BigData And the Zoo. Mansour Raad Federal GIS Conference 2014
|
|
|
- Beverley Bishop
- 5 years ago
- Views:
Transcription






1 Federal GIS Conference 2014 February 10 11, 2014 Washington DC BigData And the Zoo Mansour Raad
2 What is BigData?
3 Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it - Dan Ariely
4 No but seriously!
5 Academics Volume Velocity Variety
6 But then I ve seen Volume data at rest Velocity data in motion Variety many types, forms and structures or no structures Veracity data in doubt Validity data that is correct Visualization data in patterns Vulnerability data at risk Value data that is meaningful
7 I m sticking with Volume Velocity Variety
8 When the traditional means are failing you -Anonymous
9 What are the new means?


10
11 What Is Hadoop? Library / Framework Multi Node Distributed Processing Very Very Large Dataset Resilient To Hardware Failure
12 Hadoop Basic Stack MapReduce Yet Another Resource Negotiator (YARN) Hadoop Distributed File System (HDFS) Commodity Servers
13 Other Hadoop Projects Avro - Serialization / RPC System HBase - Distributed Columnar Database Hive - Ad Hoc SQL Interface Pig - Data Flow Parallel Execution (AML) ZooKeeper - Coordination Service More.
14 HDFS Distributed File System Lots and Lots of Commodity Drives Fault Tolerant Loves Big Files POSIX Like Interface
15 HDFS HDFS Client NameNode DataNode DataNode DataNode
16 HDFS Resilience! HDFS DataNode DataNode DataNode
17 Program BigData
18 Program BigData
19 MapReduce
20 What Is MapReduce? Parallel Fault Tolerant Framework Splits Large Input Invoke User Defined Map Function Shuffle and Sort Invoke User Defined Reduce Function


21 MapReduce
22 MapReduce & HDFS Client.jar Job Tracker Name Node Task Tracker Data Node Task Tracker Data Node Task Tracker Data Node
23 Thinking In MR K1,V1 K2,list(V2) Map list(k2,v2) Reduce list(k3,v3) Shuffle/Sort (filter & transform) (group & aggregate)
24 Hello MapReduce!
25 ID1,X1,Y1 ID2,X2,Y2 ID3,X3,Y3 ID4,X4,Y4 DensityMap
26 DensityMap function map(lineno,text) { tokens = text.split(, ) cell = tocell(tokens[1],tokens[2]) emit( cell, 1) } function tocell(x,y) { // some math!! return cell } function reduce(cell,iterator) { sum = 0 for( one : iterator) sum += one emit( cell, sum) }
27 Writing MR Is Hard

28
29 Think of Data as Water In Pipes


30 Workflow Pipeline Filter X,Y Collection Source To Cell M GroupBy R count Cell Count Sink
31 Cascading pipeline MapReduce Job
32 Cascading Pipe // Pipe tap x,y input fields into spatial function Pipe pipe = new Each("start", new Fields("X", "Y"), new SpatialDensity()); // Group by emitted cell value pipe = new GroupBy(pipe, cell ); // Count by group and name count POPULATION pipe = new Every(pipe, Fields.GROUP, new Count(new Fields("POPULATION")));
33 How About. No Programing???

34 Apache HIVE
35 Apache HIVE SQL MapReduce Job
36 HQL drop table if exists logs; create external table if not exists logs( ip string, method string, uri string, status string, bytes int, time_taken int, referrer string, user_agent string ) partitioned by (year int, month int, day int, hour int) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile location hdfs://hadoop:8020/logs/';
37 HQL $ hive hive> select hour,count(hour) from logs where year=2014 and month=01 and uri = group by hour order by hour;
38 Other AdHoc Engines Cloudera Impala Facebook Presto Amplab Shark Bypass MR generation / Direct HDFS Access
39 What About Spatial?




40
41 GIS Tools For Hadoop Open Source / Github Apache 2.0 License Geometry API Spatial Framework Hive GeoProcessing Tools
42 Geometry API Shapes Points Polylines Polygons Envelopes
43 Geometry API Geometry Operations Contains / Intersects / Union / Difference / Buffer / ConvexHull Spatial Index
44 Geometry API I/O Operations WKT OGC GeoJSON Shape (bin)
45 API Usage in BigData Map-only jobs - GeoEnrichment Given set of locations Given demographic area Augment location with demographic attributes
46 BigData Binning
47 BigData Binning

48 BigData Binning
49 BigData Spatial Join knn Range Queries Custom Input Format
50 SQL Is Still King!
51 Spatial Hive UDF (User Defined Functions)
52 Spatial Hive UDF Uses Geometry API Constructor ST_POINT / ST_GeomFromGeoJSON Relations ST_Contains / ST_Buffer Accessor ST_Distance, ST_Area
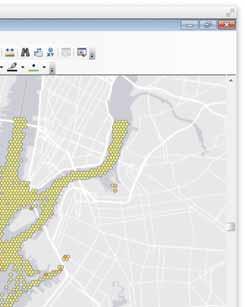
53 Spatial Hive SELECT counties.name, count(*) cnt FROM counties JOIN earthquakes WHERE ST_Contains(counties.boundaryshape, ST_Point(earthquakes.longitude, earthquakes.latitude)) GROUP BY counties.name ORDER BY cnt desc;
54 AIS Demo
55 AIS Data 14.8 million GPS information 1 month Zone 18 (North East / NY Area) MMSI, ZuluTime, Lon/Lat, VoyageId, Draught
56 Demo Steps GP Toolbox Track Assembly From Targets Hex Generation Density Analysis

57 AIS CSV Import Partitioner /ais/yyyy/mm/dd/hh/uuid.csv HDFS MapReduce



58






59






60





61
62 How to get started?





63 Cloudera QuickStart VM
64 Book That I Recommend Hadoop - The Definitive Guide Hadoop In Action HBase In Action Hadoop - Real World Solution Cookbook MapReduce Design Pattern
65 Q&A
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Click Stream Data Analysis Using Hadoop
 Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Click Stream Data Analysis Using Hadoop Krishna Chand Reddy Gaddam Governors
Governors State University OPUS Open Portal to University Scholarship All Capstone Projects Student Capstone Projects Spring 2015 Click Stream Data Analysis Using Hadoop Krishna Chand Reddy Gaddam Governors
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Hadoop: The Definitive Guide
 THIRD EDITION Hadoop: The Definitive Guide Tom White Q'REILLY Beijing Cambridge Farnham Köln Sebastopol Tokyo labte of Contents Foreword Preface xv xvii 1. Meet Hadoop 1 Daw! 1 Data Storage and Analysis
THIRD EDITION Hadoop: The Definitive Guide Tom White Q'REILLY Beijing Cambridge Farnham Köln Sebastopol Tokyo labte of Contents Foreword Preface xv xvii 1. Meet Hadoop 1 Daw! 1 Data Storage and Analysis
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Big Data and Hadoop. Course Curriculum: Your 10 Module Learning Plan. About Edureka
 Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Hadoop Online Training
 Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Hadoop Online Training IQ training facility offers Hadoop Online Training. Our Hadoop trainers come with vast work experience and teaching skills. Our Hadoop training online is regarded as the one of the
Big Data Technologies and Geospatial Data Processing:
 Big Data Technologies and Geospatial Data Processing: A perfect fit Albert Godfrind Spatial and Graph Solutions Architect Oracle Corporation Agenda 1 2 3 4 The Data Explosion Big Data? Big Data and Geo
Big Data Technologies and Geospatial Data Processing: A perfect fit Albert Godfrind Spatial and Graph Solutions Architect Oracle Corporation Agenda 1 2 3 4 The Data Explosion Big Data? Big Data and Geo
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
I am a Data Nerd and so are YOU!
 I am a Data Nerd and so are YOU! Not This Type of Nerd Data Nerd Coffee Talk We saw Cloudera as the lone open source champion of Hadoop and the EMC/Greenplum/MapR initiative as a more closed and
I am a Data Nerd and so are YOU! Not This Type of Nerd Data Nerd Coffee Talk We saw Cloudera as the lone open source champion of Hadoop and the EMC/Greenplum/MapR initiative as a more closed and
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Big Data and Scripting map reduce in Hadoop
 Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Bring Location Intelligence To Big Data Applications on Hadoop, Spark, and NoSQL
 Bring Location Intelligence To Big Data Applications on Hadoop, Spark, and NoSQL Siva Ravada Senior Director of Development Copyright 2015, Oracle and/or its affiliates. All rights reserved. Program Agenda
Bring Location Intelligence To Big Data Applications on Hadoop, Spark, and NoSQL Siva Ravada Senior Director of Development Copyright 2015, Oracle and/or its affiliates. All rights reserved. Program Agenda
Cmprssd Intrduction To
 Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Cmprssd Intrduction To Hadoop, SQL-on-Hadoop, NoSQL Arseny.Chernov@Dell.com Singapore University of Technology & Design 2016-11-09 @arsenyspb Thank You For Inviting! My special kind regards to: Professor
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
A Glimpse of the Hadoop Echosystem
 A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
A Glimpse of the Hadoop Echosystem 1 Hadoop Echosystem A cluster is shared among several users in an organization Different services HDFS and MapReduce provide the lower layers of the infrastructures Other
Vendor: Cloudera. Exam Code: CCD-410. Exam Name: Cloudera Certified Developer for Apache Hadoop. Version: Demo
 Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Big Data for Engineers Spring Resource Management
 Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
Ghislain Fourny Big Data for Engineers Spring 2018 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
HBase... And Lewis Carroll! Twi:er,
 HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Big Data 7. Resource Management
 Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Ghislain Fourny Big Data 7. Resource Management artjazz / 123RF Stock Photo Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
MapReduce review. Spark and distributed data processing. Who am I? Today s Talk. Reynold Xin
 Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
The Reality of Qlik and Big Data. Chris Larsen Q3 2016
 The Reality of Qlik and Big Data Chris Larsen Q3 2016 Introduction Chris Larsen Sr Solutions Architect, Partner Engineering @Qlik Based in Lund, Sweden Primary Responsibility Advanced Analytics (and formerly
The Reality of Qlik and Big Data Chris Larsen Q3 2016 Introduction Chris Larsen Sr Solutions Architect, Partner Engineering @Qlik Based in Lund, Sweden Primary Responsibility Advanced Analytics (and formerly
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Big Data Development HADOOP Training - Workshop. FEB 12 to (5 days) 9 am to 5 pm HOTEL DUBAI GRAND DUBAI
 9 am to 5 pm HOTEL DUBAI GRAND DUBAI") Big Data Development HADOOP Training - Workshop FEB 12 to 16 2017 (5 days) 9 am to 5 pm HOTEL DUBAI GRAND DUBAI ISIDUS TECH TEAM FZE PO Box 9798 Dubai UAE, email training-coordinator@isidusnet M: +97150
Big Data Development HADOOP Training - Workshop FEB 12 to 16 2017 (5 days) 9 am to 5 pm HOTEL DUBAI GRAND DUBAI ISIDUS TECH TEAM FZE PO Box 9798 Dubai UAE, email training-coordinator@isidusnet M: +97150
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma
 Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Data Partitioning and MapReduce
 Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Data Partitioning and MapReduce Krzysztof Dembczyński Intelligent Decision Support Systems Laboratory (IDSS) Poznań University of Technology, Poland Intelligent Decision Support Systems Master studies,
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
We are ready to serve Latest Testing Trends, Are you ready to learn.?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn.?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : About Quality Thought We are
We are ready to serve Latest Testing Trends, Are you ready to learn.?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : About Quality Thought We are