Performance Diagnosis for Hybrid CPU/GPU Environments
|
|
|
- Angelina West
- 5 years ago
- Views:
Transcription
1 Performance Diagnosis for Hybrid CPU/GPU Environments Michael M. Smith and Karen L. Karavanic Computer Science Department Portland State University
2 Performance Diagnosis for Hybrid CPU/GPU Environments Michael M. Smith and Karen L. Karavanic Computer Science Department Portland State University Work in Progress
3 Introduction Shift to GPUs: Single core processors have hit performance wall due to heat dissipation and power requirements => multicore, manycore Top500 (June 2011): 17/500 are GPU-accelerated Includes #2 (Tianhe-1a), #4 (Nebulae) and #5 (Tsubame 2.0) Hybrid GPU programming model different, and programmers need tools to provide unified view of application s performance
4 Performance Diagnosis of Hybrid Applications: Project Overview A benchmark suite for evaluating performance tools under development High level diagnostic metrics to convey most important performance trends (note: want them to work for CUDA and OpenCL) Visualizations to convey most important performance trends Funding for Curriculum Innovation in Multicore Computing New PSU Course: General Purpose GPU Computing


5 Graphic Processor Unit (GPU) Scheduling unit: warp = 32 threads Max per MP: 8 blocks, 32 warps Nvidia Cuda Programming Guide, compute/cuda/2_0/docs/nvidia_cuda_programming_guide_2.0.pdf



6 GPU Programming /03/xeon-processor.jpg images/tesla_c1060.png Compute Cap.>= 2.0: streams Compute Cap.>= 2.0: multiple kernels
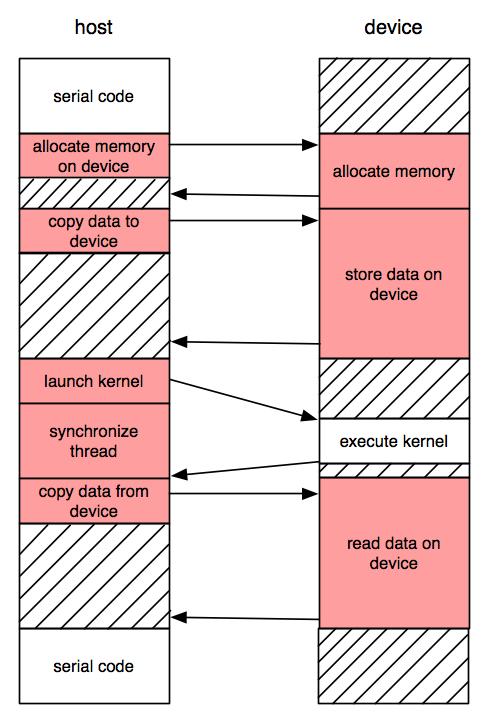
7 GPU Programming With CUDA 1 int main(int argc, char** argv) { 2 int a_host; 3 int b_host; 4 int answer; 5 6 a_host = thread_id; 7 b_host = 3; 8 9 answer = a_host + b_host; return 0; 12 } 1 global void add(int *a, int *b, int *answer_dev) { 2 *answer_dev = *a + *b; 3 } 4 5 int main(int argc, char** argv) { 6 int a_host; 7 int *a_dev; 8 int b_host; 9 int *b_dev; 10 int answer; 11 int *answer_dev; a_host = thread_id; 14 b_host = 3; cudamalloc((void **) &answer_dev, sizeof(int)); 17 cudamalloc((void **) &a_dev, sizeof(int)); 18 cudamalloc((void **) &b_dev, sizeof(int)); cudamemcpy(a_dev, &a_host, sizeof(int), cudamemcpyhosttodevice); 21 cudamemcpy(b_dev, &b_host, sizeof(int), cudamemcpyhosttodevice); dim3 dimgrid(1); 24 dim3 dimblock(1,32); 25 add<<<dimgrid, dimblock, 0>>>(a_dev, b_dev, answer_dev); cudathreadsynchronize(); cudamemcpy(&answer, answer_dev, sizeof(int), cudamemcpydevicetohost); return 0; 32 } define kernel serial code allocate memory move data launch kernel move data serial code
8 A Simple Performance Tool Benchmark Suite Inspired by APART Test Suite Goals: Easily understandable behavior Used to check correctness of diagnosis Started with an existing single device implementation of matrix multiplication and extended it to support: Multiple GPU devices Overlap CPU and GPU computation Use pinned memory Use asynchronous memory transfers Based on Programming Massively Parallel Processors: A Hands-on Approach by Kirk and Hwu
9 Naive Kernel P = M x N [4x4] d: data in global memory ds: data in shared memory Matrix multiplication performed by calculating dot product of rows in M and columns in N Kernel configured to use one block of threads, so size of matrices limited by the maximum number of threads in a block In our case this was 16x16 Maximum number of threads in a block is x16 is largest size that is a power of two

10 Tiled Kernel Breaks the P d matrix up into tiles Tiles the same size as a block P = M x N [4x4] d: data in global memory ds: data in shared memory
11 Tiled Kernel P = M x N [4x4] d: data in global memory ds: data in shared memory
12 Tiled Plus Shared Memory Kernel Tiled kernel accesses data in global memory multiple times Tiled plus shared memory kernel uses shared memory to reduce global memory traffic Breaks computation up into phases Threads cooperatively load elements into shared memory P = M x N [4x4] d: data in global memory ds: data in shared memory
13 Phase One Global Memory: 4GB Shared Memory per Block: 16KB P = M x N [4x4] d: data in global memory ds: data in shared memory
14 Phase Two Global Memory: 4GB Shared Memory per Block: 16KB P = M x N [4x4] d: data in global memory ds: data in shared memory
15 CUDA programming model requires at least one host thread per device We divide the work among multiple host threads. Multiple Device Support P = M x N [4x4] d: data in global memory ds: data in shared memory
16 Multiple Device Support P = M x N [4x4] d: data in global memory ds: data in shared memory
17 Pinned Memory Optimizations Asynchronous memory transfers Requires pinned memory Non-blocking memory transfers for host

18 Hybrid Matrix Multiplication Overlaps CPU and GPU computation Divides work same as multiple device version One thread performs computation on device Other thread performs computation on host
19 Device Efficiency Metric Goal - indicate if the overhead of moving data to the device was justified Theoretical definition: kernel compute time / kernel wall clock Kernel device time: amount of time kernel executes on device Device time: amount of time kernel and data movement functions execute on the device Minimum value: 0 Maximum value: 1 DE = kernel device time device time
20 Device Utilization Goal - show how much of device s available computation is used Device time: amount of time kernel and data movement functions execute on the device Wall clock time: amount of time the application ran Minimum value: 0 Maximum value: 1 DU = device time wall clock time
21 Experiments Goals: Use matrix multiplication benchmark suite to study the behavior of the derived metrics What do the derived metrics tell us about a real scientific application?
22 Experimental Design - Instrumentation CudaProf configured to gather: kernel device time: gputime for kernel functions device time: gputime for kernel and data movement functions wall clock time: external time utility Tesla C1060 (1 GPU), S1070 (4 GPUs): compute capability 1.3 DE = kernel device time device time DU = device time wall clock time
23 Experimental Design - Matrix Multiplication Kernels: Naive Tiled Tiled plus shared memory Memory optimizations: Paged memory Pinned memory Pinned memory with asynchronous memory transfers Multiple devices Overlapped CPU and GPU computation Matrix sizes: from 16x16 to 16,384x16,384
24 Matrix Multiplication Case Study Device Efficiency DE = kernel device time device time x16 512x x x x x x16384 Matrix multiplication configured with: tiled+shared memory kernel, pinned memory, asynchronous memory transfers, single device
25 Matrix Multiplication Case Study Device Efficiency DE = kernel device time device time dev0 dev1 dev0 dev1 dev0 dev1 dev0 dev1 dev0 dev1 dev0 dev1 dev0 dev1 32x32 512x x x x x x16384 Matrix multiplication configured with: tiled+shared memory kernel, pinned memory, asynchronous memory transfers, two devices
26 Matrix Multiplication Case Study Device Efficiency DE = kernel device time device time x32 512x x x x4096 Matrix multiplication configured with: tiled+shared memory kernel, pinned memory, asynchronous memory transfers, overlapping CPU and GPU computation
27 Matrix Multiplication Case Study DE DU 0.50 DE DU x x x x x x x x x x x x16384 Matrix multiplication using tiled kernel, paged memory, single device. Matrix multiplication using tiled plus shared memory kernel, paged memory, single device.
28 Matrix Multiplication Case Study Matrix Size Device Utilization 1 device 2 devices dev0 dev0 dev1 16x DU = device time wall clock time 512x x x x x x Matrix multiplication configured with: tiled+shared memory kernel, pinned memory, asynchronous memory transfers
29 Experimental Design - NAMD Are these metrics useful for full-scale application? Molecular dynamics simulator Extended by Phillips et al. to support GPUs Configured to simulate the Satellite Tobacco Mosaic Virus (STMV) Modified an existing simulation configuration
30 NAMD Case Study Device Efficiency single device two devices DE = kernel device time device time dev0 dev1
31 NAMD Case Study Device Utilization single device two devices DU = device time wall clock time dev0 dev1
32 Observations & Questions Device efficiency can be used to indicate performance in a hybrid environment, but doesn t reflect optimizations between kernels Device utilization can be used to indicate performance in a hybrid environment, but doesn t show how much an application can be accelerated Does device utilization matter? What about CPU utilization? Is CPU wait time free? FLOPs/watt? How can we visualize the asynchronous transfers and streams? Most common student questions: How can I tell what the GPU is doing?? (perf.,scheduling) How should I break down the problem? (blocks, streams)
33 Acknowledgments and contact info This work funded in part by National Science Foundation Award # Thanks to all students in Performance Analysis of Heterogeneous Multicore Systems. Benchmark suite completed for CUDA and OpenCL.
Performance Analysis of Hybrid CPU/GPU Environments
 Portland State University PDXScholar Dissertations and Theses Dissertations and Theses 1-1-2010 Performance Analysis of Hybrid CPU/GPU Environments Michael Shawn Smith Portland State University Let us
Portland State University PDXScholar Dissertations and Theses Dissertations and Theses 1-1-2010 Performance Analysis of Hybrid CPU/GPU Environments Michael Shawn Smith Portland State University Let us
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
GPU Programming with CUDA. Pedro Velho
 GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
GPU Computing: A Quick Start
 GPU Computing: A Quick Start Orest Shardt Department of Chemical and Materials Engineering University of Alberta August 25, 2011 Session Goals Get you started with highly parallel LBM Take a practical
GPU Computing: A Quick Start Orest Shardt Department of Chemical and Materials Engineering University of Alberta August 25, 2011 Session Goals Get you started with highly parallel LBM Take a practical
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Introduction to CUDA CIRC Summer School 2014
 Introduction to CUDA CIRC Summer School 2014 Baowei Liu Center of Integrated Research Computing University of Rochester October 20, 2014 Introduction Overview What will you learn on this class? Start from
Introduction to CUDA CIRC Summer School 2014 Baowei Liu Center of Integrated Research Computing University of Rochester October 20, 2014 Introduction Overview What will you learn on this class? Start from
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Parallel Hybrid Computing F. Bodin, CAPS Entreprise
 Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
Accelerated Test Execution Using GPUs
 Accelerated Test Execution Using GPUs Vanya Yaneva Supervisors: Ajitha Rajan, Christophe Dubach Mathworks May 27, 2016 The Problem Software testing is time consuming Functional testing The Problem Software
Accelerated Test Execution Using GPUs Vanya Yaneva Supervisors: Ajitha Rajan, Christophe Dubach Mathworks May 27, 2016 The Problem Software testing is time consuming Functional testing The Problem Software
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Using a GPU in InSAR processing to improve performance
 Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Accelerating Molecular Modeling Applications with Graphics Processors
 Accelerating Molecular Modeling Applications with Graphics Processors John Stone Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign Research/gpu/ SIAM Conference
Accelerating Molecular Modeling Applications with Graphics Processors John Stone Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign Research/gpu/ SIAM Conference
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Kepler Overview Mark Ebersole
 Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Lessons learned from a simple application
 Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
Computation to Core Mapping Lessons learned from a simple application
 Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
ARCHER Champions 2 workshop
 ARCHER Champions 2 workshop Mike Giles Mathematical Institute & OeRC, University of Oxford Sept 5th, 2016 Mike Giles (Oxford) ARCHER Champions 2 Sept 5th, 2016 1 / 14 Tier 2 bids Out of the 8 bids, I know
ARCHER Champions 2 workshop Mike Giles Mathematical Institute & OeRC, University of Oxford Sept 5th, 2016 Mike Giles (Oxford) ARCHER Champions 2 Sept 5th, 2016 1 / 14 Tier 2 bids Out of the 8 bids, I know
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
CUDA Programming. Aiichiro Nakano
 CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Performance Considerations and GMAC
 Performance Considerations and GMAC 1 Warps and Thread Execution Theoretically all threads in a block can execute concurrently Hardware cost forces compromise Bundle threads with a single control unit
Performance Considerations and GMAC 1 Warps and Thread Execution Theoretically all threads in a block can execute concurrently Hardware cost forces compromise Bundle threads with a single control unit
Dynamic Task Parallelism with a GPU Work-Stealing Runtime System
 Dynamic Task Parallelism with a GPU Work-Stealing Runtime System Sanjay Chatterjee, Max Grossman, Alina Sbîrlea, and Vivek Sarkar Department of Computer Science Rice University Background As parallel programming
Dynamic Task Parallelism with a GPU Work-Stealing Runtime System Sanjay Chatterjee, Max Grossman, Alina Sbîrlea, and Vivek Sarkar Department of Computer Science Rice University Background As parallel programming
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CUDA by Example. The University of Mississippi Computer Science Seminar Series. April 28, 2010
 CUDA by Example The University of Mississippi Computer Science Seminar Series Martin.Lilleeng.Satra@sintef.no SINTEF ICT Department of Applied Mathematics April 28, 2010 Outline 1 The GPU 2 cudapi 3 CUDA
CUDA by Example The University of Mississippi Computer Science Seminar Series Martin.Lilleeng.Satra@sintef.no SINTEF ICT Department of Applied Mathematics April 28, 2010 Outline 1 The GPU 2 cudapi 3 CUDA
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Pragma-based GPU Programming and HMPP Workbench. Scott Grauer-Gray
 Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
An Introduction to OpenAcc
 An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
GPGPU. Alan Gray/James Perry EPCC The University of Edinburgh.
 GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
GPGPU Alan Gray/James Perry EPCC The University of Edinburgh a.gray@ed.ac.uk Contents Introduction GPU Technology Programming GPUs GPU Performance Optimisation 2 Introduction 3 Introduction Central Processing
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Unified Memory. Notes on GPU Data Transfers. Andreas Herten, Forschungszentrum Jülich, 24 April Member of the Helmholtz Association
 Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Introduction to CUDA
 Introduction to CUDA Oliver Meister November 7 th 2012 Tutorial Parallel Programming and High Performance Computing, November 7 th 2012 1 References D. Kirk, W. Hwu: Programming Massively Parallel Processors,
Introduction to CUDA Oliver Meister November 7 th 2012 Tutorial Parallel Programming and High Performance Computing, November 7 th 2012 1 References D. Kirk, W. Hwu: Programming Massively Parallel Processors,
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Overview: Graphics Processing Units
 advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
GPU Programming for Mathematical and Scientific Computing
 GPU Programming for Mathematical and Scientific Computing Ethan Kerzner and Timothy Urness Department of Mathematics and Computer Science Drake University Des Moines, IA 50311 ethan.kerzner@gmail.com timothy.urness@drake.edu
GPU Programming for Mathematical and Scientific Computing Ethan Kerzner and Timothy Urness Department of Mathematics and Computer Science Drake University Des Moines, IA 50311 ethan.kerzner@gmail.com timothy.urness@drake.edu
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Empirical Modeling: an Auto-tuning Method for Linear Algebra Routines on CPU plus Multi-GPU Platforms
 Empirical Modeling: an Auto-tuning Method for Linear Algebra Routines on CPU plus Multi-GPU Platforms Javier Cuenca Luis-Pedro García Domingo Giménez Francisco J. Herrera Scientific Computing and Parallel
Empirical Modeling: an Auto-tuning Method for Linear Algebra Routines on CPU plus Multi-GPU Platforms Javier Cuenca Luis-Pedro García Domingo Giménez Francisco J. Herrera Scientific Computing and Parallel
Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory
 Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
Institute of Computational Science Efficient CPU GPU data transfers CUDA 6.0 Unified Virtual Memory Juraj Kardoš (University of Lugano) July 9, 2014 Juraj Kardoš Efficient GPU data transfers July 9, 2014
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
Module 3: CUDA Execution Model -I. Objective
 ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis
 GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
About 30 student clubs/associations 1500 students 5 years program
 CUDA & OpenCV ESIEE Engineering school 2 places Noisy-le-grand (East of Paris) Amiens (North of France) About 30 student clubs/associations 1500 students 5 years program 3 years of common courses (maths,
CUDA & OpenCV ESIEE Engineering school 2 places Noisy-le-grand (East of Paris) Amiens (North of France) About 30 student clubs/associations 1500 students 5 years program 3 years of common courses (maths,
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
Performance-Portable Many Core Plasma Simulations: Porting PIConGPU to OpenPower and Beyond
 Performance-Portable Many Core Plasma Simulations: Porting PIConGPU to OpenPower and Beyond Erik Zenker1,2, René Widera1, Axel Huebl1,2, Guido Juckeland1, Andreas Knüpfer2, Wolfgang E. Nagel2, Michael
Performance-Portable Many Core Plasma Simulations: Porting PIConGPU to OpenPower and Beyond Erik Zenker1,2, René Widera1, Axel Huebl1,2, Guido Juckeland1, Andreas Knüpfer2, Wolfgang E. Nagel2, Michael
GPU COMPUTING. Ana Lucia Varbanescu (UvA)
") GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
CUDA Advanced Techniques 2 Mohamed Zahran (aka Z)
") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux