Mothra: A Large-Scale Data Processing Platform for Network Security Analysis
|
|
|
- Loreen Williams
- 6 years ago
- Views:
Transcription

1 Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Tony Cebzanov Software Engineering Institute Carnegie Mellon University Pittsburgh, PA REV

2 Agenda Introduction Architecture and Design Demonstration Future Work 2

3 Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Introduction 3
4 Introduction In the beginning... there was Netflow Netflow was designed to retain the most important attributes of network conversations between TCP/IP endpoints on large networks without having to collect, store, and analyze all of the network's packet-level data For many years, this has been the most effective way to perform security analysis on large networks Over time, demand has increased for a platform that can support analytical workflows that make use of attributes beyond the transport layer Modern flow collectors can export payload attributes at wire speed The challenge is scalable storage and analysis The current generation of distributed data processing platforms provides tools to address this challenge 4
5 Introduction Project Goals The Mothra security analysis platform enables scalable analytical workflows that extend beyond the limitations of conventional flow records. With the Mothra project, we aim to: facilitate bulk storage and analysis of cybersecurity data with high levels of flexibility, performance, and interoperability reduce the engineering effort involved in developing, transitioning, and operationalizing new analytics serve all major constituencies within the network security community, including data scientists, first-tier incident responders, system administrators, and hobbyists 5
6 Introduction SiLK: The Next Generation? Mothra is not the next version of SiLK SiLK s design philosophy was inspired by UNIX Command-line tools that each focus on doing one thing well Tools are composable into analytics via shell scripting Fixed-length record formats for optimal performance With larger, variable-length records, this design can t scale Solution? Throw more hardware at the problem ( big data ) We view SiLK and Mothra as complementary projects that will be developed in parallel for the foreseeable future SiLK still performs well for queries that don t look beyond layer 4 Mothra enables more complex analyses at a scale beyond the capability of SiLK s single-node architecture 6
7 Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Architecture and Design 7
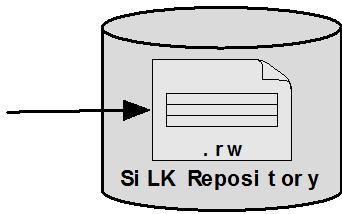

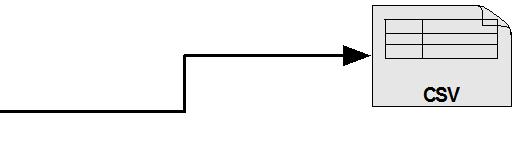
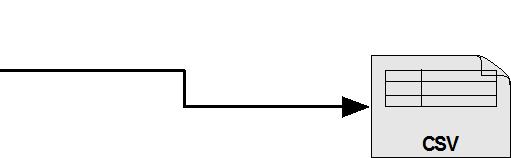


8 Architecture and Design YAF to SiLK Data Flow 8
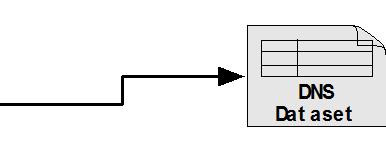
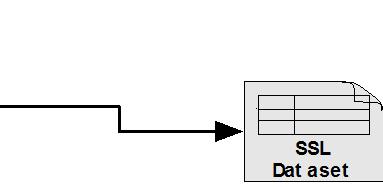
9 Architecture and Design YAF to Mothra Data Flow 9
10 Architecture and Design SiLK vs. Mothra Mothra departs from SiLK s UNIX-like design in significant ways: SiLK Command-line tools, mostly written in C, with some Python Analytics are written as UNIX shell scripts Mothra Built on Apache Spark, a cluster computing framework Written primary in Scala, which runs on the Java Virtual Machine Language bindings for Java, Python, R, and SQL Runs standalone or on an existing cluster platform (e.g. Hadoop) Mothra s core libraries are written in Scala and Java Analytics can be written using any language Spark supports A web notebook interface is provided for developing analytics 10


11 Architecture and Design Platform Languages and Technologies (continued) 11
12 Architecture and Design Why Spark? Building Mothra on an established platform like Spark, with its active industry-sponsored open source development community, allows us to focus on components that deliver value to analysts. The Spark platform: enables a degree of scalability not possible with SiLK supports higher-level languages for faster development and transition of core functionality and analytics provides consistent interfaces to a variety of data sources includes libraries for graph analysis and machine learning integrates well with other big data platforms and technologies 12
13 Architecture and Design Mothra Architecture 13

14 Architecture and Design SiLK vs. Mothra Scalability 14
15 Architecture and Design User Interfaces Mothra uses Jupyter Notebook as an exploratory analysis UI: Rich web-based interface Input cells for developing and executing code Output cells display analysis results, including visualizations Markdown for annotations with rich text Simple sharing and publishing of analytics and results Less daunting for novices to learn than the UNIX command-line For CLI fans, jupyter-console and spark-shell are available 15

16 Architecture and Design Jupyter Notebook 16
17 Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Demonstration 17
18 Demonstration Field Specifier Syntax IPFIX fields are specified using strings of the following format: [path][/][operator]name[:format][=alias] where: path (optional) is a path to the desired information element paths are made up of template names, delimited by / characters if path is empty, the field specifier will look for the given element in all top-level IPFIX records operator (optional) is a character indicating how the information element should be treated currently, the only operator indicating that the IE is a basiclist field name (required) is the name of the IPFIX informtaion element format (optional) is a string indicating how the field should be formatted in the data frame current formats are: - str format IE as a string - iso8601 format IE as an ISO-8601 date string - base64 format IE as as base64-encoded string alias (optional) is a string to be used for the data frame column name instead of the IPFIX IE name if alias is unspecified, the column name will default to the IPFIX IE name 18
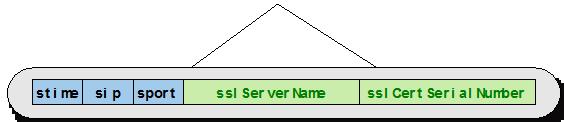
19 Demonstration Field Spec Examples flowstartmilliseconds the flow start time in milliseconds at the top level of any IPFIX record flowstartmilliseconds:iso8601 same, but formatted as an ISO-8601 string flow_total_ip6/flowstartmilliseconds:iso8601 same, but only if the top-level record matches the IPv6 template flow_total_ip6/flowstartmilliseconds:iso8601=stime same, but rename the field to stime the HTTP user agent list within the http template a list of SSL certificates in the flow, each base64-encoded 19
20 Demonstration Spark DataFrames From the Spark documentation: "A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. To build a DataFrame in Mothra with the Scala language interface: To count the number of records: 20
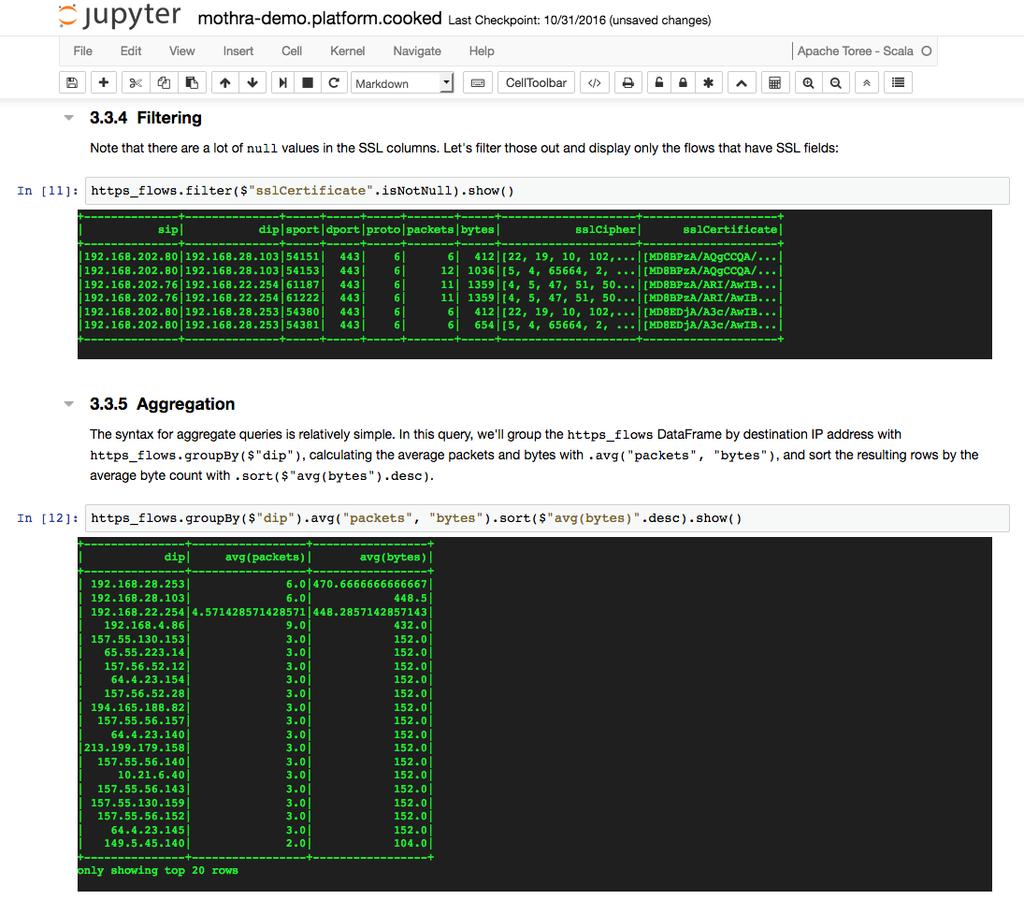
21 Demonstration Queries Spark DataFrame API maps reasonably well to rw* commands: Filtering (rwfilter) Syntax is similar with the Python API: 21
")
22 Demonstration Queries Column selection & display (rwcut) 22
 Sorting:")
23 Demonstration Queries (continued) Sorting: Aggregation: 23
 Full SQL")
24 Demonstration Queries (continued) Full SQL syntax 24

25 Demonstration Queries (continued) Compound query example Build dataframe of SSL flows with a known bad SSL cert Build dataframe of DNS flows with non-null qname Join two dataframes on the sip field Select the sip, sslcertificate, and dnsqname fields 25
26 Mothra: A Large-Scale Data Processing Platform for Network Security Analysis Future Work 26
27 Future Work Future Work On the horizon: Streaming ingest from sensors Operational analyst console integration Simplified deployment and configuration Open source release Integration of useful components into other FOSS projects 27
28 Future Work Related Projects Apache Metron (incubating) Sponsored by Hortonworks, Rackspace, Cisco, and others Apache Spot (incubating): Sponsored by Cloudera, Intel, EBay, and others Similar in scope and scale, different in emphasis and design As these projects mature and grow in popularity, we may pursue integration opportunities 28

29 Questions? CERT NetSA Tools Home Contact Mailing list 29
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
R: A Proposed Analysis and Visualization Environment for Network Security Data
 R: A Proposed Analysis and Visualization Environment for Network Security Data Josh McNutt 2005 Carnegie Mellon University Outline SiLK Tools Analyst s Desktop Introduction to R R-SiLK
R: A Proposed Analysis and Visualization Environment for Network Security Data Josh McNutt 2005 Carnegie Mellon University Outline SiLK Tools Analyst s Desktop Introduction to R R-SiLK
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Apache Hadoop 3. Balazs Gaspar Sales Engineer CEE & CIS Cloudera, Inc. All rights reserved.
 Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Apache Hadoop 3 Balazs Gaspar Sales Engineer CEE & CIS balazs@cloudera.com 1 We believe data can make what is impossible today, possible tomorrow 2 We empower people to transform complex data into clear
Cisco Stealthwatch Endpoint License with Cisco AnyConnect NVM
 Cisco Stealthwatch Endpoint License with Cisco AnyConnect NVM How to implement the Cisco Stealthwatch Endpoint License with the Cisco AnyConnect Network Visibility Module Table of Contents About This Document...
Cisco Stealthwatch Endpoint License with Cisco AnyConnect NVM How to implement the Cisco Stealthwatch Endpoint License with the Cisco AnyConnect Network Visibility Module Table of Contents About This Document...
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Fun with Flow. Richard Friedberg rf [at] cert.org Carnegie Mellon University
![Fun with Flow. Richard Friedberg rf [at] cert.org Carnegie Mellon University](/thumbs/80/81762596.jpg "Fun with Flow. Richard Friedberg rf [at] cert.org Carnegie Mellon University") Fun with Flow Richard Friedberg rf [at] cert.org Objectives Flow Primer Why do I care? Tools Capabilities and examples Almost live demo Build it! Where to go for more 2 What is flow? The simple version:
Fun with Flow Richard Friedberg rf [at] cert.org Objectives Flow Primer Why do I care? Tools Capabilities and examples Almost live demo Build it! Where to go for more 2 What is flow? The simple version:
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Implementing Coarse, Long- Term Traffic Capture
 Implementing Coarse, Long- Term Traffic Capture Michael Collins, CERT/Network Situational Awareness 2005 Carnegie Mellon University Outline of Talk Introduction To Work Logistics of Traffic Analysis Implementing
Implementing Coarse, Long- Term Traffic Capture Michael Collins, CERT/Network Situational Awareness 2005 Carnegie Mellon University Outline of Talk Introduction To Work Logistics of Traffic Analysis Implementing
CloudExpo November 2017 Tomer Levi
 CloudExpo November 2017 Tomer Levi About me Full Stack Engineer @ Intel s Advanced Analytics group. Artificial Intelligence unit at Intel. Responsible for (1) Radical improvement of critical processes
CloudExpo November 2017 Tomer Levi About me Full Stack Engineer @ Intel s Advanced Analytics group. Artificial Intelligence unit at Intel. Responsible for (1) Radical improvement of critical processes
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
SQL Server Machine Learning Marek Chmel & Vladimir Muzny
 SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
SQL Server Machine Learning Marek Chmel & Vladimir Muzny @VladimirMuzny & @MarekChmel MCTs, MVPs, MCSEs Data Enthusiasts! vladimir@datascienceteam.cz marek@datascienceteam.cz Session Agenda Machine learning
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Application monitoring with BELK. Nishant Sahay, Sr. Architect Bhavani Ananth, Architect
 Application monitoring with BELK Nishant Sahay, Sr. Architect Bhavani Ananth, Architect Why logs Business PoV Input Data Analytics User Interactions /Behavior End user Experience/ Improvements 2017 Wipro
Application monitoring with BELK Nishant Sahay, Sr. Architect Bhavani Ananth, Architect Why logs Business PoV Input Data Analytics User Interactions /Behavior End user Experience/ Improvements 2017 Wipro
From NetFlow to IPFIX the evolution of IP flow information export
 From NetFlow to IPFIX the evolution of IP flow information export Brian Trammell - CERT/NetSA - Pittsburgh, PA, US Elisa Boschi - Hitachi Europe - Zurich, CH NANOG 41 - Albuquerque, NM, US - October 15,
From NetFlow to IPFIX the evolution of IP flow information export Brian Trammell - CERT/NetSA - Pittsburgh, PA, US Elisa Boschi - Hitachi Europe - Zurich, CH NANOG 41 - Albuquerque, NM, US - October 15,
Oracle Big Data SQL. Release 3.2. Rich SQL Processing on All Data
 Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
New Data Architectures For Netflow Analytics NANOG 74. Fangjin Yang - Imply
 New Data Architectures For Netflow Analytics NANOG 74 Fangjin Yang - Cofounder @ Imply The Problem Comparing technologies Overview Operational analytic databases Try this at home The Problem Netflow data
New Data Architectures For Netflow Analytics NANOG 74 Fangjin Yang - Cofounder @ Imply The Problem Comparing technologies Overview Operational analytic databases Try this at home The Problem Netflow data
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
PNDA.io: when BGP meets Big-Data
 PNDA.io: when BGP meets Big-Data Let s go back in time 26 th April 2017 The Internet is very much alive Millions of BGP events occurring every day 15 Routers Monitored 410 active peers (both IPv4 and IPv6)
PNDA.io: when BGP meets Big-Data Let s go back in time 26 th April 2017 The Internet is very much alive Millions of BGP events occurring every day 15 Routers Monitored 410 active peers (both IPv4 and IPv6)
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Time Series Storage with Apache Kudu (incubating)
") Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Time Series Analytics with Simple Relational Database Paradigms Ben Leighton, Julia Anticev, Alex Khassapov
 Time Series Analytics with Simple Relational Database Paradigms Ben Leighton, Julia Anticev, Alex Khassapov LAND AND WATER & CSIRO IMT SCIENTIFIC COMPUTING Energy Use Data Model (EUDM) endeavours to deliver
Time Series Analytics with Simple Relational Database Paradigms Ben Leighton, Julia Anticev, Alex Khassapov LAND AND WATER & CSIRO IMT SCIENTIFIC COMPUTING Energy Use Data Model (EUDM) endeavours to deliver
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Faster ETL Workflows using Apache Pig & Spark. - Praveen Rachabattuni,
 Faster ETL Workflows using Apache Pig & Spark - Praveen Rachabattuni, Sigmoid @praveenr019 About me Apache Pig committer and Pig on Spark project lead. OUR CUSTOMERS Why pig on spark? Spark shell (scala),
Faster ETL Workflows using Apache Pig & Spark - Praveen Rachabattuni, Sigmoid @praveenr019 About me Apache Pig committer and Pig on Spark project lead. OUR CUSTOMERS Why pig on spark? Spark shell (scala),
Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data
 Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data THE RISE OF BIG DATA BIG DATA: A REVOLUTION IN ACCESS Large-scale data sets are nothing
Spotfire Data Science with Hadoop Using Spotfire Data Science to Operationalize Data Science in the Age of Big Data THE RISE OF BIG DATA BIG DATA: A REVOLUTION IN ACCESS Large-scale data sets are nothing
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
SFO15-TR6: Hadoop on ARM
 SFO15-TR6: Hadoop on ARM Presented by Nachiket Bhoyar Steve Capper Date Wednesday 23 September 2015 Nachiket Bhoyar Steve Capper Event SFO15 Agenda 1. Quick intro to Hadoop stack. 2. Summary of our work.
SFO15-TR6: Hadoop on ARM Presented by Nachiket Bhoyar Steve Capper Date Wednesday 23 September 2015 Nachiket Bhoyar Steve Capper Event SFO15 Agenda 1. Quick intro to Hadoop stack. 2. Summary of our work.
Novetta Cyber Analytics
 Know your network. Arm your analysts. Introduction Novetta Cyber Analytics is an advanced network traffic analytics solution that empowers analysts with comprehensive, near real time cyber security visibility
Know your network. Arm your analysts. Introduction Novetta Cyber Analytics is an advanced network traffic analytics solution that empowers analysts with comprehensive, near real time cyber security visibility
Cost Effective, Scalable Packet Capture and Cyber Analytics Cluster for Low Bandwidth Enterprise Customers
 Cost Effective, Scalable Packet Capture and Cyber Analytics Cluster for Low Bandwidth Enterprise Customers The Enterprise Lite Packet Capture Cluster Platform is a complete solution based on NextComputing
Cost Effective, Scalable Packet Capture and Cyber Analytics Cluster for Low Bandwidth Enterprise Customers The Enterprise Lite Packet Capture Cluster Platform is a complete solution based on NextComputing
1 Big Data Hadoop. 1. Introduction About this Course About Big Data Course Logistics Introductions
 Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
or You don t have to work here to be paranoid, but it helps.
 Network Awareness and Network Security or You don t have to work here to be paranoid, but it helps. TRUST Seminar, Berkeley, 3 May 2007 John M c Hugh Canada Research Chair in Privacy and Security Director,
Network Awareness and Network Security or You don t have to work here to be paranoid, but it helps. TRUST Seminar, Berkeley, 3 May 2007 John M c Hugh Canada Research Chair in Privacy and Security Director,
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Using Apache Phoenix to store and access data
 3 Using Apache Phoenix to store and access data Date of Publish: 2018-07-15 http://docs.hortonworks.com Contents ii Contents What's New in Apache Phoenix...4 Orchestrating SQL and APIs with Apache Phoenix...4
3 Using Apache Phoenix to store and access data Date of Publish: 2018-07-15 http://docs.hortonworks.com Contents ii Contents What's New in Apache Phoenix...4 Orchestrating SQL and APIs with Apache Phoenix...4
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Resource Allocation Resource Usage Data Access Control. Network Intelligence, Guidance. Statistics, States, Objects and Events.
 Resource Allocation Resource Usage Data Access Control POLICY ENGINE Network Intelligence, Guidance APPLICATIONS & PaaS ANALYTICS Workflow SERVICE ORCHESTRATION AND CONTROL NETWORK Statistics, States,
Resource Allocation Resource Usage Data Access Control POLICY ENGINE Network Intelligence, Guidance APPLICATIONS & PaaS ANALYTICS Workflow SERVICE ORCHESTRATION AND CONTROL NETWORK Statistics, States,
Oracle NoSQL Database Enterprise Edition, Version 18.1
 Oracle NoSQL Database Enterprise Edition, Version 18.1 Oracle NoSQL Database is a scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management across
Oracle NoSQL Database Enterprise Edition, Version 18.1 Oracle NoSQL Database is a scalable, distributed NoSQL database, designed to provide highly reliable, flexible and available data management across
ForeScout CounterACT. Configuration Guide. Version 3.4
 ForeScout CounterACT Open Integration Module: Data Exchange Version 3.4 Table of Contents About the Data Exchange Module... 4 About Support for Dual Stack Environments... 4 Requirements... 4 CounterACT
ForeScout CounterACT Open Integration Module: Data Exchange Version 3.4 Table of Contents About the Data Exchange Module... 4 About Support for Dual Stack Environments... 4 Requirements... 4 CounterACT
SCRIPT: An Architecture for IPFIX Data Distribution
 SCRIPT Public Workshop January 20, 2010, Zurich, Switzerland SCRIPT: An Architecture for IPFIX Data Distribution Peter Racz Communication Systems Group CSG Department of Informatics IFI University of Zürich
SCRIPT Public Workshop January 20, 2010, Zurich, Switzerland SCRIPT: An Architecture for IPFIX Data Distribution Peter Racz Communication Systems Group CSG Department of Informatics IFI University of Zürich
Hortonworks Cybersecurity Platform
 1 Hortonworks Cybersecurity Platform Date of Publish: 2018-07-30 http://docs.hortonworks.com Contents Introduction to Metron Dashboard... 3 Functionality of Metron Dashboard... 3 Metron Default Dashboard...
1 Hortonworks Cybersecurity Platform Date of Publish: 2018-07-30 http://docs.hortonworks.com Contents Introduction to Metron Dashboard... 3 Functionality of Metron Dashboard... 3 Metron Default Dashboard...
Big Data Applications with Spring XD
 Big Data Applications with Spring XD Thomas Darimont, Software Engineer, Pivotal Inc. @thomasdarimont Unless otherwise indicated, these slides are 2013-2015 Pivotal Software, Inc. and licensed under a
Big Data Applications with Spring XD Thomas Darimont, Software Engineer, Pivotal Inc. @thomasdarimont Unless otherwise indicated, these slides are 2013-2015 Pivotal Software, Inc. and licensed under a
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Migrate from Netezza Workload Migration
 Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science
 Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Best Practice Deployment of F5 App Services in Private Clouds. Henry Tam, Senior Product Marketing Manager John Gruber, Sr. PM Solutions Architect
 Best Practice Deployment of F5 App Services in Private Clouds Henry Tam, Senior Product Marketing Manager John Gruber, Sr. PM Solutions Architect Agenda 1 2 3 4 5 The trend of data center, private cloud
Best Practice Deployment of F5 App Services in Private Clouds Henry Tam, Senior Product Marketing Manager John Gruber, Sr. PM Solutions Architect Agenda 1 2 3 4 5 The trend of data center, private cloud
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation. Chris Herrera Hashmap
 Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Putting A Spark in Web Apps
 Putting A Spark in Web Apps Apache Big Data, Seville ES, 2016 David Fallside Intro Web app development has moved from Java etc to Node.js and JavaScript JS environment relatively simple and very rich,
Putting A Spark in Web Apps Apache Big Data, Seville ES, 2016 David Fallside Intro Web app development has moved from Java etc to Node.js and JavaScript JS environment relatively simple and very rich,
Oracle Big Data Discovery
 Oracle Big Data Discovery Turning Data into Business Value Harald Erb Oracle Business Analytics & Big Data 1 Safe Harbor Statement The following is intended to outline our general product direction. It
Oracle Big Data Discovery Turning Data into Business Value Harald Erb Oracle Business Analytics & Big Data 1 Safe Harbor Statement The following is intended to outline our general product direction. It
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Deep Learning Frameworks with Spark and GPUs
 Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Deep Learning Frameworks with Spark and GPUs Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel,
Hortonworks Data Platform
 Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Hortonworks Data Platform Workflow Management (August 31, 2017) docs.hortonworks.com Hortonworks Data Platform: Workflow Management Copyright 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks
Python, PySpark and Riak TS. Stephen Etheridge Lead Solution Architect, EMEA
 Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
Python, PySpark and Riak TS Stephen Etheridge Lead Solution Architect, EMEA Agenda Introduction to Riak TS The Riak Python client The Riak Spark connector and PySpark CONFIDENTIAL Basho Technologies 3
TRex Realistic Traffic Generator
 DEVNET-1120 TRex Realistic Traffic Generator Hanoch Haim, Principal Engineer Cisco Spark How Questions? Use Cisco Spark to communicate with the speaker after the session 1. Find this session in the Cisco
DEVNET-1120 TRex Realistic Traffic Generator Hanoch Haim, Principal Engineer Cisco Spark How Questions? Use Cisco Spark to communicate with the speaker after the session 1. Find this session in the Cisco
Netflow in Daily Information Security Operations
 Netflow in Daily Information Security Operations Mike Pochan Software Engineering Institute Carnegie Mellon University Pittsburgh, PA 15213 Copyright 2016 Carnegie Mellon University This material is based
Netflow in Daily Information Security Operations Mike Pochan Software Engineering Institute Carnegie Mellon University Pittsburgh, PA 15213 Copyright 2016 Carnegie Mellon University This material is based
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch
 Nick Pentreath Nov / 14 / 16 Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch About @MLnick Principal Engineer, IBM Apache Spark PMC Focused on machine learning
Nick Pentreath Nov / 14 / 16 Building a Scalable Recommender System with Apache Spark, Apache Kafka and Elasticsearch About @MLnick Principal Engineer, IBM Apache Spark PMC Focused on machine learning
Structured Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
IoT with Apache ActiveMQ, Camel and Spark
 IoT with Apache ActiveMQ, Camel and Spark Burr Sutter - Red Hat Agenda Business & IT Architecture IoT Architecture IETF IoT Use Case Ingestion: Apache ActiveMQ, Apache Camel Analytics: Apache Spark Demos
IoT with Apache ActiveMQ, Camel and Spark Burr Sutter - Red Hat Agenda Business & IT Architecture IoT Architecture IETF IoT Use Case Ingestion: Apache ActiveMQ, Apache Camel Analytics: Apache Spark Demos
Part2: Let s pick one cloud IaaS middleware: OpenStack. Sergio Maffioletti
 S3IT: Service and Support for Science IT Cloud middleware Part2: Let s pick one cloud IaaS middleware: OpenStack Sergio Maffioletti S3IT: Service and Support for Science IT, University of Zurich http://www.s3it.uzh.ch/
S3IT: Service and Support for Science IT Cloud middleware Part2: Let s pick one cloud IaaS middleware: OpenStack Sergio Maffioletti S3IT: Service and Support for Science IT, University of Zurich http://www.s3it.uzh.ch/
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
SAP Vora - AWS Marketplace Production Edition Reference Guide
 SAP Vora - AWS Marketplace Production Edition Reference Guide 1. Introduction 2 1.1. SAP Vora 2 1.2. SAP Vora Production Edition in Amazon Web Services 2 1.2.1. Vora Cluster Composition 3 1.2.2. Ambari
SAP Vora - AWS Marketplace Production Edition Reference Guide 1. Introduction 2 1.1. SAP Vora 2 1.2. SAP Vora Production Edition in Amazon Web Services 2 1.2.1. Vora Cluster Composition 3 1.2.2. Ambari
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Cisco Wide Area Bonjour Solution Overview
 , page 1 Topology Overview, page 2 About the Cisco Application Policy Infrastructure Controller Enterprise Module (APIC-EM), page 5 The Cisco Wide Area Bonjour solution is based on a distributed and hierarchical
, page 1 Topology Overview, page 2 About the Cisco Application Policy Infrastructure Controller Enterprise Module (APIC-EM), page 5 The Cisco Wide Area Bonjour solution is based on a distributed and hierarchical
Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016
 Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016 Hans Viehmann Product Manager EMEA ORACLE Corporation 12. Mai 2016 Safe Harbor Statement The following
Verarbeitung von Vektor- und Rasterdaten auf der Hadoop Plattform DOAG Spatial and Geodata Day 2016 Hans Viehmann Product Manager EMEA ORACLE Corporation 12. Mai 2016 Safe Harbor Statement The following
EZY Intellect Pte. Ltd., #1 Changi North Street 1, Singapore
 Tableau in Business Intelligence Duration: 6 Days Tableau Desktop Tableau Introduction Tableau Introduction. Overview of Tableau workbook, worksheets. Dimension & Measures Discrete and Continuous Install
Tableau in Business Intelligence Duration: 6 Days Tableau Desktop Tableau Introduction Tableau Introduction. Overview of Tableau workbook, worksheets. Dimension & Measures Discrete and Continuous Install
Consuming Model-Driven Telemetry
 Consuming Model-Driven Telemetry Cristina Precup & Stefan Braicu Software Systems Engineers Cisco Spark How Questions? Use Cisco Spark to communicate with the speaker after the session 1. Find this session
Consuming Model-Driven Telemetry Cristina Precup & Stefan Braicu Software Systems Engineers Cisco Spark How Questions? Use Cisco Spark to communicate with the speaker after the session 1. Find this session
The Portal Aspect of the LSST Science Platform. Gregory Dubois-Felsmann Caltech/IPAC. LSST2017 August 16, 2017
 The Portal Aspect of the LSST Science Platform Gregory Dubois-Felsmann Caltech/IPAC LSST2017 August 16, 2017 1 Purpose of the LSST Science Platform (LSP) Enable access to the LSST data products Enable
The Portal Aspect of the LSST Science Platform Gregory Dubois-Felsmann Caltech/IPAC LSST2017 August 16, 2017 1 Purpose of the LSST Science Platform (LSP) Enable access to the LSST data products Enable
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores