Web Archiving Workshop
|
|
|
- Dorothy Fleming
- 6 years ago
- Views:
Transcription
1 Web Archiving Workshop Mark Phillips Texas Conference on Digital Libraries June 4, 2008
2 Agenda 1:00 Welcome/Introductions 1:15 Introduction to Web Archiving History Concepts/Terms Examples 2:15 Collection Development Pt 1 3:00 Break 3:15 Collection Development Pt 2 4:00 Tools Overview Crawlers Display Search 4:45 Closing/Questions
3 Introductions Name: Institution: Level: Beginner, Moderate, Advanced Expectations: What did you want to leave today knowing that you don't already
4 Web Archiving History (according to Mark) 1996 Internet Archive 1996 Pandora 1996 CyberCemetery 1997 Nordic Web Archive 2000 Library of Congress: Minerva 2001 International Web Archiving Workshop 2003 International Internet Preservation Consortium 2004 Heritrix first release 2005 NDIIPP Web-At-Risk project starts 2005 Archive-It released 2006 Web Curator Tool 2008 Web Archiving Service
5 Concepts/Terms Crawler/Harvester/Spider Seed Robots Exclusion Protocol Surts Hops Crawler Traps Politeness ARC/WARC




6 Crawler/Harvester/Spider next URL in queue URL List URL Fetcher get URL Web Parser add URL to queue
7 Seed/entry-point URLs A URL appearing in a seed list as one of the starting addresses a web crawler uses to capture content. Seed for University of North Texas Web Harvest Seeds for 2004 End of Term Harvest URL's covering all branches of Federal government
8 Robots Exclusion Protocol Sometimes referred to as robots.txt Allows site owners to restrict content from being crawled by crawlers It is common to obey robots.txt directives, though there are exceptions (2100 lines long) Image folders
9 Surt Sort-friendly URI Reordering Transform Normalizes URLs for sorting purposes URL: SURT:
10 Hops A hop occurs when a crawler retrieves a URL based on a link found in another document. Link Hop Count = Number of links follow from the seed to the current URI. This is different than Levels
11 Levels Websites don't really have levels or depth. We think they do because all of us built a website at one time and we remember putting things in directories. We sometimes see this But we also see this
12 Levels (cont.) Link
13 hops 1 Link
14 Crawler Traps is a set of web pages that may intentionally or unintentionally cause a web crawler or search bot to make an infinite number of requests Calendars that have next buttons forever Content management systems Forums
15 Politeness Politeness refers to attempts by the crawler software to limit load on a site. adaptive politeness policy: if it took n seconds to download a document from a given server, the crawler waits for 2n seconds before downloading the next page.
16 arc/warc arc: Historic file format used by the internet archive for storing harvested web content. warc: New file format being developed by IIPC and others in attempts to create a standard for storing harvested web content
17 arc/warc (cont) Text format Concatenated bitstreams into a series of larger files. ~100 MB per file containing many (thousands) of smaller files. Contains metadata as well as content The only way that web archives are able to store millions and billions of files on a standard file system.
18 arc vs warc arc: older format, non standard, changed over time, more than 1.5 PB of legacy arc files warc: new format, standard, developed by many people, allows for more metadata to be collected, allows for other uses for the warc file format. Should lead to adoption by tools like wget and Httrack Heritrix has the option to write both formats.
19 Examples Internet Archive CyberCemetery Pandora Minerva Archive-it

20 Internet Archive
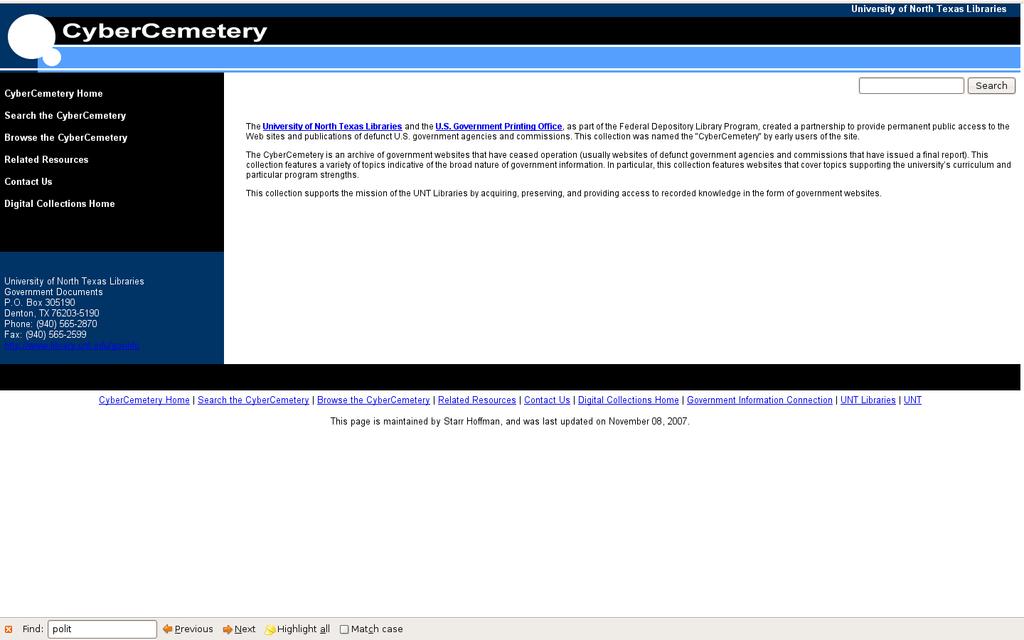
21 CyberCemetery

22 Pandora Archive

23 Library of Congress: Minerva
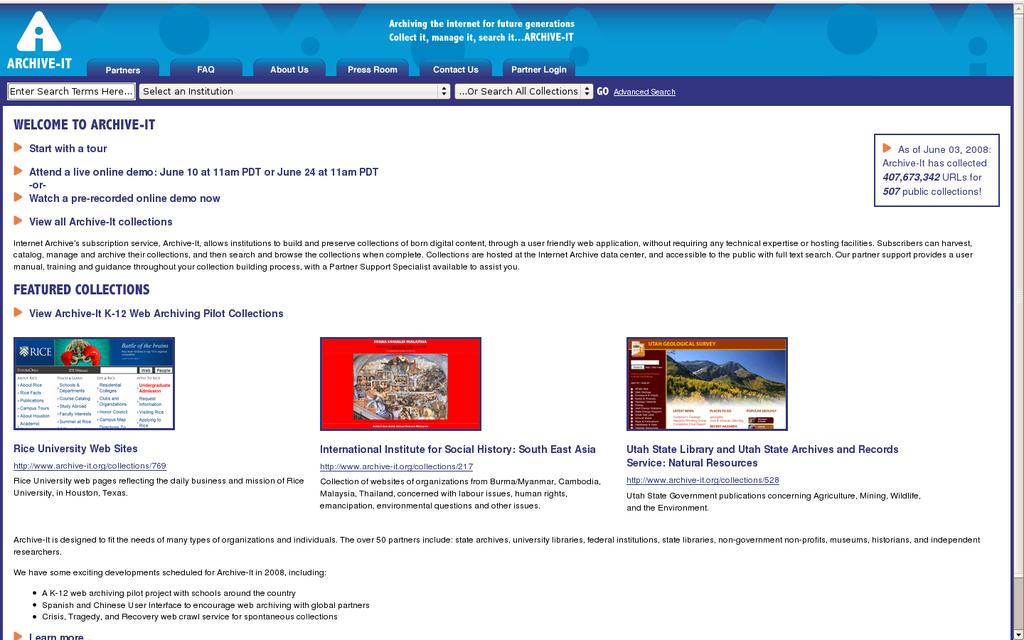
24 Archive-it
Web-Archiving: Collecting and Preserving Important Web-based National Resources
 Web-Archiving: Collecting and Preserving Important Web-based National Resources Mark Phillips Dr. Daniel Gelaw Alemneh University of North Texas UNT Libraries The Web is the platform for communication
Web-Archiving: Collecting and Preserving Important Web-based National Resources Mark Phillips Dr. Daniel Gelaw Alemneh University of North Texas UNT Libraries The Web is the platform for communication
Comparison of Web Archives created by HTTrack and Heritrix (H3) and the conversion of HTTrack Web Archives to the Web ARChive File Format (WARC)
 and the conversion of HTTrack Web Archives to the Web ARChive File Format (WARC)") Comparison of Web Archives created by HTTrack and Heritrix (H3) and the conversion of HTTrack Web Archives to the Web ARChive File Format (WARC) Barbara Löhle Bibliotheksservice-Zentrum Baden-Württemberg
Comparison of Web Archives created by HTTrack and Heritrix (H3) and the conversion of HTTrack Web Archives to the Web ARChive File Format (WARC) Barbara Löhle Bibliotheksservice-Zentrum Baden-Württemberg
Archiving and Preserving the Web. Kristine Hanna Internet Archive November 2006
 Archiving and Preserving the Web Kristine Hanna Internet Archive November 2006 1 About Internet Archive Non profit founded in 1996 by Brewster Kahle, as an Internet library Provide universal and permanent
Archiving and Preserving the Web Kristine Hanna Internet Archive November 2006 1 About Internet Archive Non profit founded in 1996 by Brewster Kahle, as an Internet library Provide universal and permanent
2008 DOT GOV HARVEST PRESERVING ACCESS
 2008 DOT GOV HARVEST PRESERVING ACCESS Cathy N. Hartman Mark E. Phillips FDLC Oct 21, 2008 UNIVERSITY OF NORTH TEXAS LIBRARIES Outline Project History Tool Building Partner Activities Future Work Project
2008 DOT GOV HARVEST PRESERVING ACCESS Cathy N. Hartman Mark E. Phillips FDLC Oct 21, 2008 UNIVERSITY OF NORTH TEXAS LIBRARIES Outline Project History Tool Building Partner Activities Future Work Project
NDSA Web Archiving Survey
 NDSA Web Archiving Survey Introduction In 2011 and 2013, the National Digital Stewardship Alliance (NDSA) conducted surveys of U.S. organizations currently or prospectively engaged in web archiving to
NDSA Web Archiving Survey Introduction In 2011 and 2013, the National Digital Stewardship Alliance (NDSA) conducted surveys of U.S. organizations currently or prospectively engaged in web archiving to
Archiving the Web: What can Institutions learn from National and International Web Archiving Initiatives
 Archiving the Web: What can Institutions learn from National and International Web Archiving Initiatives Maureen Pennock Michael Day Lizzie Richmond UKOLN University of Bath UKOLN University of Bath University
Archiving the Web: What can Institutions learn from National and International Web Archiving Initiatives Maureen Pennock Michael Day Lizzie Richmond UKOLN University of Bath UKOLN University of Bath University
Preserving Legal Blogs
 Preserving Legal Blogs Georgetown Law School Linda Frueh Internet Archive July 25, 2009 1 Contents 1. Intro to the Internet Archive All media The Web Archive 2. Where do blogs fit? 3. How are blogs collected?
Preserving Legal Blogs Georgetown Law School Linda Frueh Internet Archive July 25, 2009 1 Contents 1. Intro to the Internet Archive All media The Web Archive 2. Where do blogs fit? 3. How are blogs collected?
Preserving Public Government Information: The 2008 End of Term Crawl Project
 Preserving Public Government Information: The 2008 End of Term Crawl Project Abbie Grotke, Library of Congress Mark Phillips, University of North Texas Libraries George Barnum, U.S. Government Printing
Preserving Public Government Information: The 2008 End of Term Crawl Project Abbie Grotke, Library of Congress Mark Phillips, University of North Texas Libraries George Barnum, U.S. Government Printing
Web Archiving at UTL
 Web Archiving at UTL iskills workshops February 2018 Sam-chin Li Reference and Government Information Librarian, UTL Nich Worby Government Information and Statistics Librarian, UTL Agenda What is web archiving
Web Archiving at UTL iskills workshops February 2018 Sam-chin Li Reference and Government Information Librarian, UTL Nich Worby Government Information and Statistics Librarian, UTL Agenda What is web archiving
August 14th - 18th 2005, Oslo, Norway. Web crawling : The Bibliothèque nationale de France experience
 World Library and Information Congress: 71th IFLA General Conference and Council "Libraries - A voyage of discovery" August 14th - 18th 2005, Oslo, Norway Conference Programme: http://www.ifla.org/iv/ifla71/programme.htm
World Library and Information Congress: 71th IFLA General Conference and Council "Libraries - A voyage of discovery" August 14th - 18th 2005, Oslo, Norway Conference Programme: http://www.ifla.org/iv/ifla71/programme.htm
1. Name of Your Organization. 2. About Your Organization. Page 1. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj. nmlkj.
 In Fall 2011, the National Digital Stewardship Alliance (NDSA) conducted a survey of U.S. organizations currently or prospectively engaged in web archiving to better understand the landscape: similarities
In Fall 2011, the National Digital Stewardship Alliance (NDSA) conducted a survey of U.S. organizations currently or prospectively engaged in web archiving to better understand the landscape: similarities
Strategy for long term preservation of material collected for the Netarchive by the Royal Library and the State and University Library 2014
 Strategy for long term preservation of material collected for the Netarchive by the Royal Library and the State and University Library 2014 Introduction This document presents a strategy for long term
Strategy for long term preservation of material collected for the Netarchive by the Royal Library and the State and University Library 2014 Introduction This document presents a strategy for long term
Utilizing Digital Library Infrastructure to Build Modern Research Collections
 Utilizing Digital Library Infrastructure to Build Modern Research Collections Mark Phillips Wisconsin Association of Academic Librarians What is a digital library? 2 After 15+ years surely we've figured
Utilizing Digital Library Infrastructure to Build Modern Research Collections Mark Phillips Wisconsin Association of Academic Librarians What is a digital library? 2 After 15+ years surely we've figured
CDL s Web Archiving System
 CDL s Web Archiving System Erik Hetzner UC3, California Digital Library 16 June 2011 Erik Hetzner (UC3, California Digital Library) CDL s Web Archiving System 16 June 2011 1 / 24 Introduction We don t
CDL s Web Archiving System Erik Hetzner UC3, California Digital Library 16 June 2011 Erik Hetzner (UC3, California Digital Library) CDL s Web Archiving System 16 June 2011 1 / 24 Introduction We don t
Chilkat: crawling. Marlon Dias Information Retrieval DCC/UFMG
 Chilkat: crawling Marlon Dias msdias@dcc.ufmg.br Information Retrieval DCC/UFMG - 2017 Introduction Page collector (create collections) Navigate through links Unpleasant for some Caution: Bandwidth Scalability
Chilkat: crawling Marlon Dias msdias@dcc.ufmg.br Information Retrieval DCC/UFMG - 2017 Introduction Page collector (create collections) Navigate through links Unpleasant for some Caution: Bandwidth Scalability
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
The Internet Archive and The Wayback Machine
 The Internet Archive and The Wayback Machine The Internet Archive (IA) is a non-profit that was founded in 1996 to build an Internet library. Its primary purpose is to support a free and open internet
The Internet Archive and The Wayback Machine The Internet Archive (IA) is a non-profit that was founded in 1996 to build an Internet library. Its primary purpose is to support a free and open internet
Workflow for web archive indexing and search using limited resources. Sara Elshobaky & Youssef Eldakar
 Workflow for web archive indexing and search using limited resources Sara Elshobaky & Youssef Eldakar BA web archive IA collection 1996-2006 1 PB ARC files Egyptian collection 2011+ 20 TB WARC files BA
Workflow for web archive indexing and search using limited resources Sara Elshobaky & Youssef Eldakar BA web archive IA collection 1996-2006 1 PB ARC files Egyptian collection 2011+ 20 TB WARC files BA
Full-Text Indexing For Heritrix
 Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
DSpace and Web Material: Inroads and Challenges. Leslie Myrick, NYU DLF Spring Forum April 15, 2005
 DSpace and Web Material: Inroads and Challenges Leslie Myrick, NYU DLF Spring Forum April 15, 2005 What I ll Be Covering NDIIPP Web at Risk Project Web Archive Data Object Modeling DSpace and HTML Issues,
DSpace and Web Material: Inroads and Challenges Leslie Myrick, NYU DLF Spring Forum April 15, 2005 What I ll Be Covering NDIIPP Web at Risk Project Web Archive Data Object Modeling DSpace and HTML Issues,
Overview of the Netarkivet web archiving system
 Overview of the Netarkivet web archiving system Lars R. Clausen Statsbiblioteket May 24, 2006 Abstract The Netarkivet web archiving system is creating to fulfill our obligation as national archives to
Overview of the Netarkivet web archiving system Lars R. Clausen Statsbiblioteket May 24, 2006 Abstract The Netarkivet web archiving system is creating to fulfill our obligation as national archives to
Crawling. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Information Retrieval. Lecture 10 - Web crawling
 Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Uniformed Search (cont.)
") Uniformed Search (cont.) Computer Science cpsc322, Lecture 6 (Textbook finish 3.5) Sept, 16, 2013 CPSC 322, Lecture 6 Slide 1 Lecture Overview Recap DFS vs BFS Uninformed Iterative Deepening (IDS) Search
Uniformed Search (cont.) Computer Science cpsc322, Lecture 6 (Textbook finish 3.5) Sept, 16, 2013 CPSC 322, Lecture 6 Slide 1 Lecture Overview Recap DFS vs BFS Uninformed Iterative Deepening (IDS) Search
Systems Interoperability and Collaborative Development for Web Archiving
 Systems Interoperability and Collaborative Development for Web Archiving Filling Gaps in the IMLS National Digital Platform Mark Phillips, University of North Texas Courtney Mumma, Internet Archive Talk
Systems Interoperability and Collaborative Development for Web Archiving Filling Gaps in the IMLS National Digital Platform Mark Phillips, University of North Texas Courtney Mumma, Internet Archive Talk
Crawling the Web. Web Crawling. Main Issues I. Type of crawl
 Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
HOW DOES A SEARCH ENGINE WORK?
 HOW DOES A SEARCH ENGINE WORK? Hector says... Hi there! Did you know that the World Wide Web is made up of over a trillion web pages? That s more information than you d find in a really big library and
HOW DOES A SEARCH ENGINE WORK? Hector says... Hi there! Did you know that the World Wide Web is made up of over a trillion web pages? That s more information than you d find in a really big library and
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
Yioop Full Historical Indexing In Cache Navigation. Akshat Kukreti
 Yioop Full Historical Indexing In Cache Navigation Akshat Kukreti Agenda Introduction History Feature Cache Page Validation Feature Conclusion Demo Introduction Project goals History feature for enabling
Yioop Full Historical Indexing In Cache Navigation Akshat Kukreti Agenda Introduction History Feature Cache Page Validation Feature Conclusion Demo Introduction Project goals History feature for enabling
WEB ARCHIVE COLLECTING POLICY
 WEB ARCHIVE COLLECTING POLICY Purdue University Libraries Virginia Kelly Karnes Archives and Special Collections Research Center 504 West State Street West Lafayette, Indiana 47907-2058 (765) 494-2839
WEB ARCHIVE COLLECTING POLICY Purdue University Libraries Virginia Kelly Karnes Archives and Special Collections Research Center 504 West State Street West Lafayette, Indiana 47907-2058 (765) 494-2839
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
User Manual. Version September 2013
 User Manual Version 1.6.1 September 2013 Contents Introduction... 4 About the Web Curator Tool... 4 About this document... 4 Where to find more information... 4 System Overview... 5 Background... 5 Purpose
User Manual Version 1.6.1 September 2013 Contents Introduction... 4 About the Web Curator Tool... 4 About this document... 4 Where to find more information... 4 System Overview... 5 Background... 5 Purpose
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION
 San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 2013 YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION Akshat Kukreti Follow this and additional
San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 2013 YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION Akshat Kukreti Follow this and additional
Wayback for Accessing Web Archives
 Wayback for Accessing Web Archives ABSTRACT 'Wayback' is an open-source, Java software package for browserbased access of archived web material, offering a variety of operation modes and opportunities
Wayback for Accessing Web Archives ABSTRACT 'Wayback' is an open-source, Java software package for browserbased access of archived web material, offering a variety of operation modes and opportunities
Oh My, How the Archive has Grown: Library of Congress Challenges and Strategies for Managing Selective Harvesting on a Domain Crawl Scale
 Oh My, How the Archive has Grown: Library of Congress Challenges and Strategies for Managing Selective Harvesting on a Domain Crawl Scale Abbie Grotke abgr@loc.gov @agrotke WAC, June 16, 2017 LC WEB ARCHIVING
Oh My, How the Archive has Grown: Library of Congress Challenges and Strategies for Managing Selective Harvesting on a Domain Crawl Scale Abbie Grotke abgr@loc.gov @agrotke WAC, June 16, 2017 LC WEB ARCHIVING
The MDR: A Grand Experiment in Storage & Preservation
 The MDR: A Grand Experiment in Storage & Preservation Agenda Overview of the IA Web Archive MDR What is it and why deploy it? Before & After: Philosophy & Best Practices Wayback Access Services What s
The MDR: A Grand Experiment in Storage & Preservation Agenda Overview of the IA Web Archive MDR What is it and why deploy it? Before & After: Philosophy & Best Practices Wayback Access Services What s
Workshop on Web Archiving
 Workshop on Web Archiving MODULE 1 A: WEB ARCHIVING Niels Brügger Asger Harlung Program, KB 10.40-11.50 Workshop part 1: Web archiving 11.50-12.10 Discussion and a short break before lunch 12.10-13.00
Workshop on Web Archiving MODULE 1 A: WEB ARCHIVING Niels Brügger Asger Harlung Program, KB 10.40-11.50 Workshop part 1: Web archiving 11.50-12.10 Discussion and a short break before lunch 12.10-13.00
Preservation of Web Materials
 Preservation of Web Materials Julie Dietrich INFO 560 Literature Review 7/20/13 1 Introduction Websites are a communication and informational tool that can be shared and updated across the World Wide Web.
Preservation of Web Materials Julie Dietrich INFO 560 Literature Review 7/20/13 1 Introduction Websites are a communication and informational tool that can be shared and updated across the World Wide Web.
Large Crawls of the Web for Linguistic Purposes
 Large Crawls of the Web for Linguistic Purposes SSLMIT, University of Bologna Birmingham, July 2005 Outline Introduction 1 Introduction 2 3 Basics Heritrix My ongoing crawl 4 Filtering and cleaning 5 Annotation
Large Crawls of the Web for Linguistic Purposes SSLMIT, University of Bologna Birmingham, July 2005 Outline Introduction 1 Introduction 2 3 Basics Heritrix My ongoing crawl 4 Filtering and cleaning 5 Annotation
Curators Needed How Public Libraries are Bringing Community Members into their Web Archiving Practice
 Curators Needed How Public Libraries are Bringing Community Members into their Web Archiving Practice Karl-Rainer Blumenthal, Internet Archive Emily Ward, East Baton Rouge Parish Library Natalie Milbrodt,
Curators Needed How Public Libraries are Bringing Community Members into their Web Archiving Practice Karl-Rainer Blumenthal, Internet Archive Emily Ward, East Baton Rouge Parish Library Natalie Milbrodt,
How Does a Search Engine Work? Part 1
 How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
User Manual Version August 2011
 User Manual Version 1.5.2 August 2011 Contents Contents... 2 Introduction... 4 About the Web Curator Tool... 4 About this document... 4 Where to find more information... 4 System Overview... 5 Background...
User Manual Version 1.5.2 August 2011 Contents Contents... 2 Introduction... 4 About the Web Curator Tool... 4 About this document... 4 Where to find more information... 4 System Overview... 5 Background...
Integration of non harvested web data into an existing web archive
 Integration of non harvested web data into an existing web archive Bjarne Andersen Daily manager netarchive.dk bja@netarkivet.dk Abstract This paper describes a software prototype developed for transforming
Integration of non harvested web data into an existing web archive Bjarne Andersen Daily manager netarchive.dk bja@netarkivet.dk Abstract This paper describes a software prototype developed for transforming
Information Networks. Hacettepe University Department of Information Management DOK 422: Information Networks
 Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Legal Deposit of Online Newspapers at the BnF - Clément Oury - IFLA PAC Paris 2012
 1 Legal Deposit of Online Newspapers Digital collections in BnF stacks Clément Oury Head of Digital Legal Deposit Bibliothèque nationale de France Summary The issue : ensuring the continuity of BnF heritage
1 Legal Deposit of Online Newspapers Digital collections in BnF stacks Clément Oury Head of Digital Legal Deposit Bibliothèque nationale de France Summary The issue : ensuring the continuity of BnF heritage
Search Engines. Charles Severance
 Search Engines Charles Severance Google Architecture Web Crawling Index Building Searching http://infolab.stanford.edu/~backrub/google.html Google Search Google I/O '08 Keynote by Marissa Mayer Usablity
Search Engines Charles Severance Google Architecture Web Crawling Index Building Searching http://infolab.stanford.edu/~backrub/google.html Google Search Google I/O '08 Keynote by Marissa Mayer Usablity
Harvesting Democracy: Archiving Federal Government Web Content at End of Term
 Harvesting Democracy: Archiving Federal Government Web Content at End of Term Jefferson Bailey, Director, Web Archiving, Internet Archive @jefferson_bail jefferson@archive.org Abbie Grotke, Web Archiving
Harvesting Democracy: Archiving Federal Government Web Content at End of Term Jefferson Bailey, Director, Web Archiving, Internet Archive @jefferson_bail jefferson@archive.org Abbie Grotke, Web Archiving
Meeting researchers needs in mining web archives: the experience of the National Library of France
 Meeting researchers needs in mining web archives: the experience of the National Library of France Sara Aubry, IT Department Peter Stirling, Legal Deposit Department Bibliothèque nationale de France LIBER
Meeting researchers needs in mining web archives: the experience of the National Library of France Sara Aubry, IT Department Peter Stirling, Legal Deposit Department Bibliothèque nationale de France LIBER
Community Tools and Best Practices for Harvesting and Preserving At-Risk Web Content ACA 2013
 Community Tools and Best Practices for Harvesting and Preserving At-Risk Web Content ACA 2013 Scott Reed, Internet Archive Amanda Wakaruk, University of Alberta Libraries Kelly E. Lau, University of Alberta
Community Tools and Best Practices for Harvesting and Preserving At-Risk Web Content ACA 2013 Scott Reed, Internet Archive Amanda Wakaruk, University of Alberta Libraries Kelly E. Lau, University of Alberta
Collection Building on the Web. Basic Algorithm
 Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
The Web-at-Risk at Three: Overview of an NDIIPP Web Archiving Initiative
 The Web-at-Risk at Three: Overview of an NDIIPP Web Archiving Initiative Tracy Seneca Abstract The Web-at-Risk project is a multi-year National Digital Information Infrastructure and Preservation Program
The Web-at-Risk at Three: Overview of an NDIIPP Web Archiving Initiative Tracy Seneca Abstract The Web-at-Risk project is a multi-year National Digital Information Infrastructure and Preservation Program
Developing New Methods for Web Archiving: Preserving the Dynamic Content of the ischool Website
 1 Developing New Methods for Web Archiving: Preserving the Dynamic Content of the ischool Website by Kathryn Darnall, Laura Vincent, Elliot Williams, and Jarred Wilson INF 392K: Digital Archiving and Preservation
1 Developing New Methods for Web Archiving: Preserving the Dynamic Content of the ischool Website by Kathryn Darnall, Laura Vincent, Elliot Williams, and Jarred Wilson INF 392K: Digital Archiving and Preservation
INLS : Introduction to Information Retrieval System Design and Implementation. Fall 2008.
 INLS 490-154: Introduction to Information Retrieval System Design and Implementation. Fall 2008. 12. Web crawling Chirag Shah School of Information & Library Science (SILS) UNC Chapel Hill NC 27514 chirag@unc.edu
INLS 490-154: Introduction to Information Retrieval System Design and Implementation. Fall 2008. 12. Web crawling Chirag Shah School of Information & Library Science (SILS) UNC Chapel Hill NC 27514 chirag@unc.edu
Workshop B: Archiving the Web
 Workshop B: Archiving the Web Michael Day and Maureen Pennock Digital Curation Centre UKOLN, University of Bath http://www.ukoln.ac.uk/ Driving the Long-Term Preservation of Electronic Records, London,
Workshop B: Archiving the Web Michael Day and Maureen Pennock Digital Curation Centre UKOLN, University of Bath http://www.ukoln.ac.uk/ Driving the Long-Term Preservation of Electronic Records, London,
Search with Costs and Heuristic Search
 Search with Costs and Heuristic Search Alan Mackworth UBC CS 322 Search 3 January 14, 2013 Textbook 3.5.3, 3.6, 3.6.1 1 Today s Lecture Recap from last lecture, combined with AIspace demo Search with costs:
Search with Costs and Heuristic Search Alan Mackworth UBC CS 322 Search 3 January 14, 2013 Textbook 3.5.3, 3.6, 3.6.1 1 Today s Lecture Recap from last lecture, combined with AIspace demo Search with costs:
warcinfo: contains information about the files within the WARC response: contains the full http response
 Title Preservation Metadata for Complex Digital Objects. A Report of the ALCTS PARS Preservation Metadata Interest Group Meeting. American Library Association Annual Meeting, San Francisco, June 2015 Authors
Title Preservation Metadata for Complex Digital Objects. A Report of the ALCTS PARS Preservation Metadata Interest Group Meeting. American Library Association Annual Meeting, San Francisco, June 2015 Authors
Explorations of Netarkivet: Preliminary Findings. Emily Maemura, PhD Candidate Faculty of Information, University of Toronto NetLab Forum May 4, 2018
 Explorations of Netarkivet: Preliminary Findings Emily Maemura, PhD Candidate Faculty of Information, University of Toronto NetLab Forum May 4, 2018 Elements of Provenance Maemura, Worby, Milligan, Becker,
Explorations of Netarkivet: Preliminary Findings Emily Maemura, PhD Candidate Faculty of Information, University of Toronto NetLab Forum May 4, 2018 Elements of Provenance Maemura, Worby, Milligan, Becker,
This guide will walk you through the steps for installing and using wget on Windows.
 Wget Windows Guide This guide will walk you through the steps for installing and using wget on Windows. The Eye is currently sponsored by 10gbps.io. Check out their services, they re awesome. :) Quick
Wget Windows Guide This guide will walk you through the steps for installing and using wget on Windows. The Eye is currently sponsored by 10gbps.io. Check out their services, they re awesome. :) Quick
Becoming a Web Archivist: My 10 Year Journey in the National Library of Estonia
 Becoming a Web Archivist: My 10 Year Journey in the National Library of Estonia Tiiu Daniel National Library of Estonia IIPC Web Archiving Conference, New Zealand, Wellington November 13, 2018 You can't
Becoming a Web Archivist: My 10 Year Journey in the National Library of Estonia Tiiu Daniel National Library of Estonia IIPC Web Archiving Conference, New Zealand, Wellington November 13, 2018 You can't
SE Workshop PLAN. What is a Search Engine? Components of a SE. Crawler-Based Search Engines. How Search Engines (SEs) Work?
 Work?") PLAN SE Workshop Ellen Wilson Olena Zubaryeva Search Engines: How do they work? Search Engine Optimization (SEO) optimize your website How to search? Tricks Practice What is a Search Engine? A page on
PLAN SE Workshop Ellen Wilson Olena Zubaryeva Search Engines: How do they work? Search Engine Optimization (SEO) optimize your website How to search? Tricks Practice What is a Search Engine? A page on
Only applies where the starting URL specifies a starting location other than the root folder. For example:
 Allows you to set crawling rules for a Website Index. Character Encoding Allow Navigation Above Starting Directory Only applies where the starting URL specifies a starting location other than the root
Allows you to set crawling rules for a Website Index. Character Encoding Allow Navigation Above Starting Directory Only applies where the starting URL specifies a starting location other than the root
Putting it all together
 Putting it all together Annick Le Follic, Peter Stirling, Bert Wendland To cite this version: Annick Le Follic, Peter Stirling, Bert Wendland. Putting it all together: creating a unified web harvesting
Putting it all together Annick Le Follic, Peter Stirling, Bert Wendland To cite this version: Annick Le Follic, Peter Stirling, Bert Wendland. Putting it all together: creating a unified web harvesting
Crawling the Web for. Sebastian Nagel. Apache Big Data Europe
 Crawling the Web for Sebastian Nagel snagel@apache.org sebastian@commoncrawl.org Apache Big Data Europe 2016 About Me computational linguist software developer, search and data matching since 2016 crawl
Crawling the Web for Sebastian Nagel snagel@apache.org sebastian@commoncrawl.org Apache Big Data Europe 2016 About Me computational linguist software developer, search and data matching since 2016 crawl
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
AN OVERVIEW OF SEARCHING AND DISCOVERING WEB BASED INFORMATION RESOURCES
 Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Journal of Defense Resources Management No. 1 (1) / 2010 AN OVERVIEW OF SEARCHING AND DISCOVERING Cezar VASILESCU Regional Department of Defense Resources Management Studies Abstract: The Internet becomes
Workshop on Web Archiving
 Workshop on Web Archiving MODULE 1: WEB ARCHIVING Niels Brügger Asger Harlung Program, KU 12.00-13.00 Workshop part 1: Web archiving 13.00-13.15 Coffee 13.15-14.00 Workshop part 2: Existing collections
Workshop on Web Archiving MODULE 1: WEB ARCHIVING Niels Brügger Asger Harlung Program, KU 12.00-13.00 Workshop part 1: Web archiving 13.00-13.15 Coffee 13.15-14.00 Workshop part 2: Existing collections
From Web Page Storage to Living Web Archives
 From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawling today & Open Issues LiWA Living
From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawling today & Open Issues LiWA Living
Web Crawler Middleware for Search Engine Digital Libraries: A Case Study for CiteSeerX
 Web Crawler Middleware for Search Engine Digital Libraries: A Case Study for CiteSeerX Jian Wu, Pradeep Teregowda, Madian Khabsa, Stephen Carman, Douglas Jordan, Jose San Pedro Wandelmer, Xin Lu, Prasenjit
Web Crawler Middleware for Search Engine Digital Libraries: A Case Study for CiteSeerX Jian Wu, Pradeep Teregowda, Madian Khabsa, Stephen Carman, Douglas Jordan, Jose San Pedro Wandelmer, Xin Lu, Prasenjit
World Wide Web has specific challenges and opportunities
 6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
Web archiving: practices and options for academic libraries
 Web archiving: practices and options for academic libraries Helen Hockx-Yu, Director of Global Web Services, Internet Archive @hhockx helen@archive.org Outline Web archiving basics Web archiving landscape
Web archiving: practices and options for academic libraries Helen Hockx-Yu, Director of Global Web Services, Internet Archive @hhockx helen@archive.org Outline Web archiving basics Web archiving landscape
Understanding Primary Storage Optimization Options Jered Floyd Permabit Technology Corp.
 Understanding Primary Storage Optimization Options Jered Floyd Permabit Technology Corp. Primary Storage Optimization Technologies that let you store more data on the same storage Thin provisioning Copy-on-write
Understanding Primary Storage Optimization Options Jered Floyd Permabit Technology Corp. Primary Storage Optimization Technologies that let you store more data on the same storage Thin provisioning Copy-on-write
Building a Web Curator Tool for The National Library of New Zealand
 Building a Web Curator Tool for The National Library of New Zealand Gordon Paynter Technical Analyst The National Library of New Zealand Gordon.Paynter@natlib.govt.nz Ingrid Mason E-Publications Librarian
Building a Web Curator Tool for The National Library of New Zealand Gordon Paynter Technical Analyst The National Library of New Zealand Gordon.Paynter@natlib.govt.nz Ingrid Mason E-Publications Librarian
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Patent-Crawler. A real-time recursive focused web crawler to gather information on patent usage. HPC-AI Advisory Council, Lugano, April 2018
 Patent-Crawler A real-time recursive focused web crawler to gather information on patent usage HPC-AI Advisory Council, Lugano, April 2018 E. Orliac 1,2, G. Fourestey 2, D. Portabella 2, G. de Rassenfosse
Patent-Crawler A real-time recursive focused web crawler to gather information on patent usage HPC-AI Advisory Council, Lugano, April 2018 E. Orliac 1,2, G. Fourestey 2, D. Portabella 2, G. de Rassenfosse
Using the Penn State Search Engine
 Using the Penn State Search Engine Jeffrey D Angelo and James Leous root@aset.psu.edu http://aset.its.psu.edu/ ITS Academic Services and Emerging Technologies ITS Training root@aset.psu.edu p.1 How Does
Using the Penn State Search Engine Jeffrey D Angelo and James Leous root@aset.psu.edu http://aset.its.psu.edu/ ITS Academic Services and Emerging Technologies ITS Training root@aset.psu.edu p.1 How Does
CAT (CURATOR ARCHIVING TOOL): IMPROVING ACCESS TO WEB ARCHIVES
: IMPROVING ACCESS TO WEB ARCHIVES") CAT (CURATOR ARCHIVING TOOL): IMPROVING ACCESS TO WEB ARCHIVES Ciro Llueca, Daniel Cócera Biblioteca de Catalunya (BC) Barcelona, Spain padicat@bnc.cat Natalia Torres, Gerard Suades, Ricard de la Vega
CAT (CURATOR ARCHIVING TOOL): IMPROVING ACCESS TO WEB ARCHIVES Ciro Llueca, Daniel Cócera Biblioteca de Catalunya (BC) Barcelona, Spain padicat@bnc.cat Natalia Torres, Gerard Suades, Ricard de la Vega
Enabling Collaboration for Digital Preservation
 Enabling Collaboration for Digital Preservation ipres 2009, San Francisco Martha Anderson The Library of Congress .trust and reciprocity lengthen the shadow of the future. Axelrod,The Evolution of Cooperation,1984.
Enabling Collaboration for Digital Preservation ipres 2009, San Francisco Martha Anderson The Library of Congress .trust and reciprocity lengthen the shadow of the future. Axelrod,The Evolution of Cooperation,1984.
Google Groups. Using, joining, creating, and sharing. content with groups. What's Google Groups? About Google Groups and Google Contacts
 Google Groups Using, joining, creating, and sharing content with groups What's Google Groups? Google Groups is a feature of Google Apps that makes it easy to communicate and collaborate with groups of
Google Groups Using, joining, creating, and sharing content with groups What's Google Groups? Google Groups is a feature of Google Apps that makes it easy to communicate and collaborate with groups of
From Web Page Storage to Living Web Archives Thomas Risse
 From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawlingtoday& Open Issues LiWA Living
From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawlingtoday& Open Issues LiWA Living
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
SEO Technical & On-Page Audit
 SEO Technical & On-Page Audit http://www.fedex.com Hedging Beta has produced this analysis on 05/11/2015. 1 Index A) Background and Summary... 3 B) Technical and On-Page Analysis... 4 Accessibility & Indexation...
SEO Technical & On-Page Audit http://www.fedex.com Hedging Beta has produced this analysis on 05/11/2015. 1 Index A) Background and Summary... 3 B) Technical and On-Page Analysis... 4 Accessibility & Indexation...
Needs Assessment Survey
 The Web-at-Risk: A Distributed Approach to Preserving our Nation s Political Cultural Heritage Content Identification, Selection, and Acquisition Path Needs Assessment Survey Purpose : The purpose of this
The Web-at-Risk: A Distributed Approach to Preserving our Nation s Political Cultural Heritage Content Identification, Selection, and Acquisition Path Needs Assessment Survey Purpose : The purpose of this
Archiving dynamic websites: a considerations framework and a tool comparison
 Archiving dynamic websites: a considerations framework and a tool comparison Allard Oelen Student number: 2560801 Supervisor: Victor de Boer 30 June 2017 Vrije Universiteit Amsterdam a.b.oelen@student.vu.nl
Archiving dynamic websites: a considerations framework and a tool comparison Allard Oelen Student number: 2560801 Supervisor: Victor de Boer 30 June 2017 Vrije Universiteit Amsterdam a.b.oelen@student.vu.nl
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
data analysis - basic steps Arend Hintze
 data analysis - basic steps Arend Hintze 1/13: Data collection, (web scraping, crawlers, and spiders) 1/15: API for Twitter, Reddit 1/20: no lecture due to MLK 1/22: relational databases, SQL 1/27: SQL,
data analysis - basic steps Arend Hintze 1/13: Data collection, (web scraping, crawlers, and spiders) 1/15: API for Twitter, Reddit 1/20: no lecture due to MLK 1/22: relational databases, SQL 1/27: SQL,
Itsy-Bitsy Spider: A Look at Web Crawlers and Web Archiving
 Digital Preservation: CINE-GT 1807 Fall 2017 Caroline Z. Oliveira 12/15/2017 Itsy-Bitsy Spider: A Look at Web Crawlers and Web Archiving Introduction Human beings have always felt the need to share information.
Digital Preservation: CINE-GT 1807 Fall 2017 Caroline Z. Oliveira 12/15/2017 Itsy-Bitsy Spider: A Look at Web Crawlers and Web Archiving Introduction Human beings have always felt the need to share information.
Web scraping and social media scraping introduction
 Web scraping and social media scraping introduction Jacek Lewkowicz, Dorota Celińska University of Warsaw February 23, 2018 Motivation Definition of scraping Tons of (potentially useful) information on
Web scraping and social media scraping introduction Jacek Lewkowicz, Dorota Celińska University of Warsaw February 23, 2018 Motivation Definition of scraping Tons of (potentially useful) information on
You got a website. Now what?
 You got a website I got a website! Now what? Adriana Kuehnel Nov.2017 The majority of the traffic to your website will come through a search engine. Need to know: Best practices so ensure your information
You got a website I got a website! Now what? Adriana Kuehnel Nov.2017 The majority of the traffic to your website will come through a search engine. Need to know: Best practices so ensure your information
Safe Havens in a Choppy Sea:
 Safe Havens in a Choppy Sea: Digital Object Management Workflows at the National Library of Australia Gerard Clifton Manager, Digital and Audio Preservation Resources National Library of Australia 1 Seascape:
Safe Havens in a Choppy Sea: Digital Object Management Workflows at the National Library of Australia Gerard Clifton Manager, Digital and Audio Preservation Resources National Library of Australia 1 Seascape:
NATION WIDE WEBS. Jefferson Bailey, Director, Web Archiving & Data Services, Internet Archive IIPC WAC NLNZ 2018
 NATION WIDE WEBS Jefferson Bailey, Director, Web Archiving & Data Services, Internet Archive IIPC WAC NLNZ 2018 jefferson@archive.org NATION WHO WIDE WHAT WEBS WHY Jefferson Bailey, Director, Web Archiving
NATION WIDE WEBS Jefferson Bailey, Director, Web Archiving & Data Services, Internet Archive IIPC WAC NLNZ 2018 jefferson@archive.org NATION WHO WIDE WHAT WEBS WHY Jefferson Bailey, Director, Web Archiving
CSCE 463/612: Networks and Distributed Processing Homework 1 Part 2 (25 pts) Due date: 1/29/19
 Due date: 1/29/19") CSCE 463/612: Networks and Distributed Processing Homework 1 Part 2 (25 pts) Due date: 1/29/19 1. Problem Description You will now expand into downloading multiple URLs from an input file using a single
CSCE 463/612: Networks and Distributed Processing Homework 1 Part 2 (25 pts) Due date: 1/29/19 1. Problem Description You will now expand into downloading multiple URLs from an input file using a single
Web Crawling. Advanced methods of Information Retrieval. Gerhard Gossen Gerhard Gossen Web Crawling / 57
 Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Cloud Archiving & ediscovery Client System Implementation Requirements
 Cloud Archiving & ediscovery Client System Implementation Requirements MessageSolution, Inc. 1851 McCarthy Blvd. Suite 105 Milpitas, CA 95035 SalesDesk@MessageSolution.com Copyright 2012 MessageSolution,
Cloud Archiving & ediscovery Client System Implementation Requirements MessageSolution, Inc. 1851 McCarthy Blvd. Suite 105 Milpitas, CA 95035 SalesDesk@MessageSolution.com Copyright 2012 MessageSolution,
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
Search. (Textbook Chpt ) Computer Science cpsc322, Lecture 2. May, 10, CPSC 322, Lecture 2 Slide 1
 Computer Science cpsc322, Lecture 2. May, 10, CPSC 322, Lecture 2 Slide 1") Search Computer Science cpsc322, Lecture 2 (Textbook Chpt 3.0-3.4) May, 10, 2012 CPSC 322, Lecture 2 Slide 1 Colored Cards You need to have 4 colored index cards Come and get them from me if you still
Search Computer Science cpsc322, Lecture 2 (Textbook Chpt 3.0-3.4) May, 10, 2012 CPSC 322, Lecture 2 Slide 1 Colored Cards You need to have 4 colored index cards Come and get them from me if you still
COMP Web Crawling
 COMP 4601 Web Crawling What is Web Crawling? Process by which an agent traverses links on a web page For each page visited generally store content Start from a root page (or several) 2 MoFvaFon for Crawling
COMP 4601 Web Crawling What is Web Crawling? Process by which an agent traverses links on a web page For each page visited generally store content Start from a root page (or several) 2 MoFvaFon for Crawling
Making your agency s sites more accessible to web search engine users. Implementing the Sitemap protocol
 Making your agency s sites more accessible to web search engine users Implementing the Sitemap protocol Agenda Common barriers to web search engine crawling Supporting the two levels of search The Sitemap
Making your agency s sites more accessible to web search engine users Implementing the Sitemap protocol Agenda Common barriers to web search engine crawling Supporting the two levels of search The Sitemap
WEB CURATOR TOOL. Quick Start Guide
 WEB CURATOR TOOL Quick Start Guide 12 August 2009 Contents Introduction... 3 Basic functions: authorisation, targets, harvests... 3 Terminology... 3 General workflow... 4 Contents of this document... 6
WEB CURATOR TOOL Quick Start Guide 12 August 2009 Contents Introduction... 3 Basic functions: authorisation, targets, harvests... 3 Terminology... 3 General workflow... 4 Contents of this document... 6