Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture. Alexander Berreth. Markus Bühler, Benedikt Anlauf
|
|
|
- Sabrina Cross
- 5 years ago
- Views:
Transcription
1 PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland Research & Development GmbH Pascal Vezolle IBM Systems France
2 Coal Fired Power Station Source: 2











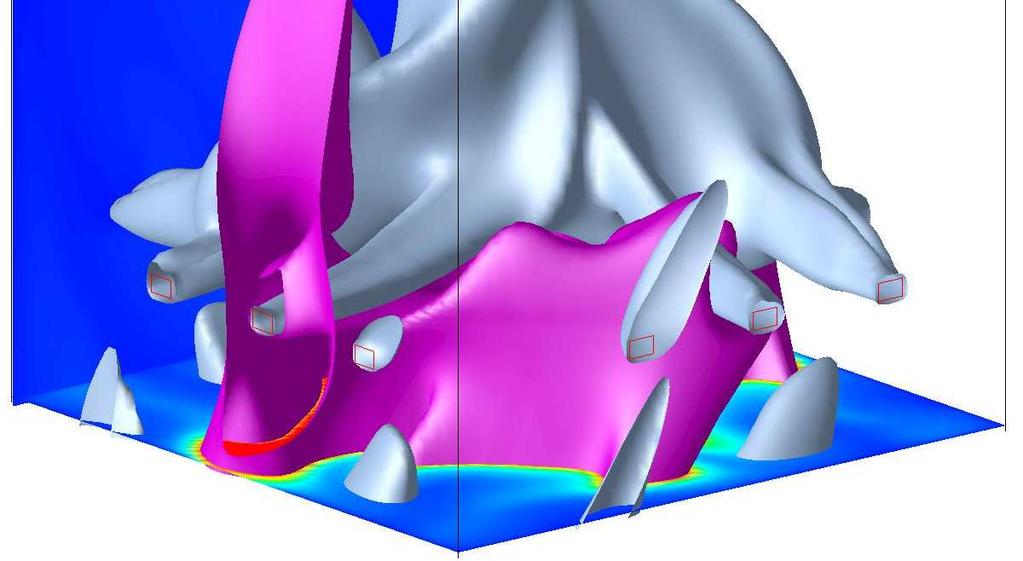
3 Simulation of the Combustion Process with RECOM-AIOLOS 3D-Boiler Model Visualisation of computational results Simulation using the in-house 3D-Combustion Simulation Code RECOM-AIOLOS on HPC Hardware Improved understanding of the process leads to: - Reduced Emissions (NOx, CO, ) - Higher Efficiency (CO2 reduction) - Higher Availability of the boiler Source: 3


4 3D-CFD Simulation Software RECOM-AIOLOS RECOM-AIOLOS contains models for the description of: Multi-Phase continuum mechanics for solid, liquid and gaseous fuels Combustion chemistry, pollutant formation and radiation/heat transfer 0-0 Mio cells Solves 00 non-linear coupled equations with - Billion unknowns Intense computational demand: e.g. up to 2 h on 6 Haswell nodes Validated against measured data from real, full scale power plants.


5 Performance evaluation of RECOM-AIOLOS 2-socket Intel Xeon E5-2680v3 (Haswell) node of Cray XC0 2 x 2 core 2.5 GHz 68 GB/s memory bandwidth Cray Fortran Compiler V Symbolic picture Source: 2-socket IBM S82L POWER8 node 2 x 0 core 3. GHz 230 GB/s memory bandwidth IBM xlf FORTRAN compiler V
6 2-Socket node POWER8 Memory Organization Socket 0 (CPU 0) POWER8 DCM P8-Chip NUMA node 0 P8-Chip NUMA node Core 0 Core Core 2 Core 3 Core Core 5 Socket (CPU ) POWER8 DCM Core 0 Core Core 2 Core 3 Core Core 5 P8-Chip NUMA node 2 P8-Chip NUMA node 3 Local memory access: Within Power Chip (NUMA node) Direct attachment of cores to memory controllers Near memory access: Between the Power Chips By intra-node communication paths Far memory access When connecting multiple nodes (not shown here) Core 6 Core 7 Core 8 Core 9 Core 6 Core 7 Core 8 Core 9 Local memory access is much faster than near or far memory access! 6
7 2-Socket node POWER8 Memory Organization Socket 0 (CPU 0) POWER8 DCM P8-Chip NUMA node 0 P8-Chip NUMA node Core 0 Core Core 2 Core 3 Core Core 5 Core 6 Core 7 Core 8 Core 9 Socket (CPU ) POWER8 DCM Core 0 Core Core 2 Core 3 Core Core 5 Core 6 Core 7 Core 8 Core 9 P8-Chip NUMA node 2 P8-Chip NUMA node 3 What does it mean: OpenMP Parallelization: First touch policy Core pinning to avoid thread migration Hybrid Parallelization (OpenMP + MPI): MPI ranks across NUMA nodes OpenMP within NUMA nodes vectorize loops loop lengths 75k 8.M Core pinning 7
8 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup using a hybrid parallelization approach 32 8 processes processes 2 processes OpenMP only Linear Speedup 8 2*0 cores (2 sockets) MPI process (rank) with 20 OpenMP threads (SMT) 2 MPI process on the node Number of Threads*MPI Processes 8
9 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup using a hybrid parallelization approach 32 8 processes processes 2 processes OpenMP only Linear Speedup 8 SMT 2 SMT2 SMT 20 Cores SMT8 MPI process on the node Number of Threads*MPI Processes 9
10 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup using a hybrid parallelization approach 32 8 processes processes 2 processes OpenMP only Linear Speedup 8 SMT 2 SMT2 SMT 20 Cores SMT8 MPI process on each socket Number of Threads*MPI Processes 0
11 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup using a hybrid parallelization approach 32 8 processes processes 2 processes OpenMP only Linear Speedup 8 SMT 2 SMT2 SMT 20 Cores SMT8 MPI process on each NUMA node Number of Threads*MPI Processes
12 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup using a hybrid parallelization approach Best Speedup 22.7 with SMT 32 8 processes processes 2 processes OpenMP only Linear Speedup 8 Difference because of short loops??? Speedup 5. without SMT SMT SMT2 SMT 20 Cores SMT8 2 Significant performance increase 2 MPI processes each NUMA node withon SMT No further performance increase with SMT Number of Threads*MPI Processes 2
13 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup using OpenMP with idealized test case 3D model of an idealized test case Numerical grid (structured) with 0 mio. cells in total No domain decomposition; only domain Loop length 0 mio elements Parallelization (OpenMP) and vectorization of the loops 3
14 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup: Hybrid vs. idealized OpenMP 32 Speedup 8 SMT SMT2 SMT SMT8 20 Cores 2 Idealized test case with OpenMP only Linear Number of Threads*MPI Processes



15 Single Node Performance of RECOM-AIOLOS on POWER8 RECOM-AIOLOS Speedup: Hybrid vs. idealized OpenMP 32 Speedup 8 2 SMT SMT2 SMT SMT8 20 Cores Excellent scaling with pure OpenMP parallelization when using long loops Real test case with 8 MPI processes Idealized test case with OpenMP only Linear NUMA placement seems to be OK Number of Threads*MPI Processes 5
16 Single Node Performance of RECOM-AIOLOS on Haswell RECOM-AIOLOS Speedup using a hybrid parallelization approach 32 8 processes processes 2 processes OpenMP only Linear Speedup 8 Best Speedup 2 cores + HT. 2 cores Speedup significantly lower compared to POWER8 but less dependent on the parallelization setting (Only 2 NUMA nodes on Haswell) 2 No performance gain with HT Number of Threads*MPI Processes
17 Single Node Performance of RECOM-AIOLOS Computing time (wall-clock-time) on POWER8 vs. Haswell Avg. comp. time for iteration [s] IBM Power 8 50 Intel Haswell Core2Core Node2Node 7
18 Single Node Performance of RECOM-AIOLOS Routine based computing time on POWER8 vs. Haswell Avg. comp. time for iteration [s] POWER8 slower High computational load POWER8 faster High memory transfer Further analysis (e.g. compiler output) revealed that major loops are unvectorized IBM Power 8 Intel Haswell 8
19 Summary The 3D-combustion simulation software RECOM-AIOLOS was successfully ported to the POWER8 hardware With proper NUMA memory allocation, an excellent speedup was achieved when using OpenMP or a hybrid (OpenMP + MPI) approach Significant performance gain was observed when using SMT Similar node to node performance of POWER8 and Haswell Memory intense routines were faster on POWER8 Compute intense routines were slower on POWER8, which could be attributed to a lack of vectorization on POWER8 9
Code Saturne on POWER8 clusters: First Investigations
 Code Saturne on POWER8 clusters: First Investigations C. MOULINEC, V. SZEREMI, D.R. EMERSON (STFC Daresbury Lab., UK) Y. FOURNIER (EDF R&D, FR) P. VEZOLLE, L. ENAULT (IBM Montpellier, FR) B. ANLAUF, M.
Code Saturne on POWER8 clusters: First Investigations C. MOULINEC, V. SZEREMI, D.R. EMERSON (STFC Daresbury Lab., UK) Y. FOURNIER (EDF R&D, FR) P. VEZOLLE, L. ENAULT (IBM Montpellier, FR) B. ANLAUF, M.
Porting and Optimisation of UM on ARCHER. Karthee Sivalingam, NCAS-CMS. HPC Workshop ECMWF JWCRP
 Porting and Optimisation of UM on ARCHER Karthee Sivalingam, NCAS-CMS HPC Workshop ECMWF JWCRP Acknowledgements! NCAS-CMS Bryan Lawrence Jeffrey Cole Rosalyn Hatcher Andrew Heaps David Hassell Grenville
Porting and Optimisation of UM on ARCHER Karthee Sivalingam, NCAS-CMS HPC Workshop ECMWF JWCRP Acknowledgements! NCAS-CMS Bryan Lawrence Jeffrey Cole Rosalyn Hatcher Andrew Heaps David Hassell Grenville
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
IFS migrates from IBM to Cray CPU, Comms and I/O
 IFS migrates from IBM to Cray CPU, Comms and I/O Deborah Salmond & Peter Towers Research Department Computing Department Thanks to Sylvie Malardel, Philippe Marguinaud, Alan Geer & John Hague and many
IFS migrates from IBM to Cray CPU, Comms and I/O Deborah Salmond & Peter Towers Research Department Computing Department Thanks to Sylvie Malardel, Philippe Marguinaud, Alan Geer & John Hague and many
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
LS-DYNA Scalability Analysis on Cray Supercomputers
 13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
IBM Information Technology Guide For ANSYS Fluent Customers
 IBM ISV & Developer Relations Manufacturing IBM Information Technology Guide For ANSYS Fluent Customers A collaborative effort between ANSYS and IBM 2 IBM Information Technology Guide For ANSYS Fluent
IBM ISV & Developer Relations Manufacturing IBM Information Technology Guide For ANSYS Fluent Customers A collaborative effort between ANSYS and IBM 2 IBM Information Technology Guide For ANSYS Fluent
CFD exercise. Regular domain decomposition
 CFD exercise Regular domain decomposition Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CFD exercise Regular domain decomposition Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
1. Many Core vs Multi Core. 2. Performance Optimization Concepts for Many Core. 3. Performance Optimization Strategy for Many Core
 1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Introducing Overdecomposition to Existing Applications: PlasComCM and AMPI
 Introducing Overdecomposition to Existing Applications: PlasComCM and AMPI Sam White Parallel Programming Lab UIUC 1 Introduction How to enable Overdecomposition, Asynchrony, and Migratability in existing
Introducing Overdecomposition to Existing Applications: PlasComCM and AMPI Sam White Parallel Programming Lab UIUC 1 Introduction How to enable Overdecomposition, Asynchrony, and Migratability in existing
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
Multicore Performance and Tools. Part 1: Topology, affinity, clock speed
 Multicore Performance and Tools Part 1: Topology, affinity, clock speed Tools for Node-level Performance Engineering Gather Node Information hwloc, likwid-topology, likwid-powermeter Affinity control and
Multicore Performance and Tools Part 1: Topology, affinity, clock speed Tools for Node-level Performance Engineering Gather Node Information hwloc, likwid-topology, likwid-powermeter Affinity control and
NUMA-aware OpenMP Programming
 NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
NUMA-aware OpenMP Programming Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group schmidl@itc.rwth-aachen.de Christian Terboven IT Center, RWTH Aachen University Deputy lead of the HPC
Bring your application to a new era:
 Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Bring your application to a new era: learning by example how to parallelize and optimize for Intel Xeon processor and Intel Xeon Phi TM coprocessor Manel Fernández, Roger Philp, Richard Paul Bayncore Ltd.
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Deutscher Wetterdienst
 Accelerating Work at DWD Ulrich Schättler Deutscher Wetterdienst Roadmap Porting operational models: revisited Preparations for enabling practical work at DWD My first steps with the COSMO on a GPU First
Accelerating Work at DWD Ulrich Schättler Deutscher Wetterdienst Roadmap Porting operational models: revisited Preparations for enabling practical work at DWD My first steps with the COSMO on a GPU First
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
Brief notes on setting up semi-high performance computing environments. July 25, 2014
 Brief notes on setting up semi-high performance computing environments July 25, 2014 1 We have two different computing environments for fitting demanding models to large space and/or time data sets. 1
Brief notes on setting up semi-high performance computing environments July 25, 2014 1 We have two different computing environments for fitting demanding models to large space and/or time data sets. 1
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
simulation framework for piecewise regular grids
 WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
WALBERLA, an ultra-scalable multiphysics simulation framework for piecewise regular grids ParCo 2015, Edinburgh September 3rd, 2015 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler
Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace
 Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace James Southern, Jim Tuccillo SGI 25 October 2016 0 Motivation Trend in HPC continues to be towards more
Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace James Southern, Jim Tuccillo SGI 25 October 2016 0 Motivation Trend in HPC continues to be towards more
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Performance and Energy Usage of Workloads on KNL and Haswell Architectures
 Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Performance and Energy Usage of Workloads on KNL and Haswell Architectures Tyler Allen 1 Christopher Daley 2 Doug Doerfler 2 Brian Austin 2 Nicholas Wright 2 1 Clemson University 2 National Energy Research
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Tianhe-2, the world s fastest supercomputer. Shaohua Wu Senior HPC application development engineer
 Tianhe-2, the world s fastest supercomputer Shaohua Wu Senior HPC application development engineer Inspur Inspur revenue 5.8 2010-2013 6.4 2011 2012 Unit: billion$ 8.8 2013 21% Staff: 14, 000+ 12% 10%
Tianhe-2, the world s fastest supercomputer Shaohua Wu Senior HPC application development engineer Inspur Inspur revenue 5.8 2010-2013 6.4 2011 2012 Unit: billion$ 8.8 2013 21% Staff: 14, 000+ 12% 10%
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
AACE: Applications. Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn-
 AACE: Applications R. Glenn Brook Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn- brook@tennessee.edu Ryan C. Hulguin Computational Science
AACE: Applications R. Glenn Brook Director, Application Acceleration Center of Excellence National Institute for Computational Sciences glenn- brook@tennessee.edu Ryan C. Hulguin Computational Science
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
Scientific Programming in C XIV. Parallel programming
 Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
Scientific Programming in C XIV. Parallel programming Susi Lehtola 11 December 2012 Introduction The development of microchips will soon reach the fundamental physical limits of operation quantum coherence
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Slurm Configuration Impact on Benchmarking
 Slurm Configuration Impact on Benchmarking José A. Moríñigo, Manuel Rodríguez-Pascual, Rafael Mayo-García CIEMAT - Dept. Technology Avda. Complutense 40, Madrid 28040, SPAIN Slurm User Group Meeting 16
Slurm Configuration Impact on Benchmarking José A. Moríñigo, Manuel Rodríguez-Pascual, Rafael Mayo-García CIEMAT - Dept. Technology Avda. Complutense 40, Madrid 28040, SPAIN Slurm User Group Meeting 16
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks
 An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
Binding Nested OpenMP Programs on Hierarchical Memory Architectures
 Binding Nested OpenMP Programs on Hierarchical Memory Architectures Dirk Schmidl, Christian Terboven, Dieter an Mey, and Martin Bücker {schmidl, terboven, anmey}@rz.rwth-aachen.de buecker@sc.rwth-aachen.de
Binding Nested OpenMP Programs on Hierarchical Memory Architectures Dirk Schmidl, Christian Terboven, Dieter an Mey, and Martin Bücker {schmidl, terboven, anmey}@rz.rwth-aachen.de buecker@sc.rwth-aachen.de
Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs
 Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs M. J. McNenly and R. A. Whitesides GPU Technology Conference March 27, 2014 San Jose, CA LLNL-PRES-652254! This work performed under
Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs M. J. McNenly and R. A. Whitesides GPU Technology Conference March 27, 2014 San Jose, CA LLNL-PRES-652254! This work performed under
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
6.1 Multiprocessor Computing Environment
 6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
The IBM Blue Gene/Q: Application performance, scalability and optimisation
 The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
Overview. Idea: Reduce CPU clock frequency This idea is well suited specifically for visualization
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Performance Impact of Resource Contention in Multicore Systems
 Performance Impact of Resource Contention in Multicore Systems R. Hood, H. Jin, P. Mehrotra, J. Chang, J. Djomehri, S. Gavali, D. Jespersen, K. Taylor, R. Biswas Commodity Multicore Chips in NASA HEC 2004:
Performance Impact of Resource Contention in Multicore Systems R. Hood, H. Jin, P. Mehrotra, J. Chang, J. Djomehri, S. Gavali, D. Jespersen, K. Taylor, R. Biswas Commodity Multicore Chips in NASA HEC 2004:
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Welcome. Virtual tutorial starts at BST
 Welcome Virtual tutorial starts at 15.00 BST Using KNL on ARCHER Adrian Jackson With thanks to: adrianj@epcc.ed.ac.uk @adrianjhpc Harvey Richardson from Cray Slides from Intel Xeon Phi Knights Landing
Welcome Virtual tutorial starts at 15.00 BST Using KNL on ARCHER Adrian Jackson With thanks to: adrianj@epcc.ed.ac.uk @adrianjhpc Harvey Richardson from Cray Slides from Intel Xeon Phi Knights Landing
Modern CPU Architectures
 Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Multi-GPU simulations in OpenFOAM with SpeedIT technology.
 Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
OPTIMIZATION OF THE CODE OF THE NUMERICAL MAGNETOSHEATH-MAGNETOSPHERE MODEL
 Journal of Theoretical and Applied Mechanics, Sofia, 2013, vol. 43, No. 2, pp. 77 82 OPTIMIZATION OF THE CODE OF THE NUMERICAL MAGNETOSHEATH-MAGNETOSPHERE MODEL P. Dobreva Institute of Mechanics, Bulgarian
Journal of Theoretical and Applied Mechanics, Sofia, 2013, vol. 43, No. 2, pp. 77 82 OPTIMIZATION OF THE CODE OF THE NUMERICAL MAGNETOSHEATH-MAGNETOSPHERE MODEL P. Dobreva Institute of Mechanics, Bulgarian
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Hybrid (MPP+OpenMP) version of LS-DYNA
 version of LS-DYNA") Hybrid (MPP+OpenMP) version of LS-DYNA LS-DYNA Forum 2011 Jason Wang Oct. 12, 2011 Outline 1) Why MPP HYBRID 2) What is HYBRID 3) Benefits 4) How to use HYBRID Why HYBRID LS-DYNA LS-DYNA/MPP Speedup, 10M
Hybrid (MPP+OpenMP) version of LS-DYNA LS-DYNA Forum 2011 Jason Wang Oct. 12, 2011 Outline 1) Why MPP HYBRID 2) What is HYBRID 3) Benefits 4) How to use HYBRID Why HYBRID LS-DYNA LS-DYNA/MPP Speedup, 10M
Advanced Job Launching. mapping applications to hardware
 Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
Advanced Job Launching mapping applications to hardware A Quick Recap - Glossary of terms Hardware This terminology is used to cover hardware from multiple vendors Socket The hardware you can touch and
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Non-uniform memory access (NUMA)
") Non-uniform memory access (NUMA) Memory access between processor core to main memory is not uniform. Memory resides in separate regions called NUMA domains. For highest performance, cores should only access
Non-uniform memory access (NUMA) Memory access between processor core to main memory is not uniform. Memory resides in separate regions called NUMA domains. For highest performance, cores should only access
Glenn Luecke, Olga Weiss, Marina Kraeva, James Coyle, James Hoekstra High Performance Computing Group Iowa State University Ames, Iowa, USA May 2010
 Glenn Luecke, Olga Weiss, Marina Kraeva, James Coyle, James Hoekstra High Performance Computing Group Iowa State University Ames, Iowa, USA May 2010 Professor Glenn Luecke - Iowa State University 2010
Glenn Luecke, Olga Weiss, Marina Kraeva, James Coyle, James Hoekstra High Performance Computing Group Iowa State University Ames, Iowa, USA May 2010 Professor Glenn Luecke - Iowa State University 2010
Memory Footprint of Locality Information On Many-Core Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25
 ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
ROME Workshop @ IPDPS Vancouver Memory Footprint of Locality Information On Many- Platforms Brice Goglin Inria Bordeaux Sud-Ouest France 2018/05/25 Locality Matters to HPC Applications Locality Matters
Molecular Modelling and the Cray XC30 Performance Counters. Michael Bareford, ARCHER CSE Team
 Molecular Modelling and the Cray XC30 Performance Counters Michael Bareford, ARCHER CSE Team michael.bareford@epcc.ed.ac.uk Reusing this material This work is licensed under a Creative Commons Attribution-
Molecular Modelling and the Cray XC30 Performance Counters Michael Bareford, ARCHER CSE Team michael.bareford@epcc.ed.ac.uk Reusing this material This work is licensed under a Creative Commons Attribution-
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster
 Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster G. Jost*, H. Jin*, D. an Mey**,F. Hatay*** *NASA Ames Research Center **Center for Computing and Communication, University of
Comparing the OpenMP, MPI, and Hybrid Programming Paradigm on an SMP Cluster G. Jost*, H. Jin*, D. an Mey**,F. Hatay*** *NASA Ames Research Center **Center for Computing and Communication, University of
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Transport Simulations beyond Petascale. Jing Fu (ANL)
") Transport Simulations beyond Petascale Jing Fu (ANL) A) Project Overview The project: Peta- and exascale algorithms and software development (petascalable codes: Nek5000, NekCEM, NekLBM) Science goals:
Transport Simulations beyond Petascale Jing Fu (ANL) A) Project Overview The project: Peta- and exascale algorithms and software development (petascalable codes: Nek5000, NekCEM, NekLBM) Science goals:
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
Dr. Ilia Bermous, the Australian Bureau of Meteorology. Acknowledgements to Dr. Martyn Corden (Intel), Dr. Zhang Zhang (Intel), Dr. Martin Dix (CSIRO)
, Dr. Zhang Zhang (Intel), Dr. Martin Dix (CSIRO)") Performance, accuracy and bit-reproducibility aspects in handling transcendental functions with Cray and Intel compilers for the Met Office Unified Model Dr. Ilia Bermous, the Australian Bureau of Meteorology
Performance, accuracy and bit-reproducibility aspects in handling transcendental functions with Cray and Intel compilers for the Met Office Unified Model Dr. Ilia Bermous, the Australian Bureau of Meteorology
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Acknowledgments. Amdahl s Law. Contents. Programming with MPI Parallel programming. 1 speedup = (1 P )+ P N. Type to enter text
+ P N. Type to enter text") Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Application Performance on Dual Processor Cluster Nodes
 Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs
 Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs C.-C. Su a, C.-W. Hsieh b, M. R. Smith b, M. C. Jermy c and J.-S. Wu a a Department of Mechanical Engineering, National Chiao Tung
Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs C.-C. Su a, C.-W. Hsieh b, M. R. Smith b, M. C. Jermy c and J.-S. Wu a a Department of Mechanical Engineering, National Chiao Tung
Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method
 Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method G. Wellein, T. Zeiser, G. Hager HPC Services Regional Computing Center A. Nitsure, K. Iglberger, U. Rüde Chair for System
Introducing a Cache-Oblivious Blocking Approach for the Lattice Boltzmann Method G. Wellein, T. Zeiser, G. Hager HPC Services Regional Computing Center A. Nitsure, K. Iglberger, U. Rüde Chair for System
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Cray XE6 Performance Workshop
 Cray XE6 Performance Workshop Multicore Programming Overview Shared memory systems Basic Concepts in OpenMP Brief history of OpenMP Compiling and running OpenMP programs 2 1 Shared memory systems OpenMP
Cray XE6 Performance Workshop Multicore Programming Overview Shared memory systems Basic Concepts in OpenMP Brief history of OpenMP Compiling and running OpenMP programs 2 1 Shared memory systems OpenMP
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems presented by Wayne Joubert Motivation Design trends are leading to non-power of 2 core counts for multicore processors, due to layout constraints
Performance of Variant Memory Configurations for Cray XT Systems presented by Wayne Joubert Motivation Design trends are leading to non-power of 2 core counts for multicore processors, due to layout constraints
Почему IBM POWER8 оптимальная платформа для PostgreSQL
 Почему IBM POWER8 оптимальная платформа для PostgreSQL Иван Гончаров Технический специалист igoncharov@ru.ibm.com What server should I choose for PG? 2 Old-fashioned approach Slides borrowed from Bruce
Почему IBM POWER8 оптимальная платформа для PostgreSQL Иван Гончаров Технический специалист igoncharov@ru.ibm.com What server should I choose for PG? 2 Old-fashioned approach Slides borrowed from Bruce
New Features in LS-DYNA HYBRID Version
 11 th International LS-DYNA Users Conference Computing Technology New Features in LS-DYNA HYBRID Version Nick Meng 1, Jason Wang 2, Satish Pathy 2 1 Intel Corporation, Software and Services Group 2 Livermore
11 th International LS-DYNA Users Conference Computing Technology New Features in LS-DYNA HYBRID Version Nick Meng 1, Jason Wang 2, Satish Pathy 2 1 Intel Corporation, Software and Services Group 2 Livermore
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn