Joe Hummel, PhD. Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago
|
|
|
- Ashlynn Dean
- 5 years ago
- Views:
Transcription

1 Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials:
2 A little history Why Hadoop? How it works Demos Summary Hadoop on Azure 2
 = return x + y // count the number of primes in 1..N: let countprimes(n) = let L = [ 1.. N ] // [ 1, 2, 3, 4, 5, 6,.")
3 Map-Reduce is from functional programming // function returns 1 if i is prime, 0 if not: let isprime(i) =... // sums 2 numbers: let sum(x, y) = return x + y // count the number of primes in 1..N: let countprimes(n) = let L = [ 1.. N ] // [ 1, 2, 3, 4, 5, 6,... ] let T = map isprime L // [ 0, 1, 1, 0, 1, 0,... ] let count = reduce sum T // 42 return count Hadoop on Azure 3

4 Created by to drive internet search BIG data scalable to TBs and beyond Parallelism: to get the performance Data partitioning: to drive the parallelism Fault tolerance: at this scale, machines are going to crash, a lot BIG Data page hits 4
5 Search engines: Google, Yahoo, Bing Facebook Twitter Financials Health industry Insurance Credit card companies Just about any company collecting user data Hadoop on Azure 5



6 Freely-available framework for big data Based on concept of Map-Reduce: map function reduce intermediate results Map BIG data Map Map Reduce R Map.. 6

7 Reducer Reducer Reducer Reducer Reducer Reducer Hadoop on Azure 7
![Data Map Map Map [ <key1,value>, <key4,value>, <key2,value>, ] Sort Sort Sort [ <key1,value>,](/docs-images/86/94771695/images/8-4.jpg "<key1,value>, ] Merge [ <key1, [value,value, ]>, <key2, [value,value, ]>, ] Reduce [ <key1, value>, <key2,")
8 Data Map Map Map [ <key1,value>, <key4,value>, <key2,value>, ] Sort Sort Sort [ <key1,value>, <key1,value>, ] Merge [ <key1, [value,value, ]>, <key2, [value,value, ]>, ] Reduce [ <key1, value>, <key2, value> ] R 8

 Netflix Data")



9 Netflix data-mining Average rating Netflix Movie Reviews (.txt) Netflix Data Mining App movieid,userid,rating,date 1, ,3, , ,5, , ,3, , ,5, Hadoop on Azure 9
![Data Map Map Map [ <1,3>, <217,5>, <42,3>, <1,5>, <134,2>, <42,1>, ] Sort Sort Sort [ <1,3>, <1,5>, <42,3>, <42,1>,](/docs-images/86/94771695/images/10-6.jpg "<134,2>, <217,5>, ] Merge [ <1, [3,5]>, <42, [3,1]>, <134, [2, ]>, <217, [5, ]>, ] Reduce [ <1, 4>, <42, 2>, <134,?")
10 Data Map Map Map [ <1,3>, <217,5>, <42,3>, <1,5>, <134,2>, <42,1>, ] Sort Sort Sort [ <1,3>, <1,5>, <42,3>, <42,1>, <134,2>, <217,5>, ] Merge [ <1, [3,5]>, <42, [3,1]>, <134, [2, ]>, <217, [5, ]>, ] Reduce [ <1, 4>, <42, 2>, <134,?>, ] R 10
; }; var reduce = function (key, values, context) { var sum = 0; var count = 0; while (values.hasnext()) { count++; sum += parseint(values.next()); } context.")
11 To compute average rating for every movie: // Javascript version: var map = function (key, value, context) { var values = value.split(","); // field 0 contains movieid, field 2 the rating: context.write(values[0], values[2]); }; var reduce = function (key, values, context) { var sum = 0; var count = 0; while (values.hasnext()) { count++; sum += parseint(values.next()); } context.write(key, sum/count); }; Hadoop on Azure 11
12 Upload data to HDFS Hadoop file system Write map / reduce functions default is to use Java most languages supported: C, C++, C#, JavaScript, Python, Compile and upload code For Java, you upload.jar file For others,.exe or script Submit MapReduce job Wait for job to complete Hadoop on Azure 12
13 Queries against big datasets Embarrassingly-parallel problems Solution must fit into map-reduce framework Non-real-time demands Hadoop is not for: Small datasets (< 1GB?) Sub-second / real-time needs (though clearly Google makes it work) Hadoop on Azure 13


14 We ll be working with Chicago crime data GB 5M rows 14


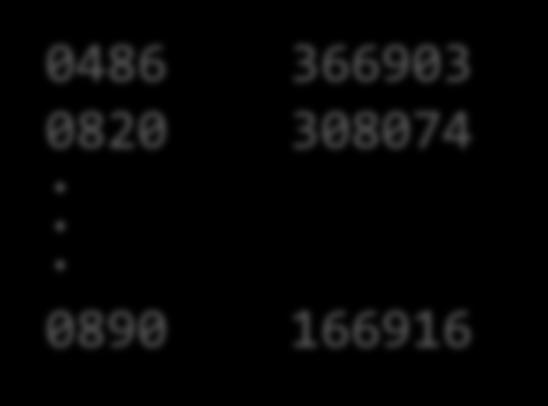
15 Compute top-10 crimes IUCR Count IUCR = Illinois Uniform Crime Codes Uniform-Crime-R/c7ck-438e 15
 Hadoop on")
16 Hadoop on Azure Supports traditional Hadoop usage Upload data Write MapReduce program Submit job Additional features: Allows access to persistent data from Azure Storage Vault Provides interactive JavaScript console Built-in higher-level query languages (PIG, HIVE) Hadoop on Azure 16
; }; var reduce = function (key, values, context) { var sum = 0; while (values.hasnext()) { sum += parseint(values.next()); } context.")
17 // Javascript version: var map = function (key, value, context) { var values = value.split(","); context.write(values[4], 1); }; var reduce = function (key, values, context) { var sum = 0; while (values.hasnext()) { sum += parseint(values.next()); } context.write(key, sum); }; Hadoop on Azure 17
. mapreduce(\"scripts/iucr-count.")
 // visualize the results: file = fs.")
18 // interactive PIG with explicit Map-Reduce functions: pig.from("asv://datafiles/cc-from-2001.txt"). mapreduce("scripts/iucr-count.js", "IUCR, Count:long"). orderby("count DESC"). take(10). to("output-from-2001") // visualize the results: file = fs.read("output-from2001/part-r-00000") data = parse(file.data, "IUCR, Count:long") graph.bar(data) Hadoop on Azure 18
19 Microsoft is offering free access to Hadoop Request Hadoop connector for Excel Process data using Hadoop, analyze/visualize using Excel Hadoop on Azure 19

20 Hadoop on Azure 20

21 Hadoop is all about big data processing Scalable, parallel, fault-tolerant Easy to understand programming model Map-Reduce But then solution must fit into this framework Rich ecosystem developing around Hadoop Technologies: PIG, HIVE, HBase, Companies: Cloudera, Hortonworks, MapR, Hadoop on Azure 21
22 Presenter: Joe Hummel Materials: For more info: Overview, including how to access via.net API: Hadoop on Azure 22
Joe Hummel, PhD. Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago
 Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials: http://www.joehummel.net/downloads.html Email: joe@joehummel.net
Joe Hummel, PhD Visiting Researcher: U. of California, Irvine Adjunct Professor: U. of Illinois, Chicago & Loyola U., Chicago Materials: http://www.joehummel.net/downloads.html Email: joe@joehummel.net
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora
 Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI
 DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
DHANALAKSHMI COLLEGE OF ENGINEERING, CHENNAI Department of Information Technology IT6701 - INFORMATION MANAGEMENT Anna University 2 & 16 Mark Questions & Answers Year / Semester: IV / VII Regulation: 2013
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Windows Azure Overview
 Windows Azure Overview Christine Collet, Genoveva Vargas-Solar Grenoble INP, France MS Azure Educator Grant Packaged Software Infrastructure (as a Service) Platform (as a Service) Software (as a Service)
Windows Azure Overview Christine Collet, Genoveva Vargas-Solar Grenoble INP, France MS Azure Educator Grant Packaged Software Infrastructure (as a Service) Platform (as a Service) Software (as a Service)
ExamTorrent. Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you
 ExamTorrent http://www.examtorrent.com Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you Exam : Apache-Hadoop-Developer Title : Hadoop 2.0 Certification exam for Pig
ExamTorrent http://www.examtorrent.com Best exam torrent, excellent test torrent, valid exam dumps are here waiting for you Exam : Apache-Hadoop-Developer Title : Hadoop 2.0 Certification exam for Pig
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Pig A language for data processing in Hadoop
 Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
Pig A language for data processing in Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Apache Pig: Introduction Tool for querying data on Hadoop
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Project Design. Version May, Computer Science Department, Texas Christian University
 Project Design Version 4.0 2 May, 2016 2015-2016 Computer Science Department, Texas Christian University Revision Signatures By signing the following document, the team member is acknowledging that he
Project Design Version 4.0 2 May, 2016 2015-2016 Computer Science Department, Texas Christian University Revision Signatures By signing the following document, the team member is acknowledging that he
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
HBase vs Neo4j. Technical overview. Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon
 Ecolé Normale Superiuere de Lyon") HBase vs Neo4j Technical overview Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon 12th October 2017 1 Contents 1 Introduction 3 2 Overview of HBase and Neo4j
HBase vs Neo4j Technical overview Name: Vladan Jovičić CR09 Advanced Scalable Data (Fall, 2017) Ecolé Normale Superiuere de Lyon 12th October 2017 1 Contents 1 Introduction 3 2 Overview of HBase and Neo4j
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
MapReduce and Hadoop
 Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Big Data and Hadoop. Course Curriculum: Your 10 Module Learning Plan. About Edureka
 Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Course Curriculum: Your 10 Module Learning Plan Big Data and Hadoop About Edureka Edureka is a leading e-learning platform providing live instructor-led interactive online training. We cater to professionals
Apache TM Hadoop TM - based Services for Windows Azure How- To and FAQ Guide
 Apache TM Hadoop TM - based Services for Windows Azure How- To and FAQ Guide Welcome to Hadoop for Azure CTP How- To Guide 1. Setup your Hadoop on Azure cluster 2. How to run a job on Hadoop on Azure 3.
Apache TM Hadoop TM - based Services for Windows Azure How- To and FAQ Guide Welcome to Hadoop for Azure CTP How- To Guide 1. Setup your Hadoop on Azure cluster 2. How to run a job on Hadoop on Azure 3.
PROFESSIONAL. NoSQL. Shashank Tiwari WILEY. John Wiley & Sons, Inc.
 PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa
 YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa ozawa.tsuyoshi@lab.ntt.co.jp ozawa@apache.org About me Tsuyoshi Ozawa Research Engineer @ NTT Twitter: @oza_x86_64 Over 150 reviews in 2015
YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa ozawa.tsuyoshi@lab.ntt.co.jp ozawa@apache.org About me Tsuyoshi Ozawa Research Engineer @ NTT Twitter: @oza_x86_64 Over 150 reviews in 2015
Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data
 Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data Yojna Arora, Dinesh Goyal Abstract: Big Data refers to that huge amount of data which cannot be analyzed by using traditional analytics
Performance Comparison of Hive, Pig & Map Reduce over Variety of Big Data Yojna Arora, Dinesh Goyal Abstract: Big Data refers to that huge amount of data which cannot be analyzed by using traditional analytics
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
TESTING BIG DATA WORLD RIGA. by Konstantin Pletenev OCTOBER, 2017, TAPOST GROW CONFIDENTLY
 RIGA TESTING BIG DATA WORLD by Konstantin Pletenev OCTOBER, 2017, TAPOST GROW CONFIDENTLY BIG DATA IS NOT ABOUT THE DATA THE REVOLUTION IS NOT THAT THERE S MORE DATA AVAILABLE THE REVOLUTION IS THAT WE
RIGA TESTING BIG DATA WORLD by Konstantin Pletenev OCTOBER, 2017, TAPOST GROW CONFIDENTLY BIG DATA IS NOT ABOUT THE DATA THE REVOLUTION IS NOT THAT THERE S MORE DATA AVAILABLE THE REVOLUTION IS THAT WE
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Column Stores and HBase. Rui LIU, Maksim Hrytsenia
 Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Vendor: Cloudera. Exam Code: CCD-410. Exam Name: Cloudera Certified Developer for Apache Hadoop. Version: Demo
 Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Vendor: Cloudera Exam Code: CCD-410 Exam Name: Cloudera Certified Developer for Apache Hadoop Version: Demo QUESTION 1 When is the earliest point at which the reduce method of a given Reducer can be called?
Actual4Dumps. Provide you with the latest actual exam dumps, and help you succeed
 Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Oracle Big Data Fundamentals Ed 1
 Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Oracle University Contact Us: +0097143909050 Oracle Big Data Fundamentals Ed 1 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, learn to use Oracle's Integrated Big Data
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
This is a brief tutorial that explains how to make use of Sqoop in Hadoop ecosystem.
 About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
About the Tutorial Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Big Data Analytics. Description:
 Big Data Analytics Description: With the advance of IT storage, pcoressing, computation, and sensing technologies, Big Data has become a novel norm of life. Only until recently, computers are able to capture
Big Data Analytics Description: With the advance of IT storage, pcoressing, computation, and sensing technologies, Big Data has become a novel norm of life. Only until recently, computers are able to capture
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Distributed Systems. 21. Graph Computing Frameworks. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
Towards a Real- time Processing Pipeline: Running Apache Flink on AWS
 Towards a Real- time Processing Pipeline: Running Apache Flink on AWS Dr. Steffen Hausmann, Solutions Architect Michael Hanisch, Manager Solutions Architecture November 18 th, 2016 Stream Processing Challenges
Towards a Real- time Processing Pipeline: Running Apache Flink on AWS Dr. Steffen Hausmann, Solutions Architect Michael Hanisch, Manager Solutions Architecture November 18 th, 2016 Stream Processing Challenges
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)