Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma
|
|
|
- Lawrence Cobb
- 6 years ago
- Views:
Transcription
1 Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma
2 Course Schedule Tuesday Introduction and the Big Data Challenge Tuesday MapReduce and Spark: Overview Tuesday MapReduce Optimizations and Algorithms. Spark Internals. Tuesday Distributed algorithms for Big Data: Elastic Data Processing and Developing Spark Algorithms. Tuesday MLBase, MLLib, and GraphX. Streaming Spark. Tuesday Industry views to Big Data Tuesday Summary Four exercise problem sheets
3 Big Data A massive volume of structured and unstructured data Cannot be processed with traditional database and software solutions Traditional data analysis algorithms run too slow over the data High-volume, high-velocity, high-variety Big Data Pipeline: Data acquisition, storage, analysis, post-processing, results
4 Big Data Process 1. Acquisition 2. Extraction 3. Integration 4. Analysis 5. Interpretation 6. Decision 7. Understanding decision and starting from 1. We have a feedback loop and the process is iterative.










5 Apache Hadoop Ecosystem Analysis BI reporting RDBMS Pig (data flow) Hive (SQL) Sqoop Zookeeper MapReduce and YARN (also Spark) Avro Serialization HBase HDFS
6 BDAS BlinkDB SQL w/ bounded errors/response times Spark Streaming Stream processing GraphX Graph computation MLlib User-friendly machine learning SparkSQL SQL API Hive Storm MPI Spark Fast memory-optimized execution engine (Python/Java/Scala APIs) Hadoop MR Tachyon Distributed Memory-Centric Storage System HDFS, S3, GlusterFS Mesos Cluster resource manager, multi-tenancy Supported Release In Development Related External Project







7 Lambda Architecture All data Batch processing (analysis) and storage Batch results New data and its acquisition Real-time data storage and processing Data analysis Combined results This is integrated in Spark
8 MapReduce Model Google MapReduce introduced in 2004 Jeffrey Dean et al. MapReduce: Simplified Data Processing on Large Clusters. OSDI Apache Hadoop since Apache Hadoop 2.0 introduced in 2012 Vinod Kumar Vavilapalli et al. Apache Hadoop YARN: Yet Another Resource Negotiator, SOCC New cluster resource management layer (YARN)
9 MapReduce Automatic distribution and parallelization Fault-tolerance Cluster management tools Abstraction for programmers
10 MapReduce Worker (1)fork (2)assign map User program (1)fork Master (2) assign reduce (1)fork Example: Map: word len as key Reduce: number of words per word len split 0 split 1 split 2 (3)read Worker (4) local write (5)Remote read Worker (6)write output file 0 split 3 split 4 Worker output file 1 Worker Input files Map phase Intermediate files (on local disks) Reduce phase Output files
11 MapReduce Summary Two key functions that need to be implemented: map (in_key, in_value) à (out_key, intermediate_value) list reduce (out_key, intermediate_value list) à out_value list With two optimizations: combine (key, intermediate_value list) à intermediate_out_value list partition (key, number of partitions) à partition for key
12 Partition and Shuffle Data loading is expensive!"##$%!"##$%!"##$%!"##$% &'()$%*$+'")$,- &'()$%*$+'")$,- &'()$%*$+'")$,- &'()$%*$+'")$,- 1"%)')'2($% 1"%)')'2($% 1"%)')'2($% 1"%)')'2($%,3/ 5'(! &'()$%*$+'")$,- &'()$%*$+'")$,- &'()$%*$+'")$,- Shuffling is expensive.$+/0$%.$+/0$%.$+/0$%
13 Hadoop Hadoop is an Apache open source framework that implements the MapReduce paradigm Originally created by Yahoo! Hadoop is based on the HDFS file system Hadoop has its own RPC protocol The Hadoop framework includes Apache Pig, Apache Hbase, Apache Hive, Apache Spark, Used in production systems by Facebook, Google, Yahoo! And many other companies h"p://hadoop.apache.org/
14 HDFS Architecture HDFS has a master/slave architecture NameNode is the master server for metadata DataNodes manage storage A file is stored as a sequence of blocks The blocks are replicated for fault-tolerance Common replication scheme: factor of 3, one replica local, two in a remote rack Rack-aware replica placement Namenode provides information for retrieving blocks Nearest replica is used to retrieve a block
15 Key algorithms for MapReduce Inverted Index Statistics Sorting Searching K-Means Transitive closure PageRank Advanced algorithms
16 K-Means for MapReduce Map phase Each map reads the K centroids and a block from the input dataset Each point is assigned to the closest centroid Output: <centroid, point> Reduce phase Obtain all points for a given centroid Recompute the new centroid Output: <new centroid> Iteration: Compare the old and new set of K centroids If they are similar then Stop Else Start another iteration unless maximum of iterations has been reached.
17 MapReduce K-Means k i = k centroids at iteration i P0 k i M r P1 k i M r k i+1 P2 k i M k i - k i+1 < threshold? i=i+1 Client done Limitation: reads the whole point set P at each iteration Source: HaLoop presentation, Yyingyi Bu et al. VLDB 2010
18 Optimizing K-Means for MapReduce Combiners can be used to optimize the distributed algorithm Compute for each centroid the local sums of the points Send to the reducer: <centroid, partial sums> Use of a single reducer Data to reducers is very small Single reducer can tell immediately if the computation has converged Creation of a single output file

19 HaLoop for iterative MapReduce MapReduce cannot express iteration or recursion HaLooP modifies Hadoop for supporting fixpoint operations, loop-aware task scheduling, and cache management Map Reduce Fixpoint model for recursive languages For example: the vector of PageRank values of web pages is the fixed point of a linear transformation derived from the link structure Source: HaLoop presentation, Yyingyi Bu et al. VLDB 2010
20 HaLoop: Inter-iteration caching Loop body M M M Mapper output cache (MO) r r Reducer output cache (RO) for access to output of previous iterations, for fixpoint evaluation Reducer input cache (RI) for loop invariant data without map/shuffle Mapper input cache (MI) for access to nonlocal mapper input on later iterations Source: HaLoop presentation, Yyingyi Bu et al. VLDB 2010 Largest gain by caching loop invariant data
21 Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based on MapReduce enhanced with new operations and an engine that supports execution graphs Tools include Spark SQL, MLLlib for machine learning, GraphX for graph processing and Spark Streaming

22 Spark Aim Unifies batch, streaming, interactive computing Making it easy to build sophisticated applications
23 Key idea in Spark Resilient distributed datasets (RDDs) Immutable collections of objects across a cluster Built with parallel transformations (map, filter, ) Automatically rebuilt when failure is detected Allow persistence to be controlled (in-memory operation) Transformations on RDDs Lazy operations to build RDDs from other RDDs Always creates a new RDD Actions on RDDs Count, collect, save

24 Spark overview Worker Node Executor Tasks Cache Driver Program SparkContext Spark Scheduler Cluster Manager Spark Scheduler SparkContext connects to a cluster manager Obtains executors on cluster nodes Sends app code to them Sends task to the executors Worker Node Executor Tasks Cache
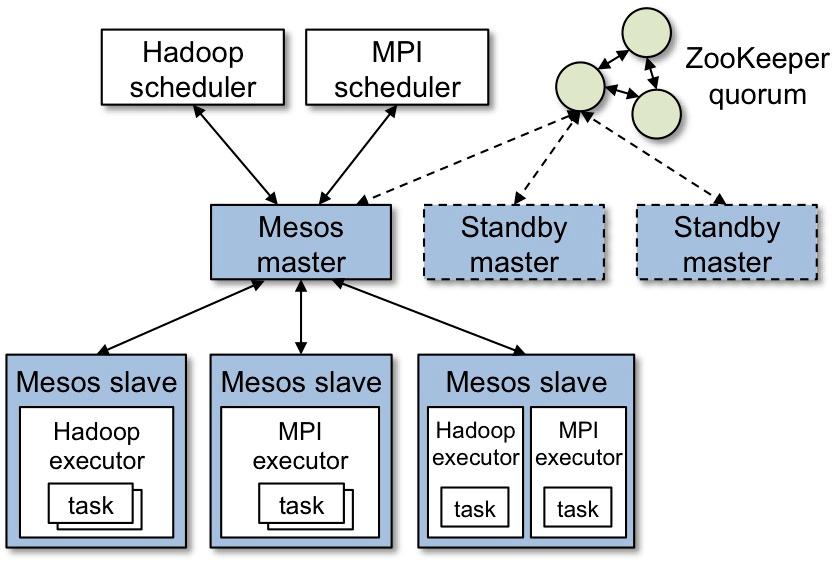
25 MESOS Architecture
26 Task Scheduler Supports general task graphs Pipelines functions where possible Cache-aware data reuse & locality Partitioning-aware to avoid shuffles A: B: Stage 1 groupby C: D: E: F: join MESOS provides resource allocation (offer resources to framework, accept/reject by framework scheduler) Stage 2 map filter = RDD Stage 3 = cached partition M.Zaharia. Parallel programming with Spark. O Reilly Strata Conference. February 2013.
27 Implementing Spark Algorithms Broadcast everything Master broadcasts data and initial models At each iteration updated models are broadcast by master (driver program) Does not scale well due to communication overhead Data parallel Worker loads data Master broadcasts initial models At each iteration updated models are broadcast by master Works for large datasets, because data is available to workers Fully parallel Workers load data and they instantiate the models At each iteration, models are shared via join between workers Much better scalability
28 Machine Learning and Spark Spark RDDs support efficient data sharing In-memory caching increases performance Reported to have performance of up to 100 times faster than Hadoop in memory or 10 times faster on disk High-level programming interface for complex algorithms
 is an API for machine learning development that aims to abstract low-level details from the developers MLOpt is a declarative layer that aims to automate")

29 MLBase and MLlib MLBase has been designed for simplifying the development of machine learning pipelines: MLlib is a machine learning library MLI (ML Developer API) is an API for machine learning development that aims to abstract low-level details from the developers MLOpt is a declarative layer that aims to automate the machine learning pipeline The idea is that the system searches feature extractors and models best fit for the ML task Source: Towards an Optimizer for MLbase, Ameet Talwalkar, Databricks, Matlab stack Matlab interface Lapack fortran linear algebra library ML Optimizer MLI MLLib MLBase stack Single machine Spark
30 Graph-Parallel Systems Graph-based computation depends only on the neighbors of a particular vertex Think like a Vertex. Pregel (SIGMOD 2010) Systems with specialized APIs to simplify graph processing Pregel from Google Push abstraction: Vertex programs interact by sending messages Receive msgs, process, send msgs GraphLab Pull abstraction: Vertex programs access adjacent vertices and edges Foreach (j in neighbours) calculate pagerank total for j
31 GraphX Separation of system support for each view (table, graph) involves expensive data movement and duplication GraphX makes tables and graphs views of the same physical data The views have their own optimized semantics Table operators inherited from Spark Graph operators form relational algebra
32 Performance Gains for PageRank Revisited Spark is reported to be 4x faster than Hadoop Graphlab is 16x faster than Spark GraphX is roughly 3x slower than Graphlab GraphX is reported to compare favourably to Graphlab with pipelines (raw -> hyperlink -> pagerank -> top 20) Graph structure can be exploited for significant performance gains
33 Spark Streaming Spark extension of accepting and processing of streaming high-throughput live data streams Data is accepted from various sources Kafka, Flume, TCP sockets, Twitter, Machine learning algorithms and graph processing algorithms can be applied for the streams Similar systems Twitter (Storm), Google (MillWheel), Yahoo! (S4) Discretized Streams: A Fault-Tolerant Model for Scalable Stream Processing. Matei Zaharia,Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica. Berkeley EECS ( )
34 Stream Processing: Discretized Streaming computation is run as a series of very small deterministic batch jobs Live stream is divided into batches of x seconds Each batch of data is an RDD and RDD operations can be used Results are also returned in batches Batch size as low as 0.5 seconds, results in approx. one second latency Can combine streaming and batch processing
35 Discussion A distributed data operating system is emerging Supported by YARN and MESOS Various data services on top of this (Hadoop and Spark) Some services are being integrated (for example in Spark) for better coherence and performance Important points Data format (row/column, block size) Network topology and data/code placement Algorithm structure and coordination Scheduling and resource management
36 Outlook Big Data Frameworks are evolving Spark represents unification of streaming, machine learning and graphs Big Data pipeline management is at an early stage How to achieve better mapping between cluster resources, scheduling, and pipelines?
37 Exam material (in addition to slides and exercises) Articles (part of the exam material): 1. Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. Originally OSDI CACM Volume 51 Issue 1, January Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia et al. NSDI (2012) usenix.org/system/ files/conference/nsdi12/nsdi12-final138.pdf 3. HaLoop: Efficient Iterative Data Processing on Large Clusters by Yingyi Bu et al. In VLDB'10: The 36th International Conference on Very Large Data Bases, Singapore, September, MLbase: A Distributed Machine-learning System. Tim Kraska et al. CIDR Additional material (not part of the exam):
38 Grading Course grading will be based on the final exam and the assignments/exercises. Exam 60% and exercises 40% of the grade. Exam Friday :00 at B123 Exam will have essay questions 4 questions, answer 3
39 Main theme Prerequisites Approaches learning goals Meets learning goals Deepens learning goals Big Data Frameworks: definitions and systems Basics of data communications and distributed systems (Introduction to Data Communications, Distributed Systems) Knowledge of how to define the concepts of MapReduce and variants and state their central features Ability to describe at least one system in detail Ability of being able to compare different Big Data frameworks in a qualitative manner Ability to assess the suitability of different systems to different use cases Ability to give one s own definition of the central concepts and discuss the key design and deployment issues Internal operation and implementation of a Big Data framework Basics of data communications and distributed systems (Introduction to Data Communications, Distributed Systems) Big-O-notation and basics of algorithmic complexity Basics of reliability in distributed systems Knowledge of the design and implementation level concepts of Big Data frameworks, specifically Hadoop and Spark. Knowledge of how distributed state is maintained and synchronized. Understanding of the communication and computational costs in Big Data processing. Ability of being able to compare different Big Data frameworks based on their design and implementation. Ability of designing distributed Big Data systems building on existing frameworks for batch and streaming processing. Knowledge of key performance issues and the ability to analyze these systems The knowledge of designing a Big Data platform for a given problem Familiarity with the state of the art Ability to describe at least one algorithm in detail Knowledge of the most important factors pertaining to reliability Distributed algorithms for Big Data frameworks Basics of algorithm design and machine learning Knowledge of the basic design of a distributed algorithm for MapReduce and Spark. Ability to use graph processing and machine learning in a distributed cluster environment Ability to design and implement a solution that uses distributed algorithms for a large dataset Ability to create both batch and streaming solutions Design and implementation of a new machine learning algorithm for Big Data Familiarity with the state of the art Data Science applications - Knowledge of the basic Data Science use cases based on Big Data frameworks Knowledge of at least two Data Science use cases and how they use the Big Data framework Knowledge of Data Science pipelines Familiarity with the state of the art Automation of Data Science pipelines
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Spark Streaming. Professor Sasu Tarkoma.
 Spark Streaming 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Spark Streaming Spark extension of accepting and processing of streaming high-throughput live data streams Data is accepted from various sources
Spark Streaming 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Spark Streaming Spark extension of accepting and processing of streaming high-throughput live data streams Data is accepted from various sources
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
The Datacenter Needs an Operating System
 UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
UC BERKELEY The Datacenter Needs an Operating System Anthony D. Joseph LASER Summer School September 2013 My Talks at LASER 2013 1. AMP Lab introduction 2. The Datacenter Needs an Operating System 3. Mesos,
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
MLBase, MLLib and GraphX
 MLBase, MLLib and GraphX 2015 Professor Sasu Tarkoma www.cs.helsinki.fi MLBase and MLlib: Vision Same system for Exploring data interactively using Spark Spark standalone programs Spark streaming for problems
MLBase, MLLib and GraphX 2015 Professor Sasu Tarkoma www.cs.helsinki.fi MLBase and MLlib: Vision Same system for Exploring data interactively using Spark Spark standalone programs Spark streaming for problems
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Warehouse- Scale Computing and the BDAS Stack
 Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Twitter data Analytics using Distributed Computing
 Twitter data Analytics using Distributed Computing Uma Narayanan Athrira Unnikrishnan Dr. Varghese Paul Dr. Shelbi Joseph Research Scholar M.tech Student Professor Assistant Professor Dept. of IT, SOE
Twitter data Analytics using Distributed Computing Uma Narayanan Athrira Unnikrishnan Dr. Varghese Paul Dr. Shelbi Joseph Research Scholar M.tech Student Professor Assistant Professor Dept. of IT, SOE
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
A REVIEW: MAPREDUCE AND SPARK FOR BIG DATA ANALYTICS
 A REVIEW: MAPREDUCE AND SPARK FOR BIG DATA ANALYTICS Meenakshi Sharma 1, Vaishali Chauhan 2, Keshav Kishore 3 1,2 Students of Master of Technology, A P Goyal Shimla University, (India) 3 Head of department,
A REVIEW: MAPREDUCE AND SPARK FOR BIG DATA ANALYTICS Meenakshi Sharma 1, Vaishali Chauhan 2, Keshav Kishore 3 1,2 Students of Master of Technology, A P Goyal Shimla University, (India) 3 Head of department,
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
SCALABLE, LOW LATENCY MODEL SERVING AND MANAGEMENT WITH VELOX
 THE MISSING PIECE IN COMPLEX ANALYTICS: SCALABLE, LOW LATENCY MODEL SERVING AND MANAGEMENT WITH VELOX Daniel Crankshaw, Peter Bailis, Joseph Gonzalez, Haoyuan Li, Zhao Zhang, Ali Ghodsi, Michael Franklin,
THE MISSING PIECE IN COMPLEX ANALYTICS: SCALABLE, LOW LATENCY MODEL SERVING AND MANAGEMENT WITH VELOX Daniel Crankshaw, Peter Bailis, Joseph Gonzalez, Haoyuan Li, Zhao Zhang, Ali Ghodsi, Michael Franklin,
Coflow. Recent Advances and What s Next? Mosharaf Chowdhury. University of Michigan
 Coflow Recent Advances and What s Next? Mosharaf Chowdhury University of Michigan Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow Networking Open Source Apache Spark Open
Coflow Recent Advances and What s Next? Mosharaf Chowdhury University of Michigan Rack-Scale Computing Datacenter-Scale Computing Geo-Distributed Computing Coflow Networking Open Source Apache Spark Open
MLlib. Distributed Machine Learning on. Evan Sparks. UC Berkeley
 MLlib & ML base Distributed Machine Learning on Evan Sparks UC Berkeley January 31st, 2014 Collaborators: Ameet Talwalkar, Xiangrui Meng, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia,
MLlib & ML base Distributed Machine Learning on Evan Sparks UC Berkeley January 31st, 2014 Collaborators: Ameet Talwalkar, Xiangrui Meng, Virginia Smith, Xinghao Pan, Shivaram Venkataraman, Matei Zaharia,
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
HaLoop Efficient Iterative Data Processing on Large Clusters
 HaLoop Efficient Iterative Data Processing on Large Clusters Yingyi Bu, Bill Howe, Magdalena Balazinska, and Michael D. Ernst University of Washington Department of Computer Science & Engineering Presented
HaLoop Efficient Iterative Data Processing on Large Clusters Yingyi Bu, Bill Howe, Magdalena Balazinska, and Michael D. Ernst University of Washington Department of Computer Science & Engineering Presented
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
IMPLEMENTING A LAMBDA ARCHITECTURE TO PERFORM REAL-TIME UPDATES
 IMPLEMENTING A LAMBDA ARCHITECTURE TO PERFORM REAL-TIME UPDATES by PRAMOD KUMAR GUDIPATI B.E., OSMANIA UNIVERSITY (OU), INDIA, 2012 A REPORT submitted in partial fulfillment of the requirements of the
IMPLEMENTING A LAMBDA ARCHITECTURE TO PERFORM REAL-TIME UPDATES by PRAMOD KUMAR GUDIPATI B.E., OSMANIA UNIVERSITY (OU), INDIA, 2012 A REPORT submitted in partial fulfillment of the requirements of the
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing