High-Performance Packet Classification on GPU
|
|
|
- Jessie Poole
- 6 years ago
- Views:
Transcription
1 High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California 1
2 Outline Introduction Background Contributions Algorithm Evaluation Conclusion and Future Work 2
3 Outline Introduction Background Contributions Algorithm Evaluation Conclusion and Future Work 3

4 Introduction (1) Internet: Global system of interconnected computer networks Exponentially increasing network traffic Future Internet More network traffic Large amounts of data Changing more frequently 4



5 Introduction (2) Multi-field Packet Classification Applications Routing Access control in firewalls Provision of differentiated qualities of service OpenFlow flow table lookup 5
6 Outline Introduction Background Contributions Algorithm Evaluation Conclusion and Future Work 6
7 Multi-field Packet Classification (1) 5-Fields Source IP address Destination IP address Source port number Destination port number Protocol Src IP Des IP Src Port Des Port Protocol Bits
8 Multi-field Packet Classification (2) Rule-set A certain number of rules Matching criteria for each field Wildcard bit in the rule:1, 0 or (do not care) Priority Multiple matches choose the highest priority rule take the action 8
9 Multi-field Packet Classification (3) ID Src IP Des IP Src Port Des Port Protocol Priority ACTION / / x06 1 Act / / x06 2 Act / / x11 3 Act 2 9
10 Related Work Packet classification on GPU Relatively less explored Previous GPU implementations Unique Rules: small [1] Throughput or Latency not discussed [2] ~11 and 5 MPPS for 500 and 2000 rules [3] [1] A. Nottingham and B. Irwin, Parallel packet classification using GPU co-processors, in SAICSIT Conf.ACM., pp , [2] C. Hung, Y. Lin, K. Li, H. Wang and S. Guo, Efficient GPGPUbased parallel packet classification, in Trust, Security and Privacy in Computing and Communications (TrustCom), pp , [3] K. Kang and Y. S. Deng, Scalable packet classification via GPU metaprograming, in Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 1-4,
11 CUDA Programming Model CUDA program Host + Kernel Host function runs on CPU Kernel function runs on GPU 11
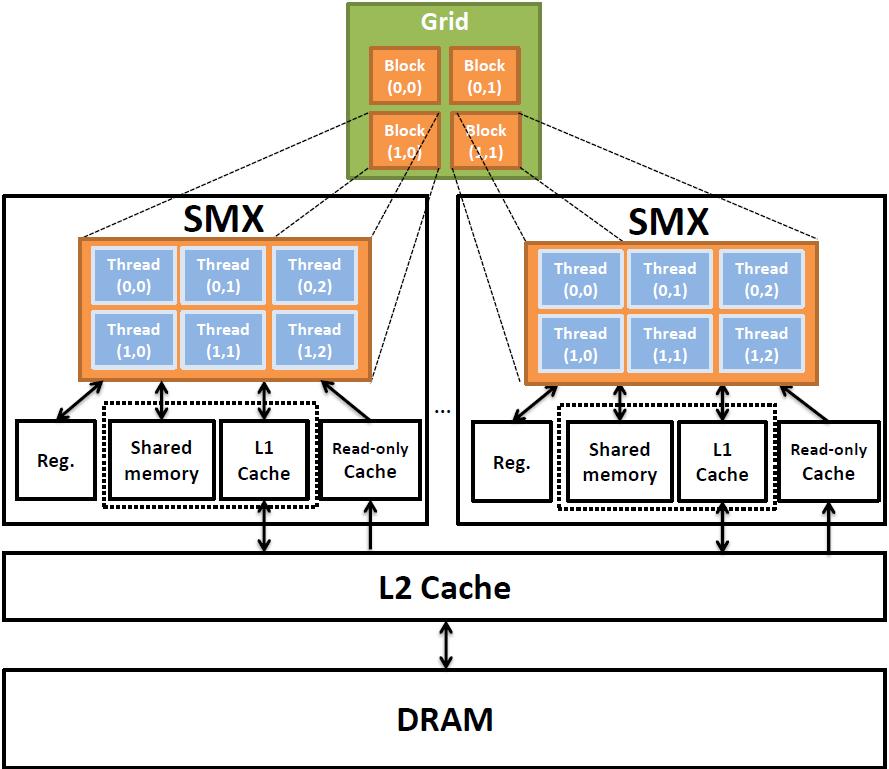
12 GPU Architecture 12
13 Outline Introduction Background Contributions Algorithm Evaluation Conclusion and Future Work 13
14 Contributions Range-tree search and bit vector (BV) based packet classifier on GPU Efficient range-tree search on GPU Optimize data layout to minimize shared memory bank conflict Throughput of 85 MPPS for 512-rule rule-set 14


15 Challenges Divergence Overhead Limited on-chip memory: data layout Classic Tree-Search: pointers to connect nodes Time Warp T T F T F F F F True: False: Action_a() Action_b() 15
16 Outline Introduction Background Contributions Algorithm Evaluation Conclusion and Future Work 16
17 Algorithm (1) Decomposition-based approach Range-tree Search 17
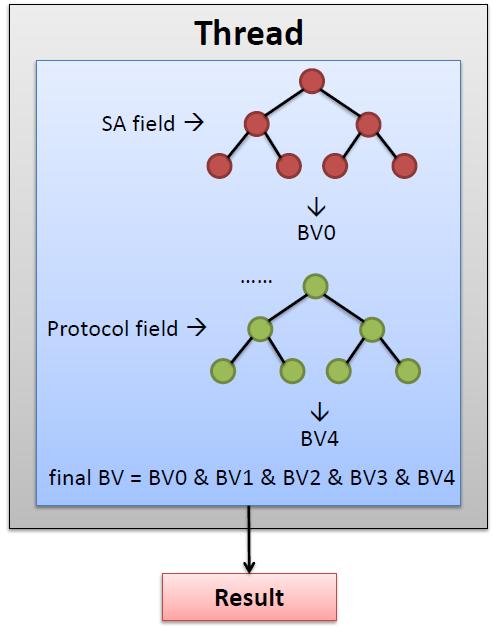
18 Algorithm (2) Bit Vector Representation i th bit i th original rule 1 match 0 not match Merge by Bit AND operation & 1 0 & 1 1 = 1 0 match
19 Algorithm (3) 32 threads (a warp) per packet Pre-processing (In CPU): Partition rule-set into 32 subsets Construct range-trees & BVs for each subset Classification (In GPU): Phase 1: obtain an intermediate result (using the range-trees and BVs) Phase 2: intermediate results final result 19
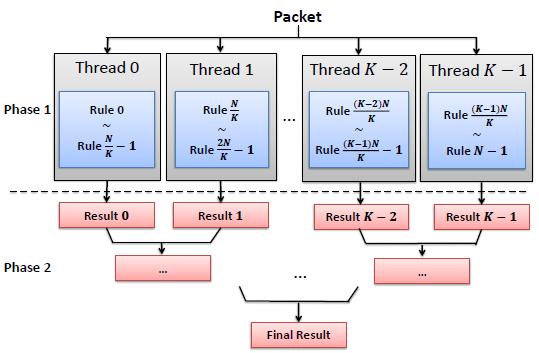
20 Architecture Note: K =32 20
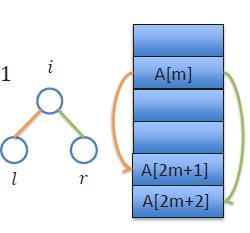
21 Optimizations (1) 21

22 Optimizations (2) Store range-trees in shared memory Data for Thread 1 Data for Thread 2 Data for Thread n Shared memory bank conflicts Row-major 22
23 Optimizations (3) Minimize shared memory bank conflicts Data for Thread 1 Data for Thread 2 Data for Thread n Column-major 23
24 Outline Introduction Background Contributions Algorithm Evaluation Conclusion and Future Work 24
25 Platform CPU (Intel E5-2665) Cores: 16 Frequency: 2.4 GHz GPU (NVIDIA K20 Kepler) Streaming Multi-Processor (SMX): 13 CUDA cores: 2496 Frequency: MHz 25
26 Latency ( s) Performance (1) 30 No. of rules = Column-major (With Shared-memory) Row-major (With Shared-memory) Without Shared-memory 26
27 Latency ( s) Performance (2) 100 Throughput 10 Latency Throughput (MPPS) No. of rules No. of rules 27
28 Throughput (MPPS) Latency ( s) Performance (3) Best Case: smallest possible range-trees Worst Case: largest possible range-trees 120 Best Case 16 Best Case 90 Worst Case 12 Worst Case No. of rules No. of rules 28
29 Outline Introduction Background Summary of Contributions Algorithm Evaluation Conclusion and Future Work 29
30 Conclusions Range-trees + BV packet packet classifier on GPU: 85 MPPS for 512-rule rule-set Performance: throughput and latency number of rules ( ) data layout in shared memory Compared to state-of-the-art multi-core implementation: 2x improvement in throughput 30
31 Future Work Hash-based packet classification algorithms Other networking applications using GPUs Traffic classification OpenFlow flow table lookup 31
32 Thank you! Group Webpage: IDs: 32
High-Performance Packet Classification on GPU
 High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura and Viktor. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Los Angeles, CA 99
High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura and Viktor. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Los Angeles, CA 99
Multi-core Implementation of Decomposition-based Packet Classification Algorithms 1
 Multi-core Implementation of Decomposition-based Packet Classification Algorithms 1 Shijie Zhou, Yun R. Qu, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering, University of Southern
Multi-core Implementation of Decomposition-based Packet Classification Algorithms 1 Shijie Zhou, Yun R. Qu, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering, University of Southern
Decision Forest: A Scalable Architecture for Flexible Flow Matching on FPGA
 Decision Forest: A Scalable Architecture for Flexible Flow Matching on FPGA Weirong Jiang, Viktor K. Prasanna University of Southern California Norio Yamagaki NEC Corporation September 1, 2010 Outline
Decision Forest: A Scalable Architecture for Flexible Flow Matching on FPGA Weirong Jiang, Viktor K. Prasanna University of Southern California Norio Yamagaki NEC Corporation September 1, 2010 Outline
Performance Modeling and Optimizations for Decomposition-based Large-scale Packet Classification on Multi-core Processors*
 Performance Modeling and Optimizations for Decomposition-based Large-scale Packet Classification on Multi-core Processors* Yun R. Qu, Shijie Zhou, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering
Performance Modeling and Optimizations for Decomposition-based Large-scale Packet Classification on Multi-core Processors* Yun R. Qu, Shijie Zhou, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA
 Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
High-throughput Online Hash Table on FPGA*
 High-throughput Online Hash Table on FPGA* Da Tong, Shijie Zhou, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 989 Email: datong@usc.edu,
High-throughput Online Hash Table on FPGA* Da Tong, Shijie Zhou, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 989 Email: datong@usc.edu,
Fast and Scalable Subgraph Isomorphism using Dynamic Graph Techniques. James Fox
 Fast and Scalable Subgraph Isomorphism using Dynamic Graph Techniques James Fox Collaborators Oded Green, Research Scientist (GT) Euna Kim, PhD student (GT) Federico Busato, PhD student (Universita di
Fast and Scalable Subgraph Isomorphism using Dynamic Graph Techniques James Fox Collaborators Oded Green, Research Scientist (GT) Euna Kim, PhD student (GT) Federico Busato, PhD student (Universita di
Evaluating the Potential of Graphics Processors for High Performance Embedded Computing
 Evaluating the Potential of Graphics Processors for High Performance Embedded Computing Shuai Mu, Chenxi Wang, Ming Liu, Yangdong Deng Department of Micro-/Nano-electronics Tsinghua University Outline
Evaluating the Potential of Graphics Processors for High Performance Embedded Computing Shuai Mu, Chenxi Wang, Ming Liu, Yangdong Deng Department of Micro-/Nano-electronics Tsinghua University Outline
Hermes: An Integrated CPU/GPU Microarchitecture for IP Routing
 Hermes: An Integrated CPU/GPU Microarchitecture for IP Routing Yuhao Zhu * Yangdong Deng Yubei Chen * Electrical and Computer Engineering University of Texas at Austin Institute of Microelectronics Tsinghua
Hermes: An Integrated CPU/GPU Microarchitecture for IP Routing Yuhao Zhu * Yangdong Deng Yubei Chen * Electrical and Computer Engineering University of Texas at Austin Institute of Microelectronics Tsinghua
Energy Optimizations for FPGA-based 2-D FFT Architecture
 Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
P4GPU: A Study of Mapping a P4 Program onto GPU Target
 P4GPU: A Study of Mapping a P4 Program onto GPU Target Peilong Li, Tyler Alterio, Swaroop Thool and Yan Luo ACANETS Lab (http://acanets.uml.edu/) University of Massachusetts Lowell 11/18/15 University
P4GPU: A Study of Mapping a P4 Program onto GPU Target Peilong Li, Tyler Alterio, Swaroop Thool and Yan Luo ACANETS Lab (http://acanets.uml.edu/) University of Massachusetts Lowell 11/18/15 University
EECS 122: Introduction to Computer Networks Switch and Router Architectures. Today s Lecture
 EECS : Introduction to Computer Networks Switch and Router Architectures Computer Science Division Department of Electrical Engineering and Computer Sciences University of California, Berkeley Berkeley,
EECS : Introduction to Computer Networks Switch and Router Architectures Computer Science Division Department of Electrical Engineering and Computer Sciences University of California, Berkeley Berkeley,
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Scalable Enterprise Networks with Inexpensive Switches
 Scalable Enterprise Networks with Inexpensive Switches Minlan Yu minlanyu@cs.princeton.edu Princeton University Joint work with Alex Fabrikant, Mike Freedman, Jennifer Rexford and Jia Wang 1 Enterprises
Scalable Enterprise Networks with Inexpensive Switches Minlan Yu minlanyu@cs.princeton.edu Princeton University Joint work with Alex Fabrikant, Mike Freedman, Jennifer Rexford and Jia Wang 1 Enterprises
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
Parallel Exact Inference on the Cell Broadband Engine Processor
 Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, prasanna}@usc.edu University of Southern California http://ceng.usc.edu/~prasanna/ SC 08 Overview
Parallel Exact Inference on the Cell Broadband Engine Processor Yinglong Xia and Viktor K. Prasanna {yinglonx, prasanna}@usc.edu University of Southern California http://ceng.usc.edu/~prasanna/ SC 08 Overview
Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18
 Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
The dark powers on Intel processor boards
 The dark powers on Intel processor boards Processing Resources (3U VPX) Boards with Multicore CPUs: Up to 16 cores using Intel Xeon D-1577 on TR C4x/msd Boards with 4-Core CPUs and Multiple Graphical Execution
The dark powers on Intel processor boards Processing Resources (3U VPX) Boards with Multicore CPUs: Up to 16 cores using Intel Xeon D-1577 on TR C4x/msd Boards with 4-Core CPUs and Multiple Graphical Execution
The Power of Batching in the Click Modular Router
 The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Analysis-driven Engineering of Comparison-based Sorting Algorithms on GPUs
 AlgoPARC Analysis-driven Engineering of Comparison-based Sorting Algorithms on GPUs 32nd ACM International Conference on Supercomputing June 17, 2018 Ben Karsin 1 karsin@hawaii.edu Volker Weichert 2 weichert@cs.uni-frankfurt.de
AlgoPARC Analysis-driven Engineering of Comparison-based Sorting Algorithms on GPUs 32nd ACM International Conference on Supercomputing June 17, 2018 Ben Karsin 1 karsin@hawaii.edu Volker Weichert 2 weichert@cs.uni-frankfurt.de
Decision Forest: A Scalable Architecture for Flexible Flow Matching on FPGA
 2010 International Conference on Field Programmable Logic and Applications Decision Forest: A Scalable Architecture for Flexible Flow Matching on FPGA Weirong Jiang, Viktor K. Prasanna Ming Hsieh Department
2010 International Conference on Field Programmable Logic and Applications Decision Forest: A Scalable Architecture for Flexible Flow Matching on FPGA Weirong Jiang, Viktor K. Prasanna Ming Hsieh Department
CSE398: Network Systems Design
 CSE398: Network Systems Design Instructor: Dr. Liang Cheng Department of Computer Science and Engineering P.C. Rossin College of Engineering & Applied Science Lehigh University March 14, 2005 Outline Classification
CSE398: Network Systems Design Instructor: Dr. Liang Cheng Department of Computer Science and Engineering P.C. Rossin College of Engineering & Applied Science Lehigh University March 14, 2005 Outline Classification
Benchmarking results of SMIP project software components
 Benchmarking results of SMIP project software components NAILabs September 15, 23 1 Introduction As packets are processed by high-speed security gateways and firewall devices, it is critical that system
Benchmarking results of SMIP project software components NAILabs September 15, 23 1 Introduction As packets are processed by high-speed security gateways and firewall devices, it is critical that system
Generic Architecture. EECS 122: Introduction to Computer Networks Switch and Router Architectures. Shared Memory (1 st Generation) Today s Lecture
 Today s Lecture") Generic Architecture EECS : Introduction to Computer Networks Switch and Router Architectures Computer Science Division Department of Electrical Engineering and Computer Sciences University of California,
Generic Architecture EECS : Introduction to Computer Networks Switch and Router Architectures Computer Science Division Department of Electrical Engineering and Computer Sciences University of California,
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
 Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
Scalable Packet Classification on FPGA
 1668 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 20, NO. 9, SEPTEMBER 2012 Scalable Packet Classification on FPGA Weirong Jiang, Member, IEEE, and Viktor K. Prasanna, Fellow,
1668 IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 20, NO. 9, SEPTEMBER 2012 Scalable Packet Classification on FPGA Weirong Jiang, Member, IEEE, and Viktor K. Prasanna, Fellow,
Packet Classification Using Dynamically Generated Decision Trees
 1 Packet Classification Using Dynamically Generated Decision Trees Yu-Chieh Cheng, Pi-Chung Wang Abstract Binary Search on Levels (BSOL) is a decision-tree algorithm for packet classification with superior
1 Packet Classification Using Dynamically Generated Decision Trees Yu-Chieh Cheng, Pi-Chung Wang Abstract Binary Search on Levels (BSOL) is a decision-tree algorithm for packet classification with superior
TUPLE PRUNING USING BLOOM FILTERS FOR PACKET CLASSIFICATION
 ... TUPLE PRUNING USING BLOOM FILTERS FOR PACKET CLASSIFICATION... TUPLE PRUNING FOR PACKET CLASSIFICATION PROVIDES FAST SEARCH AND A LOW IMPLEMENTATION COMPLEXITY. THE TUPLE PRUNING ALGORITHM REDUCES
... TUPLE PRUNING USING BLOOM FILTERS FOR PACKET CLASSIFICATION... TUPLE PRUNING FOR PACKET CLASSIFICATION PROVIDES FAST SEARCH AND A LOW IMPLEMENTATION COMPLEXITY. THE TUPLE PRUNING ALGORITHM REDUCES
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Dynamically Configurable Online Statistical Flow Feature Extractor on FPGA
 Dynamically Configurable Online Statistical Flow Feature Extractor on FPGA Da Tong, Viktor Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Email: {datong, prasanna}@usc.edu
Dynamically Configurable Online Statistical Flow Feature Extractor on FPGA Da Tong, Viktor Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Email: {datong, prasanna}@usc.edu
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Multi-Layer Packet Classification with Graphics Processing Units
 Multi-Layer Packet Classification with Graphics Processing Units Matteo Varvello, Rafael Laufer, Feixiong Zhang, T.V. Lakshman Telefonica Research, matteo.varvello@telefonica.com Bell Labs, {firstname.lastname}@alcatel-lucent.com
Multi-Layer Packet Classification with Graphics Processing Units Matteo Varvello, Rafael Laufer, Feixiong Zhang, T.V. Lakshman Telefonica Research, matteo.varvello@telefonica.com Bell Labs, {firstname.lastname}@alcatel-lucent.com
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
SSA: A Power and Memory Efficient Scheme to Multi-Match Packet Classification. Fang Yu, T.V. Lakshman, Martin Austin Motoyama, Randy H.
 SSA: A Power and Memory Efficient Scheme to Multi-Match Packet Classification Fang Yu, T.V. Lakshman, Martin Austin Motoyama, Randy H. Katz Presented by: Discussion led by: Sailesh Kumar Packet Classification
SSA: A Power and Memory Efficient Scheme to Multi-Match Packet Classification Fang Yu, T.V. Lakshman, Martin Austin Motoyama, Randy H. Katz Presented by: Discussion led by: Sailesh Kumar Packet Classification
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Fast Tridiagonal Solvers on GPU
 Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
GASPP: A GPU- Accelerated Stateful Packet Processing Framework
 GASPP: A GPU- Accelerated Stateful Packet Processing Framework Giorgos Vasiliadis, FORTH- ICS, Greece Lazaros Koromilas, FORTH- ICS, Greece Michalis Polychronakis, Columbia University, USA So5ris Ioannidis,
GASPP: A GPU- Accelerated Stateful Packet Processing Framework Giorgos Vasiliadis, FORTH- ICS, Greece Lazaros Koromilas, FORTH- ICS, Greece Michalis Polychronakis, Columbia University, USA So5ris Ioannidis,
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION. Julien Demouth, NVIDIA Cliff Woolley, NVIDIA
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
A Scalable Approach for Packet Classification Using Rule-Base Partition
 CNIR Journal, Volume (5), Issue (1), Dec., 2005 A Scalable Approach for Packet Classification Using Rule-Base Partition Mr. S J Wagh 1 and Dr. T. R. Sontakke 2 [1] Assistant Professor in Information Technology,
CNIR Journal, Volume (5), Issue (1), Dec., 2005 A Scalable Approach for Packet Classification Using Rule-Base Partition Mr. S J Wagh 1 and Dr. T. R. Sontakke 2 [1] Assistant Professor in Information Technology,
Highly Efficient Compensationbased Parallelism for Wavefront Loops on GPUs
 Highly Efficient Compensationbased Parallelism for Wavefront Loops on GPUs Kaixi Hou, Hao Wang, Wu chun Feng {kaixihou, hwang121, wfeng}@vt.edu Jeffrey S. Vetter, Seyong Lee vetter@computer.org, lees2@ornl.gov
Highly Efficient Compensationbased Parallelism for Wavefront Loops on GPUs Kaixi Hou, Hao Wang, Wu chun Feng {kaixihou, hwang121, wfeng}@vt.edu Jeffrey S. Vetter, Seyong Lee vetter@computer.org, lees2@ornl.gov
GPUfs: Integrating a File System with GPUs. Yishuai Li & Shreyas Skandan
 GPUfs: Integrating a File System with GPUs Yishuai Li & Shreyas Skandan Von Neumann Architecture Mem CPU I/O Von Neumann Architecture Mem CPU I/O slow fast slower Direct Memory Access Mem CPU I/O slow
GPUfs: Integrating a File System with GPUs Yishuai Li & Shreyas Skandan Von Neumann Architecture Mem CPU I/O Von Neumann Architecture Mem CPU I/O slow fast slower Direct Memory Access Mem CPU I/O slow
A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang
 A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal
A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Multi2sim Kepler: A Detailed Architectural GPU Simulator
 Multi2sim Kepler: A Detailed Architectural GPU Simulator Xun Gong, Rafael Ubal, David Kaeli Northeastern University Computer Architecture Research Lab Department of Electrical and Computer Engineering
Multi2sim Kepler: A Detailed Architectural GPU Simulator Xun Gong, Rafael Ubal, David Kaeli Northeastern University Computer Architecture Research Lab Department of Electrical and Computer Engineering
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
PFAC Library: GPU-Based String Matching Algorithm
 PFAC Library: GPU-Based String Matching Algorithm Cheng-Hung Lin Lung-Sheng Chien Chen-Hsiung Liu Shih-Chieh Chang Wing-Kai Hon National Taiwan Normal University, Taipei, Taiwan National Tsing-Hua University,
PFAC Library: GPU-Based String Matching Algorithm Cheng-Hung Lin Lung-Sheng Chien Chen-Hsiung Liu Shih-Chieh Chang Wing-Kai Hon National Taiwan Normal University, Taipei, Taiwan National Tsing-Hua University,
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
IP Address Lookup and Packet Classification Algorithms
 IP Address Lookup and Packet Classification Algorithms Zhen Xu, Jeff Nie, Xuehong Sun, and Yiqiang Q. Zhao School of Mathematics and Statistics, Carleton University Outline 1. Background 2. Two IP Address
IP Address Lookup and Packet Classification Algorithms Zhen Xu, Jeff Nie, Xuehong Sun, and Yiqiang Q. Zhao School of Mathematics and Statistics, Carleton University Outline 1. Background 2. Two IP Address
High-Performance Graph Primitives on the GPU: Design and Implementation of Gunrock
 High-Performance Graph Primitives on the GPU: Design and Implementation of Gunrock Yangzihao Wang University of California, Davis yzhwang@ucdavis.edu March 24, 2014 Yangzihao Wang (yzhwang@ucdavis.edu)
High-Performance Graph Primitives on the GPU: Design and Implementation of Gunrock Yangzihao Wang University of California, Davis yzhwang@ucdavis.edu March 24, 2014 Yangzihao Wang (yzhwang@ucdavis.edu)
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Fast Segmented Sort on GPUs
 Fast Segmented Sort on GPUs Kaixi Hou, Weifeng Liu, Hao Wang, Wu-chun Feng {kaixihou, hwang121, wfeng}@vt.edu weifeng.liu@nbi.ku.dk Segmented Sort (SegSort) Perform a segment-by-segment sort on a given
Fast Segmented Sort on GPUs Kaixi Hou, Weifeng Liu, Hao Wang, Wu-chun Feng {kaixihou, hwang121, wfeng}@vt.edu weifeng.liu@nbi.ku.dk Segmented Sort (SegSort) Perform a segment-by-segment sort on a given
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Lecture 27: Multiprocessors. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs
 GPUs") Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
G-NET: Effective GPU Sharing In NFV Systems
 G-NET: Effective Sharing In NFV Systems Kai Zhang*, Bingsheng He^, Jiayu Hu #, Zeke Wang^, Bei Hua #, Jiayi Meng #, Lishan Yang # *Fudan University ^National University of Singapore #University of Science
G-NET: Effective Sharing In NFV Systems Kai Zhang*, Bingsheng He^, Jiayu Hu #, Zeke Wang^, Bei Hua #, Jiayi Meng #, Lishan Yang # *Fudan University ^National University of Singapore #University of Science
Optimizing Memory Performance for FPGA Implementation of PageRank
 Optimizing Memory Performance for FPGA Implementation of PageRank Shijie Zhou, Charalampos Chelmis, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles,
Optimizing Memory Performance for FPGA Implementation of PageRank Shijie Zhou, Charalampos Chelmis, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles,
Hardware Assisted Recursive Packet Classification Module for IPv6 etworks ABSTRACT
 Hardware Assisted Recursive Packet Classification Module for IPv6 etworks Shivvasangari Subramani [shivva1@umbc.edu] Department of Computer Science and Electrical Engineering University of Maryland Baltimore
Hardware Assisted Recursive Packet Classification Module for IPv6 etworks Shivvasangari Subramani [shivva1@umbc.edu] Department of Computer Science and Electrical Engineering University of Maryland Baltimore
CUB. collective software primitives. Duane Merrill. NVIDIA Research
 CUB collective software primitives Duane Merrill NVIDIA Research What is CUB?. A design model for collective primitives How to make reusable SIMT software constructs. A library of collective primitives
CUB collective software primitives Duane Merrill NVIDIA Research What is CUB?. A design model for collective primitives How to make reusable SIMT software constructs. A library of collective primitives
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Towards Performance Modeling of 3D Memory Integrated FPGA Architectures
 Towards Performance Modeling of 3D Memory Integrated FPGA Architectures Shreyas G. Singapura, Anand Panangadan and Viktor K. Prasanna University of Southern California, Los Angeles CA 90089, USA, {singapur,
Towards Performance Modeling of 3D Memory Integrated FPGA Architectures Shreyas G. Singapura, Anand Panangadan and Viktor K. Prasanna University of Southern California, Los Angeles CA 90089, USA, {singapur,
Fast BVH Construction on GPUs
 Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Chapter 5: CPU Scheduling
 Chapter 5: CPU Scheduling Basic Concepts Scheduling Criteria Scheduling Algorithms Thread Scheduling Multiple-Processor Scheduling Operating Systems Examples Algorithm Evaluation Chapter 5: CPU Scheduling
Chapter 5: CPU Scheduling Basic Concepts Scheduling Criteria Scheduling Algorithms Thread Scheduling Multiple-Processor Scheduling Operating Systems Examples Algorithm Evaluation Chapter 5: CPU Scheduling
Energy Efficient Adaptive Beamforming on Sensor Networks
 Energy Efficient Adaptive Beamforming on Sensor Networks Viktor K. Prasanna Bhargava Gundala, Mitali Singh Dept. of EE-Systems University of Southern California email: prasanna@usc.edu http://ceng.usc.edu/~prasanna
Energy Efficient Adaptive Beamforming on Sensor Networks Viktor K. Prasanna Bhargava Gundala, Mitali Singh Dept. of EE-Systems University of Southern California email: prasanna@usc.edu http://ceng.usc.edu/~prasanna
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #8 2/7/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #8 2/7/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
Lecture: Storage, GPUs. Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4)
") Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Problem Statement. Algorithm MinDPQ (contd.) Algorithm MinDPQ. Summary of Algorithm MinDPQ. Algorithm MinDPQ: Experimental Results.
 Algorithm MinDPQ. Summary of Algorithm MinDPQ. Algorithm MinDPQ: Experimental Results.") Algorithms for Routing Lookups and Packet Classification October 3, 2000 High Level Outline Part I. Routing Lookups - Two lookup algorithms Part II. Packet Classification - One classification algorithm
Algorithms for Routing Lookups and Packet Classification October 3, 2000 High Level Outline Part I. Routing Lookups - Two lookup algorithms Part II. Packet Classification - One classification algorithm
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Accelerating String Matching Using Multi-threaded Algorithm
 Accelerating String Matching Using Multi-threaded Algorithm on GPU Cheng-Hung Lin*, Sheng-Yu Tsai**, Chen-Hsiung Liu**, Shih-Chieh Chang**, Jyuo-Min Shyu** *National Taiwan Normal University, Taiwan **National
Accelerating String Matching Using Multi-threaded Algorithm on GPU Cheng-Hung Lin*, Sheng-Yu Tsai**, Chen-Hsiung Liu**, Shih-Chieh Chang**, Jyuo-Min Shyu** *National Taiwan Normal University, Taiwan **National
CS 179: GPU Programming. Lecture 7
 CS 179: GPU Programming Lecture 7 Week 3 Goals: More involved GPU-accelerable algorithms Relevant hardware quirks CUDA libraries Outline GPU-accelerated: Reduction Prefix sum Stream compaction Sorting(quicksort)
CS 179: GPU Programming Lecture 7 Week 3 Goals: More involved GPU-accelerable algorithms Relevant hardware quirks CUDA libraries Outline GPU-accelerated: Reduction Prefix sum Stream compaction Sorting(quicksort)
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
A Hybrid Approach to CAM-Based Longest Prefix Matching for IP Route Lookup
 A Hybrid Approach to CAM-Based Longest Prefix Matching for IP Route Lookup Yan Sun and Min Sik Kim School of Electrical Engineering and Computer Science Washington State University Pullman, Washington
A Hybrid Approach to CAM-Based Longest Prefix Matching for IP Route Lookup Yan Sun and Min Sik Kim School of Electrical Engineering and Computer Science Washington State University Pullman, Washington
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors
 ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
A Software LDPC Decoder Implemented on a Many-Core Array of Programmable Processors
 A Software LDPC Decoder Implemented on a Many-Core Array of Programmable Processors Brent Bohnenstiehl and Bevan Baas Department of Electrical and Computer Engineering University of California, Davis {bvbohnen,
A Software LDPC Decoder Implemented on a Many-Core Array of Programmable Processors Brent Bohnenstiehl and Bevan Baas Department of Electrical and Computer Engineering University of California, Davis {bvbohnen,
OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI
 CMPE 655- MULTIPLE PROCESSOR SYSTEMS OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI What is MULTI PROCESSING?? Multiprocessing is the coordinated processing
CMPE 655- MULTIPLE PROCESSOR SYSTEMS OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI What is MULTI PROCESSING?? Multiprocessing is the coordinated processing
CSE 599 I Accelerated Computing - Programming GPUS. Memory performance
 CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
FPX Architecture for a Dynamically Extensible Router
 FPX Architecture for a Dynamically Extensible Router Alex Chandra, Yuhua Chen, John Lockwood, Sarang Dharmapurikar, Wenjing Tang, David Taylor, Jon Turner http://www.arl.wustl.edu/arl Dynamically Extensible
FPX Architecture for a Dynamically Extensible Router Alex Chandra, Yuhua Chen, John Lockwood, Sarang Dharmapurikar, Wenjing Tang, David Taylor, Jon Turner http://www.arl.wustl.edu/arl Dynamically Extensible
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
Topic & Scope. Content: The course gives
 Topic & Scope Content: The course gives an overview of network processor cards (architectures and use) an introduction of how to program Intel IXP network processors some ideas of how to use network processors
Topic & Scope Content: The course gives an overview of network processor cards (architectures and use) an introduction of how to program Intel IXP network processors some ideas of how to use network processors
DevoFlow: Scaling Flow Management for High Performance Networks
 DevoFlow: Scaling Flow Management for High Performance Networks SDN Seminar David Sidler 08.04.2016 1 Smart, handles everything Controller Control plane Data plane Dump, forward based on rules Existing
DevoFlow: Scaling Flow Management for High Performance Networks SDN Seminar David Sidler 08.04.2016 1 Smart, handles everything Controller Control plane Data plane Dump, forward based on rules Existing
Flow Caching for High Entropy Packet Fields
 Flow Caching for High Entropy Packet Fields Nick Shelly Nick McKeown! Ethan Jackson Teemu Koponen Jarno Rajahalme Outline Current flow classification in OVS Problems with high entropy packets Proposed
Flow Caching for High Entropy Packet Fields Nick Shelly Nick McKeown! Ethan Jackson Teemu Koponen Jarno Rajahalme Outline Current flow classification in OVS Problems with high entropy packets Proposed
Generic Polyphase Filterbanks with CUDA
 Generic Polyphase Filterbanks with CUDA Jan Krämer German Aerospace Center Communication and Navigation Satellite Networks Weßling 04.02.2017 Knowledge for Tomorrow www.dlr.de Slide 1 of 27 > Generic Polyphase
Generic Polyphase Filterbanks with CUDA Jan Krämer German Aerospace Center Communication and Navigation Satellite Networks Weßling 04.02.2017 Knowledge for Tomorrow www.dlr.de Slide 1 of 27 > Generic Polyphase
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Towards Effective Packet Classification. J. Li, Y. Qi, and B. Xu Network Security Lab RIIT, Tsinghua University Dec, 2005
 Towards Effective Packet Classification J. Li, Y. Qi, and B. Xu Network Security Lab RIIT, Tsinghua University Dec, 2005 Outline Algorithm Study Understanding Packet Classification Worst-case Complexity
Towards Effective Packet Classification J. Li, Y. Qi, and B. Xu Network Security Lab RIIT, Tsinghua University Dec, 2005 Outline Algorithm Study Understanding Packet Classification Worst-case Complexity
Stochastic Pre-Classification for SDN Data Plane Matching
 Stochastic Pre-Classification for SDN Data Plane Matching Luke McHale, C. Jasson Casey, Paul V. Gratz, Alex Sprintson Presenter: Luke McHale Ph.D. Student, Texas A&M University Contact: luke.mchale@tamu.edu
Stochastic Pre-Classification for SDN Data Plane Matching Luke McHale, C. Jasson Casey, Paul V. Gratz, Alex Sprintson Presenter: Luke McHale Ph.D. Student, Texas A&M University Contact: luke.mchale@tamu.edu
A Configurable Packet Classification Architecture for Software- Defined Networking
 A Configurable Packet Classification Architecture for Software- Defined Networking Guerra Pérez, K., Yang, X., Scott-Hayward, S., & Sezer, S. (2014). A Configurable Packet Classification Architecture for
A Configurable Packet Classification Architecture for Software- Defined Networking Guerra Pérez, K., Yang, X., Scott-Hayward, S., & Sezer, S. (2014). A Configurable Packet Classification Architecture for