Moab Workload Manager on Cray XT3
|
|
|
- Erik Banks
- 5 years ago
- Views:
Transcription
1 Moab Workload Manager on Cray XT3 presented by Don Maxwell (ORNL) Michael Jackson (Cluster Resources, Inc.)
2 MOAB Workload Manager on Cray XT3 Why MOAB? Requirements Features Support/Futures 2
3 Why Moab? Existing platforms Cray X1E/XT3 and SGI Altix running PBSPro Opteron-based visualization cluster running SLURM IBM Power 4 running LoadLeveler Traditional resource management features missing Dynamic Backfill for high resource utilization Run this Next (e.g. llfavorjob) Diagnostics too limited (e.g. determine topdog ) More flexible scheduling for NLCF resources Integration with resource allocation system (RATS) Dynamic prioritization of jobs Reputation of Cluster Resources, Inc. Developers of leading scheduling systems Maui and Moab New ORNL staff with prior experience with Cluster Resources 3
4 Cluster Resources Solution Space Cluster (Intelligence and Orchestration) Workload Management Resource Management Allocation Management Event and Condition Management Grid Grid Workload Management Grid Submission (Grid Portal) Grid Allocation Management Utility/Hosted Computing Services Support Consulting (Solution Design, Optimization, etc.) Integration Development Training 4
5 Solution Framework: Where Does it Fit? Grid Workload Manager Cluster Workload Manager Moab Grid Suite: Scheduler, Policy Manager, Event Engine, Integration Platform Moab Cluster Suite: Scheduler, Policy Manager, Event Engine, Integration Platform Compute Resource Manager TORQUE OpenPBS PBS Pro LSF Load Leveler SLURM Other Workload Type & Message Passing MPI MPICH Parallel PVM Batch Workload LAM Serial Transaction Operating System SUSE Linux RedHat Linux Other Linux Scyld BProc Unicos AIX Solaris Other Unix Mac OS X Windows Hardware/ CPU (Cluster or SMP) Cray XT3 Cray X1E Intel Xeon 32/EM64T Intel Itanium AMD Opteron AMD Athlon IBM Power Processor Other 5

6 Integration Points: 6
7 Moab XT3 Integration at ORNL Identity Manager (Security, Policies, Prioritization, etc.) Other Services (Grid & Peer Services, Allocation Manager, Etc.) Virtualization Interface Node Monitor Monitor Start Config File Config File Cancel Moab Holistic Intelligence Multi-resource Manager Tunable Prioritization Fault Protection (file system, rogue processes, bad nodes, etc.) Moab Workload Manager Native Resource Manager Interface Requeue Event Policy Engine Advanced Reporting Control Co-allocation Other Commands Moab Cluster Manager (GUI Manage, Monitor & Report) Moab Access Portal (Web-base Management) Administrators manage via CLI or GUI. Managers get reports. End Users apply existing scripts via RM. OS & Middleware Cray XT3 Operating System Compute XTAdmin Database (Node, resource and file system allocation and statistics) Resource Manager (PBS Pro, LSF, TORQUE, etc.) yod Login File System (e.g. Lustre) ORNL Environment 7
8 Requirements Port Moab to XT3, deploy It, integrate it with 3 tools, test it and go production in 3 Weeks! No disruption of production work No change in the interface to the batch system on NLCF machines Monitor and Simulation Mode allows evaluation of priority changes without impacting the current job queue Dynamic Backfill Static backfill (a.k.a. FIFO backfill) = underutilization Cathy Scheduler More control over workload to meet objectives better run-this-job-next More flexible prioritization supporting fairshare Preemption for visualization workload 8
9 Moab Features for a System Administrator Monitor and Simulation mode Installing new versions Changing policies Diagnostics Load the scheduler is placing on the server Accounts and associated attributes (priorities, QOS, etc.) priorities Prior failures and reasons Configuration problems Admin levels User support could see all and influence jobs Operators could see all but not change anything SSH X11 forwarding Multiple login and yod nodes complicated with batch Moab perl interface (Virtualization Layer) Easy placement of jobs Knowledge of submitting host and interactive state retrieved from PBS Pro Discovered Lustre node recovery state missing in CPA and PBS Pro Diagnostics revealed jobs were failing Moab modified to consult Lustre recovery table in SDB 9
10 Moab: Safe Evaluation and Deployment Monitor Mode Moab monitors all information, processes and policies, decides what it would do, but does not implement it. Simulation Mode Moab imports historical or scenario based information and allows offline evaluation of changes to resources, workload and policies. Interactive Mode Moab fully schedules workload, but asks administrator to approve each decision before implementing it. Partition Mode Moab applies full workload management to a subset of resources, all other resources are unaffected. Also allows for mixed production and test environments. Normal Mode Normal production mode with full capabilities. 10
11 Moab Features for a System Administrator Monitor and Simulation mode Installing new versions Changing policies Diagnostics Load the scheduler is placing on the server Accounts and associated attributes (priorities, QOS, etc.) priorities Prior failures and reasons Configuration problems Admin levels User support could see all and influence jobs Operators could see all but not change anything SSH X11 forwarding Multiple login and yod nodes complicated with batch Moab perl interface (Virtualization Layer) Easy placement of jobs Knowledge of submitting host and interactive state retrieved from PBS Pro Discovered Lustre node recovery state missing in CPA and PBS Pro Diagnostics revealed jobs were failing Moab modified to consult Lustre recovery table in SDB 11
12 Moab Features for a System Administrator Monitor and Simulation mode Installing new versions Changing policies Diagnostics Load the scheduler is placing on the server Accounts and associated attributes (priorities, QOS, etc.) priorities Prior failures and reasons Configuration problems Admin levels User support could see all and influence jobs Operators could see all but not change anything SSH X11 forwarding Multiple login and yod nodes complicated with batch Moab perl interface (Virtualization Layer) Easy placement of jobs Knowledge of submitting host and interactive state retrieved from PBS Pro Discovered Lustre node recovery state missing in CPA and PBS Pro Diagnostics revealed jobs were failing Moab modified to consult Lustre recovery table in SDB 12
13 Moab Features for a System Administrator Monitor and Simulation mode Installing new versions Changing policies Diagnostics Load the scheduler is placing on the server Accounts and associated attributes (priorities, QOS, etc.) priorities Prior failures and reasons Configuration problems Admin levels User support could see all and influence jobs Operators could see all but not change anything SSH X11 forwarding Multiple login and yod nodes complicated with batch Moab perl interface (Virtualization Layer) Easy placement of jobs Knowledge of submitting host and interactive state retrieved from PBS Pro Discovered Lustre node recovery state missing in CPA and PBS Pro Diagnostics revealed jobs were failing Moab modified to consult Lustre recovery table in SDB 13
14 Moab SSH X11 Interactive Sessions Identity Manager (Security, Policies, Prioritization, etc.) Other Services (Grid & Peer Services, Allocation Manager, Etc.) Virtualization Interface Node Monitor 3. Moab gets host information of the node that submitted the job Config File Monitor Start Config File Cancel Moab Holistic Intelligence Multi-resource Manager Tunable Prioritization Fault Protection (file system, rogue processes, bad nodes, etc.) Moab Workload Manager Native Resource Manager Interface Requeue 2. Moab sees that it is Interactive Event Policy Engine Advanced Reporting Control Co-allocation Other Commands Moab Cluster Manager (GUI Manage, Monitor & Report) Moab Access Portal (Web-base Management) 1. End User submits an Interactive End Users apply existing scripts via RM. OS & Middleware Cray XT3 Operating System Compute XTAdmin Database (Node, resource and file system allocation and statistics) Resource Manager (PBS Pro, LSF, TORQUE, etc.) yod ORNL Environment Login File System (e.g. Lustre) 4. Moab ensures the yod service and X11 applications are started where the SSH tunnel was created. 14
15 Moab Features for a System Administrator Monitor and Simulation mode Installing new versions Changing policies Diagnostics Load the scheduler is placing on the server Accounts and associated attributes (priorities, QOS, etc.) priorities Prior failures and reasons Configuration problems Admin levels User support could see all and influence jobs Operators could see all but not change anything SSH X11 forwarding Multiple login and yod nodes complicated with batch Moab perl interface (Virtualization Layer) Easy placement of jobs Knowledge of submitting host and interactive state retrieved from PBS Pro Discovered Lustre node recovery state missing in CPA and PBS Pro Diagnostics revealed jobs were failing Moab modified to consult Lustre recovery table in SDB (database) 15
16 Non Moab Lustre Clean Up Experience 7. Scheduling decisions are made improperly and backfill does not work correctly. Identity Manager (Security, Policies, Prioritization, etc.) Other Services (Grid & Peer Services, Allocation Manager, Etc.) Virtualization Interface 6. s are started on these nodes, but fail, because the nodes are not truly available. Node Monitor Monitor Start Config File Config File Cancel Moab Holistic Intelligence Multi-resource Manager Tunable Prioritization Fault Protection (file system, rogue processes, bad nodes, etc.) Moab Workload Manager Native Resource Manager Interface Requeue 5. Lustre continues recovery process. Event Policy Engine Advanced Reporting Control Co-allocation Other Commands 2. Resource Manager starts job on XT3 Moab Cluster Manager (GUI Manage, Monitor & Report) Moab Access Portal (Web-base Management) 1. End User submits job End Users apply existing scripts via RM. OS & Middleware Cray XT3 Operating System Utilization Loss Compute XTAdmin Database (Node, resource and file system allocation and statistics) Resource Manager (PBS Pro, LSF, TORQUE, etc.) yod Login File System (e.g. Lustre) 3. After job completes Lustre begins its file lock recovery process. ORNL Environment 4. Resource manager and XTAdmin Database report nodes as available. 16
17 Moab Lustre Clean Up Experience 6. Moab sees that Lustre is still cleaning up and schedules and backfills jobs properly around the nodes. Identity Manager (Security, Policies, Prioritization, etc.) Other Services (Grid & Peer Services, Allocation Manager, Etc.) Virtualization Interface Node Monitor 5. Moab checks status of Lustre recovery to see if the nodes are truly available. Monitor Start Config File Config File Cancel Moab Holistic Intelligence Multi-resource Manager Tunable Prioritization Fault Protection (file system, rogue processes, bad nodes, etc.) Moab Workload Manager Native Resource Manager Interface Requeue 4. Moab checks job status. Event Policy Engine Advanced Reporting Control Co-allocation Other Commands 2. Moab tells resource manager to start job on XT3 Moab Cluster Manager (GUI Manage, Monitor & Report) Moab Access Portal (Web-base Management) Administrators 1. End User submits job End Users apply existing scripts via RM. OS & Middleware Cray XT3 7. Once Lustre status is back to normal, additional jobs are applied to the nodes. Operating System Compute XTAdmin Database (Node, resource and file system allocation and statistics) Good Utilization Resource Manager (PBS Pro, LSF, TORQUE, etc.) yod ORNL Environment Login File System (e.g. Lustre) 3. After job completes Lustre begins its file lock recovery process. 17
18 Rogue Process Issues Identity Manager (Security, Policies, Prioritization, etc.) Other Services (Grid & Peer Services, Allocation Manager, Etc.) Virtualization Interface Node Monitor Monitor Start Config File Config File Cancel Moab Holistic Intelligence Multi-resource Manager Tunable Prioritization Fault Protection (file system, rogue processes, bad nodes, etc.) Moab Workload Manager Native Resource Manager Interface Requeue Event Policy Engine Advanced Reporting Control Co-allocation Other Commands 2. Resource Manager starts job on XT3 Moab Cluster Manager (GUI Manage, Monitor & Report) Moab Access Portal (Web-base Management) 1. End User submits job End Users apply existing scripts via RM. OS & Middleware Cray XT3 Operating System Utilization Loss Compute XTAdmin Database (Node, resource and file system allocation and statistics) Resource Manager (PBS Pro, LSF, TORQUE, etc.) yod Login File System (e.g. Lustre) 3. Resource or other failure causes job to fail. ORNL Environment 5. Failure condition repeats causing additional blockage. 4. Resource manager believes jobs are still running and that nodes are busy, thus blocking nodes. 18
19 Moab Rogue Process Recovery 7. Moab issues hold status on impacted jobs. Identity Manager (Security, Policies, Prioritization, etc.) Other Services (Grid & Peer Services, Allocation Manager, Etc.) Virtualization Interface 8. Moab associates issue information to the job 6. Moab checks status of yod service. Node Monitor Monitor Start 5. Moab checks job status. Config File Holistic Intelligence Multi-resource Manager Tunable Prioritization Fault Protection (file system, rogue processes, bad nodes, etc.) Moab Workload Manager Native Resource Manager Interface Config File Cancel Moab Requeue 4. Moab detects Resource failure condition. Event Policy Engine Advanced Reporting Control Co-allocation Other Commands 2. Moab tells resource manager to send job to XT3 Moab Cluster Manager (GUI Manage, Monitor & Report) Moab Access Portal (Web-base Management) Administrators 1. End User submits job End Users apply existing scripts via RM. OS & Middleware 9. Moab is able to send notice of job issue to Admin Cray XT3 10. Moab realizes nodes can now be used and additional jobs are applied to the nodes. Operating System Compute XTAdmin Database (Node, resource and file system allocation and statistics) Good Recovery Resource Manager (PBS Pro, LSF, TORQUE, etc.) yod ORNL Environment Login File System (e.g. Lustre) 3. Resource or other failure causes jobs to fail. 19
20 ORNL s Moab Priority Implementation Factor Unit of Weight Actual Weight (Minutes) Value Quality of Service # of days 1440 High (7) Account Priority # of days 1440 Allocated Hours (0) No Hours (-365) Queue # of days 1440 Debug (5) Batch (0) Size 1 day / 1000cpu 1 Provided by Moab Queue Time 1 minute 1 Provided by Moab PRIORITY* Cred(Accnt: QOS:Class) Serv(QTime) Res(Proc) Weights 1(1440: 1440: 1440) 1(1) 1(1) (0.0: 0.0: 5.0) 0.0(2.1) 1.3(96.0) The resulting priority is a simple calculation * =
21 Moab s Flexibility w/ Multi-Factor Prioritization Fairshare User Group Account Class Quality of Service s per User Processor Seconds Per User Processors Per User Resources Node Disk Processor Memory Swap Processor Seconds Processor Equivalent Walltime Usage Consumed Remaining Percentage Consumed Service Levels Queue Time XFactor Policy Violation ByPass Target Levels Queue Time XFactor Credential Based User Group Account Class Quality of Service Attribute State And More. 21
22 Moab Features for an End User showbf Determine the size and length of a job that will backfill at any instance in time checkjob Why is my job not starting? Has it tried to run and failed due to a system problem? showstart An estimated start and end time for jobs currently sitting in the queue 22
23 Moab Features for Management Difficult to Visualize Cluster Usage Performance Historical Data (Big Picture and Capacity Planning) 23

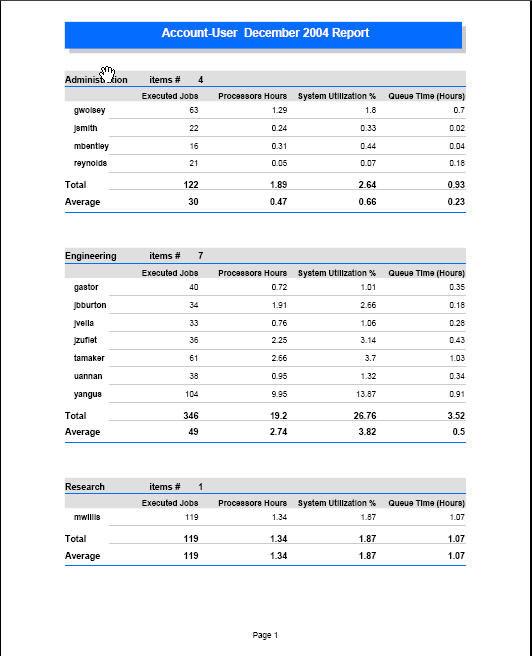

24 Moab Reports Service Monitoring and Management 24
25 Support/Future Port for XT3 completed in about three weeks X1E ported and running monitor mode currently Quick turnaround for bugs and features Next step issue resolution or feature requests with top priority sometimes fails Feels like CPA timing problem (CPA_NO_NODES) New feature for multi-dimensional MAXIJOB 25
26 Conclusion Rollout has gone very well on multiple architectures (XT3, X1E, Altix, Opteron), OSs, Resource Managers (PBS Pro, SLURM), and Interconnects (XT3, Crossbar, Quadrics, Numalink) ORNL policies are now properly represented and enforced Admin staff time is reduced Utilization is increased Progress on future projects has accelerated Users are happier More science is being delivered! 26
27 Questions? Or Contact Us Afterwards Don Maxwell: Michael Jackson: +1 (801)
Queuing and Scheduling on Compute Clusters
 Queuing and Scheduling on Compute Clusters Andrew Caird acaird@umich.edu Queuing and Scheduling on Compute Clusters p.1/17 The reason for me being here Give some queuing background Introduce some queuing
Queuing and Scheduling on Compute Clusters Andrew Caird acaird@umich.edu Queuing and Scheduling on Compute Clusters p.1/17 The reason for me being here Give some queuing background Introduce some queuing
Cluster Computing. Resource and Job Management for HPC 16/08/2010 SC-CAMP. ( SC-CAMP) Cluster Computing 16/08/ / 50
 Cluster Computing 16/08/ / 50") Cluster Computing Resource and Job Management for HPC SC-CAMP 16/08/2010 ( SC-CAMP) Cluster Computing 16/08/2010 1 / 50 Summary 1 Introduction Cluster Computing 2 About Resource and Job Management Systems
Cluster Computing Resource and Job Management for HPC SC-CAMP 16/08/2010 ( SC-CAMP) Cluster Computing 16/08/2010 1 / 50 Summary 1 Introduction Cluster Computing 2 About Resource and Job Management Systems
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine
 Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Introduction to Slurm
 Introduction to Slurm Tim Wickberg SchedMD Slurm User Group Meeting 2017 Outline Roles of resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm configuration
Introduction to Slurm Tim Wickberg SchedMD Slurm User Group Meeting 2017 Outline Roles of resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm configuration
PBS PROFESSIONAL VS. MICROSOFT HPC PACK
 PBS PROFESSIONAL VS. MICROSOFT HPC PACK On the Microsoft Windows Platform PBS Professional offers many features which are not supported by Microsoft HPC Pack. SOME OF THE IMPORTANT ADVANTAGES OF PBS PROFESSIONAL
PBS PROFESSIONAL VS. MICROSOFT HPC PACK On the Microsoft Windows Platform PBS Professional offers many features which are not supported by Microsoft HPC Pack. SOME OF THE IMPORTANT ADVANTAGES OF PBS PROFESSIONAL
Unifying Heterogeneous Resources Moab Con Scott Jackson Engineering
 Unifying Heterogeneous Resources Moab Con 2009 Scott Jackson Engineering Overview Introduction Heterogeneous Resources w/in the Cluster Disparate Clusters -- Multiple Resource Managers Disparate Clusters
Unifying Heterogeneous Resources Moab Con 2009 Scott Jackson Engineering Overview Introduction Heterogeneous Resources w/in the Cluster Disparate Clusters -- Multiple Resource Managers Disparate Clusters
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
OpenPBS Users Manual
 How to Write a PBS Batch Script OpenPBS Users Manual PBS scripts are rather simple. An MPI example for user your-user-name: Example: MPI Code PBS -N a_name_for_my_parallel_job PBS -l nodes=7,walltime=1:00:00
How to Write a PBS Batch Script OpenPBS Users Manual PBS scripts are rather simple. An MPI example for user your-user-name: Example: MPI Code PBS -N a_name_for_my_parallel_job PBS -l nodes=7,walltime=1:00:00
and how to use TORQUE & Maui Piero Calucci
 Queue and how to use & Maui Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 We Are Trying to Solve 2 Using the Manager
Queue and how to use & Maui Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 We Are Trying to Solve 2 Using the Manager
Queue systems. and how to use Torque/Maui. Piero Calucci. Scuola Internazionale Superiore di Studi Avanzati Trieste
 Queue systems and how to use Torque/Maui Piero Calucci Scuola Internazionale Superiore di Studi Avanzati Trieste March 9th 2007 Advanced School in High Performance Computing Tools for e-science Outline
Queue systems and how to use Torque/Maui Piero Calucci Scuola Internazionale Superiore di Studi Avanzati Trieste March 9th 2007 Advanced School in High Performance Computing Tools for e-science Outline
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Batch Systems. Running calculations on HPC resources
 Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Slurm Overview. Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17. Copyright 2017 SchedMD LLC
 Slurm Overview Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17 Outline Roles of a resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm
Slurm Overview Brian Christiansen, Marshall Garey, Isaac Hartung SchedMD SC17 Outline Roles of a resource manager and job scheduler Slurm description and design goals Slurm architecture and plugins Slurm
Reduces latency and buffer overhead. Messaging occurs at a speed close to the processors being directly connected. Less error detection
 Switching Operational modes: Store-and-forward: Each switch receives an entire packet before it forwards it onto the next switch - useful in a general purpose network (I.e. a LAN). usually, there is a
Switching Operational modes: Store-and-forward: Each switch receives an entire packet before it forwards it onto the next switch - useful in a general purpose network (I.e. a LAN). usually, there is a
Resource Managers, Schedulers, and Grid Computing
 Resource Managers, Schedulers, and Grid Computing James E. Prewett October 8, 2008 Outline Resource Managers Practical: TORQUE Installation and Configuration Schedulers Practical: Maui Installation and
Resource Managers, Schedulers, and Grid Computing James E. Prewett October 8, 2008 Outline Resource Managers Practical: TORQUE Installation and Configuration Schedulers Practical: Maui Installation and
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010
 Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Batch Systems. Running your jobs on an HPC machine
 Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Comparison of Scheduling Policies and Workloads on the NCCS and NICS XT4 Systems at Oak Ridge National Laboratory
 Comparison of Scheduling Policies and Workloads on the NCCS and NICS XT4 Systems at Oak Ridge National Laboratory Troy Baer HPC System Administrator National Institute for Computational Sciences University
Comparison of Scheduling Policies and Workloads on the NCCS and NICS XT4 Systems at Oak Ridge National Laboratory Troy Baer HPC System Administrator National Institute for Computational Sciences University
Batch Scheduling on XT3
 Batch Scheduling on XT3 Chad Vizino Pittsburgh Supercomputing Center Overview Simon Scheduler Design Features XT3 Scheduling at PSC Past Present Future Back to the Future! Scheduler Design
Batch Scheduling on XT3 Chad Vizino Pittsburgh Supercomputing Center Overview Simon Scheduler Design Features XT3 Scheduling at PSC Past Present Future Back to the Future! Scheduler Design
Using Quality of Service for Scheduling on Cray XT Systems
 Using Quality of Service for Scheduling on Cray XT Systems Troy Baer HPC System Administrator National Institute for Computational Sciences, University of Tennessee Outline Introduction Scheduling Cray
Using Quality of Service for Scheduling on Cray XT Systems Troy Baer HPC System Administrator National Institute for Computational Sciences, University of Tennessee Outline Introduction Scheduling Cray
A Brief Introduction to The Center for Advanced Computing
 A Brief Introduction to The Center for Advanced Computing November 10, 2009 Outline 1 Resources Hardware Software 2 Mechanics: Access Transferring files and data to and from the clusters Logging into the
A Brief Introduction to The Center for Advanced Computing November 10, 2009 Outline 1 Resources Hardware Software 2 Mechanics: Access Transferring files and data to and from the clusters Logging into the
NUSGRID a computational grid at NUS
 NUSGRID a computational grid at NUS Grace Foo (SVU/Academic Computing, Computer Centre) SVU is leading an initiative to set up a campus wide computational grid prototype at NUS. The initiative arose out
NUSGRID a computational grid at NUS Grace Foo (SVU/Academic Computing, Computer Centre) SVU is leading an initiative to set up a campus wide computational grid prototype at NUS. The initiative arose out
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
Parallel File Systems Compared
 Parallel File Systems Compared Computing Centre (SSCK) University of Karlsruhe, Germany Laifer@rz.uni-karlsruhe.de page 1 Outline» Parallel file systems (PFS) Design and typical usage Important features
Parallel File Systems Compared Computing Centre (SSCK) University of Karlsruhe, Germany Laifer@rz.uni-karlsruhe.de page 1 Outline» Parallel file systems (PFS) Design and typical usage Important features
Moab, TORQUE, and Gold in a Heterogeneous, Federated Computing System at the University of Michigan
 Moab, TORQUE, and Gold in a Heterogeneous, Federated Computing System at the University of Michigan Andrew Caird Matthew Britt Brock Palen September 18, 2009 Who We Are College of Engineering centralized
Moab, TORQUE, and Gold in a Heterogeneous, Federated Computing System at the University of Michigan Andrew Caird Matthew Britt Brock Palen September 18, 2009 Who We Are College of Engineering centralized
Future Trends in Hardware and Software for use in Simulation
 Future Trends in Hardware and Software for use in Simulation Steve Feldman VP/IT, CD-adapco April, 2009 HighPerformanceComputing Building Blocks CPU I/O Interconnect Software General CPU Maximum clock
Future Trends in Hardware and Software for use in Simulation Steve Feldman VP/IT, CD-adapco April, 2009 HighPerformanceComputing Building Blocks CPU I/O Interconnect Software General CPU Maximum clock
SLURM Operation on Cray XT and XE
 SLURM Operation on Cray XT and XE Morris Jette jette@schedmd.com Contributors and Collaborators This work was supported by the Oak Ridge National Laboratory Extreme Scale Systems Center. Swiss National
SLURM Operation on Cray XT and XE Morris Jette jette@schedmd.com Contributors and Collaborators This work was supported by the Oak Ridge National Laboratory Extreme Scale Systems Center. Swiss National
Cheese Cluster Training
 Cheese Cluster Training The Biostatistics Computer Committee (BCC) Anjishnu Banerjee Dan Eastwood Chris Edwards Michael Martens Rodney Sparapani Sergey Tarima and The Research Computing Center (RCC) Matthew
Cheese Cluster Training The Biostatistics Computer Committee (BCC) Anjishnu Banerjee Dan Eastwood Chris Edwards Michael Martens Rodney Sparapani Sergey Tarima and The Research Computing Center (RCC) Matthew
LSF HPC :: getting most out of your NUMA machine
 Leopold-Franzens-Universität Innsbruck ZID Zentraler Informatikdienst (ZID) LSF HPC :: getting most out of your NUMA machine platform computing conference, Michael Fink who we are & what we do university
Leopold-Franzens-Universität Innsbruck ZID Zentraler Informatikdienst (ZID) LSF HPC :: getting most out of your NUMA machine platform computing conference, Michael Fink who we are & what we do university
1 Obtaining and compiling TORQUE and Maui
 1 Obtaining and compiling TORQUE and Maui Obtaining and compiling TORQUE TORQUE Source Code TORQUE is available from www.clusterresources.com Building TORQUE configure --prefix=/whatever/you/likemakemake
1 Obtaining and compiling TORQUE and Maui Obtaining and compiling TORQUE TORQUE Source Code TORQUE is available from www.clusterresources.com Building TORQUE configure --prefix=/whatever/you/likemakemake
Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide
 - Linux Getting Started Guide") Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide Introduction What are the intended uses of the MTL? The MTL is prioritized for supporting the Intel Academic Community for the testing, validation
Intel Manycore Testing Lab (MTL) - Linux Getting Started Guide Introduction What are the intended uses of the MTL? The MTL is prioritized for supporting the Intel Academic Community for the testing, validation
An Integrated Approach to Workload and Cluster Management: The HP CMU PBS Professional Connector
 An Integrated Approach to Workload and Cluster Management: The HP CMU PBS Professional Connector Scott Suchyta Altair Engineering Inc., 1820 Big Beaver Road, Troy, MI 48083, USA Contents 1 Abstract...
An Integrated Approach to Workload and Cluster Management: The HP CMU PBS Professional Connector Scott Suchyta Altair Engineering Inc., 1820 Big Beaver Road, Troy, MI 48083, USA Contents 1 Abstract...
HTCondor on Titan. Wisconsin IceCube Particle Astrophysics Center. Vladimir Brik. HTCondor Week May 2018
 HTCondor on Titan Wisconsin IceCube Particle Astrophysics Center Vladimir Brik HTCondor Week May 2018 Overview of Titan Cray XK7 Supercomputer at Oak Ridge Leadership Computing Facility Ranked #5 by TOP500
HTCondor on Titan Wisconsin IceCube Particle Astrophysics Center Vladimir Brik HTCondor Week May 2018 Overview of Titan Cray XK7 Supercomputer at Oak Ridge Leadership Computing Facility Ranked #5 by TOP500
OAR batch scheduler and scheduling on Grid'5000
 http://oar.imag.fr OAR batch scheduler and scheduling on Grid'5000 Olivier Richard (UJF/INRIA) joint work with Nicolas Capit, Georges Da Costa, Yiannis Georgiou, Guillaume Huard, Cyrille Martin, Gregory
http://oar.imag.fr OAR batch scheduler and scheduling on Grid'5000 Olivier Richard (UJF/INRIA) joint work with Nicolas Capit, Georges Da Costa, Yiannis Georgiou, Guillaume Huard, Cyrille Martin, Gregory
Resource Management at LLNL SLURM Version 1.2
 UCRL PRES 230170 Resource Management at LLNL SLURM Version 1.2 April 2007 Morris Jette (jette1@llnl.gov) Danny Auble (auble1@llnl.gov) Chris Morrone (morrone2@llnl.gov) Lawrence Livermore National Laboratory
UCRL PRES 230170 Resource Management at LLNL SLURM Version 1.2 April 2007 Morris Jette (jette1@llnl.gov) Danny Auble (auble1@llnl.gov) Chris Morrone (morrone2@llnl.gov) Lawrence Livermore National Laboratory
1 Bull, 2011 Bull Extreme Computing
 1 Bull, 2011 Bull Extreme Computing Table of Contents Overview. Principal concepts. Architecture. Scheduler Policies. 2 Bull, 2011 Bull Extreme Computing SLURM Overview Ares, Gerardo, HPC Team Introduction
1 Bull, 2011 Bull Extreme Computing Table of Contents Overview. Principal concepts. Architecture. Scheduler Policies. 2 Bull, 2011 Bull Extreme Computing SLURM Overview Ares, Gerardo, HPC Team Introduction
RHRK-Seminar. High Performance Computing with the Cluster Elwetritsch - II. Course instructor : Dr. Josef Schüle, RHRK
 RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
RHRK-Seminar High Performance Computing with the Cluster Elwetritsch - II Course instructor : Dr. Josef Schüle, RHRK Overview Course I Login to cluster SSH RDP / NX Desktop Environments GNOME (default)
Trust Separation on the XC40 using PBS Pro
 Trust Separation on the XC40 using PBS Pro Sam Clarke May 2017 Overview About the Met Office workload Trust zone design Node configuration Lustre implementation PBS Implementation Use of hooks Placement
Trust Separation on the XC40 using PBS Pro Sam Clarke May 2017 Overview About the Met Office workload Trust zone design Node configuration Lustre implementation PBS Implementation Use of hooks Placement
Cray events. ! Cray User Group (CUG): ! Cray Technical Workshop Europe:
: ! Cray Technical Workshop Europe:") Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Slurm basics. Summer Kickstart June slide 1 of 49
 Slurm basics Summer Kickstart 2017 June 2017 slide 1 of 49 Triton layers Triton is a powerful but complex machine. You have to consider: Connecting (ssh) Data storage (filesystems and Lustre) Resource
Slurm basics Summer Kickstart 2017 June 2017 slide 1 of 49 Triton layers Triton is a powerful but complex machine. You have to consider: Connecting (ssh) Data storage (filesystems and Lustre) Resource
CENTER FOR HIGH PERFORMANCE COMPUTING. Overview of CHPC. Martin Čuma, PhD. Center for High Performance Computing
 Overview of CHPC Martin Čuma, PhD Center for High Performance Computing m.cuma@utah.edu Spring 2014 Overview CHPC Services HPC Clusters Specialized computing resources Access and Security Batch (PBS and
Overview of CHPC Martin Čuma, PhD Center for High Performance Computing m.cuma@utah.edu Spring 2014 Overview CHPC Services HPC Clusters Specialized computing resources Access and Security Batch (PBS and
Use of Common Technologies between XT and Black Widow
 Use of Common Technologies between XT and Black Widow CUG 2006 This Presentation May Contain Some Preliminary Information, Subject To Change Agenda System Architecture Directions Software Development and
Use of Common Technologies between XT and Black Widow CUG 2006 This Presentation May Contain Some Preliminary Information, Subject To Change Agenda System Architecture Directions Software Development and
Compiling applications for the Cray XC
 Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
Compiling applications for the Cray XC Compiler Driver Wrappers (1) All applications that will run in parallel on the Cray XC should be compiled with the standard language wrappers. The compiler drivers
An Advance Reservation-Based Computation Resource Manager for Global Scheduling
 An Advance Reservation-Based Computation Resource Manager for Global Scheduling 1.National Institute of Advanced Industrial Science and Technology, 2 Suuri Giken Hidemoto Nakada 1, Atsuko Takefusa 1, Katsuhiko
An Advance Reservation-Based Computation Resource Manager for Global Scheduling 1.National Institute of Advanced Industrial Science and Technology, 2 Suuri Giken Hidemoto Nakada 1, Atsuko Takefusa 1, Katsuhiko
Readme for Platform Open Cluster Stack (OCS)
") Readme for Platform Open Cluster Stack (OCS) Version 4.1.1-2.0 October 25 2006 Platform Computing Contents What is Platform OCS? What's New in Platform OCS 4.1.1-2.0? Supported Architecture Distribution
Readme for Platform Open Cluster Stack (OCS) Version 4.1.1-2.0 October 25 2006 Platform Computing Contents What is Platform OCS? What's New in Platform OCS 4.1.1-2.0? Supported Architecture Distribution
Your Microservice Layout
 Your Microservice Layout Data Ingestor Storm Detection Algorithm Storm Clustering Algorithm Storms Exist No Stop UI API Gateway Yes Registry Run Weather Forecast Many of these steps are actually very computationally
Your Microservice Layout Data Ingestor Storm Detection Algorithm Storm Clustering Algorithm Storms Exist No Stop UI API Gateway Yes Registry Run Weather Forecast Many of these steps are actually very computationally
Designing a Cluster for a Small Research Group
 Designing a Cluster for a Small Research Group Jim Phillips, John Stone, Tim Skirvin Low-cost Linux Clusters for Biomolecular Simulations Using NAMD Outline Why and why not clusters? Consider your Users
Designing a Cluster for a Small Research Group Jim Phillips, John Stone, Tim Skirvin Low-cost Linux Clusters for Biomolecular Simulations Using NAMD Outline Why and why not clusters? Consider your Users
ECE 574 Cluster Computing Lecture 4
 ECE 574 Cluster Computing Lecture 4 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 31 January 2017 Announcements Don t forget about homework #3 I ran HPCG benchmark on Haswell-EP
ECE 574 Cluster Computing Lecture 4 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 31 January 2017 Announcements Don t forget about homework #3 I ran HPCG benchmark on Haswell-EP
Porting SLURM to the Cray XT and XE. Neil Stringfellow and Gerrit Renker
 Porting SLURM to the Cray XT and XE Neil Stringfellow and Gerrit Renker Background Cray XT/XE basics Cray XT systems are among the largest in the world 9 out of the top 30 machines on the top500 list June
Porting SLURM to the Cray XT and XE Neil Stringfellow and Gerrit Renker Background Cray XT/XE basics Cray XT systems are among the largest in the world 9 out of the top 30 machines on the top500 list June
Moab Passthrough. Administrator Guide February 2018
 Moab Passthrough Administrator Guide 9.1.2 February 2018 2018 Adaptive Computing Enterprises, Inc. All rights reserved. Distribution of this document for commercial purposes in either hard or soft copy
Moab Passthrough Administrator Guide 9.1.2 February 2018 2018 Adaptive Computing Enterprises, Inc. All rights reserved. Distribution of this document for commercial purposes in either hard or soft copy
Cluster Distributions Review
 Cluster Distributions Review Emir Imamagi Damir Danijel Žagar Department of Computer Systems, University Computing Centre, Croatia {eimamagi, dzagar}@srce.hr Abstract Computer cluster is a set of individual
Cluster Distributions Review Emir Imamagi Damir Danijel Žagar Department of Computer Systems, University Computing Centre, Croatia {eimamagi, dzagar}@srce.hr Abstract Computer cluster is a set of individual
Using the IAC Chimera Cluster
 Using the IAC Chimera Cluster Ángel de Vicente (Tel.: x5387) SIE de Investigación y Enseñanza Chimera overview Beowulf type cluster Chimera: a monstrous creature made of the parts of multiple animals.
Using the IAC Chimera Cluster Ángel de Vicente (Tel.: x5387) SIE de Investigación y Enseñanza Chimera overview Beowulf type cluster Chimera: a monstrous creature made of the parts of multiple animals.
Grid Scheduling Architectures with Globus
 Grid Scheduling Architectures with Workshop on Scheduling WS 07 Cetraro, Italy July 28, 2007 Ignacio Martin Llorente Distributed Systems Architecture Group Universidad Complutense de Madrid 1/38 Contents
Grid Scheduling Architectures with Workshop on Scheduling WS 07 Cetraro, Italy July 28, 2007 Ignacio Martin Llorente Distributed Systems Architecture Group Universidad Complutense de Madrid 1/38 Contents
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Introduction to Discovery http://discovery.dartmouth.edu The Discovery Cluster 2 Agenda What is a cluster and why use it Overview of computer hardware in cluster Help Available to Discovery Users Logging
Lecture Topics. Announcements. Today: Advanced Scheduling (Stallings, chapter ) Next: Deadlock (Stallings, chapter
 Next: Deadlock (Stallings, chapter") Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Introduction to High-Performance Computing (HPC)
") Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit cores : individual processing units within a CPU Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
IRIX Resource Management Plans & Status
 IRIX Resource Management Plans & Status Dan Higgins Engineering Manager, Resource Management Team, SGI E-mail: djh@sgi.com CUG Minneapolis, May 1999 Abstract This paper will detail what work has been done
IRIX Resource Management Plans & Status Dan Higgins Engineering Manager, Resource Management Team, SGI E-mail: djh@sgi.com CUG Minneapolis, May 1999 Abstract This paper will detail what work has been done
Sharpen Exercise: Using HPC resources and running parallel applications
 Sharpen Exercise: Using HPC resources and running parallel applications Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into ARCHER frontend nodes and run commands.... 3 3.2 Download and extract
Sharpen Exercise: Using HPC resources and running parallel applications Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into ARCHER frontend nodes and run commands.... 3 3.2 Download and extract
Running Jobs on Blue Waters. Greg Bauer
 Running Jobs on Blue Waters Greg Bauer Policies and Practices Placement Checkpointing Monitoring a job Getting a nodelist Viewing the torus 2 Resource and Job Scheduling Policies Runtime limits expected
Running Jobs on Blue Waters Greg Bauer Policies and Practices Placement Checkpointing Monitoring a job Getting a nodelist Viewing the torus 2 Resource and Job Scheduling Policies Runtime limits expected
The University of Michigan Center for Advanced Computing
 The University of Michigan Center for Advanced Computing Andy Caird acaird@umich.edu The University of MichiganCenter for Advanced Computing p.1/29 The CAC What is the Center for Advanced Computing? we
The University of Michigan Center for Advanced Computing Andy Caird acaird@umich.edu The University of MichiganCenter for Advanced Computing p.1/29 The CAC What is the Center for Advanced Computing? we
A Brief Introduction to The Center for Advanced Computing
 A Brief Introduction to The Center for Advanced Computing May 1, 2006 Hardware 324 Opteron nodes, over 700 cores 105 Athlon nodes, 210 cores 64 Apple nodes, 128 cores Gigabit networking, Myrinet networking,
A Brief Introduction to The Center for Advanced Computing May 1, 2006 Hardware 324 Opteron nodes, over 700 cores 105 Athlon nodes, 210 cores 64 Apple nodes, 128 cores Gigabit networking, Myrinet networking,
Enabling Contiguous Node Scheduling on the Cray XT3
 Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino vizino@psc.edu Pittsburgh Supercomputing Center ABSTRACT: The Pittsburgh Supercomputing Center has enabled contiguous node scheduling to
Enabling Contiguous Node Scheduling on the Cray XT3 Chad Vizino vizino@psc.edu Pittsburgh Supercomputing Center ABSTRACT: The Pittsburgh Supercomputing Center has enabled contiguous node scheduling to
Slurm Birds of a Feather
 Slurm Birds of a Feather Tim Wickberg SchedMD SC17 Outline Welcome Roadmap Review of 17.02 release (Februrary 2017) Overview of upcoming 17.11 (November 2017) release Roadmap for 18.08 and beyond Time
Slurm Birds of a Feather Tim Wickberg SchedMD SC17 Outline Welcome Roadmap Review of 17.02 release (Februrary 2017) Overview of upcoming 17.11 (November 2017) release Roadmap for 18.08 and beyond Time
OBTAINING AN ACCOUNT:
 HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
HPC Usage Policies The IIA High Performance Computing (HPC) System is managed by the Computer Management Committee. The User Policies here were developed by the Committee. The user policies below aim to
Sherlock for IBIIS. William Law Stanford Research Computing
 Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Introduction to the Cluster
 Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu Follow us on Twitter for important news and updates: @ACCREVandy The Cluster We will be
Introduction to the Cluster Advanced Computing Center for Research and Education http://www.accre.vanderbilt.edu Follow us on Twitter for important news and updates: @ACCREVandy The Cluster We will be
Compilation and Parallel Start
 Compiling MPI Programs Programming with MPI Compiling and running MPI programs Type to enter text Jan Thorbecke Delft University of Technology 2 Challenge the future Compiling and Starting MPI Jobs Compiling:
Compiling MPI Programs Programming with MPI Compiling and running MPI programs Type to enter text Jan Thorbecke Delft University of Technology 2 Challenge the future Compiling and Starting MPI Jobs Compiling:
ACCRE High Performance Compute Cluster
 6 중 1 2010-05-16 오후 1:44 Enabling Researcher-Driven Innovation and Exploration Mission / Services Research Publications User Support Education / Outreach A - Z Index Our Mission History Governance Services
6 중 1 2010-05-16 오후 1:44 Enabling Researcher-Driven Innovation and Exploration Mission / Services Research Publications User Support Education / Outreach A - Z Index Our Mission History Governance Services
Working on the NewRiver Cluster
 Working on the NewRiver Cluster CMDA3634: Computer Science Foundations for Computational Modeling and Data Analytics 22 February 2018 NewRiver is a computing cluster provided by Virginia Tech s Advanced
Working on the NewRiver Cluster CMDA3634: Computer Science Foundations for Computational Modeling and Data Analytics 22 February 2018 NewRiver is a computing cluster provided by Virginia Tech s Advanced
CS500 SMARTER CLUSTER SUPERCOMPUTERS
 CS500 SMARTER CLUSTER SUPERCOMPUTERS OVERVIEW Extending the boundaries of what you can achieve takes reliable computing tools matched to your workloads. That s why we tailor the Cray CS500 cluster supercomputer
CS500 SMARTER CLUSTER SUPERCOMPUTERS OVERVIEW Extending the boundaries of what you can achieve takes reliable computing tools matched to your workloads. That s why we tailor the Cray CS500 cluster supercomputer
XSEDE New User Tutorial
 April 2, 2014 XSEDE New User Tutorial Jay Alameda National Center for Supercomputing Applications XSEDE Training Survey Make sure you sign the sign in sheet! At the end of the module, I will ask you to
April 2, 2014 XSEDE New User Tutorial Jay Alameda National Center for Supercomputing Applications XSEDE Training Survey Make sure you sign the sign in sheet! At the end of the module, I will ask you to
with TORQUE & Maui Piero Calucci
 Setting up with & Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 2 3 Source Code is available from www.clusterresources.com
Setting up with & Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 2 3 Source Code is available from www.clusterresources.com
ICAT Job Portal. a generic job submission system built on a scientific data catalog. IWSG 2013 ETH, Zurich, Switzerland 3-5 June 2013
 ICAT Job Portal a generic job submission system built on a scientific data catalog IWSG 2013 ETH, Zurich, Switzerland 3-5 June 2013 Steve Fisher, Kevin Phipps and Dan Rolfe Rutherford Appleton Laboratory
ICAT Job Portal a generic job submission system built on a scientific data catalog IWSG 2013 ETH, Zurich, Switzerland 3-5 June 2013 Steve Fisher, Kevin Phipps and Dan Rolfe Rutherford Appleton Laboratory
MyCloud Computing Business computing in the cloud, ready to go in minutes
 MyCloud Computing Business computing in the cloud, ready to go in minutes In today s dynamic environment, businesses need to be able to respond quickly to changing demands. Using virtualised computing
MyCloud Computing Business computing in the cloud, ready to go in minutes In today s dynamic environment, businesses need to be able to respond quickly to changing demands. Using virtualised computing
Shared File System Requirements for SAS Grid Manager. Table Talk #1546 Ben Smith / Brian Porter
 Shared File System Requirements for SAS Grid Manager Table Talk #1546 Ben Smith / Brian Porter About the Presenters Main Presenter: Ben Smith, Technical Solutions Architect, IBM smithbe1@us.ibm.com Brian
Shared File System Requirements for SAS Grid Manager Table Talk #1546 Ben Smith / Brian Porter About the Presenters Main Presenter: Ben Smith, Technical Solutions Architect, IBM smithbe1@us.ibm.com Brian
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016
 1/18/2016") Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
Batch environment PBS (Running applications on the Cray XC30) 1/18/2016 1 Running on compute nodes By default, users do not log in and run applications on the compute nodes directly. Instead they launch
MPI versions. MPI History
 MPI versions MPI History Standardization started (1992) MPI-1 completed (1.0) (May 1994) Clarifications (1.1) (June 1995) MPI-2 (started: 1995, finished: 1997) MPI-2 book 1999 MPICH 1.2.4 partial implemention
MPI versions MPI History Standardization started (1992) MPI-1 completed (1.0) (May 1994) Clarifications (1.1) (June 1995) MPI-2 (started: 1995, finished: 1997) MPI-2 book 1999 MPICH 1.2.4 partial implemention
MPI History. MPI versions MPI-2 MPICH2
 MPI versions MPI History Standardization started (1992) MPI-1 completed (1.0) (May 1994) Clarifications (1.1) (June 1995) MPI-2 (started: 1995, finished: 1997) MPI-2 book 1999 MPICH 1.2.4 partial implemention
MPI versions MPI History Standardization started (1992) MPI-1 completed (1.0) (May 1994) Clarifications (1.1) (June 1995) MPI-2 (started: 1995, finished: 1997) MPI-2 book 1999 MPICH 1.2.4 partial implemention
Outline. March 5, 2012 CIRMMT - McGill University 2
 Outline CLUMEQ, Calcul Quebec and Compute Canada Research Support Objectives and Focal Points CLUMEQ Site at McGill ETS Key Specifications and Status CLUMEQ HPC Support Staff at McGill Getting Started
Outline CLUMEQ, Calcul Quebec and Compute Canada Research Support Objectives and Focal Points CLUMEQ Site at McGill ETS Key Specifications and Status CLUMEQ HPC Support Staff at McGill Getting Started
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Minnesota Supercomputing Institute Introduction to MSI Systems Andrew Gustafson The Machines at MSI Machine Type: Cluster Source: http://en.wikipedia.org/wiki/cluster_%28computing%29 Machine Type: Cluster
Native SLURM on Cray XC30. SLURM Birds of a Feather SC 13
 Native on Cray XC30 Birds of a Feather SC 13 What s being offered? / ALPS The current open source version available on the SchedMD/ web page 2.6 validated for Cray systems Basic WLM functions This version
Native on Cray XC30 Birds of a Feather SC 13 What s being offered? / ALPS The current open source version available on the SchedMD/ web page 2.6 validated for Cray systems Basic WLM functions This version
Bright Cluster Manager Advanced HPC cluster management made easy. Martijn de Vries CTO Bright Computing
 Bright Cluster Manager Advanced HPC cluster management made easy Martijn de Vries CTO Bright Computing About Bright Computing Bright Computing 1. Develops and supports Bright Cluster Manager for HPC systems
Bright Cluster Manager Advanced HPC cluster management made easy Martijn de Vries CTO Bright Computing About Bright Computing Bright Computing 1. Develops and supports Bright Cluster Manager for HPC systems
Platform LSF Version 9 Release 1.1. Foundations SC
 Platform LSF Version 9 Release 1.1 Foundations SC27-5304-01 Platform LSF Version 9 Release 1.1 Foundations SC27-5304-01 Note Before using this information and the product it supports, read the information
Platform LSF Version 9 Release 1.1 Foundations SC27-5304-01 Platform LSF Version 9 Release 1.1 Foundations SC27-5304-01 Note Before using this information and the product it supports, read the information
Table of Contents. Table of Contents Job Manager for remote execution of QuantumATK scripts. A single remote machine
 Table of Contents Table of Contents Job Manager for remote execution of QuantumATK scripts A single remote machine Settings Environment Resources Notifications Diagnostics Save and test the new machine
Table of Contents Table of Contents Job Manager for remote execution of QuantumATK scripts A single remote machine Settings Environment Resources Notifications Diagnostics Save and test the new machine
XSEDE New User Training. Ritu Arora November 14, 2014
 XSEDE New User Training Ritu Arora Email: rauta@tacc.utexas.edu November 14, 2014 1 Objectives Provide a brief overview of XSEDE Computational, Visualization and Storage Resources Extended Collaborative
XSEDE New User Training Ritu Arora Email: rauta@tacc.utexas.edu November 14, 2014 1 Objectives Provide a brief overview of XSEDE Computational, Visualization and Storage Resources Extended Collaborative
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
Minnesota Supercomputing Institute Introduction to Job Submission and Scheduling Andrew Gustafson Interacting with MSI Systems Connecting to MSI SSH is the most reliable connection method Linux and Mac
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Setting up Queue Systems
 Setting up Queue Systems with TORQUE & Maui Piero Calucci Scuola Internazionale Superiore di Studi Avanzati Trieste March 14th 2007 Advanced School in High Performance Computing Tools for e-science Outline
Setting up Queue Systems with TORQUE & Maui Piero Calucci Scuola Internazionale Superiore di Studi Avanzati Trieste March 14th 2007 Advanced School in High Performance Computing Tools for e-science Outline
Introduction to Discovery.
 Introduction to Discovery http://discovery.dartmouth.edu March 2014 The Discovery Cluster 2 Agenda Resource overview Logging on to the cluster with ssh Transferring files to and from the cluster The Environment
Introduction to Discovery http://discovery.dartmouth.edu March 2014 The Discovery Cluster 2 Agenda Resource overview Logging on to the cluster with ssh Transferring files to and from the cluster The Environment
Workload management at KEK/CRC -- status and plan
 Workload management at KEK/CRC -- status and plan KEK/CRC Hiroyuki Matsunaga Most of the slides are prepared by Koichi Murakami and Go Iwai CPU in KEKCC Work server & Batch server Xeon 5670 (2.93 GHz /
Workload management at KEK/CRC -- status and plan KEK/CRC Hiroyuki Matsunaga Most of the slides are prepared by Koichi Murakami and Go Iwai CPU in KEKCC Work server & Batch server Xeon 5670 (2.93 GHz /
Introduction to HPC Using the New Cluster at GACRC
 Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Introduction to HPC Using the New Cluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is the new cluster
Open SpeedShop Capabilities and Internal Structure: Current to Petascale. CScADS Workshop, July 16-20, 2007 Jim Galarowicz, Krell Institute
 1 Open Source Performance Analysis for Large Scale Systems Open SpeedShop Capabilities and Internal Structure: Current to Petascale CScADS Workshop, July 16-20, 2007 Jim Galarowicz, Krell Institute 2 Trademark
1 Open Source Performance Analysis for Large Scale Systems Open SpeedShop Capabilities and Internal Structure: Current to Petascale CScADS Workshop, July 16-20, 2007 Jim Galarowicz, Krell Institute 2 Trademark
How to Use a Supercomputer - A Boot Camp
 How to Use a Supercomputer - A Boot Camp Shelley Knuth Peter Ruprecht shelley.knuth@colorado.edu peter.ruprecht@colorado.edu www.rc.colorado.edu Outline Today we will discuss: Who Research Computing is
How to Use a Supercomputer - A Boot Camp Shelley Knuth Peter Ruprecht shelley.knuth@colorado.edu peter.ruprecht@colorado.edu www.rc.colorado.edu Outline Today we will discuss: Who Research Computing is
High Performance Computing (HPC) Club Training Session. Xinsheng (Shawn) Qin
 Club Training Session. Xinsheng (Shawn) Qin") High Performance Computing (HPC) Club Training Session Xinsheng (Shawn) Qin Outline HPC Club The Hyak Supercomputer Logging in to Hyak Basic Linux Commands Transferring Files Between Your PC and Hyak Submitting
High Performance Computing (HPC) Club Training Session Xinsheng (Shawn) Qin Outline HPC Club The Hyak Supercomputer Logging in to Hyak Basic Linux Commands Transferring Files Between Your PC and Hyak Submitting
First evaluation of the Globus GRAM Service. Massimo Sgaravatto INFN Padova
 First evaluation of the Globus GRAM Service Massimo Sgaravatto INFN Padova massimo.sgaravatto@pd.infn.it Draft version release 1.0.5 20 June 2000 1 Introduction...... 3 2 Running jobs... 3 2.1 Usage examples.
First evaluation of the Globus GRAM Service Massimo Sgaravatto INFN Padova massimo.sgaravatto@pd.infn.it Draft version release 1.0.5 20 June 2000 1 Introduction...... 3 2 Running jobs... 3 2.1 Usage examples.
Sharpen Exercise: Using HPC resources and running parallel applications
 Sharpen Exercise: Using HPC resources and running parallel applications Andrew Turner, Dominic Sloan-Murphy, David Henty, Adrian Jackson Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into
Sharpen Exercise: Using HPC resources and running parallel applications Andrew Turner, Dominic Sloan-Murphy, David Henty, Adrian Jackson Contents 1 Aims 2 2 Introduction 2 3 Instructions 3 3.1 Log into
ELIMINATE SECURITY BLIND SPOTS WITH THE VENAFI AGENT
 ELIMINATE SECURITY BLIND SPOTS WITH THE VENAFI AGENT less discovery can t find all keys and certificates Key and certificate management is no longer just an IT function. So it cannot be treated the same
ELIMINATE SECURITY BLIND SPOTS WITH THE VENAFI AGENT less discovery can t find all keys and certificates Key and certificate management is no longer just an IT function. So it cannot be treated the same
Headline in Arial Bold 30pt. SGI Altix XE Server ANSYS Microsoft Windows Compute Cluster Server 2003
 Headline in Arial Bold 30pt SGI Altix XE Server ANSYS Microsoft Windows Compute Cluster Server 2003 SGI Altix XE Building Blocks XE Cluster Head Node Two dual core Xeon processors 16GB Memory SATA/SAS
Headline in Arial Bold 30pt SGI Altix XE Server ANSYS Microsoft Windows Compute Cluster Server 2003 SGI Altix XE Building Blocks XE Cluster Head Node Two dual core Xeon processors 16GB Memory SATA/SAS
Cray RS Programming Environment
 Cray RS Programming Environment Gail Alverson Cray Inc. Cray Proprietary Red Storm Red Storm is a supercomputer system leveraging over 10,000 AMD Opteron processors connected by an innovative high speed,
Cray RS Programming Environment Gail Alverson Cray Inc. Cray Proprietary Red Storm Red Storm is a supercomputer system leveraging over 10,000 AMD Opteron processors connected by an innovative high speed,