IMPLEMENTATION OF THE. Alexander J. Yee University of Illinois Urbana-Champaign
|
|
|
- Scarlett George
- 5 years ago
- Views:
Transcription
1 SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign
2 The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory bandwidth is always problem. Single-node shared memory: not enough bandwidth Multi-node: even worse Dominant factor in performance. Naïve implementations also bound by latency. Data-reordering can be many times slower than FFT computation itself!
3 The Classic Approach to 3D-FFT 1. Perform x-dimension FFT. 2. In-memory transpose. 3. All-to-all communication. 4. Perform y-dimension FFT. 5. In-memory transpose. 6. All-to-all communication. 7. Perform z-dimension FFT. 8. In-memory transpose. 9. All-to-all communication. Exact order may differ. 3 all-to-all communication steps. An extra transpose may be needed at beginning i to get data into order.








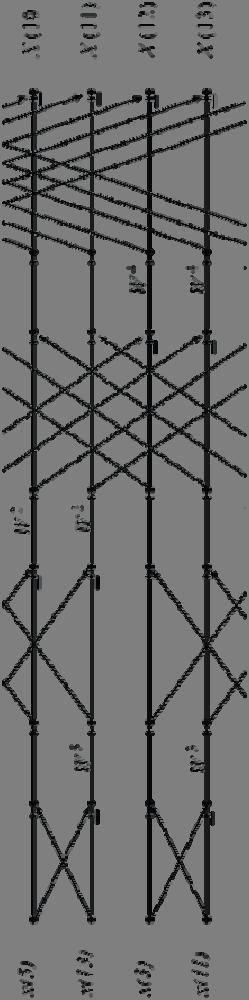
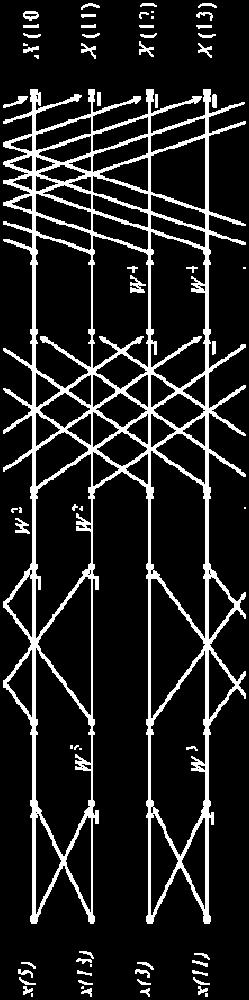
4 What is an out-of-order FFT? The Out-of-order FFT is mathematically the same as in-order FFT: Frequency domain is not in order. Forward Transform: Start from in-order time domain. End with out-of-order frequency domain. Use Decimation-in-Frequency algorithm. Inverse Transform: Start from out-of-order frequency domain. End with in-order time domain. Use Decimation-in-Time algorithm. Order of Frequency Domain: Bit-reversed is the most common. Other orders exist. Some algorithms are even faster at the cost of further scrambling up the frequency domain. Decimation-in-Frequency FFT (Image taken from cnx.org)
5 Why Out-of-Order? Many applications do not need an in-order frequency domain. Convolution Do not even need to look at Frequency Domain. Out-of-order FFT is faster: In-order FFTs require data-reordering -> bit-reversal Very poor memory access. Re-ordering is more expensive than FFT itself! In-order FFTs cannot be easily done in place. Requires double the memory of out-of-order FFT. Aggravates memory bottleneck. Out-of-order order FFT can be several times faster! No need for final transpose for distributed FFTs over many nodes.
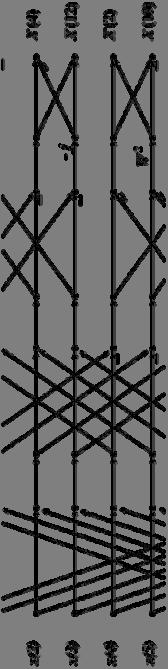


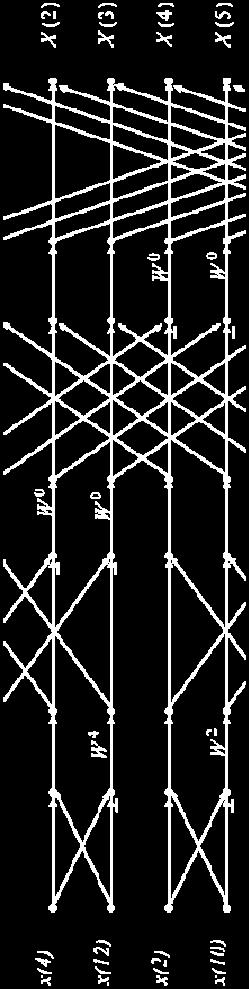

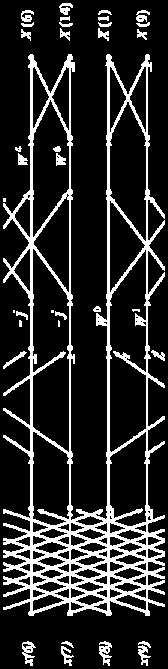



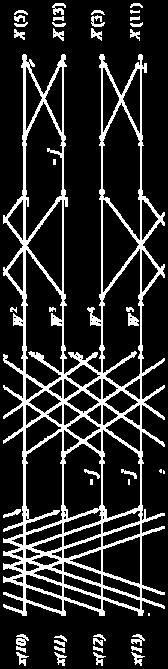
6 Convolution via Out-of-order FFT Time-domain (in order) Pointwise Multiply (order does not matter) Time-domain (in order) (Images taken from cnx.org)
7 Implementations of out-of-order FFT Prime95/MPrime By George Woltman Used in GIMPs (Great Internet t Mersenne Pi Prime Search) World record holder for the largest prime number found. (August 2008) 9 of 10 largest known prime numbers found by GIMPS. Uses FFT for cyclic convolution. Fastest known out-of-order of order FFT. (x assembly for Windows + Linux) y-cruncher Multi-threaded Pi Program By Alexander J. Yee Fastest program to compute Pi and other constants. World Record holder for the most digits it of Pi ever computed. (5 trillion digits it August 2010) Uses FFT and NTT for multiplying large numbers. Almost as fast as Prime95. (Standard C with Intel SSE Intrinsics cross platform) djbfft By Daniel J. Bernstein One of the first implementations of out-of-order FFTs. Outperformed FFTW by factors > 3 for convolution. Never widely-used, but motivated other out-of-order FFT projects.
8 Our Approach to 3D-FFT Recognize that n-d FFT is same as 1D FFT. Different Twiddle Factors. Same Memory Access. Same Data-Flow. Implement a 1D-FFT with modified twiddle factors instead! All tricks for optimizing 1D-FFT are now available. Use Bailey s 4-step algorithm for 1D FFT. 1. First computation ti pass. 2. Matrix Transpose 3. Second computation pass. 4. Matrix Transpose data back to initial order. Out-of-order FFT -> No need for final transpose! Total: 1 transpose -> Only 1 all-to-all communication.
9 Our Approach to 3D-FFT (cont.) To apply Bailey s 4-step method: Break the FFT into 2 passes. Easy way (slab decomposition): x and y into one pass. z by itself in second pass. (y can go with x or z) Hard way (split dimension): i Split the y dimension across the two passes. Overcomes scalability issue with 1 st method. (see next section) Both are being implemented. Frequency Domain will be Bit-reversed.
10 Drawbacks Slab Decomposition Split Dimension Can use standard FFT libraries. Cannot use standard libraries. Optimal performance will still require custom sub-routines. Everything must be written from scratch. Input data can be contiguous. Input data must be strided. Most common representation. Could imply extra transpose. # of nodes must divide evenly into either x or z dimension. # of nodes must divide evenly into x*y or x*z. Scalability is limited i to N nodes for N 3 3D-FFT Scalability is limited i to N 3/2 nodes for N 3 3D-FFT. Blue Waters will have more than 10, nodes Not a problem on Blue Waters.
11 Some Implementation Details All code written from scratch. No libraries. i Everything is customized. SIMD SSE for x86-64 AltiVec for PowerPC Struct of Arrays layout Will extend to AVX and FMA in the future. (Next-gen Intel/AMD x64.) Radix 4 FFT Good performance. Fits into 16 registers. Not too bad for cache associativity. Pre-compute Twiddle Factors Duplicate tables to ensure sequential access.
12 Benchmarks Memory Bottleneck Complex Out-of-order 3D-FFT ( ) Windows OpenMP - 16 GB needed 2 x Intel Xeon X GB DDR2 2 memory channels per socket 4 memory channels total 50 Seconds Affinity 1 socket 2 sockets different socke ets all in same soc cket 2 per socket 1 thread 2 threads 4 threads 8 threads Threads all cores utilize ed
13 Benchmarks - Shared Memory 80 Complex Out-of-order 3D-FFT ( ) Slab Decomposition - 32 GB needed 2 x Intel Xeon X GB DDR Time (second ds) 50 All 40 FFT-z All-to-all 30 Transpose 20 FFT-xy 10 0
14 Early Benchmarks - Distributed 25 Complex Out-of-order 3D-FFT ( ) Slab Decomposition - 32 GB needed Accelerator Cluster - UIUC 20 s) Time (second Strided FFT-z All-to-all Inner-node Transpose Dense FFT-xy / 8 32 / 8 32 / / 16 MPI Processes / Nodes
15 Analysis All-to-all communication steps reduced: Reduced from 3 to 1 for out-of-order FFT. In-order FFT doable by adding one transpose at end. Possibly communication optimal: No data dt is transferred more than once. Some data is never transferred at all. Hard to further reduce the # of bytes transferred. (Is our current approach optimal?) Maybe possible to improve communication pattern instead? Lots of room for improvement within the node. FFT computation can be better optimized. Difficult to imagine more nodes than x or z dimension. Blue Waters: > 10,000 nodes 10,000 may be greater than one of the dimensions. May not be possible (or efficient) to use slab-decomposition.
16 Next Steps Test current code on larger systems. Make sure the current implementation scales Port the code to PowerPC AltiVec. Currently implemented using x SSE3. Implement blocking and padding. Breaks cache associativity -> allows higher radix transforms. Overlapped communication i and computation. Support for prime factors other than 2 3*2 k, 5*2 k, and maybe 7*2 k Real-input transforms. In-order FFT.
17 Thanks for Listening Questions?
c 2013 Alexander Jih-Hing Yee
 c 2013 Alexander Jih-Hing Yee A FASTER FFT IN THE MID-WEST BY ALEXANDER JIH-HING YEE THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science
c 2013 Alexander Jih-Hing Yee A FASTER FFT IN THE MID-WEST BY ALEXANDER JIH-HING YEE THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
John W. Romein. Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands
 Dwingeloo, the Netherlands") Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Intel Performance Libraries
 Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
The p196 mpi implementation of the reverse-and-add algorithm for the palindrome quest.
 The p196 mpi implementation of the reverse-and-add algorithm for the palindrome quest. Romain Dolbeau March 24, 2014 1 Introduction To quote John Walker, the first person to brute-force the problem [1]:
The p196 mpi implementation of the reverse-and-add algorithm for the palindrome quest. Romain Dolbeau March 24, 2014 1 Introduction To quote John Walker, the first person to brute-force the problem [1]:
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
1. Many Core vs Multi Core. 2. Performance Optimization Concepts for Many Core. 3. Performance Optimization Strategy for Many Core
 1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
1. Many Core vs Multi Core 2. Performance Optimization Concepts for Many Core 3. Performance Optimization Strategy for Many Core 4. Example Case Studies NERSC s Cori will begin to transition the workload
My 2 hours today: 1. Efficient arithmetic in finite fields minute break 3. Elliptic curves. My 2 hours tomorrow:
 My 2 hours today: 1. Efficient arithmetic in finite fields 2. 10-minute break 3. Elliptic curves My 2 hours tomorrow: 4. Efficient arithmetic on elliptic curves 5. 10-minute break 6. Choosing curves Efficient
My 2 hours today: 1. Efficient arithmetic in finite fields 2. 10-minute break 3. Elliptic curves My 2 hours tomorrow: 4. Efficient arithmetic on elliptic curves 5. 10-minute break 6. Choosing curves Efficient
Achieving Peak Performance on Intel Hardware. Intel Software Developer Conference London, 2017
 Achieving Peak Performance on Intel Hardware Intel Software Developer Conference London, 2017 Welcome Aims for the day You understand some of the critical features of Intel processors and other hardware
Achieving Peak Performance on Intel Hardware Intel Software Developer Conference London, 2017 Welcome Aims for the day You understand some of the critical features of Intel processors and other hardware
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Multi-core processors are here, but how do you resolve data bottlenecks in native code?
 Multi-core processors are here, but how do you resolve data bottlenecks in native code? hint: it s all about locality Michael Wall October, 2008 part I of II: System memory 2 PDC 2008 October 2008 Session
Multi-core processors are here, but how do you resolve data bottlenecks in native code? hint: it s all about locality Michael Wall October, 2008 part I of II: System memory 2 PDC 2008 October 2008 Session
Adaptive Transpose Algorithms for Distributed Multicore Processors
 Adaptive Transpose Algorithms for Distributed Multicore Processors John C. Bowman and Malcolm Roberts University of Alberta and Université de Strasbourg April 15, 2016 www.math.ualberta.ca/ bowman/talks
Adaptive Transpose Algorithms for Distributed Multicore Processors John C. Bowman and Malcolm Roberts University of Alberta and Université de Strasbourg April 15, 2016 www.math.ualberta.ca/ bowman/talks
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
FAST FIR FILTERS FOR SIMD PROCESSORS WITH LIMITED MEMORY BANDWIDTH
 Key words: Digital Signal Processing, FIR filters, SIMD processors, AltiVec. Grzegorz KRASZEWSKI Białystok Technical University Department of Electrical Engineering Wiejska
Key words: Digital Signal Processing, FIR filters, SIMD processors, AltiVec. Grzegorz KRASZEWSKI Białystok Technical University Department of Electrical Engineering Wiejska
San Diego Supercomputer Center. Georgia Institute of Technology 3 IBM UNIVERSITY OF CALIFORNIA, SAN DIEGO
 Scalability of a pseudospectral DNS turbulence code with 2D domain decomposition on Power4+/Federation and Blue Gene systems D. Pekurovsky 1, P.K.Yeung 2,D.Donzis 2, S.Kumar 3, W. Pfeiffer 1, G. Chukkapalli
Scalability of a pseudospectral DNS turbulence code with 2D domain decomposition on Power4+/Federation and Blue Gene systems D. Pekurovsky 1, P.K.Yeung 2,D.Donzis 2, S.Kumar 3, W. Pfeiffer 1, G. Chukkapalli
Adaptive Matrix Transpose Algorithms for Distributed Multicore Processors
 Adaptive Matrix Transpose Algorithms for Distributed Multicore ors John C. Bowman and Malcolm Roberts Abstract An adaptive parallel matrix transpose algorithm optimized for distributed multicore architectures
Adaptive Matrix Transpose Algorithms for Distributed Multicore ors John C. Bowman and Malcolm Roberts Abstract An adaptive parallel matrix transpose algorithm optimized for distributed multicore architectures
High Performance Computing: Tools and Applications
 High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 8 Processor-level SIMD SIMD instructions can perform
High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 8 Processor-level SIMD SIMD instructions can perform
Parallelized Progressive Network Coding with Hardware Acceleration
 Parallelized Progressive Network Coding with Hardware Acceleration Hassan Shojania, Baochun Li Department of Electrical and Computer Engineering University of Toronto Network coding Information is coded
Parallelized Progressive Network Coding with Hardware Acceleration Hassan Shojania, Baochun Li Department of Electrical and Computer Engineering University of Toronto Network coding Information is coded
Adaptive Matrix Transpose Algorithms for Distributed Multicore Processors
 Adaptive Matrix Transpose Algorithms for Distributed Multicore ors John C. Bowman and Malcolm Roberts Abstract An adaptive parallel matrix transpose algorithm optimized for distributed multicore architectures
Adaptive Matrix Transpose Algorithms for Distributed Multicore ors John C. Bowman and Malcolm Roberts Abstract An adaptive parallel matrix transpose algorithm optimized for distributed multicore architectures
An Adaptive Framework for Scientific Software Libraries. Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston
 An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
High-Performance and Parallel Computing
 9 High-Performance and Parallel Computing 9.1 Code optimization To use resources efficiently, the time saved through optimizing code has to be weighed against the human resources required to implement
9 High-Performance and Parallel Computing 9.1 Code optimization To use resources efficiently, the time saved through optimizing code has to be weighed against the human resources required to implement
Efficient FFT Algorithm and Programming Tricks
 Connexions module: m12021 1 Efficient FFT Algorithm and Programming Tricks Douglas L. Jones This work is produced by The Connexions Project and licensed under the Creative Commons Attribution License Abstract
Connexions module: m12021 1 Efficient FFT Algorithm and Programming Tricks Douglas L. Jones This work is produced by The Connexions Project and licensed under the Creative Commons Attribution License Abstract
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
Results and Discussion *
 OpenStax-CNX module: m Results and Discussion * Anthony Blake This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License. In order to test the hypotheses set out
OpenStax-CNX module: m Results and Discussion * Anthony Blake This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License. In order to test the hypotheses set out
Double-precision General Matrix Multiply (DGEMM)
") Double-precision General Matrix Multiply (DGEMM) Parallel Computation (CSE 0), Assignment Andrew Conegliano (A0) Matthias Springer (A00) GID G-- January, 0 0. Assumptions The following assumptions apply
Double-precision General Matrix Multiply (DGEMM) Parallel Computation (CSE 0), Assignment Andrew Conegliano (A0) Matthias Springer (A00) GID G-- January, 0 0. Assumptions The following assumptions apply
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Lecture Notes on Cache Iteration & Data Dependencies
 Lecture Notes on Cache Iteration & Data Dependencies 15-411: Compiler Design André Platzer Lecture 23 1 Introduction Cache optimization can have a huge impact on program execution speed. It can accelerate
Lecture Notes on Cache Iteration & Data Dependencies 15-411: Compiler Design André Platzer Lecture 23 1 Introduction Cache optimization can have a huge impact on program execution speed. It can accelerate
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Introduction. Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: We study the bandwidth problem
 Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Introduction Stream processor: high computation to bandwidth ratio To make legacy hardware more like stream processor: Increase computation power Make the best use of available bandwidth We study the bandwidth
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Performance of deal.ii on a node
 Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Parallel Computing Ideas
 Parallel Computing Ideas K. 1 1 Department of Mathematics 2018 Why When to go for speed Historically: Production code Code takes a long time to run Code runs many times Code is not end in itself 2010:
Parallel Computing Ideas K. 1 1 Department of Mathematics 2018 Why When to go for speed Historically: Production code Code takes a long time to run Code runs many times Code is not end in itself 2010:
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Storage Hierarchy Management for Scientific Computing
 Storage Hierarchy Management for Scientific Computing by Ethan Leo Miller Sc. B. (Brown University) 1987 M.S. (University of California at Berkeley) 1990 A dissertation submitted in partial satisfaction
Storage Hierarchy Management for Scientific Computing by Ethan Leo Miller Sc. B. (Brown University) 1987 M.S. (University of California at Berkeley) 1990 A dissertation submitted in partial satisfaction
Issues In Implementing The Primal-Dual Method for SDP. Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM
 Issues In Implementing The Primal-Dual Method for SDP Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM 87801 borchers@nmt.edu Outline 1. Cache and shared memory parallel computing concepts.
Issues In Implementing The Primal-Dual Method for SDP Brian Borchers Department of Mathematics New Mexico Tech Socorro, NM 87801 borchers@nmt.edu Outline 1. Cache and shared memory parallel computing concepts.
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
NUMA replicated pagecache for Linux
 NUMA replicated pagecache for Linux Nick Piggin SuSE Labs January 27, 2008 0-0 Talk outline I will cover the following areas: Give some NUMA background information Introduce some of Linux s NUMA optimisations
NUMA replicated pagecache for Linux Nick Piggin SuSE Labs January 27, 2008 0-0 Talk outline I will cover the following areas: Give some NUMA background information Introduce some of Linux s NUMA optimisations
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Performance of Multicore LUP Decomposition
 Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection
 An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
An Evaluation of an Energy Efficient Many-Core SoC with Parallelized Face Detection Hiroyuki Usui, Jun Tanabe, Toru Sano, Hui Xu, and Takashi Miyamori Toshiba Corporation, Kawasaki, Japan Copyright 2013,
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Algorithms and Architecture. William D. Gropp Mathematics and Computer Science
 Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
CSE 160 Lecture 10. Instruction level parallelism (ILP) Vectorization
 Vectorization") CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Progress Report on QDP-JIT
 Progress Report on QDP-JIT F. T. Winter Thomas Jefferson National Accelerator Facility USQCD Software Meeting 14 April 16-17, 14 at Jefferson Lab F. Winter (Jefferson Lab) QDP-JIT USQCD-Software 14 1 /
Progress Report on QDP-JIT F. T. Winter Thomas Jefferson National Accelerator Facility USQCD Software Meeting 14 April 16-17, 14 at Jefferson Lab F. Winter (Jefferson Lab) QDP-JIT USQCD-Software 14 1 /
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Case study: OpenMP-parallel sparse matrix-vector multiplication
 Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
A Matrix--Matrix Multiplication methodology for single/multi-core architectures using SIMD
 A Matrix--Matrix Multiplication methodology for single/multi-core architectures using SIMD KELEFOURAS, Vasileios , KRITIKAKOU, Angeliki and GOUTIS, Costas Available
A Matrix--Matrix Multiplication methodology for single/multi-core architectures using SIMD KELEFOURAS, Vasileios , KRITIKAKOU, Angeliki and GOUTIS, Costas Available
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Maximizing Memory Performance for ANSYS Simulations
 Maximizing Memory Performance for ANSYS Simulations By Alex Pickard, 2018-11-19 Memory or RAM is an important aspect of configuring computers for high performance computing (HPC) simulation work. The performance
Maximizing Memory Performance for ANSYS Simulations By Alex Pickard, 2018-11-19 Memory or RAM is an important aspect of configuring computers for high performance computing (HPC) simulation work. The performance
A common scenario... Most of us have probably been here. Where did my performance go? It disappeared into overheads...
 OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
OPENMP PERFORMANCE 2 A common scenario... So I wrote my OpenMP program, and I checked it gave the right answers, so I ran some timing tests, and the speedup was, well, a bit disappointing really. Now what?.
Intel Parallel Studio XE 2015
 2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
2015 Create faster code faster with this comprehensive parallel software development suite. Faster code: Boost applications performance that scales on today s and next-gen processors Create code faster:
GAIL The Graph Algorithm Iron Law
 GAIL The Graph Algorithm Iron Law Scott Beamer, Krste Asanović, David Patterson GAP Berkeley Electrical Engineering & Computer Sciences gap.cs.berkeley.edu Graph Applications Social Network Analysis Recommendations
GAIL The Graph Algorithm Iron Law Scott Beamer, Krste Asanović, David Patterson GAP Berkeley Electrical Engineering & Computer Sciences gap.cs.berkeley.edu Graph Applications Social Network Analysis Recommendations
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature. Intel Software Developer Conference London, 2017
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
COMP Parallel Computing. SMM (1) Memory Hierarchies and Shared Memory
 Memory Hierarchies and Shared Memory") COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
OpenMP for next generation heterogeneous clusters
 OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
Modern CPU Architectures
 Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Scalability and Classifications
 Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
Scalability and Classifications 1 Types of Parallel Computers MIMD and SIMD classifications shared and distributed memory multicomputers distributed shared memory computers 2 Network Topologies static
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
LogCA: A High-Level Performance Model for Hardware Accelerators
 Everything should be made as simple as possible, but not simpler Albert Einstein LogCA: A High-Level Performance Model for Hardware Accelerators Muhammad Shoaib Bin Altaf* David A. Wood University of Wisconsin-Madison
Everything should be made as simple as possible, but not simpler Albert Einstein LogCA: A High-Level Performance Model for Hardware Accelerators Muhammad Shoaib Bin Altaf* David A. Wood University of Wisconsin-Madison
Storage I/O Summary. Lecture 16: Multimedia and DSP Architectures
 Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Lecture 2: Single processor architecture and memory
 Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters
 InfiniBand Clusters") Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Designing Optimized MPI Broadcast and Allreduce for Many Integrated Core (MIC) InfiniBand Clusters K. Kandalla, A. Venkatesh, K. Hamidouche, S. Potluri, D. Bureddy and D. K. Panda Presented by Dr. Xiaoyi
Why Multiprocessors?
 Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Optimizing Fusion PIC Code XGC1 Performance on Cori Phase 2
 Optimizing Fusion PIC Code XGC1 Performance on Cori Phase 2 T. Koskela, J. Deslippe NERSC / LBNL tkoskela@lbl.gov June 23, 2017-1 - Thank you to all collaborators! LBNL Brian Friesen, Ankit Bhagatwala,
Optimizing Fusion PIC Code XGC1 Performance on Cori Phase 2 T. Koskela, J. Deslippe NERSC / LBNL tkoskela@lbl.gov June 23, 2017-1 - Thank you to all collaborators! LBNL Brian Friesen, Ankit Bhagatwala,
Using a Scalable Parallel 2D FFT for Image Enhancement
 Introduction Using a Scalable Parallel 2D FFT for Image Enhancement Yaniv Sapir Adapteva, Inc. Email: yaniv@adapteva.com Frequency domain operations on spatial or time data are often used as a means for
Introduction Using a Scalable Parallel 2D FFT for Image Enhancement Yaniv Sapir Adapteva, Inc. Email: yaniv@adapteva.com Frequency domain operations on spatial or time data are often used as a means for
The ECM (Execution-Cache-Memory) Performance Model
 Performance Model") The ECM (Execution-Cache-Memory) Performance Model J. Treibig and G. Hager: Introducing a Performance Model for Bandwidth-Limited Loop Kernels. Proceedings of the Workshop Memory issues on Multi- and Manycore
The ECM (Execution-Cache-Memory) Performance Model J. Treibig and G. Hager: Introducing a Performance Model for Bandwidth-Limited Loop Kernels. Proceedings of the Workshop Memory issues on Multi- and Manycore
Introduction to Runtime Systems
 Introduction to Runtime Systems Towards Portability of Performance ST RM Static Optimizations Runtime Methods Team Storm Olivier Aumage Inria LaBRI, in cooperation with La Maison de la Simulation Contents
Introduction to Runtime Systems Towards Portability of Performance ST RM Static Optimizations Runtime Methods Team Storm Olivier Aumage Inria LaBRI, in cooperation with La Maison de la Simulation Contents
Accelerating String Matching Algorithms on Multicore Processors Cheng-Hung Lin
 Accelerating String Matching Algorithms on Multicore Processors Cheng-Hung Lin Department of Electrical Engineering, National Taiwan Normal University, Taipei, Taiwan Abstract String matching is the most
Accelerating String Matching Algorithms on Multicore Processors Cheng-Hung Lin Department of Electrical Engineering, National Taiwan Normal University, Taipei, Taiwan Abstract String matching is the most
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture
 Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Double Rewards of Porting Scientific Applications to the Intel MIC Architecture Troy A. Porter Hansen Experimental Physics Laboratory and Kavli Institute for Particle Astrophysics and Cosmology Stanford
Optimising for the p690 memory system
 Optimising for the p690 memory Introduction As with all performance optimisation it is important to understand what is limiting the performance of a code. The Power4 is a very powerful micro-processor
Optimising for the p690 memory Introduction As with all performance optimisation it is important to understand what is limiting the performance of a code. The Power4 is a very powerful micro-processor
Introduction to Parallel Computing
 Introduction to Parallel Computing W. P. Petersen Seminar for Applied Mathematics Department of Mathematics, ETHZ, Zurich wpp@math. ethz.ch P. Arbenz Institute for Scientific Computing Department Informatik,
Introduction to Parallel Computing W. P. Petersen Seminar for Applied Mathematics Department of Mathematics, ETHZ, Zurich wpp@math. ethz.ch P. Arbenz Institute for Scientific Computing Department Informatik,
Day 6: Optimization on Parallel Intel Architectures
 Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
Sorting. Overview. External sorting. Warm up: in memory sorting. Purpose. Overview. Sort benchmarks
 15-823 Advanced Topics in Database Systems Performance Sorting Shimin Chen School of Computer Science Carnegie Mellon University 22 March 2001 Sort benchmarks A base case: AlphaSort Improving Sort Performance
15-823 Advanced Topics in Database Systems Performance Sorting Shimin Chen School of Computer Science Carnegie Mellon University 22 March 2001 Sort benchmarks A base case: AlphaSort Improving Sort Performance
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
ESPRESO ExaScale PaRallel FETI Solver. Hybrid FETI Solver Report
 ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
Introduction to MPI. May 20, Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign
 Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s