Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms
|
|
|
- Jemima Kennedy
- 6 years ago
- Views:
Transcription

1 Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms Candidate Andrea Spina Advisor Prof. Sonia Bergamaschi Co-Advisor Dr. Tilmann Rabl Co-Advisor Christoph Boden Dipartimento di Ingegneria Enzo Ferrari - Laurea Magistrale di Ingegneria Informatica - MODENA



2 Where, When, How and Why Berlin, DE 5 months Traineeship - MAY - OCT 16 Database Systems and Information Management Group, Technische Universität Team Project - Systems Performance Research Unit 2
3 Agenda Background Experiments Definition Benchmarking and Results Analysis Insights by Results Agenda 3

4 Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms Background

5 Why Distributed Machine Learning? Mutliple Sources Background MapReduce Iterative Algorithms 5
6 Because represents innovation SOLUTION Mutliple Sources Iterative Algorithms Massive DataFlow Engines Background 6

7 One of the goals - fairness give code open-source keep jobs reproducible make benchmark exhaustive model systems as same as possible Background 7

8 Another Goal - include more and more systems Background 8
9 My Goal - OK, may I start with a couple of those? Background 9
10 Apache Flink vs. Apache Spark Apache Flink Apache Spark THE GOAL - Benchmark on Performance and Scalability Background 10
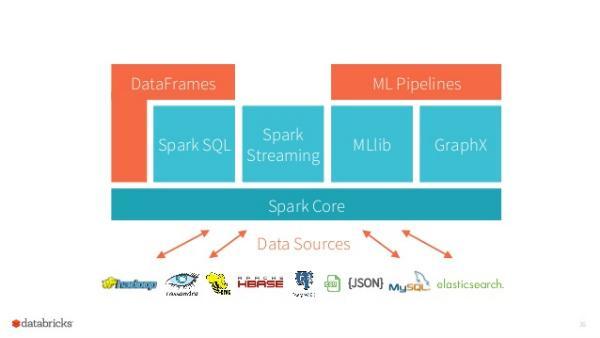

11 Systems similarities - they are stacks Background 11
12 Systems similarities - they do batch and streaming JAVA Background SCALA JAVA SCALA PYTHON R PYTHON 12
13 Systems similarities - they do batch and streaming JAVA Background SCALA JAVA SCALA PYTHON R PYTHON 13
14 Apache Spark vs Apache Flink - differences batch to Streaming streaming to Batch and iterations, memory management, user policies we do batch Background 14


15 Peel Experiment Peel Framework - The Benchmarking Software submits config by dependency injection packages together by peel bundles Background 15
16 Peel execution flow - the suite:run command SETUP SUITE Background 16
17 Peel execution flow - turn on systems SETUP SUITE SETUP EXP SETUP RUN Background EXPERIMENT SCOPE 17
18 Peel execution flow - collect logs and run again SETUP SUITE SETUP EXP EXPERIMENT SCOPE SETUP RUN EXECUTE RUN to next RUN Background TEARDOWN RUN LOGS 18
19 Peel execution flow - turn off systems TEARDOWN SUITE SETUP SUITE SETUP EXP to next EXP TEARDOWN EXP EXPERIMENT SCOPE SETUP RUN EXECUTE RUN to next RUN Background TEARDOWN RUN LOGS 19
20 shee - fast and furios peel data visualization tool built on top of Python, Pandas and matplotlib APIs node - level cluster - level web UI Background 20

21 shee - fast and furios peel data visualization tool built on top of Python, Pandas and matplotlib APIs node - level cluster - level web UI Background 21


22 shee - fast and furios peel data visualization tool built on top of Python, Pandas and matplotlib APIs node - level cluster - level web UI Background 22
23 shee - fast and furios peel data visualization tool built on top of Python, Pandas and matplotlib APIs node - level cluster - level web UI Background 23



24 shee - fast and furios peel data visualization tool built on top of Python, Pandas and matplotlib APIs node - level cluster - level web UI 1 Star Background 48 Commit 1 Fork 3 Contributors 24

25 Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms Defining Experiments

26 The fairness constraint Apache Spark Apache Flink We want the same (as much as possible)... data structures pipeline for solvers operators configuration parameters environment Guaranteed by Peel Defining Experiments 26
27 Experiments Overview - Four applications APPROACH Regression Supervised Learning Not Supervised Learning Recommendation System Multiple Linear Regression Support Vector Machine * KMeans Alternating Least Squares Apache SystemML Apache Spark Apache Spark Apache Flink We want to cover many applications ALGORITHM Choosed by a Tradeoff between complexity and fairness DATA GENERATION Writing Data on-demand by Peel Framework Defining Experiments 27
28 Building the Experiment Pipeline - KMeans Example PREMISE We always evaluate Training Phase Performance Defining Experiments 28
29 Building the KMeans Pipeline - Studying KMEANS clustering find new classes from unlabeled data by grouping ASSIGNMENT ASSIGNMENT STEP re-partition datapoints according to centroids Defining Experiments UPDATE UPDATE STEP retrieve new centroids by datapoints location mean 29


30 Building the KMeans Pipeline - Studying 1. Explore systems machine learning libraries 2. Do research! ML E.g. keeping smarter initial k centroids choice random KMeans ++ KMeans INITIAL CENTROIDS KMEANS ITERATION What do we want to compare? What keeps Systems on Stress! Defining Experiments 30
31 Building the KMeans Pipeline - Data Structures INIT CENTERS DATA EXPERIMENT SCOPE Dataset Point vectors p0 x0 x1 xn-1 p1 x0 x1 xn-1 Init centers (id, vector) c0 id0 x0 x1 xn-1 c1 id1 x0 x1 xn-1 Defining Experiments We need to: We employed: model data Flink Vectors operate on data Spark Vectors Breeze Vectors Scala Arrays 31
32 Building the KMeans Pipeline - KMeans Iteration INIT CENTERS INPUT EXPERIMENT SCOPE CACHING RDD/DataSet DATA ASSIGNMENT STEP UPDATE STEP SPARK Map Function ReduceByKey Map Function Aggregate by AVG Broadcasting Function FLINK RichMapFunction GroupBy Reduce Map Function Aggregate by AVG Broadcasting Function Defining Experiments 32



33 Building the KMeans Pipeline - Materializing INIT CENTERS INPUT EXPERIMENT SCOPE CACHING KMEANS ITERATIONS MODEL RDD/DataSet DATA Model final centers Defining Experiments 33
34 Building the KMeans Pipeline - Validation INIT CENTERS INPUT EXPERIMENT SCOPE CACHING KMEANS ITERATIONS OUTPUT MODEL RDD/DataSet DATA Model Evaluation fairness first convergence of metrics good-enough model then Defining Experiments Evaluation Metrics 34

35 Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms Benchmarking and Results Analysis
![Some general insights TOTAL RUNTIME [h] CLUSTERS DATASETS 200 2 28 WALLY nodes 30](/docs-images/75/72458348/images/36-0.jpg "CPUs/node 8 RAM/node 16GB Storage/no.")

36 Some general insights TOTAL RUNTIME [h] CLUSTERS DATASETS WALLY nodes 30 CPUs/node 8 RAM/node 16GB Storage/no. 3x1TB Eth 1Gbit TUNING FLINK 22% SPARK 30% CLOUD-11 nodes 25 CPUs/node 16 RAM/node 32GB Storage/no. 2x1TB Eth 1Gbit Benchmarking and Results Analysis AVERAGE SIZE 275GB EVALUATIONS strong scale weak scale data scale 36
37 Spark versus Flink Summary 34 RUNTIMEaaaaaaaa WINS Multiple Linear Regression Spark v Flink 8-1 Spark 63% outperforms Flink Flink 74% faster on critic resources FlinkML provides better runtimes KMeans Spark v Flink Support Vector Machine Spark v Flink 16-0 Spark 71% outperforms Flink Flink likes MORE Data Good Scalability Behavior Reccomendation System Similar Performance Flink definitely likes MORE data Flink 11% faster on critic resources Benchmarking and Results Analysis NOT COMPARABLE 37
38 Spark versus Flink Summary 34 RUNTIMEaaaaaaaa WINS Multiple Linear Regression Spark v Flink 8-1 Spark 63% outperforms Flink Flink 74% faster on critic resources FlinkML provides better runtimes KMeans Spark v Flink Support Vector Machine Spark v Flink 16-0 Spark 71% outperforms Flink Flink likes MORE Data Good Scalability Behavior Alternating Least Squares Similar Performance Flink definitely likes MORE data Flink 11% faster on critic resources Benchmarking and Results Analysis NOT COMPARABLE 38
39 KMeans strong scale and scale data 12GB RAM per node 8 core CPU per node Benchmarking and Results Analysis sparsity 0% model size

40 Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms Insights from Executions
41 How should a large-scale processing engine work? CPU user DISK read / write Flink KMeans 30 centroids 5 iterations 1TB data 30 nodes 12GB RAM / node NETWORK send / recv Insights from Executions 41
42 Like This KMeans Experiment! A Step A A: Building Execution Pipeline Reading from Source Map Points to Breeze Insights from Executions 42
43 Step B - The master sends partitions across the cluster B B: Repartition Data Cache Data and spill to Disk First Iteration Execution Insights from Executions 43



44 Regular Iterations Frequency - Step C C C: Next Iterations (2 to 5) Read spilled data Broadcast the model Produce Sink (write to disk) Insights from Executions 44

45 How Spark outperforms Flink - #1 Repartitioning SVM - 6 Nodes - 212GB Dataset - 5 iterations - 30 nodes - 12GB RAM / node Insights from Executions 45
46 #1 Repartitioning - Distributed-to-Distributed Insights from Executions 46
47 #1 Repartitioning - What Spark does Narrow Transformation GOAL - no data movements Insights from Executions 47

48 #1 Repartitioning - What Flink does Narrow Transformation GOAL - no data movements Insights from Executions Shuffling data between nodes 48
49 #1 Repartitioning - Flink Network Overhead Insights from Executions 49
50 Additional Relevants #2 Caching Flink Issue - FLINK Spark - user-defined caching returns faster intra-iteration timing Flink manages caching internally (Bulk Iterations) and it is slower when the data is not Big #3 Broadcasting Flink Improvements Proposal - FLIP-5 oadcasts Flink Broadcast brings communication overhead Anyway it was not critical to this benchmark Insights from Executions 50


51 Benchmarking Apache Flink and Apache Spark DataFlow Systems on Large-Scale Distributed Machine Learning Algorithms Conclusions
52 Main Considerations Currently Spark is the right choice for batch purposes and now Spark 2.0 Flink was born to stream and is growing along streaming need to find a tradeoff Flink put first robustness and availability and it masters join, hashing, grouping Spark put first performance and efficiency Background 52

53 Thank You
54 Media - background image - pag background image - pag spark stack - pag flink stack -pag background image - pag background image - pag background image - pag.61 Media 54

55 Bonus Slides 55
56 Peel Framework Deploy Flow Defining Experiments 56
57 Peel execution flow - the suite:run command SETUP SUITE Background 57
58 Peel execution flow - turn on systems SETUP SUITE SETUP EXP SETUP RUN Background EXPERIMENT SCOPE 58
59 Peel execution flow - collect logs and run again SETUP SUITE SETUP EXP EXPERIMENT SCOPE SETUP RUN EXECUTE RUN to next RUN Background TEARDOWN RUN LOGS 59

60 Peel execution flow - turn off systems TEARDOWN SUITE SETUP SUITE SETUP EXP to next EXP TEARDOWN EXP EXPERIMENT SCOPE SETUP RUN EXECUTE RUN to next RUN Background TEARDOWN RUN LOGS 60
61 Peel execution flow - It enables context fairness 1 SETUP SUITE 2 SETUP EXP 3 SETUP RUN to next EXP 5 TEARDOWN EXP 4 EXPERIMENT SCOPE EXECUTE RUN to next RUN Background TEARDOWN SUITE TEARDOWN RUN LOGS 61
62 The KMeans Theory Defining Experiments 62
63 Building the Experiment Pipeline - KMeans Example KMEANS clustering find new classes from unlabeled data by grouping ASSIGNMENT ASSIGNMENT STEP re-partition datapoints according to centroids Defining Experiments UPDATE UPDATE STEP retrieve new centroids by datapoints location mean 63
64 KMeans Workload Code Bonus Slides 64
65 Building the KMeans Pipeline - Data Structures INIT CENTERS EXPERIMENT SCOPE DATA * the project is developed in Scala Bonus Slides 65
66 @ForwardedFields(Array("*->_2")) final class CommonSelectNearestCenter extends RichMapFunction[BDVector[Double], (Int, BDVector[Double], Long)] { private var centroids: Traversable[(Int, BDVector[Double])] = null /** reads centroids and indexing values from the broadcasted set **/ override def open(parameters: Configuration): Unit = { centroids = getruntimecontext.getbroadcastvariable[(int, BDVector[Double])]("centroids").asScala } override def map(point: BDVector[Double]): (Int, BDVector[Double], Long) = { var mindistance: Double = Double.MaxValue var closestcentroidid: Int = -1 for ((idx, centroid) <- centroids) { val distance = squareddistance(point, centroid) if (distance < mindistance) { mindistance = distance closestcentroidid = idx }} (closestcentroidid, point, 1L) }} KMeans Iteration #1 val finalcentroids: DataSet[(Int, BDVector[Double])] = centroids.iterate(iterations) { currentcentroids => val newcentroids = points.map(new CommonSelectNearestCenter).withBroadcastSet(currentCentroids, "centroids") /** **/ Bonus Slides 66
67 while(iterations < maxiterations) { val bccentroids = data.context.broadcast(currentcentroids) val newcentroids: RDD[(Int, (BDVector[Double], Long))] = data.map (point => { var mindistance: Double = Double.MaxValue var closestcentroidid: Int = -1 val centers = bccentroids.value centers.foreach(c => { // c = (idx, centroid) val distance = squareddistance(point, c._2) if (distance < mindistance) { mindistance = distance closestcentroidid = c._1 } }) KMeans Iteration #1 (closestcentroidid, (point, 1L)) }) /** **/ Bonus Slides 67
68 val finalcentroids: DataSet[(Int, BDVector[Double])] = centroids.iterate(iterations) { currentcentroids => val newcentroids = points.map(new CommonSelectNearestCenter).withBroadcastSet(currentCentroids, "centroids").groupby(0).reduce((p1, p2) => { (p1._1, p1._2 + p2._2, p1._3 + p2._3)}).withforwardedfields("_1") /** **/ (closestcentroidid, (point, 1L)) }).reducebykey(mergecontribs) KMeans Iteration #2 type WeightedPoint = (BDVector[Double], Long) def mergecontribs(x: WeightedPoint, y: WeightedPoint): WeightedPoint = { (x._1 + y._1, x._2 + y._2) } Bonus Slides 68
69 KMeans Iteration #2 val avgnewcentroids = newcentroids.map(x => { val avgcenter = x._2 / x._3.todouble (x._1, avgcenter) }).withforwardedfields("_1") avgnewcentroids Bonus Slides currentcentroids = newcentroids.map(x => { val (center, count) = x._2 val avgcenter = center / count.todouble (x._1, avgcenter) }).collect() iterations += 1 69
70 When Experiment Definition Goes Wrong Defining Experiments 70
71 SVM and Gradient Descent: what we wanted to do ORIGINAL IDEA Gradient Descent + mini-batching 1. sampling not comparable Custom and Common Sampler 2. mappartitions over mini-batches p0 Defining Experiments p1... pn shuffle indices and subset local gd gradient global gd update 71
72 SVM and Gradient Descent: what we did ISSUE Spark not able to Run mappartitions OutOfMemory Exception to Batch Gradient Descent p0 Defining Experiments p1... pn shuffle indices and subset local gd gradient global gd update 72
73 When Experiment Definition Goes Wrong Defining Experiments 73

74 The Supervised Learning Framework Defining Experiments 74
75 Other Results Defining Experiments 75
76 Spark versus Flink Summary 34 RUNTIMEaaaaaaaa WINS Multiple Linear Regression Spark v Flink 8-1 Spark 63% outperforms Flink Flink 74% faster on critic resources FlinkML provides better runtimes KMeans Spark v Flink Support Vector Machine Spark v Flink 16-0 Spark 71% outperforms Flink Flink likes MORE Data Alternating Least Squares Similar Performance Flink definitely likes MORE data Flink 11% faster on critic resources Benchmarking and Results Analysis NOT COMPARABLE 76
77 Multiple Linear Regression strong scale CLOUD-11 (25nodes) 28GB RAM per node 16 core CPU per node DATASET INFO ALGORITHM INFO 7 no. datapoints 10 model size 1000 Benchmarking and Results Analysis data size 80GB sparsity 30% Iterations
78 Spark versus Flink Summary 34 RUNTIMEaaaaaaaa WINS Multiple Linear Regression Spark v Flink 8-1 Spark 63% outperforms Flink Flink 74% faster on critic resources FlinkML provides better runtimes KMeans Spark v Flink Support Vector Machine Spark v Flink 16-0 Spark 71% outperforms Flink Flink likes MORE Data Alternating Least Squares Similar Performance Flink definitely likes MORE data Flink 11% faster on critic resources Benchmarking and Results Analysis NOT COMPARABLE 78

79 Support Vector Machine strong scale and weak scale 12GB RAM per node 8 core CPU per node Benchmarking and Results Analysis sparsity 0% model size
80 Future Developments Defining Experiments 80
81 Future Improvements Complete not comparable benchmarking Redefine ALS benchmarking Add not Included Systems Improve shee and integrate it in peel framework Bonus Slides 81
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Apache Flink- A System for Batch and Realtime Stream Processing
 Apache Flink- A System for Batch and Realtime Stream Processing Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich Prof Dr. Matthias Schubert 2016 Introduction to Apache Flink
Apache Flink- A System for Batch and Realtime Stream Processing Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich Prof Dr. Matthias Schubert 2016 Introduction to Apache Flink
Apache Flink. Fuchkina Ekaterina with Material from Andreas Kunft -TU Berlin / DIMA; dataartisans slides
 Apache Flink Fuchkina Ekaterina with Material from Andreas Kunft -TU Berlin / DIMA; dataartisans slides What is Apache Flink Massive parallel data flow engine with unified batch-and streamprocessing CEP
Apache Flink Fuchkina Ekaterina with Material from Andreas Kunft -TU Berlin / DIMA; dataartisans slides What is Apache Flink Massive parallel data flow engine with unified batch-and streamprocessing CEP
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Apache Flink
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Apache Flink Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid, Daniyal Kazempour,
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Apache Flink Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur Schmid, Daniyal Kazempour,
Dynamic Resource Allocation for Distributed Dataflows. Lauritz Thamsen Technische Universität Berlin
 Dynamic Resource Allocation for Distributed Dataflows Lauritz Thamsen Technische Universität Berlin 04.05.2018 Distributed Dataflows E.g. MapReduce, SCOPE, Spark, and Flink Used for scalable processing
Dynamic Resource Allocation for Distributed Dataflows Lauritz Thamsen Technische Universität Berlin 04.05.2018 Distributed Dataflows E.g. MapReduce, SCOPE, Spark, and Flink Used for scalable processing
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Scaled Machine Learning at Matroid
 Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Machine learning library for Apache Flink
 Machine learning library for Apache Flink MTP Mid Term Report submitted to Indian Institute of Technology Mandi for partial fulfillment of the degree of B. Tech. by Devang Bacharwar (B2059) under the guidance
Machine learning library for Apache Flink MTP Mid Term Report submitted to Indian Institute of Technology Mandi for partial fulfillment of the degree of B. Tech. by Devang Bacharwar (B2059) under the guidance
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Linear Regression Optimization
 Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
Gradient Descent Linear Regression Optimization Goal: Find w that minimizes f(w) f(w) = Xw y 2 2 Closed form solution exists Gradient Descent is iterative (Intuition: go downhill!) n w * w Scalar objective:
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
Apache Storm: Hands-on Session A.A. 2016/17
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Storm: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Storm: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Motivation And Intro Programming Model Spark Data Transformation Model Construction Model Training Model Inference Execution Model Data Parallel Training
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Motivation And Intro Programming Model Spark Data Transformation Model Construction Model Training Model Inference Execution Model Data Parallel Training
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Kafka Streams: Hands-on Session A.A. 2017/18
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Kafka Streams: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Kafka Streams: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Architecture of Flink's Streaming Runtime. Robert
 Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
Architecture of Flink's Streaming Runtime Robert Metzger @rmetzger_ rmetzger@apache.org What is stream processing Real-world data is unbounded and is pushed to systems Right now: people are using the batch
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Simplifying ML Workflows with Apache Beam & TensorFlow Extended
 Simplifying ML Workflows with Apache Beam & TensorFlow Extended Tyler Akidau @takidau Software Engineer at Google Apache Beam PMC Apache Beam Portable data-processing pipelines Example pipelines Python
Simplifying ML Workflows with Apache Beam & TensorFlow Extended Tyler Akidau @takidau Software Engineer at Google Apache Beam PMC Apache Beam Portable data-processing pipelines Example pipelines Python
HiTune. Dataflow-Based Performance Analysis for Big Data Cloud
 HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
HiTune Dataflow-Based Performance Analysis for Big Data Cloud Jinquan (Jason) Dai, Jie Huang, Shengsheng Huang, Bo Huang, Yan Liu Intel Asia-Pacific Research and Development Ltd Shanghai, China, 200241
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
MLI - An API for Distributed Machine Learning. Sarang Dev
 MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
Machine Learning In A Snap. Thomas Parnell Research Staff Member IBM Research - Zurich
 Machine Learning In A Snap Thomas Parnell Research Staff Member IBM Research - Zurich What are GLMs? Ridge Regression Support Vector Machines Regression Generalized Linear Models Classification Lasso Regression
Machine Learning In A Snap Thomas Parnell Research Staff Member IBM Research - Zurich What are GLMs? Ridge Regression Support Vector Machines Regression Generalized Linear Models Classification Lasso Regression
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Using Numerical Libraries on Spark
 Using Numerical Libraries on Spark Brian Spector London Spark Users Meetup August 18 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm with
Using Numerical Libraries on Spark Brian Spector London Spark Users Meetup August 18 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm with
MDHIM: A Parallel Key/Value Store Framework for HPC
 MDHIM: A Parallel Key/Value Store Framework for HPC Hugh Greenberg 7/6/2015 LA-UR-15-25039 HPC Clusters Managed by a job scheduler (e.g., Slurm, Moab) Designed for running user jobs Difficult to run system
MDHIM: A Parallel Key/Value Store Framework for HPC Hugh Greenberg 7/6/2015 LA-UR-15-25039 HPC Clusters Managed by a job scheduler (e.g., Slurm, Moab) Designed for running user jobs Difficult to run system
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Spark and distributed data processing
 Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
Stanford CS347 Guest Lecture Spark and distributed data processing Reynold Xin @rxin 2016-05-23 Who am I? Reynold Xin PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD),
MapReduce review. Spark and distributed data processing. Who am I? Today s Talk. Reynold Xin
 Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
COMP6237 Data Mining Data Mining & Machine Learning with Big Data. Jonathon Hare
 COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
MIT805 BIG DATA MAPREDUCE
 MIT805 BIG DATA MAPREDUCE Christoph Stallmann Department of Computer Science University of Pretoria Admin Part 2 & 3 of the assignment Team registrations Concept Roman Empire Concept Roman Empire Concept
MIT805 BIG DATA MAPREDUCE Christoph Stallmann Department of Computer Science University of Pretoria Admin Part 2 & 3 of the assignment Team registrations Concept Roman Empire Concept Roman Empire Concept
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Apache SystemML Declarative Machine Learning
 Apache Big Data Seville 2016 Apache SystemML Declarative Machine Learning Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing to open
Apache Big Data Seville 2016 Apache SystemML Declarative Machine Learning Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing to open
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Apache Flink: Distributed Stream Data Processing
 Apache Flink: Distributed Stream Data Processing K.M.J. Jacobs CERN, Geneva, Switzerland 1 Introduction The amount of data is growing significantly over the past few years. Therefore, the need for distributed
Apache Flink: Distributed Stream Data Processing K.M.J. Jacobs CERN, Geneva, Switzerland 1 Introduction The amount of data is growing significantly over the past few years. Therefore, the need for distributed
Track Join. Distributed Joins with Minimal Network Traffic. Orestis Polychroniou! Rajkumar Sen! Kenneth A. Ross
 Track Join Distributed Joins with Minimal Network Traffic Orestis Polychroniou Rajkumar Sen Kenneth A. Ross Local Joins Algorithms Hash Join Sort Merge Join Index Join Nested Loop Join Spilling to disk
Track Join Distributed Joins with Minimal Network Traffic Orestis Polychroniou Rajkumar Sen Kenneth A. Ross Local Joins Algorithms Hash Join Sort Merge Join Index Join Nested Loop Join Spilling to disk
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation. Chris Herrera Hashmap
 Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
The Stream Processor as a Database. Ufuk
 The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
The Stream Processor as a Database Ufuk Celebi @iamuce Realtime Counts and Aggregates The (Classic) Use Case 2 (Real-)Time Series Statistics Stream of Events Real-time Statistics 3 The Architecture collect
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Shark: SQL and Rich Analytics at Scale. Reynold Xin UC Berkeley
 Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
Shark: SQL and Rich Analytics at Scale Reynold Xin UC Berkeley Challenges in Modern Data Analysis Data volumes expanding. Faults and stragglers complicate parallel database design. Complexity of analysis:
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Accelerate Big Data Insights
 Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
An Introduction to The Beam Model
 An Introduction to The Beam Model Apache Beam (incubating) Slides by Tyler Akidau & Frances Perry, April 2016 Agenda 1 Infinite, Out-of-order Data Sets 2 The Evolution of the Beam Model 3 What, Where,
An Introduction to The Beam Model Apache Beam (incubating) Slides by Tyler Akidau & Frances Perry, April 2016 Agenda 1 Infinite, Out-of-order Data Sets 2 The Evolution of the Beam Model 3 What, Where,
A Parallel R Framework
 A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
WHITE PAPER. Apache Spark: RDD, DataFrame and Dataset. API comparison and Performance Benchmark in Spark 2.1 and Spark 1.6.3
 WHITE PAPER Apache Spark: RDD, DataFrame and Dataset API comparison and Performance Benchmark in Spark 2.1 and Spark 1.6.3 Prepared by: Eyal Edelman, Big Data Practice Lead Michael Birch, Big Data and
WHITE PAPER Apache Spark: RDD, DataFrame and Dataset API comparison and Performance Benchmark in Spark 2.1 and Spark 1.6.3 Prepared by: Eyal Edelman, Big Data Practice Lead Michael Birch, Big Data and
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457683.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
TOWARDS PORTABILITY AND BEYOND. Maximilian maximilianmichels.com DATA PROCESSING WITH APACHE BEAM
 TOWARDS PORTABILITY AND BEYOND Maximilian Michels mxm@apache.org DATA PROCESSING WITH APACHE BEAM @stadtlegende maximilianmichels.com !2 BEAM VISION Write Pipeline Execute SDKs Runners Backends !3 THE
TOWARDS PORTABILITY AND BEYOND Maximilian Michels mxm@apache.org DATA PROCESSING WITH APACHE BEAM @stadtlegende maximilianmichels.com !2 BEAM VISION Write Pipeline Execute SDKs Runners Backends !3 THE
Bringing Data to Life
 Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Bringing Data to Life Data management and Visualization Techniques Benika Hall Rob Harrison Corporate Model Risk March 16, 2018 Introduction Benika Hall Analytic Consultant Wells Fargo - Corporate Model
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 29, 2013 UC BERKELEY Stage 0:M ap-shuffle-reduce M apper(row ) { fields = row.split("\t") em it(fields[0],fields[1]); } Reducer(key,values)
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 29, 2013 UC BERKELEY Stage 0:M ap-shuffle-reduce M apper(row ) { fields = row.split("\t") em it(fields[0],fields[1]); } Reducer(key,values)
SparkBench: A Comprehensive Spark Benchmarking Suite Characterizing In-memory Data Analytics
 SparkBench: A Comprehensive Spark Benchmarking Suite Characterizing In-memory Data Analytics Min LI,, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura, Alan Bivens IBM TJ Watson Research Center * A
SparkBench: A Comprehensive Spark Benchmarking Suite Characterizing In-memory Data Analytics Min LI,, Jian Tan, Yandong Wang, Li Zhang, Valentina Salapura, Alan Bivens IBM TJ Watson Research Center * A
Introduction to Apache Beam
 Introduction to Apache Beam Dan Halperin JB Onofré Google Beam podling PMC Talend Beam Champion & PMC Apache Member Apache Beam is a unified programming model designed to provide efficient and portable
Introduction to Apache Beam Dan Halperin JB Onofré Google Beam podling PMC Talend Beam Champion & PMC Apache Member Apache Beam is a unified programming model designed to provide efficient and portable
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Functional Comparison and Performance Evaluation. Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14
 Functional Comparison and Performance Evaluation Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Micro-Batch
Functional Comparison and Performance Evaluation Huafeng Wang Tianlun Zhang Wei Mao 2016/11/14 Overview Streaming Core MISC Performance Benchmark Choose your weapon! 2 Continuous Streaming Micro-Batch
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Distributed Optimization for Machine Learning
 Distributed Optimization for Machine Learning Martin Jaggi EPFL Machine Learning and Optimization Laboratory mlo.epfl.ch AI Summer School - MSR Cambridge - July 5 th Machine Learning Methods to Analyze
Distributed Optimization for Machine Learning Martin Jaggi EPFL Machine Learning and Optimization Laboratory mlo.epfl.ch AI Summer School - MSR Cambridge - July 5 th Machine Learning Methods to Analyze
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Apache Beam. Modèle de programmation unifié pour Big Data
 Apache Beam Modèle de programmation unifié pour Big Data Who am I? Jean-Baptiste Onofre @jbonofre http://blog.nanthrax.net Member of the Apache Software Foundation
Apache Beam Modèle de programmation unifié pour Big Data Who am I? Jean-Baptiste Onofre @jbonofre http://blog.nanthrax.net Member of the Apache Software Foundation
Optimizing Across Relational and Linear Algebra in Parallel Analytics Pipelines
 Optimizing Across Relational and Linear Algebra in Parallel Analytics Pipelines Asterios Katsifodimos Assistant Professor @ TU Delft a.katsifodimos@tudelft.nl http://asterios.katsifodimos.com Outline Introduction
Optimizing Across Relational and Linear Algebra in Parallel Analytics Pipelines Asterios Katsifodimos Assistant Professor @ TU Delft a.katsifodimos@tudelft.nl http://asterios.katsifodimos.com Outline Introduction