Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
|
|
|
- Jesse Harrison
- 5 years ago
- Views:
Transcription

1 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark



2 About me Vitalii Bondarenko Data Platform Competency Manager Eleks 20 years in software development 9+ years of developing for MS SQL Server 3+ years of architecting Big Data Solutions

3 Spark Stack Clustered computing platform Designed to be fast and general purpose Integrated with distributed systems API for Python, Scala, Java, clear and understandable code Integrated with Big Data and BI Tools Integrated with different Data Bases, systems and libraries like Cassanda, Kafka, H2O First Apache release 2013, Aug 2016 v.2.0 has been released


4 Map-reduce computations
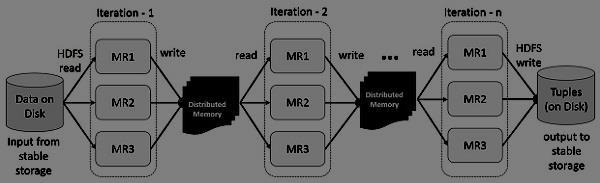

5 In-memory map-reduce

6 Execution Model Spark Execution Shells and Standalone application Local and Cluster (Standalone, Yarn, Mesos, Cloud) Spark Cluster Architecture Master / Cluster manager Cluster allocates resources on nodes Master sends app code and tasks tor nodes Executers run tasks and cache data
 Transformations are lazy Actions trigger transformations computation from pyspart import SparkContext as sc Broadcast Variables send data to executors inputrdd =")
7 RDD: resilient distributed dataset Parallelized collections with fault-tolerant (Hadoop datasets) Transformations set new RDDs (filter, map, distinct, union, subtract, etc) Actions call to calculations (count, collect, first) Transformations are lazy Actions trigger transformations computation from pyspart import SparkContext as sc Broadcast Variables send data to executors inputrdd = sc.textfile("log.txt") Accumulators collect data on driver errorsrdd = inputrdd.filter(lambda x: "error" in x) warningsrdd = inputrdd.filter(lambda x: "warning" in x) badlinesrdd = errorsrdd.union(warningsrdd) print "Input had " + badlinesrdd.count() + " concerning lines"
 Transform Persist intermediate RDDs as results Launch")
8 Spark program scenario Create RDD (loading external datasets, parallelizing a collection on driver) Transform Persist intermediate RDDs as results Launch actions

9 Transformations (1)
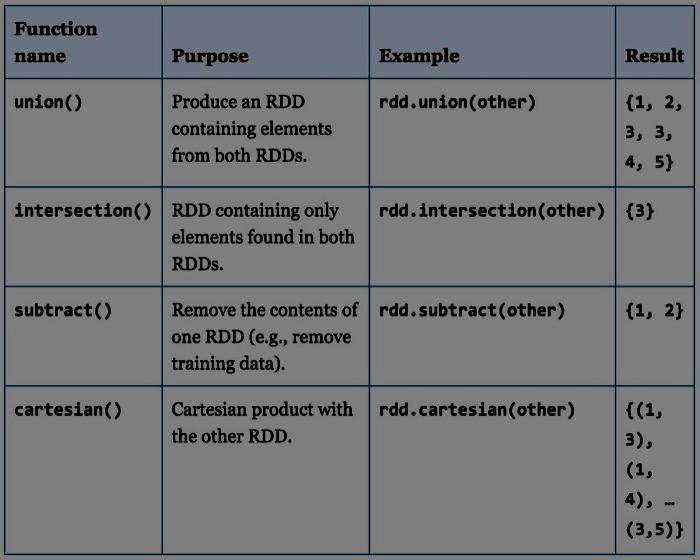
10 Transformations (2)
")
11 Actions (1)
")
12 Actions (2)




13 Spark Streaming Architecture Micro-batch architecture SparkStreaming Concext Batch interval from 500ms Transformation on Spark Engine Outup operations instead of Actions Different sources and outputs
14 Spark Streaming Example from pyspark.streaming import StreamingContext ssc = StreamingContext(sc, 1) input_stream = ssc.textfilestream("sampletextdir") word_pairs = input_stream.flatmap( lambda l:l.split(" ")).map(lambda w: (w,1)) counts = word_pairs.reducebykey(lambda x,y: x + y) counts.print() ssc.start() ssc.awaittermination() Process RDDs in batches Start after ssc.start() Output to console on Driver Awaiting termination
 with defined schema JDBC/ODBC connectors for BI tools Integrated with Hive and Hive types, uses HiveUDF DataFrame")
15 Spark SQL SparkSQL interface for working with structured data by SQL Works with Hive tables and HiveQL Works with files (Json, Parquet etc) with defined schema JDBC/ODBC connectors for BI tools Integrated with Hive and Hive types, uses HiveUDF DataFrame abstraction
16 Spark DataFrames # Import Spark SQLfrom pyspark.sql import HiveContext, Row # Or if you can't include the hive requirementsfrom pyspark.sql import SQLContext, Row sc = new SparkContext(...) hivectx = HiveContext(sc) sqlcontext = SQLContext(sc) input = hivectx.jsonfile(inputfile) # Register the input schema RDD input.registertemptable("tweets") # Select tweets based on the retweet CounttopTweets = hivectx.sql("""select text, retweetcount FROM tweets ORDER BY retweetcount LIMIT 10""") hivectx.cachetable("tablename"), in-memory, column-store, while driver is alive df.show() df.select( name, df( age )+1) df.filtr(df( age ) > 19)


17 Spark ML Spark ML Classification Regression Clustering Recommendation Feature transformation, selection Statistics Linear algebra Data mining tools Pipeline Cmponents
18 DEMO: Spark Local Spark installation Shells and Notebook Spark Examples HDInsight Spark Cluster SSH connection to Spark in Azure Jupyter Notebook connected to HDInsight Spark Transformations ActionsSimple SparkSQL querying Data Frames Data exploration with SparkSQL Connect from BI

19 Eleks Enterprice Platform
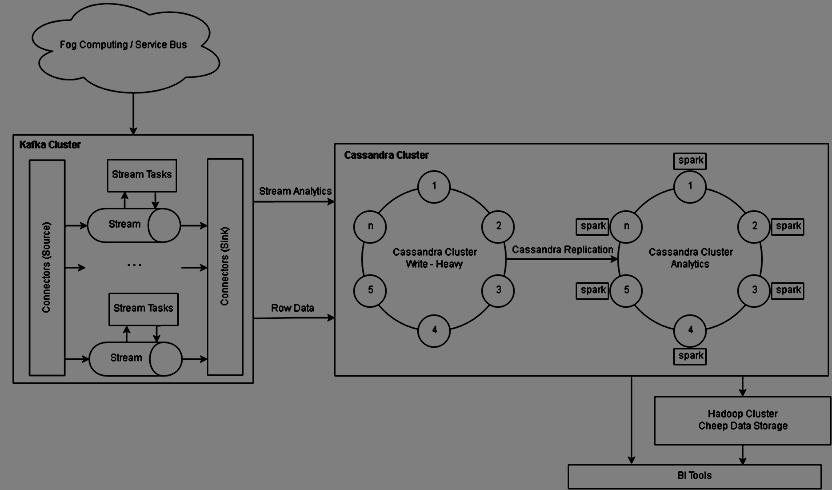
20 Fast Data Processing

21 BI / DS Platform
22 Using Spark 1.Visual data exploration and interactive analysis (HDFS) 2.Spark with NoSQL (HBase and Cassandra) 3.Spark with Data Lake 4.Spark with Data Warehouse 5.Machine Learning using R Server, Mllib 6.Putting it all together in a notebook experience 7.Using BI with Spark 8.Spark Environmens On-Premis, Cloudera, Hortonworks, DataBricks HDInsight, AWS, DataBriks Cloud
23 Q&A
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Olivia Klose Technical Evangelist. Sascha Dittmann Cloud Solution Architect
 Olivia Klose Technical Evangelist Sascha Dittmann Cloud Solution Architect What is Apache Spark? Apache Spark is a fast and general engine for large-scale data processing. An unified, open source, parallel,
Olivia Klose Technical Evangelist Sascha Dittmann Cloud Solution Architect What is Apache Spark? Apache Spark is a fast and general engine for large-scale data processing. An unified, open source, parallel,
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Data Architectures in Azure for Analytics & Big Data
 Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Spark Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Spark Streaming Big Data Analysis with Scala and Spark Heather Miller Where Spark Streaming fits in (1) Spark is focused on batching Processing large, already-collected batches of data. For example: Where
Spark Streaming Big Data Analysis with Scala and Spark Heather Miller Where Spark Streaming fits in (1) Spark is focused on batching Processing large, already-collected batches of data. For example: Where
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
빅데이터기술개요 2016/8/20 ~ 9/3. 윤형기
 빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect
 Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Intro to Big Data on AWS Igor Roiter Big Data Cloud Solution Architect Igor Roiter Big Data Cloud Solution Architect Working as a Data Specialist for the last 11 years 9 of them as a Consultant specializing
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 HOTSPOT You install the Microsoft Hive ODBC Driver on a computer that runs Windows
Evolution of the Logging Service Hands-on Hadoop Proof of Concept for CALS-2.0
 Evolution of the Logging Service Hands-on Hadoop Proof of Concept for CALS-2.0 Chris Roderick Marcin Sobieszek Piotr Sowinski Nikolay Tsvetkov Jakub Wozniak Courtesy IT-DB Agenda Intro to CALS System Hadoop
Evolution of the Logging Service Hands-on Hadoop Proof of Concept for CALS-2.0 Chris Roderick Marcin Sobieszek Piotr Sowinski Nikolay Tsvetkov Jakub Wozniak Courtesy IT-DB Agenda Intro to CALS System Hadoop
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS
 WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
732A54 Big Data Analytics: SparkSQL. Version: Dec 8, 2016
 732A54 Big Data Analytics: SparkSQL Version: Dec 8, 2016 2016-12-08 2 DataFrames A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in
732A54 Big Data Analytics: SparkSQL Version: Dec 8, 2016 2016-12-08 2 DataFrames A DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team
 TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Microsoft Perform Data Engineering on Microsoft Azure HDInsight.
 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight http://killexams.com/pass4sure/exam-detail/70-775 QUESTION: 30 You are building a security tracking solution in Apache Kafka to parse
Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight http://killexams.com/pass4sure/exam-detail/70-775 QUESTION: 30 You are building a security tracking solution in Apache Kafka to parse
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Franck Mercier. Technical Solution Professional Data + AI Azure Databricks
 Franck Mercier Technical Solution Professional Data + AI http://aka.ms/franck @FranmerMS Azure Databricks Thanks to our sponsors Global Gold Silver Bronze Microsoft JetBrains Rubrik Delphix Solution OMD
Franck Mercier Technical Solution Professional Data + AI http://aka.ms/franck @FranmerMS Azure Databricks Thanks to our sponsors Global Gold Silver Bronze Microsoft JetBrains Rubrik Delphix Solution OMD
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
/ Cloud Computing. Recitation 13 April 17th 2018
 15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Khadija Souissi. Auf z Systems November IBM z Systems Mainframe Event 2016
 Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Elastify Cloud-Native Spark Application with PMEM. Junping Du --- Chief Architect, Tencent Cloud Big Data Department Yue Li --- Cofounder, MemVerge
 Elastify Cloud-Native Spark Application with PMEM Junping Du --- Chief Architect, Tencent Cloud Big Data Department Yue Li --- Cofounder, MemVerge Table of Contents Sparkling: The Tencent Cloud Data Warehouse
Elastify Cloud-Native Spark Application with PMEM Junping Du --- Chief Architect, Tencent Cloud Big Data Department Yue Li --- Cofounder, MemVerge Table of Contents Sparkling: The Tencent Cloud Data Warehouse
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/85/91873103.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Frequently asked questions from the previous class survey 48-bit bookending in Bzip2: does the number have to be special? Spark seems to have too many
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Frequently asked questions from the previous class survey 48-bit bookending in Bzip2: does the number have to be special? Spark seems to have too many
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Apache Spark Streaming with Twitter (and Python) LinkedIn
 LinkedIn") From left to right:, Russell Hanson, Sascha Ishikawa, Asa Wilks, James Liu, Angel Martinez, & Scot Hickey. Photo copyright (c) 2017 by L. Weichberger Apache Spark Streaming with Twitter (and Python) Published
From left to right:, Russell Hanson, Sascha Ishikawa, Asa Wilks, James Liu, Angel Martinez, & Scot Hickey. Photo copyright (c) 2017 by L. Weichberger Apache Spark Streaming with Twitter (and Python) Published
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Intro to Spark and Spark SQL. AMP Camp 2014 Michael Armbrust
 Intro to Spark and Spark SQL AMP Camp 2014 Michael Armbrust - @michaelarmbrust What is Apache Spark? Fast and general cluster computing system, interoperable with Hadoop, included in all major distros
Intro to Spark and Spark SQL AMP Camp 2014 Michael Armbrust - @michaelarmbrust What is Apache Spark? Fast and general cluster computing system, interoperable with Hadoop, included in all major distros
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
In-Memory Processing with Apache Spark. Vincent Leroy
 In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
The age of Big Data Big Data for Oracle Database Professionals
 The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
The age of Big Data Big Data for Oracle Database Professionals Oracle OpenWorld 2017 #OOW17 SessionID: SUN5698 Tom S. Reddy tom.reddy@datareddy.com About the Speaker COLLABORATE & OpenWorld Speaker IOUG
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma
 Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
Summary of Big Data Frameworks Course 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Course Schedule Tuesday 10.3. Introduction and the Big Data Challenge Tuesday 17.3. MapReduce and Spark: Overview Tuesday
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Apache Bahir Writing Applications using Apache Bahir
 Apache Big Data Seville 2016 Apache Bahir Writing Applications using Apache Bahir Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing
Apache Big Data Seville 2016 Apache Bahir Writing Applications using Apache Bahir Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM
 Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail
Kafka pours and Spark resolves! Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With Spark since 2014 With EPAM since 2015 About Contacts E-mail