An Adaptive Framework for Scientific Software Libraries. Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston
|
|
|
- Angelina Snow
- 6 years ago
- Views:
Transcription
1 An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston

 Wide range of application needs Dimensionality and sizes")
2 Diversity of execution environments Growing complexity of modern microprocessors. Deep memory hierarchies Out-of-order execution Instruction level parallelism Growing diversity of platform characteristics Multicores SMPs Clusters (employing a range of interconnect technologies) Grids (heterogeneity, wide range of characteristics) Wide range of application needs Dimensionality and sizes Data structures and data types Challenges
3 Approach Automatic algorithm selection polyalgorithmic functions Code generation from high-level descriptions Extensive application independent compile-time analysis Integrated performance modeling and analysis Run-time application and execution environment dependent composition Automated installation process
4 Discrete Fourier Transform (DFT) DFT Algorithm is a Matrix Vector multiplication 2 ( n ) y N 1 jk j N. xk k 0 DFT of size N=4 Y w w w 1 w 1 1 w w w w X N N e 2 i N i cos( 2 ).sin( 2 N N)
5 FFT There is a faster algorithm called Fast Fourier Transform (FFT) by Cooley Tukey Algorithm (1965) ( N log N) n F ( F I ). T.( I F ). P n N r m m r m r y x0 1 y x y x y x3 N m r 4 2 2
6 Some common factorizations Cooley Tukey Factorization: Radix 2 Radix 4 Radix 8 Mixed Radix Split Radix Prime Factor Rader s 5N logn 4.25N log 4.08Nlog N N ( Nlog N) 4Nlog N when N m r n F ( F I ). T.( I F ). P when N 2 i when gcd( m, r) 1 when N prime n N r m m r m r N F ( F I ). T.( I F ). P N F P( F F ) P N N N N N N N 2 r m 1 Saving N No Twiddle Multiplication No Bit-Reversal Needed F Q.(1 F ). B. D.(1 F ). Q, T T N 1 Nr N 1 N 1 N, r
7 Op-Counts Effect of Algorithm Selection on Op-Count. Factorizations
8 Size 16 implementation options (8) MFLOPS Codelet is-os Plan
9 Some size 2520 options "MFLOPS" Plan


10 Impact of strides Intel PIV 1.8 GHz AMD Athlon 1.4 GHz PowerPC G4 867 MHz

11 UHFFT Codelet Performance 64-bit Architectures

12 UHFFT Codelet Performance 64-bit Architectures

13 UHFFT Codelet Performance 64-bit Architectures
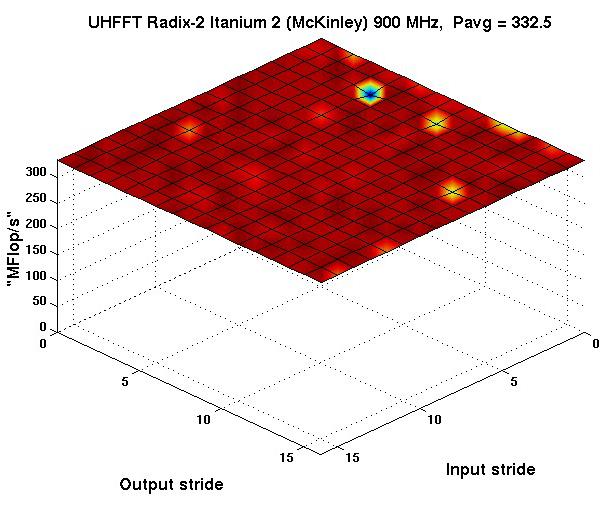

14 Codelet Performance Radix-2

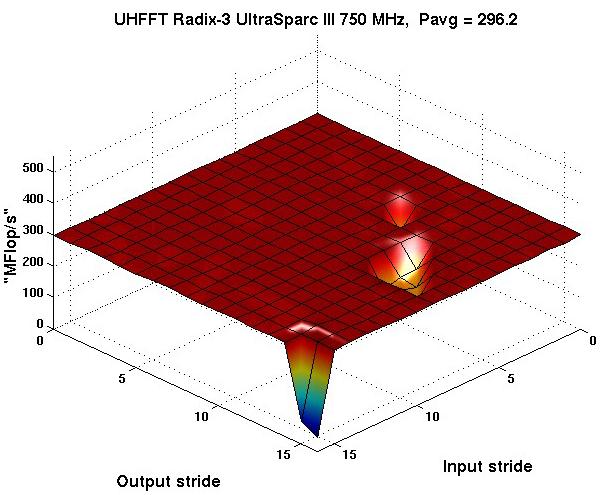
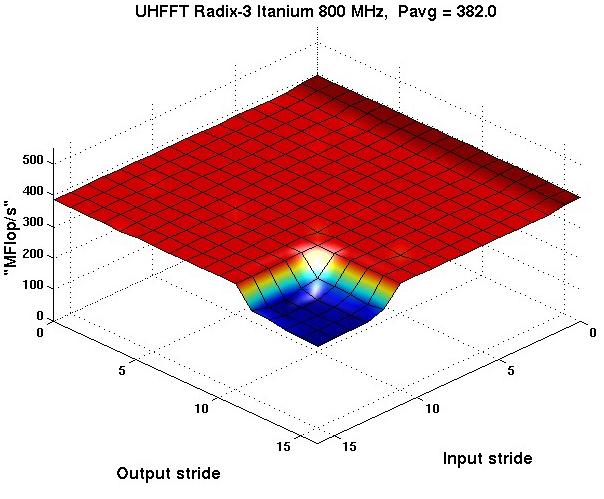
15 Codelet Performance Radix-3



16 Codelet Performance Radix-4

17 Codelet Performance Radix-5

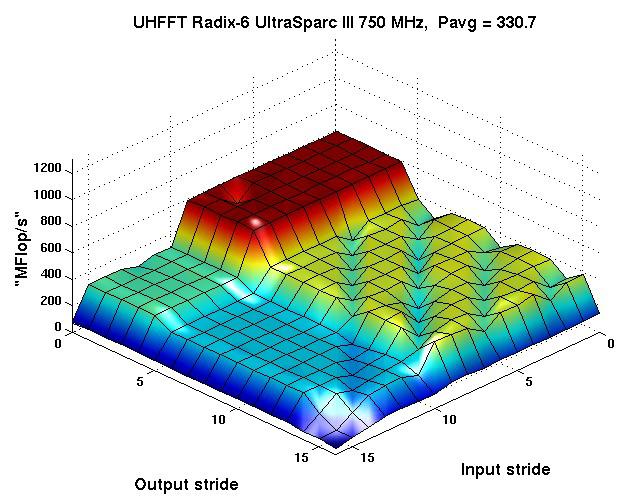
18 Codelet Performance Radix-6
19 Codelet Performance Radix-7

20 Codelet Performance Radix-8


21 Codelet Performance Radix-32


22 Codelet Performance Radix-45
23 Codelet Performance Radix-64
24 Challenges Algorithmic Unfavorable data access pattern (big 2 n strides) High efficiency of the algorithm low floating-point v.s. load/store ratio Additions/multiplications unbalance Version explosion Verification Maintenance
25 UHFFT- An Adaptive, Portable Library Auto-tuning performed in two stages. At Installation Time: Codelet Generator adapts to the Microprocessor Architecture by optimizing to reduce operation count and register reuse distance. At Run Time: Planner adapts to the Memory System by searching for the best combination of codelets (schedule) to solve given FFT Problem. The plan/schedule can be repeatedly used for same size transform.

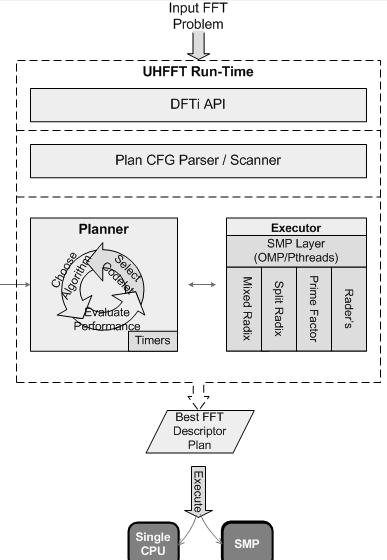
26 UHFFT structure
27 UHFFT2.0 Code Generator: Support multiple Codelet types. Finer Scheduling through DAG. Register Blocking and Privatization. Run-time Optimization: Prime Size Support (Rader s Algorithm). Plan Search Schemes (Planner). API Standardization (Intel s DFT with Parallel extensions). Support for both In-place and Out-of-place Transforms. Formal description of FFT Plans or Schedules. Parallelization Multi-core/Many Core
28 Code Generator Four main Codelet Types dyvmc* dynmc* dxvmc* (inplace) dyvpc (PFA) *Four sub-types Forward/inverse Twiddle/non-twiddle

29 Empirical Auto-tuning
30 How many codelets to generate? Itanium has more registers Opteron has larger instruction cache
31 Opteron Codelet 3 (is=os) Stride MFLOPS UHFFT FFTW TWUHFFT Codelet 4 (is=os) Stride MFLOPS UHFFT FFTW TWUHFFT Codelet 8 (is=os) Stride MFLOPS UHFFT FFTW TWUHFFT Codelet 7 (is=os) Stride MFLOPS UHFFT FFTW TWUHFFT Codelet 16 (is=os) Stride MFLOPS UHFFT FFTW TWUHFFT Codelet 64 (is=os) Stride MFLOPS UHFFT FFTW TWUHFFT
32 Itanium2 Codelet 3 (is=os) Stride MFLOPS UHFFT2.0 FFTW FFTW_old UHFFT162 Codelet 4 (is=os) Stride MFLOPS UHFFT2.0 FFTW FFTW_old UHFFT162 Codelet 7 (is=os) Stride MFLOPS UHFFT2.0 FFTW FFTW_old UHFFT162 Codelet 8 (is=os) Stride MFLOPS UHFFT2.0 FFTW FFTW_old UHFFT162 Codelet 16 (is=os) Stride MFLOPS UHFFT2.0 FFTW FFTW_old UHFFT162 Codelet 64 (is=os) Stride MFLOPS UHFFT2.0 FFTW FFTW_old UHFFT162
33 Planner Search for the best factors and algorithms to solve a given FFT problem. Main Parameters of Search: Factors and Algorithms at each level of tree (Op-count and Locality) Parallelization (Load Balance) Cost of Search: Search cost amortizes (especially in multidimensional FFTs). Support for multiple search schemes with varying costs (high/medium/low). Empirical Search. Hybrid (Empirical/Estimation) Search. High Resolution Timers are important.
34 Planner
35 FFT Schedule Specification Language (FSSL) FSSL GRAMMAR UHFFT provides an expert user the flexibility to specify the schedule using its CFG.
36 FFT Schedule Specification Language (FSSL) Example Schedule: (outplace1020, (rader17,16)mr (inplace60,2mr(pfa15,3pfa5)mr2) )

37 Parallelization Example N 16 m 4, r 4 P 4
38 Parallelization Transpose Step (Barrier) Data sharing among processors takes place Example N 16 m 4, r 4 P 4 Step1 r Row FFTs of Size m distributed among P processors Step3 m Column FFTs of radix r distributed among p processors
39 Data Distribution (SMP/CMP) Row FFTs Example N 16 m 4, r 4 P Column FFTs
40 Data Distribution (SMP/CMP) Large block size ~ Less cache coherence issues. N 64K ( mrp2b8:$ Col, ( outplace65536, 16mr16mr16mr16 ) )65536
41 OpenMP vs PThreads Generated plan is load balanced by planner. Distributing loops is straightforward.
42 Speedup FFT is bandwidth starved. Super linear Speedup due to increase in effective cache size. Synchronization to Computation ratio is high

43 CPU Affinity (Multi-cores) Scheduling Problem / Cache conflicts in shared cache
44 UHFFT2.0.1beta vs FFTW3.2alpha2
45 UHFFT2.0.1beta vs FFTW3.2alpha2
46 In-place In-order FFT Performance Powers of two sizes.
47 In-place In-order FFT Performance Prime Factor Sizes.
48 UHFFT2 Current Status 1D Complex Out-of-place/In-place in-order Forward scrambled (Out-of-place/In-place) Forward/Inverse (Configurable Sign) High, Medium and Low Effort Plan Search Single/Double Precision SMP/CMP Executor (DFTi Extension) Empirical Auto-tuning code generator. Executor Extendibility through FSSL Grammar. Real FFT (not-integrated)
49 Executor: Multidimensional MPI Planner: Future Work Accurate Model Driven Plan Search Scheme. Economical (time and memory). Schedule memory transactions through pre-fetching. Code Generator: ISA specific codelet generation (e.g. sse, fma etc.). Generate codelet cost models.
50 Acknowledgements The SGAS work largely carried out by Thomas Sandholm. Other contributors: Olle Mulmo, Peter Gardfjall, Erik Elmroth, Bo Kagstrom The FFT work: Ayaz Ali, Fredrik Mwandia, Rishad Mahasoom, Dragan Mirkovic, Purvi Shah, Haiyan Teng Support: NSF and Intel
51 Thank You!
52 End of Moore s Law? Can not keep up with the power requirements! Source: Unknown
53 10000??%/year Performance (vs. VAX-11/780) %/year 52%/year VAX : 25%/year 1978 to 1986 RISC + x86: 52%/year 1986 to 2002 RISC + x86:??%/year 2002 to present
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Advanced Computing Research Laboratory. Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Scheduling FFT Computation on SMP and Multicore Systems
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali Dept. of Computer Science University of Houston Houston, TX 77, USA ayaz@cs.uh.edu Lennart Johnsson Dept. of Computer Science University
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali Dept. of Computer Science University of Houston Houston, TX 77, USA ayaz@cs.uh.edu Lennart Johnsson Dept. of Computer Science University
Input parameters System specifics, user options. Input parameters size, dim,... FFT Code Generator. Initialization Select fastest execution plan
 Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Introduction to HPC. Lecture 21
 443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed
443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed
Grid Computing: Application Development
 Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis
Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms
 Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine. David A. Bader, Virat Agarwal
 FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine David A. Bader, Virat Agarwal Cell System Features Heterogeneous multi-core system architecture Power Processor Element for control tasks
FFTC: Fastest Fourier Transform on the IBM Cell Broadband Engine David A. Bader, Virat Agarwal Cell System Features Heterogeneous multi-core system architecture Power Processor Element for control tasks
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Formal Loop Merging for Signal Transforms
 Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
The Fastest Fourier Transform in the West
 : The Fastest Fourier Transform in the West Steven G. ohnson, MIT Applied Mathematics Matteo Frigo, Cilk Arts Inc. In the beginning (c. 1805): Carl Friedrich Gauss declination angle ( ) 30 25 20 15 10
: The Fastest Fourier Transform in the West Steven G. ohnson, MIT Applied Mathematics Matteo Frigo, Cilk Arts Inc. In the beginning (c. 1805): Carl Friedrich Gauss declination angle ( ) 30 25 20 15 10
Why Multiprocessors?
 Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
Why Multiprocessors? Motivation: Go beyond the performance offered by a single processor Without requiring specialized processors Without the complexity of too much multiple issue Opportunity: Software
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
IMPLEMENTATION OF THE. Alexander J. Yee University of Illinois Urbana-Champaign
 SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
Research in High-Performance Grid Software
 Research in High-Performance Grid Software Lennart Johnsson NADA, KTH and Department of Computer Science University of Houston EU Project: Neurogenerator Collection and processing of PET and fmri data
Research in High-Performance Grid Software Lennart Johnsson NADA, KTH and Department of Computer Science University of Houston EU Project: Neurogenerator Collection and processing of PET and fmri data
SPIRAL Generated Modular FFTs *
 SPIRAL Generated Modular FFTs * Jeremy Johnson Lingchuan Meng Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for SPIRAL overview provided by Franz Francheti, Yevgen Voronenko,,
SPIRAL Generated Modular FFTs * Jeremy Johnson Lingchuan Meng Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for SPIRAL overview provided by Franz Francheti, Yevgen Voronenko,,
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
The Design and Implementation of FFTW3
 The Design and Implementation of FFTW3 MATTEO FRIGO AND STEVEN G. JOHNSON Invited Paper FFTW is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize
The Design and Implementation of FFTW3 MATTEO FRIGO AND STEVEN G. JOHNSON Invited Paper FFTW is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Energy Optimizations for FPGA-based 2-D FFT Architecture
 Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
A Hybrid GPU/CPU FFT Library for Large FFT Problems
 A Hybrid GPU/CPU FFT Library for Large FFT Problems Shuo Chen Dept. of Electrical and Computer Engineering University of Delaware Newark, DE 19716 schen@udel.edu Abstract Graphic Processing Units (GPU)
A Hybrid GPU/CPU FFT Library for Large FFT Problems Shuo Chen Dept. of Electrical and Computer Engineering University of Delaware Newark, DE 19716 schen@udel.edu Abstract Graphic Processing Units (GPU)
Grid Application Development Software
 Grid Application Development Software Department of Computer Science University of Houston, Houston, Texas GrADS Vision Goals Approach Status http://www.hipersoft.cs.rice.edu/grads GrADS Team (PIs) Ken
Grid Application Development Software Department of Computer Science University of Houston, Houston, Texas GrADS Vision Goals Approach Status http://www.hipersoft.cs.rice.edu/grads GrADS Team (PIs) Ken
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Effect of memory latency
 CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries
 System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Parallel FFT Libraries
 Parallel FFT Libraries Evangelos Brachos August 19, 2011 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2011 Abstract The focus of this project is the area of the fast
Parallel FFT Libraries Evangelos Brachos August 19, 2011 MSc in High Performance Computing The University of Edinburgh Year of Presentation: 2011 Abstract The focus of this project is the area of the fast
Advanced School in High Performance and GRID Computing November Mathematical Libraries. Part I
 1967-10 Advanced School in High Performance and GRID Computing 3-14 November 2008 Mathematical Libraries. Part I KOHLMEYER Axel University of Pennsylvania Department of Chemistry 231 South 34th Street
1967-10 Advanced School in High Performance and GRID Computing 3-14 November 2008 Mathematical Libraries. Part I KOHLMEYER Axel University of Pennsylvania Department of Chemistry 231 South 34th Street
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Susumu Yamamoto. Tokyo, , JAPAN. Fourier Transform (DFT), and the calculation time is in proportion to N logn,
, and the calculation time is in proportion to N logn,") Effective Implementations of Multi-Dimensional Radix-2 FFT Susumu Yamamoto Department of Applied Physics, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo, 113-8656, JAPAN Abstract The Fast Fourier Transform
Effective Implementations of Multi-Dimensional Radix-2 FFT Susumu Yamamoto Department of Applied Physics, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo, 113-8656, JAPAN Abstract The Fast Fourier Transform
Adaptive Transpose Algorithms for Distributed Multicore Processors
 Adaptive Transpose Algorithms for Distributed Multicore Processors John C. Bowman and Malcolm Roberts University of Alberta and Université de Strasbourg April 15, 2016 www.math.ualberta.ca/ bowman/talks
Adaptive Transpose Algorithms for Distributed Multicore Processors John C. Bowman and Malcolm Roberts University of Alberta and Université de Strasbourg April 15, 2016 www.math.ualberta.ca/ bowman/talks
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
FFT. There are many ways to decompose an FFT [Rabiner and Gold] The simplest ones are radix-2 Computation made up of radix-2 butterflies X = A + BW
![FFT. There are many ways to decompose an FFT [Rabiner and Gold] The simplest ones are radix-2 Computation made up of radix-2 butterflies X = A + BW](/thumbs/84/90604577.jpg "FFT. There are many ways to decompose an FFT [Rabiner and Gold] The simplest ones are radix-2 Computation made up of radix-2 butterflies X = A + BW") FFT There are many ways to decompose an FFT [Rabiner and Gold] The simplest ones are radix-2 Computation made up of radix-2 butterflies A X = A + BW B Y = A BW B. Baas 442 FFT Dataflow Diagram Dataflow
FFT There are many ways to decompose an FFT [Rabiner and Gold] The simplest ones are radix-2 Computation made up of radix-2 butterflies A X = A + BW B Y = A BW B. Baas 442 FFT Dataflow Diagram Dataflow
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
FFTSS Library Version 3.0 User s Guide
 Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO
 F. Bodin, CTO") How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
How to Write Fast Numerical Code Spring 2011 Lecture 22. Instructor: Markus Püschel TA: Georg Ofenbeck
 How to Write Fast Numerical Code Spring 2011 Lecture 22 Instructor: Markus Püschel TA: Georg Ofenbeck Schedule Today Lecture Project presentations 10 minutes each random order random speaker 10 Final code
How to Write Fast Numerical Code Spring 2011 Lecture 22 Instructor: Markus Püschel TA: Georg Ofenbeck Schedule Today Lecture Project presentations 10 minutes each random order random speaker 10 Final code
A Matrix--Matrix Multiplication methodology for single/multi-core architectures using SIMD
 A Matrix--Matrix Multiplication methodology for single/multi-core architectures using SIMD KELEFOURAS, Vasileios , KRITIKAKOU, Angeliki and GOUTIS, Costas Available
A Matrix--Matrix Multiplication methodology for single/multi-core architectures using SIMD KELEFOURAS, Vasileios , KRITIKAKOU, Angeliki and GOUTIS, Costas Available
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads
 A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads Sardar Anisul Haque Marc Moreno Maza Ning Xie University of Western Ontario, Canada IBM CASCON, November 4, 2014 ardar
A Many-Core Machine Model for Designing Algorithms with Minimum Parallelism Overheads Sardar Anisul Haque Marc Moreno Maza Ning Xie University of Western Ontario, Canada IBM CASCON, November 4, 2014 ardar
Objective. We will study software systems that permit applications programs to exploit the power of modern high-performance computers.
 CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
c 2013 Alexander Jih-Hing Yee
 c 2013 Alexander Jih-Hing Yee A FASTER FFT IN THE MID-WEST BY ALEXANDER JIH-HING YEE THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science
c 2013 Alexander Jih-Hing Yee A FASTER FFT IN THE MID-WEST BY ALEXANDER JIH-HING YEE THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science
Automatic Generation of the HPC Challenge's Global FFT Benchmark for BlueGene/P
 Automatic Generation of the HPC Challenge's Global FFT Benchmark for BlueGene/P Franz Franchetti 1, Yevgen Voronenko 2, Gheorghe Almasi 3 1 University and SpiralGen, Inc. 2 AccuRay, Inc., 3 IBM Research
Automatic Generation of the HPC Challenge's Global FFT Benchmark for BlueGene/P Franz Franchetti 1, Yevgen Voronenko 2, Gheorghe Almasi 3 1 University and SpiralGen, Inc. 2 AccuRay, Inc., 3 IBM Research
Outline. Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities
 Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Alternate definition: Instruction Set Architecture (ISA) What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model
 What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model") What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Design Principles for End-to-End Multicore Schedulers
 c Systems Group Department of Computer Science ETH Zürich HotPar 10 Design Principles for End-to-End Multicore Schedulers Simon Peter Adrian Schüpbach Paul Barham Andrew Baumann Rebecca Isaacs Tim Harris
c Systems Group Department of Computer Science ETH Zürich HotPar 10 Design Principles for End-to-End Multicore Schedulers Simon Peter Adrian Schüpbach Paul Barham Andrew Baumann Rebecca Isaacs Tim Harris
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Lecture 3: Intro to parallel machines and models
 Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Parallelization. Saman Amarasinghe. Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Using recursion to improve performance of dense linear algebra software. Erik Elmroth Dept of Computing Science & HPC2N Umeå University, Sweden
 Using recursion to improve performance of dense linear algebra software Erik Elmroth Dept of Computing Science & HPCN Umeå University, Sweden Joint work with Fred Gustavson, Isak Jonsson & Bo Kågström
Using recursion to improve performance of dense linear algebra software Erik Elmroth Dept of Computing Science & HPCN Umeå University, Sweden Joint work with Fred Gustavson, Isak Jonsson & Bo Kågström
Generating Parallel Transforms Using Spiral
 Generating Parallel Transforms Using Spiral Franz Franchetti Yevgen Voronenko Markus Püschel Part of the Spiral Team Electrical and Computer Engineering Carnegie Mellon University Sponsors: DARPA DESA
Generating Parallel Transforms Using Spiral Franz Franchetti Yevgen Voronenko Markus Püschel Part of the Spiral Team Electrical and Computer Engineering Carnegie Mellon University Sponsors: DARPA DESA
I. INTRODUCTION FACTORS RELATED TO PERFORMANCE ANALYSIS
 Performance Analysis of Java NativeThread and NativePthread on Win32 Platform Bala Dhandayuthapani Veerasamy Research Scholar Manonmaniam Sundaranar University Tirunelveli, Tamilnadu, India dhanssoft@gmail.com
Performance Analysis of Java NativeThread and NativePthread on Win32 Platform Bala Dhandayuthapani Veerasamy Research Scholar Manonmaniam Sundaranar University Tirunelveli, Tamilnadu, India dhanssoft@gmail.com
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
How to Write Fast Numerical Code Spring 2012 Lecture 20. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 20 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Planning Today Lecture Project meetings Project presentations 10 minutes each
How to Write Fast Numerical Code Spring 2012 Lecture 20 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato Planning Today Lecture Project meetings Project presentations 10 minutes each
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Accelerating the Fast Fourier Transform using Mixed Precision on Tensor Core Hardware
 NSF REU - 2018: Project Report Accelerating the Fast Fourier Transform using Mixed Precision on Tensor Core Hardware Anumeena Sorna Electronics and Communciation Engineering National Institute of Technology,
NSF REU - 2018: Project Report Accelerating the Fast Fourier Transform using Mixed Precision on Tensor Core Hardware Anumeena Sorna Electronics and Communciation Engineering National Institute of Technology,
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
A SEARCH OPTIMIZATION IN FFTW. by Liang Gu
 A SEARCH OPTIMIZATION IN FFTW by Liang Gu A thesis submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Master of Science in Electrical and
A SEARCH OPTIMIZATION IN FFTW by Liang Gu A thesis submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Master of Science in Electrical and
Specializing Code for FFT Libraries. Minhaj Ahmad Khan Henri Pierre Charles University of Versailles Saint-Quentin-en-Yvelines, France
 Specializing Code for FFT Libraries Minhaj Ahmad Khan Henri Pierre Charles University of Versailles Saint-Quentin-en-Yvelines, France Outline Specialization Issues for FFT Libraries Limited Code Specialization
Specializing Code for FFT Libraries Minhaj Ahmad Khan Henri Pierre Charles University of Versailles Saint-Quentin-en-Yvelines, France Outline Specialization Issues for FFT Libraries Limited Code Specialization
Intel Math Kernel Library
 Intel Math Kernel Library Release 7.0 March 2005 Intel MKL Purpose Performance, performance, performance! Intel s scientific and engineering floating point math library Initially only basic linear algebra
Intel Math Kernel Library Release 7.0 March 2005 Intel MKL Purpose Performance, performance, performance! Intel s scientific and engineering floating point math library Initially only basic linear algebra
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
An Efficient Architecture for Ultra Long FFTs in FPGAs and ASICs
 An Efficient Architecture for Ultra Long FFTs in FPGAs and ASICs Architecture optimized for Fast Ultra Long FFTs Parallel FFT structure reduces external memory bandwidth requirements Lengths from 32K to
An Efficient Architecture for Ultra Long FFTs in FPGAs and ASICs Architecture optimized for Fast Ultra Long FFTs Parallel FFT structure reduces external memory bandwidth requirements Lengths from 32K to
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Optimizing FFT, FFTW Instructor: Markus Püschel TA: Georg Ofenbeck & Daniele Spampinato Rest of Semester Today Lecture Project meetings Project presentations 10
How to Write Fast Numerical Code Lecture: Optimizing FFT, FFTW Instructor: Markus Püschel TA: Georg Ofenbeck & Daniele Spampinato Rest of Semester Today Lecture Project meetings Project presentations 10
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Adaptive Matrix Transpose Algorithms for Distributed Multicore Processors
 Adaptive Matrix Transpose Algorithms for Distributed Multicore ors John C. Bowman and Malcolm Roberts Abstract An adaptive parallel matrix transpose algorithm optimized for distributed multicore architectures
Adaptive Matrix Transpose Algorithms for Distributed Multicore ors John C. Bowman and Malcolm Roberts Abstract An adaptive parallel matrix transpose algorithm optimized for distributed multicore architectures
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Small Discrete Fourier Transforms on GPUs
 Small Discrete Fourier Transforms on GPUs S. Mitra and A. Srinivasan Dept. of Computer Science, Florida State University, Tallahassee, FL 32306, USA {mitra,asriniva}@cs.fsu.edu Abstract Efficient implementations
Small Discrete Fourier Transforms on GPUs S. Mitra and A. Srinivasan Dept. of Computer Science, Florida State University, Tallahassee, FL 32306, USA {mitra,asriniva}@cs.fsu.edu Abstract Efficient implementations
Optimizing the Fast Fourier Transform on a Multi-core Architecture
 Optimizing the Fast Fourier Transform on a Multi-core Architecture Long Chen 1,ZiangHu 1, Junmin Lin 2, Guang R. Gao 1 1 University of Delaware 2 Tsinghua University Dept. of Electrical & Computer Engineering
Optimizing the Fast Fourier Transform on a Multi-core Architecture Long Chen 1,ZiangHu 1, Junmin Lin 2, Guang R. Gao 1 1 University of Delaware 2 Tsinghua University Dept. of Electrical & Computer Engineering
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
3.2 Cache Oblivious Algorithms
 3.2 Cache Oblivious Algorithms Cache-Oblivious Algorithms by Matteo Frigo, Charles E. Leiserson, Harald Prokop, and Sridhar Ramachandran. In the 40th Annual Symposium on Foundations of Computer Science,
3.2 Cache Oblivious Algorithms Cache-Oblivious Algorithms by Matteo Frigo, Charles E. Leiserson, Harald Prokop, and Sridhar Ramachandran. In the 40th Annual Symposium on Foundations of Computer Science,
Fitting FFT onto the G80 Architecture
 Fitting FFT onto the G80 Architecture Vasily Volkov Brian Kazian University of California, Berkeley May 9, 2008. Abstract In this work we present a novel implementation of FFT on GeForce 8800GTX that achieves
Fitting FFT onto the G80 Architecture Vasily Volkov Brian Kazian University of California, Berkeley May 9, 2008. Abstract In this work we present a novel implementation of FFT on GeForce 8800GTX that achieves
CSE 392/CS 378: High-performance Computing - Principles and Practice
 CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
CSE 392/CS 378: High-performance Computing - Principles and Practice Parallel Computer Architectures A Conceptual Introduction for Software Developers Jim Browne browne@cs.utexas.edu Parallel Computer
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Mixed MPI-OpenMP EUROBEN kernels
 Mixed MPI-OpenMP EUROBEN kernels Filippo Spiga ( on behalf of CINECA ) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany Outline Short kernel description MPI and OpenMP
Mixed MPI-OpenMP EUROBEN kernels Filippo Spiga ( on behalf of CINECA ) PRACE Workshop New Languages & Future Technology Prototypes, March 1-2, LRZ, Germany Outline Short kernel description MPI and OpenMP
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
X-Ray : Automatic Measurement of Hardware Parameters
 X-Ray : Automatic Measurement of Hardware Parameters Kamen Yotov, Keshav Pingali, Paul Stodghill, Department of Computer Science, Cornell University, Ithaca, NY 14853. October 6, 2004 Abstract There is
X-Ray : Automatic Measurement of Hardware Parameters Kamen Yotov, Keshav Pingali, Paul Stodghill, Department of Computer Science, Cornell University, Ithaca, NY 14853. October 6, 2004 Abstract There is
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
In 1986, I had degrees in math and engineering and found I wanted to compute things. What I ve mostly found is that:
 Parallel Computing and Data Locality Gary Howell In 1986, I had degrees in math and engineering and found I wanted to compute things. What I ve mostly found is that: Real estate and efficient computation
Parallel Computing and Data Locality Gary Howell In 1986, I had degrees in math and engineering and found I wanted to compute things. What I ve mostly found is that: Real estate and efficient computation
FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES
 FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES FRANCHETTI Franz, (AUT), KALTENBERGER Florian, (AUT), UEBERHUBER Christoph W. (AUT) Abstract. FFTs are the single most important algorithms in science and
FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES FRANCHETTI Franz, (AUT), KALTENBERGER Florian, (AUT), UEBERHUBER Christoph W. (AUT) Abstract. FFTs are the single most important algorithms in science and
Cache-oblivious Programming
 Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix
Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix