Data Mining: Principles and Algorithms Mining Data Streams
|
|
|
- Shanon Hall
- 6 years ago
- Views:
Transcription
1 Data Mining: Principles and Algorithms Mining Data Streams Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign Jiawei Han. All rights reserved. 1

2 2
3 Mining Data Streams What is stream data? Why Stream Data Systems? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 3
4 Characteristics of Data Streams Data Streams Data streams continuous, ordered, changing, fast, huge amount Traditional DBMS data stored in finite, persistent data sets Characteristics Huge volumes of continuous data, possibly infinite Fast changing and requires fast, real-time response Data stream captures nicely our data processing needs of today Random access is expensive single scan algorithm (can only have one look) Store only the summary of the data seen thus far Most stream data are at pretty low-level or multi-dimensional in nature, needs multi-level and multi-dimensional processing 4
5 Stream Data Applications Telecommunication calling records Business: credit card transaction flows Network monitoring and traffic engineering Financial market: stock exchange Engineering & industrial processes: power supply & manufacturing Sensor, monitoring & surveillance: video streams, RFIDs Security monitoring Web logs and Web page click streams Massive data sets (even saved but random access is too expensive) 5
6 DBMS versus DSMS Persistent relations One-time queries Random access Unbounded disk store Only current state matters No real-time services Relatively low update rate Data at any granularity Assume precise data Access plan determined by query processor, physical DB design Transient streams Continuous queries Sequential access Bounded main memory Historical data is important Real-time requirements Possibly multi-gb arrival rate Data at fine granularity Data stale/imprecise Unpredictable/variable data arrival and characteristics Ack. From Motwani s PODS tutorial slides 6
7 Mining Data Streams What is stream data? Why Stream Data Systems? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 7

8 Architecture: Stream Query Processing SDMS (Stream Data Management System) User/Application Continuous Query Results Multiple streams Stream Query Processor Scratch Space (Main memory and/or Disk) 8
9 Challenges of Stream Data Processing Multiple, continuous, rapid, time-varying, ordered streams Main memory computations Queries are often continuous Evaluated continuously as stream data arrives Answer updated over time Queries are often complex Beyond element-at-a-time processing Beyond stream-at-a-time processing Beyond relational queries (scientific, data mining, OLAP) Multi-level/multi-dimensional processing and data mining Most stream data are at low-level or multi-dimensional in nature 9
10 Processing Stream Queries Query types One-time query vs. continuous query (being evaluated continuously as stream continues to arrive) Predefined query vs. ad-hoc query (issued on-line) Unbounded memory requirements For real-time response, main memory algorithm should be used Memory requirement is unbounded if one will join future tuples Approximate query answering With bounded memory, it is not always possible to produce exact answers High-quality approximate answers are desired Data reduction and synopsis construction methods Sketches, random sampling, histograms, wavelets, etc. 10
11 Methodologies for Stream Data Processing Major challenges Keep track of a large universe, e.g., pairs of IP address, not ages Methodology Synopses (trade-off between accuracy and storage): A summary given in brief terms that covers the major points of a subject matter Use synopsis data structure, much smaller (O(log k N) space) than their base data set (O(N) space) Compute an approximate answer within a small error range (factor ε of the actual answer) Major methods Random sampling Histograms Sliding windows Multi-resolution model Sketches Radomized algorithms 11
12 Stream Data Processing Methods (1) Random sampling (but without knowing the total length in advance) Reservoir sampling: maintains a set of s candidates in the reservoir, which form a true random sample of the element seen so far in the stream. As the data stream flow, every new element has a certain probability (s/n) of replacing an old element in the reservoir. Sliding windows Make decisions based only on recent data of sliding window size w An element arriving at time t expires at time t + w Histograms Approximate the frequency distribution of element values in a stream Partition data into a set of contiguous buckets Equal-width (equal value range for buckets) vs. V-optimal (minimizing frequency variance within each bucket) Multi-resolution models Popular models: balanced binary trees, micro-clusters, and wavelets 12
13 Stream Data Processing Methods (2) Sketches Histograms and wavelets require multi-passes over the data but sketches can operate in a single pass v k F Frequency moments of a stream A = {a 1,, a N }, F k : k m i where v: the universe or domain size, m i: the frequency of i in the sequence Given N elements and v values, sketches can approximate F 0, F 1, F 2 in O(log v + log N) space Randomized algorithms Monte Carlo algorithm: bound on running time but may not return correct result Chebyshev s inequality: P( X k) 2 k Let X be a random variable with mean μ and standard deviation σ Chernoff bound: P[ X (1 ) ] e Let X be the sum of independent Poisson trials X 1,, X n, δ in (0, 1] The probability decreases exponentially as we move from the mean 2 2 / 4 i 1 13
14 Approximate Query Answering in Streams Sliding windows Only over sliding windows of recent stream data Approximation but often more desirable in applications Batched processing, sampling and synopses Batched if update is fast but computing is slow Compute periodically, not very timely Sampling if update is slow but computing is fast Compute using sample data, but not good for joins, etc. Synopsis data structures Maintain a small synopsis or sketch of data Good for querying historical data Blocking operators, e.g., sorting, avg, min, etc. Blocking if unable to produce the first output until seeing the entire input 14
: telecom streams Niagara (OGI/Wisconsin): Internet XML databases OpenCQ (Georgia Tech): triggers, incr.")
15 Projects on DSMS (Data Stream Management System) Research projects and system prototypes STREAM (Stanford): A general-purpose DSMS Cougar (Cornell): sensors Aurora (Brown/MIT): sensor monitoring, dataflow Hancock (AT&T): telecom streams Niagara (OGI/Wisconsin): Internet XML databases OpenCQ (Georgia Tech): triggers, incr. view maintenance Tapestry (Xerox): pub/sub content-based filtering Telegraph (Berkeley): adaptive engine for sensors Tradebot ( stock tickers & streams Tribeca (Bellcore): network monitoring MAIDS (UIUC/NCSA): Mining Alarming Incidents in Data Streams 15
16 Stream Data Mining vs. Stream Querying Stream mining A more challenging task in many cases It shares most of the difficulties with stream querying But often requires less precision, e.g., no join, grouping, sorting Patterns are hidden and more general than querying It may require exploratory analysis Not necessarily continuous queries Stream data mining tasks Multi-dimensional on-line analysis of streams Mining outliers and unusual patterns in stream data Clustering data streams Classification of stream data 16
17 Mining Data Streams What is stream data? Why Stream Data Systems? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 17
18 Challenges for Mining Dynamics in Data Streams Most stream data are at pretty low-level or multidimensional in nature: needs ML/MD processing Analysis requirements Multi-dimensional trends and unusual patterns Capturing important changes at multi-dimensions/levels Fast, real-time detection and response Comparing with data cube: Similarity and differences Stream (data) cube or stream OLAP: Is this feasible? Can we implement it efficiently? 18
19 Multi-Dimensional Stream Analysis: Examples Analysis of Web click streams Raw data at low levels: seconds, web page addresses, user IP addresses, Analysts want: changes, trends, unusual patterns, at reasonable levels of details E.g., Average clicking traffic in North America on sports in the last 15 minutes is 40% higher than that in the last 24 hours. Analysis of power consumption streams Raw data: power consumption flow for every household, every minute Patterns one may find: average hourly power consumption surges up 30% for manufacturing companies in Chicago in the last 2 hours today than that of the same day a week ago 19
20 A Stream Cube Architecture A tilted time frame Different time granularities second, minute, quarter, hour, day, week, Critical layers Minimum interest layer (m-layer) Observation layer (o-layer) User: watches at o-layer and occasionally needs to drill-down down to m-layer Partial materialization of stream cubes Full materialization: too space and time consuming No materialization: slow response at query time Partial materialization: what do we mean partial? 20
21 Cube: A Lattice of Cuboids all time item location supplier 0-D(apex) cuboid 1-D cuboids time,item time,location item,location location,supplier time,supplier item,supplier 2-D cuboids time,location,supplier time,item,location time,item,supplier item,location,supplier 3-D cuboids 4-D(base) cuboid time, item, location, supplier 21
22 Time Dimension: A Titled Time Model Natural tilted time frame: Example: Minimal: 15min, then 4 * 15mins 1 hour, 24 hours day, Logarithmic tilted time frame: Example: Minimal: 1 minute, then 1, 2, 4, 8, 16, 32, 64t 32t 16t 8t 4t 2t t t Time 22
23 A Titled Time Model (2) Pyramidal tilted time frame: Example: Suppose there are 5 frames and each takes maximal 3 snapshots Given a snapshot number N, if N mod 2 d = 0, insert into the frame number d. If there are more than 3 snapshots, kick out the oldest one. Frame no. Snapshots (by clock time)
24 Two Critical Layers in the Stream Cube (*, theme, quarter) o-layer (observation) (user-group, URL-group, minute) m-layer (minimal interest) (individual-user, URL, second) (primitive) stream data layer 24
25 OLAP Operation and Cube Materialization OLAP( Online Analytical Processing) operations: Roll up (drill-up): summarize data by climbing up hierarchy or by dimension reduction Drill down (roll down): reverse of roll-up from higher level summary to lower level summary or detailed data, or introducing new dimensions Slice and dice: project and select Pivot (rotate): reorient the cube, visualization, 3D to series of 2D planes Cube partial materialization Store some pre-computed cuboids for fast online processing 25
26 On-Line Partial Materialization vs. OLAP Processing On-line materialization Materialization takes precious space and time Only incremental materialization (with tilted time frame) Only materialize cuboids of the critical layers? Online computation may take too much time Preferred solution: popular-path approach: Materializing those along the popular drilling paths H-tree structure: Such cuboids can be computed and stored efficiently using the H-tree structure Online aggregation vs. query-based computation Online computing while streaming: aggregating stream cubes Query-based computation: using computed cuboids 26
27 Stream Cube Structure: From m-layer to o-layer (A1, *, C1) (A1, *, C2) (A1, B1, C1) (A2, *, C1) (A1, B1, C2) (A1, B2, C1) (A2, *, C2) (A2, B1, C1) (A1, B2, C2) (A2, B1, C2) (A2, B2, C1) (A2, B2, C2) 27
28 An H-Tree Cubing Structure root Observation layer Chicago Urbana Springfield.com.edu.com.gov Minimal int. layer Elec Chem Elec Bio 6:00AM-7:00AM 156 7:00AM-8:00AM 201 8:00AM-9:00AM
29 Benefits of H-Tree and H-Cubing H-tree and H-cubing Developed for computing data cubes and ice-berg cubes J. Han, J. Pei, G. Dong, and K. Wang, Efficient Computation of Iceberg Cubes with Complex Measures, SIGMOD'01 Fast cubing, space preserving in cube computation Using H-tree for stream cubing Space preserving Intermediate aggregates can be computed incrementally and saved in tree nodes Facilitate computing other cells and multi-dimensional analysis H-tree with computed cells can be viewed as stream cube 29
30 Mining Data Streams What is stream data? Why Stream Data Systems? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 30
31 What Is Frequent Pattern Analysis? Frequent pattern: A pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set First proposed by Agrawal, Imielinski, and Swami [AIS93] in the context of frequent itemsets and association rule mining Motivation: Finding inherent regularities in data What products were often purchased together? Beer and diapers?! What are the subsequent purchases after buying a PC? What kinds of DNA are sensitive to this new drug? Can we automatically classify web documents? Applications Basket data analysis, cross-marketing, catalog design, sale campaign analysis, Web log (click stream) analysis, and DNA sequence analysis. 31
32 Frequent Patterns for Stream Data Frequent pattern mining is valuable in stream applications e.g., network intrusion mining (Dokas et al., 02) Mining precise freq. patterns in stream data: unrealistic Even store them in a compressed form, such as FPtree How to mine frequent patterns with good approximation? Approximate frequent patterns (Manku & Motwani, VLDB 02) Keep only current frequent patterns? No changes can be detected Mining evolution freq. patterns (C. Giannella, J. Han, X. Yan, P.S. Yu, 2003) Use tilted time window frame Mining evolution and dramatic changes of frequent patterns Space-saving computation of frequent and top-k elements (Metwally, Agrawal, and El Abbadi, ICDT'05) 32
33 Mining Approximate Frequent Patterns Mining precise freq. patterns in stream data: unrealistic Even store them in a compressed form, such as FPtree Approximate answers are often sufficient (e.g., trend/pattern analysis) Example: A router is interested in all flows: whose frequency is at least 1% (σ) of the entire traffic stream seen so far and feels that 1/10 of σ (ε = 0.1%) error is comfortable How to mine frequent patterns with good approximation? Lossy Counting Algorithm (Manku & Motwani, VLDB 02) Major ideas: not tracing items until it becomes frequent Adv: guaranteed error bound Disadv: keep a large set of traces 33
34 Lossy Counting for Frequent Single Items Bucket 1 Bucket 2 Bucket 3 Divide stream into buckets (bucket size is 1/ ε = 1000) 34
35 First Bucket of Stream Empty (summary) + At bucket boundary, decrease all counters by 1 35
36 Next Bucket of Stream + At bucket boundary, decrease all counters by 1 36
37 Approximation Guarantee Given: (1) support threshold: σ, (2) error threshold: ε, and (3) stream length N Output: items with frequency counts exceeding (σ ε) N How much do we undercount? If stream length seen so far = N and bucket-size = 1/ε then frequency count error #buckets = N/bucket-size = N/(1/ε) = εn Approximation guarantee No false negatives False positives have true frequency count at least (σ ε)n Frequency count underestimated by at most εn 37
38 Lossy Counting For Frequent Itemsets Divide Stream into Buckets as for frequent items But fill as many buckets as possible in main memory one time Bucket 1 Bucket 2 Bucket 3 If we put 3 buckets of data into main memory one time, then decrease each frequency count by 3 38
39 Update of Summary Data Structure summary data 3 bucket data in memory summary data Itemset ( ) is deleted. That s why we choose a large number of buckets delete more 39
40 Pruning Itemsets Apriori Rule summary data 3 bucket data in memory If we find itemset ( ) is not frequent itemset, then we needn t consider its superset 40
41 Summary of Lossy Counting Strength A simple idea Can be extended to frequent itemsets Weakness: Space bound is not good For frequent itemsets, they do scan each record many times The output is based on all previous data. But sometimes, we are only interested in recent data A space-saving method for stream frequent item mining Metwally, Agrawal, and El Abbadi, ICDT'05 41
42 Mining Evolution of Frequent Patterns for Stream Data Approximate frequent patterns (Manku & Motwani VLDB 02) Keep only current frequent patterns No changes can be detected Mining evolution and dramatic changes of frequent patterns (Giannella, Han, Yan, Yu, 2003) Use tilted time window frame Use compressed form to store significant (approximate) frequent patterns and their time-dependent traces Note: To mine precise counts, one has to trace/keep a fixed (and small) set of items 42
43 Mining Data Streams What is stream data? Why Stream Data Systems? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 43
44 Classification Methods Classification: Model construction based on training sets Typical classification methods Decision tree induction Bayesian classification Rule-based classification Neural network approach Support Vector Machines (SVM) Associative classification K-Nearest neighbor approach Other methods Are they all good for stream classification? 44
45 Classification for Dynamic Data Streams Decision tree induction for stream data classification VFDT (Very Fast Decision Tree)/CVFDT (Domingos, Hulten, Spencer, KDD00/KDD01) Is decision-tree good for modeling fast changing data, e.g., stock market analysis? Other stream classification methods Instead of decision-trees, consider other models Naïve Bayesian Ensemble (Wang, Fan, Yu, Han. KDD 03) K-nearest neighbors (Aggarwal, Han, Wang, Yu. KDD 04) Classifying skewed stream data (Gao, Fan, and Han, SDM'07) Evolution modeling: Tilted time framework, incremental updating, dynamic maintenance, and model construction Comparing of models to find changes 45
46 Build Very Fast Decision Trees Based on Hoeffding Inequality (Domingos, et al., KDD 00) Hoeffding's inequality: A result in probability theory that gives an upper bound on the probability for the sum of random variables to deviate from its expected value Based on Hoeffding Bound principle, classifying different samples leads to the same model with high probability can use a small set of samples Hoeffding Bound (Additive Chernoff Bound) Given: r: random variable, R: range of r, N: # independent observations True mean of r is at least r avg ε, with probability 1 δ (where δ is user-specified) R 2 ln(1/ 2N ) 46
47 Decision-Tree Induction with Data Streams Packets > 10 yes no Data Stream Protocol = http Bytes > 60K yes Packets > 10 yes no Protocol = http Data Stream Protocol = ftp Ack. From Gehrke s SIGMOD tutorial slides 47
48 Hoeffding Tree: Strengths and Weaknesses Strengths Scales better than traditional methods Sublinear with sampling Very small memory utilization Incremental Make class predictions in parallel New examples are added as they come Weakness Could spend a lot of time with ties Memory used with tree expansion Number of candidate attributes 48
49 CVFDT (Concept-adapting VFDT) Concept Drift Time-changing data streams Incorporate new and eliminate old CVFDT Increments count with new example Decrement old example Sliding window Nodes assigned monotonically increasing IDs Grows alternate subtrees When alternate more accurate => replace old O(w) better runtime than VFDT-window 49
50 Ensemble of Classifiers Algorithm H. Wang, W. Fan, P. S. Yu, and J. Han, Mining Concept- Drifting Data Streams using Ensemble Classifiers, KDD'03. Method (derived from the ensemble idea in classification) train K classifiers from K chunks for each subsequent chunk train a new classifier test other classifiers against the chunk assign weight to each classifier select top K classifiers 50
51 Classifying Data Streams with Skewed Distribution Stream Classification: Construct a classification model based on past records Use the model to predict labels for new data Help decision making Concept drifts: Define and analyze concept drifts in data streams Show that expected error is not directly related to concept drifts Classify data stream with skewed distribution (i.e., rare events) Employ both biased sampling and ensemble techniques Results indicate the proposed method reduces classification errors on the minority class 51
52 Concept Drifts Changes in P(x, y) x-feature vector y-class label P(x,y) = P(y x)p(x) Four possibilities: No change: P(y x), P(x) remain unchanged Feature change: only P(x) changes Conditional change: only P(y x) changes Dual change: both P(y x) and P(x) changes Expected error: No matter how concept changes, the expected error could increase, decrease, or remain unchanged Training on the most recent data could help reduce expected error 52
53 Issues in stream classification Descriptive model vs. generative model Generative models assume data follows some distribution while descriptive models make no assumptions Distribution of stream data is unknown and may evolve, so descriptive model is better Label prediction vs. probability estimation Classify test examples into one class or estimate P(y x) for each y Probability estimation is better: Stream applications may be stochastic (an example could be assigned to several classes with different probabilities) Probability estimates provide confidence information and could be used in post processing 53
54 Mining Skewed Data Stream Skewed distribution Seen in many stream applications where positive examples are much less popular than the negative ones. Credit card fraud detection, network intrusion detection Existing stream classification methods Evaluate their methods on data with balanced class distribution Problems of these methods on skewed data: Tend to ignore positive examples due to the small number The cost of misclassifying positive examples is usually huge, e.g., misclassifying credit card fraud as normal 54
55 Stream Ensemble Approach (1)? S 1 S 2 S m S m+1 Classification Model S m as training data? Positive examples not sufficient! 55
56 Stream Ensemble Approach (2) Sampling Ensemble Sm S 1 S 2? C 1 C 2 C k 56
57 Analysis Error Reduction: Sampling: Ensemble: Efficiency Analysis: Single model: Ensemble: Ensemble is more efficient 57

58 Experiments: Mean Squared Error on Synthetic Data Test on concept-drift streams 58

59 Experiments: Mean Squared Error on Real Data Test on real data 59
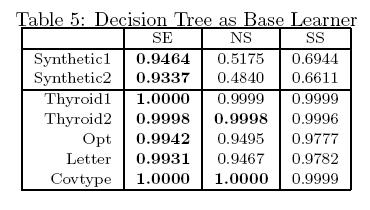

60 Experiments: Model Accuracy Model accuracy 60
61 Training time Experiments: Efficiency 61
62 Mining Data Streams What is stream data? Why Stream Data Systems? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 62
63 Cluster Analysis Methods Cluster Analysis: Grouping similar objects into clusters Types of data in cluster analysis Numerical, categorical, high-dimensional, Major Clustering Methods Partitioning Methods Hierarchical Methods Density-Based Methods Grid-Based Methods Model-Based Methods Clustering High-Dimensional Data Constraint-Based Clustering Outlier Analysis: often a by-product of cluster analysis 63
64 Stream Clustering: A K-Median Approach O'Callaghan et al., Streaming-Data Algorithms for High-Quality Clustering, (ICDE'02) Base on the k-median method Data stream points from metric space Find k clusters in the stream s.t. the sum of distances from data points to their closest center is minimized Constant factor approximation algorithm In small space, a simple two step algorithm: 1. For each set of M records, S i, find O(k) centers in S 1,, S l Local clustering: Assign each point in S i to its closest center 2. Let S be centers for S 1,, S l with each center weighted by number of points assigned to it Cluster S to find k centers 64
65 Hierarchical Clustering Tree level-(i+1) medians level-i medians data points 65
66 Hierarchical Tree and Drawbacks Method: maintain at most m level-i medians On seeing m of them, generate O(k) level-(i+1) medians of weight equal to the sum of the weights of the intermediate medians assigned to them Drawbacks: Low quality for evolving data streams (register only k centers) Limited functionality in discovering and exploring clusters over different portions of the stream over time 66
67 Clustering for Mining Stream Dynamics Network intrusion detection: one example Detect bursts of activities or abrupt changes in real time by online clustering Our methodology (C. Agarwal, J. Han, J. Wang, P.S. Yu, VLDB 03) Tilted time frame work: o.w. dynamic changes cannot be found Micro-clustering: better quality than k-means/k-median incremental, online processing and maintenance) Two stages: micro-clustering and macro-clustering With limited overhead to achieve high efficiency, scalability, quality of results and power of evolution/change detection 67
68 CluStream: A Framework for Clustering Evolving Data Streams Design goal High quality for clustering evolving data streams with greater functionality While keep the stream mining requirement in mind One-pass over the original stream data Limited space usage and high efficiency CluStream: A framework for clustering evolving data streams Divide the clustering process into online and offline components Online component: periodically stores summary statistics about the stream data Offline component: answers various user questions based on the stored summary statistics 68
69 BIRCH: A Micro-Clustering Approach Clustering Feature: CF = (N, LS, SS) where N: # data points, LS =, SS = N i 1 X i N i 1 X i 2 B = 7 L = 6 CF 1 CF 2 Root child 1 child 2 child 3 child 6 CF 3 CF 6 CF 1 CF 2 Non-leaf node child 1 child 2 child 3 child 5 CF 3 CF 5 Leaf node Leaf node prev CF 1 CF 2 CF 6 next prev CF 1 CF 2 CF 4 next 69
70 Micro-cluster The CluStream Framework Statistical information about data locality Temporal extension of the cluster-feature vector CF2, CF1, CF2 X... X... T1... Tk... Multi-dimensional points with time stamps x x t t, CF1, 1 k Each point contains d dimensions, i.e., n i X x... A micro-cluster for n points is defined as a (2.d + 3) tuple Pyramidal time frame Decide at what moments the snapshots of the statistical information are stored away on disk 1 i x d i 70
71 CluStream: Pyramidal Time Frame Pyramidal time frame Snapshots of a set of micro-clusters are stored following the pyramidal pattern They are stored at differing levels of granularity depending on the recency Snapshots are classified into different orders varying from 1 to log(t) The i-th order snapshots occur at intervals of α i where α 1 Only the last (α + 1) snapshots are stored 71
72 CluStream: Clustering On-line Streams Online micro-cluster maintenance Initial creation of q micro-clusters q is usually significantly larger than the number of natural clusters Online incremental update of micro-clusters If new point is within max-boundary, insert into the microcluster o.w., create a new cluster May delete obsolete micro-cluster or merge two closest ones Query-based macro-clustering Based on a user-specified time-horizon h and the number of macro-clusters k, compute macroclusters using the k-means algorithm 72
73 Mining Data Streams What is stream data? Why SDS? Stream data management systems: Issues and solutions Stream data cube and multidimensional OLAP analysis Stream frequent pattern analysis Stream classification Stream cluster analysis Research issues 73
74 Stream Data Mining: Research Issues Mining sequential patterns in data streams Mining partial periodicity in data streams Mining outliers and unusual patterns for botnet detection Stream clustering Multi-dimensional clustering analysis Cluster not confined to 2-D metric space, how to incorporate other features, especially non-numerical properties Stream clustering with other clustering approaches Constraint-based cluster analysis with data streams Real-time stream data mining in cyberphysical systems 74
75 Summary: Stream Data Mining Stream data mining: A rich and on-going research field Current research focus in database community: DSMS system architecture, continuous query processing, supporting mechanisms Stream data mining and stream OLAP analysis Powerful tools for finding general and unusual patterns Effectiveness, efficiency and scalability: lots of open problems Our philosophy on stream data analysis and mining A multi-dimensional stream analysis framework Time is a special dimension: Tilted time frame What to compute and what to save? Critical layers Partial materialization and precomputation Mining dynamics of stream data 75
76 References on Stream Data Mining (1) C. Aggarwal, J. Han, J. Wang, P. S. Yu, A Framework for Clustering Data Streams, VLDB'03 C. C. Aggarwal, J. Han, J. Wang and P. S. Yu, On-Demand Classification of Evolving Data Streams, KDD'04 C. Aggarwal, J. Han, J. Wang, and P. S. Yu, A Framework for Projected Clustering of High Dimensional Data Streams, VLDB'04 S. Babu and J. Widom, Continuous Queries over Data Streams, SIGMOD Record, Sept B. Babcock, S. Babu, M. Datar, R. Motwani and J. Widom, Models and Issues in Data Stream Systems, PODS'02. Y. Chen, G. Dong, J. Han, B. W. Wah, and J. Wang, Multi-Dimensional Regression Analysis of Time-Series Data Streams, VLDB'02 P. Domingos and G. Hulten, Mining high-speed data streams, KDD'00 A. Dobra, M. N. Garofalakis, J. Gehrke, and R. Rastogi, Processing Complex Aggregate Queries over Data Streams, SIGMOD 02 J. Gehrke, F. Korn, and D. Srivastava, On computing correlated aggregates over continuous data streams, SIGMOD'01 J. Gao, W. Fan, and J. Han, A General Framework for Mining Concept-Drifting Data Streams with Skewed Distributions, SDM'07. 76
77 References on Stream Data Mining (2) S. Guha, N. Mishra, R. Motwani, and L. O'Callaghan, Clustering Data Streams, FOCS'00 G. Hulten, L. Spencer and P. Domingos, Mining time-changing data streams, KDD 01 S. Madden, M. Shah, J. Hellerstein, V. Raman, Continuously Adaptive Continuous Queries over Streams, SIGMOD 02 G. Manku, R. Motwani, Approximate Frequency Counts over Data Streams, VLDB 02 A. Metwally, D. Agrawal, and A. El Abbadi. Efficient Computation of Frequent and Top-k Elements in Data Streams. ICDT'05 S. Muthukrishnan, Data streams: algorithms and applications, Proc 2003 ACM-SIAM Symp. Discrete Algorithms, 2003 R. Motwani and P. Raghavan, Randomized Algorithms, Cambridge Univ. Press, 1995 S. Viglas and J. Naughton, Rate-Based Query Optimization for Streaming Information Sources, SIGMOD 02 Y. Zhu and D. Shasha. StatStream: Statistical Monitoring of Thousands of Data Streams in Real Time, VLDB 02 H. Wang, W. Fan, P. S. Yu, and J. Han, Mining Concept-Drifting Data Streams using Ensemble Classifiers, KDD'03 77

78 78
Mining Data Streams Data Mining and Text Mining (UIC Politecnico di Milano) Daniele Loiacono
 Daniele Loiacono") Mining Data Streams Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data
Mining Data Streams Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann Series in Data
Mining Data Streams. From Data-Streams Management System Queries to Knowledge Discovery from continuous and fast-evolving Data Records.
 DATA STREAMS MINING Mining Data Streams From Data-Streams Management System Queries to Knowledge Discovery from continuous and fast-evolving Data Records. Hammad Haleem Xavier Plantaz APPLICATIONS Sensors
DATA STREAMS MINING Mining Data Streams From Data-Streams Management System Queries to Knowledge Discovery from continuous and fast-evolving Data Records. Hammad Haleem Xavier Plantaz APPLICATIONS Sensors
Data Mining: Concepts and Techniques. Chapter Mining data streams
 Data Mining: Concepts and Techniques Chapter 8 8.1. Mining data streams Jiawei Han and Micheline Kamber Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006
Data Mining: Concepts and Techniques Chapter 8 8.1. Mining data streams Jiawei Han and Micheline Kamber Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006
Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams
![Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams](/thumbs/85/93020188.jpg "Mining Data Streams. Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction. Summarization Methods. Clustering Data Streams") Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
Mining Data Streams Outline [Garofalakis, Gehrke & Rastogi 2002] Introduction Summarization Methods Clustering Data Streams Data Stream Classification Temporal Models CMPT 843, SFU, Martin Ester, 1-06
MAIDS: Mining Alarming Incidents from Data Streams
 MAIDS: Mining Alarming Incidents from Data Streams (Demonstration Proposal) Y. Dora Cai David Clutter Greg Pape Jiawei Han Michael Welge Loretta Auvil Automated Learning Group, NCSA, University of Illinois
MAIDS: Mining Alarming Incidents from Data Streams (Demonstration Proposal) Y. Dora Cai David Clutter Greg Pape Jiawei Han Michael Welge Loretta Auvil Automated Learning Group, NCSA, University of Illinois
Clustering from Data Streams
 Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting
Clustering from Data Streams João Gama LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 Introduction 2 Clustering Micro Clustering 3 Clustering Time Series Growing the Structure Adapting
Data Mining: Concepts and Techniques. Chap 8. Data Streams, Time Series Data, and. Sequential Patterns. Li Xiong
 Data Mining: Concepts and Techniques Chap 8. Data Streams, Time Series Data, and Sequential Patterns Li Xiong Slides credits: Jiawei Han and Micheline Kamber and others March 27, 2008 Data Mining: Concepts
Data Mining: Concepts and Techniques Chap 8. Data Streams, Time Series Data, and Sequential Patterns Li Xiong Slides credits: Jiawei Han and Micheline Kamber and others March 27, 2008 Data Mining: Concepts
Mining Unusual Patterns by Multi-Dimensional Analysis of Data Streams
 Mining Unusual Patterns by Multi-Dimensional Analysis of Data Streams Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign Email: hanj@cs.uiuc.edu Abstract It has been popularly
Mining Unusual Patterns by Multi-Dimensional Analysis of Data Streams Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign Email: hanj@cs.uiuc.edu Abstract It has been popularly
Mining Frequent Itemsets for data streams over Weighted Sliding Windows
 Mining Frequent Itemsets for data streams over Weighted Sliding Windows Pauray S.M. Tsai Yao-Ming Chen Department of Computer Science and Information Engineering Minghsin University of Science and Technology
Mining Frequent Itemsets for data streams over Weighted Sliding Windows Pauray S.M. Tsai Yao-Ming Chen Department of Computer Science and Information Engineering Minghsin University of Science and Technology
Data Cube Technology
 Data Cube Technology Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ s.manegold@liacs.leidenuniv.nl e.m.bakker@liacs.leidenuniv.nl
Data Cube Technology Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/ s.manegold@liacs.leidenuniv.nl e.m.bakker@liacs.leidenuniv.nl
CS570 Introduction to Data Mining
 CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
Extended R-Tree Indexing Structure for Ensemble Stream Data Classification
 Extended R-Tree Indexing Structure for Ensemble Stream Data Classification P. Sravanthi M.Tech Student, Department of CSE KMM Institute of Technology and Sciences Tirupati, India J. S. Ananda Kumar Assistant
Extended R-Tree Indexing Structure for Ensemble Stream Data Classification P. Sravanthi M.Tech Student, Department of CSE KMM Institute of Technology and Sciences Tirupati, India J. S. Ananda Kumar Assistant
Data Cube Technology. Chapter 5: Data Cube Technology. Data Cube: A Lattice of Cuboids. Data Cube: A Lattice of Cuboids
 Chapter 5: Data Cube Technology Data Cube Technology Data Cube Computation: Basic Concepts Data Cube Computation Methods Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/
Chapter 5: Data Cube Technology Data Cube Technology Data Cube Computation: Basic Concepts Data Cube Computation Methods Erwin M. Bakker & Stefan Manegold https://homepages.cwi.nl/~manegold/dbdm/ http://liacs.leidenuniv.nl/~bakkerem2/dbdm/
Chapter 1, Introduction
 CSI 4352, Introduction to Data Mining Chapter 1, Introduction Young-Rae Cho Associate Professor Department of Computer Science Baylor University What is Data Mining? Definition Knowledge Discovery from
CSI 4352, Introduction to Data Mining Chapter 1, Introduction Young-Rae Cho Associate Professor Department of Computer Science Baylor University What is Data Mining? Definition Knowledge Discovery from
1. General. 2. Stream. 3. Aurora. 4. Conclusion
 1. General 2. Stream 3. Aurora 4. Conclusion 1. Motivation Applications 2. Definition of Data Streams 3. Data Base Management System (DBMS) vs. Data Stream Management System(DSMS) 4. Stream Projects interpreting
1. General 2. Stream 3. Aurora 4. Conclusion 1. Motivation Applications 2. Definition of Data Streams 3. Data Base Management System (DBMS) vs. Data Stream Management System(DSMS) 4. Stream Projects interpreting
Table Of Contents: xix Foreword to Second Edition
 Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Data Mining : Concepts and Techniques Table Of Contents: Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments xxxi About the Authors xxxv Chapter 1 Introduction 1 (38) 1.1 Why Data
Frequent Patterns mining in time-sensitive Data Stream
 Frequent Patterns mining in time-sensitive Data Stream Manel ZARROUK 1, Mohamed Salah GOUIDER 2 1 University of Gabès. Higher Institute of Management of Gabès 6000 Gabès, Gabès, Tunisia zarrouk.manel@gmail.com
Frequent Patterns mining in time-sensitive Data Stream Manel ZARROUK 1, Mohamed Salah GOUIDER 2 1 University of Gabès. Higher Institute of Management of Gabès 6000 Gabès, Gabès, Tunisia zarrouk.manel@gmail.com
Mining Frequent Itemsets from Data Streams with a Time- Sensitive Sliding Window
 Mining Frequent Itemsets from Data Streams with a Time- Sensitive Sliding Window Chih-Hsiang Lin, Ding-Ying Chiu, Yi-Hung Wu Department of Computer Science National Tsing Hua University Arbee L.P. Chen
Mining Frequent Itemsets from Data Streams with a Time- Sensitive Sliding Window Chih-Hsiang Lin, Ding-Ying Chiu, Yi-Hung Wu Department of Computer Science National Tsing Hua University Arbee L.P. Chen
Stream Sequential Pattern Mining with Precise Error Bounds
 Stream Sequential Pattern Mining with Precise Error Bounds Luiz F. Mendes,2 Bolin Ding Jiawei Han University of Illinois at Urbana-Champaign 2 Google Inc. lmendes@google.com {bding3, hanj}@uiuc.edu Abstract
Stream Sequential Pattern Mining with Precise Error Bounds Luiz F. Mendes,2 Bolin Ding Jiawei Han University of Illinois at Urbana-Champaign 2 Google Inc. lmendes@google.com {bding3, hanj}@uiuc.edu Abstract
Volume 2, Issue 2, February 2014 International Journal of Advance Research in Computer Science and Management Studies
 Volume 2, Issue 2, February 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com Mining
Volume 2, Issue 2, February 2014 International Journal of Advance Research in Computer Science and Management Studies Research Article / Paper / Case Study Available online at: www.ijarcsms.com Mining
Contents. Foreword to Second Edition. Acknowledgments About the Authors
 Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Contents Foreword xix Foreword to Second Edition xxi Preface xxiii Acknowledgments About the Authors xxxi xxxv Chapter 1 Introduction 1 1.1 Why Data Mining? 1 1.1.1 Moving toward the Information Age 1
Nesnelerin İnternetinde Veri Analizi
 Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
DATA STREAMS: MODELS AND ALGORITHMS
 DATA STREAMS: MODELS AND ALGORITHMS DATA STREAMS: MODELS AND ALGORITHMS Edited by CHARU C. AGGARWAL IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 Kluwer Academic Publishers Boston/Dordrecht/London
DATA STREAMS: MODELS AND ALGORITHMS DATA STREAMS: MODELS AND ALGORITHMS Edited by CHARU C. AGGARWAL IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 Kluwer Academic Publishers Boston/Dordrecht/London
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R,
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Chapter 5, Data Cube Computation
 CSI 4352, Introduction to Data Mining Chapter 5, Data Cube Computation Young-Rae Cho Associate Professor Department of Computer Science Baylor University A Roadmap for Data Cube Computation Full Cube Full
CSI 4352, Introduction to Data Mining Chapter 5, Data Cube Computation Young-Rae Cho Associate Professor Department of Computer Science Baylor University A Roadmap for Data Cube Computation Full Cube Full
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 07 : 06/11/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 07 : 06/11/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Chapter 4: Mining Frequent Patterns, Associations and Correlations
 Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY
 INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK REAL TIME DATA SEARCH OPTIMIZATION: AN OVERVIEW MS. DEEPASHRI S. KHAWASE 1, PROF.
INTERNATIONAL JOURNAL OF PURE AND APPLIED RESEARCH IN ENGINEERING AND TECHNOLOGY A PATH FOR HORIZING YOUR INNOVATIVE WORK REAL TIME DATA SEARCH OPTIMIZATION: AN OVERVIEW MS. DEEPASHRI S. KHAWASE 1, PROF.
This tutorial has been prepared for computer science graduates to help them understand the basic-to-advanced concepts related to data mining.
 About the Tutorial Data Mining is defined as the procedure of extracting information from huge sets of data. In other words, we can say that data mining is mining knowledge from data. The tutorial starts
About the Tutorial Data Mining is defined as the procedure of extracting information from huge sets of data. In other words, we can say that data mining is mining knowledge from data. The tutorial starts
Association Rule Mining. Entscheidungsunterstützungssysteme
 Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Data Mining: Concepts and Techniques. Chapter 5. SS Chung. April 5, 2013 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Queries on streams
DATA WAREHOUING UNIT I
 BHARATHIDASAN ENGINEERING COLLEGE NATTRAMAPALLI DEPARTMENT OF COMPUTER SCIENCE SUB CODE & NAME: IT6702/DWDM DEPT: IT Staff Name : N.RAMESH DATA WAREHOUING UNIT I 1. Define data warehouse? NOV/DEC 2009
BHARATHIDASAN ENGINEERING COLLEGE NATTRAMAPALLI DEPARTMENT OF COMPUTER SCIENCE SUB CODE & NAME: IT6702/DWDM DEPT: IT Staff Name : N.RAMESH DATA WAREHOUING UNIT I 1. Define data warehouse? NOV/DEC 2009
Data Mining and Analytics. Introduction
 Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
A Framework for Clustering Massive Text and Categorical Data Streams
 A Framework for Clustering Massive Text and Categorical Data Streams Charu C. Aggarwal IBM T. J. Watson Research Center charu@us.ibm.com Philip S. Yu IBM T. J.Watson Research Center psyu@us.ibm.com Abstract
A Framework for Clustering Massive Text and Categorical Data Streams Charu C. Aggarwal IBM T. J. Watson Research Center charu@us.ibm.com Philip S. Yu IBM T. J.Watson Research Center psyu@us.ibm.com Abstract
CS377: Database Systems Data Warehouse and Data Mining. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Data Warehouse and Data Mining Li Xiong Department of Mathematics and Computer Science Emory University 1 1960s: Evolution of Database Technology Data collection, database creation,
CS377: Database Systems Data Warehouse and Data Mining Li Xiong Department of Mathematics and Computer Science Emory University 1 1960s: Evolution of Database Technology Data collection, database creation,
Random Sampling over Data Streams for Sequential Pattern Mining
 Random Sampling over Data Streams for Sequential Pattern Mining Chedy Raïssi LIRMM, EMA-LGI2P/Site EERIE 161 rue Ada 34392 Montpellier Cedex 5, France France raissi@lirmm.fr Pascal Poncelet EMA-LGI2P/Site
Random Sampling over Data Streams for Sequential Pattern Mining Chedy Raïssi LIRMM, EMA-LGI2P/Site EERIE 161 rue Ada 34392 Montpellier Cedex 5, France France raissi@lirmm.fr Pascal Poncelet EMA-LGI2P/Site
Database and Knowledge-Base Systems: Data Mining. Martin Ester
 Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/24/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 High dim. data
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
Quotient Cube: How to Summarize the Semantics of a Data Cube
 Quotient Cube: How to Summarize the Semantics of a Data Cube Laks V.S. Lakshmanan (Univ. of British Columbia) * Jian Pei (State Univ. of New York at Buffalo) * Jiawei Han (Univ. of Illinois at Urbana-Champaign)
Quotient Cube: How to Summarize the Semantics of a Data Cube Laks V.S. Lakshmanan (Univ. of British Columbia) * Jian Pei (State Univ. of New York at Buffalo) * Jiawei Han (Univ. of Illinois at Urbana-Champaign)
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
What Is Data Mining? CMPT 354: Database I -- Data Mining 2
 Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Warehousing & Mining. Data integration. OLTP versus OLAP. CPS 116 Introduction to Database Systems
 Data Warehousing & Mining CPS 116 Introduction to Database Systems Data integration 2 Data resides in many distributed, heterogeneous OLTP (On-Line Transaction Processing) sources Sales, inventory, customer,
Data Warehousing & Mining CPS 116 Introduction to Database Systems Data integration 2 Data resides in many distributed, heterogeneous OLTP (On-Line Transaction Processing) sources Sales, inventory, customer,
Data mining techniques for data streams mining
 REVIEW OF COMPUTER ENGINEERING STUDIES ISSN: 2369-0755 (Print), 2369-0763 (Online) Vol. 4, No. 1, March, 2017, pp. 31-35 DOI: 10.18280/rces.040106 Licensed under CC BY-NC 4.0 A publication of IIETA http://www.iieta.org/journals/rces
REVIEW OF COMPUTER ENGINEERING STUDIES ISSN: 2369-0755 (Print), 2369-0763 (Online) Vol. 4, No. 1, March, 2017, pp. 31-35 DOI: 10.18280/rces.040106 Licensed under CC BY-NC 4.0 A publication of IIETA http://www.iieta.org/journals/rces
Jarek Szlichta Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques
 Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Roadmap DB Sys. Design & Impl. Association rules - outline. Citations. Association rules - idea. Association rules - idea.
 15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
Pattern Mining. Knowledge Discovery and Data Mining 1. Roman Kern KTI, TU Graz. Roman Kern (KTI, TU Graz) Pattern Mining / 42
 Pattern Mining / 42") Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Data Stream Mining. Tore Risch Dept. of information technology Uppsala University Sweden
 Data Stream Mining Tore Risch Dept. of information technology Uppsala University Sweden 2016-02-25 Enormous data growth Read landmark article in Economist 2010-02-27: http://www.economist.com/node/15557443/
Data Stream Mining Tore Risch Dept. of information technology Uppsala University Sweden 2016-02-25 Enormous data growth Read landmark article in Economist 2010-02-27: http://www.economist.com/node/15557443/
Data Streams. Models and Issues in Data Stream Systems. Meta-Questions. Executive Summary. Sample Applications. Data Stream Management System
 Models and Issues in Data Stream Systems Rajeev Motwani Stanford University (with Brian Babcock, Shivnath Babu, Mayur Datar, and Jennifer Widom) STREAM Project Members: Arvind Arasu, Gurmeet Manku, Liadan
Models and Issues in Data Stream Systems Rajeev Motwani Stanford University (with Brian Babcock, Shivnath Babu, Mayur Datar, and Jennifer Widom) STREAM Project Members: Arvind Arasu, Gurmeet Manku, Liadan
Frequent Pattern Mining in Data Streams. Raymond Martin
 Frequent Pattern Mining in Data Streams Raymond Martin Agenda -Breakdown & Review -Importance & Examples -Current Challenges -Modern Algorithms -Stream-Mining Algorithm -How KPS Works -Combing KPS and
Frequent Pattern Mining in Data Streams Raymond Martin Agenda -Breakdown & Review -Importance & Examples -Current Challenges -Modern Algorithms -Stream-Mining Algorithm -How KPS Works -Combing KPS and
GUJARAT TECHNOLOGICAL UNIVERSITY MASTER OF COMPUTER APPLICATIONS (MCA) Semester: IV
 Semester: IV") GUJARAT TECHNOLOGICAL UNIVERSITY MASTER OF COMPUTER APPLICATIONS (MCA) Semester: IV Subject Name: Elective I Data Warehousing & Data Mining (DWDM) Subject Code: 2640005 Learning Objectives: To understand
GUJARAT TECHNOLOGICAL UNIVERSITY MASTER OF COMPUTER APPLICATIONS (MCA) Semester: IV Subject Name: Elective I Data Warehousing & Data Mining (DWDM) Subject Code: 2640005 Learning Objectives: To understand
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/25/2013 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 3 In many data mining
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Warehousing and Data Mining. Announcements (December 1) Data integration. CPS 116 Introduction to Database Systems
 Data integration. CPS 116 Introduction to Database Systems") Data Warehousing and Data Mining CPS 116 Introduction to Database Systems Announcements (December 1) 2 Homework #4 due today Sample solution available Thursday Course project demo period has begun! Check
Data Warehousing and Data Mining CPS 116 Introduction to Database Systems Announcements (December 1) 2 Homework #4 due today Sample solution available Thursday Course project demo period has begun! Check
Chapter 6: Basic Concepts: Association Rules. Basic Concepts: Frequent Patterns. (absolute) support, or, support. (relative) support, s, is the
 support, or, support. (relative) support, s, is the") Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Incremental Learning Algorithm for Dynamic Data Streams
 338 IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.9, September 2008 Incremental Learning Algorithm for Dynamic Data Streams Venu Madhav Kuthadi, Professor,Vardhaman College
338 IJCSNS International Journal of Computer Science and Network Security, VOL.8 No.9, September 2008 Incremental Learning Algorithm for Dynamic Data Streams Venu Madhav Kuthadi, Professor,Vardhaman College
INSTITUTE OF AERONAUTICAL ENGINEERING (Autonomous) Dundigal, Hyderabad
 Dundigal, Hyderabad") INSTITUTE OF AERONAUTICAL ENGINEERING (Autonomous) Dundigal, Hyderabad - 500 043 INFORMATION TECHNOLOGY DEFINITIONS AND TERMINOLOGY Course Name : DATA WAREHOUSING AND DATA MINING Course Code : AIT006 Program
INSTITUTE OF AERONAUTICAL ENGINEERING (Autonomous) Dundigal, Hyderabad - 500 043 INFORMATION TECHNOLOGY DEFINITIONS AND TERMINOLOGY Course Name : DATA WAREHOUSING AND DATA MINING Course Code : AIT006 Program
Mining Frequent Patterns in Data Streams at Multiple Time Granularities
 Chapter 3 Mining Frequent Patterns in Data Streams at Multiple Time Granularities Chris Giannella,JiaweiHan y,jianpei z, Xifeng Yan y, Philip S. Yu ] Indiana University, cgiannel@cs.indiana.edu y University
Chapter 3 Mining Frequent Patterns in Data Streams at Multiple Time Granularities Chris Giannella,JiaweiHan y,jianpei z, Xifeng Yan y, Philip S. Yu ] Indiana University, cgiannel@cs.indiana.edu y University
Data Preprocessing Yudho Giri Sucahyo y, Ph.D , CISA
 Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Nesnelerin İnternetinde Veri Analizi
 Nesnelerin İnternetinde Veri Analizi Bölüm 3. Classification in Data Streams w3.gazi.edu.tr/~suatozdemir Supervised vs. Unsupervised Learning (1) Supervised learning (classification) Supervision: The training
Nesnelerin İnternetinde Veri Analizi Bölüm 3. Classification in Data Streams w3.gazi.edu.tr/~suatozdemir Supervised vs. Unsupervised Learning (1) Supervised learning (classification) Supervision: The training
An Improved Apriori Algorithm for Association Rules
 Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
An Overview of various methodologies used in Data set Preparation for Data mining Analysis
 An Overview of various methodologies used in Data set Preparation for Data mining Analysis Arun P Kuttappan 1, P Saranya 2 1 M. E Student, Dept. of Computer Science and Engineering, Gnanamani College of
An Overview of various methodologies used in Data set Preparation for Data mining Analysis Arun P Kuttappan 1, P Saranya 2 1 M. E Student, Dept. of Computer Science and Engineering, Gnanamani College of
Deakin Research Online
 Deakin Research Online This is the published version: Saha, Budhaditya, Lazarescu, Mihai and Venkatesh, Svetha 27, Infrequent item mining in multiple data streams, in Data Mining Workshops, 27. ICDM Workshops
Deakin Research Online This is the published version: Saha, Budhaditya, Lazarescu, Mihai and Venkatesh, Svetha 27, Infrequent item mining in multiple data streams, in Data Mining Workshops, 27. ICDM Workshops
Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently New challenges: with a
 Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
USC Real-time Pattern Isolation and Recognition Over Immersive Sensor Data Streams
 Real-time Pattern Isolation and Recognition Over Immersive Sensor Data Streams Cyrus Shahabi and Donghui Yan Integrated Media Systems Center and Computer Science Department, University of Southern California
Real-time Pattern Isolation and Recognition Over Immersive Sensor Data Streams Cyrus Shahabi and Donghui Yan Integrated Media Systems Center and Computer Science Department, University of Southern California
Data warehouse and Data Mining
 Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Chapter 4 Data Mining A Short Introduction
 Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CT75 (ALCCS) DATA WAREHOUSING AND DATA MINING JUN
 DATA WAREHOUSING AND DATA MINING JUN") Q.1 a. Define a Data warehouse. Compare OLTP and OLAP systems. Data Warehouse: A data warehouse is a subject-oriented, integrated, time-variant, and 2 Non volatile collection of data in support of management
Q.1 a. Define a Data warehouse. Compare OLTP and OLAP systems. Data Warehouse: A data warehouse is a subject-oriented, integrated, time-variant, and 2 Non volatile collection of data in support of management
What is a Data Warehouse?
 What is a Data Warehouse? COMP 465 Data Mining Data Warehousing Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Defined in many different ways,
What is a Data Warehouse? COMP 465 Data Mining Data Warehousing Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Defined in many different ways,
Data Stream Clustering Using Micro Clusters
 Data Stream Clustering Using Micro Clusters Ms. Jyoti.S.Pawar 1, Prof. N. M.Shahane. 2 1 PG student, Department of Computer Engineering K. K. W. I. E. E. R., Nashik Maharashtra, India 2 Assistant Professor
Data Stream Clustering Using Micro Clusters Ms. Jyoti.S.Pawar 1, Prof. N. M.Shahane. 2 1 PG student, Department of Computer Engineering K. K. W. I. E. E. R., Nashik Maharashtra, India 2 Assistant Professor
Sampling for Sequential Pattern Mining: From Static Databases to Data Streams
 Sampling for Sequential Pattern Mining: From Static Databases to Data Streams Chedy Raïssi LIRMM, EMA-LGI2P/Site EERIE 161 rue Ada 34392 Montpellier Cedex 5, France raissi@lirmm.fr Pascal Poncelet EMA-LGI2P/Site
Sampling for Sequential Pattern Mining: From Static Databases to Data Streams Chedy Raïssi LIRMM, EMA-LGI2P/Site EERIE 161 rue Ada 34392 Montpellier Cedex 5, France raissi@lirmm.fr Pascal Poncelet EMA-LGI2P/Site
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 3/6/2012 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 In many data mining
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING
 SHRI ANGALAMMAN COLLEGE OF ENGINEERING & TECHNOLOGY (An ISO 9001:2008 Certified Institution) SIRUGANOOR,TRICHY-621105. DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year / Semester: IV/VII CS1011-DATA
SHRI ANGALAMMAN COLLEGE OF ENGINEERING & TECHNOLOGY (An ISO 9001:2008 Certified Institution) SIRUGANOOR,TRICHY-621105. DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year / Semester: IV/VII CS1011-DATA
Product presentations can be more intelligently planned
 Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Data Mining Concepts
 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms Sequential
Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms Sequential
Frequent Pattern Mining
 Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Data Preprocessing. Why Data Preprocessing? MIT-652 Data Mining Applications. Chapter 3: Data Preprocessing. Multi-Dimensional Measure of Data Quality
 Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
Why Data Preprocessing? Data in the real world is dirty incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data e.g., occupation = noisy: containing
DOI:: /ijarcsse/V7I1/0111
 Volume 7, Issue 1, January 2017 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey on
Volume 7, Issue 1, January 2017 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey on
Challenges in Ubiquitous Data Mining
 LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 2 Very-short-term Forecasting in Photovoltaic Systems 3 4 Problem Formulation: Network Data Model Querying Model Query = Q( n i=0 S i)
LIAAD-INESC Porto, University of Porto, Portugal jgama@fep.up.pt 1 2 Very-short-term Forecasting in Photovoltaic Systems 3 4 Problem Formulation: Network Data Model Querying Model Query = Q( n i=0 S i)
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Batch-Incremental vs. Instance-Incremental Learning in Dynamic and Evolving Data
 Batch-Incremental vs. Instance-Incremental Learning in Dynamic and Evolving Data Jesse Read 1, Albert Bifet 2, Bernhard Pfahringer 2, Geoff Holmes 2 1 Department of Signal Theory and Communications Universidad
Batch-Incremental vs. Instance-Incremental Learning in Dynamic and Evolving Data Jesse Read 1, Albert Bifet 2, Bernhard Pfahringer 2, Geoff Holmes 2 1 Department of Signal Theory and Communications Universidad
COMP 465: Data Mining Still More on Clustering
 3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
ON CLUSTERING MASSIVE DATA STREAMS: A SUMMARIZATION PARADIGM
 Chapter 2 ON CLUSTERING MASSIVE DATA STREAMS: A SUMMARIZATION PARADIGM Cham C. Aggarwal IBM Z J. Watson Research Center Hawthorne, W 1053.2 Jiawei Han University of Illinois at Urbana-Champaign Urbana,
Chapter 2 ON CLUSTERING MASSIVE DATA STREAMS: A SUMMARIZATION PARADIGM Cham C. Aggarwal IBM Z J. Watson Research Center Hawthorne, W 1053.2 Jiawei Han University of Illinois at Urbana-Champaign Urbana,
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 5
 Chapter 5") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013 Han, Kamber & Pei. All rights
Building Fuzzy Blocks from Data Cubes
 Building Fuzzy Blocks from Data Cubes Yeow Wei Choong HELP University College Kuala Lumpur MALAYSIA choongyw@help.edu.my Anne Laurent Dominique Laurent LIRMM ETIS Université Montpellier II Université de
Building Fuzzy Blocks from Data Cubes Yeow Wei Choong HELP University College Kuala Lumpur MALAYSIA choongyw@help.edu.my Anne Laurent Dominique Laurent LIRMM ETIS Université Montpellier II Université de
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Unit # 1 1 Acknowledgement Several Slides in this presentation are taken from course slides provided by Han and Kimber (Data Mining Concepts and Techniques) and Tan,
Knowledge Discovery and Data Mining Unit # 1 1 Acknowledgement Several Slides in this presentation are taken from course slides provided by Han and Kimber (Data Mining Concepts and Techniques) and Tan,
Data Mining: Exploring Data. Lecture Notes for Chapter 3
 Data Mining: Exploring Data Lecture Notes for Chapter 3 1 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include
Data Mining: Exploring Data Lecture Notes for Chapter 3 1 What is data exploration? A preliminary exploration of the data to better understand its characteristics. Key motivations of data exploration include
Robust Clustering for Tracking Noisy Evolving Data Streams
 Robust Clustering for Tracking Noisy Evolving Data Streams Olfa Nasraoui Carlos Rojas Abstract We present a new approach for tracking evolving and noisy data streams by estimating clusters based on density,
Robust Clustering for Tracking Noisy Evolving Data Streams Olfa Nasraoui Carlos Rojas Abstract We present a new approach for tracking evolving and noisy data streams by estimating clusters based on density,
Code No: R Set No. 1
 Code No: R05321204 Set No. 1 1. (a) Draw and explain the architecture for on-line analytical mining. (b) Briefly discuss the data warehouse applications. [8+8] 2. Briefly discuss the role of data cube
Code No: R05321204 Set No. 1 1. (a) Draw and explain the architecture for on-line analytical mining. (b) Briefly discuss the data warehouse applications. [8+8] 2. Briefly discuss the role of data cube
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
A Framework for Clustering Evolving Data Streams
 VLDB 03 Paper ID: 312 A Framework for Clustering Evolving Data Streams Charu C. Aggarwal, Jiawei Han, Jianyong Wang, Philip S. Yu IBM T. J. Watson Research Center & UIUC charu@us.ibm.com, hanj@cs.uiuc.edu,
VLDB 03 Paper ID: 312 A Framework for Clustering Evolving Data Streams Charu C. Aggarwal, Jiawei Han, Jianyong Wang, Philip S. Yu IBM T. J. Watson Research Center & UIUC charu@us.ibm.com, hanj@cs.uiuc.edu,
Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Data mining - detailed outline. Problem
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
SCHEME OF COURSE WORK. Data Warehousing and Data mining
 SCHEME OF COURSE WORK Course Details: Course Title Course Code Program: Specialization: Semester Prerequisites Department of Information Technology Data Warehousing and Data mining : 15CT1132 : B.TECH
SCHEME OF COURSE WORK Course Details: Course Title Course Code Program: Specialization: Semester Prerequisites Department of Information Technology Data Warehousing and Data mining : 15CT1132 : B.TECH
B561 Advanced Database Concepts Streaming Model. Qin Zhang 1-1
 B561 Advanced Database Concepts 2.2. Streaming Model Qin Zhang 1-1 Data Streams Continuous streams of data elements (massive possibly unbounded, rapid, time-varying) Some examples: 1. network monitoring
B561 Advanced Database Concepts 2.2. Streaming Model Qin Zhang 1-1 Data Streams Continuous streams of data elements (massive possibly unbounded, rapid, time-varying) Some examples: 1. network monitoring
Mining Frequent Itemsets in Time-Varying Data Streams
 Mining Frequent Itemsets in Time-Varying Data Streams Abstract A transactional data stream is an unbounded sequence of transactions continuously generated, usually at a high rate. Mining frequent itemsets
Mining Frequent Itemsets in Time-Varying Data Streams Abstract A transactional data stream is an unbounded sequence of transactions continuously generated, usually at a high rate. Mining frequent itemsets
Lecture 7. Data Stream Mining. Building decision trees
 1 / 26 Lecture 7. Data Stream Mining. Building decision trees Ricard Gavaldà MIRI Seminar on Data Streams, Spring 2015 Contents 2 / 26 1 Data Stream Mining 2 Decision Tree Learning Data Stream Mining 3
1 / 26 Lecture 7. Data Stream Mining. Building decision trees Ricard Gavaldà MIRI Seminar on Data Streams, Spring 2015 Contents 2 / 26 1 Data Stream Mining 2 Decision Tree Learning Data Stream Mining 3