Human Pose Estimation with Deep Learning. Wei Yang
|
|
|
- Arlene Allison Malone
- 5 years ago
- Views:
Transcription

1 Human Pose Estimation with Deep Learning Wei Yang
 - The Bank Robbery Scene 2")
2 Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2


3 What do we need to know to recognize a crime scene? 3
4 stand stand Cues Scene: bank Abnormal pose Lay down Lay down Lay down Hands up Activity: robbery 4
5 Why is human pose estimation challenging? 5
6 #1. Articulation #2. Occlusion #3. Scale variation 6
7 #1. Articulation #2. Occlusion #3. Scale variation 7
8 #1. Articulation #2. Occlusion #3. Scale variation 8


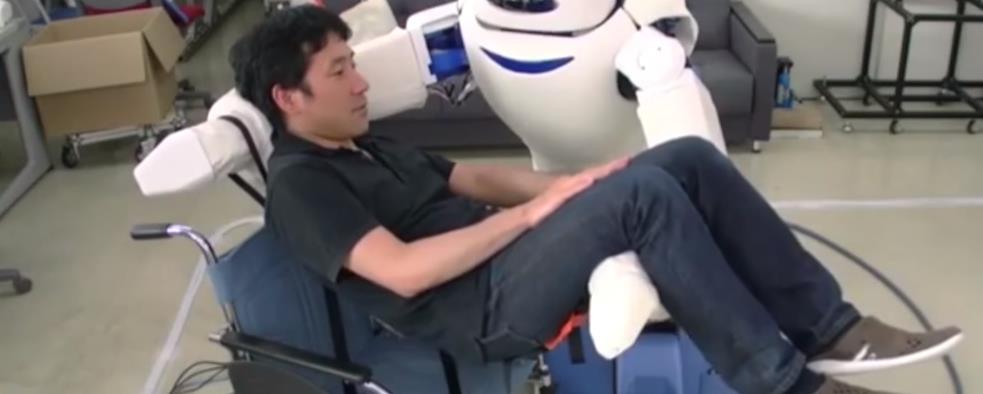

9 Applications Understand Activities Family Robots 9

10 3D Human Poses Real-Time Imitation of Human Whole-Body Motions by Humanoids. J. Koenemann, F. Burget, and M. Bennewitz. ICRA,



11 Deep Learning Based Methods Fully Convolutional Network Regression with Euclidean Loss: P heatmaps H p L = 1 σ P 2 2 p=1 H p H p 2 where H p N l p, Σ, s. t., p = 1,, P 11
12 Outline Scale 3D Pose Gray Feature pyramid learning Black In-the-wild 3D pose estimation ICCV 2017 CVPR
13 Outline Scale 3D Pose Gray Feature pyramid learning Black In-the-wild 3D pose estimation ICCV 2017 CVPR

14 Why the Scale Matters? Yipin Yang, Yao Yu, Yu Zhou, Sidan Du, James Davis, Ruigang Yang. Semantic Parametric Reshaping of Human Body Models. In 3DV Workshop on Dynamic Shape Measurement and Analysis,


15 Why the Scale Matters? Learning Feature Pyramids for Human Pose Estimation Wei Yang, Shuang Li, Wanli Ouyang, Hongsheng Li, Xiaogang Wang ICCV,

16 Previous work Multi-scale testing Multi-branch network The model itself is not scale invariant Felzenszwalb, Pedro F., et al. "Object detection with discriminatively trained part-based models." TPAMI, Need much more memory and computation Tompson, Jonathan, et al. "Efficient object localization using convolutional networks." CVPR

![estimation[c]//european Conference on](/docs-images/90/102232214/images/17-1.jpg "Computer Vision.")
17 Hourglass Newell A, Yang K, Deng J. Stacked hourglass networks for human pose estimation[c]//european Conference on Computer Vision. Springer, Cham, 2016:
 Newell et al. Stacked Hourglass Networks for Human Pose Estimation.")
18 Identity Mapping Conv PRM + Pool PRM Pyramid Residual Modules 256x Stack 1 Stack n (a) x (l) Hourglass Hourglass Ratio 1 Ratio n (b) f 1 f C Detailed hourglass structure f 0 g Convolution Pyramid Residual module Score maps Addition x (l+1) Newell et al. Stacked Hourglass Networks for Human Pose Estimation. ECCV,

, are not applicable for multi-branch networks.")
19 Initialization of Multi-Branch Networks Single-branch networks VGG Multi-branch networks Inceptions Traditional weight initialization methods, e.g., Gaussian, Xavier, MSRA (Kaiming), are not applicable for multi-branch networks. Xavier Glorot, Yoshua Bengio ; Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, PMLR 9: ,
20 Forward Backward Initialization of Multi-Branch Networks x 1 (l) x2 (l) (l) x ci x (l) Conv / FC Conv / FC y (l) C i (l) y (l) = W (l) (l) x c + b (l) c=1 x (l+1) = f(y (l) ) y 1 (l) y2 (l) C o (l) Δx (l) = W l T Δy (l) c=1 Δy (l) = f (y l )Δx (l+1) (l) y co αc i l n i l Var ω l = 1 αc o l n o l Var ω l = 1 * α = 0.5 for ReLU and 1 for Tanh and Sigmoid. 20
21 OUTPUT STD Initialization of Multi-Branch Networks 1.1 MSR init Ours init LAYER INDEX He, Kaiming, et al. "Delving deep into rectifiers: Surpassing human-level performance on imagenet classification." ICCV

22 Qualitative Results MPII dataset LSP dataset 22
23 Evaluation Metric PCK: Percentage of Correct Keypoints α max(h, w) 23

24 Results on MPII Human Pose State-of-the-art performance 24
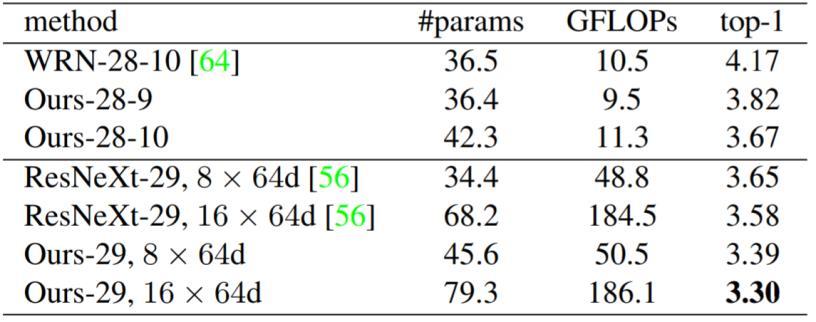

25 Image Classification Top-1 Test Error on CIFAR-10 25










26 Semantic Segmentation: PASCAL VOC 2012 dataset (a) Image (b) DeepLab (c) DeepLap+PRM (a) Image (b) DeepLab (c) DeepLap+PRM (a) Image (b) DeepLab (c) DeepLap+PRM
27 Section Summary Feature pyramid module Generalizable for various networks and tasks Weight initialization for multi-branch networks Learning Feature Pyramids for Human Pose Estimation Wei Yang, Shuang Li, Wanli Ouyang, Hongsheng Li, Xiaogang Wang ICCV,
28 Outline Scale 3D Pose Gray Feature pyramid learning Black In-the-wild 3D pose estimation ICCV 2017 CVPR



29 Challenges: No Annotation Constrained scenes In-the-wild scenes Domain Discrepancy No annotation 29
30 Which one is more plausible? Discriminator 30

31 Weakly Supervised Adversarial Learning 3D dataset Images w/o GT Real Fake G 3D Human Pose Estimator Prediction D Multi-source Discriminator Ground-truth 31
32 Adversarial Learning Fool Generator Discriminator Loss G Euclidean Loss Tell Loss D Classification Loss 32
33 Conv Residual Residual Depth Generator 2D module Depth module 256x Stack 1 Stack n Hourglass 2D score maps 3D Poses 33



34 Discriminator 34









35 64 P 256 Multi-Source Discriminator Real or Fake samples Image I CNN Geometric descriptor P [Δx, Δy, Δz] [Δx 2, Δy 2, Δz 2 ] CNN Fully Connected layers Real Fake Raw poses CNN 64 2D Heatmaps Depthmaps Concatenation 35

36 Effectiveness of Adversarial Learning 36
37 (Ours) Ablation Study on H36M Dataset MPJPE (error in mm) on H36M Image+Pose+Geo Image+Geo Image+Pose Jointly learn 2D + depth Fix 2D, finetune depth Zhou et al. ICCV % less error Full Geo Pose Baseline Baseline (fix 2D) State-of-art* *Zhou et al. ICCV 17 37


38 Ours baseline Results on Images in the Wild 38

39 Multi-view Results 39
40 Section Summary Weakly supervised adversarial learning for 3D pose estimation in the wild Multi-source discriminator 3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang, Wanli Ouyang, Xiaolong Wang, Hongsheng Li, Xiaogang Wang CVPR,
41 Code Open-source PyTorch code ICCV
42 Thanks! 42
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
 Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material
 Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
3D Human Pose Estimation in the Wild by Adversarial Learning
 3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang 1 Wanli Ouyang 2 Xiaolong Wang 3 Jimmy Ren 4 Hongsheng Li 1 Xiaogang Wang 1 1 CUHK-SenseTime Joint Lab, The Chinese University of Hong
3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang 1 Wanli Ouyang 2 Xiaolong Wang 3 Jimmy Ren 4 Hongsheng Li 1 Xiaogang Wang 1 1 CUHK-SenseTime Joint Lab, The Chinese University of Hong
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
CNNS FROM THE BASICS TO RECENT ADVANCES. Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague
 CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification
 Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification Xiaodong Yang, Pavlo Molchanov, Jan Kautz INTELLIGENT VIDEO ANALYTICS Surveillance event detection Human-computer interaction
Multilayer and Multimodal Fusion of Deep Neural Networks for Video Classification Xiaodong Yang, Pavlo Molchanov, Jan Kautz INTELLIGENT VIDEO ANALYTICS Surveillance event detection Human-computer interaction
Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images
 Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images Wenlin Zhuang 1, Cong Peng 2, Siyu Xia 1, and Yangang, Wang 1 1 School of Automation, Southeast University, Nanjing, China
Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images Wenlin Zhuang 1, Cong Peng 2, Siyu Xia 1, and Yangang, Wang 1 1 School of Automation, Southeast University, Nanjing, China
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Learning Deep Features for Visual Recognition
 7x7 conv, 64, /2, pool/2 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 128, /2 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv,
7x7 conv, 64, /2, pool/2 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 64 3x3 conv, 64 1x1 conv, 128, /2 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv,
Speaker: Ming-Ming Cheng Nankai University 15-Sep-17 Towards Weakly Supervised Image Understanding
 Towards Weakly Supervised Image Understanding (WSIU) Speaker: Ming-Ming Cheng Nankai University http://mmcheng.net/ 1/50 Understanding Visual Information Image by kirkh.deviantart.com 2/50 Dataset Annotation
Towards Weakly Supervised Image Understanding (WSIU) Speaker: Ming-Ming Cheng Nankai University http://mmcheng.net/ 1/50 Understanding Visual Information Image by kirkh.deviantart.com 2/50 Dataset Annotation
Crafting GBD-Net for Object Detection
 MANUSCRIPT 1 Crafting GBD-Net for Object Detection Xingyu Zeng*,Wanli Ouyang*,Junjie Yan, Hongsheng Li,Tong Xiao, Kun Wang, Yu Liu, Yucong Zhou, Bin Yang, Zhe Wang,Hui Zhou, Xiaogang Wang, To handle these
MANUSCRIPT 1 Crafting GBD-Net for Object Detection Xingyu Zeng*,Wanli Ouyang*,Junjie Yan, Hongsheng Li,Tong Xiao, Kun Wang, Yu Liu, Yucong Zhou, Bin Yang, Zhe Wang,Hui Zhou, Xiaogang Wang, To handle these
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION
 LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
Human Pose Estimation using Global and Local Normalization. Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang
 Human Pose Estimation using Global and Local Normalization Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang Overview of the supplementary material In this supplementary material,
Human Pose Estimation using Global and Local Normalization Ke Sun, Cuiling Lan, Junliang Xing, Wenjun Zeng, Dong Liu, Jingdong Wang Overview of the supplementary material In this supplementary material,
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Learning Deep Representations for Visual Recognition
 Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Learning Deep Representations for Visual Recognition CVPR 2018 Tutorial Kaiming He Facebook AI Research (FAIR) Deep Learning is Representation Learning Representation Learning: worth a conference name
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Photo OCR ( )
") Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Photo OCR (2017-2018) Xiang Bai Huazhong University of Science and Technology Outline VALSE2018, DaLian Xiang Bai 2 Deep Direct Regression for Multi-Oriented Scene Text Detection [He et al., ICCV, 2017.]
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL
 SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Generative Modeling with Convolutional Neural Networks. Denis Dus Data Scientist at InData Labs
 Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
Generative Modeling with Convolutional Neural Networks Denis Dus Data Scientist at InData Labs What we will discuss 1. 2. 3. 4. Discriminative vs Generative modeling Convolutional Neural Networks How to
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
THE task of human pose estimation is to determine the. Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation
 1 Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation Guanghan Ning, Student Member, IEEE, Zhi Zhang, Student Member, IEEE, and Zhihai He, Fellow, IEEE arxiv:1705.02407v2 [cs.cv] 8
1 Knowledge-Guided Deep Fractal Neural Networks for Human Pose Estimation Guanghan Ning, Student Member, IEEE, Zhi Zhang, Student Member, IEEE, and Zhihai He, Fellow, IEEE arxiv:1705.02407v2 [cs.cv] 8
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
MSCOCO Keypoints Challenge Megvii (Face++)
") MSCOCO Keypoints Challenge 2017 Megvii (Face++) Team members(keypoints & Detection): Yilun Chen* Zhicheng Wang* Xiangyu Peng Zhiqiang Zhang Gang Yu Chao Peng Tete Xiao Zeming Li Xiangyu Zhang Yuning Jiang
MSCOCO Keypoints Challenge 2017 Megvii (Face++) Team members(keypoints & Detection): Yilun Chen* Zhicheng Wang* Xiangyu Peng Zhiqiang Zhang Gang Yu Chao Peng Tete Xiao Zeming Li Xiangyu Zhang Yuning Jiang
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Towards Weakly- and Semi- Supervised Object Localization and Semantic Segmentation
 Towards Weakly- and Semi- Supervised Object Localization and Semantic Segmentation Lecturer: Yunchao Wei Image Formation and Processing (IFP) Group University of Illinois at Urbanahttps://weiyc.githu Champaign
Towards Weakly- and Semi- Supervised Object Localization and Semantic Segmentation Lecturer: Yunchao Wei Image Formation and Processing (IFP) Group University of Illinois at Urbanahttps://weiyc.githu Champaign
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
Generative Networks. James Hays Computer Vision
 Generative Networks James Hays Computer Vision Interesting Illusion: Ames Window https://www.youtube.com/watch?v=ahjqe8eukhc https://en.wikipedia.org/wiki/ames_trapezoid Recap Unsupervised Learning Style
Generative Networks James Hays Computer Vision Interesting Illusion: Ames Window https://www.youtube.com/watch?v=ahjqe8eukhc https://en.wikipedia.org/wiki/ames_trapezoid Recap Unsupervised Learning Style
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Lab meeting (Paper review session) Stacked Generative Adversarial Networks
 Stacked Generative Adversarial Networks") Lab meeting (Paper review session) Stacked Generative Adversarial Networks 2017. 02. 01. Saehoon Kim (Ph. D. candidate) Machine Learning Group Papers to be covered Stacked Generative Adversarial Networks
Lab meeting (Paper review session) Stacked Generative Adversarial Networks 2017. 02. 01. Saehoon Kim (Ph. D. candidate) Machine Learning Group Papers to be covered Stacked Generative Adversarial Networks
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Introduction to Deep Learning for Facial Understanding Part III: Regional CNNs
 Introduction to Deep Learning for Facial Understanding Part III: Regional CNNs Raymond Ptucha, Rochester Institute of Technology, USA Tutorial-9 May 19, 218 www.nvidia.com/dli R. Ptucha 18 1 Fair Use Agreement
Introduction to Deep Learning for Facial Understanding Part III: Regional CNNs Raymond Ptucha, Rochester Institute of Technology, USA Tutorial-9 May 19, 218 www.nvidia.com/dli R. Ptucha 18 1 Fair Use Agreement
Progress in Computer Vision in the Last Decade & Open Problems: People Detection & Human Pose Estimation
 Progress in Computer Vision in the Last Decade & Open Problems: People Detection & Human Pose Estimation Bernt Schiele Max Planck Institute for Informatics & Saarland University, Saarland Informatics Campus
Progress in Computer Vision in the Last Decade & Open Problems: People Detection & Human Pose Estimation Bernt Schiele Max Planck Institute for Informatics & Saarland University, Saarland Informatics Campus
arxiv: v1 [cs.cv] 6 Oct 2017
![arxiv: v1 [cs.cv] 6 Oct 2017](/thumbs/79/79518536.jpg "arxiv: v1 [cs.cv] 6 Oct 2017") Human Pose Regression by Combining Indirect Part Detection and Contextual Information arxiv:1710.02322v1 [cs.cv] 6 Oct 2017 Diogo C. Luvizon Abstract In this paper, we propose an end-to-end trainable regression
Human Pose Regression by Combining Indirect Part Detection and Contextual Information arxiv:1710.02322v1 [cs.cv] 6 Oct 2017 Diogo C. Luvizon Abstract In this paper, we propose an end-to-end trainable regression
arxiv: v1 [cs.cv] 12 Sep 2018
![arxiv: v1 [cs.cv] 12 Sep 2018](/thumbs/93/112746977.jpg "arxiv: v1 [cs.cv] 12 Sep 2018") In Proceedings of the 2018 IEEE International Conference on Image Processing (ICIP) The final publication is available at: http://dx.doi.org/10.1109/icip.2018.8451026 A TWO-STEP LEARNING METHOD FOR DETECTING
In Proceedings of the 2018 IEEE International Conference on Image Processing (ICIP) The final publication is available at: http://dx.doi.org/10.1109/icip.2018.8451026 A TWO-STEP LEARNING METHOD FOR DETECTING
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Final Report: Smart Trash Net: Waste Localization and Classification
 Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015)
") AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
CENG 783. Special topics in. Deep Learning. AlchemyAPI. Week 11. Sinan Kalkan
 CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
CENG 783 Special topics in Deep Learning AlchemyAPI Week 11 Sinan Kalkan TRAINING A CNN Fig: http://www.robots.ox.ac.uk/~vgg/practicals/cnn/ Feed-forward pass Note that this is written in terms of the
A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation
 A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Submission ID: 2065 Abstract Accurate keypoint localization of human pose needs diversified features:
A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Submission ID: 2065 Abstract Accurate keypoint localization of human pose needs diversified features:
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Wentao Liu, 1,2 Jie Chen,
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation Wentao Liu, 1,2 Jie Chen,
Bidirectional Recurrent Convolutional Networks for Video Super-Resolution
 Bidirectional Recurrent Convolutional Networks for Video Super-Resolution Qi Zhang & Yan Huang Center for Research on Intelligent Perception and Computing (CRIPAC) National Laboratory of Pattern Recognition
Bidirectional Recurrent Convolutional Networks for Video Super-Resolution Qi Zhang & Yan Huang Center for Research on Intelligent Perception and Computing (CRIPAC) National Laboratory of Pattern Recognition
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Convolution Neural Network for Traditional Chinese Calligraphy Recognition
 Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution