COMP Web Crawling
|
|
|
- Randall Harmon
- 6 years ago
- Views:
Transcription
1 COMP 4601 Web Crawling
2 What is Web Crawling? Process by which an agent traverses links on a web page For each page visited generally store content Start from a root page (or several) 2
3 MoFvaFon for Crawling Want to create a view of the World Wide Web Interested in a graph represenfng linked pages Graph provides: Ability to measure distance Ability to measure node importance Node content (page) can be indexed 3
4 MoFvaFon for Web Crawling Want to perform informa(on extrac(on. InformaFon ExtracFon (IE): IE is the task of automafcally extracfng structured informafon from unstructured and/or semi-structured machine-readable documents. In most of the cases this acfvity concerns processing human language texts by means of natural language processing (NLP). Recent acfvifes in mulfmedia document processing like automafc annotafon and content extracfon out of images/audio/ video could be seen as informafon extracfon. 4
5 What is a Web Crawler According to Wikipedia: hvp://en.wikipedia.org/wiki/web_crawler A Web crawler is an Internet bot that systemafcally browses the World Wide Web, typically for the purpose of Web indexing. Can potenfally crawl any graph; e.g., Facebook social network 5

6 Web Crawler From: hvp://en.wikipedia.org/wiki/web_crawler 6
7 Structure of a Web Crawler Behaviour defined by policies: SelecFon policy Re-visit policy Politeness policy ParallelizaFon policy 7
8 SelecFon Policy Even large search engines cover only 40-70% of indexable web. Need to provide a metric of importance for priorifzing pages. Page importance a funcfon of: Intrinsic quality Popularity of its links 8
9 SelecFon Policy Cho et al used 180,000 page data set from stanford.edu domain Tested: Breadth-first Backlink-count ParFal PageRank (PPR) calculafon Conclusion: For finding high PageRank pages, use PPR Study: hvp://oak.cs.ucla.edu/~cho/papers/cho-thesis.pdf 9
 followed by all nodes at distance 2 etc.")
10 SelecFon Policy Najork and Wiener used 328 million pages using breadth-first explorafon. Found that strategy captures high PageRank pages early Idea is to visit all nodes at distance from root node (labelled 0) followed by all nodes at distance 2 etc. Stop when we reach a certain distance (d max ) from the 9 root node. 10 0
11 Backlink Crawler Backlink-count This strategy crawls first the pages with the highest number of links poinfng to it, so the next page to be crawled is the most linked from the pages already downloaded. This strategy was described by Cho et al. [CGMP98]. See: hvp://chato.cl/papers/crawling_thesis/scheduling.pdf hvp://en.wikipedia.org/wiki/focused_crawler hvp://www10.org/cdrom/papers/208/ (Najork,Weiner) 11

12 Backlink Example Has 3 backlinks Has 2 backlinks Already downloaded 12
13 Online Page Importance ComputaFon (OPIC) OPIC This strategy is based on OPIC [APC03], which can be seen as a weighted backlink-count strategy. All pages start with the same amount of cash. Every Fme a page is crawled, its cash is split among the pages it links to. The priority of an uncrawled page is the sum of the cash it has received from the pages poinfng to it. This strategy is similar to Pagerank, but has no random links and the calculafon is not iterafve so it is much faster. 13

14 OPIC Example 5 OPIC= = OPC=1+2.5=3.5 n Already downloaded, OPIC = n 14
15 RestricFng Followed Links May want to follow HTML pages May want to avoid specific MIME types May want to filter based upon URL; e.g., if there s a? in it then it is probably dynamically generated. 15
16 Re-visit Policy Typically, we re storing the pages that we visit (or creafng a hash of them) We need to re-visit them Want to compute 2 measures: Freshness: binary, whether local copy is accurate or not Age: indicates how outdated the local copy is 16
17 Age and Freshness p is a page in the above equa(ons 17
18 Re-visit Policy Uniform: Revisit with same frequency regardless of rate of change Propor(onal: Revisit in proporfon to rate of change 18

19 Politeness Policy Web crawlers work faster than humans Can retrieve A LOT of data Has significant performance impact on a site Robots.txt defines a robot exclusion protocol: hvp://en.wikipedia.org/wiki/robots_exclusion_standard Example: User-agent: * Disallow: User-agent: * Disallow: / Allow everybody Allow nobody 19
20 Crawl-delay Shouldn t access pages as fast as I can! User-agent: * Crawl-delay: 10 Wait 10 seconds between requests on the same server Web crawler delay: Fixed: 15 seconds (WIRE) AdapFve: If page took t secs, use 10t before next page. (MERCATORWEB) 20
21 Delay Setng It is a problem! Brin and Page note:.. running a crawler which connects to more than half a million servers (...) generates a fair amount of and phone calls. Because of the vast number of people coming on line, there are always those who do not know what a crawler is, because this is the first one they have seen. Conclusion: Use adap(ve with lower bound 21
22 ParallelizaFon Policy Use mulfple threads/processes to crawl in parallel. Need to: Dynamically assign URLs to different crawlers Want to balance load Ensure that we don t access a URL more than once Manage concurrency properly (i.e., serialize access to shared state) See: hvp://en.wikipedia.org/wiki/distributed_web_crawling 22
23 Architectures for Parallel Crawlers Shared Space Map Reduce 23

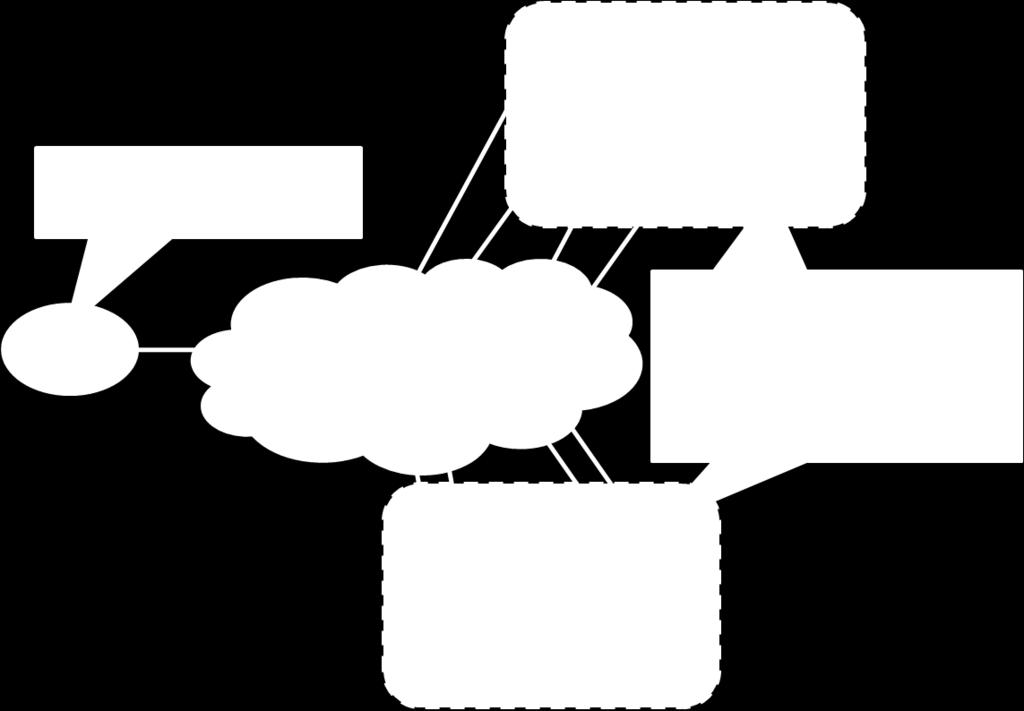
24 Shared Space 24

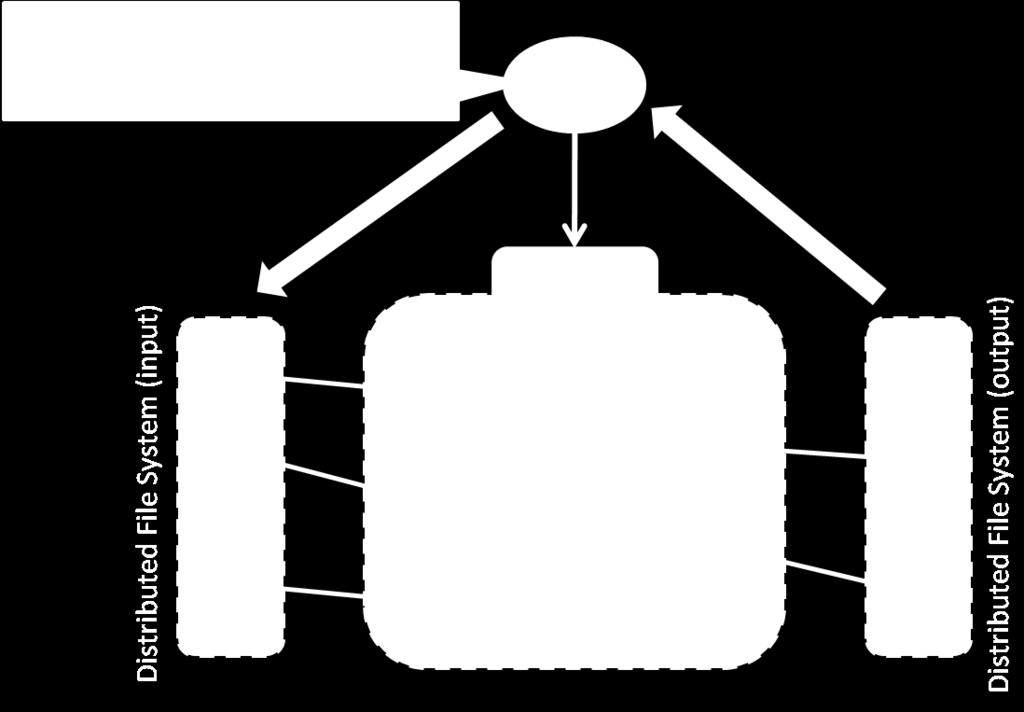
25 Map Reduce 25
26 Web Crawlers Many open source crawlers in Java hvp://java-source.net/open-source/crawlers Heritrix Used at Internet scale Highly extensible 26
27 Webcrawler Sowware Crawler4j Java, described in following slides Nutch Java Used in conjuncfon with Lucene (more later) See: hvp://en.wikipedia.org/wiki/nutch Several search engines built on it: Krugle (code search engine) DiscoverEd (open eduafonal resources) 27
28 crawler4j Crawler4j Open source web crawler WriVen in Java, is simple and fast Found at: hvps://github.com/yasserg/crawler4j Requires that user extend WebCrawler to implement a web crawler See BasicCrawler and ImageCrawler for examples See hvps://github.com/yasserg/crawler4j Configura(on Details for configurafon informafon 28
29 Crawler4j Details Have to implement 2 classes: Controller: defines parameters for crawl Seed URLs, storage folder, max pages crawled, Class with extends WebCrawler class Create instance of CrawlConfig Modify crawl parameters This should be converted to a parameter file! 29
30 WebCrawler: Important APIs boolean shouldvisit(page page, WebURL url) Determines whether a link should be followed Usually base this on a PaVern May also want to restrict to a domain void visit(page page) Called when a page is visited Allows analysis of page contents 30
Collection Building on the Web. Basic Algorithm
 Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Discussion 3: crawler4j
 Discussion 3: crawler4j Jan 22 nd, 2014 Content adapted from hfp://code.google.com/p/crawler4j/ INF 141 / CS 121 Tao Wang 1 Recall: a robust crawl architecture * Adapted from Jan 21 lecture INF 141 / CS
Discussion 3: crawler4j Jan 22 nd, 2014 Content adapted from hfp://code.google.com/p/crawler4j/ INF 141 / CS 121 Tao Wang 1 Recall: a robust crawl architecture * Adapted from Jan 21 lecture INF 141 / CS
Modern Information Retrieval
 Modern Information Retrieval Chapter 12 Web Crawling with Carlos Castillo Applications of a Web Crawler Architecture and Implementation Scheduling Algorithms Crawling Evaluation Extensions Examples of
Modern Information Retrieval Chapter 12 Web Crawling with Carlos Castillo Applications of a Web Crawler Architecture and Implementation Scheduling Algorithms Crawling Evaluation Extensions Examples of
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
FILTERING OF URLS USING WEBCRAWLER
 FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
CS101 Lecture 30: How Search Works and searching algorithms.
 CS101 Lecture 30: How Search Works and searching algorithms. John Magee 5 August 2013 Web Traffic - pct of Page Views Source: alexa.com, 4/2/2012 1 What You ll Learn Today Google: What is a search engine?
CS101 Lecture 30: How Search Works and searching algorithms. John Magee 5 August 2013 Web Traffic - pct of Page Views Source: alexa.com, 4/2/2012 1 What You ll Learn Today Google: What is a search engine?
Chapter 2: Literature Review
 Chapter 2: Literature Review 2.1 Introduction Literature review provides knowledge, understanding and familiarity of the research field undertaken. It is a critical study of related reviews from various
Chapter 2: Literature Review 2.1 Introduction Literature review provides knowledge, understanding and familiarity of the research field undertaken. It is a critical study of related reviews from various
Information Retrieval. Lecture 10 - Web crawling
 Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Breadth-First Search Crawling Yields High-Quality Pages
 Breadth-First Search Crawling Yields High-Quality Pages Marc Najork Compaq Systems Research Center 13 Lytton Avenue Palo Alto, CA 9431, USA marc.najork@compaq.com Janet L. Wiener Compaq Systems Research
Breadth-First Search Crawling Yields High-Quality Pages Marc Najork Compaq Systems Research Center 13 Lytton Avenue Palo Alto, CA 9431, USA marc.najork@compaq.com Janet L. Wiener Compaq Systems Research
Information Networks. Hacettepe University Department of Information Management DOK 422: Information Networks
 Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
How to Crawl the Web. Hector Garcia-Molina Stanford University. Joint work with Junghoo Cho
 How to Crawl the Web Hector Garcia-Molina Stanford University Joint work with Junghoo Cho Stanford InterLib Technologies Information Overload Service Heterogeneity Interoperability Economic Concerns Information
How to Crawl the Web Hector Garcia-Molina Stanford University Joint work with Junghoo Cho Stanford InterLib Technologies Information Overload Service Heterogeneity Interoperability Economic Concerns Information
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
World Wide Web has specific challenges and opportunities
 6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
Crawling. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Web Crawling. Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India
 Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
A SURVEY ON WEB FOCUSED INFORMATION EXTRACTION ALGORITHMS
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 A SURVEY ON WEB FOCUSED INFORMATION EXTRACTION ALGORITHMS Satwinder Kaur 1 & Alisha Gupta 2 1 Research Scholar (M.tech
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONS AND ROBOTICS ISSN 2320-7345 A SURVEY ON WEB FOCUSED INFORMATION EXTRACTION ALGORITHMS Satwinder Kaur 1 & Alisha Gupta 2 1 Research Scholar (M.tech
Plan for today. CS276B Text Retrieval and Mining Winter Evolution of search engines. Connectivity analysis
 CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 6: Information Retrieval I. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com Postponing MANAGING TEXT DATA Information Overload If we didn t have search Contains all
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
CS 572: Information Retrieval
 CS 572: Information Retrieval Web Crawling Acknowledgements Some slides in this lecture are adapted from Chris Manning (Stanford) and Soumen Chakrabarti (IIT Bombay) Status Project 1 results sent Final
CS 572: Information Retrieval Web Crawling Acknowledgements Some slides in this lecture are adapted from Chris Manning (Stanford) and Soumen Chakrabarti (IIT Bombay) Status Project 1 results sent Final
Crawlers - Introduction
 Introduction to Search Engine Technology Crawlers Ronny Lempel Yahoo! Labs, Haifa Crawlers - Introduction The role of crawlers is to collect Web content Starting with some seed URLs, crawlers learn of
Introduction to Search Engine Technology Crawlers Ronny Lempel Yahoo! Labs, Haifa Crawlers - Introduction The role of crawlers is to collect Web content Starting with some seed URLs, crawlers learn of
Crawling the Web. Web Crawling. Main Issues I. Type of crawl
 Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Crawling Assignment. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc. Fingerprints
Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc. Fingerprints
Computer Science 572 Exam Prof. Horowitz Wednesday, February 22, 2017, 8:00am 8:50am
 Computer Science 572 Exam Prof. Horowitz Wednesday, February 22, 2017, 8:00am 8:50am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 25 questions.
Computer Science 572 Exam Prof. Horowitz Wednesday, February 22, 2017, 8:00am 8:50am Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 25 questions.
Bixo - Web Mining Toolkit 23 Sep Ken Krugler TransPac Software, Inc.
 Web Mining Toolkit Ken Krugler TransPac Software, Inc. My background - did a startup called Krugle from 2005-2008 Used Nutch to do a vertical crawl of the web, looking for technical software pages. Mined
Web Mining Toolkit Ken Krugler TransPac Software, Inc. My background - did a startup called Krugle from 2005-2008 Used Nutch to do a vertical crawl of the web, looking for technical software pages. Mined
Crawling - part II. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling - part II CS6200: Information Retrieval Slides by: Jesse Anderton Coverage Good coverage is obtained by carefully selecting seed URLs and using a good page selection policy to decide what to crawl
Crawling - part II CS6200: Information Retrieval Slides by: Jesse Anderton Coverage Good coverage is obtained by carefully selecting seed URLs and using a good page selection policy to decide what to crawl
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 7: Information Retrieval I. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 7: Information Retrieval I Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains all books with
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 7: Information Retrieval I Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains all books with
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
Web Archiving Workshop
 Web Archiving Workshop Mark Phillips Texas Conference on Digital Libraries June 4, 2008 Agenda 1:00 Welcome/Introductions 1:15 Introduction to Web Archiving History Concepts/Terms Examples 2:15 Collection
Web Archiving Workshop Mark Phillips Texas Conference on Digital Libraries June 4, 2008 Agenda 1:00 Welcome/Introductions 1:15 Introduction to Web Archiving History Concepts/Terms Examples 2:15 Collection
Web scraping and social media scraping introduction
 Web scraping and social media scraping introduction Jacek Lewkowicz, Dorota Celińska University of Warsaw February 23, 2018 Motivation Definition of scraping Tons of (potentially useful) information on
Web scraping and social media scraping introduction Jacek Lewkowicz, Dorota Celińska University of Warsaw February 23, 2018 Motivation Definition of scraping Tons of (potentially useful) information on
Design and implementation of an incremental crawler for large scale web. archives
 DEWS2007 B9-5 Web, 247 850 5 53 8505 4 6 E-mail: ttamura@acm.org, kitsure@tkl.iis.u-tokyo.ac.jp Web Web Web Web Web Web Web URL Web Web PC Web Web Design and implementation of an incremental crawler for
DEWS2007 B9-5 Web, 247 850 5 53 8505 4 6 E-mail: ttamura@acm.org, kitsure@tkl.iis.u-tokyo.ac.jp Web Web Web Web Web Web Web URL Web Web PC Web Web Design and implementation of an incremental crawler for
Full-Text Indexing For Heritrix
 Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Crawling CE-324: Modern Information Retrieval Sharif University of Technology
 Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
OnCrawl Metrics. What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for.
 1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
Deep Web Crawling and Mining for Building Advanced Search Application
 Deep Web Crawling and Mining for Building Advanced Search Application Zhigang Hua, Dan Hou, Yu Liu, Xin Sun, Yanbing Yu {hua, houdan, yuliu, xinsun, yyu}@cc.gatech.edu College of computing, Georgia Tech
Deep Web Crawling and Mining for Building Advanced Search Application Zhigang Hua, Dan Hou, Yu Liu, Xin Sun, Yanbing Yu {hua, houdan, yuliu, xinsun, yyu}@cc.gatech.edu College of computing, Georgia Tech
A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index.
 A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index. The major search engines on the Web all have such a program,
A crawler is a program that visits Web sites and reads their pages and other information in order to create entries for a search engine index. The major search engines on the Web all have such a program,
Revised Edition: 2016 ISBN All rights reserved.
 Revised Edition: 2016 ISBN 978-1-280-29913-1 All rights reserved. Published by: Library Press 48 West 48 Street, Suite 1116, New York, NY 10036, United States Email: info@wtbooks.com Table of Contents
Revised Edition: 2016 ISBN 978-1-280-29913-1 All rights reserved. Published by: Library Press 48 West 48 Street, Suite 1116, New York, NY 10036, United States Email: info@wtbooks.com Table of Contents
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES
 SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES Introduction to Information Retrieval CS 150 Donald J. Patterson This content based on the paper located here: http://dx.doi.org/10.1007/s10618-008-0118-x
SOURCERER: MINING AND SEARCHING INTERNET- SCALE SOFTWARE REPOSITORIES Introduction to Information Retrieval CS 150 Donald J. Patterson This content based on the paper located here: http://dx.doi.org/10.1007/s10618-008-0118-x
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Search. Web Spidering. Introduction
 Web Search. Web Spidering Introduction 1 Outline Information Retrieval applied on the Web The Web the largest collection of documents available today Still, a collection Should be able to apply traditional
Web Search. Web Spidering Introduction 1 Outline Information Retrieval applied on the Web The Web the largest collection of documents available today Still, a collection Should be able to apply traditional
How Does a Search Engine Work? Part 1
 How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
Google Search Appliance
 Google Search Appliance Administering Crawl Google Search Appliance software version 7.0 September 2012 Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com September 2012 Copyright
Google Search Appliance Administering Crawl Google Search Appliance software version 7.0 September 2012 Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com September 2012 Copyright
RTCWEB Signaling. Ma/hew Kaufman
 RTCWEB Signaling Ma/hew Kaufman Scope Web Server Browser Browser Scope Web Server HTTP Already standardized Beyond that several possibilifes Browser Browser Scope Web Server Browser Browser Media Transport
RTCWEB Signaling Ma/hew Kaufman Scope Web Server Browser Browser Scope Web Server HTTP Already standardized Beyond that several possibilifes Browser Browser Scope Web Server Browser Browser Media Transport
Crawler. Crawler. Crawler. Crawler. Anchors. URL Resolver Indexer. Barrels. Doc Index Sorter. Sorter. URL Server
 Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Authors: Sergey Brin, Lawrence Page Google, word play on googol or 10 100 Centralized system, entire HTML text saved Focused on high precision, even at expense of high recall Relies heavily on document
Title: Artificial Intelligence: an illustration of one approach.
 Name : Salleh Ahshim Student ID: Title: Artificial Intelligence: an illustration of one approach. Introduction This essay will examine how different Web Crawling algorithms and heuristics that are being
Name : Salleh Ahshim Student ID: Title: Artificial Intelligence: an illustration of one approach. Introduction This essay will examine how different Web Crawling algorithms and heuristics that are being
Web Crawlers Detection. Yomna ElRashidy
 Web Crawlers Detection Yomna ElRashidy yomna.elrashidi@aucegypt.com Outline A web crawler is a program that traverse the web autonomously with the purpose of discovering and retrieving content and knowledge
Web Crawlers Detection Yomna ElRashidy yomna.elrashidi@aucegypt.com Outline A web crawler is a program that traverse the web autonomously with the purpose of discovering and retrieving content and knowledge
Search Engines. Dr. Johan Hagelbäck.
 Search Engines Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Search Engines This lecture is about full-text search engines, like Google and Microsoft Bing They allow people to search a large
Search Engines Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Search Engines This lecture is about full-text search engines, like Google and Microsoft Bing They allow people to search a large
CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA
 CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA An Implementation Amit Chawla 11/M.Tech/01, CSE Department Sat Priya Group of Institutions, Rohtak (Haryana), INDIA anshmahi@gmail.com
CRAWLING THE WEB: DISCOVERY AND MAINTENANCE OF LARGE-SCALE WEB DATA An Implementation Amit Chawla 11/M.Tech/01, CSE Department Sat Priya Group of Institutions, Rohtak (Haryana), INDIA anshmahi@gmail.com
Web-Crawling Approaches in Search Engines
 Web-Crawling Approaches in Search Engines Thesis submitted in partial fulfillment of the requirements for the award of degree of Master of Engineering in Computer Science & Engineering Thapar University,
Web-Crawling Approaches in Search Engines Thesis submitted in partial fulfillment of the requirements for the award of degree of Master of Engineering in Computer Science & Engineering Thapar University,
Advanced Crawling Techniques. Outline. Web Crawler. Chapter 6. Selective Crawling Focused Crawling Distributed Crawling Web Dynamics
 Chapter 6 Advanced Crawling Techniques Outline Selective Crawling Focused Crawling Distributed Crawling Web Dynamics Web Crawler Program that autonomously navigates the web and downloads documents For
Chapter 6 Advanced Crawling Techniques Outline Selective Crawling Focused Crawling Distributed Crawling Web Dynamics Web Crawler Program that autonomously navigates the web and downloads documents For
URLs excluded by REP may still appear in a search engine index.
 Robots Exclusion Protocol Guide The Robots Exclusion Protocol (REP) is a very simple but powerful mechanism available to webmasters and SEOs alike. Perhaps it is the simplicity of the file that means it
Robots Exclusion Protocol Guide The Robots Exclusion Protocol (REP) is a very simple but powerful mechanism available to webmasters and SEOs alike. Perhaps it is the simplicity of the file that means it
Efficient extraction of news articles based on RSS crawling
 Efficient extraction of news articles based on RSS crawling George Adam, Christos Bouras and Vassilis Poulopoulos Research Academic Computer Technology Institute, and Computer and Informatics Engineer
Efficient extraction of news articles based on RSS crawling George Adam, Christos Bouras and Vassilis Poulopoulos Research Academic Computer Technology Institute, and Computer and Informatics Engineer
Web Crawling. Advanced methods of Information Retrieval. Gerhard Gossen Gerhard Gossen Web Crawling / 57
 Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Web Crawling Advanced methods of Information Retrieval Gerhard Gossen 2015-06-04 Gerhard Gossen Web Crawling 2015-06-04 1 / 57 Agenda 1 Web Crawling 2 How to crawl the Web 3 Challenges 4 Architecture of
Efficient extraction of news articles based on RSS crawling
 Efficient extraction of news based on RSS crawling George Adam Research Academic Computer Technology Institute, and Computer and Informatics Engineer Department, University of Patras Patras, Greece adam@cti.gr
Efficient extraction of news based on RSS crawling George Adam Research Academic Computer Technology Institute, and Computer and Informatics Engineer Department, University of Patras Patras, Greece adam@cti.gr
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Data Collection & Data Preprocessing
 Data Collection & Data Preprocessing Bayu Distiawan Natural Language Processing & Text Mining Short Course Pusat Ilmu Komputer UI 22 26 Agustus 2016 DATA COLLECTION Fakultas Ilmu Komputer Universitas Indonesia
Data Collection & Data Preprocessing Bayu Distiawan Natural Language Processing & Text Mining Short Course Pusat Ilmu Komputer UI 22 26 Agustus 2016 DATA COLLECTION Fakultas Ilmu Komputer Universitas Indonesia
Web scraping. Donato Summa. 3 WP1 face to face meeting September 2017 Thessaloniki (EL)
") Web scraping Donato Summa Summary Web scraping : Specific vs Generic Web scraping phases Web scraping tools Istat Web scraping chain Summary Web scraping : Specific vs Generic Web scraping phases Web scraping
Web scraping Donato Summa Summary Web scraping : Specific vs Generic Web scraping phases Web scraping tools Istat Web scraping chain Summary Web scraping : Specific vs Generic Web scraping phases Web scraping
wagtail-robots Documentation
 wagtail-robots Documentation Release dev Adrian Turjak Feb 28, 2018 Contents 1 Wagtail Robots In Action 3 2 Installation 9 3 Initialization 11 4 Rules 13 5 URLs 15 6 Caching 17 7 Sitemaps 19 8 Host directive
wagtail-robots Documentation Release dev Adrian Turjak Feb 28, 2018 Contents 1 Wagtail Robots In Action 3 2 Installation 9 3 Initialization 11 4 Rules 13 5 URLs 15 6 Caching 17 7 Sitemaps 19 8 Host directive
Table of contents. 1. Backlink Audit Summary...3. Marketer s Center. 2. Site Auditor Summary Social Audit Summary...9
 EXECUTIVE SUMMARIES Table of contents Marketer s Center 1. Backlink Audit Summary...3 Top Referring TLDs...3 Anchor Text Cloud...3 Anchor Text Phrases...3 Offpage Competitive Comparison...4 Referring Domains...4
EXECUTIVE SUMMARIES Table of contents Marketer s Center 1. Backlink Audit Summary...3 Top Referring TLDs...3 Anchor Text Cloud...3 Anchor Text Phrases...3 Offpage Competitive Comparison...4 Referring Domains...4
HOW DOES A SEARCH ENGINE WORK?
 HOW DOES A SEARCH ENGINE WORK? Hector says... Hi there! Did you know that the World Wide Web is made up of over a trillion web pages? That s more information than you d find in a really big library and
HOW DOES A SEARCH ENGINE WORK? Hector says... Hi there! Did you know that the World Wide Web is made up of over a trillion web pages? That s more information than you d find in a really big library and
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Effective Page Refresh Policies for Web Crawlers
 For CS561 Web Data Management Spring 2013 University of Crete Effective Page Refresh Policies for Web Crawlers and a Semantic Web Document Ranking Model Roger-Alekos Berkley IMSE 2012/2014 Paper 1: Main
For CS561 Web Data Management Spring 2013 University of Crete Effective Page Refresh Policies for Web Crawlers and a Semantic Web Document Ranking Model Roger-Alekos Berkley IMSE 2012/2014 Paper 1: Main
Website Name. Project Code: # SEO Recommendations Report. Version: 1.0
 Website Name Project Code: #10001 Version: 1.0 DocID: SEO/site/rec Issue Date: DD-MM-YYYY Prepared By: - Owned By: Rave Infosys Reviewed By: - Approved By: - 3111 N University Dr. #604 Coral Springs FL
Website Name Project Code: #10001 Version: 1.0 DocID: SEO/site/rec Issue Date: DD-MM-YYYY Prepared By: - Owned By: Rave Infosys Reviewed By: - Approved By: - 3111 N University Dr. #604 Coral Springs FL
Log- in. Go to survey.wisc.edu Log- in using your network ID Create an account with your .
 Qualtrics Log- in Go to survey.wisc.edu Log- in using your network ID Create an account with your email. In the future, you can log- in through survey.wisc.edu and it will bring you to your Qualitrics
Qualtrics Log- in Go to survey.wisc.edu Log- in using your network ID Create an account with your email. In the future, you can log- in through survey.wisc.edu and it will bring you to your Qualitrics
power up your business SEO (SEARCH ENGINE OPTIMISATION)
") SEO (SEARCH ENGINE OPTIMISATION) SEO (SEARCH ENGINE OPTIMISATION) The visibility of your business when a customer is looking for services that you offer is important. The first port of call for most people
SEO (SEARCH ENGINE OPTIMISATION) SEO (SEARCH ENGINE OPTIMISATION) The visibility of your business when a customer is looking for services that you offer is important. The first port of call for most people
A Novel Interface to a Web Crawler using VB.NET Technology
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 6 (Nov. - Dec. 2013), PP 59-63 A Novel Interface to a Web Crawler using VB.NET Technology Deepak Kumar
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661, p- ISSN: 2278-8727Volume 15, Issue 6 (Nov. - Dec. 2013), PP 59-63 A Novel Interface to a Web Crawler using VB.NET Technology Deepak Kumar
Google Search Appliance
 Google Search Appliance Administering Crawl Google Search Appliance software version 7.4 Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com GSA-ADM_200.02 March 2015 Copyright
Google Search Appliance Administering Crawl Google Search Appliance software version 7.4 Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com GSA-ADM_200.02 March 2015 Copyright
DATA MINING II - 1DL460. Spring 2017
 DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2017 A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt17 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Corso di Biblioteche Digitali
 Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION
 San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 2013 YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION Akshat Kukreti Follow this and additional
San Jose State University SJSU ScholarWorks Master's Projects Master's Theses and Graduate Research Spring 2013 YIOOP FULL HISTORICAL INDEXING IN CACHE NAVIGATION Akshat Kukreti Follow this and additional
Corso di Biblioteche Digitali
 Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics
 Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics Media Intelligence Business intelligence (BI) Uses data mining techniques and tools for the transformation of raw data into meaningful
Prof. Ahmet Süerdem Istanbul Bilgi University London School of Economics Media Intelligence Business intelligence (BI) Uses data mining techniques and tools for the transformation of raw data into meaningful
Review of Ezgif.com. Generated on Introduction. Table of Contents. Iconography
 Review of Ezgif.com Generated on 2016-12-11 Introduction This report provides a review of the key factors that influence SEO and the usability of your website. The homepage rank is a grade on a 100-point
Review of Ezgif.com Generated on 2016-12-11 Introduction This report provides a review of the key factors that influence SEO and the usability of your website. The homepage rank is a grade on a 100-point
The Topic Specific Search Engine
 The Topic Specific Search Engine Benjamin Stopford 1 st Jan 2006 Version 0.1 Overview This paper presents a model for creating an accurate topic specific search engine through a focussed (vertical)
The Topic Specific Search Engine Benjamin Stopford 1 st Jan 2006 Version 0.1 Overview This paper presents a model for creating an accurate topic specific search engine through a focussed (vertical)
A FAST COMMUNITY BASED ALGORITHM FOR GENERATING WEB CRAWLER SEEDS SET
 A FAST COMMUNITY BASED ALGORITHM FOR GENERATING WEB CRAWLER SEEDS SET Shervin Daneshpajouh, Mojtaba Mohammadi Nasiri¹ Computer Engineering Department, Sharif University of Technology, Tehran, Iran daneshpajouh@ce.sharif.edu,
A FAST COMMUNITY BASED ALGORITHM FOR GENERATING WEB CRAWLER SEEDS SET Shervin Daneshpajouh, Mojtaba Mohammadi Nasiri¹ Computer Engineering Department, Sharif University of Technology, Tehran, Iran daneshpajouh@ce.sharif.edu,
Parallel Crawlers. 1 Introduction. Junghoo Cho, Hector Garcia-Molina Stanford University {cho,
 Parallel Crawlers Junghoo Cho, Hector Garcia-Molina Stanford University {cho, hector}@cs.stanford.edu Abstract In this paper we study how we can design an effective parallel crawler. As the size of the
Parallel Crawlers Junghoo Cho, Hector Garcia-Molina Stanford University {cho, hector}@cs.stanford.edu Abstract In this paper we study how we can design an effective parallel crawler. As the size of the
Today s lecture. Information Retrieval. Basic crawler operation. Crawling picture. What any crawler must do. Simple picture complications
 Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning, Pandu Nayak and Prabhakar Raghavan Crawling and Duplicates
Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning, Pandu Nayak and Prabhakar Raghavan Crawling and Duplicates
Review of Wordpresskingdom.com
 Review of Wordpresskingdom.com Generated on 208-2-6 Introduction This report provides a review of the key factors that influence the SEO and usability of your website. The homepage rank is a grade on a
Review of Wordpresskingdom.com Generated on 208-2-6 Introduction This report provides a review of the key factors that influence the SEO and usability of your website. The homepage rank is a grade on a
The Web Servers + Crawlers
 Outline The Web Servers + Crawlers HTTP Crawling Server Architecture Connecting on the WWW Internet What happens when you click? Suppose You are at www.yahoo.com/index.html You click on www.grippy.org/mattmarg/
Outline The Web Servers + Crawlers HTTP Crawling Server Architecture Connecting on the WWW Internet What happens when you click? Suppose You are at www.yahoo.com/index.html You click on www.grippy.org/mattmarg/
Search Engine Visibility Analysis
 2018 Search Engine Visibility Analysis We do the market research, so you don t have to! Report For www.yourclientsite.com Contents Introduction... 2 Website Analysis and Recommendations... 3 Current Status
2018 Search Engine Visibility Analysis We do the market research, so you don t have to! Report For www.yourclientsite.com Contents Introduction... 2 Website Analysis and Recommendations... 3 Current Status
Questions. 6. Suppose we were to define a hash code on strings s by:
 Questions 1. Suppose you are given a list of n elements. A brute force method to find duplicates could use two (nested) loops. The outer loop iterates over position i the list, and the inner loop iterates
Questions 1. Suppose you are given a list of n elements. A brute force method to find duplicates could use two (nested) loops. The outer loop iterates over position i the list, and the inner loop iterates
12. Web Spidering. These notes are based, in part, on notes by Dr. Raymond J. Mooney at the University of Texas at Austin.
 12. Web Spidering These notes are based, in part, on notes by Dr. Raymond J. Mooney at the University of Texas at Austin. 1 Web Search Web Spider Document corpus Query String IR System 1. Page1 2. Page2
12. Web Spidering These notes are based, in part, on notes by Dr. Raymond J. Mooney at the University of Texas at Austin. 1 Web Search Web Spider Document corpus Query String IR System 1. Page1 2. Page2
Natural Language Processing Technique for Information Extraction and Analysis
 International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 2, Issue 8, August 2015, PP 32-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Natural
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 2, Issue 8, August 2015, PP 32-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Natural
EECS 395/495 Lecture 5: Web Crawlers. Doug Downey
 EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
Lecture 3: Semaphores (chap. 6) K. V. S. Prasad Dept of Computer Science Chalmer University 6 Sep 2013
 K. V. S. Prasad Dept of Computer Science Chalmer University 6 Sep 2013") Lecture 3: Semaphores (chap. 6) K. V. S. Prasad Dept of Computer Science Chalmer University 6 Sep 2013 QuesFons? Anything you did not get Was I too fast/slow? Have you joined the google group? Found a
Lecture 3: Semaphores (chap. 6) K. V. S. Prasad Dept of Computer Science Chalmer University 6 Sep 2013 QuesFons? Anything you did not get Was I too fast/slow? Have you joined the google group? Found a
Search Engines. Charles Severance
 Search Engines Charles Severance Google Architecture Web Crawling Index Building Searching http://infolab.stanford.edu/~backrub/google.html Google Search Google I/O '08 Keynote by Marissa Mayer Usablity
Search Engines Charles Severance Google Architecture Web Crawling Index Building Searching http://infolab.stanford.edu/~backrub/google.html Google Search Google I/O '08 Keynote by Marissa Mayer Usablity
Chapter IR:IX. IX. Acquisition. Crawling the Web Conversion Storing Documents
 Chapter IR:IX IX. Acquisition Conversion Storing Documents IR:IX-1 Acquisition HAGEN/POTTHAST/STEIN 2018 Web Technology Internet World Wide Web Addressing HTTP HTML Web Graph IR:IX-2 Acquisition HAGEN/POTTHAST/STEIN
Chapter IR:IX IX. Acquisition Conversion Storing Documents IR:IX-1 Acquisition HAGEN/POTTHAST/STEIN 2018 Web Technology Internet World Wide Web Addressing HTTP HTML Web Graph IR:IX-2 Acquisition HAGEN/POTTHAST/STEIN
Digital Marketing. Introduction of Marketing. Introductions
 Digital Marketing Introduction of Marketing Origin of Marketing Why Marketing is important? What is Marketing? Understanding Marketing Processes Pillars of marketing Marketing is Communication Mass Communication
Digital Marketing Introduction of Marketing Origin of Marketing Why Marketing is important? What is Marketing? Understanding Marketing Processes Pillars of marketing Marketing is Communication Mass Communication
Web Crawling. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.