 10 th,
 Introduction to MPI Jerome Vienne Texas Advanced Computing Center January 10 th, 2013 Email: viennej@tacc.utexas.edu 1 Course Objectives & Assumptions Objectives Teach basics of MPI-Programming Share information
Introduction to MPI Jerome Vienne Texas Advanced Computing Center January 10 th, 2013 Email: viennej@tacc.utexas.edu 1 Course Objectives & Assumptions Objectives Teach basics of MPI-Programming Share information
COMP 322: Fundamentals of Parallel Programming
 COMP 322: Fundamentals of Parallel Programming https://wiki.rice.edu/confluence/display/parprog/comp322 Lecture 37: Introduction to MPI (contd) Vivek Sarkar Department of Computer Science Rice University
COMP 322: Fundamentals of Parallel Programming https://wiki.rice.edu/confluence/display/parprog/comp322 Lecture 37: Introduction to MPI (contd) Vivek Sarkar Department of Computer Science Rice University
An Introduction to Parallel Programming
 Guide 48 Version 2 An Introduction to Parallel Programming Document code: Guide 48 Title: An Introduction to Parallel Programming Version: 2 Date: 31/01/2011 Produced by: University of Durham Information
Guide 48 Version 2 An Introduction to Parallel Programming Document code: Guide 48 Title: An Introduction to Parallel Programming Version: 2 Date: 31/01/2011 Produced by: University of Durham Information
COSC 4397 Parallel Computation. Introduction to MPI (III) Process Grouping. Terminology (I)
 Process Grouping. Terminology (I)") COSC 4397 Introduction to MPI (III) Process Grouping Spring 2010 Terminology (I) an MPI_Group is the object describing the list of processes forming a logical entity a group has a size MPI_Group_size every
COSC 4397 Introduction to MPI (III) Process Grouping Spring 2010 Terminology (I) an MPI_Group is the object describing the list of processes forming a logical entity a group has a size MPI_Group_size every
LECTURE 5: MESSAGE-ORIENTED COMMUNICATION. CA4006 Lecture Notes (Martin Crane 2018)
") LECTURE 5: MESSAGE-ORIENTED COMMUNICATION CA4006 Lecture Notes (Martin Crane 2018) 1 Lecture Contents Message Passing primitives: Send/Receive Synchronous & Asynchronous Message Passing Types of Processes
LECTURE 5: MESSAGE-ORIENTED COMMUNICATION CA4006 Lecture Notes (Martin Crane 2018) 1 Lecture Contents Message Passing primitives: Send/Receive Synchronous & Asynchronous Message Passing Types of Processes
Introduction to Parallel. Programming
 University of Nizhni Novgorod Faculty of Computational Mathematics & Cybernetics Introduction to Parallel Section 4. Part 3. Programming Parallel Programming with MPI Gergel V.P., Professor, D.Sc., Software
University of Nizhni Novgorod Faculty of Computational Mathematics & Cybernetics Introduction to Parallel Section 4. Part 3. Programming Parallel Programming with MPI Gergel V.P., Professor, D.Sc., Software
Practical Introduction to Message-Passing Interface (MPI)
") 1 Outline of the workshop 2 Practical Introduction to Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your
1 Outline of the workshop 2 Practical Introduction to Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your