Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators
|
|
|
- Gabriel Dorsey
- 5 years ago
- Views:
Transcription




1 Remote CUDA (rcuda)
2 Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators Better performance-watt, performance-cost ratios for certain applications
3 Why? One Hw. accelerator per node? Acquisition costs Power consumption ( 20 30%), including cooling Maintenance Space Not all applications can be accelerated In general, waste of resources!
4 rcuda
5 Contents Motivation Virtualization and CUDA rcuda Architecture Example Performance and power Status and usability Future work
6 Virtualization taxonomy Back-end (hardware facing) virtualization Impossible: clients without direct access to HW Front-end (application facing) virtualization Device emulation: API remoting: Sw. replication of the entire Hw. accelerator Performance is not the target Not appropriate for HPC emulation overhead Time-sharing real device Client-server architecture
7 CUDA Facilitates general-purpose computing on latest NVIDIA GPUs C + extensions: closer to non-gpu programmers than OpenGL, Cg,... GPU architecture viewed as a set of SIMD multiprocessors 2 APIs: Runtime (high-level) & driver (low-level)
8 CUDA Device code has to be written as a kernel Kernels: are sent and executed on the GPU at runtime Data used by kernels has to be sent, too Managed by the driver Explicitly addressed by the programmer
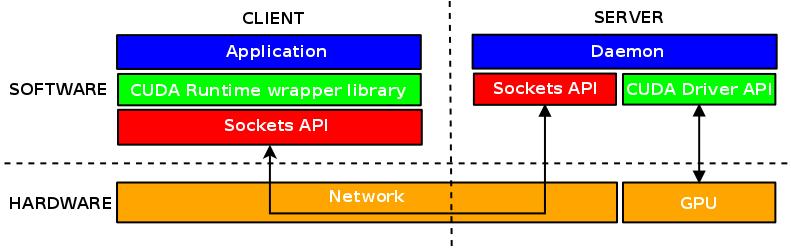
9 rcuda: Architecture
10 rcuda: Architecture Client-server Client: Emulates local GPUs Handles communication with the server Server: Waits for requests Executes GPU code (kernel) Reports status
11 rcuda: Example Matrix product (I): 1. Socket opening + module sending 2. Memory allocation 3. Data transfer
12 rcuda: Example Matrix product (II): Kernel execution 5. Results reception 6. Memory release 7. Socket closing
13 rcuda: Performance and power Execution time (virtualized GPU vs. local CPU):

14 rcuda: Performance and power Overhead mostly caused by the network Matrix product
15 rcuda: Performance and power HPC interconnects:
16 rcuda: Performance and power HPC interconnects: Remote GPU faster than local CPU
17 rcuda: Performance and power HPC interconnects:
18 rcuda: Performance and power HPC interconnects:
19 rcuda: Performance and power 100 node cluster (600 W/node) NVIDIA Tesla C1060 ( W/GPU) 4 InfiniBand Mellanox MTS3600 switches in tree topology (316 W/switch) GPUs Consumption Savings Ratio KW 0.0 W 0.0% KW 9.6 KW 12.0% KW 14.5 KW 18.0% KW 17.4 KW 21.6%
20 rcuda: Status and usability rcuda R.C. 1.0 ready! Support for Linux OS (32 & 64 bits) on clients and servers CUDA Runtime API 2.3 Except OpenGL and Direct3D interoperability
21 rcuda: Status and usability Limitations: Virtualized devices do not offer zero copy Lack of support for CUDA C extensions Why? hidden and undocumented functions Device and host codes compiled separately Forces to use the plain C API Unable to locate embedded code: No support for precompiled libraries (CUFFT, CUBLAS, etc.)
22 rcuda: Status and usability Limitations (II): Kernel call using CUDA C extensions: kernel<<<blocks, threads>>>(a, b, c) Same call using plain C API: #define ALIGN_UP(offset, align) (offset) = \ ((offset) + (align) 1) & ~((align) - 1) template<class T> inline void setuparg(t arg, int *offst) { ALIGN_UP(*offst, alignof(arg)); cudasetupargument(&arg, sizeof(arg), *offst); *offst += sizeof(arg); } cudaconfigurecall(blocks, threads); int offset = 0; setupargument(&a); setupargument(&b); setupargument(&c); cudalaunch( kernel ); Aux. code
23 rcuda: Status and usability Lines of code modified (or added) to avoid using CUDA C extensions in SDK examples: Example* Original Modified Rate bandwidthtest % binomialoptions % dct8x % simplepitchlineartexture % simplestreams % simpletexture % Average %
24 rcuda: Status and usability CUDA 2.3 SDK: 67 examples in total 51 ported to plain C API & successfully run w/ rcuda 16 not feasible: 10 modified to avoid using OpenGL interoperability 11 use precompiled CUDA libraries 5 directly use the Driver API
25 rcuda: Status and usability Current possibilities: HPC clusters: reduced number of GPUs Energy & resource savings Educational: remote GPU servers Virtual Machines: accessing CUDA facilities on the physical machine
26 Future Work Multi-server functionalities: Automatic discovery Load balancing Integrate with 3D remoting acceleration works to enable OpenGL and Direct3D interoperability Optimized version for VMs (shared memory) Windows OS Full open API: OpenCL
27 rcuda and Bull? Customized cluster: optimal configuration for particular needs (client) How many GPUs Distribution of GPUs Network type Which computations in remote GPU vs local CPU
28 rcuda and Bull? Customized cluster: Given a fixed budget... Present a more competitive offer in terms of energy consumption and performance
29 References J. Duato, F. D. Igual, R. Mayo, A. J. Peña, E. S. Quintana-Ortí, and F. Silla, An efficient implementation of GPU virtualization in high performance clusters, in 4 th Workshop on Virtualization in High Performance Cloud Computing, 2009 J. Duato, A. J. Peña, F. Silla, R. Mayo, and E. S. Quintana-Ortí. Modeling the CUDA remoting virtualization behaviour in high performance networks, in First Workshop on Language, Compiler, and Architecture Support for GPGPU, 2010
rcuda: an approach to provide remote access to GPU computational power
 rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop Outline computing Cost of a node rcuda goals rcuda
rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop Outline computing Cost of a node rcuda goals rcuda
computational power computational
 rcuda: rcuda: an an approach approach to to provide provide remote remote access access to to computational computational power power Rafael Mayo Gual Universitat Jaume I Spain (1 of 59) HPC Advisory Council
rcuda: rcuda: an an approach approach to to provide provide remote remote access access to to computational computational power power Rafael Mayo Gual Universitat Jaume I Spain (1 of 59) HPC Advisory Council
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Carlos Reaño Universitat Politècnica de València (Spain) HPC Advisory Council Switzerland Conference April 3, Lugano (Switzerland)
 HPC Advisory Council Switzerland Conference April 3, Lugano (Switzerland)") Carlos Reaño Universitat Politècnica de València (Spain) Switzerland Conference April 3, 2014 - Lugano (Switzerland) What is rcuda? Installing and using rcuda rcuda over HPC networks InfiniBand How taking
Carlos Reaño Universitat Politècnica de València (Spain) Switzerland Conference April 3, 2014 - Lugano (Switzerland) What is rcuda? Installing and using rcuda rcuda over HPC networks InfiniBand How taking
Framework of rcuda: An Overview
 Framework of rcuda: An Overview Mohamed Hussain 1, M.B.Potdar 2, Third Viraj Choksi 3 11 Research scholar, VLSI & Embedded Systems, Gujarat Technological University, Ahmedabad, India 2 Project Director,
Framework of rcuda: An Overview Mohamed Hussain 1, M.B.Potdar 2, Third Viraj Choksi 3 11 Research scholar, VLSI & Embedded Systems, Gujarat Technological University, Ahmedabad, India 2 Project Director,
An approach to provide remote access to GPU computational power
 An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
The rcuda technology: an inexpensive way to improve the performance of GPU-based clusters Federico Silla
 The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Exploiting Task-Parallelism on GPU Clusters via OmpSs and rcuda Virtualization
 Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
GETTING STARTED WITH CUDA SDK SAMPLES
 GETTING STARTED WITH CUDA SDK SAMPLES DA-05723-001_v01 January 2012 Application Note TABLE OF CONTENTS Getting Started with CUDA SDK Samples... 1 Before You Begin... 2 Getting Started With SDK Samples...
GETTING STARTED WITH CUDA SDK SAMPLES DA-05723-001_v01 January 2012 Application Note TABLE OF CONTENTS Getting Started with CUDA SDK Samples... 1 Before You Begin... 2 Getting Started With SDK Samples...
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Speeding up the execution of numerical computations and simulations with rcuda José Duato
 Speeding up the execution of numerical computations and simulations with rcuda José Duato Universidad Politécnica de Valencia Spain Outline 1. Introduction to GPU computing 2. What is remote GPU virtualization?
Speeding up the execution of numerical computations and simulations with rcuda José Duato Universidad Politécnica de Valencia Spain Outline 1. Introduction to GPU computing 2. What is remote GPU virtualization?
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies
 Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
dopencl Evaluation of an API-Forwarding Implementation
 dopencl Evaluation of an API-Forwarding Implementation Karsten Tausche, Max Plauth and Andreas Polze Operating Systems and Middleware Group Hasso Plattner Institute for Software Systems Engineering, University
dopencl Evaluation of an API-Forwarding Implementation Karsten Tausche, Max Plauth and Andreas Polze Operating Systems and Middleware Group Hasso Plattner Institute for Software Systems Engineering, University
Document downloaded from:
 Document downloaded from: http://hdl.handle.net/10251/70225 This paper must be cited as: Reaño González, C.; Silla Jiménez, F. (2015). On the Deployment and Characterization of CUDA Teaching Laboratories.
Document downloaded from: http://hdl.handle.net/10251/70225 This paper must be cited as: Reaño González, C.; Silla Jiménez, F. (2015). On the Deployment and Characterization of CUDA Teaching Laboratories.
Opportunities of the rcuda remote GPU virtualization middleware. Federico Silla Universitat Politècnica de València Spain
 Opportunities of the rcuda remote virtualization middleware Federico Silla Universitat Politècnica de València Spain st Outline What is rcuda? HPC Advisory Council China Conference 2017 2/45 s are the
Opportunities of the rcuda remote virtualization middleware Federico Silla Universitat Politècnica de València Spain st Outline What is rcuda? HPC Advisory Council China Conference 2017 2/45 s are the
SPOC : GPGPU programming through Stream Processing with OCaml
 SPOC : GPGPU programming through Stream Processing with OCaml Mathias Bourgoin - Emmanuel Chailloux - Jean-Luc Lamotte January 23rd, 2012 GPGPU Programming Two main frameworks Cuda OpenCL Different Languages
SPOC : GPGPU programming through Stream Processing with OCaml Mathias Bourgoin - Emmanuel Chailloux - Jean-Luc Lamotte January 23rd, 2012 GPGPU Programming Two main frameworks Cuda OpenCL Different Languages
Profiling and Debugging OpenCL Applications with ARM Development Tools. October 2014
 Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
designing a GPU Computing Solution
 designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
Remote GPU virtualization: pros and cons of a recent technology. Federico Silla Technical University of Valencia Spain
 Remote virtualization: pros and cons of a recent technology Federico Silla Technical University of Valencia Spain The scope of this talk HPC Advisory Council Brazil Conference 2015 2/43 st Outline What
Remote virtualization: pros and cons of a recent technology Federico Silla Technical University of Valencia Spain The scope of this talk HPC Advisory Council Brazil Conference 2015 2/43 st Outline What
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
rcuda: towards energy-efficiency in GPU computing by leveraging low-power processors and InfiniBand interconnects
 rcuda: towards energy-efficiency in computing by leveraging low-power processors and InfiniBand interconnects Federico Silla Technical University of Valencia Spain Joint research effort Outline Current
rcuda: towards energy-efficiency in computing by leveraging low-power processors and InfiniBand interconnects Federico Silla Technical University of Valencia Spain Joint research effort Outline Current
Is remote GPU virtualization useful? Federico Silla Technical University of Valencia Spain
 Is remote virtualization useful? Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC Advisory Council Spain Conference 2015 2/57 We deal with s, obviously!
Is remote virtualization useful? Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC Advisory Council Spain Conference 2015 2/57 We deal with s, obviously!
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
CS179 GPU Programming Introduction to CUDA. Lecture originally by Luke Durant and Tamas Szalay
 Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
rcuda: desde máquinas virtuales a clústers mixtos CPU-GPU
 rcuda: desde máquinas virtuales a clústers mixtos CPU-GPU Federico Silla Universitat Politècnica de València HPC ADMINTECH 2018 rcuda: from virtual machines to hybrid CPU-GPU clusters Federico Silla Universitat
rcuda: desde máquinas virtuales a clústers mixtos CPU-GPU Federico Silla Universitat Politècnica de València HPC ADMINTECH 2018 rcuda: from virtual machines to hybrid CPU-GPU clusters Federico Silla Universitat
Improving overall performance and energy consumption of your cluster with remote GPU virtualization
 Improving overall performance and energy consumption of your cluster with remote GPU virtualization Federico Silla & Carlos Reaño Technical University of Valencia Spain Tutorial Agenda 9.00-10.00 SESSION
Improving overall performance and energy consumption of your cluster with remote GPU virtualization Federico Silla & Carlos Reaño Technical University of Valencia Spain Tutorial Agenda 9.00-10.00 SESSION
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Increasing the efficiency of your GPU-enabled cluster with rcuda. Federico Silla Technical University of Valencia Spain
 Increasing the efficiency of your -enabled cluster with rcuda Federico Silla Technical University of Valencia Spain Outline Why remote virtualization? How does rcuda work? The performance of the rcuda
Increasing the efficiency of your -enabled cluster with rcuda Federico Silla Technical University of Valencia Spain Outline Why remote virtualization? How does rcuda work? The performance of the rcuda
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
OpenCL: History & Future. November 20, 2017
 Mitglied der Helmholtz-Gemeinschaft OpenCL: History & Future November 20, 2017 OpenCL Portable Heterogeneous Computing 2 APIs and 2 kernel languages C Platform Layer API OpenCL C and C++ kernel language
Mitglied der Helmholtz-Gemeinschaft OpenCL: History & Future November 20, 2017 OpenCL Portable Heterogeneous Computing 2 APIs and 2 kernel languages C Platform Layer API OpenCL C and C++ kernel language
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
pvocl: Power-Aware Dynamic Placement and Migration in Virtualized GPU Environments
 IEEE rd International Conference on Distributed Computing Systems pvocl: Power-Aware Dynamic Placement and Migration in Virtualized Environments Palden Lama, Yan Li, Ashwin M. Aji, Pavan Balaji, James
IEEE rd International Conference on Distributed Computing Systems pvocl: Power-Aware Dynamic Placement and Migration in Virtualized Environments Palden Lama, Yan Li, Ashwin M. Aji, Pavan Balaji, James
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
rcuda: hybrid CPU-GPU clusters Federico Silla Technical University of Valencia Spain
 rcuda: hybrid - clusters Federico Silla Technical University of Valencia Spain Outline 1. Hybrid - clusters 2. Concerns with hybrid clusters 3. One possible solution: virtualize s! 4. rcuda what s that?
rcuda: hybrid - clusters Federico Silla Technical University of Valencia Spain Outline 1. Hybrid - clusters 2. Concerns with hybrid clusters 3. One possible solution: virtualize s! 4. rcuda what s that?
AMBER 11 Performance Benchmark and Profiling. July 2011
 AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
Kernel level AES Acceleration using GPUs
 Kernel level AES Acceleration using GPUs TABLE OF CONTENTS 1 PROBLEM DEFINITION 1 2 MOTIVATIONS.................................................1 3 OBJECTIVE.....................................................2
Kernel level AES Acceleration using GPUs TABLE OF CONTENTS 1 PROBLEM DEFINITION 1 2 MOTIVATIONS.................................................1 3 OBJECTIVE.....................................................2
Sharing High-Performance Devices Across Multiple Virtual Machines
 Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Matrix Computations on GPUs, multiple GPUs and clusters of GPUs
 Matrix Computations on GPUs, multiple GPUs and clusters of GPUs Francisco D. Igual Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón (Spain). Matrix Computations on
Matrix Computations on GPUs, multiple GPUs and clusters of GPUs Francisco D. Igual Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón (Spain). Matrix Computations on
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
On the Use of Remote GPUs and Low-Power Processors for the Acceleration of Scientific Applications
 On the Use of Remote GPUs and Low-Power Processors for the Acceleration of Scientific Applications A. Castelló, J. Duato, R. Mayo, A. J. Peña, E. S. Quintana-Ortí, V. Roca, F. Silla Universitat Politècnica
On the Use of Remote GPUs and Low-Power Processors for the Acceleration of Scientific Applications A. Castelló, J. Duato, R. Mayo, A. J. Peña, E. S. Quintana-Ortí, V. Roca, F. Silla Universitat Politècnica
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Technische Universität München. GPU Programming. Rüdiger Westermann Chair for Computer Graphics & Visualization. Faculty of Informatics
 GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
GPU Programming Rüdiger Westermann Chair for Computer Graphics & Visualization Faculty of Informatics Overview Programming interfaces and support libraries The CUDA programming abstraction An in-depth
Accelerated Test Execution Using GPUs
 Accelerated Test Execution Using GPUs Vanya Yaneva Supervisors: Ajitha Rajan, Christophe Dubach Mathworks May 27, 2016 The Problem Software testing is time consuming Functional testing The Problem Software
Accelerated Test Execution Using GPUs Vanya Yaneva Supervisors: Ajitha Rajan, Christophe Dubach Mathworks May 27, 2016 The Problem Software testing is time consuming Functional testing The Problem Software
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
GPUfs: Integrating a file system with GPUs
 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms
 Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
GPGPU, 4th Meeting Mordechai Butrashvily, CEO GASS Company for Advanced Supercomputing Solutions
 GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
GPGPU, 4th Meeting Mordechai Butrashvily, CEO moti@gass-ltd.co.il GASS Company for Advanced Supercomputing Solutions Agenda 3rd meeting 4th meeting Future meetings Activities All rights reserved (c) 2008
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Dynamic Sharing of GPUs in Cloud Systems
 Dynamic Sharing of GPUs in Cloud Systems Khaled M. Diab, M. Mustafa Rafique, Mohamed Hefeeda Qatar Computing Research Institute (QCRI), Qatar Foundation; IBM Research, Ireland Email: kdiab@qf.org.qa; mustafa.rafique@ie.ibm.com;
Dynamic Sharing of GPUs in Cloud Systems Khaled M. Diab, M. Mustafa Rafique, Mohamed Hefeeda Qatar Computing Research Institute (QCRI), Qatar Foundation; IBM Research, Ireland Email: kdiab@qf.org.qa; mustafa.rafique@ie.ibm.com;
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CU2rCU: towards the Complete rcuda Remote GPU Virtualization and Sharing Solution
 CU2rCU: towards the Complete rcuda Remote GPU Virtualization and Sharing Solution C. Reaño, A. J. Peña, F. Silla and J. Duato Universitat Politècnica de València 46.022 València, Spain {carregon, apenya}@gap.upv.es,{fsilla,
CU2rCU: towards the Complete rcuda Remote GPU Virtualization and Sharing Solution C. Reaño, A. J. Peña, F. Silla and J. Duato Universitat Politècnica de València 46.022 València, Spain {carregon, apenya}@gap.upv.es,{fsilla,
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand
 Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Deploying remote GPU virtualization with rcuda. Federico Silla Technical University of Valencia Spain
 Deploying remote virtualization with rcuda Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC ADMINTECH 2016 2/53 It deals with s, obviously! HPC ADMINTECH
Deploying remote virtualization with rcuda Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC ADMINTECH 2016 2/53 It deals with s, obviously! HPC ADMINTECH
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
IO virtualization. Michael Kagan Mellanox Technologies
 IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
Accelerators in Technical Computing: Is it Worth the Pain?
 Accelerators in Technical Computing: Is it Worth the Pain? A TCO Perspective Sandra Wienke, Dieter an Mey, Matthias S. Müller Center for Computing and Communication JARA High-Performance Computing RWTH
Accelerators in Technical Computing: Is it Worth the Pain? A TCO Perspective Sandra Wienke, Dieter an Mey, Matthias S. Müller Center for Computing and Communication JARA High-Performance Computing RWTH
Predictive Runtime Code Scheduling for Heterogeneous Architectures
 Predictive Runtime Code Scheduling for Heterogeneous Architectures Víctor Jiménez, Lluís Vilanova, Isaac Gelado Marisa Gil, Grigori Fursin, Nacho Navarro HiPEAC 2009 January, 26th, 2009 1 Outline Motivation
Predictive Runtime Code Scheduling for Heterogeneous Architectures Víctor Jiménez, Lluís Vilanova, Isaac Gelado Marisa Gil, Grigori Fursin, Nacho Navarro HiPEAC 2009 January, 26th, 2009 1 Outline Motivation
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
Manycore and GPU Channelisers. Seth Hall High Performance Computing Lab, AUT
 Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
Enabling GPU support for the COMPSs-Mobile framework
 Enabling GPU support for the COMPSs-Mobile framework Francesc Lordan, Rosa M Badia and Wen-Mei Hwu Nov 13, 2017 4th Workshop on Accelerator Programming Using Directives COMPSs-Mobile infrastructure WAN
Enabling GPU support for the COMPSs-Mobile framework Francesc Lordan, Rosa M Badia and Wen-Mei Hwu Nov 13, 2017 4th Workshop on Accelerator Programming Using Directives COMPSs-Mobile infrastructure WAN
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Automatic Intra-Application Load Balancing for Heterogeneous Systems
 Automatic Intra-Application Load Balancing for Heterogeneous Systems Michael Boyer, Shuai Che, and Kevin Skadron Department of Computer Science University of Virginia Jayanth Gummaraju and Nuwan Jayasena
Automatic Intra-Application Load Balancing for Heterogeneous Systems Michael Boyer, Shuai Che, and Kevin Skadron Department of Computer Science University of Virginia Jayanth Gummaraju and Nuwan Jayasena
Deep Learning: Transforming Engineering and Science The MathWorks, Inc.
 Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP