Ajitha Rajan, Christophe Dubach. in preparation for: ISSTA July 2017 Santa Barbara, CA
|
|
|
- Meghan Horn
- 5 years ago
- Views:
Transcription


1 COMPILER-ASSISTED TEST ACCELERATION ON GPUS FOR EMBEDDED SOFTWARE VANYA YANEVA Ajitha Rajan, Christophe Dubach in preparation for: ISSTA July 2017 Santa Barbara, CA



2 EMBEDDED SOFTWARE IS EVERYWHERE ITS SAFETY AND CORRECTNESS ARE CRUCIAL FUNCTIONAL TESTING IS CRITICAL

3 FUNCTIONAL TESTING CAN BE EXTREMELY TIME CONSUMING TESTING IS AN IDEAL CANDIDATE FOR PARALLELISATION


4 Expensive CPU SERVERS Do not scale to thousands of threads Can be extremely underutilised GPUS Cheap and widely available Large-scale parallelism, thousands of threads SIMD architecture suited to functional testing

5 EXECUTE TESTS IN PARALLEL ON THE GPU THREADS CHALLENGES Usability Scope Performance? Ajitha Rajan, Subodh Sharma, Peter Schrammel, Daniel Kroening. Accelerated test execution using GPUs. In proceedings of ASE 2014, pages , Sweden, Nov 2014.
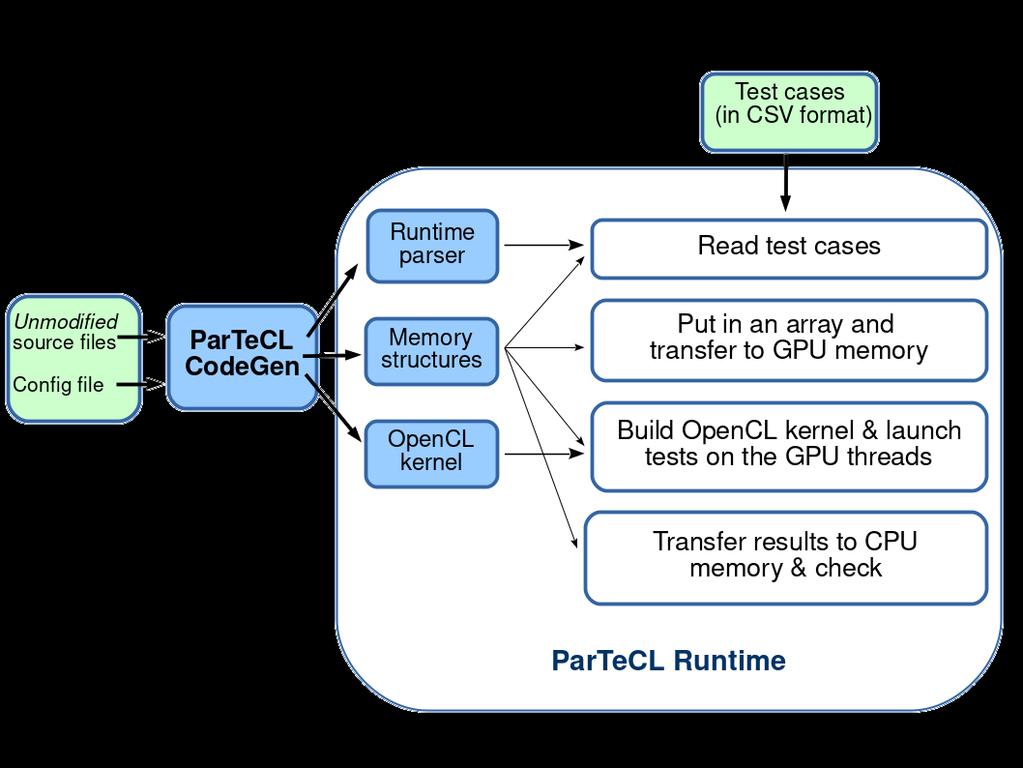
6 INTRODUCING PARTECL Test cases (CSV format) Unmodified source files ParTeCL CodeGen OpenCL ParTeCL Runtime Execution on the GPU Config file
7 #include <stdio.h> #include <stdlib.h> int c; Example: int addc(int a, int b){ return a + b + c; } int main(int argc, char* argv[]){ int a = atoi(argv[1]); int b = atoi(argv[2]); c = 3; int sum = addc(a, b); INPUTS Configuration: input: int a 1 input: int b 2 result: int sum variable: sum Test cases: } printf("%d + %d + %c = %d\n", a, b, c, sum);
8 Example: PARTECL CODEGEN OpenCL: #include <stdio.h> #include <stdlib.h> int c; int addc(int a, int b){ return a + b + c; } int main(int argc, char* argv[]){ int a = atoi(argv[1]); int b = atoi(argv[2]); c = 3; int sum = addc(a, b); #include "structs.h" //#include <stdio.h> //#include <stdlib.h> /*int c;*/ int addc(int a, int b, int *c){ return a + b + (*c); } kernel void main_kernel( global struct test_input* inputs, global struct test_result* results){ int idx = get_global_id(0); struct test_input input_gen = inputs[idx]; global struct test_result *result_gen = &results[idx]; } printf("%d + %d + %c = %d\n", a, b, c, sum); } int argc = input_gen.argc; result_gen->test_case_num = input_gen.test_case_num; int c; int a = input_gen.a; int b = input_gen.b; c = 3; int sum = addc(a, b, &c); /*printf("%d + %d + %c = %d\n", a, b, c, sum);*/ result_gen->sum = sum;
9 CODE TRANSFORMATIONS global scope variables command line arguments standard in/out standard library (partial support): clclibc

10 PARTECL RUNTIME
11 CHALLENGES Usability Scope Performance? Test cases (CSV format) Unmodified source files ParTeCL CodeGen OpenCL ParTeCL Runtime Execution on the GPU Config file
12 EVALUATION 1. Speedup against CPU 2. Data transfer overhead 3. Comparison to a multi-core CPU 4. Correctness
13 EXPERIMENT Subjects: EEMBC - Industry-standard benchmark suite for embedded so ware Hardware: GPU - NVidia Tesla K40m; CPU - Intel Xeon, 8 cores Test suite size: 130K
14 SPEEDUP AGAINST CPU
15 DATA TRANSFER OVERHEAD Execution time [ms] viterb00 Input transfer Output transfer Kernelexecution Execution time [ms] fbital00 Input transfer Output transfer Kernelexecution Execution time [ms] a2time01 Input transfer Output transfer Kernelexecution Execution time [ms] autcor00 Input transfer Output transfer Kernelexecution Number of tests (log base 2 s Number of tests (log base 2 sc Number of tests (log base 2 s Number of tests (log base 2 sc Execution time [ms] tblook01 Input transfer Output transfer Kernelexecution Execution time [ms]60 10 conven00 Input transfer Output transfer Kernelexecution Execution time [ms] fft00 Input transfer Output transfer Kernelexecution Execution time [ms] puwmod01 Input transfer Output transfer Kernelexecution Execution time [ms] rspeed01 Input transfer Output transfer Kernelexecution Number of tests (log base 2 s Number of tests (log base 2 sc Number of tests (log base 2 sc Number of tests (log base 2 s Number of tests (log base 2 s
16 DATA TRANSFER OVERHEAD
17 COMPARISON TO A MULTI-CORE CPU
18 CHALLENGES Usability Scope Performance
19 CORRECTNESS For all 9 benchmarks, testing results from the GPU are an exact match to the testing results from the CPU.
20 SUMMARY Automatic GPU code generation Automatic test execution on the GPU threads Speedup of up to 53x (avg 16x) on EEMBC benchmarks Correct testing results FUTURE WORK Extend evaluation & scope Analyse & improve performance
21 THANKS ParTeCL CodeGen ParTeCL Runtime clclibc github.com/wyaneva/partecl-codegen github.com/wyaneva/partecl-runtime github.com/wyaneva/clclibc

22
23 C FEATURES Out of the box: pure functions, function calls, double precision (for OpenCL 1.2) With transformations: standard in/out global scope variables standard library calls (partial support) Unsupported (yet): dynamic memory allocation file I/O recursion
COMPILER-ASSISTED TEST ACCELERATION ON GPUS FOR EMBEDDED SOFTWARE
 COMPILER-ASSISTED TEST ACCELERATION ON GPUS FOR EMBEDDED SOFTWARE VANYA YANEVA Ajitha Rajan, Christophe Dubach ISSTA 2017 10 July 2017 Santa Barbara, CA EMBEDDED SOFTWARE IS EVERYWHERE ITS SAFETY AND CORRECTNESS
COMPILER-ASSISTED TEST ACCELERATION ON GPUS FOR EMBEDDED SOFTWARE VANYA YANEVA Ajitha Rajan, Christophe Dubach ISSTA 2017 10 July 2017 Santa Barbara, CA EMBEDDED SOFTWARE IS EVERYWHERE ITS SAFETY AND CORRECTNESS
Accelerated Test Execution Using GPUs
 Accelerated Test Execution Using GPUs Vanya Yaneva Supervisors: Ajitha Rajan, Christophe Dubach Mathworks May 27, 2016 The Problem Software testing is time consuming Functional testing The Problem Software
Accelerated Test Execution Using GPUs Vanya Yaneva Supervisors: Ajitha Rajan, Christophe Dubach Mathworks May 27, 2016 The Problem Software testing is time consuming Functional testing The Problem Software
Compiler-Assisted Test Acceleration on GPUs for Embedded Software
 Compiler-Assisted Test Acceleration on GPUs for Embedded Software Vanya Yaneva School of Informatics University of Edinburgh, UK vanya.yaneva@ed.ac.uk Ajitha Rajan School of Informatics University of Edinburgh,
Compiler-Assisted Test Acceleration on GPUs for Embedded Software Vanya Yaneva School of Informatics University of Edinburgh, UK vanya.yaneva@ed.ac.uk Ajitha Rajan School of Informatics University of Edinburgh,
Automated Test Execution Using GPUs
 Automated Test Execution Using GPUs Vanya Yaneva E H U N I V E R S I T Y T O H F R G E D I N B U Master of Science by Research Laboratory for Foundations of Computer Science CDT in Pervasive Parallelism
Automated Test Execution Using GPUs Vanya Yaneva E H U N I V E R S I T Y T O H F R G E D I N B U Master of Science by Research Laboratory for Foundations of Computer Science CDT in Pervasive Parallelism
Parallel Hybrid Computing F. Bodin, CAPS Entreprise
 Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
Pragma-based GPU Programming and HMPP Workbench. Scott Grauer-Gray
 Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Dealing with Heterogeneous Multicores
 Dealing with Heterogeneous Multicores François Bodin INRIA-UIUC, June 12 th, 2009 Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism
Dealing with Heterogeneous Multicores François Bodin INRIA-UIUC, June 12 th, 2009 Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism
ECE 574 Cluster Computing Lecture 10
 ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
When you add a number to a pointer, that number is added, but first it is multiplied by the sizeof the type the pointer points to.
 Refresher When you add a number to a pointer, that number is added, but first it is multiplied by the sizeof the type the pointer points to. i.e. char *ptr1 = malloc(1); ptr1 + 1; // adds 1 to pointer
Refresher When you add a number to a pointer, that number is added, but first it is multiplied by the sizeof the type the pointer points to. i.e. char *ptr1 = malloc(1); ptr1 + 1; // adds 1 to pointer
Data Parallel Algorithmic Skeletons with Accelerator Support
 MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support Steffen Ernsting and Herbert Kuchen July 2, 2015 Agenda WESTFÄLISCHE MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support
MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support Steffen Ernsting and Herbert Kuchen July 2, 2015 Agenda WESTFÄLISCHE MÜNSTER Data Parallel Algorithmic Skeletons with Accelerator Support
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Performance Diagnosis for Hybrid CPU/GPU Environments
 Performance Diagnosis for Hybrid CPU/GPU Environments Michael M. Smith and Karen L. Karavanic Computer Science Department Portland State University Performance Diagnosis for Hybrid CPU/GPU Environments
Performance Diagnosis for Hybrid CPU/GPU Environments Michael M. Smith and Karen L. Karavanic Computer Science Department Portland State University Performance Diagnosis for Hybrid CPU/GPU Environments
CSCI565 Compiler Design
 CSCI565 Compiler Design Spring 2011 Homework 4 Solution Due Date: April 6, 2011 in class Problem 1: Activation Records and Stack Layout [50 points] Consider the following C source program shown below.
CSCI565 Compiler Design Spring 2011 Homework 4 Solution Due Date: April 6, 2011 in class Problem 1: Activation Records and Stack Layout [50 points] Consider the following C source program shown below.
CS16 Midterm Exam 1 E01, 10S, Phill Conrad, UC Santa Barbara Wednesday, 04/21/2010, 1pm-1:50pm
 CS16 Midterm Exam 1 E01, 10S, Phill Conrad, UC Santa Barbara Wednesday, 04/21/2010, 1pm-1:50pm Name: Umail Address: @ umail.ucsb.edu Circle Lab section: 9am 10am 11am noon (Link to Printer Friendly-PDF
CS16 Midterm Exam 1 E01, 10S, Phill Conrad, UC Santa Barbara Wednesday, 04/21/2010, 1pm-1:50pm Name: Umail Address: @ umail.ucsb.edu Circle Lab section: 9am 10am 11am noon (Link to Printer Friendly-PDF
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening. Alberto Magni, Christophe Dubach, Michael O'Boyle
 A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
OpenCL C. Matt Sellitto Dana Schaa Northeastern University NUCAR
 OpenCL C Matt Sellitto Dana Schaa Northeastern University NUCAR OpenCL C Is used to write kernels when working with OpenCL Used to code the part that runs on the device Based on C99 with some extensions
OpenCL C Matt Sellitto Dana Schaa Northeastern University NUCAR OpenCL C Is used to write kernels when working with OpenCL Used to code the part that runs on the device Based on C99 with some extensions
CSCI-243 Exam 1 Review February 22, 2015 Presented by the RIT Computer Science Community
 CSCI-243 Exam 1 Review February 22, 2015 Presented by the RIT Computer Science Community http://csc.cs.rit.edu History and Evolution of Programming Languages 1. Explain the relationship between machine
CSCI-243 Exam 1 Review February 22, 2015 Presented by the RIT Computer Science Community http://csc.cs.rit.edu History and Evolution of Programming Languages 1. Explain the relationship between machine
cuda-on-cl A compiler and runtime for running NVIDIA CUDA C++11 applications on OpenCL 1.2 devices Hugh Perkins (ASAPP)
") cuda-on-cl A compiler and runtime for running NVIDIA CUDA C++11 applications on OpenCL 1.2 devices Hugh Perkins (ASAPP) Demo: CUDA on Intel HD5500 global void setvalue(float *data, int idx, float value)
cuda-on-cl A compiler and runtime for running NVIDIA CUDA C++11 applications on OpenCL 1.2 devices Hugh Perkins (ASAPP) Demo: CUDA on Intel HD5500 global void setvalue(float *data, int idx, float value)
GPU Programming with Ateji PX June 8 th Ateji All rights reserved.
 GPU Programming with Ateji PX June 8 th 2010 Ateji All rights reserved. Goals Write once, run everywhere, even on a GPU Target heterogeneous architectures from Java GPU accelerators OpenCL standard Get
GPU Programming with Ateji PX June 8 th 2010 Ateji All rights reserved. Goals Write once, run everywhere, even on a GPU Target heterogeneous architectures from Java GPU accelerators OpenCL standard Get
C programming for beginners
 C programming for beginners Lesson 2 December 10, 2008 (Medical Physics Group, UNED) C basics Lesson 2 1 / 11 Main task What are the values of c that hold bounded? x n+1 = x n2 + c (x ; c C) (Medical Physics
C programming for beginners Lesson 2 December 10, 2008 (Medical Physics Group, UNED) C basics Lesson 2 1 / 11 Main task What are the values of c that hold bounded? x n+1 = x n2 + c (x ; c C) (Medical Physics
ECE264 Fall 2013 Exam 1, September 24, 2013
 ECE264 Fall 2013 Exam 1, September 24, 2013 In signing this statement, I hereby certify that the work on this exam is my own and that I have not copied the work of any other student while completing it.
ECE264 Fall 2013 Exam 1, September 24, 2013 In signing this statement, I hereby certify that the work on this exam is my own and that I have not copied the work of any other student while completing it.
Computer Systems Assignment 2: Fork and Threads Package
 Autumn Term 2018 Distributed Computing Computer Systems Assignment 2: Fork and Threads Package Assigned on: October 5, 2018 Due by: October 12, 2018 1 Understanding fork() and exec() Creating new processes
Autumn Term 2018 Distributed Computing Computer Systems Assignment 2: Fork and Threads Package Assigned on: October 5, 2018 Due by: October 12, 2018 1 Understanding fork() and exec() Creating new processes
3L Diamond. Multiprocessor DSP RTOS
 3L Diamond Multiprocessor DSP RTOS What is 3L Diamond? Diamond is an operating system designed for multiprocessor DSP applications. With Diamond you develop efficient applications that use networks of
3L Diamond Multiprocessor DSP RTOS What is 3L Diamond? Diamond is an operating system designed for multiprocessor DSP applications. With Diamond you develop efficient applications that use networks of
A Code Merging Optimization Technique for GPU. Ryan Taylor Xiaoming Li University of Delaware
 A Code Merging Optimization Technique for GPU Ryan Taylor Xiaoming Li University of Delaware FREE RIDE MAIN FINDING A GPU program can use the spare resources of another GPU program without hurting its
A Code Merging Optimization Technique for GPU Ryan Taylor Xiaoming Li University of Delaware FREE RIDE MAIN FINDING A GPU program can use the spare resources of another GPU program without hurting its
OpenACC (Open Accelerators - Introduced in 2012)
") OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
Parallel Computing. November 20, W.Homberg
 Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
Mitglied der Helmholtz-Gemeinschaft Parallel Computing November 20, 2017 W.Homberg Why go parallel? Problem too large for single node Job requires more memory Shorter time to solution essential Better
OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel
 www.bsc.es OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel Guray Ozen guray.ozen@bsc.es Exascale in BSC Marenostrum 4 (13.7 Petaflops ) General purpose cluster (3400
www.bsc.es OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel Guray Ozen guray.ozen@bsc.es Exascale in BSC Marenostrum 4 (13.7 Petaflops ) General purpose cluster (3400
Lesson 5: Functions and Libraries. EE3490E: Programming S1 2018/2019 Dr. Đào Trung Kiên Hanoi Univ. of Science and Technology
 Lesson 5: Functions and Libraries 1 Functions 2 Overview Function is a block of statements which performs a specific task, and can be called by others Each function has a name (not identical to any other),
Lesson 5: Functions and Libraries 1 Functions 2 Overview Function is a block of statements which performs a specific task, and can be called by others Each function has a name (not identical to any other),
Parallel Programming Using MPI
 Parallel Programming Using MPI Prof. Hank Dietz KAOS Seminar, February 8, 2012 University of Kentucky Electrical & Computer Engineering Parallel Processing Process N pieces simultaneously, get up to a
Parallel Programming Using MPI Prof. Hank Dietz KAOS Seminar, February 8, 2012 University of Kentucky Electrical & Computer Engineering Parallel Processing Process N pieces simultaneously, get up to a
 ntroduction to C CS 2022: ntroduction to C nstructor: Hussam Abu-Libdeh (based on slides by Saikat Guha) Fall 2011, Lecture 1 ntroduction to C CS 2022, Fall 2011, Lecture 1 History of C Writing code in
ntroduction to C CS 2022: ntroduction to C nstructor: Hussam Abu-Libdeh (based on slides by Saikat Guha) Fall 2011, Lecture 1 ntroduction to C CS 2022, Fall 2011, Lecture 1 History of C Writing code in
CS 0449 Sample Midterm
 Name: CS 0449 Sample Midterm Multiple Choice 1.) Given char *a = Hello ; char *b = World;, which of the following would result in an error? A) strlen(a) B) strcpy(a, b) C) strcmp(a, b) D) strstr(a, b)
Name: CS 0449 Sample Midterm Multiple Choice 1.) Given char *a = Hello ; char *b = World;, which of the following would result in an error? A) strlen(a) B) strcpy(a, b) C) strcmp(a, b) D) strstr(a, b)
Generating Performance Portable Code using Rewrite Rules
 Generating Performance Portable Code using Rewrite Rules From High-Level Functional Expressions to High-Performance OpenCL Code Michel Steuwer Christian Fensch Sam Lindley Christophe Dubach The Problem(s)
Generating Performance Portable Code using Rewrite Rules From High-Level Functional Expressions to High-Performance OpenCL Code Michel Steuwer Christian Fensch Sam Lindley Christophe Dubach The Problem(s)
Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators
 Remote CUDA (rcuda) Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators Better performance-watt, performance-cost
Remote CUDA (rcuda) Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators Better performance-watt, performance-cost
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC. Jeff Larkin, NVIDIA Developer Technologies
 INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
ECE 264 Exam 2. 6:30-7:30PM, March 9, You must sign here. Otherwise you will receive a 1-point penalty.
 ECE 264 Exam 2 6:30-7:30PM, March 9, 2011 I certify that I will not receive nor provide aid to any other student for this exam. Signature: You must sign here. Otherwise you will receive a 1-point penalty.
ECE 264 Exam 2 6:30-7:30PM, March 9, 2011 I certify that I will not receive nor provide aid to any other student for this exam. Signature: You must sign here. Otherwise you will receive a 1-point penalty.
CPSC 341 OS & Networks. Threads. Dr. Yingwu Zhu
 CPSC 341 OS & Networks Threads Dr. Yingwu Zhu Processes Recall that a process includes many things An address space (defining all the code and data pages) OS resources (e.g., open files) and accounting
CPSC 341 OS & Networks Threads Dr. Yingwu Zhu Processes Recall that a process includes many things An address space (defining all the code and data pages) OS resources (e.g., open files) and accounting
AMCAT Automata Coding Sample Questions And Answers
 1) Find the syntax error in the below code without modifying the logic. #include int main() float x = 1.1; switch (x) case 1: printf( Choice is 1 ); default: printf( Invalid choice ); return
1) Find the syntax error in the below code without modifying the logic. #include int main() float x = 1.1; switch (x) case 1: printf( Choice is 1 ); default: printf( Invalid choice ); return
PARALUTION - a Library for Iterative Sparse Methods on CPU and GPU
 - a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
- a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
OpenACC Fundamentals. Steve Abbott November 15, 2017
 OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
CS 789 Multiprocessor Programming. Optimizing the Sequential Mandelbrot Computation.
 CS 789 Multiprocessor Programming Optimizing the Sequential Mandelbrot Computation. School of Computer Science Howard Hughes College of Engineering University of Nevada, Las Vegas (c) Matt Pedersen, 2010
CS 789 Multiprocessor Programming Optimizing the Sequential Mandelbrot Computation. School of Computer Science Howard Hughes College of Engineering University of Nevada, Las Vegas (c) Matt Pedersen, 2010
ECE264 Summer 2013 Exam 1, June 20, 2013
 ECE26 Summer 2013 Exam 1, June 20, 2013 In signing this statement, I hereby certify that the work on this exam is my own and that I have not copied the work of any other student while completing it. I
ECE26 Summer 2013 Exam 1, June 20, 2013 In signing this statement, I hereby certify that the work on this exam is my own and that I have not copied the work of any other student while completing it. I
CUDA Programming. Aiichiro Nakano
 CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
Advanced OpenMP Features
 Christian Terboven, Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group {terboven,schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Vectorization 2 Vectorization SIMD =
Christian Terboven, Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group {terboven,schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Vectorization 2 Vectorization SIMD =
DS Assignment I. 1. Set a pointer by name first and last to point to the first element and last element of the list respectively.
 DS Assignment I 1 Suppose an integer array by name list is declared of size N (ex: #define N 10 int list[n]; ) Write C statements to achieve the following: 1 Set a pointer by name first and last to point
DS Assignment I 1 Suppose an integer array by name list is declared of size N (ex: #define N 10 int list[n]; ) Write C statements to achieve the following: 1 Set a pointer by name first and last to point
CS/CoE 1541 Final exam (Fall 2017). This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4
. This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4") CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
OpenMP examples. Sergeev Efim. Singularis Lab, Ltd. Senior software engineer
 OpenMP examples Sergeev Efim Senior software engineer Singularis Lab, Ltd. OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism.
OpenMP examples Sergeev Efim Senior software engineer Singularis Lab, Ltd. OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism.
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Fluidic Kernels: Cooperative Execution of OpenCL Programs on Multiple Heterogeneous Devices
 Fluidic Kernels: Cooperative Execution of OpenCL Programs on Multiple Heterogeneous Devices Prasanna Pandit Supercomputer Education and Research Centre, Indian Institute of Science, Bangalore, India prasanna@hpc.serc.iisc.ernet.in
Fluidic Kernels: Cooperative Execution of OpenCL Programs on Multiple Heterogeneous Devices Prasanna Pandit Supercomputer Education and Research Centre, Indian Institute of Science, Bangalore, India prasanna@hpc.serc.iisc.ernet.in
CS 2301 Exam 3 B-Term 2011
 NAME: CS 2301 Exam 3 B-Term 2011 Questions 1-3: (15) Question 4: (15) Question 5: (20) Question 6: (10) Question 7: (15) Question 8: (15) Question 9: (10) TOTAL: (100) You may refer to one sheet of notes
NAME: CS 2301 Exam 3 B-Term 2011 Questions 1-3: (15) Question 4: (15) Question 5: (20) Question 6: (10) Question 7: (15) Question 8: (15) Question 9: (10) TOTAL: (100) You may refer to one sheet of notes
GPU Linear algebra extensions for GNU/Octave
 Journal of Physics: Conference Series GPU Linear algebra extensions for GNU/Octave To cite this article: L B Bosi et al 2012 J. Phys.: Conf. Ser. 368 012062 View the article online for updates and enhancements.
Journal of Physics: Conference Series GPU Linear algebra extensions for GNU/Octave To cite this article: L B Bosi et al 2012 J. Phys.: Conf. Ser. 368 012062 View the article online for updates and enhancements.
Strings. Compare these program fragments:
 Objects 1 What are objects? 2 C doesn't properly support object oriented programming But it is reasonable to use the word object to mean a structure or array, accessed using a pointer This represents another
Objects 1 What are objects? 2 C doesn't properly support object oriented programming But it is reasonable to use the word object to mean a structure or array, accessed using a pointer This represents another
INTRODUCTION TO OPENCL TM A Beginner s Tutorial. Udeepta Bordoloi AMD
 INTRODUCTION TO OPENCL TM A Beginner s Tutorial Udeepta Bordoloi AMD IT S A HETEROGENEOUS WORLD Heterogeneous computing The new normal CPU Many CPU s 2, 4, 8, Very many GPU processing elements 100 s Different
INTRODUCTION TO OPENCL TM A Beginner s Tutorial Udeepta Bordoloi AMD IT S A HETEROGENEOUS WORLD Heterogeneous computing The new normal CPU Many CPU s 2, 4, 8, Very many GPU processing elements 100 s Different
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
BIL 104E Introduction to Scientific and Engineering Computing. Lecture 14
 BIL 104E Introduction to Scientific and Engineering Computing Lecture 14 Because each C program starts at its main() function, information is usually passed to the main() function via command-line arguments.
BIL 104E Introduction to Scientific and Engineering Computing Lecture 14 Because each C program starts at its main() function, information is usually passed to the main() function via command-line arguments.
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise. June 2011
 MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
518 Lecture Notes Week 3
 518 Lecture Notes Week 3 (Sept. 15, 2014) 1/8 518 Lecture Notes Week 3 1 Topics Process management Process creation with fork() Overlaying an existing process with exec Notes on Lab 3 2 Process management
518 Lecture Notes Week 3 (Sept. 15, 2014) 1/8 518 Lecture Notes Week 3 1 Topics Process management Process creation with fork() Overlaying an existing process with exec Notes on Lab 3 2 Process management
Introduction to OpenACC. 16 May 2013
 Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
CAPS Technology. ProHMPT, 2009 March12 th
 CAPS Technology ProHMPT, 2009 March12 th Overview of the Talk 1. HMPP in a nutshell Directives for Hardware Accelerators (HWA) 2. HMPP Code Generation Capabilities Efficient code generation for CUDA 3.
CAPS Technology ProHMPT, 2009 March12 th Overview of the Talk 1. HMPP in a nutshell Directives for Hardware Accelerators (HWA) 2. HMPP Code Generation Capabilities Efficient code generation for CUDA 3.
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
CS16 Midterm Exam 2 E02, 10W, Phill Conrad, UC Santa Barbara Tuesday, 03/02/2010
 CS16 Midterm Exam 2 E02, 10W, Phill Conrad, UC Santa Barbara Tuesday, 03/02/2010 Name: Umail Address: @ umail.ucsb.edu Circle Lab section: 3PM 4PM 5PM Link to Printer Friendly PDF Version Please write
CS16 Midterm Exam 2 E02, 10W, Phill Conrad, UC Santa Barbara Tuesday, 03/02/2010 Name: Umail Address: @ umail.ucsb.edu Circle Lab section: 3PM 4PM 5PM Link to Printer Friendly PDF Version Please write
Threads. What is a thread? Motivation. Single and Multithreaded Processes. Benefits
 CS307 What is a thread? Threads A thread is a basic unit of CPU utilization contains a thread ID, a program counter, a register set, and a stack shares with other threads belonging to the same process
CS307 What is a thread? Threads A thread is a basic unit of CPU utilization contains a thread ID, a program counter, a register set, and a stack shares with other threads belonging to the same process
Ruud van der Pas. Senior Principal So2ware Engineer SPARC Microelectronics. Santa Clara, CA, USA
 Senior Principal So2ware Engineer SPARC Microelectronics Santa Clara, CA, USA SC 13 Talk at OpenMP Booth Wednesday, November 20, 2013 1 What Was Missing? 2 Before OpenMP 3.0 n Constructs worked well for
Senior Principal So2ware Engineer SPARC Microelectronics Santa Clara, CA, USA SC 13 Talk at OpenMP Booth Wednesday, November 20, 2013 1 What Was Missing? 2 Before OpenMP 3.0 n Constructs worked well for
Lecture Topic: An Overview of OpenCL on Xeon Phi
 C-DAC Four Days Technology Workshop ON Hybrid Computing Coprocessors/Accelerators Power-Aware Computing Performance of Applications Kernels hypack-2013 (Mode-4 : GPUs) Lecture Topic: on Xeon Phi Venue
C-DAC Four Days Technology Workshop ON Hybrid Computing Coprocessors/Accelerators Power-Aware Computing Performance of Applications Kernels hypack-2013 (Mode-4 : GPUs) Lecture Topic: on Xeon Phi Venue
The following program computes a Calculus value, the "trapezoidal approximation of
 Multicore machines and shared memory Multicore CPUs have more than one core processor that can execute instructions at the same time. The cores share main memory. In the next few activities, we will learn
Multicore machines and shared memory Multicore CPUs have more than one core processor that can execute instructions at the same time. The cores share main memory. In the next few activities, we will learn
TR On Using Multiple CPU Threads to Manage Multiple GPUs under CUDA
 TR-2008-04 On Using Multiple CPU Threads to Manage Multiple GPUs under CUDA Hammad Mazhar Simulation Based Engineering Lab University of Wisconsin Madison August 1, 2008 Abstract Presented here is a short
TR-2008-04 On Using Multiple CPU Threads to Manage Multiple GPUs under CUDA Hammad Mazhar Simulation Based Engineering Lab University of Wisconsin Madison August 1, 2008 Abstract Presented here is a short
Applying OpenCL. IWOCL, May Andrew Richards
 Applying OpenCL IWOCL, May 2017 Andrew Richards The next generation of software will not be built on CPUs 2 On a 100 millimetre-squared chip, Google needs something like 50 teraflops of performance - Daniel
Applying OpenCL IWOCL, May 2017 Andrew Richards The next generation of software will not be built on CPUs 2 On a 100 millimetre-squared chip, Google needs something like 50 teraflops of performance - Daniel
An introduction to Halide. Jonathan Ragan-Kelley (Stanford) Andrew Adams (Google) Dillon Sharlet (Google)
 Andrew Adams (Google) Dillon Sharlet (Google)") An introduction to Halide Jonathan Ragan-Kelley (Stanford) Andrew Adams (Google) Dillon Sharlet (Google) Today s agenda Now: the big ideas in Halide Later: writing & optimizing real code Hello world (brightness)
An introduction to Halide Jonathan Ragan-Kelley (Stanford) Andrew Adams (Google) Dillon Sharlet (Google) Today s agenda Now: the big ideas in Halide Later: writing & optimizing real code Hello world (brightness)
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
CA341 - Comparative Programming Languages
 CA341 - Comparative Programming Languages David Sinclair Dynamic Data Structures Generally we do not know how much data a program will have to process. There are 2 ways to handle this: Create a fixed data
CA341 - Comparative Programming Languages David Sinclair Dynamic Data Structures Generally we do not know how much data a program will have to process. There are 2 ways to handle this: Create a fixed data
Chapter 6: CPU Scheduling
 Chapter 6: CPU Scheduling Silberschatz, Galvin and Gagne Histogram of CPU-burst Times 6.2 Silberschatz, Galvin and Gagne Alternating Sequence of CPU And I/O Bursts 6.3 Silberschatz, Galvin and Gagne CPU
Chapter 6: CPU Scheduling Silberschatz, Galvin and Gagne Histogram of CPU-burst Times 6.2 Silberschatz, Galvin and Gagne Alternating Sequence of CPU And I/O Bursts 6.3 Silberschatz, Galvin and Gagne CPU
Heterogeneous Computing and OpenCL
 Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
Heterogeneous Computing and OpenCL Hongsuk Yi (hsyi@kisti.re.kr) (Korea Institute of Science and Technology Information) Contents Overview of the Heterogeneous Computing Introduction to Intel Xeon Phi
OpenCL implementation of PSO: a comparison between multi-core CPU and GPU performances
 OpenCL implementation of PSO: a comparison between multi-core CPU and GPU performances Stefano Cagnoni 1, Alessandro Bacchini 1,2, Luca Mussi 1 1 Dept. of Information Engineering, University of Parma,
OpenCL implementation of PSO: a comparison between multi-core CPU and GPU performances Stefano Cagnoni 1, Alessandro Bacchini 1,2, Luca Mussi 1 1 Dept. of Information Engineering, University of Parma,
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC
 INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
Brushing the Locks out of the Fur: A Lock-Free Work Stealing Library Based on Wool
 Brushing the Locks out of the Fur: A Lock-Free Work Stealing Library Based on Wool Håkan Sundell School of Business and Informatics University of Borås, 50 90 Borås E-mail: Hakan.Sundell@hb.se Philippas
Brushing the Locks out of the Fur: A Lock-Free Work Stealing Library Based on Wool Håkan Sundell School of Business and Informatics University of Borås, 50 90 Borås E-mail: Hakan.Sundell@hb.se Philippas
CS 33. Architecture and the OS. CS33 Intro to Computer Systems XIX 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 33 Architecture and the OS CS33 Intro to Computer Systems XIX 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. The Operating System My Program Mary s Program Bob s Program OS CS33 Intro to
CS 33 Architecture and the OS CS33 Intro to Computer Systems XIX 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. The Operating System My Program Mary s Program Bob s Program OS CS33 Intro to
A506 / C201 Computer Programming II Placement Exam Sample Questions. For each of the following, choose the most appropriate answer (2pts each).
.") A506 / C201 Computer Programming II Placement Exam Sample Questions For each of the following, choose the most appropriate answer (2pts each). 1. Which of the following functions is causing a temporary
A506 / C201 Computer Programming II Placement Exam Sample Questions For each of the following, choose the most appropriate answer (2pts each). 1. Which of the following functions is causing a temporary
Supporting Class / C++ Lecture Notes
 Goal Supporting Class / C++ Lecture Notes You started with an understanding of how to write Java programs. This course is about explaining the path from Java to executing programs. We proceeded in a mostly
Goal Supporting Class / C++ Lecture Notes You started with an understanding of how to write Java programs. This course is about explaining the path from Java to executing programs. We proceeded in a mostly
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Threaded Programming. Lecture 9: Alternatives to OpenMP
 Threaded Programming Lecture 9: Alternatives to OpenMP What s wrong with OpenMP? OpenMP is designed for programs where you want a fixed number of threads, and you always want the threads to be consuming
Threaded Programming Lecture 9: Alternatives to OpenMP What s wrong with OpenMP? OpenMP is designed for programs where you want a fixed number of threads, and you always want the threads to be consuming
Online Judge and C. Roy Chan. January 12, Outline Information Online Judge Introduction to C. CSC2100B Data Structures Tutorial 1
 Roy Chan CSC2100B Data Structures Tutorial 1 January 12, 2009 1 / 38 1 Information Your TA team Course Information Assignment 2 Online Judge Writing Your Assignment Program Submitting Your Program Online
Roy Chan CSC2100B Data Structures Tutorial 1 January 12, 2009 1 / 38 1 Information Your TA team Course Information Assignment 2 Online Judge Writing Your Assignment Program Submitting Your Program Online
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
ARCHER Champions 2 workshop
 ARCHER Champions 2 workshop Mike Giles Mathematical Institute & OeRC, University of Oxford Sept 5th, 2016 Mike Giles (Oxford) ARCHER Champions 2 Sept 5th, 2016 1 / 14 Tier 2 bids Out of the 8 bids, I know
ARCHER Champions 2 workshop Mike Giles Mathematical Institute & OeRC, University of Oxford Sept 5th, 2016 Mike Giles (Oxford) ARCHER Champions 2 Sept 5th, 2016 1 / 14 Tier 2 bids Out of the 8 bids, I know
New features in AddressSanitizer. LLVM developer meeting Nov 7, 2013 Alexey Samsonov, Kostya Serebryany
 New features in AddressSanitizer LLVM developer meeting Nov 7, 2013 Alexey Samsonov, Kostya Serebryany Agenda AddressSanitizer (ASan): a quick reminder New features: Initialization-order-fiasco Stack-use-after-scope
New features in AddressSanitizer LLVM developer meeting Nov 7, 2013 Alexey Samsonov, Kostya Serebryany Agenda AddressSanitizer (ASan): a quick reminder New features: Initialization-order-fiasco Stack-use-after-scope
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
Programs. Function main. C Refresher. CSCI 4061 Introduction to Operating Systems
 Programs CSCI 4061 Introduction to Operating Systems C Program Structure Libraries and header files Compiling and building programs Executing and debugging Instructor: Abhishek Chandra Assume familiarity
Programs CSCI 4061 Introduction to Operating Systems C Program Structure Libraries and header files Compiling and building programs Executing and debugging Instructor: Abhishek Chandra Assume familiarity
unsigned char memory[] STACK ¼ 0x xC of address space globals function KERNEL code local variables
![unsigned char memory[] STACK ¼ 0x xC of address space globals function KERNEL code local variables](/thumbs/92/109489696.jpg "unsigned char memory[] STACK ¼ 0x xC of address space globals function KERNEL code local variables") Graded assignment 0 will be handed out in section Assignment 1 Not that bad Check your work (run it through the compiler) Factorial Program Prints out ENTERING, LEAVING, and other pointers unsigned char
Graded assignment 0 will be handed out in section Assignment 1 Not that bad Check your work (run it through the compiler) Factorial Program Prints out ENTERING, LEAVING, and other pointers unsigned char
Predictive Runtime Code Scheduling for Heterogeneous Architectures
 Predictive Runtime Code Scheduling for Heterogeneous Architectures Víctor Jiménez, Lluís Vilanova, Isaac Gelado Marisa Gil, Grigori Fursin, Nacho Navarro HiPEAC 2009 January, 26th, 2009 1 Outline Motivation
Predictive Runtime Code Scheduling for Heterogeneous Architectures Víctor Jiménez, Lluís Vilanova, Isaac Gelado Marisa Gil, Grigori Fursin, Nacho Navarro HiPEAC 2009 January, 26th, 2009 1 Outline Motivation
Case Study: Parallelizing a Recursive Problem with Intel Threading Building Blocks
 4/8/2012 2:44:00 PM Case Study: Parallelizing a Recursive Problem with Intel Threading Building Blocks Recently I have been working closely with DreamWorks Animation engineers to improve the performance
4/8/2012 2:44:00 PM Case Study: Parallelizing a Recursive Problem with Intel Threading Building Blocks Recently I have been working closely with DreamWorks Animation engineers to improve the performance
Memory Allocation in C
 Memory Allocation in C When a C program is loaded into memory, it is organized into three areas of memory, called segments: the text segment, stack segment and heap segment. The text segment (also called
Memory Allocation in C When a C program is loaded into memory, it is organized into three areas of memory, called segments: the text segment, stack segment and heap segment. The text segment (also called
CUDA Advanced Techniques 2 Mohamed Zahran (aka Z)
") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
CS 223: Data Structures and Programming Techniques. Exam 2
 CS 223: Data Structures and Programming Techniques. Exam 2 Instructor: Jim Aspnes Work alone. Do not use any notes or books. You have approximately 75 minutes to complete this exam. Please write your answers
CS 223: Data Structures and Programming Techniques. Exam 2 Instructor: Jim Aspnes Work alone. Do not use any notes or books. You have approximately 75 minutes to complete this exam. Please write your answers
The University of Nottingham
 The University of Nottingham SCHOOL OF COMPUTER SCIENCE A LEVEL 2 MODULE, AUTUMN SEMESTER 2008 2009 C/C++ for Java Programmers Time allowed TWO hours Candidates may complete the front cover of their answer
The University of Nottingham SCHOOL OF COMPUTER SCIENCE A LEVEL 2 MODULE, AUTUMN SEMESTER 2008 2009 C/C++ for Java Programmers Time allowed TWO hours Candidates may complete the front cover of their answer
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Memory Management. To do. q Basic memory management q Swapping q Kernel memory allocation q Next Time: Virtual memory
 Memory Management To do q Basic memory management q Swapping q Kernel memory allocation q Next Time: Virtual memory Memory management Ideal memory for a programmer large, fast, nonvolatile and cheap not
Memory Management To do q Basic memory management q Swapping q Kernel memory allocation q Next Time: Virtual memory Memory management Ideal memory for a programmer large, fast, nonvolatile and cheap not
OpenCL. Matt Sellitto Dana Schaa Northeastern University NUCAR
 OpenCL Matt Sellitto Dana Schaa Northeastern University NUCAR OpenCL Architecture Parallel computing for heterogenous devices CPUs, GPUs, other processors (Cell, DSPs, etc) Portable accelerated code Defined
OpenCL Matt Sellitto Dana Schaa Northeastern University NUCAR OpenCL Architecture Parallel computing for heterogenous devices CPUs, GPUs, other processors (Cell, DSPs, etc) Portable accelerated code Defined
Thread-Level Parallelism. Instructor: Adam C. Champion, Ph.D. CSE 2431: Introduction to Operating Systems Reading: Section 12.
 Thread-Level Parallelism Instructor: Adam C. Champion, Ph.D. CSE 2431: Introduction to Operating Systems Reading: Section 12.6, [CSAPP] 1 Contents Parallel Computing Hardware Multicore Multiple separate
Thread-Level Parallelism Instructor: Adam C. Champion, Ph.D. CSE 2431: Introduction to Operating Systems Reading: Section 12.6, [CSAPP] 1 Contents Parallel Computing Hardware Multicore Multiple separate