Michele Samorani. University of Alberta School of Business. More tutorials are available on Youtube
|
|
|
- David Flynn
- 5 years ago
- Views:
Transcription
1 Dataconda Tutorial* Michele Samorani University of Alberta School of Business More tutorials are available on Youtube
2 What is Dataconda? Software program to generate a mining table from a relational database State-of-the-art attribute generation Full version is free for research and teaching purposes 1. Install Dataconda ( 2. (optional but recommended) Install R ( 3. (optional but recommended) Install Weka (
3 Outline 1. Motivation 2. Attribute generation algorithm 3. How to use Dataconda 1. Load data 2. Generate Attributes 3. Interpret the Output 4. Extend Dataconda 4. Some Experiments
4 Motivation



5 Idealized vs Real view of classification Real Idealized Classifier Flat Mining table New knowledge A lot of research focuses on this step Relational Database This is the actual critical step (and the main task performed by Dataconda)
6 Class Problem: classify purchases by Return First step: build a flat mining table: Purchas e ID Online Gender Age Price Customer s past return rate What else? Return (0/1) Pur1 1 M 33 $200 NA 1 Pur2 0 F 45 $100 NA 0 Pur3 0 M 33 $ Pur4 0 M 28 $160 NA 1
7 Building the mining table MANUALLY The analyst formulates hypotheses Computes only the attributes that she suspects will confirm or reject the hypothesis Cons: Time consuming Limited knowledge discovery AUTOMATICALLY A software generates the hypotheses (attributes) Pros: Fast Enhanced knowledge discovery QUICK DEMO
8 Attribute Generation Algorithm
9 Building attributes automatically Consider the Entity-Relationship diagram of the database Clients Gender Age 0-to-N 1-to-1 Purchases Date Online Return 1-to-1 0-to-N Products Price The idea is to add attributes to the target table (Purchases)
10 Building attributes automatically 0-to-N 2 Purchases Date Online Return 3 0-to-N Clients Gender Age 1 1-to-1 1-to-1 Products Price
11 Step 2: roll up from the end of the path Purchases 1 Date Online Return Clients Gender Age Purchases 2 1-to-1 0-to-N 1-to-1 Date Online Return Product price Products Price Virtual attribute Add a column to Purchase 2, which brings in information from Products
12 Purchases 1 Date Online Return Clients Gender Age Purchases 2 1-to-1 0-to-N 1-to-1 Avg Return where Price > $150 Date Online Return Product price Products Price Add a column to Clients, which brings in information from Purchases 2
13 Purchases 1 Date Online Return Avg Ret w/ Price > $150 Clients Gender Age Purchases 2 1-to-1 0-to-N 1-to-1 Avg Return where Price > $150 Date Online Return Product price Products Price Add a column to Purchases 1, which brings in information from Clients
14 Purchases 1 Date Online Return Clients Gender Age Avg Ret w/ Price > $150 and P2.Date $150 < P1.Date Purchases 2 1-to-1 0-to-N 1-to-1 Avg Return where Price > and P2.Date < P1.Date Date Online Return Product price Products Price Add the where condition on the date
15 Purchases 1 Date Online Return Avg Ret w/ Price > $150 and P2.Date < P1.Date Clients Gender Age Purchases 2 1-to-1 0-to-N 1-to-1 Avg Return where Price > $150 and P2.Date < P1.Date Date Online Return Product price Products Price Could have chosen any attribute of Products Could have chosen any threshold for attribute Price Could have chosen any aggregating function compatible with the attribute Return Could have chosen any comparison operator compatible with the attribute Price The red boxes above represent user settings. Let s see how to configure them
16 How to Use Dataconda
17 Simulated Data Purchases Clients Gender Age 0-to-N Date Online Return 0-to-N Products Price Build all the tables randomly, except for the target attribute Return: Depth 2 Depth 3 Depth 4 P(Return) ~ logit -1 ( * price + 2 * customer s past return rate * age of the client who most recently purchased the current product online) TRUEVARIABLES


18 Load CSV file



19

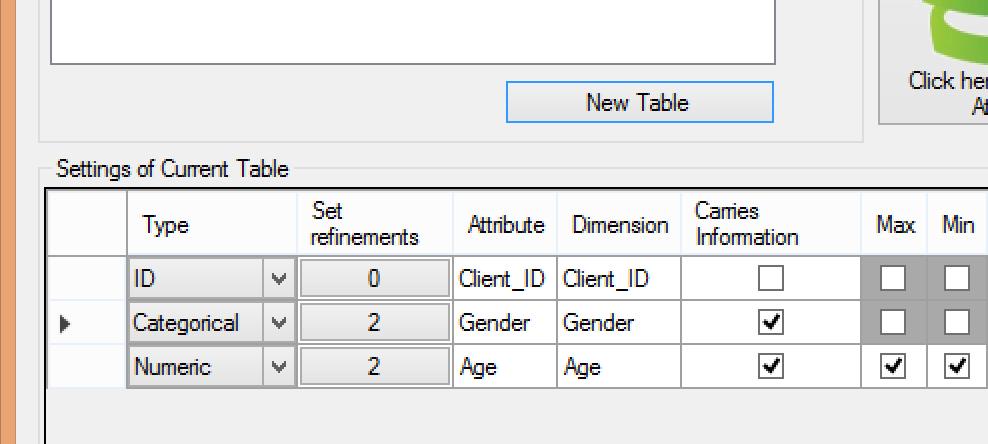
20 Load all three tables


21 Save/Load project You can save the project at any moment. Note that the project file does NOT contain the data. So, it needs to be saved in the same folder as the csv files




22 Declare association between two tables


23 Dataconda only supports 0:n and 0:1 associations In the example above, we declare in one step: A 0:n association from Products to Purchases A 0:1 association from Purchases to Products


24

25 Settings of Table Purchases Column name in the csv file
26

27 Generates attributes and refinements based on this attribute The aggregator AVG will be used on the attribute Return Since Online and Return are 0-1 attributes, it could make sense to define them as categorical or numeric. Here, we define them as numeric so that the mathematical aggregators (MAX, MIN, AVG, etc) are enabled.
28 Selecting a different table will show the options for the attributes of that table


29 Click to set the refinements for this attribute


30 Refinements Refinements are the SQL where conditions Click to set refinements
31 Refinements Comparison refinements: If the path considered passes two times through the table products, you might want a refinement like: where Products1.price > Products2.price
32 Refinements ToValue refinements: You might want a refinement like: where Products.price > 200 By selecting All possible values, we enable the generation of the refinements: where Products.price > val (for each distinct value val of Price) Alternatively, we can split the values of Price in bins. The binning performed is by equal width


33 Refinements Operators We can select which operators to use in the where condition

34 After declaring attribute types, associations, enabled aggregations and refinements, It s time to generate the flat table




35 We need to select which tables we want to expand by adding new attributes (in this case: purchases)


36 We need to select which attribute is the target attribute (in this case: return) Dataconda places the target attribute among the class spoilers Class spoilers are those attributes that should not be used to predict the target attribute, because the target attribute is functionally dependent on them. If we used them, the classification rule would be trivial. Clearly, we cannot use the target attribute to predict itself. Otherwise, the classification rule would be If return = 1, then predict 1. In this case, return is the only class spoiler. If the Purchases table contained an attribute ReasonForReturn (defective product, client doesn t like it, not returned, ), then ReasonForReturn would also be a class spoiler
 Time to press Run! Note: Increasing the max depth will result in many more attributes (good).")
37 Time spent generating attributes in order (scan time) When the Scan Time is up, Dataconda starts generating more complex attributes in random order Maximum depth of the paths used to generate attributes (see slide 6) Time to press Run! Note: Increasing the max depth will result in many more attributes (good). However, they may also be very complex and hard to interpret


38 An important option If the attribute generation procedure is executed for a long time, you might want an intermediate output once in a while Note that too frequent updates slow down the procedure
39 Data.csv and Data.arff These files contain the flat table The target attribute is still there Since here the target table is Purchases, the flat table will have the same number of rows as Purchases but a lot more attributes!these attributes are new attributes for Purchases The arff file can be opened directly in Weka The meaning of the generated attributes is reported in attributes.txt
40 Attributes.txt
41 Analysis output.txt After generating the attributes, if R is installed and if the output folder contains a file Rtemplate.R, Dataconda executes an attribute selection procedure in order to find the best predictors price Client s return rate The price has a significant (***) impact on return. The correlation is positive (because its coefficient 1.580e-02 is greater than 0) The client s return rate has also a significant (***) impact on return. The correlation is positive (because its coefficient is greater than 0)




42 The results are also reported in the window The discriminant attributes
43 Important When preparing the csv file, make sure that the rows are order by date asc When saving/loading the project, remember to place it in the same folder as the csv files Do not keep the data.csv file open in Excel when executing the attribute generation procedure. Otherwise, Dataconda will give an error.
44 Two ways to extend Dataconda 1. Write attribute selection procedure (in R) After generating attributes, Dataconda executes the file Rscript.R in the folder The default attribute selection procedure is based on Lasso 2. Write aggregating functions (in.net) Extend the interface dataconda.core.iaggregatingfunction Place the dll in the program folder of Dataconda The new function will appear in the GUI
45 Some Experiments
46 Real Data (ISMS Dataset) ISMS Dataset: all transactions of 1% of the registered customers of Circuit City. In total: 173,262 transactions Target table 0-to-N Transactions Return Subcategories 0-to-N Households 0-to-N Brands 0-to-N Locations Too large! Sample 1,000 customers and retain all their transactions End up with a target table with ~6,000 rows Generated 2,496 attributes up to depth 4 in 1h 21
47 Att value Prob return Count % % NULL 11.8% 37789
48 Attr Value Prob return Count % %

49 Conclusion Relational attribute generation: Underdeveloped field with high potential Find new knowledge Increase classification accuracy Dataconda Full version is free for research and teaching purposes Can be extended: Add new aggregating functions Change the attribute selection procedure Can be improved: Integrate it with a DBMS Thank you very much! Contact: samorani@ualberta.ca
Data Mining. ❷Chapter 2 Basic Statistics. Asso.Prof.Dr. Xiao-dong Zhu. Business School, University of Shanghai for Science & Technology
 ❷Chapter 2 Basic Statistics Business School, University of Shanghai for Science & Technology 2016-2017 2nd Semester, Spring2017 Contents of chapter 1 1 recording data using computers 2 3 4 5 6 some famous
❷Chapter 2 Basic Statistics Business School, University of Shanghai for Science & Technology 2016-2017 2nd Semester, Spring2017 Contents of chapter 1 1 recording data using computers 2 3 4 5 6 some famous
Data Mining With Weka A Short Tutorial
 Data Mining With Weka A Short Tutorial Dr. Wenjia Wang School of Computing Sciences University of East Anglia (UEA), Norwich, UK Content 1. Introduction to Weka 2. Data Mining Functions and Tools 3. Data
Data Mining With Weka A Short Tutorial Dr. Wenjia Wang School of Computing Sciences University of East Anglia (UEA), Norwich, UK Content 1. Introduction to Weka 2. Data Mining Functions and Tools 3. Data
Introduction to Data Mining and Data Analytics
 1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
Tutorial on Association Rule Mining
 Tutorial on Association Rule Mining Yang Yang yang.yang@itee.uq.edu.au DKE Group, 78-625 August 13, 2010 Outline 1 Quick Review 2 Apriori Algorithm 3 FP-Growth Algorithm 4 Mining Flickr and Tag Recommendation
Tutorial on Association Rule Mining Yang Yang yang.yang@itee.uq.edu.au DKE Group, 78-625 August 13, 2010 Outline 1 Quick Review 2 Apriori Algorithm 3 FP-Growth Algorithm 4 Mining Flickr and Tag Recommendation
KNIME TUTORIAL. Anna Monreale KDD-Lab, University of Pisa
 KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it Outline Introduction on KNIME KNIME components Exercise: Data Understanding Exercise: Market Basket Analysis Exercise:
KNIME TUTORIAL Anna Monreale KDD-Lab, University of Pisa Email: annam@di.unipi.it Outline Introduction on KNIME KNIME components Exercise: Data Understanding Exercise: Market Basket Analysis Exercise:
An Overview of various methodologies used in Data set Preparation for Data mining Analysis
 An Overview of various methodologies used in Data set Preparation for Data mining Analysis Arun P Kuttappan 1, P Saranya 2 1 M. E Student, Dept. of Computer Science and Engineering, Gnanamani College of
An Overview of various methodologies used in Data set Preparation for Data mining Analysis Arun P Kuttappan 1, P Saranya 2 1 M. E Student, Dept. of Computer Science and Engineering, Gnanamani College of
Data Mining: STATISTICA
 Outline Data Mining: STATISTICA Prepare the data Classification and regression (C & R, ANN) Clustering Association rules Graphic user interface Prepare the Data Statistica can read from Excel,.txt and
Outline Data Mining: STATISTICA Prepare the data Classification and regression (C & R, ANN) Clustering Association rules Graphic user interface Prepare the Data Statistica can read from Excel,.txt and
Fast or furious? - User analysis of SF Express Inc
 CS 229 PROJECT, DEC. 2017 1 Fast or furious? - User analysis of SF Express Inc Gege Wen@gegewen, Yiyuan Zhang@yiyuan12, Kezhen Zhao@zkz I. MOTIVATION The motivation of this project is to predict the likelihood
CS 229 PROJECT, DEC. 2017 1 Fast or furious? - User analysis of SF Express Inc Gege Wen@gegewen, Yiyuan Zhang@yiyuan12, Kezhen Zhao@zkz I. MOTIVATION The motivation of this project is to predict the likelihood
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Non-trivial extraction of implicit, previously unknown and potentially useful information from data
 CS 795/895 Applied Visual Analytics Spring 2013 Data Mining Dr. Michele C. Weigle http://www.cs.odu.edu/~mweigle/cs795-s13/ What is Data Mining? Many Definitions Non-trivial extraction of implicit, previously
CS 795/895 Applied Visual Analytics Spring 2013 Data Mining Dr. Michele C. Weigle http://www.cs.odu.edu/~mweigle/cs795-s13/ What is Data Mining? Many Definitions Non-trivial extraction of implicit, previously
Basic Concepts Weka Workbench and its terminology
 Changelog: 14 Oct, 30 Oct Basic Concepts Weka Workbench and its terminology Lecture Part Outline Concepts, instances, attributes How to prepare the input: ARFF, attributes, missing values, getting to know
Changelog: 14 Oct, 30 Oct Basic Concepts Weka Workbench and its terminology Lecture Part Outline Concepts, instances, attributes How to prepare the input: ARFF, attributes, missing values, getting to know
Outline. Prepare the data Classification and regression Clustering Association rules Graphic user interface
 Data Mining: i STATISTICA Outline Prepare the data Classification and regression Clustering Association rules Graphic user interface 1 Prepare the Data Statistica can read from Excel,.txt and many other
Data Mining: i STATISTICA Outline Prepare the data Classification and regression Clustering Association rules Graphic user interface 1 Prepare the Data Statistica can read from Excel,.txt and many other
Preprocessing Short Lecture Notes cse352. Professor Anita Wasilewska
 Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
Preprocessing Short Lecture Notes cse352 Professor Anita Wasilewska Data Preprocessing Why preprocess the data? Data cleaning Data integration and transformation Data reduction Discretization and concept
SPSS TRAINING SPSS VIEWS
 SPSS TRAINING SPSS VIEWS Dataset Data file Data View o Full data set, structured same as excel (variable = column name, row = record) Variable View o Provides details for each variable (column in Data
SPSS TRAINING SPSS VIEWS Dataset Data file Data View o Full data set, structured same as excel (variable = column name, row = record) Variable View o Provides details for each variable (column in Data
CITS4009 Introduction to Data Science
 School of Computer Science and Software Engineering CITS4009 Introduction to Data Science SEMESTER 2, 2017: CHAPTER 4 MANAGING DATA 1 Chapter Objectives Fixing data quality problems Organizing your data
School of Computer Science and Software Engineering CITS4009 Introduction to Data Science SEMESTER 2, 2017: CHAPTER 4 MANAGING DATA 1 Chapter Objectives Fixing data quality problems Organizing your data
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Summary of Last Chapter. Course Content. Chapter 3 Objectives. Chapter 3: Data Preprocessing. Dr. Osmar R. Zaïane. University of Alberta 4
 Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Principles of Knowledge Discovery in Data Fall 2004 Chapter 3: Data Preprocessing Dr. Osmar R. Zaïane University of Alberta Summary of Last Chapter What is a data warehouse and what is it for? What is
Data Mining. Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka. I. Data sets. I.1. Data sets characteristics and formats
 Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
Data Mining Lab 1: Data sets: characteristics, formats, repositories Introduction to Weka I. Data sets I.1. Data sets characteristics and formats The data to be processed can be structured (e.g. data matrix,
REALCOM-IMPUTE: multiple imputation using MLwin. Modified September Harvey Goldstein, Centre for Multilevel Modelling, University of Bristol
 REALCOM-IMPUTE: multiple imputation using MLwin. Modified September 2014 by Harvey Goldstein, Centre for Multilevel Modelling, University of Bristol This description is divided into two sections. In the
REALCOM-IMPUTE: multiple imputation using MLwin. Modified September 2014 by Harvey Goldstein, Centre for Multilevel Modelling, University of Bristol This description is divided into two sections. In the
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Data Mining and Knowledge Discovery Practice notes: Numeric Prediction, Association Rules
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 06/0/ Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Model Selection and Assessment
 Model Selection and Assessment CS4780/5780 Machine Learning Fall 2014 Thorsten Joachims Cornell University Reading: Mitchell Chapter 5 Dietterich, T. G., (1998). Approximate Statistical Tests for Comparing
Model Selection and Assessment CS4780/5780 Machine Learning Fall 2014 Thorsten Joachims Cornell University Reading: Mitchell Chapter 5 Dietterich, T. G., (1998). Approximate Statistical Tests for Comparing
Data Science with R Decision Trees with Rattle
 Data Science with R Decision Trees with Rattle Graham.Williams@togaware.com 9th June 2014 Visit http://onepager.togaware.com/ for more OnePageR s. In this module we use the weather dataset to explore the
Data Science with R Decision Trees with Rattle Graham.Williams@togaware.com 9th June 2014 Visit http://onepager.togaware.com/ for more OnePageR s. In this module we use the weather dataset to explore the
Data and Text Mining
 Data representation and manipulation I prof. dr. Bojan Cestnik Temida d.o.o. & Jozef Stefan Institute Ljubljana bojan.cestnik@temida.si prof. dr. Bojan Cestnik 1 Contents Introduction Basic Data Mining
Data representation and manipulation I prof. dr. Bojan Cestnik Temida d.o.o. & Jozef Stefan Institute Ljubljana bojan.cestnik@temida.si prof. dr. Bojan Cestnik 1 Contents Introduction Basic Data Mining
NULLs & Outer Joins. Objectives of the Lecture :
 Slide 1 NULLs & Outer Joins Objectives of the Lecture : To consider the use of NULLs in SQL. To consider Outer Join Operations, and their implementation in SQL. Slide 2 Missing Values : Possible Strategies
Slide 1 NULLs & Outer Joins Objectives of the Lecture : To consider the use of NULLs in SQL. To consider Outer Join Operations, and their implementation in SQL. Slide 2 Missing Values : Possible Strategies
PSS718 - Data Mining
 Lecture 3 Hacettepe University, IPS, PSS October 10, 2016 Data is important Data -> Information -> Knowledge -> Wisdom Dataset a collection of data, a.k.a. matrix, table. Observation a row of a dataset,
Lecture 3 Hacettepe University, IPS, PSS October 10, 2016 Data is important Data -> Information -> Knowledge -> Wisdom Dataset a collection of data, a.k.a. matrix, table. Observation a row of a dataset,
Seminars of Software and Services for the Information Society
 DIPARTIMENTO DI INGEGNERIA INFORMATICA AUTOMATICA E GESTIONALE ANTONIO RUBERTI Master of Science in Engineering in Computer Science (MSE-CS) Seminars in Software and Services for the Information Society
DIPARTIMENTO DI INGEGNERIA INFORMATICA AUTOMATICA E GESTIONALE ANTONIO RUBERTI Master of Science in Engineering in Computer Science (MSE-CS) Seminars in Software and Services for the Information Society
MapReduce: Algorithm Design for Relational Operations
 MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Projection π Projection in MapReduce Easy Map over tuples, emit
MapReduce: Algorithm Design for Relational Operations Some slides borrowed from Jimmy Lin, Jeff Ullman, Jerome Simeon, and Jure Leskovec Projection π Projection in MapReduce Easy Map over tuples, emit
Data Mining. 3.5 Lazy Learners (Instance-Based Learners) Fall Instructor: Dr. Masoud Yaghini. Lazy Learners
 Fall Instructor: Dr. Masoud Yaghini. Lazy Learners") Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Data Mining 3.5 (Instance-Based Learners) Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction k-nearest-neighbor Classifiers References Introduction Introduction Lazy vs. eager learning Eager
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
MKTG 460 Winter 2019 Solutions #1
 MKTG 460 Winter 2019 Solutions #1 Short Answer: Data Analysis 1. What is a data table and how are the data values organized? A data table stores the data values for variables across different observations,
MKTG 460 Winter 2019 Solutions #1 Short Answer: Data Analysis 1. What is a data table and how are the data values organized? A data table stores the data values for variables across different observations,
Data mining, 4 cu Lecture 6:
 582364 Data mining, 4 cu Lecture 6: Quantitative association rules Multi-level association rules Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Data mining, Spring 2010 (Slides adapted
582364 Data mining, 4 cu Lecture 6: Quantitative association rules Multi-level association rules Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Data mining, Spring 2010 (Slides adapted
Web CRM Project. Logical Data Model
 Web CRM Project Logical Data Model Prepared by Rainer Schoenrank Data Warehouse Architect The Data Organization 11 December 2007 DRAFT 4/26/2018 Page 1 TABLE OF CONTENTS 1. CHANGE LOG... 5 2. DOCUMENT
Web CRM Project Logical Data Model Prepared by Rainer Schoenrank Data Warehouse Architect The Data Organization 11 December 2007 DRAFT 4/26/2018 Page 1 TABLE OF CONTENTS 1. CHANGE LOG... 5 2. DOCUMENT
An Introduction to WEKA Explorer. In part from: Yizhou Sun 2008
 An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 2016/01/12 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Dr. Barbara Morgan Quantitative Methods
 Dr. Barbara Morgan Quantitative Methods 195.650 Basic Stata This is a brief guide to using the most basic operations in Stata. Stata also has an on-line tutorial. At the initial prompt type tutorial. In
Dr. Barbara Morgan Quantitative Methods 195.650 Basic Stata This is a brief guide to using the most basic operations in Stata. Stata also has an on-line tutorial. At the initial prompt type tutorial. In
Data Mining with Oracle 10g using Clustering and Classification Algorithms Nhamo Mdzingwa September 25, 2005
 Data Mining with Oracle 10g using Clustering and Classification Algorithms Nhamo Mdzingwa September 25, 2005 Abstract Deciding on which algorithm to use, in terms of which is the most effective and accurate
Data Mining with Oracle 10g using Clustering and Classification Algorithms Nhamo Mdzingwa September 25, 2005 Abstract Deciding on which algorithm to use, in terms of which is the most effective and accurate
Data Mining. Practical Machine Learning Tools and Techniques. Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A.
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Input: Concepts, instances, attributes Terminology What s a concept?
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 3 of Data Mining by I. H. Witten, E. Frank and M. A. Hall Input: Concepts, instances, attributes Terminology What s a concept?
LABORATORY OF DATA SCIENCE. ETL Extract, Transform and Load. Data Science & Business Informatics Degree
 LABORATORY OF DATA SCIENCE ETL Extract, Transform and Load Data Science & Business Informatics Degree BI Architecture 2 6 lessons data access 4 lessons data quality & ETL 1 lessons analytic SQL 6 lessons
LABORATORY OF DATA SCIENCE ETL Extract, Transform and Load Data Science & Business Informatics Degree BI Architecture 2 6 lessons data access 4 lessons data quality & ETL 1 lessons analytic SQL 6 lessons
Introduction to Transactions: Controlling Concurrent "Behavior" Virtual and Materialized Views" Indexes: Speeding Accesses to Data"
 Introduction to Transactions: Controlling Concurrent "Behavior" Virtual and Materialized Views" Indexes: Speeding Accesses to Data" Transaction = process involving database queries and/or modification."
Introduction to Transactions: Controlling Concurrent "Behavior" Virtual and Materialized Views" Indexes: Speeding Accesses to Data" Transaction = process involving database queries and/or modification."
Enterprise Data Catalog for Microsoft Azure Tutorial
 Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Enterprise Data Catalog for Microsoft Azure Tutorial VERSION 10.2 JANUARY 2018 Page 1 of 45 Contents Tutorial Objectives... 4 Enterprise Data Catalog Overview... 5 Overview... 5 Objectives... 5 Enterprise
Jarek Szlichta
 Jarek Szlichta http://data.science.uoit.ca/ Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns
Jarek Szlichta http://data.science.uoit.ca/ Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Author Prediction for Turkish Texts
 Ziynet Nesibe Computer Engineering Department, Fatih University, Istanbul e-mail: admin@ziynetnesibe.com Abstract Author Prediction for Turkish Texts The main idea of authorship categorization is to specify
Ziynet Nesibe Computer Engineering Department, Fatih University, Istanbul e-mail: admin@ziynetnesibe.com Abstract Author Prediction for Turkish Texts The main idea of authorship categorization is to specify
WEKA: Practical Machine Learning Tools and Techniques in Java. Seminar A.I. Tools WS 2006/07 Rossen Dimov
 WEKA: Practical Machine Learning Tools and Techniques in Java Seminar A.I. Tools WS 2006/07 Rossen Dimov Overview Basic introduction to Machine Learning Weka Tool Conclusion Document classification Demo
WEKA: Practical Machine Learning Tools and Techniques in Java Seminar A.I. Tools WS 2006/07 Rossen Dimov Overview Basic introduction to Machine Learning Weka Tool Conclusion Document classification Demo
Tutorial #1: Using Latent GOLD choice to Estimate Discrete Choice Models
 Tutorial #1: Using Latent GOLD choice to Estimate Discrete Choice Models In this tutorial, we analyze data from a simple choice-based conjoint (CBC) experiment designed to estimate market shares (choice
Tutorial #1: Using Latent GOLD choice to Estimate Discrete Choice Models In this tutorial, we analyze data from a simple choice-based conjoint (CBC) experiment designed to estimate market shares (choice
1 Topic. Image classification using Knime.
 1 Topic Image classification using Knime. The aim of image mining is to extract valuable knowledge from image data. In the context of supervised image classification, we want to assign automatically a
1 Topic Image classification using Knime. The aim of image mining is to extract valuable knowledge from image data. In the context of supervised image classification, we want to assign automatically a
Manual For Biometric User Authentication on Smartphone Accelerometer Sensor Data
 PACE UNIVERSITY; CAPSTONE PROJECT - BIOMETRIC AUTHENTICATION & ACCELEROMETER SENSOR 1 Manual For Biometric User Authentication on Smartphone Accelerometer Sensor Data Noufal Kunnathu, Seidenberg School
PACE UNIVERSITY; CAPSTONE PROJECT - BIOMETRIC AUTHENTICATION & ACCELEROMETER SENSOR 1 Manual For Biometric User Authentication on Smartphone Accelerometer Sensor Data Noufal Kunnathu, Seidenberg School
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Python With Data Science
 Course Overview This course covers theoretical and technical aspects of using Python in Applied Data Science projects and Data Logistics use cases. Who Should Attend Data Scientists, Software Developers,
Course Overview This course covers theoretical and technical aspects of using Python in Applied Data Science projects and Data Logistics use cases. Who Should Attend Data Scientists, Software Developers,
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Machine Learning Chapter 2. Input
 Machine Learning Chapter 2. Input 2 Input: Concepts, instances, attributes Terminology What s a concept? Classification, association, clustering, numeric prediction What s in an example? Relations, flat
Machine Learning Chapter 2. Input 2 Input: Concepts, instances, attributes Terminology What s a concept? Classification, association, clustering, numeric prediction What s in an example? Relations, flat
Using Weka for Classification. Preparing a data file
 Using Weka for Classification Preparing a data file Prepare a data file in CSV format. It should have the names of the features, which Weka calls attributes, on the first line, with the names separated
Using Weka for Classification Preparing a data file Prepare a data file in CSV format. It should have the names of the features, which Weka calls attributes, on the first line, with the names separated
Data Preprocessing Yudho Giri Sucahyo y, Ph.D , CISA
 Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
Obj ti Objectives Motivation: Why preprocess the Data? Data Preprocessing Techniques Data Cleaning Data Integration and Transformation Data Reduction Data Preprocessing Lecture 3/DMBI/IKI83403T/MTI/UI
A l Ain University Of Science and Technology
 A l Ain University Of Science and Technology 4 Handout(4) Database Management Principles and Applications The Entity Relationship (ER) Model http://alainauh.webs.com/ http://www.comp.nus.edu.sg/~lingt
A l Ain University Of Science and Technology 4 Handout(4) Database Management Principles and Applications The Entity Relationship (ER) Model http://alainauh.webs.com/ http://www.comp.nus.edu.sg/~lingt
CS5670: Computer Vision
 CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
CS5670: Computer Vision Noah Snavely Lecture 33: Recognition Basics Slides from Andrej Karpathy and Fei-Fei Li http://vision.stanford.edu/teaching/cs231n/ Announcements Quiz moved to Tuesday Project 4
Section 2.3: Simple Linear Regression: Predictions and Inference
 Section 2.3: Simple Linear Regression: Predictions and Inference Jared S. Murray The University of Texas at Austin McCombs School of Business Suggested reading: OpenIntro Statistics, Chapter 7.4 1 Simple
Section 2.3: Simple Linear Regression: Predictions and Inference Jared S. Murray The University of Texas at Austin McCombs School of Business Suggested reading: OpenIntro Statistics, Chapter 7.4 1 Simple
Computing a Gain Chart. Comparing the computation time of data mining tools on a large dataset under Linux.
 1 Introduction Computing a Gain Chart. Comparing the computation time of data mining tools on a large dataset under Linux. The gain chart is an alternative to confusion matrix for the evaluation of a classifier.
1 Introduction Computing a Gain Chart. Comparing the computation time of data mining tools on a large dataset under Linux. The gain chart is an alternative to confusion matrix for the evaluation of a classifier.
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
CMPUT 695 Fall 2004 Assignment 2 Xelopes
 CMPUT 695 Fall 2004 Assignment 2 Xelopes Paul Nalos, Ben Chu November 5, 2004 1 Introduction We evaluated Xelopes, a data mining library produced by prudsys 1. Xelopes is available for Java, C++, and CORBA
CMPUT 695 Fall 2004 Assignment 2 Xelopes Paul Nalos, Ben Chu November 5, 2004 1 Introduction We evaluated Xelopes, a data mining library produced by prudsys 1. Xelopes is available for Java, C++, and CORBA
Data warehouse and Data Mining
 Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Acknowledgment. MTAT Data Mining. Week 7: Online Analytical Processing and Data Warehouses. Typical Data Analysis Process.
 MTAT.03.183 Data Mining Week 7: Online Analytical Processing and Data Warehouses Marlon Dumas marlon.dumas ät ut. ee Acknowledgment This slide deck is a mashup of the following publicly available slide
MTAT.03.183 Data Mining Week 7: Online Analytical Processing and Data Warehouses Marlon Dumas marlon.dumas ät ut. ee Acknowledgment This slide deck is a mashup of the following publicly available slide
Mathematics of Data. INFO-4604, Applied Machine Learning University of Colorado Boulder. September 5, 2017 Prof. Michael Paul
 Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
PS 6: Regularization. PART A: (Source: HTF page 95) The Ridge regression problem is:
 The Ridge regression problem is:") Economics 1660: Big Data PS 6: Regularization Prof. Daniel Björkegren PART A: (Source: HTF page 95) The Ridge regression problem is: : β "#$%& = argmin (y # β 2 x #4 β 4 ) 6 6 + λ β 4 #89 Consider the
Economics 1660: Big Data PS 6: Regularization Prof. Daniel Björkegren PART A: (Source: HTF page 95) The Ridge regression problem is: : β "#$%& = argmin (y # β 2 x #4 β 4 ) 6 6 + λ β 4 #89 Consider the
Frequency Tables. Chapter 500. Introduction. Frequency Tables. Types of Categorical Variables. Data Structure. Missing Values
 Chapter 500 Introduction This procedure produces tables of frequency counts and percentages for categorical and continuous variables. This procedure serves as a summary reporting tool and is often used
Chapter 500 Introduction This procedure produces tables of frequency counts and percentages for categorical and continuous variables. This procedure serves as a summary reporting tool and is often used
Bulldozers II. Tomasek,Hajic, Havranek, Taufer
 Bulldozers II Tomasek,Hajic, Havranek, Taufer Building database CSV -> SQL Table trainraw 1 : 1 parsed csv data input Building database table trainraw Columns need transformed into the form for effective
Bulldozers II Tomasek,Hajic, Havranek, Taufer Building database CSV -> SQL Table trainraw 1 : 1 parsed csv data input Building database table trainraw Columns need transformed into the form for effective
CS377: Database Systems Data Warehouse and Data Mining. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Data Warehouse and Data Mining Li Xiong Department of Mathematics and Computer Science Emory University 1 1960s: Evolution of Database Technology Data collection, database creation,
CS377: Database Systems Data Warehouse and Data Mining Li Xiong Department of Mathematics and Computer Science Emory University 1 1960s: Evolution of Database Technology Data collection, database creation,
Structured Query Language Continued. Rose-Hulman Institute of Technology Curt Clifton
 Structured Query Language Continued Rose-Hulman Institute of Technology Curt Clifton The Story Thus Far SELECT FROM WHERE SELECT * SELECT Foo AS Bar SELECT expression SELECT FROM WHERE LIKE SELECT FROM
Structured Query Language Continued Rose-Hulman Institute of Technology Curt Clifton The Story Thus Far SELECT FROM WHERE SELECT * SELECT Foo AS Bar SELECT expression SELECT FROM WHERE LIKE SELECT FROM
OLAP Drill-through Table Considerations
 Paper 023-2014 OLAP Drill-through Table Considerations M. Michelle Buchecker, SAS Institute, Inc. ABSTRACT When creating an OLAP cube, you have the option of specifying a drill-through table, also known
Paper 023-2014 OLAP Drill-through Table Considerations M. Michelle Buchecker, SAS Institute, Inc. ABSTRACT When creating an OLAP cube, you have the option of specifying a drill-through table, also known
Views, Indexes, Authorization. Views. Views 8/6/18. Virtual and Materialized Views Speeding Accesses to Data Grant/Revoke Priviledges
 Views, Indexes, Authorization Virtual and Materialized Views Speeding Accesses to Data Grant/Revoke Priviledges 1 Views External Schema (Views) Conceptual Schema Physical Schema 2 Views A view is a relation
Views, Indexes, Authorization Virtual and Materialized Views Speeding Accesses to Data Grant/Revoke Priviledges 1 Views External Schema (Views) Conceptual Schema Physical Schema 2 Views A view is a relation
Data Mining and Analytics. Introduction
 Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
Data Mining and Analytics Introduction Data Mining Data mining refers to extracting or mining knowledge from large amounts of data It is also termed as Knowledge Discovery from Data (KDD) Mostly, data
Introduction to SPSS Faiez Mossa 2 nd Class
 Introduction to SPSS 16.0 Faiez Mossa 2 nd Class 1 Outline Review of Concepts (stats and scales) Data entry (the workspace and labels) By hand Import Excel Running an analysis- frequency, central tendency,
Introduction to SPSS 16.0 Faiez Mossa 2 nd Class 1 Outline Review of Concepts (stats and scales) Data entry (the workspace and labels) By hand Import Excel Running an analysis- frequency, central tendency,
INTERMEDIATE SQL GOING BEYOND THE SELECT. Created by Brian Duffey
 INTERMEDIATE SQL GOING BEYOND THE SELECT Created by Brian Duffey WHO I AM Brian Duffey 3 years consultant at michaels, ross, and cole 9+ years SQL user What have I used SQL for? ROADMAP Introduction 1.
INTERMEDIATE SQL GOING BEYOND THE SELECT Created by Brian Duffey WHO I AM Brian Duffey 3 years consultant at michaels, ross, and cole 9+ years SQL user What have I used SQL for? ROADMAP Introduction 1.
Lab Assignment 1. Part 1: Feature Selection, Cleaning, and Preprocessing to Construct a Data Source as Input
 CIS 660 Data Mining Sunnie Chung Lab Assignment 1 The Marketing department of Adventure Works Cycles wants to increase sales by targeting specific customers for a mailing campaign. The company's database
CIS 660 Data Mining Sunnie Chung Lab Assignment 1 The Marketing department of Adventure Works Cycles wants to increase sales by targeting specific customers for a mailing campaign. The company's database
A case study to introduce Microsoft Data Mining in the database course
 A case study to introduce Microsoft Data Mining in the database course ABSTRACT Mohammad Dadashzadeh Oakland University The content of the database management systems course in the business curriculum
A case study to introduce Microsoft Data Mining in the database course ABSTRACT Mohammad Dadashzadeh Oakland University The content of the database management systems course in the business curriculum
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Chapter 8 The C 4.5*stat algorithm
 109 The C 4.5*stat algorithm This chapter explains a new algorithm namely C 4.5*stat for numeric data sets. It is a variant of the C 4.5 algorithm and it uses variance instead of information gain for the
109 The C 4.5*stat algorithm This chapter explains a new algorithm namely C 4.5*stat for numeric data sets. It is a variant of the C 4.5 algorithm and it uses variance instead of information gain for the
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
The Relational Model (ii)
") ICS 321 Fall 2009 The Relational Model (ii) Asst. Prof. Lipyeow Lim Information and Computer Science Department University of Hawaii at Manoa 1 Internet Book Store Example Isbn title author qty price year
ICS 321 Fall 2009 The Relational Model (ii) Asst. Prof. Lipyeow Lim Information and Computer Science Department University of Hawaii at Manoa 1 Internet Book Store Example Isbn title author qty price year
WKA Studio for Beginners
 WKA Studio for Beginners The first and foremost, the WKA Studio app and its development are fundamentally different from conventional apps work and their developments using higher level programming languages
WKA Studio for Beginners The first and foremost, the WKA Studio app and its development are fundamentally different from conventional apps work and their developments using higher level programming languages
A Review on Cluster Based Approach in Data Mining
 A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
A Review on Cluster Based Approach in Data Mining M. Vijaya Maheswari PhD Research Scholar, Department of Computer Science Karpagam University Coimbatore, Tamilnadu,India Dr T. Christopher Assistant professor,
The Volcano Optimizer Generator: Extensibility and Efficient Search
 The Volcano Optimizer Generator: Extensibility and Efficient Search Presenter: Zicun Cong School of Computing Science Simon Fraser University CMPT843, February 6, 2016 1 / 18 Outline Introduction Method
The Volcano Optimizer Generator: Extensibility and Efficient Search Presenter: Zicun Cong School of Computing Science Simon Fraser University CMPT843, February 6, 2016 1 / 18 Outline Introduction Method
SAP InfiniteInsight 7.0 Event Logging: Make the Most Out of Your Transaction Data
 End User Documentation Document Version: 1.0 2014-11 Event Logging: Make the Most Out of Your Transaction Data Table of Contents Before you Start... 4 About this Document... 4 Prerequisites... 4 Technical
End User Documentation Document Version: 1.0 2014-11 Event Logging: Make the Most Out of Your Transaction Data Table of Contents Before you Start... 4 About this Document... 4 Prerequisites... 4 Technical
Data Mining. 2.4 Data Integration. Fall Instructor: Dr. Masoud Yaghini. Data Integration
 Data Mining 2.4 Fall 2008 Instructor: Dr. Masoud Yaghini Data integration: Combines data from multiple databases into a coherent store Denormalization tables (often done to improve performance by avoiding
Data Mining 2.4 Fall 2008 Instructor: Dr. Masoud Yaghini Data integration: Combines data from multiple databases into a coherent store Denormalization tables (often done to improve performance by avoiding
Tutorial on Machine Learning Tools
 Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Evaluation Report on PolyAnalyst 4.6
 1. INTRODUCTION CMPUT695: Assignment#2 Evaluation Report on PolyAnalyst 4.6 Hongqin Fan and Yunping Wang PolyAnalyst 4.6 professional edition (PA) is a commercial data mining tool developed by Megaputer
1. INTRODUCTION CMPUT695: Assignment#2 Evaluation Report on PolyAnalyst 4.6 Hongqin Fan and Yunping Wang PolyAnalyst 4.6 professional edition (PA) is a commercial data mining tool developed by Megaputer
劉介宇 國立台北護理健康大學 護理助產研究所 / 通識教育中心副教授 兼教師發展中心教師評鑑組長 Nov 19, 2012
 劉介宇 國立台北護理健康大學 護理助產研究所 / 通識教育中心副教授 兼教師發展中心教師評鑑組長 Nov 19, 2012 Overview of Data Mining ( 資料採礦 ) What is Data Mining? Steps in Data Mining Overview of Data Mining techniques Points to Remember Data mining
劉介宇 國立台北護理健康大學 護理助產研究所 / 通識教育中心副教授 兼教師發展中心教師評鑑組長 Nov 19, 2012 Overview of Data Mining ( 資料採礦 ) What is Data Mining? Steps in Data Mining Overview of Data Mining techniques Points to Remember Data mining
Introduction to object recognition. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others
 Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Data Foundations. Topic Objectives. and list subcategories of each. its properties. before producing a visualization. subsetting
 CS 725/825 Information Visualization Fall 2013 Data Foundations Dr. Michele C. Weigle http://www.cs.odu.edu/~mweigle/cs725-f13/ Topic Objectives! Distinguish between ordinal and nominal values and list
CS 725/825 Information Visualization Fall 2013 Data Foundations Dr. Michele C. Weigle http://www.cs.odu.edu/~mweigle/cs725-f13/ Topic Objectives! Distinguish between ordinal and nominal values and list
Lecture 20: Bagging, Random Forests, Boosting
 Lecture 20: Bagging, Random Forests, Boosting Reading: Chapter 8 STATS 202: Data mining and analysis November 13, 2017 1 / 17 Classification and Regression trees, in a nut shell Grow the tree by recursively
Lecture 20: Bagging, Random Forests, Boosting Reading: Chapter 8 STATS 202: Data mining and analysis November 13, 2017 1 / 17 Classification and Regression trees, in a nut shell Grow the tree by recursively
Data Analyst Nanodegree Syllabus
 Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Data Analyst Nanodegree Syllabus Discover Insights from Data with Python, R, SQL, and Tableau Before You Start Prerequisites : In order to succeed in this program, we recommend having experience working
Constraints, Views & Indexes. Running Example. Kinds of Constraints INTEGRITY CONSTRAINTS. Keys Foreign key or referential integrity constraints
 2 Constraints, Views & Indexes Introduction to databases CSCC43 Winter 2012 Ryan Johnson INTEGRITY CONSTRAINTS Thanks to Manos Papagelis, John Mylopoulos, Arnold Rosenbloom and Renee Miller for material
2 Constraints, Views & Indexes Introduction to databases CSCC43 Winter 2012 Ryan Johnson INTEGRITY CONSTRAINTS Thanks to Manos Papagelis, John Mylopoulos, Arnold Rosenbloom and Renee Miller for material
Assignment 4 (Sol.) Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran
 Introduction to Data Analytics Prof. Nandan Sudarsanam & Prof. B. Ravindran") Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Assignment 4 (Sol.) Introduction to Data Analytics Prof. andan Sudarsanam & Prof. B. Ravindran 1. Which among the following techniques can be used to aid decision making when those decisions depend upon
Database and Knowledge-Base Systems: Data Mining. Martin Ester
 Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Database and Knowledge-Base Systems: Data Mining Martin Ester Simon Fraser University School of Computing Science Graduate Course Spring 2006 CMPT 843, SFU, Martin Ester, 1-06 1 Introduction [Fayyad, Piatetsky-Shapiro
Data Mining: Classifier Evaluation. CSCI-B490 Seminar in Computer Science (Data Mining)
") Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Data Warehousing and Data Mining
 Data Warehousing and Data Mining Lecture 3 Efficient Cube Computation CITS3401 CITS5504 Wei Liu School of Computer Science and Software Engineering Faculty of Engineering, Computing and Mathematics Acknowledgement:
Data Warehousing and Data Mining Lecture 3 Efficient Cube Computation CITS3401 CITS5504 Wei Liu School of Computer Science and Software Engineering Faculty of Engineering, Computing and Mathematics Acknowledgement:
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Convex Optimization. Stephen Boyd
 Convex Optimization Stephen Boyd Electrical Engineering Computer Science Management Science and Engineering Institute for Computational Mathematics & Engineering Stanford University Institute for Advanced
Convex Optimization Stephen Boyd Electrical Engineering Computer Science Management Science and Engineering Institute for Computational Mathematics & Engineering Stanford University Institute for Advanced