Kaisen Lin and Michael Conley
|
|
|
- Aileen Barber
- 5 years ago
- Views:
Transcription

1 Kaisen Lin and Michael Conley
2 Simultaneous Multithreading Instructions from multiple threads run simultaneously on superscalar processor More instruction fetching and register state Commercialized! DEC Alpha [Dean Tullsen et al] Intel Hyperthreading (Xeon, P4, Atom, Core i7)

3 Web applications Web, DB, file server Throughput over latency Service many users Slight delay acceptable 404 not Idea? More functional units and caches Not just storage state
4
5 Instruction fetch Branch prediction and alignment Similar problems to the trace cache Large programs: inefficient I$ use Issue and retirement Complicated OOE logic not scalable Need more wires, hardware, ports Execution Register file and forwarding logic Power-hungry

6

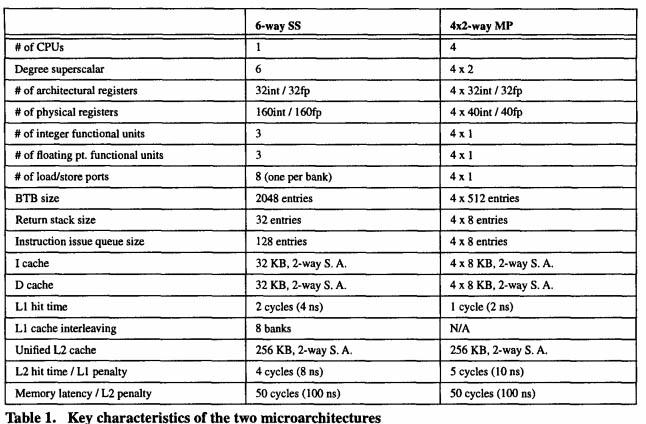
7 Replace complicated OOE with more processors Each with own L1 cache Use communication crossbar for a shared L2 cache Communication still fast, same chip Size details in paper 6-SS about the same as 4x2-MP Simpler CPU overall!
8

9 SimOS: Simulate hardware env Can run commercial operating systems on multiple CPUs IRIX 5.3 tuned for multi-cpu Applications 4 integer, 4 floating-point, 1 multiprog PARALLELLIZED!


10 Which one is better? Misses per completed instruction In general hard to tell what happens


11 Which one is better? 6-SS isn t taking advantage!

12 Actual speedup metrics MP beats the pants off SS some times Doesn t perform so much worse other times
13 6-SS better than 4x2-MP Non-parallelizable applications Fine-grained parallel applications 6-SS worse than 4x2-MP Coarse-grained parallel applications Implications Can tradeoff latency for throughput Need to parallelize software Hardware can t automagically do it anymore


14 Niagara
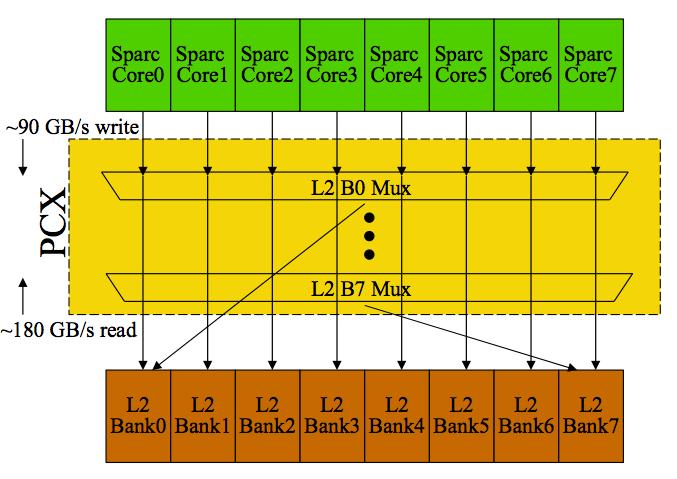
15 L2 Cache Management Cache coherency Inclusion vs Exclusion CMP for complete systems Interconnects/Communication Mixing ILP techniques with TLP Specialized processing (MPSoC) Not just server/web, mobile also!

16
17 Designed CMP to be scalable Network interface on every chip Separate I/O chip Cache coherence protocol BTB Virtually-indexed physically-tagged L1 Bypassed datapath
18 Non-inclusive L2 L1 aggregate capacity = L2 Non-inclusive to increase capacity Behaves live victim cache L1 tags in L2 to designate owner L2 access checks both sets of tags Ownership state in cache line L2 decides whether to write back
 Multicore Targeted at commercial servers 32 hardware")
19 November 2005 Sun s answer to CMP Hybrid processor Multithreading (strands) Multicore Targeted at commercial servers 32 hardware threads

20 Find out what the consumer wants High throughput Low power Sell it to them

21 Servers, web applications (integer) Lots of data High cache miss rate Throughput over latency
22 32 threads 8 thread groups 4 threads per group Shared L2 between ALL 32 threads High bandwidth crossbar interconnect High bandwidth memory 20GB/s 60W One(!) FPU for all 32 threads

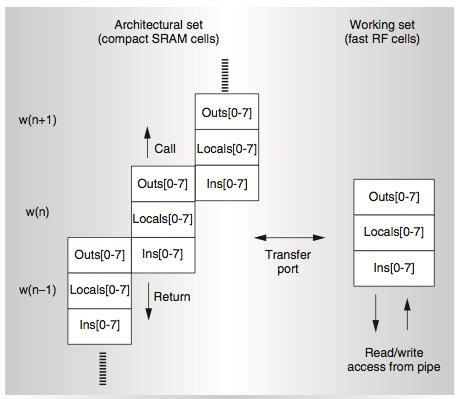
23

24 4 threads Shared processing pipeline Sparc pipe 0 cycle thread switch
25 Shared: L1 I/D caches I/D TLBs Functional units Pipeline registers Dedicated: Data registers Instruction and store buffers
26 Pick a thread for Issue Also fetch from same thread Thread priority Least recently used Long latency ops Speculative load-dependent ops
27 Single issue In-order execution 6 stages with bypass Fetch 2 instructions per cycle Second is speculative Long latency predecode bit
28

29
30 Long latency P0 Long latency P1 Speculative Load hits = Do not squash
31 Hardware call stack No ugly calling conventions Window = 8 in, 8 local, 8 out out in on call Thread has 8 windows
32 Params/Results What you see

33 16K/8K L1 I/D caches Large working sets L1 tag directory in L2 Which L1? Centralized sharing L2 updated before L1 Memory ordering
34 October cores, 8 threads each 16/4 too much area Increased power efficiency Stall Improved single threaded FP One FPU per core

35
36

37 2 INT EXU per pipeline (up from 1) More cache associativity Larger TLBs More L2 banks Cryptography coprocessor Integrated networking Close to memory Integrated PCI-E

38 2 Thread groups 4 threads each, statically partitioned 1 EXU per Pick stage Independent select within each group
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Reference. T1 Architecture. T1 ( Niagara ) Case Study of a Multi-core, Multithreaded
 Case Study of a Multi-core, Multithreaded") Reference Case Study of a Multi-core, Multithreaded Processor The Sun T ( Niagara ) Computer Architecture, A Quantitative Approach, Fourth Edition, by John Hennessy and David Patterson, chapter. :/C:8
Reference Case Study of a Multi-core, Multithreaded Processor The Sun T ( Niagara ) Computer Architecture, A Quantitative Approach, Fourth Edition, by John Hennessy and David Patterson, chapter. :/C:8
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Simultaneous Multithreading Architecture
 Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
Simultaneous Multithreading Architecture Virendra Singh Indian Institute of Science Bangalore Lecture-32 SE-273: Processor Design For most apps, most execution units lie idle For an 8-way superscalar.
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
EECS 452 Lecture 9 TLP Thread-Level Parallelism
 EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
EECS 452 Lecture 9 TLP Thread-Level Parallelism Instructor: Gokhan Memik EECS Dept., Northwestern University The lecture is adapted from slides by Iris Bahar (Brown), James Hoe (CMU), and John Shen (CMU
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
EECS 470. Lecture 18. Simultaneous Multithreading. Fall 2018 Jon Beaumont
 Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Thread-level Parallelism for the Masses. Kunle Olukotun Computer Systems Lab Stanford University 2007
 Thread-level Parallelism for the Masses Kunle Olukotun Computer Systems Lab Stanford University 2007 The World has Changed Process Technology Stops Improving! Moore s law but! Transistors don t get faster
Thread-level Parallelism for the Masses Kunle Olukotun Computer Systems Lab Stanford University 2007 The World has Changed Process Technology Stops Improving! Moore s law but! Transistors don t get faster
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Beyond ILP. Hemanth M Bharathan Balaji. Hemanth M & Bharathan Balaji
 Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
Beyond ILP Hemanth M Bharathan Balaji Multiscalar Processors Gurindar S Sohi Scott E Breach T N Vijaykumar Control Flow Graph (CFG) Each node is a basic block in graph CFG divided into a collection of
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Leveraging OpenSPARC. ESA Round Table 2006 on Next Generation Microprocessors for Space Applications EDD
 Leveraging OpenSPARC ESA Round Table 2006 on Next Generation Microprocessors for Space Applications G.Furano, L.Messina TEC- OpenSPARC T1 The T1 is a new-from-the-ground-up SPARC microprocessor implementation
Leveraging OpenSPARC ESA Round Table 2006 on Next Generation Microprocessors for Space Applications G.Furano, L.Messina TEC- OpenSPARC T1 The T1 is a new-from-the-ground-up SPARC microprocessor implementation
LIMITS OF ILP. B649 Parallel Architectures and Programming
 LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Hyperthreading Technology
 Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU
 1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
Limitations of Scalar Pipelines
 Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Beyond ILP II: SMT and variants. 1 Simultaneous MT: D. Tullsen, S. Eggers, and H. Levy
 EE482: Advanced Computer Organization Lecture #13 Processor Architecture Stanford University Handout Date??? Beyond ILP II: SMT and variants Lecture #13: Wednesday, 10 May 2000 Lecturer: Anamaya Sullery
EE482: Advanced Computer Organization Lecture #13 Processor Architecture Stanford University Handout Date??? Beyond ILP II: SMT and variants Lecture #13: Wednesday, 10 May 2000 Lecturer: Anamaya Sullery
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Simultaneous Multithreading Processor
 Simultaneous Multithreading Processor Paper presented: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor James Lue Some slides are modified from http://hassan.shojania.com/pdf/smt_presentation.pdf
Simultaneous Multithreading Processor Paper presented: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor James Lue Some slides are modified from http://hassan.shojania.com/pdf/smt_presentation.pdf
Simultaneous Multithreading (SMT)
") Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Multithreading Processors and Static Optimization Review. Adapted from Bhuyan, Patterson, Eggers, probably others
 Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Multithreading Processors and Static Optimization Review Adapted from Bhuyan, Patterson, Eggers, probably others Schedule of things to do By Wednesday the 9 th at 9pm Please send a milestone report (as
Superscalar Processors
 Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Simultaneous Multithreading (SMT)
") #1 Lec # 2 Fall 2003 9-10-2003 Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing
#1 Lec # 2 Fall 2003 9-10-2003 Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Multi-threaded processors. Hung-Wei Tseng x Dean Tullsen
 Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Niagara-2: A Highly Threaded Server-on-a-Chip. Greg Grohoski Distinguished Engineer Sun Microsystems
 Niagara-2: A Highly Threaded Server-on-a-Chip Greg Grohoski Distinguished Engineer Sun Microsystems August 22, 2006 Authors Jama Barreh Jeff Brooks Robert Golla Greg Grohoski Rick Hetherington Paul Jordan
Niagara-2: A Highly Threaded Server-on-a-Chip Greg Grohoski Distinguished Engineer Sun Microsystems August 22, 2006 Authors Jama Barreh Jeff Brooks Robert Golla Greg Grohoski Rick Hetherington Paul Jordan
2 TEST: A Tracer for Extracting Speculative Threads
 EE392C: Advanced Topics in Computer Architecture Lecture #11 Polymorphic Processors Stanford University Handout Date??? On-line Profiling Techniques Lecture #11: Tuesday, 6 May 2003 Lecturer: Shivnath
EE392C: Advanced Topics in Computer Architecture Lecture #11 Polymorphic Processors Stanford University Handout Date??? On-line Profiling Techniques Lecture #11: Tuesday, 6 May 2003 Lecturer: Shivnath
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
ECE/CS 757: Homework 1
 ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
ECE/CS 757: Homework 1 Cores and Multithreading 1. A CPU designer has to decide whether or not to add a new micoarchitecture enhancement to improve performance (ignoring power costs) of a block (coarse-grain)
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
" # " $ % & ' ( ) * + $ " % '* + * ' "
 * + $ % '* + * '") ! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
! )! # & ) * + * + * & *,+,- Update Instruction Address IA Instruction Fetch IF Instruction Decode ID Execute EX Memory Access ME Writeback Results WB Program Counter Instruction Register Register File
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Pentium IV-XEON. Computer architectures M
 Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
Simultaneous Multithreading and the Case for Chip Multiprocessing
 Simultaneous Multithreading and the Case for Chip Multiprocessing John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 2 10 January 2019 Microprocessor Architecture
Simultaneous Multithreading and the Case for Chip Multiprocessing John Mellor-Crummey Department of Computer Science Rice University johnmc@rice.edu COMP 522 Lecture 2 10 January 2019 Microprocessor Architecture
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Performance of Computer Systems. CSE 586 Computer Architecture. Review. ISA s (RISC, CISC, EPIC) Basic Pipeline Model.
 Basic Pipeline Model.") Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
Performance of Computer Systems CSE 586 Computer Architecture Review Jean-Loup Baer http://www.cs.washington.edu/education/courses/586/00sp Performance metrics Use (weighted) arithmetic means for execution
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Portland State University ECE 588/688. Cray-1 and Cray T3E
 Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Reducing Miss Penalty: Read Priority over Write on Miss. Improving Cache Performance. Non-blocking Caches to reduce stalls on misses
 Improving Cache Performance 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the. Reducing Miss Penalty: Read Priority over Write on Miss Write buffers may offer RAW
Improving Cache Performance 1. Reduce the miss rate, 2. Reduce the miss penalty, or 3. Reduce the time to hit in the. Reducing Miss Penalty: Read Priority over Write on Miss Write buffers may offer RAW
Parallelism via Multithreaded and Multicore CPUs. Bradley Dutton March 29, 2010 ELEC 6200
 Parallelism via Multithreaded and Multicore CPUs Bradley Dutton March 29, 2010 ELEC 6200 Outline Multithreading Hardware vs. Software definition Hardware multithreading Simple multithreading Interleaved
Parallelism via Multithreaded and Multicore CPUs Bradley Dutton March 29, 2010 ELEC 6200 Outline Multithreading Hardware vs. Software definition Hardware multithreading Simple multithreading Interleaved
Simultaneous Multithreading: a Platform for Next Generation Processors
 Simultaneous Multithreading: a Platform for Next Generation Processors Paulo Alexandre Vilarinho Assis Departamento de Informática, Universidade do Minho 4710 057 Braga, Portugal paulo.assis@bragatel.pt
Simultaneous Multithreading: a Platform for Next Generation Processors Paulo Alexandre Vilarinho Assis Departamento de Informática, Universidade do Minho 4710 057 Braga, Portugal paulo.assis@bragatel.pt
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
ILP Ends TLP Begins. ILP Limits via an Oracle
 ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
ILP Ends TLP Begins Today s topics: Explore a perfect machine unlimited budget to see where ILP goes answer: not far enough Look to TLP & multi-threading for help everything has it s issues we ll look
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
EE382 Processor Design. Processor Issues for MP
 EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors, Part I EE 382 Processor Design Winter 98/99 Michael Flynn 1 Processor Issues for MP Initialization Interrupts Virtual Memory TLB Coherency
EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors, Part I EE 382 Processor Design Winter 98/99 Michael Flynn 1 Processor Issues for MP Initialization Interrupts Virtual Memory TLB Coherency
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core. Prof. Onur Mutlu Carnegie Mellon University
 18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Intel Architecture for Software Developers
 Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Core Fusion: Accommodating Software Diversity in Chip Multiprocessors
 Core Fusion: Accommodating Software Diversity in Chip Multiprocessors Authors: Engin Ipek, Meyrem Kırman, Nevin Kırman, and Jose F. Martinez Navreet Virk Dept of Computer & Information Sciences University
Core Fusion: Accommodating Software Diversity in Chip Multiprocessors Authors: Engin Ipek, Meyrem Kırman, Nevin Kırman, and Jose F. Martinez Navreet Virk Dept of Computer & Information Sciences University
Cache Coherence. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
Cache Coherence CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Shared memory multi-processor Processors read and write to shared variables - More precisely: processors issues
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 18 Multicore Computers
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Computer Architecture 计算机体系结构. Lecture 9. CMP and Multicore System 第九讲 片上多处理器与多核系统. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 9. CMP and Multicore System 第九讲 片上多处理器与多核系统 Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Classification of parallel architectures Shared-memory system Cache coherency
Computer Architecture 计算机体系结构 Lecture 9. CMP and Multicore System 第九讲 片上多处理器与多核系统 Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Classification of parallel architectures Shared-memory system Cache coherency
Wenisch Final Review. Fall 2007 Prof. Thomas Wenisch EECS 470. Slide 1
 Final Review Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 Slide 1 Announcements Wenisch 2007 Exam is Monday, 12/17 4 6 in this room I recommend bringing a scientific calculator
Final Review Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 Slide 1 Announcements Wenisch 2007 Exam is Monday, 12/17 4 6 in this room I recommend bringing a scientific calculator
CS 152 Computer Architecture and Engineering. Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
OPENSPARC T1 OVERVIEW
 Chapter Four OPENSPARC T1 OVERVIEW Denis Sheahan Distinguished Engineer Niagara Architecture Group Sun Microsystems Creative Commons 3.0United United States License Creative CommonsAttribution-Share Attribution-Share
Chapter Four OPENSPARC T1 OVERVIEW Denis Sheahan Distinguished Engineer Niagara Architecture Group Sun Microsystems Creative Commons 3.0United United States License Creative CommonsAttribution-Share Attribution-Share
Superscalar Organization
 Superscalar Organization Nima Honarmand Instruction-Level Parallelism (ILP) Recall: Parallelism is the number of independent tasks available ILP is a measure of inter-dependencies between insns. Average
Superscalar Organization Nima Honarmand Instruction-Level Parallelism (ILP) Recall: Parallelism is the number of independent tasks available ILP is a measure of inter-dependencies between insns. Average
Lecture 21: Parallelism ILP to Multicores. Parallel Processing 101
 18 447 Lecture 21: Parallelism ILP to Multicores S 10 L21 1 James C. Hoe Dept of ECE, CMU April 7, 2010 Announcements: Handouts: Lab 4 due this week Optional reading assignments below. The Microarchitecture
18 447 Lecture 21: Parallelism ILP to Multicores S 10 L21 1 James C. Hoe Dept of ECE, CMU April 7, 2010 Announcements: Handouts: Lab 4 due this week Optional reading assignments below. The Microarchitecture
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define
ROEVER ENGINEERING COLLEGE DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING 16 MARKS CS 2354 ADVANCE COMPUTER ARCHITECTURE 1. Explain the concepts and challenges of Instruction-Level Parallelism. Define