Clustering Part 4 DBSCAN
|
|
|
- Cory Hodge
- 6 years ago
- Views:
Transcription
1 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of points within a specified radius (Eps) A point is a core point if it has more than specified number of points (MinPts) within Eps Core point is in the interior of a cluster A border point has fewer than MinPts within Eps but is in neighborhood of a core point A noise point is any point that is neither a core point nor a border point Data Mining Sanjay Ranka Fall
2 DBSCAN: Core, Border and Noise points Data Mining Sanjay Ranka Fall When DBSCAN works well Original Dataset Clusters found by DBSCAN Data Mining Sanjay Ranka Fall
3 DBSCAN: Core, Border and Noise points Original Points Eps = 10, Minpts = 4 Point types: Core Border Noise Data Mining Sanjay Ranka Fall DBSCAN: Determining Eps and MinPts Idea is that for points in a cluster, there k th nearest neighbors are at roughly the same distance Noise points have the k th nearest neighbor at at farther distance So, plot sorted distance of every point to its k th nearest neighbor. (k=4 used for 2D points) Data Mining Sanjay Ranka Fall
4 Where DBSCAN doesn t work well Minpts = 4, Eps = 9.75 Original Points MinPts = 4, Eps = 9.92 Data Mining Sanjay Ranka Fall DENCLUE DENsity CLUstEring is a density clustering approach that models the overall density of a set of points as the sum of influence functions associated with each point DENCLUE is based on kernel density estimation. The goal of kernel density estimation is to describe the distribution of data by a function For kernel density estimation, the contribution of each point to the overall density function is expressed by an influence (kernel) function. The overall density is then merely the sum of the influence functions associated with each point Data Mining Sanjay Ranka Fall
5 DENCLUE The resulting overall density functions will have local peaks, i.e. local density maxima, and these local peaks can be used to define clusters For each point, a hill climbing algorithm finds the nearest peak associated with that point, and set of all data points associated with a peak form a cluster However, if the density at a local peak is too low, then the points in the associated cluster are labeled as noise and discarded Similarly, if two peaks are connected by a path of data points, and the density at each point on the path is above a minimum density threshold, then the clusters associated with these two peaks are merged Data Mining Sanjay Ranka Fall DENCLUE: Kernel Function Typically the kernel function is symmetric and its value decreases as the distance from the point increases. The Gaussian function is often used as a kernel function. Data Mining Sanjay Ranka Fall
6 Subspace clustering Instead of using all the attributes (features) of a dataset, if we consider only subset of the features (subspace of the data), then the clusters that we find can be quite different from one subspace to another The clusters we find depend on the subset of the attributes that we consider Data Mining Sanjay Ranka Fall Subspace clustering Data Mining Sanjay Ranka Fall
7 Subspace clustering Data Mining Sanjay Ranka Fall Subspace Clustering Data Mining Sanjay Ranka Fall
8 CLIQUE CLIQUE is a grid based clustering algorithm CLIQUE splits each dimension (attribute) in to a fixed number ( ) of equal length intervals. This partitions the data space in to rectangular units of equal volume We can measure the density of each unit by the fraction of points it contains A unit is considered dense if its density > user specified threshold A cluster is a group of contiguous (touching) dense units Data Mining Sanjay Ranka Fall CLIQUE: Example Data Mining Sanjay Ranka Fall
9 CLIQUE CLIQUE starts by finding all the dense areas in the one dimensional spaces associated with each attribute Then it generates the set of two dimensional cells that might possibly be dense by looking at pairs of dense one dimensional cells In general, CLIQUE generates the possible set of k-dimensional cells that might possibly be dense by looking at dense (k-1)-dimensional cells. This is similar to APRIORI algorithm for finding frequent item sets It then finds clusters finds clusters by taking union of all adjacent high density cells Data Mining Sanjay Ranka Fall MAFIA Merging of Adaptive Finite Intervals (And more than a CLIQUE) MAFIA is a modification of CLIQUE that runs faster and finds better quality clusters. There is also pmafia which is a parallel version of MAFIA The main modification over CLIQUE is the use of an adaptive grid Data Mining Sanjay Ranka Fall
10 MAFIA Initially each dimension is partitioned into a large number of intervals. A histogram is generated that shows the number of data points in each interval Groups of adjacent intervals are grouped in to windows, and the maximum number of points in the window s intervals becomes the value associated with the window Data Mining Sanjay Ranka Fall MAFIA Adjacent windows are grouped together if the values of the two windows are close As a special case, if all windows are combined into one window, the dimensions is partitioned in to a fixed number of cells and the threshold for being considered a dense unit is increased for that dimension Data Mining Sanjay Ranka Fall
11 Limitations of CLIQUE and MAFIA Time complexity is exponential in the number of dimensions Will have difficulty if too many dense units are generated at lower stages May fail if clusters are of widely differing densities, since the threshold is fixed Determining the appropriate and for a variety of data sets can be challenging It is not typically possible to find all clusters using the same threshold Data Mining Sanjay Ranka Fall Clustering Scalability for Large Datasets One very common solution is sampling, but the sampling could miss small clusters. Data is sometimes not organized to make valid sampling easy or efficient. Another approach is to compress the data or portions of the data. Any such approach must ensure that not too much information is lost. (Scaling Clustering Algorithms to Large Databases, Bradley, Fayyad and Reina.) Data Mining Sanjay Ranka Fall
12 Scalable Clustering: BIRCH BIRCH (Balanced and Iterative Reducing and Clustering using Hierarchies) BIRCH can efficiently cluster data with a single pass and can improve that clustering in additional passes. Can work with a number of different distance metrics. BIRCH can also deal effectively with outliers. Data Mining Sanjay Ranka Fall Scaleable Clustering: BIRCH BIRCH is based on the notion of a clustering feature (CF) and a CF tree. A cluster of data points (vectors) can be represented by a triplet of numbers (N, LS, SS) N is the number of points in the cluster LS is the linear sum of the points SS is the sum of squares of the points. Points are processed incrementally. Each point is placed in the leaf node corresponding to the closest cluster (CF). Clusters (CFs) are updated. Data Mining Sanjay Ranka Fall
13 Scaleable Clustering: BIRCH Basic steps of BIRCH Load the data into memory by creating a CF tree that summarizes the data. Perform global clustering. Produces a better clustering than the initial step. An agglomerative, hierarchical technique was selected. Redistribute the data points using the centroids of clusters discovered in the global clustering phase, and thus, discover a new (and hopefully better) set of clusters. Data Mining Sanjay Ranka Fall Scaleable Clustering: CURE Clustering Using Representatives Uses a number of points to represent a cluster Representative points are found by selecting a constant number of points from a cluster and then shrinking them toward the center of the cluster Cluster similarity is the similarity of the closest pair of representative points from different clusters Shrinking representative points toward the center helps avoid problems with noise and outliers CURE is better able to handle clusters of arbitrary shapes and sizes Data Mining Sanjay Ranka Fall


14 Experimental results: CURE Data Mining Sanjay Ranka Fall Experimental Results: CURE Data Mining Sanjay Ranka Fall
15 CURE can not handle differing densities Original Points CURE Data Mining Sanjay Ranka Fall Graph Based Clustering Graph-Based clustering uses the proximity graph Start with the proximity matrix Consider each point as a node in a graph Each edge between two nodes has a weight which is the proximity between the two points Initially the proximity graph is fully connected MIN (single-link) and MAX (complete-link) can be viewed as starting with this graph In the most simple case, clusters are connected components in the graph Data Mining Sanjay Ranka Fall
16 Graph Based Clustering: Sparsification The amount of data that needs to be processed is drastically reduced Sparsification can eliminate more than 99% of the entries in a similarity matrix The amount of time required to cluster the data is drastically reduced The size of the problems that can be handled is increased Data Mining Sanjay Ranka Fall Sparsification Clustering may work better Sparsification techniques keep the connections to the most similar (nearest) neighbors of a point while breaking the connections to less similar points. The nearest neighbors of a point tend to belong to the same class as the point itself. This reduces the impact of noise and outliers and sharpens the distinction between clusters. Sparsification facilitates the use of graph partitioning algorithms (or algorithms based on graph partitioning algorithms. Chameleon and Hypergraph-based Clustering Data Mining Sanjay Ranka Fall
17 Sparsification Data Mining Sanjay Ranka Fall Limitations of Current Merging Schemes Existing merging schemes are static in nature Data Mining Sanjay Ranka Fall


18 Chameleon: Clustering Using Dynamic Modeling Adapt to the characteristics of the data set to find the natural clusters. Use a dynamic model to measure the similarity between clusters. Main property is the relative closeness and relative inter-connectivity of the cluster. Two clusters are combined if the resulting cluster shares certain properties with the constituent clusters. The merging scheme preserves self-similarity. One of the areas of application is spatial data. Data Mining Sanjay Ranka Fall Characteristics of Spatial Datasets Clusters are defined as densely populated regions of the space Clusters have arbitrary shapes, orientation, and non-uniform sizes Difference in densities across clusters and variation in density within clusters Existence of special artifacts (streaks) and noise The clustering algorithm must address the above characteristics and also require minimal supervision Data Mining Sanjay Ranka Fall
19 Chameleon Preprocessing Step: Represent the Data by a Graph Given a set of points, we construct the k-nearestneighbor (k-nn) graph to capture the relationship between a point and its k nearest neighbors. Phase 1: Use a multilevel graph partitioning algorithm on the graph to find a large number of clusters of well-connected vertices. Each cluster should contain mostly points from one true cluster, i.e., is a sub-cluster of a real cluster. Graph algorithms take into account global structure. Data Mining Sanjay Ranka Fall Chameleon Phase 2: Use Hierarchical Agglomerative Clustering to merge sub-clusters. Two clusters are combined if the resulting cluster shares certain properties with the constituent clusters. Two key properties are used to model cluster similarity: Relative Interconnectivity: Absolute interconnectivity of two clusters normalized by the internal connectivity of the clusters. Relative Closeness: Absolute closeness of two clusters normalized by the internal closeness of the clusters. Data Mining Sanjay Ranka Fall

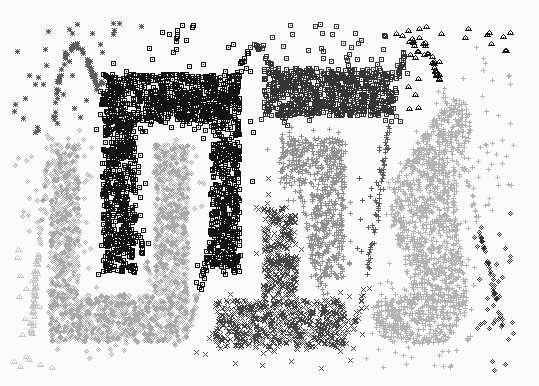
20 Experimental Results: Chameleon Data Mining Sanjay Ranka Fall Experimental Results: Chameleon Data Mining Sanjay Ranka Fall
 Data Mining Sanjay Ranka Fall")

21 Experimental Results: CURE (10 clusters) Data Mining Sanjay Ranka Fall Experimental Results: CURE (15 clusters) Data Mining Sanjay Ranka Fall

 Data Mining Sanjay Ranka")
22 Experimental Results: Chameleon Data Mining Sanjay Ranka Fall Experimental Results: CURE (9 clusters) Data Mining Sanjay Ranka Fall

23 Experimental Results: CURE (15 clusters) Data Mining Sanjay Ranka Fall
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Data Mining Cluster Analysis: Advanced Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining, 2 nd Edition
 Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Data Mining Cluster Analysis: Advanced Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Outline Prototype-based Fuzzy c-means
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/10/2017)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
University of Florida CISE department Gator Engineering. Clustering Part 5
 Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
Clustering Part 5 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville SNN Approach to Clustering Ordinary distance measures have problems Euclidean
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
CS570: Introduction to Data Mining Scalable Clustering Methods: BIRCH and Others Reading: Chapter 10.3 Han, Chapter 9.5 Tan Cengiz Gunay, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei.
Clustering in Data Mining
 Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
Clustering in Data Mining Classification Vs Clustering When the distribution is based on a single parameter and that parameter is known for each object, it is called classification. E.g. Children, young,
CSE 347/447: DATA MINING
 CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
CSE 347/447: DATA MINING Lecture 6: Clustering II W. Teal Lehigh University CSE 347/447, Fall 2016 Hierarchical Clustering Definition Produces a set of nested clusters organized as a hierarchical tree
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: KH 116 Fall 2017 Updates: v Progress Presentation: Week 15: 11/30 v Next Week Office hours
Clustering in Ratemaking: Applications in Territories Clustering
 Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Clustering in Ratemaking: Applications in Territories Clustering Ji Yao, PhD FIA ASTIN 13th-16th July 2008 INTRODUCTION Structure of talk Quickly introduce clustering and its application in insurance ratemaking
Data Mining 4. Cluster Analysis
 Data Mining 4. Cluster Analysis 4.5 Spring 2010 Instructor: Dr. Masoud Yaghini Introduction DBSCAN Algorithm OPTICS Algorithm DENCLUE Algorithm References Outline Introduction Introduction Density-based
Data Mining 4. Cluster Analysis 4.5 Spring 2010 Instructor: Dr. Masoud Yaghini Introduction DBSCAN Algorithm OPTICS Algorithm DENCLUE Algorithm References Outline Introduction Introduction Density-based
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Notes. Reminder: HW2 Due Today by 11:59PM. Review session on Thursday. Midterm next Tuesday (10/09/2018)
") 1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
1 Notes Reminder: HW2 Due Today by 11:59PM TA s note: Please provide a detailed ReadMe.txt file on how to run the program on the STDLINUX. If you installed/upgraded any package on STDLINUX, you should
DS504/CS586: Big Data Analytics Big Data Clustering II
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering II Prof. Yanhua Li Time: 6pm 8:50pm Thu Location: AK 232 Fall 2016 More Discussions, Limitations v Center based clustering K-means BFR algorithm
Clustering Lecture 4: Density-based Methods
 Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 4: Density-based Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
DBSCAN. Presented by: Garrett Poppe
 DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
DBSCAN Presented by: Garrett Poppe A density-based algorithm for discovering clusters in large spatial databases with noise by Martin Ester, Hans-peter Kriegel, Jörg S, Xiaowei Xu Slides adapted from resources
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest)
") Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Lecture-17: Clustering with K-Means (Contd: DT + Random Forest) Medha Vidyotma April 24, 2018 1 Contd. Random Forest For Example, if there are 50 scholars who take the measurement of the length of the
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Clustering Algorithms for Spatial Databases: A Survey
 Clustering Algorithms for Spatial Databases: A Survey Erica Kolatch Department of Computer Science University of Maryland, College Park CMSC 725 3/25/01 kolatch@cs.umd.edu 1. Introduction Spatial Database
Clustering Algorithms for Spatial Databases: A Survey Erica Kolatch Department of Computer Science University of Maryland, College Park CMSC 725 3/25/01 kolatch@cs.umd.edu 1. Introduction Spatial Database
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Distance-based Methods: Drawbacks
 Distance-based Methods: Drawbacks Hard to find clusters with irregular shapes Hard to specify the number of clusters Heuristic: a cluster must be dense Jian Pei: CMPT 459/741 Clustering (3) 1 How to Find
Distance-based Methods: Drawbacks Hard to find clusters with irregular shapes Hard to specify the number of clusters Heuristic: a cluster must be dense Jian Pei: CMPT 459/741 Clustering (3) 1 How to Find
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling
 To Appear in the IEEE Computer CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling George Karypis Eui-Hong (Sam) Han Vipin Kumar Department of Computer Science and Engineering University
To Appear in the IEEE Computer CHAMELEON: A Hierarchical Clustering Algorithm Using Dynamic Modeling George Karypis Eui-Hong (Sam) Han Vipin Kumar Department of Computer Science and Engineering University
COMP 465: Data Mining Still More on Clustering
 3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
3/4/015 Exercise COMP 465: Data Mining Still More on Clustering Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Describe each of the following
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
数据挖掘 Introduction to Data Mining
 数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
数据挖掘 Introduction to Data Mining Philippe Fournier-Viger Full professor School of Natural Sciences and Humanities philfv8@yahoo.com Spring 2019 S8700113C 1 Introduction Last week: Association Analysis
Clustering Algorithms for Data Stream
 Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
Clustering Algorithms for Data Stream Karishma Nadhe 1, Prof. P. M. Chawan 2 1Student, Dept of CS & IT, VJTI Mumbai, Maharashtra, India 2Professor, Dept of CS & IT, VJTI Mumbai, Maharashtra, India Abstract:
A Comparative Study of Various Clustering Algorithms in Data Mining
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320 088X IMPACT FACTOR: 6.017 IJCSMC,
Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY
 VISHAL BHARTI Computer Science Dept. GC, CUNY") Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY Clustering Algorithm Clustering is an unsupervised machine learning algorithm that divides a data into meaningful sub-groups,
Clustering Algorithm (DBSCAN) VISHAL BHARTI Computer Science Dept. GC, CUNY Clustering Algorithm Clustering is an unsupervised machine learning algorithm that divides a data into meaningful sub-groups,
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 8: Clustering
Hierarchy. No or very little supervision Some heuristic quality guidances on the quality of the hierarchy. Jian Pei: CMPT 459/741 Clustering (2) 1
 1") Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Hierarchy An arrangement or classification of things according to inclusiveness A natural way of abstraction, summarization, compression, and simplification for understanding Typical setting: organize
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Cluster Analysis: Basic Concepts and Algorithms
 Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
Cluster Analysis: Basic Concepts and Algorithms Data Warehousing and Mining Lecture 10 by Hossen Asiful Mustafa What is Cluster Analysis? Finding groups of objects such that the objects in a group will
What is Cluster Analysis? COMP 465: Data Mining Clustering Basics. Applications of Cluster Analysis. Clustering: Application Examples 3/17/2015
 // What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
// What is Cluster Analysis? COMP : Data Mining Clustering Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, rd ed. Cluster: A collection of data
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Unsupervised Learning Hierarchical Methods
 Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
Unsupervised Learning Hierarchical Methods Road Map. Basic Concepts 2. BIRCH 3. ROCK The Principle Group data objects into a tree of clusters Hierarchical methods can be Agglomerative: bottom-up approach
DATA MINING - 1DL105, 1Dl111. An introductory class in data mining
 1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1Dl111 Fall 007 An introductory class in data mining http://user.it.uu.se/~udbl/dm-ht007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Lecture 7 Cluster Analysis: Part A
 Lecture 7 Cluster Analysis: Part A Zhou Shuigeng May 7, 2007 2007-6-23 Data Mining: Tech. & Appl. 1 Outline What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering
Lecture 7 Cluster Analysis: Part A Zhou Shuigeng May 7, 2007 2007-6-23 Data Mining: Tech. & Appl. 1 Outline What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering
CS Data Mining Techniques Instructor: Abdullah Mueen
 CS 591.03 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 6: BASIC CLUSTERING Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster Analysis: Basic Concepts Partitioning Methods Hierarchical
CS 591.03 Data Mining Techniques Instructor: Abdullah Mueen LECTURE 6: BASIC CLUSTERING Chapter 10. Cluster Analysis: Basic Concepts and Methods Cluster Analysis: Basic Concepts Partitioning Methods Hierarchical
Acknowledgements First of all, my thanks go to my supervisor Dr. Osmar R. Za ane for his guidance and funding. Thanks to Jörg Sander who reviewed this
 Abstract Clustering means grouping similar objects into classes. In the result, objects within a same group should bear similarity to each other while objects in different groups are dissimilar to each
Abstract Clustering means grouping similar objects into classes. In the result, objects within a same group should bear similarity to each other while objects in different groups are dissimilar to each
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Clustering Part 2. A Partitional Clustering
 Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
Universit of Florida CISE department Gator Engineering Clustering Part Dr. Sanja Ranka Professor Computer and Information Science and Engineering Universit of Florida, Gainesville Universit of Florida
CS412 Homework #3 Answer Set
 CS41 Homework #3 Answer Set December 1, 006 Q1. (6 points) (1) (3 points) Suppose that a transaction datase DB is partitioned into DB 1,..., DB p. The outline of a distributed algorithm is as follows.
CS41 Homework #3 Answer Set December 1, 006 Q1. (6 points) (1) (3 points) Suppose that a transaction datase DB is partitioned into DB 1,..., DB p. The outline of a distributed algorithm is as follows.
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
CS570: Introduction to Data Mining Cluster Analysis Reading: Chapter 10.4, 10.6, 11.1.3 Han, Chapter 8.4,8.5,9.2.2, 9.3 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber &
Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/4 What
d(2,1) d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......
 d(3,1 ) d (3,2) 0 ( n, ) ( n ,2)......") Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Data Mining i Topic: Clustering CSEE Department, e t, UMBC Some of the slides used in this presentation are prepared by Jiawei Han and Micheline Kamber Cluster Analysis What is Cluster Analysis? Types
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Clustering Techniques
 Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
Clustering Techniques Marco BOTTA Dipartimento di Informatica Università di Torino botta@di.unito.it www.di.unito.it/~botta/didattica/clustering.html Data Clustering Outline What is cluster analysis? What
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Chapter 4: Text Clustering
 4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
Clustering Tips and Tricks in 45 minutes (maybe more :)
") Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Clustering Tips and Tricks in 45 minutes (maybe more :) Olfa Nasraoui, University of Louisville Tutorial for the Data Science for Social Good Fellowship 2015 cohort @DSSG2015@University of Chicago https://www.researchgate.net/profile/olfa_nasraoui
Density-Based Clustering. Izabela Moise, Evangelos Pournaras
 Density-Based Clustering Izabela Moise, Evangelos Pournaras Izabela Moise, Evangelos Pournaras 1 Reminder Unsupervised data mining Clustering k-means Izabela Moise, Evangelos Pournaras 2 Main Clustering
Density-Based Clustering Izabela Moise, Evangelos Pournaras Izabela Moise, Evangelos Pournaras 1 Reminder Unsupervised data mining Clustering k-means Izabela Moise, Evangelos Pournaras 2 Main Clustering
DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li
 Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Welcome to DS504/CS586: Big Data Analytics Big Data Clustering Prof. Yanhua Li Time: 6:00pm 8:50pm Thu Location: AK 232 Fall 2016 High Dimensional Data v Given a cloud of data points we want to understand
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/8/004 What
Cluster Analysis (b) Lijun Zhang
 Lijun Zhang") Cluster Analysis (b) Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Grid-Based and Density-Based Algorithms Graph-Based Algorithms Non-negative Matrix Factorization Cluster Validation Summary
Cluster Analysis (b) Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Grid-Based and Density-Based Algorithms Graph-Based Algorithms Non-negative Matrix Factorization Cluster Validation Summary
Efficient Parallel DBSCAN algorithms for Bigdata using MapReduce
 Efficient Parallel DBSCAN algorithms for Bigdata using MapReduce Thesis submitted in partial fulfillment of the requirements for the award of degree of Master of Engineering in Software Engineering Submitted
Efficient Parallel DBSCAN algorithms for Bigdata using MapReduce Thesis submitted in partial fulfillment of the requirements for the award of degree of Master of Engineering in Software Engineering Submitted
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Analyzing Outlier Detection Techniques with Hybrid Method
 Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
Analyzing Outlier Detection Techniques with Hybrid Method Shruti Aggarwal Assistant Professor Department of Computer Science and Engineering Sri Guru Granth Sahib World University. (SGGSWU) Fatehgarh Sahib,
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
Lecture Notes for Chapter 7. Introduction to Data Mining, 2 nd Edition. by Tan, Steinbach, Karpatne, Kumar
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 7 Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar Hierarchical Clustering Produces a set
Unsupervised learning on Color Images
 Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Unsupervised learning on Color Images Sindhuja Vakkalagadda 1, Prasanthi Dhavala 2 1 Computer Science and Systems Engineering, Andhra University, AP, India 2 Computer Science and Systems Engineering, Andhra
Cluster analysis. Agnieszka Nowak - Brzezinska
 Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Cluster analysis Agnieszka Nowak - Brzezinska Outline of lecture What is cluster analysis? Clustering algorithms Measures of Cluster Validity What is Cluster Analysis? Finding groups of objects such that
Local Dimensionality Reduction: A New Approach to Indexing High Dimensional Spaces
 Local Dimensionality Reduction: A New Approach to Indexing High Dimensional Spaces Kaushik Chakrabarti Department of Computer Science University of Illinois Urbana, IL 61801 kaushikc@cs.uiuc.edu Sharad
Local Dimensionality Reduction: A New Approach to Indexing High Dimensional Spaces Kaushik Chakrabarti Department of Computer Science University of Illinois Urbana, IL 61801 kaushikc@cs.uiuc.edu Sharad
Study and Implementation of CHAMELEON algorithm for Gene Clustering
 [1] Study and Implementation of CHAMELEON algorithm for Gene Clustering 1. Motivation Saurav Sahay The vast amount of gathered genomic data from Microarray and other experiments makes it extremely difficult
[1] Study and Implementation of CHAMELEON algorithm for Gene Clustering 1. Motivation Saurav Sahay The vast amount of gathered genomic data from Microarray and other experiments makes it extremely difficult
Scalable Varied Density Clustering Algorithm for Large Datasets
 J. Software Engineering & Applications, 2010, 3, 593-602 doi:10.4236/jsea.2010.36069 Published Online June 2010 (http://www.scirp.org/journal/jsea) Scalable Varied Density Clustering Algorithm for Large
J. Software Engineering & Applications, 2010, 3, 593-602 doi:10.4236/jsea.2010.36069 Published Online June 2010 (http://www.scirp.org/journal/jsea) Scalable Varied Density Clustering Algorithm for Large
Segmentation (continued)
") Segmentation (continued) Lecture 05 Computer Vision Material Citations Dr George Stockman Professor Emeritus, Michigan State University Dr Mubarak Shah Professor, University of Central Florida The Robotics
Segmentation (continued) Lecture 05 Computer Vision Material Citations Dr George Stockman Professor Emeritus, Michigan State University Dr Mubarak Shah Professor, University of Central Florida The Robotics
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
A Review: Techniques for Clustering of Web Usage Mining
 A Review: Techniques for Clustering of Web Usage Mining Rupinder Kaur 1, Simarjeet Kaur 2 1 Research Fellow, Department of CSE, SGGSWU, Fatehgarh Sahib, Punjab, India 2 Assistant Professor, Department
A Review: Techniques for Clustering of Web Usage Mining Rupinder Kaur 1, Simarjeet Kaur 2 1 Research Fellow, Department of CSE, SGGSWU, Fatehgarh Sahib, Punjab, India 2 Assistant Professor, Department
CS7267 MACHINE LEARNING
 S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
S7267 MAHINE LEARNING HIERARHIAL LUSTERING Ref: hengkai Li, Department of omputer Science and Engineering, University of Texas at Arlington (Slides courtesy of Vipin Kumar) Mingon Kang, Ph.D. omputer Science,
CS Introduction to Data Mining Instructor: Abdullah Mueen
 CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
CS 591.03 Introduction to Data Mining Instructor: Abdullah Mueen LECTURE 8: ADVANCED CLUSTERING (FUZZY AND CO -CLUSTERING) Review: Basic Cluster Analysis Methods (Chap. 10) Cluster Analysis: Basic Concepts
Analysis and Extensions of Popular Clustering Algorithms
 Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Analysis and Extensions of Popular Clustering Algorithms Renáta Iváncsy, Attila Babos, Csaba Legány Department of Automation and Applied Informatics and HAS-BUTE Control Research Group Budapest University
Data Preprocessing. Data Preprocessing
 Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
Data Preprocessing Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville ranka@cise.ufl.edu Data Preprocessing What preprocessing step can or should
What is Cluster Analysis?
 Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
Cluster Analysis What is Cluster Analysis? Finding groups of objects (data points) such that the objects in a group will be similar (or related) to one another and different from (or unrelated to) the
D-GridMST: Clustering Large Distributed Spatial Databases
 D-GridMST: Clustering Large Distributed Spatial Databases Ji Zhang Department of Computer Science University of Toronto Toronto, Ontario, M5S 3G4, Canada Email: jzhang@cs.toronto.edu Abstract: In this
D-GridMST: Clustering Large Distributed Spatial Databases Ji Zhang Department of Computer Science University of Toronto Toronto, Ontario, M5S 3G4, Canada Email: jzhang@cs.toronto.edu Abstract: In this
Clustering fundamentals
 Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Elena Baralis, Tania Cerquitelli Politecnico di Torino What is Cluster Analsis? Finding groups of objects such that the objects in a group will be similar (or related) to one another and different from
Parallelization of Hierarchical Density-Based Clustering using MapReduce. Talat Iqbal Syed
 Parallelization of Hierarchical Density-Based Clustering using MapReduce by Talat Iqbal Syed A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science Department
Parallelization of Hierarchical Density-Based Clustering using MapReduce by Talat Iqbal Syed A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science Department
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES
 CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
CHAPTER 7. PAPER 3: EFFICIENT HIERARCHICAL CLUSTERING OF LARGE DATA SETS USING P-TREES 7.1. Abstract Hierarchical clustering methods have attracted much attention by giving the user a maximum amount of
Keywords Clustering, Goals of clustering, clustering techniques, clustering algorithms.
 Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com A Survey of Clustering
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges