Background Heterogeneous Architectures Performance Modeling Single Core Performance Profiling Multicore Performance Estimation Test Cases Multicore
|
|
|
- Susan Eaton
- 6 years ago
- Views:
Transcription


1 By Dan Stafford

2 Background Heterogeneous Architectures Performance Modeling Single Core Performance Profiling Multicore Performance Estimation Test Cases Multicore Design Space Results & Observations General Limited Off-Chip Bandwidth Impact of LLC Size Optimal Heterogeneous Design Job Scheduling Summary of Design Considerations References

3
4 Typically used to obtain a higher performance for a lower power budget CPU/GPU Heterogeneous Systems Intel Core Series, AMD Fusion, NVIDIA Tegra Single ISA Heterogeneous Systems Energy optimized cores Performance optimized cores Every core shares a common ISA ARM big.little, NVIDIA Kal-El Clock Rate Heterogeneous Systems Homogenous cores Different clock rates
5
6 Single Core CPI Memory CPI Fraction of single core CPI waiting for memory Stack Distance Counters (SDC)s Captures the programs temporal memory access in the Last Level of Cache (LLC) All metrics captured every 20M instructions SPEC CPU2006 workloads
7 Profiles each core type across all SPEC CPU2006 workloads Single-core profiles then used to estimate multicore performance Traditional methods take 80 plus days Only takes a single day Accurate within 2.1%


8
9 Out-of-Order cores 4-wide: 128-entry reorder buffer 2-wide: 32-entry reorder buffer In-Order cores 4-wide, 2-wide, and scalar Caches LRU policy Private L1 instruction and data caches 32 KB, 8-way set associative Private L2 cache 256KB 8-way set associative Shared L3 cache (LLC) 1-4MB 16-way set associative
10 BCE Base Core Equivalent Relative chip area measurement Heterogeneous designs configured to use 40 BCEs #BCEs scalar in-order core 1 2-wide in-order core 2 4-wide in-order core 3 2-wide out-of-order core 4 4-wide out-of-order core 8 512KB LLC slice 1
11
12 System Throughput Multicore performance from system perspective,, Average Normalized Turnaround Time User perceived performance,, Note: n independent jobs and cores p programs
13 [1]

14 Simple in order cores have better system throughput Aggressive out-of-order cores have better turnaround time
![[1]](/docs-images/74/70863030/images/15-0.jpg)
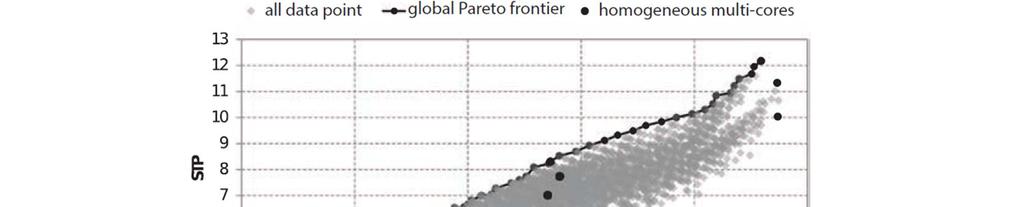
15 [1]
16 [1]

17 Same tradeoff between system throughput and turnaround time Some heterogeneous configurations outperform homogenous configurations Heterogeneity allows more precise control over the system throughput and turnaround time Two different core types provide the majority of the benefit from heterogeneity
18 [1]
19 [1]
20 Limiting the off-chip bandwidth will proportionally affect the per-program performance more Best performance achieved using heterogeneous configurations
21 [1]
22 Cache reduces the off-chip bandwidth pressure Under unlimited bandwidth Less cache leads to integrating more cores together Assuming same chip area vs. with cache
23 [1]

24 High throughput: single-issue and dual-issue in-order cores Per-program performance: At least one outof-order core
25
26 Optimal Mapping Optimal mapping so performance is optimized Prior profiling of all configurations Not feasible Cache-miss-rate Higher LLC miss-rate jobs mapped to lower-end cores Relative Slowdown Assumes relative performance of each job is known Job with highest slowdown on smaller core assigned to higher performing core Random
27 Two Core Types 4-wide out-of-order 2-wide in-order 6 separate heterogeneous configurations 4-wide out-of-order cores 2-wide in-order cores 500 randomly chosen multi-program workload mixes
28 [1]
29 None of the scheduling techniques are quantitatively better Cache-miss rate does not take into account memory parallelism Relative slowdown requires a substantial amount of information Active area of research for all types of heterogeneous architecture


30
31 Perform many simulations before committing to a specific architecture Large LLC Cache vs. Additional Cores Increase LLC cache if bandwidth constrained Additional cores otherwise System Throughput vs. Per-Program Performance In-order cores have better system throughput Out-of-order cores have better per-program throughput

32
![[1]K. Van Craeynest and L. Eeckhout, "Understanding fundamental design choices in single-isa heterogeneous multicore architectures", TACO, vol. 9, no. 4, pp. 1-23, 2013. [2]R. Kumar, D. Tullsen, P.](/docs-images/74/70863030/images/33-2.jpg "Ranganathan, N. Jouppi and K. Farkas, \"Single-ISA Heterogeneous Multi-Core Architectures for Multithreaded Workload Performance\", ACM SIGARCH Computer Architecture News, vol. 32, no. 2, p. 64, 2004.")
33 [1]K. Van Craeynest and L. Eeckhout, "Understanding fundamental design choices in single-isa heterogeneous multicore architectures", TACO, vol. 9, no. 4, pp. 1-23, [2]R. Kumar, D. Tullsen, P. Ranganathan, N. Jouppi and K. Farkas, "Single-ISA Heterogeneous Multi-Core Architectures for Multithreaded Workload Performance", ACM SIGARCH Computer Architecture News, vol. 32, no. 2, p. 64, 2004.
Evaluating Private vs. Shared Last-Level Caches for Energy Efficiency in Asymmetric Multi-Cores
 Evaluating Private vs. Shared Last-Level Caches for Energy Efficiency in Asymmetric Multi-Cores Anthony Gutierrez Adv. Computer Architecture Lab. University of Michigan EECS Dept. Ann Arbor, MI, USA atgutier@umich.edu
Evaluating Private vs. Shared Last-Level Caches for Energy Efficiency in Asymmetric Multi-Cores Anthony Gutierrez Adv. Computer Architecture Lab. University of Michigan EECS Dept. Ann Arbor, MI, USA atgutier@umich.edu
Adaptive Cache Partitioning on a Composite Core
 Adaptive Cache Partitioning on a Composite Core Jiecao Yu, Andrew Lukefahr, Shruti Padmanabha, Reetuparna Das, Scott Mahlke Computer Engineering Lab University of Michigan, Ann Arbor, MI {jiecaoyu, lukefahr,
Adaptive Cache Partitioning on a Composite Core Jiecao Yu, Andrew Lukefahr, Shruti Padmanabha, Reetuparna Das, Scott Mahlke Computer Engineering Lab University of Michigan, Ann Arbor, MI {jiecaoyu, lukefahr,
Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor.
 on a single die. Also called a chip-multiprocessor.") CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
Performance Evaluation of Heterogeneous Microprocessor Architectures
 Performance Evaluation of Heterogeneous Microprocessor Architectures G. Dimova, M. Marinova, V. Lazarov Abstract. This paper focuses on the evaluation of the performance of heterogeneous microprocessor
Performance Evaluation of Heterogeneous Microprocessor Architectures G. Dimova, M. Marinova, V. Lazarov Abstract. This paper focuses on the evaluation of the performance of heterogeneous microprocessor
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
The Reuse Cache Downsizing the Shared Last-Level Cache! Jorge Albericio 1, Pablo Ibáñez 2, Víctor Viñals 2, and José M. Llabería 3!!!
 The Reuse Cache Downsizing the Shared Last-Level Cache! Jorge Albericio 1, Pablo Ibáñez 2, Víctor Viñals 2, and José M. Llabería 3!!! 1 2 3 Modern CMPs" Intel e5 2600 (2013)! SLLC" AMD Orochi (2012)! SLLC"
The Reuse Cache Downsizing the Shared Last-Level Cache! Jorge Albericio 1, Pablo Ibáñez 2, Víctor Viñals 2, and José M. Llabería 3!!! 1 2 3 Modern CMPs" Intel e5 2600 (2013)! SLLC" AMD Orochi (2012)! SLLC"
Gaining Insights into Multicore Cache Partitioning: Bridging the Gap between Simulation and Real Systems
 Gaining Insights into Multicore Cache Partitioning: Bridging the Gap between Simulation and Real Systems 1 Presented by Hadeel Alabandi Introduction and Motivation 2 A serious issue to the effective utilization
Gaining Insights into Multicore Cache Partitioning: Bridging the Gap between Simulation and Real Systems 1 Presented by Hadeel Alabandi Introduction and Motivation 2 A serious issue to the effective utilization
Symbiotic Job Scheduling on the IBM POWER8
 Symbiotic Job Scheduling on the IBM POWER8 Josué Feliu, Stijn Eyerman 2, Julio Sahuquillo, and Salvador Petit Dept. of Computer Engineering (DISCA), Universitat Politècnica de València, València, Spain
Symbiotic Job Scheduling on the IBM POWER8 Josué Feliu, Stijn Eyerman 2, Julio Sahuquillo, and Salvador Petit Dept. of Computer Engineering (DISCA), Universitat Politècnica de València, València, Spain
Core Specific Block Tagging (CSBT) based Thread Migration Model for Single ISA Heterogeneous Multi-core Processors
 based Thread Migration Model for Single ISA Heterogeneous Multi-core Processors") Core Specific Block Tagging (CSBT) based Thread Migration Model for Single ISA Heterogeneous Multi-core Processors Venkatesh Karthik S 1, Pragadeesh R 1 College of Engineering, Guindy, Anna University
Core Specific Block Tagging (CSBT) based Thread Migration Model for Single ISA Heterogeneous Multi-core Processors Venkatesh Karthik S 1, Pragadeesh R 1 College of Engineering, Guindy, Anna University
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
Computer Performance Evaluation and Benchmarking. EE 382M Dr. Lizy Kurian John
 Computer Performance Evaluation and Benchmarking EE 382M Dr. Lizy Kurian John Evolution of Single-Chip Transistor Count 10K- 100K Clock Frequency 0.2-2MHz Microprocessors 1970 s 1980 s 1990 s 2010s 100K-1M
Computer Performance Evaluation and Benchmarking EE 382M Dr. Lizy Kurian John Evolution of Single-Chip Transistor Count 10K- 100K Clock Frequency 0.2-2MHz Microprocessors 1970 s 1980 s 1990 s 2010s 100K-1M
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Exploring the Throughput-Fairness Trade-off on Asymmetric Multicore Systems
 Exploring the Throughput-Fairness Trade-off on Asymmetric Multicore Systems J.C. Sáez, A. Pousa, F. Castro, D. Chaver y M. Prieto Complutense University of Madrid, Universidad Nacional de la Plata-LIDI
Exploring the Throughput-Fairness Trade-off on Asymmetric Multicore Systems J.C. Sáez, A. Pousa, F. Castro, D. Chaver y M. Prieto Complutense University of Madrid, Universidad Nacional de la Plata-LIDI
Database Workload. from additional misses in this already memory-intensive databases? interference could be a problem) Key question:
 Key question:") Database Workload + Low throughput (0.8 IPC on an 8-wide superscalar. 1/4 of SPEC) + Naturally threaded (and widely used) application - Already high cache miss rates on a single-threaded machine (destructive
Database Workload + Low throughput (0.8 IPC on an 8-wide superscalar. 1/4 of SPEC) + Naturally threaded (and widely used) application - Already high cache miss rates on a single-threaded machine (destructive
Computer Architecture 计算机体系结构. Lecture 9. CMP and Multicore System 第九讲 片上多处理器与多核系统. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 9. CMP and Multicore System 第九讲 片上多处理器与多核系统 Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Classification of parallel architectures Shared-memory system Cache coherency
Computer Architecture 计算机体系结构 Lecture 9. CMP and Multicore System 第九讲 片上多处理器与多核系统 Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Classification of parallel architectures Shared-memory system Cache coherency
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Microprocessor Trends and Implications for the Future
 Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
Microprocessor Trends and Implications for the Future John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 4 1 September 2016 Context Last two classes: from
Cache Memories. From Bryant and O Hallaron, Computer Systems. A Programmer s Perspective. Chapter 6.
 Cache Memories From Bryant and O Hallaron, Computer Systems. A Programmer s Perspective. Chapter 6. Today Cache memory organization and operation Performance impact of caches The memory mountain Rearranging
Cache Memories From Bryant and O Hallaron, Computer Systems. A Programmer s Perspective. Chapter 6. Today Cache memory organization and operation Performance impact of caches The memory mountain Rearranging
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
3Introduction. Memory Hierarchy. Chapter 2. Memory Hierarchy Design. Computer Architecture A Quantitative Approach, Fifth Edition
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 1. Computer Abstractions and Technology
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 1 Computer Abstractions and Technology The Computer Revolution Progress in computer technology Underpinned by Moore
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 1 Computer Abstractions and Technology The Computer Revolution Progress in computer technology Underpinned by Moore
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
Processor Performance and Parallelism Y. K. Malaiya
 Processor Performance and Parallelism Y. K. Malaiya Processor Execution time The time taken by a program to execute is the product of n Number of machine instructions executed n Number of clock cycles
Processor Performance and Parallelism Y. K. Malaiya Processor Execution time The time taken by a program to execute is the product of n Number of machine instructions executed n Number of clock cycles
Response Time and Throughput
 Response Time and Throughput Response time How long it takes to do a task Throughput Total work done per unit time e.g., tasks/transactions/ per hour How are response time and throughput affected by Replacing
Response Time and Throughput Response time How long it takes to do a task Throughput Total work done per unit time e.g., tasks/transactions/ per hour How are response time and throughput affected by Replacing
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
The University of Adelaide, School of Computer Science 13 September 2018
 Computer Architecture A Quantitative Approach, Sixth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Sixth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Predictive Thread-to-Core Assignment on a Heterogeneous Multi-core Processor*
 Predictive Thread-to-Core Assignment on a Heterogeneous Multi-core Processor* Tyler Viswanath Krishnamurthy, and Hridesh Laboratory for Software Design Department of Computer Science Iowa State University
Predictive Thread-to-Core Assignment on a Heterogeneous Multi-core Processor* Tyler Viswanath Krishnamurthy, and Hridesh Laboratory for Software Design Department of Computer Science Iowa State University
Applications Classification and Scheduling on Heterogeneous HPC Systems Using Experimental Research
 Applications Classification and Scheduling on Heterogeneous HPC Systems Using Experimental Research Yingjie Xia 1, 2, Mingzhe Zhu 2, 3, Li Kuang 2, Xiaoqiang Ma 3 1 Department of Automation School of Electronic
Applications Classification and Scheduling on Heterogeneous HPC Systems Using Experimental Research Yingjie Xia 1, 2, Mingzhe Zhu 2, 3, Li Kuang 2, Xiaoqiang Ma 3 1 Department of Automation School of Electronic
TDT 4260 lecture 3 spring semester 2015
 1 TDT 4260 lecture 3 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU http://research.idi.ntnu.no/multicore 2 Lecture overview Repetition Chap.1: Performance,
1 TDT 4260 lecture 3 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU http://research.idi.ntnu.no/multicore 2 Lecture overview Repetition Chap.1: Performance,
Cache Memory COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
PERFORMANCE AND ENERGY MODELING OF HETEROGENEOUS MANY-CORE ARCHITECTURES 1. Performance and Energy Modeling of Heterogeneous Many-core Architectures
 PERFORMANCE AND ENERGY MODELING OF HETEROGENEOUS MANY-CORE ARCHITECTURES Performance and Energy Modeling of Heterogeneous Many-core Architectures Rui Pedro Gaspar Pinheiro Abstract Advances in processor
PERFORMANCE AND ENERGY MODELING OF HETEROGENEOUS MANY-CORE ARCHITECTURES Performance and Energy Modeling of Heterogeneous Many-core Architectures Rui Pedro Gaspar Pinheiro Abstract Advances in processor
NAME: Problem Points Score. 7 (bonus) 15. Total
 15. Total") Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 NAME: Problem Points Score 1 40
Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 NAME: Problem Points Score 1 40
A Framework for Providing Quality of Service in Chip Multi-Processors
 A Framework for Providing Quality of Service in Chip Multi-Processors Fei Guo 1, Yan Solihin 1, Li Zhao 2, Ravishankar Iyer 2 1 North Carolina State University 2 Intel Corporation The 40th Annual IEEE/ACM
A Framework for Providing Quality of Service in Chip Multi-Processors Fei Guo 1, Yan Solihin 1, Li Zhao 2, Ravishankar Iyer 2 1 North Carolina State University 2 Intel Corporation The 40th Annual IEEE/ACM
Cache memories are small, fast SRAM-based memories managed automatically in hardware. Hold frequently accessed blocks of main memory
 Cache Memories Cache memories are small, fast SRAM-based memories managed automatically in hardware. Hold frequently accessed blocks of main memory CPU looks first for data in caches (e.g., L1, L2, and
Cache Memories Cache memories are small, fast SRAM-based memories managed automatically in hardware. Hold frequently accessed blocks of main memory CPU looks first for data in caches (e.g., L1, L2, and
Two hours - online. The exam will be taken on line. This paper version is made available as a backup
 COMP 25212 Two hours - online The exam will be taken on line. This paper version is made available as a backup UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date: Monday 21st
COMP 25212 Two hours - online The exam will be taken on line. This paper version is made available as a backup UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date: Monday 21st
Lecture: Large Caches, Virtual Memory. Topics: cache innovations (Sections 2.4, B.4, B.5)
") Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 Techniques to Reduce Cache Misses Victim caches Better replacement policies pseudo-lru, NRU Prefetching, cache
Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 Techniques to Reduce Cache Misses Victim caches Better replacement policies pseudo-lru, NRU Prefetching, cache
CSC501 Operating Systems Principles. OS Structure
 CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
Optimizing Replication, Communication, and Capacity Allocation in CMPs
 Optimizing Replication, Communication, and Capacity Allocation in CMPs Zeshan Chishti, Michael D Powell, and T. N. Vijaykumar School of ECE Purdue University Motivation CMP becoming increasingly important
Optimizing Replication, Communication, and Capacity Allocation in CMPs Zeshan Chishti, Michael D Powell, and T. N. Vijaykumar School of ECE Purdue University Motivation CMP becoming increasingly important
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Lixia Liu, Zhiyuan Li Purdue University, USA. grants ST-HEC , CPA and CPA , and by a Google Fellowship
 Lixia Liu, Zhiyuan Li Purdue University, USA PPOPP 2010, January 2009 Work supported in part by NSF through Work supported in part by NSF through grants ST-HEC-0444285, CPA-0702245 and CPA-0811587, and
Lixia Liu, Zhiyuan Li Purdue University, USA PPOPP 2010, January 2009 Work supported in part by NSF through Work supported in part by NSF through grants ST-HEC-0444285, CPA-0702245 and CPA-0811587, and
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
Shared Memory Multiprocessors. Symmetric Shared Memory Architecture (SMP) Cache Coherence. Cache Coherence Mechanism. Interconnection Network
 Cache Coherence. Cache Coherence Mechanism. Interconnection Network") Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
Shared Memory Multis Processor Processor Processor i Processor n Symmetric Shared Memory Architecture (SMP) cache cache cache cache Interconnection Network Main Memory I/O System Cache Coherence Cache
The Performance Potential for Single Application Heterogeneous Systems
 The Performance Potential for Single Application Heterogeneous Systems Henry Wong University of Toronto henry@eecg.utoronto.ca Tor M. Aamodt University of British Columbia aamodt@ece.ubc.ca Abstract A
The Performance Potential for Single Application Heterogeneous Systems Henry Wong University of Toronto henry@eecg.utoronto.ca Tor M. Aamodt University of British Columbia aamodt@ece.ubc.ca Abstract A
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
Heterogeneous Computing with a Fused CPU+GPU Device
 with a Fused CPU+GPU Device MediaTek White Paper January 2015 2015 MediaTek Inc. 1 Introduction Heterogeneous computing technology, based on OpenCL (Open Computing Language), intelligently fuses GPU and
with a Fused CPU+GPU Device MediaTek White Paper January 2015 2015 MediaTek Inc. 1 Introduction Heterogeneous computing technology, based on OpenCL (Open Computing Language), intelligently fuses GPU and
EXAM 1 SOLUTIONS. Midterm Exam. ECE 741 Advanced Computer Architecture, Spring Instructor: Onur Mutlu
 Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 EXAM 1 SOLUTIONS Problem Points
Midterm Exam ECE 741 Advanced Computer Architecture, Spring 2009 Instructor: Onur Mutlu TAs: Michael Papamichael, Theodoros Strigkos, Evangelos Vlachos February 25, 2009 EXAM 1 SOLUTIONS Problem Points
Improving Real-Time Performance on Multicore Platforms Using MemGuard
 Improving Real-Time Performance on Multicore Platforms Using MemGuard Heechul Yun University of Kansas 2335 Irving hill Rd, Lawrence, KS heechul@ittc.ku.edu Abstract In this paper, we present a case-study
Improving Real-Time Performance on Multicore Platforms Using MemGuard Heechul Yun University of Kansas 2335 Irving hill Rd, Lawrence, KS heechul@ittc.ku.edu Abstract In this paper, we present a case-study
Cache Memory and Performance
 Cache Memory and Performance Cache Performance 1 Many of the following slides are taken with permission from Complete Powerpoint Lecture Notes for Computer Systems: A Programmer's Perspective (CS:APP)
Cache Memory and Performance Cache Performance 1 Many of the following slides are taken with permission from Complete Powerpoint Lecture Notes for Computer Systems: A Programmer's Perspective (CS:APP)
CS3350B Computer Architecture CPU Performance and Profiling
 CS3350B Computer Architecture CPU Performance and Profiling Marc Moreno Maza http://www.csd.uwo.ca/~moreno/cs3350_moreno/index.html Department of Computer Science University of Western Ontario, Canada
CS3350B Computer Architecture CPU Performance and Profiling Marc Moreno Maza http://www.csd.uwo.ca/~moreno/cs3350_moreno/index.html Department of Computer Science University of Western Ontario, Canada
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture The Computer Revolution Progress in computer technology Underpinned by Moore s Law Makes novel applications
The Effect of Temperature on Amdahl Law in 3D Multicore Era
 The Effect of Temperature on Amdahl Law in 3D Multicore Era L Yavits, A Morad, R Ginosar Abstract This work studies the influence of temperature on performance and scalability of 3D Chip Multiprocessors
The Effect of Temperature on Amdahl Law in 3D Multicore Era L Yavits, A Morad, R Ginosar Abstract This work studies the influence of temperature on performance and scalability of 3D Chip Multiprocessors
Exam Parallel Computer Systems
 Exam Parallel Computer Systems Academic Year 2014-2015 Friday January 9, 2015: 8u30 12u00 Prof. L. Eeckhout Some remarks: Fill in your name on every page. Write down the answers in the boxes answers are
Exam Parallel Computer Systems Academic Year 2014-2015 Friday January 9, 2015: 8u30 12u00 Prof. L. Eeckhout Some remarks: Fill in your name on every page. Write down the answers in the boxes answers are
PARSEC vs. SPLASH-2: A Quantitative Comparison of Two Multithreaded Benchmark Suites
 PARSEC vs. SPLASH-2: A Quantitative Comparison of Two Multithreaded Benchmark Suites Christian Bienia (Princeton University), Sanjeev Kumar (Intel), Kai Li (Princeton University) Outline Overview What
PARSEC vs. SPLASH-2: A Quantitative Comparison of Two Multithreaded Benchmark Suites Christian Bienia (Princeton University), Sanjeev Kumar (Intel), Kai Li (Princeton University) Outline Overview What
CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]
![CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]](/thumbs/76/74076691.jpg "CSF Improving Cache Performance. [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005]") CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
CSF Improving Cache Performance [Adapted from Computer Organization and Design, Patterson & Hennessy, 2005] Review: The Memory Hierarchy Take advantage of the principle of locality to present the user
Course web site: teaching/courses/car. Piazza discussion forum:
 Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
Announcements Course web site: http://www.inf.ed.ac.uk/ teaching/courses/car Lecture slides Tutorial problems Courseworks Piazza discussion forum: http://piazza.com/ed.ac.uk/spring2018/car Tutorials start
A Comparative Performance Evaluation of Different Application Domains on Server Processor Architectures
 A Comparative Performance Evaluation of Different Application Domains on Server Processor Architectures W.M. Roshan Weerasuriya and D.N. Ranasinghe University of Colombo School of Computing A Comparative
A Comparative Performance Evaluation of Different Application Domains on Server Processor Architectures W.M. Roshan Weerasuriya and D.N. Ranasinghe University of Colombo School of Computing A Comparative
Exam-2 Scope. 3. Shared memory architecture, distributed memory architecture, SMP, Distributed Shared Memory and Directory based coherence
 Exam-2 Scope 1. Memory Hierarchy Design (Cache, Virtual memory) Chapter-2 slides memory-basics.ppt Optimizations of Cache Performance Memory technology and optimizations Virtual memory 2. SIMD, MIMD, Vector,
Exam-2 Scope 1. Memory Hierarchy Design (Cache, Virtual memory) Chapter-2 slides memory-basics.ppt Optimizations of Cache Performance Memory technology and optimizations Virtual memory 2. SIMD, MIMD, Vector,
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Topics. Digital Systems Architecture EECE EECE Need More Cache?
 Digital Systems Architecture EECE 33-0 EECE 9-0 Need More Cache? Dr. William H. Robinson March, 00 http://eecs.vanderbilt.edu/courses/eece33/ Topics Cache: a safe place for hiding or storing things. Webster
Digital Systems Architecture EECE 33-0 EECE 9-0 Need More Cache? Dr. William H. Robinson March, 00 http://eecs.vanderbilt.edu/courses/eece33/ Topics Cache: a safe place for hiding or storing things. Webster
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
EE282 Computer Architecture. Lecture 1: What is Computer Architecture?
 EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Fit for Purpose Platform Positioning and Performance Architecture
 Fit for Purpose Platform Positioning and Performance Architecture Joe Temple IBM Monday, February 4, 11AM-12PM Session Number 12927 Insert Custom Session QR if Desired. Fit for Purpose Categorized Workload
Fit for Purpose Platform Positioning and Performance Architecture Joe Temple IBM Monday, February 4, 11AM-12PM Session Number 12927 Insert Custom Session QR if Desired. Fit for Purpose Categorized Workload
Write only as much as necessary. Be brief!
 1 CIS371 Computer Organization and Design Midterm Exam Prof. Martin Thursday, March 15th, 2012 This exam is an individual-work exam. Write your answers on these pages. Additional pages may be attached
1 CIS371 Computer Organization and Design Midterm Exam Prof. Martin Thursday, March 15th, 2012 This exam is an individual-work exam. Write your answers on these pages. Additional pages may be attached
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures
 Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures by Ernily Blern, laikrishnan Menon, and Karthikeyan Sankaralingarn Danilo Dominguez Perez danilo0@iastate.edu
Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures by Ernily Blern, laikrishnan Menon, and Karthikeyan Sankaralingarn Danilo Dominguez Perez danilo0@iastate.edu
MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS
 MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing
MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing
AB-Aware: Application Behavior Aware Management of Shared Last Level Caches
 AB-Aware: Application Behavior Aware Management of Shared Last Level Caches Suhit Pai, Newton Singh and Virendra Singh Computer Architecture and Dependable Systems Laboratory Department of Electrical Engineering
AB-Aware: Application Behavior Aware Management of Shared Last Level Caches Suhit Pai, Newton Singh and Virendra Singh Computer Architecture and Dependable Systems Laboratory Department of Electrical Engineering
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 1. Computer Abstractions and Technology
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 1 Computer Abstractions and Technology Classes of Computers Personal computers General purpose, variety of software
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 1 Computer Abstractions and Technology Classes of Computers Personal computers General purpose, variety of software
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Towards Energy-Proportional Datacenter Memory with Mobile DRAM
 Towards Energy-Proportional Datacenter Memory with Mobile DRAM Krishna Malladi 1 Frank Nothaft 1 Karthika Periyathambi Benjamin Lee 2 Christos Kozyrakis 1 Mark Horowitz 1 Stanford University 1 Duke University
Towards Energy-Proportional Datacenter Memory with Mobile DRAM Krishna Malladi 1 Frank Nothaft 1 Karthika Periyathambi Benjamin Lee 2 Christos Kozyrakis 1 Mark Horowitz 1 Stanford University 1 Duke University
Energy-Efficiency Prediction of Multithreaded Workloads on Heterogeneous Composite Cores Architectures using Machine Learning Techniques
 Energy-Efficiency Prediction of Multithreaded Workloads on Heterogeneous Composite Cores Architectures using Machine Learning Techniques Hossein Sayadi Department of Electrical and Computer Engineering
Energy-Efficiency Prediction of Multithreaded Workloads on Heterogeneous Composite Cores Architectures using Machine Learning Techniques Hossein Sayadi Department of Electrical and Computer Engineering
Advanced Memory Organizations
 CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
CSE 3421: Introduction to Computer Architecture Advanced Memory Organizations Study: 5.1, 5.2, 5.3, 5.4 (only parts) Gojko Babić 03-29-2018 1 Growth in Performance of DRAM & CPU Huge mismatch between CPU
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Relative Performance of a Multi-level Cache with Last-Level Cache Replacement: An Analytic Review
 Relative Performance of a Multi-level Cache with Last-Level Cache Replacement: An Analytic Review Bijay K.Paikaray Debabala Swain Dept. of CSE, CUTM Dept. of CSE, CUTM Bhubaneswer, India Bhubaneswer, India
Relative Performance of a Multi-level Cache with Last-Level Cache Replacement: An Analytic Review Bijay K.Paikaray Debabala Swain Dept. of CSE, CUTM Dept. of CSE, CUTM Bhubaneswer, India Bhubaneswer, India
Systems Programming and Computer Architecture ( ) Timothy Roscoe
 Timothy Roscoe") Systems Group Department of Computer Science ETH Zürich Systems Programming and Computer Architecture (252-0061-00) Timothy Roscoe Herbstsemester 2016 AS 2016 Caches 1 16: Caches Computer Architecture
Systems Group Department of Computer Science ETH Zürich Systems Programming and Computer Architecture (252-0061-00) Timothy Roscoe Herbstsemester 2016 AS 2016 Caches 1 16: Caches Computer Architecture
Selective Fill Data Cache
 Selective Fill Data Cache Rice University ELEC525 Final Report Anuj Dharia, Paul Rodriguez, Ryan Verret Abstract Here we present an architecture for improving data cache miss rate. Our enhancement seeks
Selective Fill Data Cache Rice University ELEC525 Final Report Anuj Dharia, Paul Rodriguez, Ryan Verret Abstract Here we present an architecture for improving data cache miss rate. Our enhancement seeks
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Performance, Power, Die Yield. CS301 Prof Szajda
 Performance, Power, Die Yield CS301 Prof Szajda Administrative HW #1 assigned w Due Wednesday, 9/3 at 5:00 pm Performance Metrics (How do we compare two machines?) What to Measure? Which airplane has the
Performance, Power, Die Yield CS301 Prof Szajda Administrative HW #1 assigned w Due Wednesday, 9/3 at 5:00 pm Performance Metrics (How do we compare two machines?) What to Measure? Which airplane has the
A Comparison of Capacity Management Schemes for Shared CMP Caches
 A Comparison of Capacity Management Schemes for Shared CMP Caches Carole-Jean Wu and Margaret Martonosi Princeton University 7 th Annual WDDD 6/22/28 Motivation P P1 P1 Pn L1 L1 L1 L1 Last Level On-Chip
A Comparison of Capacity Management Schemes for Shared CMP Caches Carole-Jean Wu and Margaret Martonosi Princeton University 7 th Annual WDDD 6/22/28 Motivation P P1 P1 Pn L1 L1 L1 L1 Last Level On-Chip
Position Paper: OpenMP scheduling on ARM big.little architecture
 Position Paper: OpenMP scheduling on ARM big.little architecture Anastasiia Butko, Louisa Bessad, David Novo, Florent Bruguier, Abdoulaye Gamatié, Gilles Sassatelli, Lionel Torres, and Michel Robert LIRMM
Position Paper: OpenMP scheduling on ARM big.little architecture Anastasiia Butko, Louisa Bessad, David Novo, Florent Bruguier, Abdoulaye Gamatié, Gilles Sassatelli, Lionel Torres, and Michel Robert LIRMM
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual
Mapping applications into MPSoC
 Mapping applications into MPSoC concurrency & communication Jos van Eijndhoven jos@vectorfabrics.com March 12, 2011 MPSoC mapping: exploiting concurrency 2 March 12, 2012 Computation on general purpose
Mapping applications into MPSoC concurrency & communication Jos van Eijndhoven jos@vectorfabrics.com March 12, 2011 MPSoC mapping: exploiting concurrency 2 March 12, 2012 Computation on general purpose
Kaisen Lin and Michael Conley
 Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
Kaisen Lin and Michael Conley Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania
 OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer