A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang
|
|
|
- Edwina Gallagher
- 6 years ago
- Views:
Transcription
1 A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst
2 Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal matrices Σ: diagonal matrix Exact SVD can be computed in O(mn 2 ) time. 2
3 Introduction Approximate SVD A: m n matrix, whose intrinsic dimensionality is far less than n Usually sufficient to compute the k ( n) largest singular values and corresponding vectors. Approximate SVD can be solved in O(mnk) time ( compared to O(mn 2 ) for full svd). 3
4 Introduction Sample-based Approximate SVD Construct a basis V by directly sampling or taking linear combinations of rows from A. An approximate SVD can be extracted from the projection of A onto V. 4
5 Introduction Sample-based Approximate SVD Construct a basis V by directly sampling or taking linear combinations of rows from A. An approximate SVD can be extracted from the projection of A onto V. Sampling Methods Length-squared [Frieze et al. 2004, Deshpande et al. 2006] Random projection [Friedland et al 2006, Sarlos et al. 2006, Rokhlin et al. 2009] 5
6 Introduction QUIC-SVD [Holmes et al. NIPS 2008] Sampled-based approximate SVD. Progressively constructs a basis V using a cosine tree. Results have controllable L2 error basis construction adapts to the matrix and the desired error. 6


7 Our Goal Map QUIC-SVD onto the GPU (Graphics Processing Units) Powerful data-parallel computation platform. High computation density, high memory bandwidth. Relatively low-cost. NVIDIA GTX cores 1.6 Tera FLOPs 3 GB memory 200 GB/s bandwidth $549 7
8 Related Work OpenGL-based: rasterization, framebuffers, shaders [Galoppo et al. 2005] [Bondhugula et al. 2006] CUDA-based: Matrix factorizations [Volkov et al. 2008] QR decomposition [Kerr et al. 2009] SVD [Lahabar et al. 2009] Commercial GPU linear algebra package [CULA 2010] 8
9 Our Work A CUDA implementation of QUIC-SVD. Up to 6~7 times speedup over an optimized CPU version. A partitioned version that can process large, out-ofcore matrices on a single GPU The largest we tested are 22,000 x 22,000 matrices (double precision FP). 9

10 Overview of QUIC-SVD [Holmes et al. 2008] A V 10
11 Overview of QUIC-SVD [Holmes et al. 2008] A Start from a root node that owns the entire matrix (all rows). 11
12 Overview of QUIC-SVD [Holmes et al. 2008] A pivot row Select a pivot row by importance sampling the squared magnitudes of the rows. 12
13 Overview of QUIC-SVD [Holmes et al. 2008] A pivot row Compute inner product of every row with the pivot row. (this is why it s called Cosine Tree) 13
14 Overview of QUIC-SVD [Holmes et al. 2008] A Closer to zero The rest Based on the inner products, the rows are partitioned into 2 subsets, each represented by a child node. 14
 of each subset; add it to the")
15 Overview of QUIC-SVD [Holmes et al. 2008] A V Compute the row mean (average) of each subset; add it to the current basis set (keep orthogonalized). 15

16 Overview of QUIC-SVD [Holmes et al. 2008] A V Repeat, until the estimated L2 error is below a threshold. The basis set now provides a good low-rank approximation. 16
17 Overview of QUIC-SVD Monte Carlo Error Estimation: Input: any subset of rows A s, the basis V, δ [0,1] Output: estimated, s.t. with probability at least 1 δ, the L2 error: Termination Criteria: 17
18 Overview of QUIC-SVD 5 Steps: 1. Select a leaf node with maximum estimated L2 error; 2. Split the node and create two child nodes; 3. Calculate and insert the mean vector of each child to the basis set V (replacing the parent vector), orthogonalized; 4. Estimate the error of newly added child nodes; 5. Repeat steps 1 4 until the termination criteria is satisfied. 18
19 GPU Implementation of QUIC-SVD Computation cost mostly on constructing the tree. Most expensive steps: Computing vector inner products and row means Basis orthogonalization 19
20 Parallelize Vector Inner Products and Row Means Compute all inner products and row means in parallel. Assume a large matrix, there are sufficient number of rows to engage all GPU threads. An index array is used to point to the physical rows. 20
21 Parallelize Gram Schmidt Orthogonalization Classical Gram Schmidt: Assume v1, v2, v3... vn are in the current basis set (i.e. they are orthonormal vectors), to add a new vector : v (, ) (, )... (, ) r 1 r where proj( r, v) ( r v) v r r proj r v1 proj r v2 proj r v n n This is easy to parallelize (as each projection is independently calculated), but it has poor numerical stability. r 21
22 Parallelize Gram Schmidt Orthogonalization Modified Gram Schmidt: r r proj( r, v ), 1 1 r r proj( r, v ), r r r proj( r, v ) v r r n 1 k k 1 k 1 k This has good numerical stability, but is hard to parallelize, as the computation is sequential! 22
23 Parallelize Gram Schmidt Orthogonalization Our approach: Blocked Gram Schmidt (1) v v proj v u1 proj v u2 proj v um (, ) (, )... (, ) v v proj( v, u ) proj( v, u )... proj( v, u ) (2) (1) (1) (1) (1) m 1 m 2 2m... u v proj( v, u ) proj( v, u )... proj( v, u ) ( n/ m) ( n/ m) ( n/ m) ( n/ m) k 1 2m 1 2m 2 k This hybrid approach combines the advantages of the previous two numerically stable, and GPU-friendly. 23
24 Extract the Final Result Input: matrix A, basis set V Output: U, Σ, V, the best approximate SVD of A within the subspace V. Algorithm: Compute AV, then (AV) T AV, and SVD U Σ V T = (AV) T AV Let V = VV, Σ = (Σ ) 1/2, U = (AV)V Σ 1, Return U, Σ, V. 24
 T AV, and SVD U Σ V T = (AV) T AV Let V = VV, Σ = (Σ ) 1/2, U = (AV)V Σ 1, Return U, Σ, V.")
25 Extract the Final Result Input: matrix A, subspace basis V Output: U, Σ, V, the best approximate SVD of A within the subspace V. Algorithm: Compute AV, then (AV) T AV, and SVD U Σ V T = (AV) T AV Let V = VV, Σ = (Σ ) 1/2, U = (AV)V Σ 1, Return U, Σ, V. SVD of a k k matrix. 25
26 Partitioned QUIC-SVD The advantage of the GPU is only obvious for largescale problems, e.g. matrices larger than 10, For dense matrices, this will soon become an out-ofcore problem. We modified our algorithm to use a matrix partitioning scheme, so that each partition can fit in GPU memory. 26
27 Partitioned QUIC-SVD Partition the matrix into fixed-size blocks A 1 A 2 A s 27


28 Partitioned QUIC-SVD Partition the matrix into fixed-size blocks A 1 A 2 A s 28

29 Partitioned QUIC-SVD 29
30 Partitioned QUIC-SVD Termination Criteria is guaranteed: 30
31 Implementation Details Main implementation done in CUDA. Use CULA library to extract the final SVD (this involves processing a k k matrix, where k n). Selection of the splitting node is done using a priority queue, maintained on the CPU side. Source code will be made available on our site 31
32 Performance Test environment: CPU: Intel Core i GHz (8 HTs), 6 GB memory GPU: NVIDIA GTX 480 GPU Test data: Given a rank k and matrix size n, we generate a n k left matrix and k n right matrix, both filled with random numbers; the product of the two gives the test matrix. Result accuracy: Both CPU and GPU versions use double floats; termination error ε = 10 12, Monte Carlo estimation δ =
33 Performance Comparisons: 1. Matlab s svds; 2. CPU-based QUIC-SVD (optimized, multi-threaded, implemented using Intel Math Kernel Library); 3. GPU-based QUIC-SVD. 4. Tygert SVD (approximate SVD algorithm, implemented in Matlab, based on random projection); 33

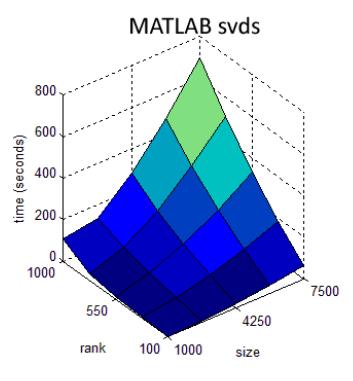
34 Performance Running Time 34
35 Performance Speedup Factors 35

36 Performance Speedup Factors 36


37 Performance CPU vs. GPU QUIC-SVD Running Time Speedup 37


38 Performance GPU QUIC-SVD vs. Tygert SVD Running Time Speedup 38

39 Integration with Manifold Alignment Framework 39
40 Conclusion A fast GPU-based implementation of an approximate SVD algorithm. Reasonable (up to 6~7 ) speedup over an optimized CPU implementation, and Tygert SVD. Our partitioned version allows processing out-of-core matrices. 40
41 Future Work Be able to process sparse matrices. Application in solving large graph Laplacians. Components from this project can become building blocks for other algorithms: random projection trees, diffusion wavelets etc. 41
42 Acknowledgement Alexander Gray PPAM reviewers NSF Grant FODAVA
Modern GPUs (Graphics Processing Units)
") Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX 580 512 cores 1.6 Tera FLOPs 1.5 GB
Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX 580 512 cores 1.6 Tera FLOPs 1.5 GB
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
An Approximate Singular Value Decomposition of Large Matrices in Julia
 An Approximate Singular Value Decomposition of Large Matrices in Julia Alexander J. Turner 1, 1 Harvard University, School of Engineering and Applied Sciences, Cambridge, MA, USA. In this project, I implement
An Approximate Singular Value Decomposition of Large Matrices in Julia Alexander J. Turner 1, 1 Harvard University, School of Engineering and Applied Sciences, Cambridge, MA, USA. In this project, I implement
QUIC-SVD: Fast SVD Using Cosine Trees
 QUIC-SVD: Fast SVD Using Cosine Trees Michael P. Holmes, Alexander G. Gray and Charles Lee Isbell, Jr. College of Computing Georgia Tech Atlanta, GA 3327 {mph, agray, isbell}@cc.gatech.edu Abstract The
QUIC-SVD: Fast SVD Using Cosine Trees Michael P. Holmes, Alexander G. Gray and Charles Lee Isbell, Jr. College of Computing Georgia Tech Atlanta, GA 3327 {mph, agray, isbell}@cc.gatech.edu Abstract The
CALCULATING RANKS, NULL SPACES AND PSEUDOINVERSE SOLUTIONS FOR SPARSE MATRICES USING SPQR
 CALCULATING RANKS, NULL SPACES AND PSEUDOINVERSE SOLUTIONS FOR SPARSE MATRICES USING SPQR Leslie Foster Department of Mathematics, San Jose State University October 28, 2009, SIAM LA 09 DEPARTMENT OF MATHEMATICS,
CALCULATING RANKS, NULL SPACES AND PSEUDOINVERSE SOLUTIONS FOR SPARSE MATRICES USING SPQR Leslie Foster Department of Mathematics, San Jose State University October 28, 2009, SIAM LA 09 DEPARTMENT OF MATHEMATICS,
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
A MATLAB Interface to the GPU
 Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Matrix algorithms: fast, stable, communication-optimizing random?!
 Matrix algorithms: fast, stable, communication-optimizing random?! Ioana Dumitriu Department of Mathematics University of Washington (Seattle) Joint work with Grey Ballard, James Demmel, Olga Holtz, Robert
Matrix algorithms: fast, stable, communication-optimizing random?! Ioana Dumitriu Department of Mathematics University of Washington (Seattle) Joint work with Grey Ballard, James Demmel, Olga Holtz, Robert
A comparison of parallel rank-structured solvers
 A comparison of parallel rank-structured solvers François-Henry Rouet Livermore Software Technology Corporation, Lawrence Berkeley National Laboratory Joint work with: - LSTC: J. Anton, C. Ashcraft, C.
A comparison of parallel rank-structured solvers François-Henry Rouet Livermore Software Technology Corporation, Lawrence Berkeley National Laboratory Joint work with: - LSTC: J. Anton, C. Ashcraft, C.
LSRN: A Parallel Iterative Solver for Strongly Over- or Under-Determined Systems
 LSRN: A Parallel Iterative Solver for Strongly Over- or Under-Determined Systems Xiangrui Meng Joint with Michael A. Saunders and Michael W. Mahoney Stanford University June 19, 2012 Meng, Saunders, Mahoney
LSRN: A Parallel Iterative Solver for Strongly Over- or Under-Determined Systems Xiangrui Meng Joint with Michael A. Saunders and Michael W. Mahoney Stanford University June 19, 2012 Meng, Saunders, Mahoney
Recognition, SVD, and PCA
 Recognition, SVD, and PCA Recognition Suppose you want to find a face in an image One possibility: look for something that looks sort of like a face (oval, dark band near top, dark band near bottom) Another
Recognition, SVD, and PCA Recognition Suppose you want to find a face in an image One possibility: look for something that looks sort of like a face (oval, dark band near top, dark band near bottom) Another
Large-Scale Face Manifold Learning
 Large-Scale Face Manifold Learning Sanjiv Kumar Google Research New York, NY * Joint work with A. Talwalkar, H. Rowley and M. Mohri 1 Face Manifold Learning 50 x 50 pixel faces R 2500 50 x 50 pixel random
Large-Scale Face Manifold Learning Sanjiv Kumar Google Research New York, NY * Joint work with A. Talwalkar, H. Rowley and M. Mohri 1 Face Manifold Learning 50 x 50 pixel faces R 2500 50 x 50 pixel random
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
The Singular Value Decomposition: Let A be any m n matrix. orthogonal matrices U, V and a diagonal matrix Σ such that A = UΣV T.
 Section 7.4 Notes (The SVD) The Singular Value Decomposition: Let A be any m n matrix. orthogonal matrices U, V and a diagonal matrix Σ such that Then there are A = UΣV T Specifically: The ordering of
Section 7.4 Notes (The SVD) The Singular Value Decomposition: Let A be any m n matrix. orthogonal matrices U, V and a diagonal matrix Σ such that Then there are A = UΣV T Specifically: The ordering of
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
A MATLAB Interface to the GPU
 A MATLAB Interface to the GPU Second Winter School Geilo, Norway André Rigland Brodtkorb SINTEF ICT Department of Applied Mathematics 2007-01-24 Outline 1 Motivation and previous
A MATLAB Interface to the GPU Second Winter School Geilo, Norway André Rigland Brodtkorb SINTEF ICT Department of Applied Mathematics 2007-01-24 Outline 1 Motivation and previous
Exploiting the Graphics Hardware to solve two compute intensive problems: Singular Value Decomposition and Ray Tracing Parametric Patches
 Exploiting the Graphics Hardware to solve two compute intensive problems: Singular Value Decomposition and Ray Tracing Parametric Patches Thesis submitted in partial fulfillment of the requirements for
Exploiting the Graphics Hardware to solve two compute intensive problems: Singular Value Decomposition and Ray Tracing Parametric Patches Thesis submitted in partial fulfillment of the requirements for
Math 2B Linear Algebra Test 2 S13 Name Write all responses on separate paper. Show your work for credit.
 Math 2B Linear Algebra Test 2 S3 Name Write all responses on separate paper. Show your work for credit.. Construct a matrix whose a. null space consists of all combinations of (,3,3,) and (,2,,). b. Left
Math 2B Linear Algebra Test 2 S3 Name Write all responses on separate paper. Show your work for credit.. Construct a matrix whose a. null space consists of all combinations of (,3,3,) and (,2,,). b. Left
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors
 Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Maths for Signals and Systems Linear Algebra in Engineering. Some problems by Gilbert Strang
 Maths for Signals and Systems Linear Algebra in Engineering Some problems by Gilbert Strang Problems. Consider u, v, w to be non-zero vectors in R 7. These vectors span a vector space. What are the possible
Maths for Signals and Systems Linear Algebra in Engineering Some problems by Gilbert Strang Problems. Consider u, v, w to be non-zero vectors in R 7. These vectors span a vector space. What are the possible
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
(Creating Arrays & Matrices) Applied Linear Algebra in Geoscience Using MATLAB
 Applied Linear Algebra in Geoscience Using MATLAB") Applied Linear Algebra in Geoscience Using MATLAB (Creating Arrays & Matrices) Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional
Applied Linear Algebra in Geoscience Using MATLAB (Creating Arrays & Matrices) Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional
Fast Algorithms for Regularized Minimum Norm Solutions to Inverse Problems
 Fast Algorithms for Regularized Minimum Norm Solutions to Inverse Problems Irina F. Gorodnitsky Cognitive Sciences Dept. University of California, San Diego La Jolla, CA 9293-55 igorodni@ece.ucsd.edu Dmitry
Fast Algorithms for Regularized Minimum Norm Solutions to Inverse Problems Irina F. Gorodnitsky Cognitive Sciences Dept. University of California, San Diego La Jolla, CA 9293-55 igorodni@ece.ucsd.edu Dmitry
Sparse LU Factorization for Parallel Circuit Simulation on GPUs
 Department of Electronic Engineering, Tsinghua University Sparse LU Factorization for Parallel Circuit Simulation on GPUs Ling Ren, Xiaoming Chen, Yu Wang, Chenxi Zhang, Huazhong Yang Nano-scale Integrated
Department of Electronic Engineering, Tsinghua University Sparse LU Factorization for Parallel Circuit Simulation on GPUs Ling Ren, Xiaoming Chen, Yu Wang, Chenxi Zhang, Huazhong Yang Nano-scale Integrated
Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU
 Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU Lifan Xu Wei Wang Marco A. Alvarez John Cavazos Dongping Zhang Department of Computer and Information Science University of Delaware
Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU Lifan Xu Wei Wang Marco A. Alvarez John Cavazos Dongping Zhang Department of Computer and Information Science University of Delaware
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
AMS 148: Chapter 1: What is Parallelization
 AMS 148: Chapter 1: What is Parallelization 1 Introduction of Parallelism Traditional codes and algorithms, much of what you, the student, have experienced previously has been computation in a sequential
AMS 148: Chapter 1: What is Parallelization 1 Introduction of Parallelism Traditional codes and algorithms, much of what you, the student, have experienced previously has been computation in a sequential
The Fast Multipole Method on NVIDIA GPUs and Multicore Processors
 The Fast Multipole Method on NVIDIA GPUs and Multicore Processors Toru Takahashi, a Cris Cecka, b Eric Darve c a b c Department of Mechanical Science and Engineering, Nagoya University Institute for Applied
The Fast Multipole Method on NVIDIA GPUs and Multicore Processors Toru Takahashi, a Cris Cecka, b Eric Darve c a b c Department of Mechanical Science and Engineering, Nagoya University Institute for Applied
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Administrative Issues. L11: Sparse Linear Algebra on GPUs. Triangular Solve (STRSM) A Few Details 2/25/11. Next assignment, triangular solve
 A Few Details 2/25/11. Next assignment, triangular solve") Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Unsupervised learning in Vision
 Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Outline. Parallel Algorithms for Linear Algebra. Number of Processors and Problem Size. Speedup and Efficiency
 1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
Dense Matrix Algorithms
 Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Communication-Avoiding QR Decomposition for GPUs
 Communication-Avoiding QR Decomposition for GPUs Michael Anderson, Grey Ballard, James Demmel and Kurt Keutzer UC Berkeley: Department of Electrical Engineering and Computer Science Berkeley, CA USA {mjanders,ballard,demmel,keutzer}@cs.berkeley.edu
Communication-Avoiding QR Decomposition for GPUs Michael Anderson, Grey Ballard, James Demmel and Kurt Keutzer UC Berkeley: Department of Electrical Engineering and Computer Science Berkeley, CA USA {mjanders,ballard,demmel,keutzer}@cs.berkeley.edu
Computational Methods in Statistics with Applications A Numerical Point of View. Large Data Sets. L. Eldén. March 2016
 Computational Methods in Statistics with Applications A Numerical Point of View L. Eldén SeSe March 2016 Large Data Sets IDA Machine Learning Seminars, September 17, 2014. Sequential Decision Making: Experiment
Computational Methods in Statistics with Applications A Numerical Point of View L. Eldén SeSe March 2016 Large Data Sets IDA Machine Learning Seminars, September 17, 2014. Sequential Decision Making: Experiment
Accelerating GPU Kernels for Dense Linear Algebra
 Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
Accelerating GPU Kernels for Dense Linear Algebra Rajib Nath, Stan Tomov, and Jack Dongarra Innovative Computing Lab University of Tennessee, Knoxville July 9, 21 xgemm performance of CUBLAS-2.3 on GTX28
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU
 Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy
 On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy Jan Verschelde joint with Genady Yoffe and Xiangcheng Yu University of Illinois at Chicago Department of Mathematics, Statistics,
On Massively Parallel Algorithms to Track One Path of a Polynomial Homotopy Jan Verschelde joint with Genady Yoffe and Xiangcheng Yu University of Illinois at Chicago Department of Mathematics, Statistics,
Determinant Computation on the GPU using the Condensation AMMCS Method / 1
 Determinant Computation on the GPU using the Condensation Method Sardar Anisul Haque Marc Moreno Maza Ontario Research Centre for Computer Algebra University of Western Ontario, London, Ontario AMMCS 20,
Determinant Computation on the GPU using the Condensation Method Sardar Anisul Haque Marc Moreno Maza Ontario Research Centre for Computer Algebra University of Western Ontario, London, Ontario AMMCS 20,
Automatic Development of Linear Algebra Libraries for the Tesla Series
 Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Contents. Implementing the QR factorization The algebraic eigenvalue problem. Applied Linear Algebra in Geoscience Using MATLAB
 Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Applied Linear Algebra in Geoscience Using MATLAB Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional Plots Programming in
Data Structures and Algorithms for Counting Problems on Graphs using GPU
 International Journal of Networking and Computing www.ijnc.org ISSN 85-839 (print) ISSN 85-847 (online) Volume 3, Number, pages 64 88, July 3 Data Structures and Algorithms for Counting Problems on Graphs
International Journal of Networking and Computing www.ijnc.org ISSN 85-839 (print) ISSN 85-847 (online) Volume 3, Number, pages 64 88, July 3 Data Structures and Algorithms for Counting Problems on Graphs
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
SIFT Descriptor Extraction on the GPU for Large-Scale Video Analysis. Hannes Fassold, Jakub Rosner
 SIFT Descriptor Extraction on the GPU for Large-Scale Video Analysis Hannes Fassold, Jakub Rosner 2014-03-26 2 Overview GPU-activities @ AVM research group SIFT descriptor extraction Algorithm GPU implementation
SIFT Descriptor Extraction on the GPU for Large-Scale Video Analysis Hannes Fassold, Jakub Rosner 2014-03-26 2 Overview GPU-activities @ AVM research group SIFT descriptor extraction Algorithm GPU implementation
Unrolling parallel loops
 Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
Unrolling parallel loops Vasily Volkov UC Berkeley November 14, 2011 1 Today Very simple optimization technique Closely resembles loop unrolling Widely used in high performance codes 2 Mapping to GPU:
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
8. Hardware-Aware Numerics. Approaching supercomputing...
 Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 48 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 48 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC
 GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
8. Hardware-Aware Numerics. Approaching supercomputing...
 Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 22 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 22 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
Randomization Algorithm to Compute Low-Rank Approximation
 Randomization Algorithm to Compute Low-Rank Approximation Ru HAN The Chinese University of Hong Kong hanru0905@gmail.com August 4, 2017 1. Background A low-rank representation of a matrix provides a powerful
Randomization Algorithm to Compute Low-Rank Approximation Ru HAN The Chinese University of Hong Kong hanru0905@gmail.com August 4, 2017 1. Background A low-rank representation of a matrix provides a powerful
Principal Component Analysis for Distributed Data
 Principal Component Analysis for Distributed Data David Woodruff IBM Almaden Based on works with Ken Clarkson, Ravi Kannan, and Santosh Vempala Outline 1. What is low rank approximation? 2. How do we solve
Principal Component Analysis for Distributed Data David Woodruff IBM Almaden Based on works with Ken Clarkson, Ravi Kannan, and Santosh Vempala Outline 1. What is low rank approximation? 2. How do we solve
Fast BVH Construction on GPUs
 Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Numerical Linear Algebra
 Numerical Linear Algebra Probably the simplest kind of problem. Occurs in many contexts, often as part of larger problem. Symbolic manipulation packages can do linear algebra "analytically" (e.g. Mathematica,
Numerical Linear Algebra Probably the simplest kind of problem. Occurs in many contexts, often as part of larger problem. Symbolic manipulation packages can do linear algebra "analytically" (e.g. Mathematica,
Comparing Hybrid CPU-GPU and Native GPU-only Acceleration for Linear Algebra. Mark Gates, Stan Tomov, Azzam Haidar SIAM LA Oct 29, 2015
 Comparing Hybrid CPU-GPU and Native GPU-only Acceleration for Linear Algebra Mark Gates, Stan Tomov, Azzam Haidar SIAM LA Oct 29, 2015 Overview Dense linear algebra algorithms Hybrid CPU GPU implementation
Comparing Hybrid CPU-GPU and Native GPU-only Acceleration for Linear Algebra Mark Gates, Stan Tomov, Azzam Haidar SIAM LA Oct 29, 2015 Overview Dense linear algebra algorithms Hybrid CPU GPU implementation
High-Performance Packet Classification on GPU
 High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California 1 Outline Introduction
High-Performance Packet Classification on GPU Shijie Zhou, Shreyas G. Singapura, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California 1 Outline Introduction
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors
 Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
MTH309 Linear Algebra: Maple Guide
 MTH309 Linear Algebra: Maple Guide Section 1. Row Echelon Form (REF) and Reduced Row Echelon Form (RREF) Example. Calculate the REF and RREF of the matrix Solution. Use the following command to insert
MTH309 Linear Algebra: Maple Guide Section 1. Row Echelon Form (REF) and Reduced Row Echelon Form (RREF) Example. Calculate the REF and RREF of the matrix Solution. Use the following command to insert
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
Image Compression using Singular Value Decomposition
 Applications of Linear Algebra 1/41 Image Compression using Singular Value Decomposition David Richards and Adam Abrahamsen Introduction The Singular Value Decomposition is a very important process. In
Applications of Linear Algebra 1/41 Image Compression using Singular Value Decomposition David Richards and Adam Abrahamsen Introduction The Singular Value Decomposition is a very important process. In
A Scalable, Numerically Stable, High- Performance Tridiagonal Solver for GPUs. Li-Wen Chang, Wen-mei Hwu University of Illinois
 A Scalable, Numerically Stable, High- Performance Tridiagonal Solver for GPUs Li-Wen Chang, Wen-mei Hwu University of Illinois A Scalable, Numerically Stable, High- How to Build a gtsv for Performance
A Scalable, Numerically Stable, High- Performance Tridiagonal Solver for GPUs Li-Wen Chang, Wen-mei Hwu University of Illinois A Scalable, Numerically Stable, High- How to Build a gtsv for Performance
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
Technical Report Performance Analysis of CULA on different NVIDIA GPU Architectures. Prateek Gupta
 Technical Report 2014-02 Performance Analysis of CULA on different NVIDIA GPU Architectures Prateek Gupta May 20, 2014 1 Spring 2014: Performance Analysis of CULA on different NVIDIA GPU Architectures
Technical Report 2014-02 Performance Analysis of CULA on different NVIDIA GPU Architectures Prateek Gupta May 20, 2014 1 Spring 2014: Performance Analysis of CULA on different NVIDIA GPU Architectures
Sparse Matrices in Image Compression
 Chapter 5 Sparse Matrices in Image Compression 5. INTRODUCTION With the increase in the use of digital image and multimedia data in day to day life, image compression techniques have become a major area
Chapter 5 Sparse Matrices in Image Compression 5. INTRODUCTION With the increase in the use of digital image and multimedia data in day to day life, image compression techniques have become a major area
Johnson-Lindenstrauss Lemma, Random Projection, and Applications
 Johnson-Lindenstrauss Lemma, Random Projection, and Applications Hu Ding Computer Science and Engineering, Michigan State University JL-Lemma The original version: Given a set P of n points in R d, let
Johnson-Lindenstrauss Lemma, Random Projection, and Applications Hu Ding Computer Science and Engineering, Michigan State University JL-Lemma The original version: Given a set P of n points in R d, let
GPGPU. Peter Laurens 1st-year PhD Student, NSC
 GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
A Multi-Tiered Optimization Framework for Heterogeneous Computing
 A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
Sampling Using GPU Accelerated Sparse Hierarchical Models
 Sampling Using GPU Accelerated Sparse Hierarchical Models Miroslav Stoyanov Oak Ridge National Laboratory supported by Exascale Computing Project (ECP) exascaleproject.org April 9, 28 Miroslav Stoyanov
Sampling Using GPU Accelerated Sparse Hierarchical Models Miroslav Stoyanov Oak Ridge National Laboratory supported by Exascale Computing Project (ECP) exascaleproject.org April 9, 28 Miroslav Stoyanov
DECOMPOSITION is one of the important subjects in
 Proceedings of the Federated Conference on Computer Science and Information Systems pp. 561 565 ISBN 978-83-60810-51-4 Analysis and Comparison of QR Decomposition Algorithm in Some Types of Matrix A. S.
Proceedings of the Federated Conference on Computer Science and Information Systems pp. 561 565 ISBN 978-83-60810-51-4 Analysis and Comparison of QR Decomposition Algorithm in Some Types of Matrix A. S.
Acceleration of Hessenberg Reduction for Nonsymmetric Matrix
 Acceleration of Hessenberg Reduction for Nonsymmetric Matrix by Hesamaldin Nekouei Bachelor of Science Degree in Electrical Engineering Iran University of Science and Technology, Iran, 2009 A thesis presented
Acceleration of Hessenberg Reduction for Nonsymmetric Matrix by Hesamaldin Nekouei Bachelor of Science Degree in Electrical Engineering Iran University of Science and Technology, Iran, 2009 A thesis presented
Fast Tridiagonal Solvers on GPU
 Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement
 Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement Tim Davis (Texas A&M University) with Sanjay Ranka, Mohamed Gadou (University of Florida) Nuri Yeralan (Microsoft) NVIDIA
Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement Tim Davis (Texas A&M University) with Sanjay Ranka, Mohamed Gadou (University of Florida) Nuri Yeralan (Microsoft) NVIDIA
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU
 April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
Diffusion Wavelets for Natural Image Analysis
 Diffusion Wavelets for Natural Image Analysis Tyrus Berry December 16, 2011 Contents 1 Project Description 2 2 Introduction to Diffusion Wavelets 2 2.1 Diffusion Multiresolution............................
Diffusion Wavelets for Natural Image Analysis Tyrus Berry December 16, 2011 Contents 1 Project Description 2 2 Introduction to Diffusion Wavelets 2 2.1 Diffusion Multiresolution............................
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
A GPU Sparse Direct Solver for AX=B
 1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms
 FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan
FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan
A GPU Implementation of a Jacobi Method for Lattice Basis Reduction
 A GPU Implementation of a Jacobi Method for Lattice Basis Reduction Filip Jeremic and Sanzheng Qiao Department of Computing and Software McMaster University Hamilton, Ontario, Canada June 25, 2013 Abstract
A GPU Implementation of a Jacobi Method for Lattice Basis Reduction Filip Jeremic and Sanzheng Qiao Department of Computing and Software McMaster University Hamilton, Ontario, Canada June 25, 2013 Abstract
Implementing Randomized Matrix Algorithms in Parallel and Distributed Environments
 Implementing Randomized Matrix Algorithms in Parallel and Distributed Environments Jiyan Yang ICME, Stanford University Nov 1, 2015 INFORMS 2015, Philadephia Joint work with Xiangrui Meng (Databricks),
Implementing Randomized Matrix Algorithms in Parallel and Distributed Environments Jiyan Yang ICME, Stanford University Nov 1, 2015 INFORMS 2015, Philadephia Joint work with Xiangrui Meng (Databricks),
A Kernel-independent Adaptive Fast Multipole Method
 A Kernel-independent Adaptive Fast Multipole Method Lexing Ying Caltech Joint work with George Biros and Denis Zorin Problem Statement Given G an elliptic PDE kernel, e.g. {x i } points in {φ i } charges
A Kernel-independent Adaptive Fast Multipole Method Lexing Ying Caltech Joint work with George Biros and Denis Zorin Problem Statement Given G an elliptic PDE kernel, e.g. {x i } points in {φ i } charges
Abstract. Introduction. Kevin Todisco
 - Kevin Todisco Figure 1: A large scale example of the simulation. The leftmost image shows the beginning of the test case, and shows how the fluid refracts the environment around it. The middle image
- Kevin Todisco Figure 1: A large scale example of the simulation. The leftmost image shows the beginning of the test case, and shows how the fluid refracts the environment around it. The middle image
Fast Multiscale Algorithms for Information Representation and Fusion
 Prepared for: Office of Naval Research Fast Multiscale Algorithms for Information Representation and Fusion No. 2 Devasis Bassu, Principal Investigator Contract: N00014-10-C-0176 Telcordia Technologies
Prepared for: Office of Naval Research Fast Multiscale Algorithms for Information Representation and Fusion No. 2 Devasis Bassu, Principal Investigator Contract: N00014-10-C-0176 Telcordia Technologies
Applications Video Surveillance (On-line or off-line)
") Face Face Recognition: Dimensionality Reduction Biometrics CSE 190-a Lecture 12 CSE190a Fall 06 CSE190a Fall 06 Face Recognition Face is the most common biometric used by humans Applications range from
Face Face Recognition: Dimensionality Reduction Biometrics CSE 190-a Lecture 12 CSE190a Fall 06 CSE190a Fall 06 Face Recognition Face is the most common biometric used by humans Applications range from
Fast Multipole and Related Algorithms
 Fast Multipole and Related Algorithms Ramani Duraiswami University of Maryland, College Park http://www.umiacs.umd.edu/~ramani Joint work with Nail A. Gumerov Efficiency by exploiting symmetry and A general
Fast Multipole and Related Algorithms Ramani Duraiswami University of Maryland, College Park http://www.umiacs.umd.edu/~ramani Joint work with Nail A. Gumerov Efficiency by exploiting symmetry and A general
An Eigenspace Update Algorithm for Image Analysis
 An Eigenspace Update Algorithm for Image Analysis S. Chandrasekaran, B.S. Manjunath, Y.F. Wang, J. Winkeler, and H. Zhang Department of Computer Science Department of Electrical and Computer Engineering
An Eigenspace Update Algorithm for Image Analysis S. Chandrasekaran, B.S. Manjunath, Y.F. Wang, J. Winkeler, and H. Zhang Department of Computer Science Department of Electrical and Computer Engineering
Height field ambient occlusion using CUDA
 Height field ambient occlusion using CUDA 3.6.2009 Outline 1 2 3 4 Theory Kernel 5 Height fields Self occlusion Current methods Marching several directions from each fragment Sampling several times along
Height field ambient occlusion using CUDA 3.6.2009 Outline 1 2 3 4 Theory Kernel 5 Height fields Self occlusion Current methods Marching several directions from each fragment Sampling several times along
DIMENSION REDUCTION FOR HYPERSPECTRAL DATA USING RANDOMIZED PCA AND LAPLACIAN EIGENMAPS
 DIMENSION REDUCTION FOR HYPERSPECTRAL DATA USING RANDOMIZED PCA AND LAPLACIAN EIGENMAPS YIRAN LI APPLIED MATHEMATICS, STATISTICS AND SCIENTIFIC COMPUTING ADVISOR: DR. WOJTEK CZAJA, DR. JOHN BENEDETTO DEPARTMENT
DIMENSION REDUCTION FOR HYPERSPECTRAL DATA USING RANDOMIZED PCA AND LAPLACIAN EIGENMAPS YIRAN LI APPLIED MATHEMATICS, STATISTICS AND SCIENTIFIC COMPUTING ADVISOR: DR. WOJTEK CZAJA, DR. JOHN BENEDETTO DEPARTMENT