How to Write Fast Numerical Code
|
|
|
- Abel Holt
- 5 years ago
- Views:
Transcription
1 How to Write Fast Numerical Code Lecture: Autotuning and Machine Learning Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Overview Rough classification of autotuning efforts seen in course Use of machine learning I Use of machine learning II 2
2 search used no search used implementation installation platform known use problem parameters known PhiPac/ATLAS: MMM Generator Whaley, Bilmes, Demmel, Dongarra, c = a Blocking improves locality * b c = (double *) calloc(sizeof(double), n*n); /* Multiply n x n matrices a and b */ void mmm(double *a, double *b, double *c, int n) { int i, j, k; for (i = 0; i < n; i+=b) for (j = 0; j < n; j+=b) for (k = 0; k < n; k+=b) /* B x B mini matrix multiplications */ for (i1 = i; i1 < i+b; i++) for (j1 = j; j1 < j+b; j++) for (k1 = k; k1 < k+b; k++) c[i1*n+j1] += a[i1*n + k1]*b[k1*n + j1]; }
3 PhiPac/ATLAS: MMM Generator Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd L * ATLAS Search Engine NB MU,NU,KU xfetch MulAdd Latency ATLAS MMM Code Generator MiniMMM Source source: Pingali, Yotov, Cornell U. search used no search used ATLAS MMM generator implementation installation platform known use problem parameters known
4 FFTW: Discrete Fourier Transform (DFT) Frigo, Johnson Installation configure/make n = 1024 radix 16 Usage d = dft(n) d(x,y) Twiddles Search for fastest computation strategy base case radix base case base case FFTW: Codelet Generator Frigo n DFT codelet generator dft_n(*x, *y, ) fixed size DFT functions straightline code
5 search used no search used FFTW codelet generator ATLAS MMM generator FFTW adaptive library implementation installation platform known use problem parameters known OSKI: Sparse Matrix-Vector Multiplication Vuduc, Im, Yelick, Demmel = * Blocking for registers: Improves locality (reuse of input vector) But creates overhead (zeros in block) * =
 search used no search used OSKI sparse MVM OSKI sparse MVM FFTW codelet generator ATLAS MMM generator FFTW adaptive library implementation installation")
6 OSKI: Sparse Matrix-Vector Multiplication Gain by blocking (dense MVM) Overhead by blocking * = 16/9 = /1.77 = 0.79 (no gain) search used no search used OSKI sparse MVM OSKI sparse MVM FFTW codelet generator ATLAS MMM generator FFTW adaptive library implementation installation platform known use problem parameters known

7 Program Generation in Spiral Transform Decomposition rules Algorithm (SPL) parallelization vectorization Algorithm ( -SPL) locality optimization C Program void sub(double *y, double *x) { double f0, f1, f2, f3, f4, f7, f8, f10, f11; f0 = x[0] - x[3]; f1 = x[0] + x[3]; f2 = x[1] - x[2]; f3 = x[1] + x[2]; f4 = f1 - f3; y[0] = f1 + f3; y[2] = * f4; f7 = * f0; < more lines> basic block optimizations + Search or Learning Spiral: Complete Automation for Transforms Memory hierarchy optimization Rewriting and search for algorithm selection Rewriting for loop optimizations Vectorization Rewriting Parallelization Rewriting fixed input size code Derivation of library structure Rewriting Other methods general input size library
8 search used no search used Machine learning Machine learning Spiral: transforms general input size Spiral: transforms general input size Spiral: transforms fixed input size OSKI sparse MVM OSKI sparse MVM FFTW codelet generator ATLAS MMM generator FFTW adaptive library implementation installation platform known use problem parameters known Overview Rough classification of autotuning efforts seen in course Use of machine learning I [de Mesmay et al., IPDPS 2010] Use of machine learning II 16
9 Online tuning ( use) Installation configure/make Offline tuning ( installation) Installation configure/make for a few n: search learn decision trees Use d = dft(n) d(x,y) Twiddles Search for fastest computation strategy Use d = dft(n) d(x,y) Twiddles Goal Library Structure: Examples DFT: scalar code DFT: full-fledged (vectorized and parallel code)
10 Library Structure: Examples DFT: scalar code Recursive choice: n = 2 k base case? radix? Example selections for n = 16: n = base case no base case radix 4 no base case radix base case base case Library Structure: Examples DFT: full-fledged (vectorized and parallel code) Recursive choice: n = 2 k base case? radix? threading? #threads? twiddles? loop exchange? Example selections for n = 1024: base case n = no base case radix 16 threading! 4 threads twiddles on the fly no loop exchange 8 8 base case base case no base case radix 8
11 Our Work Upon installation, generate decision trees for each choice Example: Statistical Classification: C4.5 Features (events) C4.5 P(play windy=false) = 6/8 P(don t play windy=false) = 2/8 P(play windy=true) = 1/2 P(don t play windy=false) = 1/2 H(windy=false) = 0.81 H(windy=true) = 1.0 Entropy of Features H(windy) = 0.89 H(outlook) = 0.69 H(humidity) =
12 Application to Libraries Features = arguments of functions (except variable pointers) dft(int n, cpx *y, cpx *x) dft_strided(int n, int istr, cpx *y, cpx *x) dft_scaled(int n, int str, cpx *d, cpx *y, cpx *x) At installation time: Run search for a few input sizes n Yields training set: features and associated decisions (several for each size) Generate decision trees using C4.5 and insert into library Issues Correctness of generated decision trees Issue: learning sizes n in {12, 18, 24, 48}, may find radix 6 Solution: correction pass through decision tree Prime factor structure n = 2 i 3 j = 2, 3, 4, 6, 9, 12, 16, 18, 24, 27, 32, i Compute i, j and add to features j



13 Experimental Setup 3GHz Intel Xeon 5160 (2 Core 2 Duos = 4 cores) Linux 64-bit, icc 10.1 Libraries: IPP 5.3 FFTW 3.2 alpha 2 Spiral-generated library Learning works as expected

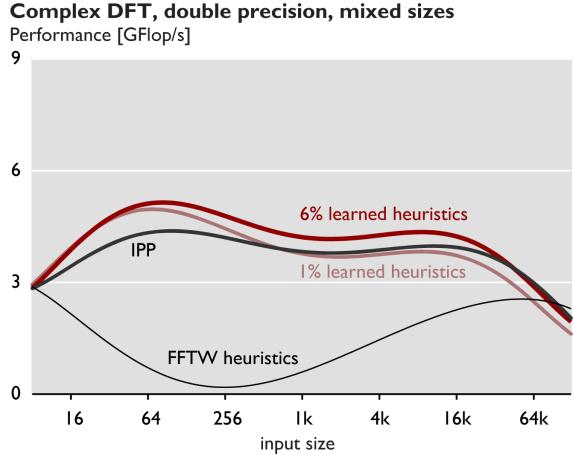
14 All Sizes All sizes n 2 18, with prime factors 19 All Sizes All sizes n 2 18, with prime factors 19 Higher order fit of all sizes

15 Overview Rough classification of autotuning efforts seen in course Use of machine learning I Use of machine learning II [de Mesmay et al., ICML 2009] 29 Picture:
16 Modeling Choice: Multi-armed Bandit Which arm to pull next to maximize reward? Modeling Choice: Multi-armed Bandit Multi-armed bandit choice 1 2 i k reward lists: (5, 7, 1) (4) (4, 3, 12, 2, 2) ( ) n i of which s i are among s best Which arm to pull next to maximize reward?

")

17 In Our Application partially expanded algorithm Multi-armed bandit choice of next expansion step Search Algorithm: TAG DFT 1024 multi-armed bandit DFT 1024 DFT 1024 (1200,1440,1520 ) (1200,1440, ) Monte Carlo 1520 Mflop/s 1520 Mflop/s Fully expanded algorithm Descend Evaluate Backpropagate

18 Experiments Spiral-generated adaptive libraries (similar to FFTW 3.x) Recursive choice: n = 2 k base case? radix? threading? #threads? twiddles? loop exchange? Intel Xeon 5160, 2 x dualcore, 3GHz Intel icc 10.1 FFTW 3.2alpha, Intel IPP 5.3 ~ 1 hour ~ 1 minute
19 Message of Lecture Machine learning should be used in autotuning Overcomes the problem of expensive searches Relatively easy to do Applicable to any search-based approach Removes searches or better searches Machine learning Machine learning implementation installation platform known use problem parameters known Research Questions How to automate the production of fastest numerical code? Domain-specific languages Rewriting Compilers Machine Learning What program language features help with program generation? What environment should be used to build generators? How to represent mathematical functionality? How to formalize the mapping to fast code? How to handle various forms of parallelism? How to integrate into standard work flows?
Automatic Performance Tuning and Machine Learning
 Automatic Performance Tuning and Machine Learning Markus Püschel Computer Science, ETH Zürich with: Frédéric de Mesmay PhD, Electrical and Computer Engineering, Carnegie Mellon PhD and Postdoc openings:
Automatic Performance Tuning and Machine Learning Markus Püschel Computer Science, ETH Zürich with: Frédéric de Mesmay PhD, Electrical and Computer Engineering, Carnegie Mellon PhD and Postdoc openings:
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Memory bound computation, sparse linear algebra, OSKI Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh ATLAS Mflop/s Compile Execute
How to Write Fast Numerical Code Lecture: Memory bound computation, sparse linear algebra, OSKI Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh ATLAS Mflop/s Compile Execute
How to Write Fast Numerical Code Spring 2012 Lecture 13. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 13 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato ATLAS Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd
How to Write Fast Numerical Code Spring 2012 Lecture 13 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato ATLAS Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd
How to Write Fast Numerical Code Spring 2012 Lecture 9. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 9 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Today Linear algebra software: history, LAPACK and BLAS Blocking (BLAS 3): key
How to Write Fast Numerical Code Spring 2012 Lecture 9 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Today Linear algebra software: history, LAPACK and BLAS Blocking (BLAS 3): key
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Dense linear algebra, LAPACK, MMM optimizations in ATLAS Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Today Linear algebra software: history,
How to Write Fast Numerical Code Lecture: Dense linear algebra, LAPACK, MMM optimizations in ATLAS Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Today Linear algebra software: history,
Automatic Performance Programming?
 A I n Automatic Performance Programming? Markus Püschel Computer Science m128i t3 = _mm_unpacklo_epi16(x[0], X[1]); m128i t4 = _mm_unpackhi_epi16(x[0], X[1]); m128i t7 = _mm_unpacklo_epi16(x[2], X[3]);
A I n Automatic Performance Programming? Markus Püschel Computer Science m128i t3 = _mm_unpacklo_epi16(x[0], X[1]); m128i t4 = _mm_unpackhi_epi16(x[0], X[1]); m128i t7 = _mm_unpacklo_epi16(x[2], X[3]);
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Cost analysis and performance Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato & Alen Stojanov Technicalities Research project: Let us know (fastcode@lists.inf.ethz.ch)
How to Write Fast Numerical Code Lecture: Cost analysis and performance Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato & Alen Stojanov Technicalities Research project: Let us know (fastcode@lists.inf.ethz.ch)
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Cost analysis and performance Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Technicalities Research project: Let us know (fastcode@lists.inf.ethz.ch)
How to Write Fast Numerical Code Lecture: Cost analysis and performance Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Technicalities Research project: Let us know (fastcode@lists.inf.ethz.ch)
How to Write Fast Numerical Code Spring 2012 Lecture 20. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 20 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Planning Today Lecture Project meetings Project presentations 10 minutes each
How to Write Fast Numerical Code Spring 2012 Lecture 20 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Planning Today Lecture Project meetings Project presentations 10 minutes each
How to Write Fast Code , spring rd Lecture, Apr. 9 th
 How to Write Fast Code 18-645, spring 2008 23 rd Lecture, Apr. 9 th Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Research Project Current status Today Papers due
How to Write Fast Code 18-645, spring 2008 23 rd Lecture, Apr. 9 th Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Research Project Current status Today Papers due
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries
 System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
Formal Loop Merging for Signal Transforms
 Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Optimizing FFT, FFTW Instructor: Markus Püschel TA: Georg Ofenbeck & Daniele Spampinato Rest of Semester Today Lecture Project meetings Project presentations 10
How to Write Fast Numerical Code Lecture: Optimizing FFT, FFTW Instructor: Markus Püschel TA: Georg Ofenbeck & Daniele Spampinato Rest of Semester Today Lecture Project meetings Project presentations 10
Optimal Performance Numerical Code Challenges and Solutions
 Optimal Performance Numerical Code Challenges and Solutions Markus Püschel Picture: www.tapety-na-pulpit.org Scientific Computing Physics/biology simulations Consumer Computing Audio/image/video processing
Optimal Performance Numerical Code Challenges and Solutions Markus Püschel Picture: www.tapety-na-pulpit.org Scientific Computing Physics/biology simulations Consumer Computing Audio/image/video processing
Program Generation, Optimization, and Adaptation: SPIRAL and other efforts
 Program Generation, Optimization, and Adaptation: SPIRAL and other efforts Markus Püschel Electrical and Computer Engineering University SPIRAL Team: José M. F. Moura (ECE, CMU) James C. Hoe (ECE, CMU)
Program Generation, Optimization, and Adaptation: SPIRAL and other efforts Markus Püschel Electrical and Computer Engineering University SPIRAL Team: José M. F. Moura (ECE, CMU) James C. Hoe (ECE, CMU)
How to Write Fast Numerical Code Spring 2011 Lecture 22. Instructor: Markus Püschel TA: Georg Ofenbeck
 How to Write Fast Numerical Code Spring 2011 Lecture 22 Instructor: Markus Püschel TA: Georg Ofenbeck Schedule Today Lecture Project presentations 10 minutes each random order random speaker 10 Final code
How to Write Fast Numerical Code Spring 2011 Lecture 22 Instructor: Markus Püschel TA: Georg Ofenbeck Schedule Today Lecture Project presentations 10 minutes each random order random speaker 10 Final code
SPIRAL Overview: Automatic Generation of DSP Algorithms & More *
 SPIRAL Overview: Automatic Generation of DSP Algorithms & More * Jeremy Johnson (& SPIRAL Team) Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for presentation provided
SPIRAL Overview: Automatic Generation of DSP Algorithms & More * Jeremy Johnson (& SPIRAL Team) Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for presentation provided
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Bandit-Based Optimization on Graphs with Application to Library Performance Tuning
 Bandit-Based Optimization on Graphs with Application to Library Performance Tuning Frédéric de Mesmay fdemesma@ece.cmu.edu Arpad Rimmel rimmel@lri.fr Yevgen Voronenko yvoronen@ece.cmu.edu Markus Püschel
Bandit-Based Optimization on Graphs with Application to Library Performance Tuning Frédéric de Mesmay fdemesma@ece.cmu.edu Arpad Rimmel rimmel@lri.fr Yevgen Voronenko yvoronen@ece.cmu.edu Markus Püschel
Tackling Parallelism With Symbolic Computation
 Tackling Parallelism With Symbolic Computation Markus Püschel and the Spiral team (only part shown) With: Franz Franchetti Yevgen Voronenko Electrical and Computer Engineering Carnegie Mellon University
Tackling Parallelism With Symbolic Computation Markus Püschel and the Spiral team (only part shown) With: Franz Franchetti Yevgen Voronenko Electrical and Computer Engineering Carnegie Mellon University
Systems Programming and Computer Architecture ( ) Timothy Roscoe
 Timothy Roscoe") Systems Group Department of Computer Science ETH Zürich Systems Programming and Computer Architecture (252-0061-00) Timothy Roscoe Herbstsemester 2016 AS 2016 Caches 1 16: Caches Computer Architecture
Systems Group Department of Computer Science ETH Zürich Systems Programming and Computer Architecture (252-0061-00) Timothy Roscoe Herbstsemester 2016 AS 2016 Caches 1 16: Caches Computer Architecture
Lecture 15: Caches and Optimization Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 15: Caches and Optimization Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Last time Program
Systems Group Department of Computer Science ETH Zürich Lecture 15: Caches and Optimization Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Last time Program
Optimizing MMM & ATLAS Library Generator
 Optimizing MMM & ATLAS Library Generator Recall: MMM miss ratios L1 Cache Miss Ratio for Intel Pentium III MMM with N = 1 1300 16 32/lock 4-way 8-byte elements IJ version (large cache) DO I = 1, N//row-major
Optimizing MMM & ATLAS Library Generator Recall: MMM miss ratios L1 Cache Miss Ratio for Intel Pentium III MMM with N = 1 1300 16 32/lock 4-way 8-byte elements IJ version (large cache) DO I = 1, N//row-major
How to Write Fast Numerical Code Spring 2011 Lecture 7. Instructor: Markus Püschel TA: Georg Ofenbeck
 How to Write Fast Numerical Code Spring 2011 Lecture 7 Instructor: Markus Püschel TA: Georg Ofenbeck Last Time: Locality Temporal and Spatial memory memory Last Time: Reuse FFT: O(log(n)) reuse MMM: O(n)
How to Write Fast Numerical Code Spring 2011 Lecture 7 Instructor: Markus Püschel TA: Georg Ofenbeck Last Time: Locality Temporal and Spatial memory memory Last Time: Reuse FFT: O(log(n)) reuse MMM: O(n)
Library Generation For Linear Transforms
 Library Generation For Linear Transforms Yevgen Voronenko May RS RS 3 RS RS RS RS 7 RS 5 Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Electrical
Library Generation For Linear Transforms Yevgen Voronenko May RS RS 3 RS RS RS RS 7 RS 5 Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Electrical
Cache-oblivious Programming
 Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix
Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix
SPIRAL Generated Modular FFTs *
 SPIRAL Generated Modular FFTs * Jeremy Johnson Lingchuan Meng Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for SPIRAL overview provided by Franz Francheti, Yevgen Voronenko,,
SPIRAL Generated Modular FFTs * Jeremy Johnson Lingchuan Meng Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for SPIRAL overview provided by Franz Francheti, Yevgen Voronenko,,
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Agenda Cache memory organization and operation Chapter 6 Performance impact of caches Cache Memories
 Agenda Chapter 6 Cache Memories Cache memory organization and operation Performance impact of caches The memory mountain Rearranging loops to improve spatial locality Using blocking to improve temporal
Agenda Chapter 6 Cache Memories Cache memory organization and operation Performance impact of caches The memory mountain Rearranging loops to improve spatial locality Using blocking to improve temporal
Autotuning (1/2): Cache-oblivious algorithms
: Cache-oblivious algorithms") Autotuning (1/2): Cache-oblivious algorithms Prof. Richard Vuduc Georgia Institute of Technology CSE/CS 8803 PNA: Parallel Numerical Algorithms [L.17] Tuesday, March 4, 2008 1 Today s sources CS 267 (Demmel
Autotuning (1/2): Cache-oblivious algorithms Prof. Richard Vuduc Georgia Institute of Technology CSE/CS 8803 PNA: Parallel Numerical Algorithms [L.17] Tuesday, March 4, 2008 1 Today s sources CS 267 (Demmel
How to Write Fast Code , spring st Lecture, Jan. 14 th
 How to Write Fast Code 18-645, spring 2008 1 st Lecture, Jan. 14 th Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Today Motivation and idea behind this course Technicalities
How to Write Fast Code 18-645, spring 2008 1 st Lecture, Jan. 14 th Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Today Motivation and idea behind this course Technicalities
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Organization Temporal and spatial locality Memory
How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Organization Temporal and spatial locality Memory
Cache memories are small, fast SRAM based memories managed automatically in hardware.
 Cache Memories Cache memories are small, fast SRAM based memories managed automatically in hardware. Hold frequently accessed blocks of main memory CPU looks first for data in caches (e.g., L1, L2, and
Cache Memories Cache memories are small, fast SRAM based memories managed automatically in hardware. Hold frequently accessed blocks of main memory CPU looks first for data in caches (e.g., L1, L2, and
Automatic Tuning Matrix Multiplication Performance on Graphics Hardware
 Automatic Tuning Matrix Multiplication Performance on Graphics Hardware Changhao Jiang (cjiang@cs.uiuc.edu) Marc Snir (snir@cs.uiuc.edu) University of Illinois Urbana Champaign GPU becomes more powerful
Automatic Tuning Matrix Multiplication Performance on Graphics Hardware Changhao Jiang (cjiang@cs.uiuc.edu) Marc Snir (snir@cs.uiuc.edu) University of Illinois Urbana Champaign GPU becomes more powerful
Today. Cache Memories. General Cache Concept. General Cache Organization (S, E, B) Cache Memories. Example Memory Hierarchy Smaller, faster,
 Cache Memories. Example Memory Hierarchy Smaller, faster,") Today Cache Memories CSci 2021: Machine Architecture and Organization November 7th-9th, 2016 Your instructor: Stephen McCamant Cache memory organization and operation Performance impact of caches The memory
Today Cache Memories CSci 2021: Machine Architecture and Organization November 7th-9th, 2016 Your instructor: Stephen McCamant Cache memory organization and operation Performance impact of caches The memory
Generating Parallel Transforms Using Spiral
 Generating Parallel Transforms Using Spiral Franz Franchetti Yevgen Voronenko Markus Püschel Part of the Spiral Team Electrical and Computer Engineering Carnegie Mellon University Sponsors: DARPA DESA
Generating Parallel Transforms Using Spiral Franz Franchetti Yevgen Voronenko Markus Püschel Part of the Spiral Team Electrical and Computer Engineering Carnegie Mellon University Sponsors: DARPA DESA
Cache Memories. Lecture, Oct. 30, Bryant and O Hallaron, Computer Systems: A Programmer s Perspective, Third Edition
 Cache Memories Lecture, Oct. 30, 2018 1 General Cache Concept Cache 84 9 14 10 3 Smaller, faster, more expensive memory caches a subset of the blocks 10 4 Data is copied in block-sized transfer units Memory
Cache Memories Lecture, Oct. 30, 2018 1 General Cache Concept Cache 84 9 14 10 3 Smaller, faster, more expensive memory caches a subset of the blocks 10 4 Data is copied in block-sized transfer units Memory
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Left alignment Attractive font (sans serif, avoid Arial) Calibri,
How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Left alignment Attractive font (sans serif, avoid Arial) Calibri,
Carnegie Mellon. Cache Lab. Recitation 7: Oct 11 th, 2016
 1 Cache Lab Recitation 7: Oct 11 th, 2016 2 Outline Memory organization Caching Different types of locality Cache organization Cache lab Part (a) Building Cache Simulator Part (b) Efficient Matrix Transpose
1 Cache Lab Recitation 7: Oct 11 th, 2016 2 Outline Memory organization Caching Different types of locality Cache organization Cache lab Part (a) Building Cache Simulator Part (b) Efficient Matrix Transpose
CS241 Computer Organization Spring Principle of Locality
 CS241 Computer Organization Spring 2015 Principle of Locality 4-21 2015 Outline! Optimization! Memory Hierarchy Locality temporal spatial Cache Readings: CSAPP2: Chapter 5, sections 5.1-5.6; 5.13 CSAPP2:
CS241 Computer Organization Spring 2015 Principle of Locality 4-21 2015 Outline! Optimization! Memory Hierarchy Locality temporal spatial Cache Readings: CSAPP2: Chapter 5, sections 5.1-5.6; 5.13 CSAPP2:
Today Cache memory organization and operation Performance impact of caches
 Cache Memories 1 Today Cache memory organization and operation Performance impact of caches The memory mountain Rearranging loops to improve spatial locality Using blocking to improve temporal locality
Cache Memories 1 Today Cache memory organization and operation Performance impact of caches The memory mountain Rearranging loops to improve spatial locality Using blocking to improve temporal locality
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Statistical Models for Automatic Performance Tuning
 Statistical Models for Automatic Performance Tuning Richard Vuduc, James Demmel (U.C. Berkeley, EECS) {richie,demmel}@cs.berkeley.edu Jeff Bilmes (Univ. of Washington, EE) bilmes@ee.washington.edu May
Statistical Models for Automatic Performance Tuning Richard Vuduc, James Demmel (U.C. Berkeley, EECS) {richie,demmel}@cs.berkeley.edu Jeff Bilmes (Univ. of Washington, EE) bilmes@ee.washington.edu May
Cache Lab Implementation and Blocking
 Cache Lab Implementation and Blocking Lou Clark February 24 th, 2014 1 Welcome to the World of Pointers! 2 Class Schedule Cache Lab Due Thursday. Start soon if you haven t yet! Exam Soon! Start doing practice
Cache Lab Implementation and Blocking Lou Clark February 24 th, 2014 1 Welcome to the World of Pointers! 2 Class Schedule Cache Lab Due Thursday. Start soon if you haven t yet! Exam Soon! Start doing practice
Advanced Computing Research Laboratory. Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform
 Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
SPIRAL: A Generator for Platform-Adapted Libraries of Signal Processing Algorithms
 SPIRAL: A Generator for Platform-Adapted Libraries of Signal Processing Algorithms Markus Püschel Faculty José Moura (CMU) Jeremy Johnson (Drexel) Robert Johnson (MathStar Inc.) David Padua (UIUC) Viktor
SPIRAL: A Generator for Platform-Adapted Libraries of Signal Processing Algorithms Markus Püschel Faculty José Moura (CMU) Jeremy Johnson (Drexel) Robert Johnson (MathStar Inc.) David Padua (UIUC) Viktor
Automated Empirical Optimizations of Software and the ATLAS project* Software Engineering Seminar Pascal Spörri
 Automated Empirical Optimizations of Software and the ATLAS project* Software Engineering Seminar Pascal Spörri *R. Clint Whaley, Antoine Petitet and Jack Dongarra. Parallel Computing, 27(1-2):3-35, 2001.
Automated Empirical Optimizations of Software and the ATLAS project* Software Engineering Seminar Pascal Spörri *R. Clint Whaley, Antoine Petitet and Jack Dongarra. Parallel Computing, 27(1-2):3-35, 2001.
Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Types of Cache Misses. The Hardware/So<ware Interface CSE351 Winter Cache Read. General Cache OrganizaJon (S, E, B) Memory and Caches II
 Memory and Caches II") Types of Cache Misses The Hardware/So
Types of Cache Misses The Hardware/So
 The Hardware/So
The Hardware/So Results and Discussion *
 OpenStax-CNX module: m Results and Discussion * Anthony Blake This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License. In order to test the hypotheses set out
OpenStax-CNX module: m Results and Discussion * Anthony Blake This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License. In order to test the hypotheses set out
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Benchmarking, Compiler Limitations Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Last Time: ILP Latency/throughput (Pentium
How to Write Fast Numerical Code Lecture: Benchmarking, Compiler Limitations Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Last Time: ILP Latency/throughput (Pentium
Problem: Processor Memory BoJleneck
 Today Memory hierarchy, caches, locality Cache organiza:on Program op:miza:ons that consider caches CSE351 Inaugural Edi:on Spring 2010 1 Problem: Processor Memory BoJleneck Processor performance doubled
Today Memory hierarchy, caches, locality Cache organiza:on Program op:miza:ons that consider caches CSE351 Inaugural Edi:on Spring 2010 1 Problem: Processor Memory BoJleneck Processor performance doubled
Carnegie Mellon. Cache Memories
 Cache Memories Thanks to Randal E. Bryant and David R. O Hallaron from CMU Reading Assignment: Computer Systems: A Programmer s Perspec4ve, Third Edi4on, Chapter 6 1 Today Cache memory organiza7on and
Cache Memories Thanks to Randal E. Bryant and David R. O Hallaron from CMU Reading Assignment: Computer Systems: A Programmer s Perspec4ve, Third Edi4on, Chapter 6 1 Today Cache memory organiza7on and
FFT Program Generation for Shared Memory: SMP and Multicore
 FFT Program Generation for Shared Memory: SMP and Multicore Franz Franchetti, Yevgen Voronenko, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University Abstract The chip maker
FFT Program Generation for Shared Memory: SMP and Multicore Franz Franchetti, Yevgen Voronenko, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University Abstract The chip maker
Program Composition and Optimization: An Introduction
 Program Composition and Optimization: An Introduction Christoph W. Kessler 1, Welf Löwe 2, David Padua 3, and Markus Püschel 4 1 Linköping University, Linköping, Sweden, chrke@ida.liu.se 2 Linnaeus University,
Program Composition and Optimization: An Introduction Christoph W. Kessler 1, Welf Löwe 2, David Padua 3, and Markus Püschel 4 1 Linköping University, Linköping, Sweden, chrke@ida.liu.se 2 Linnaeus University,
FFT Program Generation for Shared Memory: SMP and Multicore
 FFT Program Generation for Shared Memory: SMP and Multicore Franz Franchetti, Yevgen Voronenko, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University {franzf, yvoronen, pueschel@ece.cmu.edu
FFT Program Generation for Shared Memory: SMP and Multicore Franz Franchetti, Yevgen Voronenko, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University {franzf, yvoronen, pueschel@ece.cmu.edu
Performance Analysis of a Family of WHT Algorithms
 Performance Analysis of a Family of WHT Algorithms Michael Andrews and Jeremy Johnson Department of Computer Science Drexel University Philadelphia, PA USA January, 7 Abstract This paper explores the correlation
Performance Analysis of a Family of WHT Algorithms Michael Andrews and Jeremy Johnson Department of Computer Science Drexel University Philadelphia, PA USA January, 7 Abstract This paper explores the correlation
Cache Memories /18-213/15-513: Introduction to Computer Systems 12 th Lecture, October 5, Today s Instructor: Phil Gibbons
 Cache Memories 15-213/18-213/15-513: Introduction to Computer Systems 12 th Lecture, October 5, 2017 Today s Instructor: Phil Gibbons 1 Today Cache memory organization and operation Performance impact
Cache Memories 15-213/18-213/15-513: Introduction to Computer Systems 12 th Lecture, October 5, 2017 Today s Instructor: Phil Gibbons 1 Today Cache memory organization and operation Performance impact
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 8-799B spring 25 24 th and 25 th Lecture Apr. 7 and 2, 25 Instructor: Markus Pueschel TA: Srinivas Chellappa Research Projects Presentations
Algorithms and Computation in Signal Processing special topic course 8-799B spring 25 24 th and 25 th Lecture Apr. 7 and 2, 25 Instructor: Markus Pueschel TA: Srinivas Chellappa Research Projects Presentations
A Fast Fourier Transform Compiler
 RETROSPECTIVE: A Fast Fourier Transform Compiler Matteo Frigo Vanu Inc., One Porter Sq., suite 18 Cambridge, MA, 02140, USA athena@fftw.org 1. HOW FFTW WAS BORN FFTW (the fastest Fourier transform in the
RETROSPECTIVE: A Fast Fourier Transform Compiler Matteo Frigo Vanu Inc., One Porter Sq., suite 18 Cambridge, MA, 02140, USA athena@fftw.org 1. HOW FFTW WAS BORN FFTW (the fastest Fourier transform in the
Denison University. Cache Memories. CS-281: Introduction to Computer Systems. Instructor: Thomas C. Bressoud
 Cache Memories CS-281: Introduction to Computer Systems Instructor: Thomas C. Bressoud 1 Random-Access Memory (RAM) Key features RAM is traditionally packaged as a chip. Basic storage unit is normally
Cache Memories CS-281: Introduction to Computer Systems Instructor: Thomas C. Bressoud 1 Random-Access Memory (RAM) Key features RAM is traditionally packaged as a chip. Basic storage unit is normally
Input parameters System specifics, user options. Input parameters size, dim,... FFT Code Generator. Initialization Select fastest execution plan
 Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Cache Memories : Introduc on to Computer Systems 12 th Lecture, October 6th, Instructor: Randy Bryant.
 Cache Memories 15-213: Introduc on to Computer Systems 12 th Lecture, October 6th, 2016 Instructor: Randy Bryant 1 Today Cache memory organiza on and opera on Performance impact of caches The memory mountain
Cache Memories 15-213: Introduc on to Computer Systems 12 th Lecture, October 6th, 2016 Instructor: Randy Bryant 1 Today Cache memory organiza on and opera on Performance impact of caches The memory mountain
IMPLEMENTATION OF THE. Alexander J. Yee University of Illinois Urbana-Champaign
 SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
Stochastic Search for Signal Processing Algorithm Optimization
 Stochastic Search for Signal Processing Algorithm Optimization Bryan Singer and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 1213 Email: {bsinger+, mmv+}@cs.cmu.edu
Stochastic Search for Signal Processing Algorithm Optimization Bryan Singer and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 1213 Email: {bsinger+, mmv+}@cs.cmu.edu
Auto-tuning Multigrid with PetaBricks
 Auto-tuning with PetaBricks Cy Chan Joint Work with: Jason Ansel Yee Lok Wong Saman Amarasinghe Alan Edelman Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
Auto-tuning with PetaBricks Cy Chan Joint Work with: Jason Ansel Yee Lok Wong Saman Amarasinghe Alan Edelman Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
Carnegie Mellon. Cache Memories. Computer Architecture. Instructor: Norbert Lu1enberger. based on the book by Randy Bryant and Dave O Hallaron
 Cache Memories Computer Architecture Instructor: Norbert Lu1enberger based on the book by Randy Bryant and Dave O Hallaron 1 Today Cache memory organiza7on and opera7on Performance impact of caches The
Cache Memories Computer Architecture Instructor: Norbert Lu1enberger based on the book by Randy Bryant and Dave O Hallaron 1 Today Cache memory organiza7on and opera7on Performance impact of caches The
Example. How are these parameters decided?
 Example How are these parameters decided? Comparing cache organizations Like many architectural features, caches are evaluated experimentally. As always, performance depends on the actual instruction mix,
Example How are these parameters decided? Comparing cache organizations Like many architectural features, caches are evaluated experimentally. As always, performance depends on the actual instruction mix,
When Cache Blocking of Sparse Matrix Vector Multiply Works and Why
 When Cache Blocking of Sparse Matrix Vector Multiply Works and Why Rajesh Nishtala 1, Richard W. Vuduc 1, James W. Demmel 1, and Katherine A. Yelick 1 University of California at Berkeley, Computer Science
When Cache Blocking of Sparse Matrix Vector Multiply Works and Why Rajesh Nishtala 1, Richard W. Vuduc 1, James W. Demmel 1, and Katherine A. Yelick 1 University of California at Berkeley, Computer Science
Roadmap. Java: Assembly language: OS: Machine code: Computer system:
 Roadmap C: car *c = malloc(sizeof(car)); c->miles = 100; c->gals = 17; float mpg = get_mpg(c); free(c); Assembly language: Machine code: get_mpg: pushq movq... popq ret %rbp %rsp, %rbp %rbp 0111010000011000
Roadmap C: car *c = malloc(sizeof(car)); c->miles = 100; c->gals = 17; float mpg = get_mpg(c); free(c); Assembly language: Machine code: get_mpg: pushq movq... popq ret %rbp %rsp, %rbp %rbp 0111010000011000
Stochastic Search for Signal Processing Algorithm Optimization
 Stochastic Search for Signal Processing Algorithm Optimization Bryan Singer Manuela Veloso May, 01 CMU-CS-01-137 School of Computer Science Carnegie Mellon University Pittsburgh, PA 1213 Abstract Many
Stochastic Search for Signal Processing Algorithm Optimization Bryan Singer Manuela Veloso May, 01 CMU-CS-01-137 School of Computer Science Carnegie Mellon University Pittsburgh, PA 1213 Abstract Many
Cache Memories. Andrew Case. Slides adapted from Jinyang Li, Randy Bryant and Dave O Hallaron
 Cache Memories Andrew Case Slides adapted from Jinyang Li, Randy Bryant and Dave O Hallaron 1 Topics Cache memory organiza3on and opera3on Performance impact of caches 2 Cache Memories Cache memories are
Cache Memories Andrew Case Slides adapted from Jinyang Li, Randy Bryant and Dave O Hallaron 1 Topics Cache memory organiza3on and opera3on Performance impact of caches 2 Cache Memories Cache memories are
An Adaptive Framework for Scientific Software Libraries. Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston
 An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
On the Computer Generation of Adaptive Numerical Libraries
 On the Computer Generation of Adaptive Numerical Libraries A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy FRÉDÉRIC DE MESMAY Supervised by Markus
On the Computer Generation of Adaptive Numerical Libraries A Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy FRÉDÉRIC DE MESMAY Supervised by Markus
The Design and Implementation of FFTW3
 The Design and Implementation of FFTW3 MATTEO FRIGO AND STEVEN G. JOHNSON Invited Paper FFTW is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize
The Design and Implementation of FFTW3 MATTEO FRIGO AND STEVEN G. JOHNSON Invited Paper FFTW is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize
Autotuning (2.5/2): TCE & Empirical compilers
: TCE & Empirical compilers") Autotuning (2.5/2): TCE & Empirical compilers Prof. Richard Vuduc Georgia Institute of Technology CSE/CS 8803 PNA: Parallel Numerical Algorithms [L.19] Tuesday, March 11, 2008 1 Today s sources CS 267
Autotuning (2.5/2): TCE & Empirical compilers Prof. Richard Vuduc Georgia Institute of Technology CSE/CS 8803 PNA: Parallel Numerical Algorithms [L.19] Tuesday, March 11, 2008 1 Today s sources CS 267
poski: Parallel Optimized Sparse Kernel Interface Library User s Guide for Version 1.0.0
 poski: Parallel Optimized Sparse Kernel Interface Library User s Guide for Version 1.0.0 Jong-Ho Byun James W. Demmel Richard Lin Katherine A. Yelick Berkeley Benchmarking and Optimization (BeBOP) Group
poski: Parallel Optimized Sparse Kernel Interface Library User s Guide for Version 1.0.0 Jong-Ho Byun James W. Demmel Richard Lin Katherine A. Yelick Berkeley Benchmarking and Optimization (BeBOP) Group
Automatically Tuned FFTs for BlueGene/L s Double FPU
 Automatically Tuned FFTs for BlueGene/L s Double FPU Franz Franchetti, Stefan Kral, Juergen Lorenz, Markus Püschel, and Christoph W. Ueberhuber Institute for Analysis and Scientific Computing, Vienna University
Automatically Tuned FFTs for BlueGene/L s Double FPU Franz Franchetti, Stefan Kral, Juergen Lorenz, Markus Püschel, and Christoph W. Ueberhuber Institute for Analysis and Scientific Computing, Vienna University
FFT Program Generation for the Cell BE
 FFT Program Generation for the Cell BE Srinivas Chellappa, Franz Franchetti, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University Pittsburgh PA 15213, USA {schellap, franzf,
FFT Program Generation for the Cell BE Srinivas Chellappa, Franz Franchetti, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University Pittsburgh PA 15213, USA {schellap, franzf,
SFFT Documentation. Release 0.1. Jörn Schumacher
 SFFT Documentation Release 0.1 Jörn Schumacher June 11, 2013 CONTENTS 1 Introduction 3 1.1 When Should I use the SFFT library?.................................. 3 1.2 Target Platform..............................................
SFFT Documentation Release 0.1 Jörn Schumacher June 11, 2013 CONTENTS 1 Introduction 3 1.1 When Should I use the SFFT library?.................................. 3 1.2 Target Platform..............................................
Automatically Optimized FFT Codes for the BlueGene/L Supercomputer
 Automatically Optimized FFT Codes for the BlueGene/L Supercomputer Franz Franchetti, Stefan Kral, Juergen Lorenz, Markus Püschel, Christoph W. Ueberhuber, and Peter Wurzinger Institute for Analysis and
Automatically Optimized FFT Codes for the BlueGene/L Supercomputer Franz Franchetti, Stefan Kral, Juergen Lorenz, Markus Püschel, Christoph W. Ueberhuber, and Peter Wurzinger Institute for Analysis and
Joint Runtime / Energy Optimization and Hardware / Software Partitioning of Linear Transforms
 Joint Runtime / Energy Optimization and Hardware / Software Partitioning of Linear Transforms Paolo D Alberto, Franz Franchetti, Peter A. Milder, Aliaksei Sandryhaila, James C. Hoe, José M. F. Moura, Markus
Joint Runtime / Energy Optimization and Hardware / Software Partitioning of Linear Transforms Paolo D Alberto, Franz Franchetti, Peter A. Milder, Aliaksei Sandryhaila, James C. Hoe, José M. F. Moura, Markus
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms
 Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop
: Automatic Performance Tuning Workshop") Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Exploring the Optimization Space of Dense Linear Algebra Kernels
 Exploring the Optimization Space of Dense Linear Algebra Kernels Qing Yi Apan Qasem University of Texas at San Anstonio Texas State University Abstract. Dense linear algebra kernels such as matrix multiplication
Exploring the Optimization Space of Dense Linear Algebra Kernels Qing Yi Apan Qasem University of Texas at San Anstonio Texas State University Abstract. Dense linear algebra kernels such as matrix multiplication
How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core
 How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Technicalities Research project: Let
How to Write Fast Numerical Code Spring 2013 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel TA: Daniele Spampinato & Alen Stojanov Technicalities Research project: Let
Computer Systems CSE 410 Autumn Memory Organiza:on and Caches
 Computer Systems CSE 410 Autumn 2013 10 Memory Organiza:on and Caches 06 April 2012 Memory Organiza?on 1 Roadmap C: car *c = malloc(sizeof(car)); c->miles = 100; c->gals = 17; float mpg = get_mpg(c); free(c);
Computer Systems CSE 410 Autumn 2013 10 Memory Organiza:on and Caches 06 April 2012 Memory Organiza?on 1 Roadmap C: car *c = malloc(sizeof(car)); c->miles = 100; c->gals = 17; float mpg = get_mpg(c); free(c);
Special Issue on Program Generation, Optimization, and Platform Adaptation /$ IEEE
 Scanning the Issue Special Issue on Program Generation, Optimization, and Platform Adaptation This special issue of the PROCEEDINGS OF THE IEEE offers an overview of ongoing efforts to facilitate the development
Scanning the Issue Special Issue on Program Generation, Optimization, and Platform Adaptation This special issue of the PROCEEDINGS OF THE IEEE offers an overview of ongoing efforts to facilitate the development
FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES
 FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES FRANCHETTI Franz, (AUT), KALTENBERGER Florian, (AUT), UEBERHUBER Christoph W. (AUT) Abstract. FFTs are the single most important algorithms in science and
FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES FRANCHETTI Franz, (AUT), KALTENBERGER Florian, (AUT), UEBERHUBER Christoph W. (AUT) Abstract. FFTs are the single most important algorithms in science and
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply
 Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Evaluating the Role of Optimization-Specific Search Heuristics in Effective Autotuning
 Evaluating the Role of Optimization-Specific Search Heuristics in Effective Autotuning Jichi Guo 1 Qing Yi 1 Apan Qasem 2 1 University of Texas at San Antonio 2 Texas State University Abstract. The increasing
Evaluating the Role of Optimization-Specific Search Heuristics in Effective Autotuning Jichi Guo 1 Qing Yi 1 Apan Qasem 2 1 University of Texas at San Antonio 2 Texas State University Abstract. The increasing
How To Write Fast Numerical Code: A Small Introduction
 How To Write Fast Numerical Code: A Small Introduction Srinivas Chellappa, Franz Franchetti, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University {schellap, franzf, pueschel}@ece.cmu.edu
How To Write Fast Numerical Code: A Small Introduction Srinivas Chellappa, Franz Franchetti, and Markus Püschel Electrical and Computer Engineering Carnegie Mellon University {schellap, franzf, pueschel}@ece.cmu.edu
Aggressive Scheduling for Numerical Programs
 Aggressive Scheduling for Numerical Programs Richard Veras, Flavio Cruz, Berkin Akin May 2, 2012 Abstract Certain classes of algorithms are still hard to optimize by modern compilers due to the differences
Aggressive Scheduling for Numerical Programs Richard Veras, Flavio Cruz, Berkin Akin May 2, 2012 Abstract Certain classes of algorithms are still hard to optimize by modern compilers due to the differences
Memory Hierarchy Optimizations and Performance Bounds for Sparse A T Ax
 Memory Hierarchy Optimizations and Performance Bounds for Sparse A T Ax Richard Vuduc, Attila Gyulassy, James W. Demmel, and Katherine A. Yelick Computer Science Division, University of California, Berkeley
Memory Hierarchy Optimizations and Performance Bounds for Sparse A T Ax Richard Vuduc, Attila Gyulassy, James W. Demmel, and Katherine A. Yelick Computer Science Division, University of California, Berkeley
A SIMD Vectorizing Compiler for Digital Signal Processing Algorithms Λ
 A SIMD Vectorizing Compiler for Digital Signal Processing Algorithms Λ Franz Franchetti Applied and Numerical Mathematics Technical University of Vienna, Austria franz.franchetti@tuwien.ac.at Markus Püschel
A SIMD Vectorizing Compiler for Digital Signal Processing Algorithms Λ Franz Franchetti Applied and Numerical Mathematics Technical University of Vienna, Austria franz.franchetti@tuwien.ac.at Markus Püschel
Dense matrix algebra and libraries (and dealing with Fortran)
") Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
Automatic Generation of the HPC Challenge's Global FFT Benchmark for BlueGene/P
 Automatic Generation of the HPC Challenge's Global FFT Benchmark for BlueGene/P Franz Franchetti 1, Yevgen Voronenko 2, Gheorghe Almasi 3 1 University and SpiralGen, Inc. 2 AccuRay, Inc., 3 IBM Research
Automatic Generation of the HPC Challenge's Global FFT Benchmark for BlueGene/P Franz Franchetti 1, Yevgen Voronenko 2, Gheorghe Almasi 3 1 University and SpiralGen, Inc. 2 AccuRay, Inc., 3 IBM Research