Lecture 27: Multiprocessors. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs
|
|
|
- Nickolas Strickland
- 5 years ago
- Views:
Transcription
1 Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1
2 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model Communication is implicit and hardware handles protection Hardware-controlled caching Message-passing: No cache coherence simpler hardware Explicit communication easier for the programmer to restructure code Software-controlled caching Sender can initiate data transfer 2
3 Ocean Kernel Procedure Solve(A) begin diff = done = 0; while (!done) do diff = 0; for i 1 to n do for j 1 to n do temp = A[i,j]; A[i,j] 0.2 * (A[i,j] + neighbors); diff += abs(a[i,j] temp); end for end for if (diff < TOL) then done = 1; end while end procedure.. Row 1 Row k Row 2k Row 3k 3
4 Shared Address Space Model int n, nprocs; float **A, diff; LOCKDEC(diff_lock); BARDEC(bar1); main() begin read(n); read(nprocs); A G_MALLOC(); initialize (A); CREATE (nprocs,solve,a); WAIT_FOR_END (nprocs); end main procedure Solve(A) int i, j, pid, done=0; float temp, mydiff=0; int mymin = 1 + (pid * n/procs); int mymax = mymin + n/nprocs -1; while (!done) do mydiff = diff = 0; BARRIER(bar1,nprocs); for i mymin to mymax for j 1 to n do endfor endfor LOCK(diff_lock); diff += mydiff; UNLOCK(diff_lock); BARRIER (bar1, nprocs); if (diff < TOL) then done = 1; BARRIER (bar1, nprocs); endwhile 4
5 Message Passing Model main() read(n); read(nprocs); CREATE (nprocs-1, Solve); Solve(); WAIT_FOR_END (nprocs-1); procedure Solve() int i, j, pid, nn = n/nprocs, done=0; float temp, tempdiff, mydiff = 0; mya malloc( ) initialize(mya); while (!done) do mydiff = 0; if (pid!= 0) SEND(&myA[1,0], n, pid-1, ROW); if (pid!= nprocs-1) SEND(&myA[nn,0], n, pid+1, ROW); if (pid!= 0) RECEIVE(&myA[0,0], n, pid-1, ROW); if (pid!= nprocs-1) RECEIVE(&myA[nn+1,0], n, pid+1, ROW); for i 1 to nn do for j 1 to n do endfor endfor if (pid!= 0) SEND(mydiff, 1, 0, DIFF); RECEIVE(done, 1, 0, DONE); else for i 1 to nprocs-1 do RECEIVE(tempdiff, 1, *, DIFF); mydiff += tempdiff; endfor if (mydiff < TOL) done = 1; for i 1 to nprocs-1 do SEND(done, 1, I, DONE); endfor endif endwhile 5
6 Multithreading Within a Processor Until now, we have executed multiple threads of an application on different processors can multiple threads execute concurrently on the same processor? Why is this desireable? inexpensive one CPU, no external interconnects no remote or coherence misses (more capacity misses) Why does this make sense? most processors can t find enough work peak IPC is 6, average IPC is 1.5! threads can share resources we can increase threads without a corresponding linear increase in area 6
7 How are Resources Shared? Each box represents an issue slot for a functional unit. Peak thruput is 4 IPC. Thread 1 Thread 2 Cycles Thread 3 Thread 4 Superscalar Fine-Grained Multithreading Simultaneous Multithreading Idle Superscalar processor has high under-utilization not enough work every cycle, especially when there is a cache miss Fine-grained multithreading can only issue instructions from a single thread in a cycle can not find max work every cycle, but cache misses can be tolerated Simultaneous multithreading can issue instructions from any thread every cycle has the highest probability of finding work for every issue slot 7
8 Performance Implications of SMT Single thread performance is likely to go down (caches, branch predictors, registers, etc. are shared) this effect can be mitigated by trying to prioritize one thread With eight threads in a processor with many resources, SMT yields throughput improvements of roughly 2-4 8
9 SIMD Processors Single instruction, multiple data Such processors offer energy efficiency because a single instruction fetch can trigger many data operations Such data parallelism may be useful for many image/sound and numerical applications 9
10 GPUs Initially developed as graphics accelerators; now viewed as one of the densest compute engines available Many on-going efforts to run non-graphics workloads on GPUs, i.e., use them as general-purpose GPUs or GPGPUs C/C++ based programming platforms enable wider use of GPGPUs CUDA from NVidia and OpenCL from an industry consortium A heterogeneous system has a regular host CPU and a GPU that handles (say) CUDA code (they can both be on the same chip) 10
11 The GPU Architecture SIMT single instruction, multiple thread; a GPU has many SIMT cores A large data-parallel operation is partitioned into many thread blocks (one per SIMT core); a thread block is partitioned into many warps (one warp running at a time in the SIMT core); a warp is partitioned across many in-order pipelines (each is called a SIMD lane) A SIMT core can have multiple active warps at a time, i.e., the SIMT core stores the registers for each warp; warps can be context-switched at low cost; a warp scheduler keeps track of runnable warps and schedules a new warp if the currently running warp stalls 11
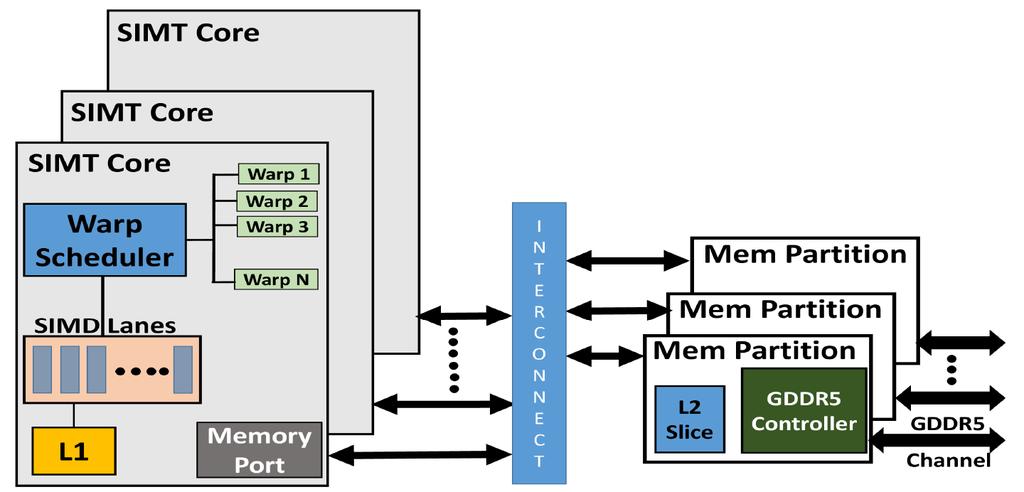
12 The GPU Architecture 12
13 Architecture Features Simple in-order pipelines that rely on thread-level parallelism to hide long latencies Many registers (~1K) per in-order pipeline (lane) to support many active warps When a branch is encountered, some of the lanes proceed along the then case depending on their data values; later, the other lanes evaluate the else case; a branch cuts the data-level parallelism by half (branch divergence) When a load/store is encountered, the requests from all lanes are coalesced into a few 128B cache line requests; each request may return at a different time (mem divergence) 13
14 GPU Memory Hierarchy Each SIMT core has a private L1 cache (shared by the warps on that core) A large L2 is shared by all SIMT cores; each L2 bank services a subset of all addresses Each L2 partition is connected to its own memory controller and memory channel The GDDR5 memory system runs at higher frequencies, and uses chips with more banks, wide IO, and better power delivery networks A portion of GDDR5 memory is private to the GPU and the rest is accessible to the host CPU (the GPU performs copies) 14
15 Title Bullet 15
Lecture 27: Pot-Pourri. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability
 GPUs Disks and reliability") Lecture 27: Pot-Pourri Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood
Lecture 27: Pot-Pourri Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood
Lecture 26: Multiprocessors. Today s topics: Synchronization Consistency Shared memory vs message-passing
 Lecture 26: Multiprocessors Today s topics: Synchronization Consistency Shared memory vs message-passing 1 Constructing Locks Applications have phases (consisting of many instructions) that must be executed
Lecture 26: Multiprocessors Today s topics: Synchronization Consistency Shared memory vs message-passing 1 Constructing Locks Applications have phases (consisting of many instructions) that must be executed
Lecture 18: Shared-Memory Multiprocessors. Topics: coherence protocols for symmetric shared-memory multiprocessors (Sections
 Lecture 18: Shared-Memory Multiprocessors Topics: coherence protocols for symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Ocean Kernel Procedure Solve(A) begin diff = done = 0; while (!done)
Lecture 18: Shared-Memory Multiprocessors Topics: coherence protocols for symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Ocean Kernel Procedure Solve(A) begin diff = done = 0; while (!done)
Lecture 17: Multiprocessors. Topics: multiprocessor intro and taxonomy, symmetric shared-memory multiprocessors (Sections )
") Lecture 17: Multiprocessors Topics: multiprocessor intro and taxonomy, symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Taxonomy SISD: single instruction and single data stream: uniprocessor
Lecture 17: Multiprocessors Topics: multiprocessor intro and taxonomy, symmetric shared-memory multiprocessors (Sections 4.1-4.2) 1 Taxonomy SISD: single instruction and single data stream: uniprocessor
Lecture 26: Multiprocessors. Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing
 Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture: Memory Technology Innovations
 Lecture: Memory Technology Innovations Topics: state-of-the-art and upcoming changes: buffer chips, 3D stacking, non-volatile cells, photonics Multiprocessor intro 1 Modern Memory System...... PROC.. 4
Lecture: Memory Technology Innovations Topics: state-of-the-art and upcoming changes: buffer chips, 3D stacking, non-volatile cells, photonics Multiprocessor intro 1 Modern Memory System...... PROC.. 4
Lecture: Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Memory, Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Modern Memory System...... PROC.. 4 DDR3 channels 64-bit data channels
Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Modern Memory System...... PROC.. 4 DDR3 channels 64-bit data channels
Lecture: Memory, Coherence Protocols. Topics: wrap-up of memory systems, intro to multi-thread programming models
 Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, intro to multi-thread programming models 1 Refresh Every DRAM cell must be refreshed within a 64 ms window A row read/write automatically
Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, intro to multi-thread programming models 1 Refresh Every DRAM cell must be refreshed within a 64 ms window A row read/write automatically
Lecture: Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Flynn's Classification
 Multiprocessors Oracles's SPARC M7-32 core, 64MB L3 cache (8 x 8 MB), 1.6TB/s. 256 KB of 4-way SA L2 ICache, 0.5 TB/s per cluster. 2 cores share 256 KB, 8-way SA L2 DCache, 0.5 TB/s. Flynn's Classification
Multiprocessors Oracles's SPARC M7-32 core, 64MB L3 cache (8 x 8 MB), 1.6TB/s. 256 KB of 4-way SA L2 ICache, 0.5 TB/s per cluster. 2 cores share 256 KB, 8-way SA L2 DCache, 0.5 TB/s. Flynn's Classification
Lecture 1: Introduction
 Lecture 1: Introduction ourse organization: 13 lectures on parallel architectures ~5 lectures on cache coherence, consistency ~3 lectures on TM ~2 lectures on interconnection networks ~2 lectures on large
Lecture 1: Introduction ourse organization: 13 lectures on parallel architectures ~5 lectures on cache coherence, consistency ~3 lectures on TM ~2 lectures on interconnection networks ~2 lectures on large
Lecture: Storage, GPUs. Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4)
") Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture 2: Parallel Programs. Topics: consistency, parallel applications, parallelization process
 Lecture 2: Parallel Programs Topics: consistency, parallel applications, parallelization process 1 Sequential Consistency A multiprocessor is sequentially consistent if the result of the execution is achievable
Lecture 2: Parallel Programs Topics: consistency, parallel applications, parallelization process 1 Sequential Consistency A multiprocessor is sequentially consistent if the result of the execution is achievable
Parallelization of an Example Program
 Parallelization of an Example Program [ 2.3] In this lecture, we will consider a parallelization of the kernel of the Ocean application. Goals: Illustrate parallel programming in a low-level parallel language.
Parallelization of an Example Program [ 2.3] In this lecture, we will consider a parallelization of the kernel of the Ocean application. Goals: Illustrate parallel programming in a low-level parallel language.
Simulating ocean currents
 Simulating ocean currents We will study a parallel application that simulates ocean currents. Goal: Simulate the motion of water currents in the ocean. Important to climate modeling. Motion depends on
Simulating ocean currents We will study a parallel application that simulates ocean currents. Goal: Simulate the motion of water currents in the ocean. Important to climate modeling. Motion depends on
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lecture: SMT, Cache Hierarchies. Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
ECE7660 Parallel Computer Architecture. Perspective on Parallel Programming
 ECE7660 Parallel Computer Architecture Perspective on Parallel Programming Outline Motivating Problems (application case studies) Process of creating a parallel program What a simple parallel program looks
ECE7660 Parallel Computer Architecture Perspective on Parallel Programming Outline Motivating Problems (application case studies) Process of creating a parallel program What a simple parallel program looks
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallelization Principles. Sathish Vadhiyar
 Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Parallelization Principles Sathish Vadhiyar Parallel Programming and Challenges Recall the advantages and motivation of parallelism But parallel programs incur overheads not seen in sequential programs
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Multiprocessors at Earth This lecture: How do we program such computers?
 Multiprocessors at IT/UPPMAX DARK 2 Programming of Multiprocessors Sverker Holmgren IT/Division of Scientific Computing Ra. 280 proc. Cluster with SM nodes Ngorongoro. 64 proc. SM (cc-numa) Debet&Kredit.
Multiprocessors at IT/UPPMAX DARK 2 Programming of Multiprocessors Sverker Holmgren IT/Division of Scientific Computing Ra. 280 proc. Cluster with SM nodes Ngorongoro. 64 proc. SM (cc-numa) Debet&Kredit.
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
RECAP. B649 Parallel Architectures and Programming
 RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Advanced Computer Architecture
 Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Fiscal Year 2018 Ver. 2019-01-24a Course number: CSC.T433 School of Computing, Graduate major in Computer Science Advanced Computer Architecture 11. Multi-Processor: Distributed Memory and Shared Memory
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
GPUs have enormous power that is enormously difficult to use
 524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
Lecture: Networks, Disks, Datacenters, GPUs. Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections
 Lecture: Networks, Disks, Datacenters, GPUs Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections 6.1-6.7, App D, Ch 4) 1 Packets/Flits A message is broken into multiple packets
Lecture: Networks, Disks, Datacenters, GPUs Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections 6.1-6.7, App D, Ch 4) 1 Packets/Flits A message is broken into multiple packets
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming. Lecturer: Alan Christopher
 Lecture 30: GP-GPU Programming. Lecturer: Alan Christopher") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming Lecturer: Alan Christopher Overview GP-GPU: What and why OpenCL, CUDA, and programming GPUs GPU Performance
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming Lecturer: Alan Christopher Overview GP-GPU: What and why OpenCL, CUDA, and programming GPUs GPU Performance
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
From Application to Technology OpenCL Application Processors Chung-Ho Chen
 From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
From Application to Technology OpenCL Application Processors Chung-Ho Chen Computer Architecture and System Laboratory (CASLab) Department of Electrical Engineering and Institute of Computer and Communication
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Programmer's View of Execution Teminology Summary
 CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPU Performance Optimisation. Alan Gray EPCC The University of Edinburgh
 GPU Performance Optimisation EPCC The University of Edinburgh Hardware NVIDIA accelerated system: Memory Memory GPU vs CPU: Theoretical Peak capabilities NVIDIA Fermi AMD Magny-Cours (6172) Cores 448 (1.15GHz)
GPU Performance Optimisation EPCC The University of Edinburgh Hardware NVIDIA accelerated system: Memory Memory GPU vs CPU: Theoretical Peak capabilities NVIDIA Fermi AMD Magny-Cours (6172) Cores 448 (1.15GHz)
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Analysis Report. Number of Multiprocessors 3 Multiprocessor Clock Rate Concurrent Kernel Max IPC 6 Threads per Warp 32 Global Memory Bandwidth
 Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Active thread Idle thread
 Active thread Idle thread") Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Lecture 11: OpenCL and Altera OpenCL. James C. Hoe Department of ECE Carnegie Mellon University
 18 643 Lecture 11: OpenCL and Altera OpenCL James C. Hoe Department of ECE Carnegie Mellon University 18 643 F17 L11 S1, James C. Hoe, CMU/ECE/CALCM, 2017 Housekeeping Your goal today: understand Altera
18 643 Lecture 11: OpenCL and Altera OpenCL James C. Hoe Department of ECE Carnegie Mellon University 18 643 F17 L11 S1, James C. Hoe, CMU/ECE/CALCM, 2017 Housekeeping Your goal today: understand Altera
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Handout 3. HSAIL and A SIMT GPU Simulator
 Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Administrivia. HW0 scores, HW1 peer-review assignments out. If you re having Cython trouble with HW2, let us know.
 Administrivia HW0 scores, HW1 peer-review assignments out. HW2 out, due Nov. 2. If you re having Cython trouble with HW2, let us know. Review on Wednesday: Post questions on Piazza Introduction to GPUs
Administrivia HW0 scores, HW1 peer-review assignments out. HW2 out, due Nov. 2. If you re having Cython trouble with HW2, let us know. Review on Wednesday: Post questions on Piazza Introduction to GPUs
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
EECS 470. Lecture 18. Simultaneous Multithreading. Fall 2018 Jon Beaumont
 Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Exploring GPU Architecture for N2P Image Processing Algorithms
 Exploring GPU Architecture for N2P Image Processing Algorithms Xuyuan Jin(0729183) x.jin@student.tue.nl 1. Introduction It is a trend that computer manufacturers provide multithreaded hardware that strongly
Exploring GPU Architecture for N2P Image Processing Algorithms Xuyuan Jin(0729183) x.jin@student.tue.nl 1. Introduction It is a trend that computer manufacturers provide multithreaded hardware that strongly
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
Review for Midterm 3/28/11. Administrative. Parts of Exam. Midterm Exam Monday, April 4. Midterm. Design Review. Final projects
 Administrative Midterm - In class April 4, open notes - Review notes, readings and review lecture (before break) - Will post prior exams Design Review - Intermediate assessment of progress on project,
Administrative Midterm - In class April 4, open notes - Review notes, readings and review lecture (before break) - Will post prior exams Design Review - Intermediate assessment of progress on project,
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
EECS 570 Final Exam - SOLUTIONS Winter 2015
 EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Preparing seismic codes for GPUs and other
 Preparing seismic codes for GPUs and other many-core architectures Paulius Micikevicius Developer Technology Engineer, NVIDIA 2010 SEG Post-convention Workshop (W-3) High Performance Implementations of
Preparing seismic codes for GPUs and other many-core architectures Paulius Micikevicius Developer Technology Engineer, NVIDIA 2010 SEG Post-convention Workshop (W-3) High Performance Implementations of
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2