Memory Systems and Compiler Support for MPSoC Architectures. Mahmut Kandemir and Nikil Dutt. Cap. 9
|
|
|
- Anastasia Nash
- 6 years ago
- Views:
Transcription

1 Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1
2 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional strategy that employs a single, more powerful (but complex) processor on the chip: design of an on-chip multiprocessor composed of multiple simple processor cores is simpler than that of a complex single- processor system better utilization of the silicon space MPSoC architecture can exploit loop-level parallelism at the software level in array-intensive embedded applications energy savings through careful and selective management of individual processors 2
3 MPSoC Critical Component MPSoC: platform for executing array-intensive computations commonly found in embedded image and video processing applications Most critical components: memory system applications spend a significant portion of their cycles in the memory hierarchy the memory system can contribute up to 90% of the overall system power it is expected that a significant portion of the transistors in an MPSoC-based architecture will be devoted to the memory hierarchy 3
4 Ways of optimizing the memory performance 1. constructing a suitable memory organization/ hierarchy caches, scratch pad memories, stream buffers, FIFOs, etc 2. optimizing the software (application) for it traditional scheme: performance (execution cycles) MPSoC: energy/power consumption and memory space usage 4
5 MEMORY ARCHITECTURES The application-specific nature of embedded systems presents new opportunities for aggressive customization and exploration of architectural issues è the features of the given application can be used to determine the architectural parameters. Example: floating point arithmetic è DISCUSS! Traditionally, memory issues have been separately addressed by disparate research groups: computer architects compiler writers CAD/embedded systems community 5
6 Types of Architectures (1) Cache line size, associativity, that can be customized for a given application access time is subject to cache misses (2) Scratch Pad Memory (SPM) data memory residing on-chip that is mapped into an address space disjoint from the off-chip memory but connected to the same address and data busses fast access (SRAM), single-cycle access time 6
7 Cache and SPM 7
8 Cache and SPM 8

9 Simple example if source and mask were to be accessed through the data cache, the performance would be affected by cache conflicts storing the small mask array in the SPM eliminates all data conflicts in the data cache the data cache is used for memory accesses to source, which are very regular storing mask on-chip ensures that frequently accessed data are never ejected offchip, thereby significantly improving the memory performance and energy dissipation (a) Procedure CONV. (b) Memory access in CONV. 9
10 Types of Architectures (3) DRAM multiple embedded memory (large) banks problems of modeling the access modes of synchronous DRAMs include: burst mode read/write: fast successive accesses to data in the same page interleaved row read/write modes: alternating burst accesses between banks. interleaved column access: alternating burst accesses between two chosen rows in different banks 10
11 Types of Architectures (4) Special Purpose Memories last-in, first-out protocol (LIFO) are used in microcontrollers queue or first-in, first-out protocol (FIFO) are used in network chips content-addressable memory (CAM) used in search applications 11
12 Customization of Memory Architectures Cache 1. cache line size 2. cache size if memory accesses are regular and consecutive (exhibit spatial locality), a longer cache line is desirable, since it minimizes the number of offchip accesses and exploits the locality by prefetching elements that will be needed in the immediate future. if the memory accesses are irregular, or have large strides, a shorter cache line is desirable, as this reduces off-chip memory traffic by not bringing unnecessary data into the cache. the maximum size of a cache line is the DRAM page size How to estimate? 12
13 Customization of Memory Architectures SPM + Cache MemExplore framework optimizes the on-chip data memory organization, addressing the following problem: given a certain amount of on-chip memory space, partition this into data cache and SPM so that the total access time and energy dissipation is minimized, i.e., the number of accesses to off-chip memory is minimized 13
14 DRAM optimization Multiple banks example of data set larger than the cache line Since each bank has its own private page buffer, there is no interference between the arrays, and the memory accesses do not represent a bo@leneck. 14
15 Memory Reconfigurabity reconfigure the cache (or SPM) architecture dynamically according to the application at hand The compiler can analyze a given application, divide its code into regions, and, for each region, select an optimum cache configuration for each processor Problems: architectural and circuit mechanisms for efficient and fast reconfiguration are essential control mechanisms for deciding when to reconfigure these caches are required mechanisms to determine the optimal configuration of the cache techniques for minimizing the overhead of data invalidation across different reconfiguration phases are essential 15
16 COMPILER SUPPORT Problems o Parallelism - parallelization strategy determines how memory is utilized by multiple on-chip processors and can be an important factor for achieving an acceptable performance - intrinsic data dependences - interprocessor communication costs Instruction and Data Locality - interprocessor communication can lead to frequent cache line invalidations/updates (interprocessor data sharing), which in turn increases overall latency - false sharing 16
17 Problems (cont) o Power/Energy Consumption - increasing the number of PE means powering up more processors along with their local caches (and/or SPMs) è more power - compiler should be able to balance the increase in power consumption and decrease in execution cycles o Memory Space - reducing memory space consumption might be of critical importance as doing so increases the effectiveness of on-chip memory utilization and can reduce the number of off-chip references 17
18 Solutions o Optimizing parallelism COMPILER SUPPORT - Parallelism can either be expressed by the programmer at the source level or be automatically derived by an optimizing compiler from the sequential code - By the compiler: - compiler needs to analyze data dependences and extract available parallelism - Task: 1. estimate performance, power consumption, and space requirements of a given piece of code 2. optimize the objective function under multiple constraints - It is easier to estimate the performance and energy consumption with SPMs (as opposed to caches) since the compiler is in full control of memory transfers 18
19 Solutions o Optimizing locality COMPILER SUPPORT - Locality optimization can be performed for both code and data - Goal: reduce the number of accesses to slower levels in the memory hierarchy. - Optimization of the data structures (statically or dynamically) - data space (memory layout) transformations, or data transformations for short - Example: software data prefetching 1. determine data references that are likely to be cache misses and therefore need to be prefetched 2. isolate the predicted cache miss instances through loop splitting 3. apply software pipelining and insert explicit prefetch instructions in the code. 19
20 COMPILER SUPPORT Solutions o Optimizing locality (cont) - From a multiple processor perspective, the locality problem is more challenging to tackle than the single processor - The SPM approach is simple and preferable - L1 is necessary à energy-aware coherence protocols/ algorithms in an important potential research direction 20
21 COMPILER SUPPORT Solutions o Optimizing Memory Space Utilization - consider lifetimes of program data structures/variables - enables sharing of the same data space - sharing data space may reduce performance due to data sharing - compiler should be able to resolve this tradeoff considering the performance and memory space con- straints at the same time. 21

22 COMPILER SUPPORT Solutions o Power/Energy Optimization - Power/energy and performance optimizations are conflict targets - Example: varying the number of PEs per application - more PEs è better performance (results normalized to 1 PE) 22

 -")
23 COMPILER SUPPORT Solutions o Power/Energy Optimization (cont) - But the energy increases 23
24 Solutions COMPILER SUPPORT o Power/Energy Optimization (cont) - most published work on parallelism for high-end machines is static; that is, the number of processors that execute the code is fixed for the entire execution - Alternative: adaptive parallelization - it is possible to consume much less energy by using the minimum number of processors for each loop nest, and shutting down the caches of the unused processors 24
25 Conclusions With the full advance knowledge of the applications being implemented by the system, many design parameters can be optimized and/or customized The optimal memory architecture for an applicationspecific system can be significantly different from the typical cache hierarchy of processors 25
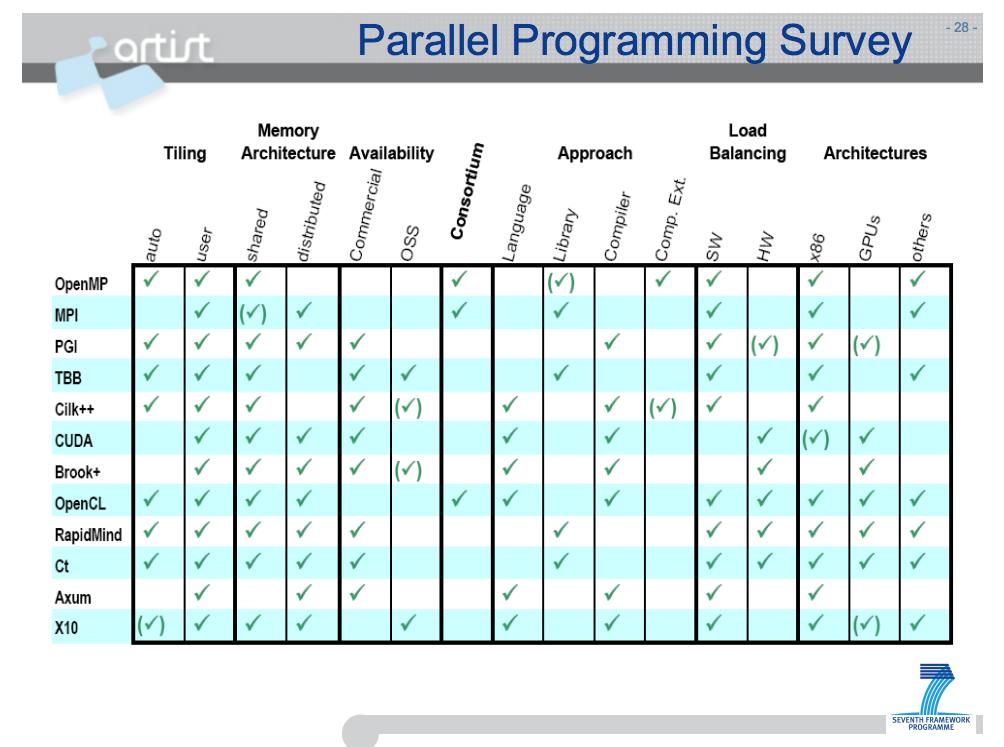
26
Memory. From Chapter 3 of High Performance Computing. c R. Leduc
 Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
Memory From Chapter 3 of High Performance Computing c 2002-2004 R. Leduc Memory Even if CPU is infinitely fast, still need to read/write data to memory. Speed of memory increasing much slower than processor
15-740/ Computer Architecture Lecture 20: Main Memory II. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 20: Main Memory II Prof. Onur Mutlu Carnegie Mellon University Today SRAM vs. DRAM Interleaving/Banking DRAM Microarchitecture Memory controller Memory buses
15-740/18-740 Computer Architecture Lecture 20: Main Memory II Prof. Onur Mutlu Carnegie Mellon University Today SRAM vs. DRAM Interleaving/Banking DRAM Microarchitecture Memory controller Memory buses
15-740/ Computer Architecture Lecture 19: Main Memory. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 19: Main Memory Prof. Onur Mutlu Carnegie Mellon University Last Time Multi-core issues in caching OS-based cache partitioning (using page coloring) Handling
15-740/18-740 Computer Architecture Lecture 19: Main Memory Prof. Onur Mutlu Carnegie Mellon University Last Time Multi-core issues in caching OS-based cache partitioning (using page coloring) Handling
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Lecture: Cache Hierarchies. Topics: cache innovations (Sections B.1-B.3, 2.1)
") Lecture: Cache Hierarchies Topics: cache innovations (Sections B.1-B.3, 2.1) 1 Types of Cache Misses Compulsory misses: happens the first time a memory word is accessed the misses for an infinite cache
Lecture: Cache Hierarchies Topics: cache innovations (Sections B.1-B.3, 2.1) 1 Types of Cache Misses Compulsory misses: happens the first time a memory word is accessed the misses for an infinite cache
10/16/2017. Miss Rate: ABC. Classifying Misses: 3C Model (Hill) Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache
 Reducing Conflict Misses: Victim Buffer. Overlapping Misses: Lockup Free Cache") Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Classifying Misses: 3C Model (Hill) Divide cache misses into three categories Compulsory (cold): never seen this address before Would miss even in infinite cache Capacity: miss caused because cache is
Module 10: "Design of Shared Memory Multiprocessors" Lecture 20: "Performance of Coherence Protocols" MOESI protocol.
 MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
Lecture: Large Caches, Virtual Memory. Topics: cache innovations (Sections 2.4, B.4, B.5)
") Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 More Cache Basics caches are split as instruction and data; L2 and L3 are unified The /L2 hierarchy can be inclusive,
Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 More Cache Basics caches are split as instruction and data; L2 and L3 are unified The /L2 hierarchy can be inclusive,
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Lecture 14: Cache Innovations and DRAM. Today: cache access basics and innovations, DRAM (Sections )
") Lecture 14: Cache Innovations and DRAM Today: cache access basics and innovations, DRAM (Sections 5.1-5.3) 1 Reducing Miss Rate Large block size reduces compulsory misses, reduces miss penalty in case
Lecture 14: Cache Innovations and DRAM Today: cache access basics and innovations, DRAM (Sections 5.1-5.3) 1 Reducing Miss Rate Large block size reduces compulsory misses, reduces miss penalty in case
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Exploiting On-Chip Data Transfers for Improving Performance of Chip-Scale Multiprocessors
 Exploiting On-Chip Data Transfers for Improving Performance of Chip-Scale Multiprocessors G. Chen 1, M. Kandemir 1, I. Kolcu 2, and A. Choudhary 3 1 Pennsylvania State University, PA 16802, USA 2 UMIST,
Exploiting On-Chip Data Transfers for Improving Performance of Chip-Scale Multiprocessors G. Chen 1, M. Kandemir 1, I. Kolcu 2, and A. Choudhary 3 1 Pennsylvania State University, PA 16802, USA 2 UMIST,
Lecture 18: DRAM Technologies
 Lecture 18: DRAM Technologies Last Time: Cache and Virtual Memory Review Today DRAM organization or, why is DRAM so slow??? Lecture 18 1 Main Memory = DRAM Lecture 18 2 Basic DRAM Architecture Lecture
Lecture 18: DRAM Technologies Last Time: Cache and Virtual Memory Review Today DRAM organization or, why is DRAM so slow??? Lecture 18 1 Main Memory = DRAM Lecture 18 2 Basic DRAM Architecture Lecture
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
A Cache Hierarchy in a Computer System
 A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
A Cache Hierarchy in a Computer System Ideally one would desire an indefinitely large memory capacity such that any particular... word would be immediately available... We are... forced to recognize the
LECTURE 5: MEMORY HIERARCHY DESIGN
 LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Lecture: Large Caches, Virtual Memory. Topics: cache innovations (Sections 2.4, B.4, B.5)
") Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 Techniques to Reduce Cache Misses Victim caches Better replacement policies pseudo-lru, NRU Prefetching, cache
Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 Techniques to Reduce Cache Misses Victim caches Better replacement policies pseudo-lru, NRU Prefetching, cache
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer and Hardware Architecture I. Benny Thörnberg Associate Professor in Electronics
 Computer and Hardware Architecture I Benny Thörnberg Associate Professor in Electronics Hardware architecture Computer architecture The functionality of a modern computer is so complex that no human can
Computer and Hardware Architecture I Benny Thörnberg Associate Professor in Electronics Hardware architecture Computer architecture The functionality of a modern computer is so complex that no human can
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Balancing DRAM Locality and Parallelism in Shared Memory CMP Systems
 Balancing DRAM Locality and Parallelism in Shared Memory CMP Systems Min Kyu Jeong, Doe Hyun Yoon^, Dam Sunwoo*, Michael Sullivan, Ikhwan Lee, and Mattan Erez The University of Texas at Austin Hewlett-Packard
Balancing DRAM Locality and Parallelism in Shared Memory CMP Systems Min Kyu Jeong, Doe Hyun Yoon^, Dam Sunwoo*, Michael Sullivan, Ikhwan Lee, and Mattan Erez The University of Texas at Austin Hewlett-Packard
Memory Hierarchy Basics. Ten Advanced Optimizations. Small and Simple
 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
Memory. Lecture 22 CS301
 Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Review: Creating a Parallel Program. Programming for Performance
 Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
Review: Creating a Parallel Program Can be done by programmer, compiler, run-time system or OS Steps for creating parallel program Decomposition Assignment of tasks to processes Orchestration Mapping (C)
SPM Management Using Markov Chain Based Data Access Prediction*
 SPM Management Using Markov Chain Based Data Access Prediction* Taylan Yemliha Syracuse University, Syracuse, NY Shekhar Srikantaiah, Mahmut Kandemir Pennsylvania State University, University Park, PA
SPM Management Using Markov Chain Based Data Access Prediction* Taylan Yemliha Syracuse University, Syracuse, NY Shekhar Srikantaiah, Mahmut Kandemir Pennsylvania State University, University Park, PA
Lecture 13: Cache Hierarchies. Today: cache access basics and innovations (Sections )
") Lecture 13: Cache Hierarchies Today: cache access basics and innovations (Sections 5.1-5.2) 1 The Cache Hierarchy Core L1 L2 L3 Off-chip memory 2 Accessing the Cache Byte address 101000 Offset 8-byte words
Lecture 13: Cache Hierarchies Today: cache access basics and innovations (Sections 5.1-5.2) 1 The Cache Hierarchy Core L1 L2 L3 Off-chip memory 2 Accessing the Cache Byte address 101000 Offset 8-byte words
15-740/ Computer Architecture, Fall 2011 Midterm Exam II
 15-740/18-740 Computer Architecture, Fall 2011 Midterm Exam II Instructor: Onur Mutlu Teaching Assistants: Justin Meza, Yoongu Kim Date: December 2, 2011 Name: Instructions: Problem I (69 points) : Problem
15-740/18-740 Computer Architecture, Fall 2011 Midterm Exam II Instructor: Onur Mutlu Teaching Assistants: Justin Meza, Yoongu Kim Date: December 2, 2011 Name: Instructions: Problem I (69 points) : Problem
1. Memory technology & Hierarchy
 1 Memory technology & Hierarchy Caching and Virtual Memory Parallel System Architectures Andy D Pimentel Caches and their design cf Henessy & Patterson, Chap 5 Caching - summary Caches are small fast memories
1 Memory technology & Hierarchy Caching and Virtual Memory Parallel System Architectures Andy D Pimentel Caches and their design cf Henessy & Patterson, Chap 5 Caching - summary Caches are small fast memories
Caches 3/23/17. Agenda. The Dataflow Model (of a Computer)
") Agenda Caches Samira Khan March 23, 2017 Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Agenda Caches Samira Khan March 23, 2017 Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Caches. Samira Khan March 23, 2017
 Caches Samira Khan March 23, 2017 Agenda Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Caches Samira Khan March 23, 2017 Agenda Review from last lecture Data flow model Memory hierarchy More Caches The Dataflow Model (of a Computer) Von Neumann model: An instruction is fetched and executed
Chapter 5. Topics in Memory Hierachy. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ.
 Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
ECE 5730 Memory Systems
 ECE 5730 Memory Systems Spring 2009 Off-line Cache Content Management Lecture 7: 1 Quiz 4 on Tuesday Announcements Only covers today s lecture No office hours today Lecture 7: 2 Where We re Headed Off-line
ECE 5730 Memory Systems Spring 2009 Off-line Cache Content Management Lecture 7: 1 Quiz 4 on Tuesday Announcements Only covers today s lecture No office hours today Lecture 7: 2 Where We re Headed Off-line
Computer Architecture Spring 2016
 omputer Architecture Spring 2016 Lecture 09: Prefetching Shuai Wang Department of omputer Science and Technology Nanjing University Prefetching(1/3) Fetch block ahead of demand Target compulsory, capacity,
omputer Architecture Spring 2016 Lecture 09: Prefetching Shuai Wang Department of omputer Science and Technology Nanjing University Prefetching(1/3) Fetch block ahead of demand Target compulsory, capacity,
Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1)
") Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Department of Electr rical Eng ineering, Chapter 5 Large and Fast: Exploiting Memory Hierarchy (Part 1) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering,
Introduction to OpenMP. Lecture 10: Caches
 Introduction to OpenMP Lecture 10: Caches Overview Why caches are needed How caches work Cache design and performance. The memory speed gap Moore s Law: processors speed doubles every 18 months. True for
Introduction to OpenMP Lecture 10: Caches Overview Why caches are needed How caches work Cache design and performance. The memory speed gap Moore s Law: processors speed doubles every 18 months. True for
Linköping University Post Print. epuma: a novel embedded parallel DSP platform for predictable computing
 Linköping University Post Print epuma: a novel embedded parallel DSP platform for predictable computing Jian Wang, Joar Sohl, Olof Kraigher and Dake Liu N.B.: When citing this work, cite the original article.
Linköping University Post Print epuma: a novel embedded parallel DSP platform for predictable computing Jian Wang, Joar Sohl, Olof Kraigher and Dake Liu N.B.: When citing this work, cite the original article.
Chapter 18 Parallel Processing
 Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 18 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data stream - SIMD Multiple instruction, single data stream - MISD
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 9: Performance Issues in Shared Memory. The Lecture Contains:
 The Lecture Contains: Data Access and Communication Data Access Artifactual Comm. Capacity Problem Temporal Locality Spatial Locality 2D to 4D Conversion Transfer Granularity Worse: False Sharing Contention
The Lecture Contains: Data Access and Communication Data Access Artifactual Comm. Capacity Problem Temporal Locality Spatial Locality 2D to 4D Conversion Transfer Granularity Worse: False Sharing Contention
Memory Hierarchy Basics
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS
 MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing
MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing
Chapter 6 Caches. Computer System. Alpha Chip Photo. Topics. Memory Hierarchy Locality of Reference SRAM Caches Direct Mapped Associative
 Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip
 STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Introduction. Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: We study the bandwidth problem
 Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
k -bit address bus n-bit data bus Control lines ( R W, MFC, etc.)
") THE MEMORY SYSTEM SOME BASIC CONCEPTS Maximum size of the Main Memory byte-addressable CPU-Main Memory Connection, Processor MAR MDR k -bit address bus n-bit data bus Memory Up to 2 k addressable locations
THE MEMORY SYSTEM SOME BASIC CONCEPTS Maximum size of the Main Memory byte-addressable CPU-Main Memory Connection, Processor MAR MDR k -bit address bus n-bit data bus Memory Up to 2 k addressable locations
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
SRAMs to Memory. Memory Hierarchy. Locality. Low Power VLSI System Design Lecture 10: Low Power Memory Design
 SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
SRAMs to Memory Low Power VLSI System Design Lecture 0: Low Power Memory Design Prof. R. Iris Bahar October, 07 Last lecture focused on the SRAM cell and the D or D memory architecture built from these
CS24: INTRODUCTION TO COMPUTING SYSTEMS. Spring 2014 Lecture 14
 CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2014 Lecture 14 LAST TIME! Examined several memory technologies: SRAM volatile memory cells built from transistors! Fast to use, larger memory cells (6+ transistors
CS24: INTRODUCTION TO COMPUTING SYSTEMS Spring 2014 Lecture 14 LAST TIME! Examined several memory technologies: SRAM volatile memory cells built from transistors! Fast to use, larger memory cells (6+ transistors
Memory Technology. Chapter 5. Principle of Locality. Chapter 5 Large and Fast: Exploiting Memory Hierarchy 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
ECE/CS 757: Homework 1
 ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
2 Improved Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers [1]
![2 Improved Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers [1]](/thumbs/73/69207197.jpg "2 Improved Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers [1]") EE482: Advanced Computer Organization Lecture #7 Processor Architecture Stanford University Tuesday, June 6, 2000 Memory Systems and Memory Latency Lecture #7: Wednesday, April 19, 2000 Lecturer: Brian
EE482: Advanced Computer Organization Lecture #7 Processor Architecture Stanford University Tuesday, June 6, 2000 Memory Systems and Memory Latency Lecture #7: Wednesday, April 19, 2000 Lecturer: Brian
Embedded Systems Design: A Unified Hardware/Software Introduction. Outline. Chapter 5 Memory. Introduction. Memory: basic concepts
 Hardware/Software Introduction Chapter 5 Memory Outline Memory Write Ability and Storage Permanence Common Memory Types Composing Memory Memory Hierarchy and Cache Advanced RAM 1 2 Introduction Memory:
Hardware/Software Introduction Chapter 5 Memory Outline Memory Write Ability and Storage Permanence Common Memory Types Composing Memory Memory Hierarchy and Cache Advanced RAM 1 2 Introduction Memory:
Embedded Systems Design: A Unified Hardware/Software Introduction. Chapter 5 Memory. Outline. Introduction
 Hardware/Software Introduction Chapter 5 Memory 1 Outline Memory Write Ability and Storage Permanence Common Memory Types Composing Memory Memory Hierarchy and Cache Advanced RAM 2 Introduction Embedded
Hardware/Software Introduction Chapter 5 Memory 1 Outline Memory Write Ability and Storage Permanence Common Memory Types Composing Memory Memory Hierarchy and Cache Advanced RAM 2 Introduction Embedded
Computer Architecture Lecture 24: Memory Scheduling
 18-447 Computer Architecture Lecture 24: Memory Scheduling Prof. Onur Mutlu Presented by Justin Meza Carnegie Mellon University Spring 2014, 3/31/2014 Last Two Lectures Main Memory Organization and DRAM
18-447 Computer Architecture Lecture 24: Memory Scheduling Prof. Onur Mutlu Presented by Justin Meza Carnegie Mellon University Spring 2014, 3/31/2014 Last Two Lectures Main Memory Organization and DRAM
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Memory Organization Part II
 ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Organization Part II Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn,
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Organization Part II Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn,
Cray XE6 Performance Workshop
 Cray XE6 Performance Workshop Mark Bull David Henty EPCC, University of Edinburgh Overview Why caches are needed How caches work Cache design and performance. 2 1 The memory speed gap Moore s Law: processors
Cray XE6 Performance Workshop Mark Bull David Henty EPCC, University of Edinburgh Overview Why caches are needed How caches work Cache design and performance. 2 1 The memory speed gap Moore s Law: processors
740: Computer Architecture, Fall 2013 SOLUTIONS TO Midterm I
 Instructions: Full Name: Andrew ID (print clearly!): 740: Computer Architecture, Fall 2013 SOLUTIONS TO Midterm I October 23, 2013 Make sure that your exam has 15 pages and is not missing any sheets, then
Instructions: Full Name: Andrew ID (print clearly!): 740: Computer Architecture, Fall 2013 SOLUTIONS TO Midterm I October 23, 2013 Make sure that your exam has 15 pages and is not missing any sheets, then
AS the processor-memory speed gap continues to widen,
 IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 7, JULY 2004 843 Design and Optimization of Large Size and Low Overhead Off-Chip Caches Zhao Zhang, Member, IEEE, Zhichun Zhu, Member, IEEE, and Xiaodong Zhang,
IEEE TRANSACTIONS ON COMPUTERS, VOL. 53, NO. 7, JULY 2004 843 Design and Optimization of Large Size and Low Overhead Off-Chip Caches Zhao Zhang, Member, IEEE, Zhichun Zhu, Member, IEEE, and Xiaodong Zhang,
Memory Consistency. Challenges. Program order Memory access order
 Memory Consistency Memory Consistency Memory Consistency Reads and writes of the shared memory face consistency problem Need to achieve controlled consistency in memory events Shared memory behavior determined
Memory Consistency Memory Consistency Memory Consistency Reads and writes of the shared memory face consistency problem Need to achieve controlled consistency in memory events Shared memory behavior determined
740: Computer Architecture, Fall 2013 Midterm I
 Instructions: Full Name: Andrew ID (print clearly!): 740: Computer Architecture, Fall 2013 Midterm I October 23, 2013 Make sure that your exam has 17 pages and is not missing any sheets, then write your
Instructions: Full Name: Andrew ID (print clearly!): 740: Computer Architecture, Fall 2013 Midterm I October 23, 2013 Make sure that your exam has 17 pages and is not missing any sheets, then write your
Cache Memory COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Chapter 5 Memory Hierarchy Design. In-Cheol Park Dept. of EE, KAIST
 Chapter 5 Memory Hierarchy Design In-Cheol Park Dept. of EE, KAIST Why cache? Microprocessor performance increment: 55% per year Memory performance increment: 7% per year Principles of locality Spatial
Chapter 5 Memory Hierarchy Design In-Cheol Park Dept. of EE, KAIST Why cache? Microprocessor performance increment: 55% per year Memory performance increment: 7% per year Principles of locality Spatial
Addressing the Memory Wall
 Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
ECE 485/585 Midterm Exam
 ECE 485/585 Midterm Exam Time allowed: 100 minutes Total Points: 65 Points Scored: Name: Problem No. 1 (12 points) For each of the following statements, indicate whether the statement is TRUE or FALSE:
ECE 485/585 Midterm Exam Time allowed: 100 minutes Total Points: 65 Points Scored: Name: Problem No. 1 (12 points) For each of the following statements, indicate whether the statement is TRUE or FALSE:
ECEN 449 Microprocessor System Design. Memories. Texas A&M University
 ECEN 449 Microprocessor System Design Memories 1 Objectives of this Lecture Unit Learn about different types of memories SRAM/DRAM/CAM Flash 2 SRAM Static Random Access Memory 3 SRAM Static Random Access
ECEN 449 Microprocessor System Design Memories 1 Objectives of this Lecture Unit Learn about different types of memories SRAM/DRAM/CAM Flash 2 SRAM Static Random Access Memory 3 SRAM Static Random Access
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
EE414 Embedded Systems Ch 5. Memory Part 2/2
 EE414 Embedded Systems Ch 5. Memory Part 2/2 Byung Kook Kim School of Electrical Engineering Korea Advanced Institute of Science and Technology Overview 6.1 introduction 6.2 Memory Write Ability and Storage
EE414 Embedded Systems Ch 5. Memory Part 2/2 Byung Kook Kim School of Electrical Engineering Korea Advanced Institute of Science and Technology Overview 6.1 introduction 6.2 Memory Write Ability and Storage
Memory systems. Memory technology. Memory technology Memory hierarchy Virtual memory
 Memory systems Memory technology Memory hierarchy Virtual memory Memory technology DRAM Dynamic Random Access Memory bits are represented by an electric charge in a small capacitor charge leaks away, need
Memory systems Memory technology Memory hierarchy Virtual memory Memory technology DRAM Dynamic Random Access Memory bits are represented by an electric charge in a small capacitor charge leaks away, need
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Review: Major Components of a Computer Processor Devices Control Memory Input Datapath Output Secondary Memory (Disk) Main Memory Cache Performance
COSC 6385 Computer Architecture - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Edgar Gabriel Spring 2018 Types of cache misses Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity
COSC 6385 Computer Architecture - Memory Hierarchies (II) Edgar Gabriel Spring 2018 Types of cache misses Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity
CS252 S05. Main memory management. Memory hardware. The scale of things. Memory hardware (cont.) Bottleneck
 Bottleneck") Main memory management CMSC 411 Computer Systems Architecture Lecture 16 Memory Hierarchy 3 (Main Memory & Memory) Questions: How big should main memory be? How to handle reads and writes? How to find
Main memory management CMSC 411 Computer Systems Architecture Lecture 16 Memory Hierarchy 3 (Main Memory & Memory) Questions: How big should main memory be? How to handle reads and writes? How to find
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
Tutorial 11. Final Exam Review
 Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Tutorial 11 Final Exam Review Introduction Instruction Set Architecture: contract between programmer and designers (e.g.: IA-32, IA-64, X86-64) Computer organization: describe the functional units, cache
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
CHAPTER 4 MEMORY HIERARCHIES TYPICAL MEMORY HIERARCHY TYPICAL MEMORY HIERARCHY: THE PYRAMID CACHE PERFORMANCE MEMORY HIERARCHIES CACHE DESIGN
 CHAPTER 4 TYPICAL MEMORY HIERARCHY MEMORY HIERARCHIES MEMORY HIERARCHIES CACHE DESIGN TECHNIQUES TO IMPROVE CACHE PERFORMANCE VIRTUAL MEMORY SUPPORT PRINCIPLE OF LOCALITY: A PROGRAM ACCESSES A RELATIVELY
CHAPTER 4 TYPICAL MEMORY HIERARCHY MEMORY HIERARCHIES MEMORY HIERARCHIES CACHE DESIGN TECHNIQUES TO IMPROVE CACHE PERFORMANCE VIRTUAL MEMORY SUPPORT PRINCIPLE OF LOCALITY: A PROGRAM ACCESSES A RELATIVELY
15-740/ Computer Architecture
 15-740/18-740 Computer Architecture Lecture 19: Caching II Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/31/2011 Announcements Milestone II Due November 4, Friday Please talk with us if you
15-740/18-740 Computer Architecture Lecture 19: Caching II Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/31/2011 Announcements Milestone II Due November 4, Friday Please talk with us if you
Effect of memory latency
 CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
L2 cache provides additional on-chip caching space. L2 cache captures misses from L1 cache. Summary
 HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
HY425 Lecture 13: Improving Cache Performance Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 25, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 13: Improving Cache Performance 1 / 40
CS650 Computer Architecture. Lecture 9 Memory Hierarchy - Main Memory
 CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
The Impact of Parallel Loop Scheduling Strategies on Prefetching in a Shared-Memory Multiprocessor
 IEEE Transactions on Parallel and Distributed Systems, Vol. 5, No. 6, June 1994, pp. 573-584.. The Impact of Parallel Loop Scheduling Strategies on Prefetching in a Shared-Memory Multiprocessor David J.
IEEE Transactions on Parallel and Distributed Systems, Vol. 5, No. 6, June 1994, pp. 573-584.. The Impact of Parallel Loop Scheduling Strategies on Prefetching in a Shared-Memory Multiprocessor David J.
Design of Embedded DSP Processors Unit 5: Data access. 9/11/2017 Unit 5 of TSEA H1 1
 Design of Embedded DSP Processors Unit 5: Data access 9/11/2017 Unit 5 of TSEA26-2017 H1 1 Data memory in a Processor Store Data FIFO supporting DSP executions Computing buffer Parameter storage Access
Design of Embedded DSP Processors Unit 5: Data access 9/11/2017 Unit 5 of TSEA26-2017 H1 1 Data memory in a Processor Store Data FIFO supporting DSP executions Computing buffer Parameter storage Access
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
The levels of a memory hierarchy. Main. Memory. 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms
 The levels of a memory hierarchy CPU registers C A C H E Memory bus Main Memory I/O bus External memory 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms 1 1 Some useful definitions When the CPU finds a requested
The levels of a memory hierarchy CPU registers C A C H E Memory bus Main Memory I/O bus External memory 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms 1 1 Some useful definitions When the CPU finds a requested
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
CACHE MEMORIES ADVANCED COMPUTER ARCHITECTURES. Slides by: Pedro Tomás
 CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design Edited by Mansour Al Zuair 1 Introduction Programmers want unlimited amounts of memory with low latency Fast
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design Edited by Mansour Al Zuair 1 Introduction Programmers want unlimited amounts of memory with low latency Fast
Performance metrics for caches
 Performance metrics for caches Basic performance metric: hit ratio h h = Number of memory references that hit in the cache / total number of memory references Typically h = 0.90 to 0.97 Equivalent metric:
Performance metrics for caches Basic performance metric: hit ratio h h = Number of memory references that hit in the cache / total number of memory references Typically h = 0.90 to 0.97 Equivalent metric:
Advanced Memory Organizations
 CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
Module 5a: Introduction To Memory System (MAIN MEMORY)
") Module 5a: Introduction To Memory System (MAIN MEMORY) R E F E R E N C E S : S T A L L I N G S, C O M P U T E R O R G A N I Z A T I O N A N D A R C H I T E C T U R E M O R R I S M A N O, C O M P U T E
Module 5a: Introduction To Memory System (MAIN MEMORY) R E F E R E N C E S : S T A L L I N G S, C O M P U T E R O R G A N I Z A T I O N A N D A R C H I T E C T U R E M O R R I S M A N O, C O M P U T E