Lecture: Networks, Disks, Datacenters, GPUs. Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections
|
|
|
- Roderick Marshall
- 5 years ago
- Views:
Transcription
1 Lecture: Networks, Disks, Datacenters, GPUs Topics: networks wrap-up, disks and reliability, datacenters, GPU intro (Sections , App D, Ch 4) 1
2 Packets/Flits A message is broken into multiple packets (each packet has header information that allows the receiver to re-construct the original message) A packet may itself be broken into flits flits do not contain additional headers Two packets can follow different paths to the destination Flits are always ordered and follow the same path Such an architecture allows the use of a large packet size (low header overhead) and yet allows fine-grained resource allocation on a per-flit basis 2
3 Flow Control The routing of a message requires allocation of various resources: the channel (or link), buffers, control state Bufferless: flits are dropped if there is contention for a link, NACKs are sent back, and the original sender has to re-transmit the packet Circuit switching: a request is first sent to reserve the channels, the request may be held at an intermediate router until the channel is available (hence, not truly bufferless), ACKs are sent back, and subsequent packets/flits are routed with little effort (good for bulk transfers) 3
4 Buffered Flow Control A buffer between two channels decouples the resource allocation for each channel Packet-buffer flow control: channels and buffers are allocated per packet H B B B T Store-and-forward Cut-through Channel Channel H B B B T H B B B T H B B B T Time-Space diagrams H B B B T H B B B T Cycle Wormhole routing: same as cut-through, but buffers in each router are allocated on a per-flit basis, not per-packet 4
5 Virtual Channels Buffers channel Buffers Flits do not carry headers. Once a packet starts going over a channel, another packet cannot cut in (else, the receiving buffer will confuse the flits of the two packets). If the packet is stalled, other packets can t use the channel. With virtual channels, the flit can be received into one of N buffers. This allows N packets to be in transit over a given physical channel. The packet must carry an ID to indicate its virtual channel. Buffers Buffers Physical channel Buffers Buffers 5
6 Example Wormhole: Node-0 A is going from Node-1 to Node-4; B is going from Node-0 to Node-5 Node-1 A Virtual channel: B idle B idle Node-2 Node-3 Node-4 Node-5 (blocked, no free VCs/buffers) Node-0 Traffic Analogy: B is trying to make a left turn; A is trying to go straight; there is no left-only lane with wormhole, but there is one with VC Node-1 A B A B A Node-2 Node-3 Node-4 Node-5 (blocked, no free VCs/buffers) 6
7 Virtual Channel Flow Control Incoming flits are placed in buffers For this flit to jump to the next router, it must acquire three resources: A free virtual channel on its intended hop We know that a virtual channel is free when the tail flit goes through Free buffer entries for that virtual channel This is determined with credit or on/off management A free cycle on the physical channel Competition among the packets that share a physical channel 7
8 Buffer Management Credit-based: keep track of the number of free buffers in the downstream node; the downstream node sends back signals to increment the count when a buffer is freed; need enough buffers to hide the round-trip latency On/Off: the upstream node sends back a signal when its buffers are close to being full reduces upstream signaling and counters, but can waste buffer space 8
9 Deadlock Avoidance with VCs VCs provide another way to number the links such that a route always uses ascending link numbers Alternatively, use West-first routing on the 1 st plane and cross over to the 2 nd plane in case you need to go West again (the 2 nd plane uses North-last, for example) 9
10 Router Functions Crossbar, buffer, arbiter, VC state and allocation, buffer management, ALUs, control logic, routing Typical on-chip network power breakdown: 30% link 30% buffers 30% crossbar 10
11 Router Pipeline Four typical stages: RC routing computation: the head flit indicates the VC that it belongs to, the VC state is updated, the headers are examined and the next output channel is computed (note: this is done for all the head flits arriving on various input channels) VA virtual-channel allocation: the head flits compete for the available virtual channels on their computed output channels SA switch allocation: a flit competes for access to its output physical channel ST switch traversal: the flit is transmitted on the output channel A head flit goes through all four stages, the other flits do nothing in the first two stages (this is an in-order pipeline and flits can not jump ahead), a tail flit also de-allocates the VC 11
12 Router Pipeline Four typical stages: RC routing computation: compute the output channel VA virtual-channel allocation: allocate VC for the head flit SA switch allocation: compete for output physical channel ST switch traversal: transfer data on output physical channel Cycle STALL Head flit Body flit 1 RC VA SA ST SA ST RC VA SA SA ST SA ST Body flit SA ST SA ST Tail flit SA ST SA ST 12
13 Speculative Pipelines Perform VA and SA in parallel Note that SA only requires knowledge of the output physical channel, not the VC If VA fails, the successfully allocated channel goes un-utilized Cycle Perform VA, SA, and ST in parallel (can cause collisions and re-tries) Typically, VA is the critical path can possibly perform SA and ST sequentially Head flit Body flit 1 RC VA SA ST -- SA ST RC VA SA ST SA ST Body flit 2 -- SA ST SA ST Tail flit -- SA ST SA ST Router pipeline latency is a greater bottleneck when there is little contention When there is little contention, speculation will likely work well! Single stage pipeline? 13


14 Example Intel Router Source: Partha Kundu, On-Die Interconnects for Next-Generation CMPs, talk at On-Chip Interconnection Networks Workshop, Dec


15 Example Intel Router Used for a 6x6 mesh 16 B, > 3 GHz Wormhole with VC flow control Source: Partha Kundu, On-Die Interconnects for Next-Generation CMPs, talk at On-Chip Interconnection Networks Workshop, Dec
16 Current Trends Growing interest in eliminating the area/power overheads of router buffers; traffic levels are also relatively low, so virtual-channel buffered routed networks may be overkill Option 1: use a bus for short distances (16 cores) and use a hierarchy of buses to travel long distances Option 2: hot-potato or bufferless routing 16
17 Centralized Crossbar Switch P0 P1 P2 P3 P4 P5 P6 P7 17
18 Crossbar Properties Assuming each node has one input and one output, a crossbar can provide maximum bandwidth: N messages can be sent as long as there are N unique sources and N unique destinations Maximum overhead: WN 2 internal switches, where W is data width and N is number of nodes To reduce overhead, use smaller switches as building blocks trade off overhead for lower effective bandwidth 18
19 Switch with Omega Network P0 P1 P2 P3 P4 P5 P P
20 Omega Network Properties The switch complexity is now O(N log N) Contention increases: P0 P5 and P1 P7 cannot happen concurrently (this was possible in a crossbar) To deal with contention, can increase the number of levels (redundant paths) by mirroring the network, we can route from P0 to P5 via N intermediate nodes, while increasing complexity by a factor of 2 20
21 Tree Network Complexity is O(N) Can yield low latencies when communicating with neighbors Can build a fat tree by having multiple incoming and outgoing links P0 P1 P2 P3 P4 P5 P6 P7 21
22 Bisection Bandwidth Split N nodes into two groups of N/2 nodes such that the bandwidth between these two groups is minimum: that is the bisection bandwidth Why is it relevant: if traffic is completely random, the probability of a message going across the two halves is ½ if all nodes send a message, the bisection bandwidth will have to be N/2 The concept of bisection bandwidth confirms that the tree network is not suited for random traffic patterns, but for localized traffic patterns 22
23 Distributed Switches: Ring Each node is connected to a 3x3 switch that routes messages between the node and its two neighbors Effectively a repeated bus: multiple messages in transit Disadvantage: bisection bandwidth of 2 and N/2 hops on average 23
24 Distributed Switch Options Performance can be increased by throwing more hardware at the problem: fully-connected switches: every switch is connected to every other switch: N 2 wiring complexity, N 2 /4 bisection bandwidth Most commercial designs adopt a point between the two extremes (ring and fully-connected): Grid: each node connects with its N, E, W, S neighbors Torus: connections wrap around Hypercube: links between nodes whose binary names differ in a single bit 24
25 Topology Examples Grid Torus Hypercube Criteria 64 nodes Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection bandwidth Cost Ports/switch Total links 25
26 Topology Examples Grid Torus Hypercube Criteria 64 nodes Bus Ring 2Dtorus 6-cube Fully connected Performance Diameter Bisection BW Cost Ports/switch Total links
27 k-ary d-cube Consider a k-ary d-cube: a d-dimension array with k elements in each dimension, there are links between elements that differ in one dimension by 1 (mod k) Number of nodes N = k d Number of switches : Switch degree : Number of links : Pins per node : Avg. routing distance: Diameter : Bisection bandwidth : Switch complexity : Should we minimize or maximize dimension? 27
28 k-ary d-cube Consider a k-ary d-cube: a d-dimension array with k elements in each dimension, there are links between elements that differ in one dimension by 1 (mod k) Number of nodes N = k d Number of switches : Switch degree : Number of links : Pins per node : N 2d + 1 Nd 2wd Avg. routing distance: Diameter : Bisection bandwidth : Switch complexity : d(k-1)/4 d(k-1)/2 2wk d-1 The switch degree, num links, pins per node, bisection bw for a hypercube are half of what is listed above (diam and avg routing distance are twice, switch complexity is (d + 1) 2 ) because unlike28 the other cases, a hypercube does not have right and left neighbors. Should we minimize or maximize dimension? (2d + 1) 2
29 Warehouse-Scale Computer (WSC) 100K+ servers in one WSC ~$150M overall cost Requests from millions of users (Google, Facebook, etc.) Cloud Computing: a model where users can rent compute and storage within a WSC, there s an associated service-level agreement (SLA) Datacenter: a collection of WSCs in a single building, possibly belonging to different clients and using different hardware/architecture 29
30 Workloads Typically, software developed in-house MapReduce, BigTable, Memcached, etc. MapReduce: embarrassingly parallel operations performed on very large datasets, e.g., organize data into clusters, aggregate a count over several documents Hadoop is an open-source implementation of the MapReduce framework; makes it easy for users to write MapReduce programs without worrying about low-level task/data management 30
31 MapReduce Application-writer provides Map and Reduce functions that operate on key-value pairs Each map function operates on a collection of records; a record is (say) a webpage or a facebook user profile The records are in the file system and scattered across several servers; thousands of map functions are spawned to work on all records in parallel The Reduce function aggregates and sorts the results produced by the Mappers, also performed in parallel 31
32 MR Framework Duties Replicate data for fault tolerance Detect failed threads and re-start threads Handle variability in thread response times Use of MR within Google has been growing every year: Aug 04 Sep 09 Number of MR jobs has increased 100x+ Data being processed has increased 100x+ Number of servers per job has increased 3x 32
33 WSC Hierarchy A rack can hold 48 1U servers (1U is 1.75 inches high) A rack switch is used for communication within and out of a rack; an array switch connects an array of racks Latency grows if data is fetched from remote DRAM or disk (300us vs. 0.1us for DRAM and 12ms vs. 10ms for disk ) Bandwidth within a rack is much higher than between arrays; hence, software must be aware of data placement and locality 33
34 PUE Metric and Power Breakdown PUE = Total facility power / IT equipment power (power utilization effectiveness) It is greater than 1; ranges from 1.33 to 3.03, median of 1.69 The cooling power is roughly half the power used by servers Within a server (circa 2007), the power distribution is as follows: Processors (33%), DRAM memory (30%), Disks (10%), Networking (5%), Miscellaneous (22%) 34
35 CapEx and OpEx Capital expenditure: infrastructure costs for the building, power delivery, cooling, and servers Operational expenditure: the monthly bill for energy, failures, personnel, etc. CapEx can be amortized into a monthly estimate by assuming that the facilities will last 10 years, server parts will last 3 years, and networking parts will last 4 35
36 CapEx/OpEx Case Study 8 MW facility : facility cost: $88M, server/networking cost: $79M Monthly expense: $3.8M. Breakdown: Servers 53% (amortized CapEx) Networking 8% (amortized CapEx) Power/cooling infrastructure 20% (amortized CapEx) Other infrastructure 4% (amortized CapEx) Monthly power bill 13% (true OpEx) Monthly personnel salaries 2% (true OpEx) 36
37 Improving Energy Efficiency An unloaded server dissipates a large amount of power Ideally, we want energy-proportional computing, but in reality, servers are not energy-proportional Can approach energy-proportionality by turning on a few servers that are heavily utilized See figures on next two slides for power/utilization profile of a server and a utilization profile of servers in a WSC 37

38 Power/Utilization Profile Source: H&P textbook. Copyright 2011, Elsevier Inc. All rights Reserved. 38

39 Server Utilization Profile Source: H&P textbook. Copyright 2011, Elsevier Inc. All rights Reserved. Figure 6.3 Average CPU utilization of more than 5000 servers during a 6-month period at Google. Servers are rarely completely idle or fully utilized, in-stead operating most of the time at between 10% and 50% of their maximum utilization. (From Figure 1 in Barroso and Hölzle [2007].) The column the third from the right in Figure 6.4 calculates percentages plus or minus 5% to come up with the weightings; thus, 1.2% for the 90% row means that 1.2% of servers were between 85% and 95% utilized. 39
40 Problem 1 Assume that a server consumes 100W at peak utilization and 50W at zero utilization. Assume a linear relationship between utilization and power. The server is capable of executing many threads in parallel. Assume that a single thread utilizes 25% of all server resources (functional units, caches, memory capacity, memory bandwidth, etc.). What is the total power dissipation when executing 99 threads on a collection of these servers, such that performance and energy are close to optimal? 40
41 Problem 1 Assume that a server consumes 100W at peak utilization and 50W at zero utilization. Assume a linear relationship between utilization and power. The server is capable of executing many threads in parallel. Assume that a single thread utilizes 25% of all server resources (functional units, caches, memory capacity, memory bandwidth, etc.). What is the total power dissipation when executing 99 threads on a collection of these servers, such that performance and energy are close to optimal? For near-optimal performance and energy, use 25 servers. 24 servers at 100% utilization, executing 96 threads, consuming 2400W. The 25th server will run the last 3 threads and consume 87.5~W. 41
42 Other Metrics Performance does matter, both latency and throughput An analysis of the Bing search engine shows that if a 200ms delay is introduced in the response, the next click by the user is delayed by 500ms; so a poor response time amplifies the user s non-productivity Reliability (MTTF) and Availability (MTTF/MTTF+MTTR) are very important, given the large scale A server with MTTF of 25 years (amazing!) : 50K servers would lead to 5 server failures a day; Similarly, annual disk failure rate is 2-10% 1 disk failure every hour 42
43 Important Problems Reducing power in power-down states Maximizing utilization Reducing cost with virtualization Reducing data movement Building a low-power low-cost processor Building a low-power low-cost hi-bw memory Low-power low-cost on-demand reliability 43
44 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material on both sides), with diameters between inches Each platter is comprised of concentric tracks (5-30K) and each track is divided into sectors ( per track, each about 512 bytes) A movable arm holds the read/write heads for each disk surface and moves them all in tandem a cylinder of data is accessible at a time 44
45 Disk Latency To read/write data, the arm has to be placed on the correct track this seek time usually takes 5 to 12 ms on average can take less if there is spatial locality Rotational latency is the time taken to rotate the correct sector under the head average is typically more than 2 ms (15,000 RPM) Transfer time is the time taken to transfer a block of bits out of the disk and is typically 3 65 MB/second A disk controller maintains a disk cache (spatial locality can be exploited) and sets up the transfer on the bus (controller overhead) 45
46 RAID Reliability and availability are important metrics for disks RAID: redundant array of inexpensive (independent) disks Redundancy can deal with one or more failures Each sector of a disk records check information that allows it to determine if the disk has an error or not (in other words, redundancy already exists within a disk) When the disk read flags an error, we turn elsewhere for correct data 46
47 RAID 0 and RAID 1 RAID 0 has no additional redundancy (misnomer) it uses an array of disks and stripes (interleaves) data across the arrays to improve parallelism and throughput RAID 1 mirrors or shadows every disk every write happens to two disks Reads to the mirror may happen only when the primary disk fails or, you may try to read both together and the quicker response is accepted Expensive solution: high reliability at twice the cost 47
48 RAID 3 Data is bit-interleaved across several disks and a separate disk maintains parity information for a set of bits For example: with 8 disks, bit 0 is in disk-0, bit 1 is in disk-1,, bit 7 is in disk-7; disk-8 maintains parity for all 8 bits For any read, 8 disks must be accessed (as we usually read more than a byte at a time) and for any write, 9 disks must be accessed as parity has to be re-calculated High throughput for a single request, low cost for redundancy (overhead: 12.5%), low task-level parallelism 48
49 RAID 4 and RAID 5 Data is block interleaved this allows us to get all our data from a single disk on a read in case of a disk error, read all 9 disks Block interleaving reduces thruput for a single request (as only a single disk drive is servicing the request), but improves task-level parallelism as other disk drives are free to service other requests On a write, we access the disk that stores the data and the parity disk parity information can be updated simply by checking if the new data differs from the old data 49
50 RAID 5 If we have a single disk for parity, multiple writes can not happen in parallel (as all writes must update parity info) RAID 5 distributes the parity block to allow simultaneous writes 50
51 Other Reliability Approaches High reliability is also expected of memory systems; many memory systems offer SEC-DED support single error correct, double error detect; implemented with an 8-bit code for every 64-bit data word on ECC DIMMs Some memory systems offer chipkill support the ability to recover from complete failure in one memory chip many implementations exist, some resembling RAID designs Caches are typically protected with SEC-DED codes Some cores implement various forms of redundancy, e.g., DMR or TMR dual or triple modular redundancy 51
52 SIMD Processors Single instruction, multiple data Such processors offer energy efficiency because a single instruction fetch can trigger many data operations Such data parallelism may be useful for many image/sound and numerical applications 52
53 GPUs Initially developed as graphics accelerators; now viewed as one of the densest compute engines available Many on-going efforts to run non-graphics workloads on GPUs, i.e., use them as general-purpose GPUs or GPGPUs C/C++ based programming platforms enable wider use of GPGPUs CUDA from NVidia and OpenCL from an industry consortium A heterogeneous system has a regular host CPU and a GPU that handles (say) CUDA code (they can both be on the same chip) 53
54 The GPU Architecture SIMT single instruction, multiple thread; a GPU has many SIMT cores A large data-parallel operation is partitioned into many thread blocks (one per SIMT core); a thread block is partitioned into many warps (one warp running at a time in the SIMT core); a warp is partitioned across many in-order pipelines (each is called a SIMD lane) A SIMT core can have multiple active warps at a time, i.e., the SIMT core stores the registers for each warp; warps can be context-switched at low cost; a warp scheduler keeps track of runnable warps and schedules a new warp if the currently running warp stalls 54
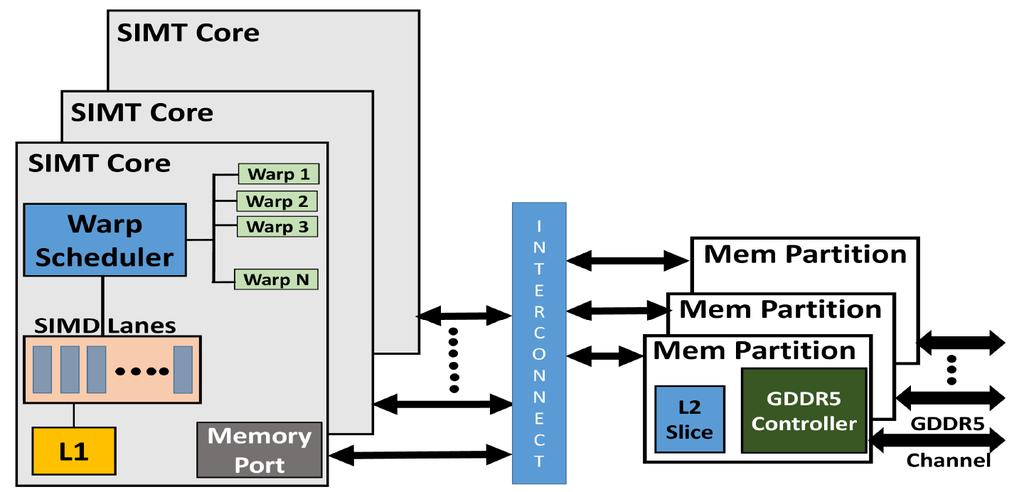
55 The GPU Architecture 55
56 Architecture Features Simple in-order pipelines that rely on thread-level parallelism to hide long latencies Many registers (~1K) per in-order pipeline (lane) to support many active warps When a branch is encountered, some of the lanes proceed along the then case depending on their data values; later, the other lanes evaluate the else case; a branch cuts the data-level parallelism by half (branch divergence) When a load/store is encountered, the requests from all lanes are coalesced into a few 128B cache line requests; each request may return at a different time (mem divergence) 56
57 GPU Memory Hierarchy Each SIMT core has a private L1 cache (shared by the warps on that core) A large L2 is shared by all SIMT cores; each L2 bank services a subset of all addresses Each L2 partition is connected to its own memory controller and memory channel The GDDR5 memory system runs at higher frequencies, and uses chips with more banks, wide IO, and better power delivery networks A portion of GDDR5 memory is private to the GPU and the rest is accessible to the host CPU (the GPU performs copies) 57
58 Title Bullet 58
Lecture: Interconnection Networks
 Lecture: Interconnection Networks Topics: Router microarchitecture, topologies Final exam next Tuesday: same rules as the first midterm 1 Packets/Flits A message is broken into multiple packets (each packet
Lecture: Interconnection Networks Topics: Router microarchitecture, topologies Final exam next Tuesday: same rules as the first midterm 1 Packets/Flits A message is broken into multiple packets (each packet
Lecture 12: Interconnection Networks. Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E)
") Lecture 12: Interconnection Networks Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E) 1 Topologies Internet topologies are not very regular they grew
Lecture 12: Interconnection Networks Topics: communication latency, centralized and decentralized switches, routing, deadlocks (Appendix E) 1 Topologies Internet topologies are not very regular they grew
Lecture 25: Interconnection Networks, Disks. Topics: flow control, router microarchitecture, RAID
 Lecture 25: Interconnection Networks, Disks Topics: flow control, router microarchitecture, RAID 1 Virtual Channel Flow Control Each switch has multiple virtual channels per phys. channel Each virtual
Lecture 25: Interconnection Networks, Disks Topics: flow control, router microarchitecture, RAID 1 Virtual Channel Flow Control Each switch has multiple virtual channels per phys. channel Each virtual
Lecture 20: WSC, Datacenters. Topics: warehouse-scale computing and datacenters (Sections )
") Lecture 20: WSC, Datacenters Topics: warehouse-scale computing and datacenters (Sections 6.1-6.7) 1 Warehouse-Scale Computer (WSC) 100K+ servers in one WSC ~$150M overall cost Requests from millions of
Lecture 20: WSC, Datacenters Topics: warehouse-scale computing and datacenters (Sections 6.1-6.7) 1 Warehouse-Scale Computer (WSC) 100K+ servers in one WSC ~$150M overall cost Requests from millions of
Lecture: Storage, GPUs. Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4)
") Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture: Storage, GPUs Topics: disks, RAID, reliability, GPUs (Appendix D, Ch 4) 1 Magnetic Disks A magnetic disk consists of 1-12 platters (metal or glass disk covered with magnetic recording material
Lecture 16: On-Chip Networks. Topics: Cache networks, NoC basics
 Lecture 16: On-Chip Networks Topics: Cache networks, NoC basics 1 Traditional Networks Huh et al. ICS 05, Beckmann MICRO 04 Example designs for contiguous L2 cache regions 2 Explorations for Optimality
Lecture 16: On-Chip Networks Topics: Cache networks, NoC basics 1 Traditional Networks Huh et al. ICS 05, Beckmann MICRO 04 Example designs for contiguous L2 cache regions 2 Explorations for Optimality
Lecture 13: Interconnection Networks. Topics: lots of background, recent innovations for power and performance
 Lecture 13: Interconnection Networks Topics: lots of background, recent innovations for power and performance 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees,
Lecture 13: Interconnection Networks Topics: lots of background, recent innovations for power and performance 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees,
Lecture 15: PCM, Networks. Today: PCM wrap-up, projects discussion, on-chip networks background
 Lecture 15: PCM, Networks Today: PCM wrap-up, projects discussion, on-chip networks background 1 Hard Error Tolerance in PCM PCM cells will eventually fail; important to cause gradual capacity degradation
Lecture 15: PCM, Networks Today: PCM wrap-up, projects discussion, on-chip networks background 1 Hard Error Tolerance in PCM PCM cells will eventually fail; important to cause gradual capacity degradation
Lecture 27: Pot-Pourri. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability
 GPUs Disks and reliability") Lecture 27: Pot-Pourri Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood
Lecture 27: Pot-Pourri Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs Disks and reliability 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood
Lecture 24: Interconnection Networks. Topics: topologies, routing, deadlocks, flow control
 Lecture 24: Interconnection Networks Topics: topologies, routing, deadlocks, flow control 1 Topology Examples Grid Torus Hypercube Criteria Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection
Lecture 24: Interconnection Networks Topics: topologies, routing, deadlocks, flow control 1 Topology Examples Grid Torus Hypercube Criteria Bus Ring 2Dtorus 6-cube Fully connected Performance Bisection
Lecture: Interconnection Networks. Topics: TM wrap-up, routing, deadlock, flow control, virtual channels
 Lecture: Interconnection Networks Topics: TM wrap-up, routing, deadlock, flow control, virtual channels 1 TM wrap-up Eager versioning: create a log of old values Handling problematic situations with a
Lecture: Interconnection Networks Topics: TM wrap-up, routing, deadlock, flow control, virtual channels 1 TM wrap-up Eager versioning: create a log of old values Handling problematic situations with a
Lecture 12: Interconnection Networks. Topics: dimension/arity, routing, deadlock, flow control
 Lecture 12: Interconnection Networks Topics: dimension/arity, routing, deadlock, flow control 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees, butterflies,
Lecture 12: Interconnection Networks Topics: dimension/arity, routing, deadlock, flow control 1 Interconnection Networks Recall: fully connected network, arrays/rings, meshes/tori, trees, butterflies,
Lecture: Transactional Memory, Networks. Topics: TM implementations, on-chip networks
 Lecture: Transactional Memory, Networks Topics: TM implementations, on-chip networks 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock
Lecture: Transactional Memory, Networks Topics: TM implementations, on-chip networks 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock
Lecture 14: Large Cache Design III. Topics: Replacement policies, associativity, cache networks, networking basics
 Lecture 14: Large Cache Design III Topics: Replacement policies, associativity, cache networks, networking basics 1 LIN Qureshi et al., ISCA 06 Memory level parallelism (MLP): number of misses that simultaneously
Lecture 14: Large Cache Design III Topics: Replacement policies, associativity, cache networks, networking basics 1 LIN Qureshi et al., ISCA 06 Memory level parallelism (MLP): number of misses that simultaneously
Lecture 23: Storage Systems. Topics: disk access, bus design, evaluation metrics, RAID (Sections )
") Lecture 23: Storage Systems Topics: disk access, bus design, evaluation metrics, RAID (Sections 7.1-7.9) 1 Role of I/O Activities external to the CPU are typically orders of magnitude slower Example: while
Lecture 23: Storage Systems Topics: disk access, bus design, evaluation metrics, RAID (Sections 7.1-7.9) 1 Role of I/O Activities external to the CPU are typically orders of magnitude slower Example: while
Lecture 27: Multiprocessors. Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs
 GPUs") Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
Lecture 27: Multiprocessors Today s topics: Shared memory vs message-passing Simultaneous multi-threading (SMT) GPUs 1 Shared-Memory Vs. Message-Passing Shared-memory: Well-understood programming model
TDT Appendix E Interconnection Networks
 TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
TDT 4260 Appendix E Interconnection Networks Review Advantages of a snooping coherency protocol? Disadvantages of a snooping coherency protocol? Advantages of a directory coherency protocol? Disadvantages
I/O CANNOT BE IGNORED
 LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
I/O CANNOT BE IGNORED
 LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
LECTURE 13 I/O I/O CANNOT BE IGNORED Assume a program requires 100 seconds, 90 seconds for main memory, 10 seconds for I/O. Assume main memory access improves by ~10% per year and I/O remains the same.
4. Networks. in parallel computers. Advances in Computer Architecture
 4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
4. Networks in parallel computers Advances in Computer Architecture System architectures for parallel computers Control organization Single Instruction stream Multiple Data stream (SIMD) All processors
Lecture 3: Flow-Control
 High-Performance On-Chip Interconnects for Emerging SoCs http://tusharkrishna.ece.gatech.edu/teaching/nocs_acaces17/ ACACES Summer School 2017 Lecture 3: Flow-Control Tushar Krishna Assistant Professor
High-Performance On-Chip Interconnects for Emerging SoCs http://tusharkrishna.ece.gatech.edu/teaching/nocs_acaces17/ ACACES Summer School 2017 Lecture 3: Flow-Control Tushar Krishna Assistant Professor
Lecture 22: Router Design
 Lecture 22: Router Design Papers: Power-Driven Design of Router Microarchitectures in On-Chip Networks, MICRO 03, Princeton A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip
Lecture 22: Router Design Papers: Power-Driven Design of Router Microarchitectures in On-Chip Networks, MICRO 03, Princeton A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip
Interconnection Networks: Topology. Prof. Natalie Enright Jerger
 Interconnection Networks: Topology Prof. Natalie Enright Jerger Topology Overview Definition: determines arrangement of channels and nodes in network Analogous to road map Often first step in network design
Interconnection Networks: Topology Prof. Natalie Enright Jerger Topology Overview Definition: determines arrangement of channels and nodes in network Analogous to road map Often first step in network design
Storage Systems. Storage Systems
 Storage Systems Storage Systems We already know about four levels of storage: Registers Cache Memory Disk But we've been a little vague on how these devices are interconnected In this unit, we study Input/output
Storage Systems Storage Systems We already know about four levels of storage: Registers Cache Memory Disk But we've been a little vague on how these devices are interconnected In this unit, we study Input/output
Lecture 26: Interconnects. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
18 447 Lecture 26: Interconnects James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L26 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Housekeeping Your goal today get an overview of parallel
Interconnection Networks
 Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
Lecture 17: Interconnection Networks Parallel Computer Architecture and Programming A comment on web site comments It is okay to make a comment on a slide/topic that has already been commented on. In fact
ΕΠΛ372 Παράλληλη Επεξεργάσια
 ΕΠΛ372 Παράλληλη Επεξεργάσια Warehouse Scale Computing and Services Γιάννος Σαζεϊδης Εαρινό Εξάμηνο 2014 READING 1. Read Barroso The Datacenter as a Computer http://www.morganclaypool.com/doi/pdf/10.2200/s00193ed1v01y200905cac006?cookieset=1
ΕΠΛ372 Παράλληλη Επεξεργάσια Warehouse Scale Computing and Services Γιάννος Σαζεϊδης Εαρινό Εξάμηνο 2014 READING 1. Read Barroso The Datacenter as a Computer http://www.morganclaypool.com/doi/pdf/10.2200/s00193ed1v01y200905cac006?cookieset=1
Virtual Memory. Reading. Sections 5.4, 5.5, 5.6, 5.8, 5.10 (2) Lecture notes from MKP and S. Yalamanchili
 Lecture notes from MKP and S. Yalamanchili") Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Routing Algorithm. How do I know where a packet should go? Topology does NOT determine routing (e.g., many paths through torus)
") Routing Algorithm How do I know where a packet should go? Topology does NOT determine routing (e.g., many paths through torus) Many routing algorithms exist 1) Arithmetic 2) Source-based 3) Table lookup
Routing Algorithm How do I know where a packet should go? Topology does NOT determine routing (e.g., many paths through torus) Many routing algorithms exist 1) Arithmetic 2) Source-based 3) Table lookup
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
Lecture 23: Router Design
 Lecture 23: Router Design Papers: A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip Networks, ISCA 06, Penn-State ViChaR: A Dynamic Virtual Channel Regulator for Network-on-Chip
Lecture 23: Router Design Papers: A Gracefully Degrading and Energy-Efficient Modular Router Architecture for On-Chip Networks, ISCA 06, Penn-State ViChaR: A Dynamic Virtual Channel Regulator for Network-on-Chip
Storage systems. Computer Systems Architecture CMSC 411 Unit 6 Storage Systems. (Hard) Disks. Disk and Tape Technologies. Disks (cont.
 Disks. Disk and Tape Technologies. Disks (cont.") Computer Systems Architecture CMSC 4 Unit 6 Storage Systems Alan Sussman November 23, 2004 Storage systems We already know about four levels of storage: registers cache memory disk but we've been a little
Computer Systems Architecture CMSC 4 Unit 6 Storage Systems Alan Sussman November 23, 2004 Storage systems We already know about four levels of storage: registers cache memory disk but we've been a little
Interconnection Networks
 Lecture 18: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Credit: many of these slides were created by Michael Papamichael This lecture is partially
Lecture 18: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Credit: many of these slides were created by Michael Papamichael This lecture is partially
EECS 570 Final Exam - SOLUTIONS Winter 2015
 EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
Administrivia. CMSC 411 Computer Systems Architecture Lecture 19 Storage Systems, cont. Disks (cont.) Disks - review
 Disks - review") Administrivia CMSC 411 Computer Systems Architecture Lecture 19 Storage Systems, cont. Homework #4 due Thursday answers posted soon after Exam #2 on Thursday, April 24 on memory hierarchy (Unit 4) and
Administrivia CMSC 411 Computer Systems Architecture Lecture 19 Storage Systems, cont. Homework #4 due Thursday answers posted soon after Exam #2 on Thursday, April 24 on memory hierarchy (Unit 4) and
Packet Switch Architecture
 Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture
 Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
Packet Switch Architecture 3. Output Queueing Architectures 4. Input Queueing Architectures 5. Switching Fabrics 6. Flow and Congestion Control in Sw. Fabrics 7. Output Scheduling for QoS Guarantees 8.
EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University
 EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University Material from: The Datacenter as a Computer: An Introduction to
EN2910A: Advanced Computer Architecture Topic 06: Supercomputers & Data Centers Prof. Sherief Reda School of Engineering Brown University Material from: The Datacenter as a Computer: An Introduction to
Interconnect Technology and Computational Speed
 Interconnect Technology and Computational Speed From Chapter 1 of B. Wilkinson et al., PARAL- LEL PROGRAMMING. Techniques and Applications Using Networked Workstations and Parallel Computers, augmented
Interconnect Technology and Computational Speed From Chapter 1 of B. Wilkinson et al., PARAL- LEL PROGRAMMING. Techniques and Applications Using Networked Workstations and Parallel Computers, augmented
Thomas Moscibroda Microsoft Research. Onur Mutlu CMU
 Thomas Moscibroda Microsoft Research Onur Mutlu CMU CPU+L1 CPU+L1 CPU+L1 CPU+L1 Multi-core Chip Cache -Bank Cache -Bank Cache -Bank Cache -Bank CPU+L1 CPU+L1 CPU+L1 CPU+L1 Accelerator, etc Cache -Bank
Thomas Moscibroda Microsoft Research Onur Mutlu CMU CPU+L1 CPU+L1 CPU+L1 CPU+L1 Multi-core Chip Cache -Bank Cache -Bank Cache -Bank Cache -Bank CPU+L1 CPU+L1 CPU+L1 CPU+L1 Accelerator, etc Cache -Bank
Interconnection Network
 Interconnection Network Recap: Generic Parallel Architecture A generic modern multiprocessor Network Mem Communication assist (CA) $ P Node: processor(s), memory system, plus communication assist Network
Interconnection Network Recap: Generic Parallel Architecture A generic modern multiprocessor Network Mem Communication assist (CA) $ P Node: processor(s), memory system, plus communication assist Network
Physical Organization of Parallel Platforms. Alexandre David
 Physical Organization of Parallel Platforms Alexandre David 1.2.05 1 Static vs. Dynamic Networks 13-02-2008 Alexandre David, MVP'08 2 Interconnection networks built using links and switches. How to connect:
Physical Organization of Parallel Platforms Alexandre David 1.2.05 1 Static vs. Dynamic Networks 13-02-2008 Alexandre David, MVP'08 2 Interconnection networks built using links and switches. How to connect:
Lecture 2: Topology - I
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 2: Topology - I Tushar Krishna Assistant Professor School of Electrical and
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 2: Topology - I Tushar Krishna Assistant Professor School of Electrical and
CS575 Parallel Processing
 CS575 Parallel Processing Lecture three: Interconnection Networks Wim Bohm, CSU Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license.
CS575 Parallel Processing Lecture three: Interconnection Networks Wim Bohm, CSU Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license.
ES1 An Introduction to On-chip Networks
 December 17th, 2015 ES1 An Introduction to On-chip Networks Davide Zoni PhD mail: davide.zoni@polimi.it webpage: home.dei.polimi.it/zoni Sources Main Reference Book (for the examination) Designing Network-on-Chip
December 17th, 2015 ES1 An Introduction to On-chip Networks Davide Zoni PhD mail: davide.zoni@polimi.it webpage: home.dei.polimi.it/zoni Sources Main Reference Book (for the examination) Designing Network-on-Chip
Network-on-chip (NOC) Topologies
 Topologies") Network-on-chip (NOC) Topologies 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and performance
Network-on-chip (NOC) Topologies 1 Network Topology Static arrangement of channels and nodes in an interconnection network The roads over which packets travel Topology chosen based on cost and performance
Interconnection Networks: Flow Control. Prof. Natalie Enright Jerger
 Interconnection Networks: Flow Control Prof. Natalie Enright Jerger Switching/Flow Control Overview Topology: determines connectivity of network Routing: determines paths through network Flow Control:
Interconnection Networks: Flow Control Prof. Natalie Enright Jerger Switching/Flow Control Overview Topology: determines connectivity of network Routing: determines paths through network Flow Control:
Lecture 2 Parallel Programming Platforms
 Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Lecture 2 Parallel Programming Platforms Flynn s Taxonomy In 1966, Michael Flynn classified systems according to numbers of instruction streams and the number of data stream. Data stream Single Multiple
Adapted from instructor s supplementary material from Computer. Patterson & Hennessy, 2008, MK]
![Adapted from instructor s supplementary material from Computer. Patterson & Hennessy, 2008, MK]](/thumbs/80/82108809.jpg "Adapted from instructor s supplementary material from Computer. Patterson & Hennessy, 2008, MK]") Lecture 17 Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] SRAM / / Flash / RRAM / HDD SRAM / / Flash / RRAM/ HDD SRAM
Lecture 17 Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] SRAM / / Flash / RRAM / HDD SRAM / / Flash / RRAM/ HDD SRAM
Interconnection Network. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Topics Taxonomy Metric Topologies Characteristics Cost Performance 2 Interconnection
Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Topics Taxonomy Metric Topologies Characteristics Cost Performance 2 Interconnection
EECS 570. Lecture 19 Interconnects: Flow Control. Winter 2018 Subhankar Pal
 Lecture 19 Interconnects: Flow Control Winter 2018 Subhankar Pal http://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Adve, Falsafi, Hill, Lebeck, Martin, Narayanasamy, Nowatzyk,
Lecture 19 Interconnects: Flow Control Winter 2018 Subhankar Pal http://www.eecs.umich.edu/courses/eecs570/ Slides developed in part by Profs. Adve, Falsafi, Hill, Lebeck, Martin, Narayanasamy, Nowatzyk,
Storage Systems : Disks and SSDs. Manu Awasthi CASS 2018
 Storage Systems : Disks and SSDs Manu Awasthi CASS 2018 Why study storage? Scalable High Performance Main Memory System Using Phase-Change Memory Technology, Qureshi et al, ISCA 2009 Trends Total amount
Storage Systems : Disks and SSDs Manu Awasthi CASS 2018 Why study storage? Scalable High Performance Main Memory System Using Phase-Change Memory Technology, Qureshi et al, ISCA 2009 Trends Total amount
Computer Science 146. Computer Architecture
 Computer Science 46 Computer Architecture Spring 24 Harvard University Instructor: Prof dbrooks@eecsharvardedu Lecture 22: More I/O Computer Science 46 Lecture Outline HW5 and Project Questions? Storage
Computer Science 46 Computer Architecture Spring 24 Harvard University Instructor: Prof dbrooks@eecsharvardedu Lecture 22: More I/O Computer Science 46 Lecture Outline HW5 and Project Questions? Storage
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Networks: Routing, Deadlock, Flow Control, Switch Design, Case Studies. Admin
 Networks: Routing, Deadlock, Flow Control, Switch Design, Case Studies Alvin R. Lebeck CPS 220 Admin Homework #5 Due Dec 3 Projects Final (yes it will be cumulative) CPS 220 2 1 Review: Terms Network characterized
Networks: Routing, Deadlock, Flow Control, Switch Design, Case Studies Alvin R. Lebeck CPS 220 Admin Homework #5 Due Dec 3 Projects Final (yes it will be cumulative) CPS 220 2 1 Review: Terms Network characterized
Chapter 11: File System Implementation. Objectives
 Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Interconnection Network
 Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Topics
Interconnection Network Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu) Topics
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Overview. Processor organizations Types of parallel machines. Real machines
 Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Course Outline Introduction in algorithms and applications Parallel machines and architectures Overview of parallel machines, trends in top-500, clusters, DAS Programming methods, languages, and environments
Warehouse-Scale Computers to Exploit Request-Level and Data-Level Parallelism
 Warehouse-Scale Computers to Exploit Request-Level and Data-Level Parallelism The datacenter is the computer Luiz Andre Barroso, Google (2007) Outline Introduction to WSCs Programming Models and Workloads
Warehouse-Scale Computers to Exploit Request-Level and Data-Level Parallelism The datacenter is the computer Luiz Andre Barroso, Google (2007) Outline Introduction to WSCs Programming Models and Workloads
Recall: The Routing problem: Local decisions. Recall: Multidimensional Meshes and Tori. Properties of Routing Algorithms
 CS252 Graduate Computer Architecture Lecture 16 Multiprocessor Networks (con t) March 14 th, 212 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
CS252 Graduate Computer Architecture Lecture 16 Multiprocessor Networks (con t) March 14 th, 212 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~kubitron/cs252
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. CPU performance keeps increasing 26 72-core Xeon
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. CPU performance keeps increasing 26 72-core Xeon
Flow Control can be viewed as a problem of
 NOC Flow Control 1 Flow Control Flow Control determines how the resources of a network, such as channel bandwidth and buffer capacity are allocated to packets traversing a network Goal is to use resources
NOC Flow Control 1 Flow Control Flow Control determines how the resources of a network, such as channel bandwidth and buffer capacity are allocated to packets traversing a network Goal is to use resources
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Interconnection networks
 Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Interconnection networks When more than one processor needs to access a memory structure, interconnection networks are needed to route data from processors to memories (concurrent access to a shared memory
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Storage and Other I/O Topics I/O Performance Measures Types and Characteristics of I/O Devices Buses Interfacing I/O Devices
Computer Organization and Structure Bing-Yu Chen National Taiwan University Storage and Other I/O Topics I/O Performance Measures Types and Characteristics of I/O Devices Buses Interfacing I/O Devices
Chapter 6. Storage and Other I/O Topics
 Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Chapter 6 Storage and Other I/O Topics Introduction I/O devices can be characterized by Behaviour: input, output, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections
Lecture 7: Flow Control - I
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 7: Flow Control - I Tushar Krishna Assistant Professor School of Electrical
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 7: Flow Control - I Tushar Krishna Assistant Professor School of Electrical
Storage. Hwansoo Han
 Storage Hwansoo Han I/O Devices I/O devices can be characterized by Behavior: input, out, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections 2 I/O System Characteristics
Storage Hwansoo Han I/O Devices I/O devices can be characterized by Behavior: input, out, storage Partner: human or machine Data rate: bytes/sec, transfers/sec I/O bus connections 2 I/O System Characteristics
Lecture 23. Finish-up buses Storage
 Lecture 23 Finish-up buses Storage 1 Example Bus Problems, cont. 2) Assume the following system: A CPU and memory share a 32-bit bus running at 100MHz. The memory needs 50ns to access a 64-bit value from
Lecture 23 Finish-up buses Storage 1 Example Bus Problems, cont. 2) Assume the following system: A CPU and memory share a 32-bit bus running at 100MHz. The memory needs 50ns to access a 64-bit value from
Interconnection topologies (cont.) [ ] In meshes and hypercubes, the average distance increases with the dth root of N.
![Interconnection topologies (cont.) [ ] In meshes and hypercubes, the average distance increases with the dth root of N.](/thumbs/82/87011135.jpg "Interconnection topologies (cont.) [ ] In meshes and hypercubes, the average distance increases with the dth root of N.") Interconnection topologies (cont.) [ 10.4.4] In meshes and hypercubes, the average distance increases with the dth root of N. In a tree, the average distance grows only logarithmically. A simple tree structure,
Interconnection topologies (cont.) [ 10.4.4] In meshes and hypercubes, the average distance increases with the dth root of N. In a tree, the average distance grows only logarithmically. A simple tree structure,
Deadlock and Router Micro-Architecture
 1 EE482: Advanced Computer Organization Lecture #8 Interconnection Network Architecture and Design Stanford University 22 April 1999 Deadlock and Router Micro-Architecture Lecture #8: 22 April 1999 Lecturer:
1 EE482: Advanced Computer Organization Lecture #8 Interconnection Network Architecture and Design Stanford University 22 April 1999 Deadlock and Router Micro-Architecture Lecture #8: 22 April 1999 Lecturer:
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Appendix D: Storage Systems
 Appendix D: Storage Systems Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Storage Systems : Disks Used for long term storage of files temporarily store parts of pgm
Appendix D: Storage Systems Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Storage Systems : Disks Used for long term storage of files temporarily store parts of pgm
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Lecture 3: Topology - II
 ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 3: Topology - II Tushar Krishna Assistant Professor School of Electrical and
ECE 8823 A / CS 8803 - ICN Interconnection Networks Spring 2017 http://tusharkrishna.ece.gatech.edu/teaching/icn_s17/ Lecture 3: Topology - II Tushar Krishna Assistant Professor School of Electrical and
Computer Architecture and System Software Lecture 09: Memory Hierarchy. Instructor: Rob Bergen Applied Computer Science University of Winnipeg
 Computer Architecture and System Software Lecture 09: Memory Hierarchy Instructor: Rob Bergen Applied Computer Science University of Winnipeg Announcements Midterm returned + solutions in class today SSD
Computer Architecture and System Software Lecture 09: Memory Hierarchy Instructor: Rob Bergen Applied Computer Science University of Winnipeg Announcements Midterm returned + solutions in class today SSD
On-Die Interconnects for next generation CMPs
 On-Die Interconnects for next generation CMPs Partha Kundu Corporate Technology Group (MTL) Intel Corporation OCIN Workshop, Stanford University December 6, 2006 1 Multi- Transition Accelerating We notified
On-Die Interconnects for next generation CMPs Partha Kundu Corporate Technology Group (MTL) Intel Corporation OCIN Workshop, Stanford University December 6, 2006 1 Multi- Transition Accelerating We notified
Chapter 6 Storage and Other I/O Topics
 Department of Electr rical Eng ineering, Chapter 6 Storage and Other I/O Topics 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Feng-Chia Unive ersity Outline 6.1 Introduction 6.2 Dependability,
Department of Electr rical Eng ineering, Chapter 6 Storage and Other I/O Topics 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Feng-Chia Unive ersity Outline 6.1 Introduction 6.2 Dependability,
Module 17: "Interconnection Networks" Lecture 37: "Introduction to Routers" Interconnection Networks. Fundamentals. Latency and bandwidth
 Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Interconnection Networks Fundamentals Latency and bandwidth Router architecture Coherence protocol and routing [From Chapter 10 of Culler, Singh, Gupta] file:///e /parallel_com_arch/lecture37/37_1.htm[6/13/2012
Chapter-6. SUBJECT:- Operating System TOPICS:- I/O Management. Created by : - Sanjay Patel
 Chapter-6 SUBJECT:- Operating System TOPICS:- I/O Management Created by : - Sanjay Patel Disk Scheduling Algorithm 1) First-In-First-Out (FIFO) 2) Shortest Service Time First (SSTF) 3) SCAN 4) Circular-SCAN
Chapter-6 SUBJECT:- Operating System TOPICS:- I/O Management Created by : - Sanjay Patel Disk Scheduling Algorithm 1) First-In-First-Out (FIFO) 2) Shortest Service Time First (SSTF) 3) SCAN 4) Circular-SCAN
CS252 S05. Main memory management. Memory hardware. The scale of things. Memory hardware (cont.) Bottleneck
 Bottleneck") Main memory management CMSC 411 Computer Systems Architecture Lecture 16 Memory Hierarchy 3 (Main Memory & Memory) Questions: How big should main memory be? How to handle reads and writes? How to find
Main memory management CMSC 411 Computer Systems Architecture Lecture 16 Memory Hierarchy 3 (Main Memory & Memory) Questions: How big should main memory be? How to handle reads and writes? How to find
Interconnection Networks
 Lecture 15: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Credit: some slides created by Michael Papamichael, others based on slides from Onur Mutlu
Lecture 15: Interconnection Networks Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2016 Credit: some slides created by Michael Papamichael, others based on slides from Onur Mutlu
Database Architecture 2 & Storage. Instructor: Matei Zaharia cs245.stanford.edu
 Database Architecture 2 & Storage Instructor: Matei Zaharia cs245.stanford.edu Summary from Last Time System R mostly matched the architecture of a modern RDBMS» SQL» Many storage & access methods» Cost-based
Database Architecture 2 & Storage Instructor: Matei Zaharia cs245.stanford.edu Summary from Last Time System R mostly matched the architecture of a modern RDBMS» SQL» Many storage & access methods» Cost-based
Lecture 28: Networks & Interconnect Architectural Issues Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 28: Networks & Interconnect Architectural Issues Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: ABCs of Networks Starting Point: Send bits between 2 computers Queue
Lecture 28: Networks & Interconnect Architectural Issues Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: ABCs of Networks Starting Point: Send bits between 2 computers Queue
Database Systems II. Secondary Storage
 Database Systems II Secondary Storage CMPT 454, Simon Fraser University, Fall 2009, Martin Ester 29 The Memory Hierarchy Swapping, Main-memory DBMS s Tertiary Storage: Tape, Network Backup 3,200 MB/s (DDR-SDRAM
Database Systems II Secondary Storage CMPT 454, Simon Fraser University, Fall 2009, Martin Ester 29 The Memory Hierarchy Swapping, Main-memory DBMS s Tertiary Storage: Tape, Network Backup 3,200 MB/s (DDR-SDRAM
CSCI-GA Database Systems Lecture 8: Physical Schema: Storage
 CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
INTERCONNECTION NETWORKS LECTURE 4
 INTERCONNECTION NETWORKS LECTURE 4 DR. SAMMAN H. AMEEN 1 Topology Specifies way switches are wired Affects routing, reliability, throughput, latency, building ease Routing How does a message get from source
INTERCONNECTION NETWORKS LECTURE 4 DR. SAMMAN H. AMEEN 1 Topology Specifies way switches are wired Affects routing, reliability, throughput, latency, building ease Routing How does a message get from source
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi, Qin Yin, Timothy Roscoe Spring Semester 2015 Oriana Riva, Department of Computer Science ETH Zürich 1 Today Flow Control Store-and-forward,
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi, Qin Yin, Timothy Roscoe Spring Semester 2015 Oriana Riva, Department of Computer Science ETH Zürich 1 Today Flow Control Store-and-forward,
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
CSC630/CSC730: Parallel Computing
 CSC630/CSC730: Parallel Computing Parallel Computing Platforms Chapter 2 (2.4.1 2.4.4) Dr. Joe Zhang PDC-4: Topology 1 Content Parallel computing platforms Logical organization (a programmer s view) Control
CSC630/CSC730: Parallel Computing Parallel Computing Platforms Chapter 2 (2.4.1 2.4.4) Dr. Joe Zhang PDC-4: Topology 1 Content Parallel computing platforms Logical organization (a programmer s view) Control
Switching/Flow Control Overview. Interconnection Networks: Flow Control and Microarchitecture. Packets. Switching.
 Switching/Flow Control Overview Interconnection Networks: Flow Control and Microarchitecture Topology: determines connectivity of network Routing: determines paths through network Flow Control: determine
Switching/Flow Control Overview Interconnection Networks: Flow Control and Microarchitecture Topology: determines connectivity of network Routing: determines paths through network Flow Control: determine
Mass-Storage. ICS332 - Fall 2017 Operating Systems. Henri Casanova
 Mass-Storage ICS332 - Fall 2017 Operating Systems Henri Casanova (henric@hawaii.edu) Magnetic Disks! Magnetic disks (a.k.a. hard drives ) are (still) the most common secondary storage devices today! They
Mass-Storage ICS332 - Fall 2017 Operating Systems Henri Casanova (henric@hawaii.edu) Magnetic Disks! Magnetic disks (a.k.a. hard drives ) are (still) the most common secondary storage devices today! They
Multiprocessor Interconnection Networks
 Multiprocessor Interconnection Networks Todd C. Mowry CS 740 November 19, 1998 Topics Network design space Contention Active messages Networks Design Options: Topology Routing Direct vs. Indirect Physical
Multiprocessor Interconnection Networks Todd C. Mowry CS 740 November 19, 1998 Topics Network design space Contention Active messages Networks Design Options: Topology Routing Direct vs. Indirect Physical
CSE 153 Design of Operating Systems
 CSE 153 Design of Operating Systems Winter 2018 Lecture 22: File system optimizations and advanced topics There s more to filesystems J Standard Performance improvement techniques Alternative important
CSE 153 Design of Operating Systems Winter 2018 Lecture 22: File system optimizations and advanced topics There s more to filesystems J Standard Performance improvement techniques Alternative important
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
I/O, Disks, and RAID Yi Shi Fall Xi an Jiaotong University
 I/O, Disks, and RAID Yi Shi Fall 2017 Xi an Jiaotong University Goals for Today Disks How does a computer system permanently store data? RAID How to make storage both efficient and reliable? 2 What does
I/O, Disks, and RAID Yi Shi Fall 2017 Xi an Jiaotong University Goals for Today Disks How does a computer system permanently store data? RAID How to make storage both efficient and reliable? 2 What does
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. Motivation: Why Care About I/O? CPU Performance:
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. Motivation: Why Care About I/O? CPU Performance:
EE382 Processor Design. Illinois
 EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors Part II EE 382 Processor Design Winter 98/99 Michael Flynn 1 Illinois EE 382 Processor Design Winter 98/99 Michael Flynn 2 1 Write-invalidate
EE382 Processor Design Winter 1998 Chapter 8 Lectures Multiprocessors Part II EE 382 Processor Design Winter 98/99 Michael Flynn 1 Illinois EE 382 Processor Design Winter 98/99 Michael Flynn 2 1 Write-invalidate