AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
|
|
|
- Loren Stafford
- 5 years ago
- Views:
Transcription
1 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth approach for both NYUD and KITTI datasets. We also present architectural details of the two discriminators D F and D Y as introduced in the main paper. Discriminator Architecture In Table 1 and Table 2, we present architecture details of the two discriminator, D Y and D F respectively. For discriminator network D Y, we follow Patch-GAN s [2] convolutional architecture with an input receptive field of size close to Layer Type Filter Size Filter Num Stride Output Size Input c1 Conv c2 Conv* c3 Conv* c4 Conv* c5 Conv* c6 Conv* c7 Conv* c8 Conv* c9 Conv* c10 Conv Table 1: Network architecture of discriminator, D Y applied on the single channel depth map. Padding is kept as SAME for all convolution layers. Conv* denotes standard convolutional layers followed by a batch-normalization with leaky-relu non-linearity. 1
2 Layer Type Filter Size Filter Num Stride Output Size Input layer-0 Conv layer-1 Conv* layer-1a Conv* layer-2 Conv* layer-2a Conv* layer-3 Conv* layer-3a Conv* layer-fc1 FC* layer-fc2 FC Table 2: Network architecture of discriminator, D F applied on Res-5c activation map(input layer). Padding is kept as SAME for all convolution layers. Conv* denotes standard convolutional layers followed by a batch-normalization with leaky-relu non-linearity. Additional Qualitative Results Figure 1 shows further qualitative results of our unsupervised depth adaptation approach AdaDepth-U along with the semi-supervised variant AdaDepth-S for NYUD dataset. In contrast to the existing fully-supervised approaches (Laina et al. [3] and Eigen et al. [1]), our semi-supervised approach achieves better performance by predicting depth values close to the ground-truth depth map, as can be seen in of Figure 1 and Figure 2. For better visualization, Figure 2 shows the error-map of depth prediction with respect to the corresponding ground-truth. This clearly demonstrates the superiority of the proposed approach over the previous state-of-the-arts methods. The results of Eigen et al. [1] and Laina et al. [3] exhibit more error on major background regions as compared to our results. For an unbiased comparison, we also share some results based on our best, median and worst metric scores for images in Figure 3. The qualitative results for KITTI dataset are shown in Figure 4. The test images are from the commonly used 697 test images from Eigen split [1]. As the ground-truth LIDAR data is very sparse, we interpolate the depth map for better visualization. For a fair comparison, we only show predictions for the cropped region following [1]. Compared to Zhou et al., predictions from AdaDepth-S are sharper, preserve more local information and are closer to the ground-truth depth map. 2




![The results of [1]](/docs-images/96/128264022/images/3-38.jpg "exhibit low-level spatial")





.")
 and row-8")
3 RGB Image Laina et al. Eigen et al. AdaDepth-U (FCF) AdaDepth-S Figure 1: Qualitative comparison of AdaDepth-U and AdaDepth-S against fully-supervised Laina et al. [3] and Eigen et al. [1]. The results of Eigen et al. [1] exhibit low-level spatial details but fail to regress to ground-truth depth values (the upper part of sofa in 8 th row and the part of table towards the wall in 6 th row). Laina et al. on the other hand regress to better depth values generally but suffer with lack of precision on the edges (bed in row 4 th ). Row-3(prediction on new scenes) and row-8 (low-contrast background) shows some of our failure cases. 3
































4 RGB Image Laina et al. Eigen et al. AdaDepth-U (FCF) AdaDepth-S Depth Figure 2: Qualitative comparison of AdaDepth-U and AdaDepth-S against Laina et al. [3] and Eigen et al. [1] from their corresponding error maps. The error-maps are computed as absolute difference between the prediction and corresponding ground-truth. For fair comparison the color scale on error map shows absolute error values from 0(blue) to 2(red) except for the last column, where it shows actual ground-truth depth. 4







































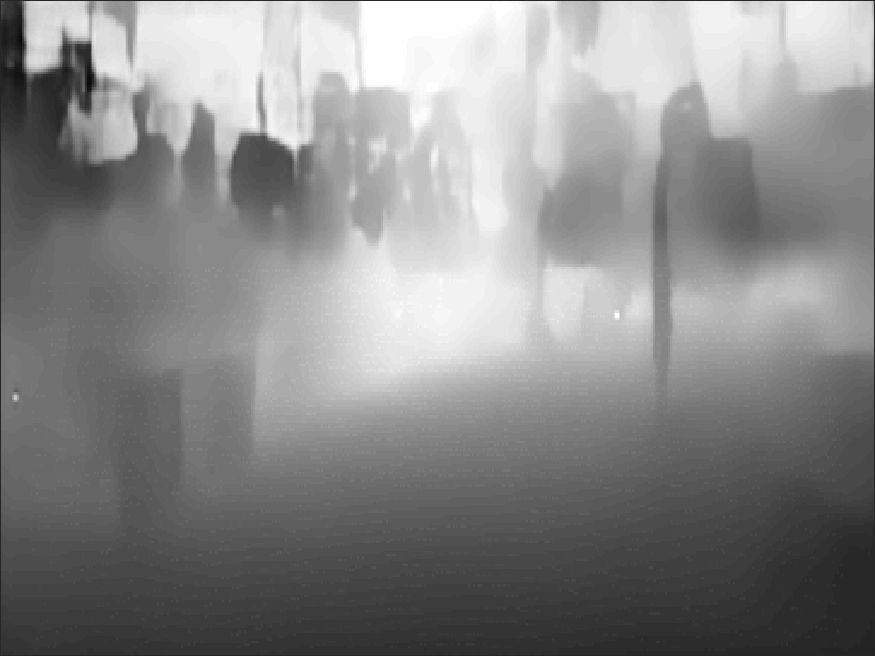



5 RGB Image Laina et al. AdaDepth-U(FCF) AdaDepth-S Randomly chosen from best 10 percentile images Randomly chosen from best percentile images Randomly chosen from worst 10 percentile images Figure 3: The percentile ranges are obtained by sorting results on NYUD test set as per the rel metric. RGB Image Zhou et al. AdaDepth-S Figure 4: Qualitative comparison of AdaDepth-S, our semi-supervised adaptation approach against Zhou et al. [4]. Compared to Zhou et al., predictions from AdaDepth-S are sharper, preserve more local information and are closer to the ground-truth depth map. 5
6 References [1] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, [2] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, [3] I. Laina, C. Rupprecht, V. Belagiannis, F. Tombari, and N. Navab. Deeper depth prediction with fully convolutional residual networks. In 3DV, [4] T. Zhou, M. Brown, N. Snavely, and D. G. Lowe. Unsupervised learning of depth and ego-motion from video. In CVPR,
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials)
") ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
Fully Convolutional Network for Depth Estimation and Semantic Segmentation
 Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
arxiv: v1 [cs.cv] 17 Oct 2016
![arxiv: v1 [cs.cv] 17 Oct 2016](/thumbs/83/87289105.jpg "arxiv: v1 [cs.cv] 17 Oct 2016") Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation Yiyi Liao 1, Lichao Huang 2, Yue Wang 1, Sarath Kodagoda 3, Yinan Yu 2, Yong Liu 1 arxiv:1611.02174v1 [cs.cv] 17 Oct
Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation Yiyi Liao 1, Lichao Huang 2, Yue Wang 1, Sarath Kodagoda 3, Yinan Yu 2, Yong Liu 1 arxiv:1611.02174v1 [cs.cv] 17 Oct
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Deep Back-Projection Networks For Super-Resolution Supplementary Material
 Deep Back-Projection Networks For Super-Resolution Supplementary Material Muhammad Haris 1, Greg Shakhnarovich 2, and Norimichi Ukita 1, 1 Toyota Technological Institute, Japan 2 Toyota Technological Institute
Deep Back-Projection Networks For Super-Resolution Supplementary Material Muhammad Haris 1, Greg Shakhnarovich 2, and Norimichi Ukita 1, 1 Toyota Technological Institute, Japan 2 Toyota Technological Institute
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary: Cross-modal Deep Variational Hand Pose Estimation
 Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
 Semi-Supervised Deep Learning for Monocular Depth Map Prediction Yevhen Kuznietsov Jörg Stückler Bastian Leibe Computer Vision Group, Visual Computing Institute, RWTH Aachen University yevhen.kuznietsov@rwth-aachen.de,
Semi-Supervised Deep Learning for Monocular Depth Map Prediction Yevhen Kuznietsov Jörg Stückler Bastian Leibe Computer Vision Group, Visual Computing Institute, RWTH Aachen University yevhen.kuznietsov@rwth-aachen.de,
arxiv: v2 [cs.cv] 9 Mar 2018
![arxiv: v2 [cs.cv] 9 Mar 2018](/thumbs/80/82468949.jpg "arxiv: v2 [cs.cv] 9 Mar 2018") Single View Stereo Matching Yue Luo 1 Jimmy Ren 1 Mude Lin 1 Jiahao Pang 1 Wenxiu Sun 1 Hongsheng Li 2 Liang Lin 1,3 arxiv:1803.02612v2 [cs.cv] 9 Mar 2018 1 SenseTime Research 2 The Chinese University
Single View Stereo Matching Yue Luo 1 Jimmy Ren 1 Mude Lin 1 Jiahao Pang 1 Wenxiu Sun 1 Hongsheng Li 2 Liang Lin 1,3 arxiv:1803.02612v2 [cs.cv] 9 Mar 2018 1 SenseTime Research 2 The Chinese University
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Depth Estimation from Single Image Using CNN-Residual Network
 Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Real-Time Depth Estimation from 2D Images
 Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Single Image Super Resolution of Textures via CNNs. Andrew Palmer
 Single Image Super Resolution of Textures via CNNs Andrew Palmer What is Super Resolution (SR)? Simple: Obtain one or more high-resolution images from one or more low-resolution ones Many, many applications
Single Image Super Resolution of Textures via CNNs Andrew Palmer What is Super Resolution (SR)? Simple: Obtain one or more high-resolution images from one or more low-resolution ones Many, many applications
Intro to Deep Learning. Slides Credit: Andrej Karapathy, Derek Hoiem, Marc Aurelio, Yann LeCunn
 Intro to Deep Learning Slides Credit: Andrej Karapathy, Derek Hoiem, Marc Aurelio, Yann LeCunn Why this class? Deep Features Have been able to harness the big data in the most efficient and effective
Intro to Deep Learning Slides Credit: Andrej Karapathy, Derek Hoiem, Marc Aurelio, Yann LeCunn Why this class? Deep Features Have been able to harness the big data in the most efficient and effective
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Multi-Task Self-Supervised Visual Learning
 Multi-Task Self-Supervised Visual Learning Sikai Zhong March 4, 2018 COMPUTER SCIENCE Table of contents 1. Introduction 2. Self-supervised Tasks 3. Architectures 4. Experiments 1 Introduction Self-supervised
Multi-Task Self-Supervised Visual Learning Sikai Zhong March 4, 2018 COMPUTER SCIENCE Table of contents 1. Introduction 2. Self-supervised Tasks 3. Architectures 4. Experiments 1 Introduction Self-supervised
Towards real-time unsupervised monocular depth estimation on CPU
 Towards real-time unsupervised monocular depth estimation on CPU Matteo Poggi1, Filippo Aleotti2, Fabio Tosi1, Stefano Mattoccia1 Abstract Unsupervised depth estimation from a single image is a very attractive
Towards real-time unsupervised monocular depth estimation on CPU Matteo Poggi1, Filippo Aleotti2, Fabio Tosi1, Stefano Mattoccia1 Abstract Unsupervised depth estimation from a single image is a very attractive
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
arxiv: v1 [cs.cv] 29 Mar 2018
![arxiv: v1 [cs.cv] 29 Mar 2018](/thumbs/77/76324907.jpg "arxiv: v1 [cs.cv] 29 Mar 2018") Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation Dan Xu, Wei Wang, Hao Tang, Hong Liu 2, Nicu Sebe, Elisa Ricci,3 Multimedia and Human Understanding Group, University
Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation Dan Xu, Wei Wang, Hao Tang, Hong Liu 2, Nicu Sebe, Elisa Ricci,3 Multimedia and Human Understanding Group, University
SINGLE image super-resolution (SR) aims to reconstruct
 aims to reconstruct") Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang 1 arxiv:1710.01992v2 [cs.cv] 11 Oct 2017 Abstract Convolutional
Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang 1 arxiv:1710.01992v2 [cs.cv] 11 Oct 2017 Abstract Convolutional
SINGLE image super-resolution (SR) aims to reconstruct
 aims to reconstruct") Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang 1 arxiv:1710.01992v3 [cs.cv] 9 Aug 2018 Abstract Convolutional
Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang 1 arxiv:1710.01992v3 [cs.cv] 9 Aug 2018 Abstract Convolutional
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
arxiv: v2 [cs.ro] 26 Feb 2018
![arxiv: v2 [cs.ro] 26 Feb 2018](/thumbs/81/83191831.jpg "arxiv: v2 [cs.ro] 26 Feb 2018") Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image Fangchang Ma 1 and Sertac Karaman 1 arxiv:179.7492v2 [cs.ro] 26 Feb 218 Abstract We consider the problem of dense depth prediction
Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image Fangchang Ma 1 and Sertac Karaman 1 arxiv:179.7492v2 [cs.ro] 26 Feb 218 Abstract We consider the problem of dense depth prediction
Monocular Depth Estimation with Ainity, Vertical Pooling, and Label Enhancement
 Monocular Depth Estimation with Ainity, Vertical Pooling, and Label Enhancement Yukang Gan 1,2, Xiangyu Xu 1,3, Wenxiu Sun 1, and Liang Lin 1,2 1 SenseTime 2 Sun Yat-sen University 3 Tsinghua University
Monocular Depth Estimation with Ainity, Vertical Pooling, and Label Enhancement Yukang Gan 1,2, Xiangyu Xu 1,3, Wenxiu Sun 1, and Liang Lin 1,2 1 SenseTime 2 Sun Yat-sen University 3 Tsinghua University
DepthNet: A Recurrent Neural Network Architecture for Monocular Depth Prediction
 DepthNet: A Recurrent Neural Network Architecture for Monocular Depth Prediction Arun CS Kumar Suchendra M. Bhandarkar The University of Georgia aruncs@uga.edu suchi@cs.uga.edu Mukta Prasad Trinity College
DepthNet: A Recurrent Neural Network Architecture for Monocular Depth Prediction Arun CS Kumar Suchendra M. Bhandarkar The University of Georgia aruncs@uga.edu suchi@cs.uga.edu Mukta Prasad Trinity College
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
From 3D descriptors to monocular 6D pose: what have we learned?
 ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
ECCV Workshop on Recovering 6D Object Pose From 3D descriptors to monocular 6D pose: what have we learned? Federico Tombari CAMP - TUM Dynamic occlusion Low latency High accuracy, low jitter No expensive
What was Monet seeing while painting? Translating artworks to photo-realistic images M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara
 What was Monet seeing while painting? Translating artworks to photo-realistic images M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara COMPUTER VISION IN THE ARTISTIC DOMAIN The effectiveness of Computer Vision
What was Monet seeing while painting? Translating artworks to photo-realistic images M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara COMPUTER VISION IN THE ARTISTIC DOMAIN The effectiveness of Computer Vision
Computing the Stereo Matching Cost with CNN
 University at Austin Figure. The of lefttexas column displays the left input image, while the right column displays the output of our stereo method. Examples are sorted by difficulty, with easy examples
University at Austin Figure. The of lefttexas column displays the left input image, while the right column displays the output of our stereo method. Examples are sorted by difficulty, with easy examples
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS. Mustafa Ozan Tezcan
 MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
3D Box Proposals from a Single Monocular Image of an Indoor Scene
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI8) 3D Box Proposals from a Single Monocular Image of an Indoor Scene Wei Zhuo,,4 Mathieu Salzmann, Xuming He, 3 Miaomiao Liu,4 Australian
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI8) 3D Box Proposals from a Single Monocular Image of an Indoor Scene Wei Zhuo,,4 Mathieu Salzmann, Xuming He, 3 Miaomiao Liu,4 Australian
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Supplementary Material for Sparsity Invariant CNNs
 Supplementary Material for Sparsity Invariant CNNs Jonas Uhrig,1,2 Nick Schneider,1,3 Lukas Schneider 1,4 Uwe Franke 1 Thomas Brox 2 Andreas Geiger 4,5 1 Daimler R&D Sindelfingen 2 University of Freiburg
Supplementary Material for Sparsity Invariant CNNs Jonas Uhrig,1,2 Nick Schneider,1,3 Lukas Schneider 1,4 Uwe Franke 1 Thomas Brox 2 Andreas Geiger 4,5 1 Daimler R&D Sindelfingen 2 University of Freiburg
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
CNN for Low Level Image Processing. Huanjing Yue
 CNN for Low Level Image Processing Huanjing Yue 2017.11 1 Deep Learning for Image Restoration General formulation: min Θ L( x, x) s. t. x = F(y; Θ) Loss function Parameters to be learned Key issues The
CNN for Low Level Image Processing Huanjing Yue 2017.11 1 Deep Learning for Image Restoration General formulation: min Θ L( x, x) s. t. x = F(y; Θ) Loss function Parameters to be learned Key issues The
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Two-Stream Convolutional Networks for Action Recognition in Videos
 Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
arxiv: v2 [cs.cv] 3 Jul 2018
![arxiv: v2 [cs.cv] 3 Jul 2018](/thumbs/92/108366420.jpg "arxiv: v2 [cs.cv] 3 Jul 2018") Self-Supervised Sparse-to-Dense: Self-Supervised Depth Completion from LiDAR and Monocular Camera Fangchang Ma, Guilherme Venturelli Cavalheiro, Sertac Karaman Massachusetts Institute of Technology {fcma,guivenca,sertac}@mit.edu
Self-Supervised Sparse-to-Dense: Self-Supervised Depth Completion from LiDAR and Monocular Camera Fangchang Ma, Guilherme Venturelli Cavalheiro, Sertac Karaman Massachusetts Institute of Technology {fcma,guivenca,sertac}@mit.edu
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
MegaDepth: Learning Single-View Depth Prediction from Internet Photos
 MegaDepth: Learning Single-View Depth Prediction from Internet Photos Zhengqi Li Noah Snavely Department of Computer Science & Cornell Tech, Cornell University Abstract Single-view depth prediction is
MegaDepth: Learning Single-View Depth Prediction from Internet Photos Zhengqi Li Noah Snavely Department of Computer Science & Cornell Tech, Cornell University Abstract Single-view depth prediction is
arxiv: v1 [cs.cv] 31 Dec 2018
![arxiv: v1 [cs.cv] 31 Dec 2018](/thumbs/93/111119630.jpg "arxiv: v1 [cs.cv] 31 Dec 2018") arxiv:1812.11941v1 [cs.cv] 31 Dec 2018 High Quality Monocular Depth Estimation via Transfer Learning Ibraheem Alhashim KAUST Peter Wonka KAUST ibraheem.alhashim@kaust.edu.sa pwonka@gmail.com Abstract Accurate
arxiv:1812.11941v1 [cs.cv] 31 Dec 2018 High Quality Monocular Depth Estimation via Transfer Learning Ibraheem Alhashim KAUST Peter Wonka KAUST ibraheem.alhashim@kaust.edu.sa pwonka@gmail.com Abstract Accurate
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Depth Learning: When Depth Estimation Meets Deep Learning
 Depth Learning: When Depth Estimation Meets Deep Learning Prof. Liang LIN SenseTime Research & Sun Yat-sen University NITRE, June 18, 2018 Outline Part 1. Introduction Motivation Stereo Matching Single
Depth Learning: When Depth Estimation Meets Deep Learning Prof. Liang LIN SenseTime Research & Sun Yat-sen University NITRE, June 18, 2018 Outline Part 1. Introduction Motivation Stereo Matching Single
Single Image Depth Estimation via Deep Learning
 Single Image Depth Estimation via Deep Learning Wei Song Stanford University Stanford, CA Abstract The goal of the project is to apply direct supervised deep learning to the problem of monocular depth
Single Image Depth Estimation via Deep Learning Wei Song Stanford University Stanford, CA Abstract The goal of the project is to apply direct supervised deep learning to the problem of monocular depth
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Mix and match networks: encoder-decoder alignment for zero-pair image translation
 Mix and match networks: encoder-decoder alignment for zero-pair image translation Yaxing Wang, Joost van de Weijer, Luis Herranz Computer Vision Center, Universitat Autònoma de Barcelona Barcelona, Spain
Mix and match networks: encoder-decoder alignment for zero-pair image translation Yaxing Wang, Joost van de Weijer, Luis Herranz Computer Vision Center, Universitat Autònoma de Barcelona Barcelona, Spain
U-N.o.1T: A U-Net exploration, in Depth
 U-N.o.1T: A U-Net exploration, in Depth John Luke Chuter, Geoffrey Boris Boullanger, Manuel Nieves Saez {jchuter, gbakker, mnievess}@stanford.edu December 18, 2018 Abstract In this paper, we are exploring
U-N.o.1T: A U-Net exploration, in Depth John Luke Chuter, Geoffrey Boris Boullanger, Manuel Nieves Saez {jchuter, gbakker, mnievess}@stanford.edu December 18, 2018 Abstract In this paper, we are exploring
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features
 Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
Deeper Depth Prediction with Fully Convolutional Residual Networks
 Deeper Depth Prediction with Fully Convolutional Residual Networks Iro Laina 1 iro.laina@tum.de Christian Rupprecht 1,2 Vasileios Belagiannis 3 christian.rupprecht@in.tum.de vb@robots.ox.ac.uk Federico
Deeper Depth Prediction with Fully Convolutional Residual Networks Iro Laina 1 iro.laina@tum.de Christian Rupprecht 1,2 Vasileios Belagiannis 3 christian.rupprecht@in.tum.de vb@robots.ox.ac.uk Federico
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
arxiv: v2 [cs.cv] 14 May 2018
![arxiv: v2 [cs.cv] 14 May 2018](/thumbs/79/79495201.jpg "arxiv: v2 [cs.cv] 14 May 2018") ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
arxiv: v2 [cs.cv] 12 Sep 2018
![arxiv: v2 [cs.cv] 12 Sep 2018](/thumbs/87/95388513.jpg "arxiv: v2 [cs.cv] 12 Sep 2018") Monocular Depth Estimation by Learning from Heterogeneous Datasets Akhil Gurram 1,2, Onay Urfalioglu 2, Ibrahim Halfaoui 2, Fahd Bouzaraa 2 and Antonio M. López 1 arxiv:13.018v2 [cs.cv] 12 Sep 2018 Abstract
Monocular Depth Estimation by Learning from Heterogeneous Datasets Akhil Gurram 1,2, Onay Urfalioglu 2, Ibrahim Halfaoui 2, Fahd Bouzaraa 2 and Antonio M. López 1 arxiv:13.018v2 [cs.cv] 12 Sep 2018 Abstract
INTRODUCTION TO DEEP LEARNING
 INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
INTRODUCTION TO DEEP LEARNING CONTENTS Introduction to deep learning Contents 1. Examples 2. Machine learning 3. Neural networks 4. Deep learning 5. Convolutional neural networks 6. Conclusion 7. Additional
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015)
") AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
arxiv: v3 [cs.lg] 30 Dec 2016
![arxiv: v3 [cs.lg] 30 Dec 2016](/thumbs/74/70392473.jpg "arxiv: v3 [cs.lg] 30 Dec 2016") Video Ladder Networks Francesco Cricri Nokia Technologies francesco.cricri@nokia.com Xingyang Ni Tampere University of Technology xingyang.ni@tut.fi arxiv:1612.01756v3 [cs.lg] 30 Dec 2016 Mikko Honkala
Video Ladder Networks Francesco Cricri Nokia Technologies francesco.cricri@nokia.com Xingyang Ni Tampere University of Technology xingyang.ni@tut.fi arxiv:1612.01756v3 [cs.lg] 30 Dec 2016 Mikko Honkala
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Image Restoration with Deep Generative Models
 Image Restoration with Deep Generative Models Raymond A. Yeh *, Teck-Yian Lim *, Chen Chen, Alexander G. Schwing, Mark Hasegawa-Johnson, Minh N. Do Department of Electrical and Computer Engineering, University
Image Restoration with Deep Generative Models Raymond A. Yeh *, Teck-Yian Lim *, Chen Chen, Alexander G. Schwing, Mark Hasegawa-Johnson, Minh N. Do Department of Electrical and Computer Engineering, University
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
IMPROVING DOCUMENT BINARIZATION VIA ADVERSARIAL NOISE-TEXTURE AUGMENTATION
 IMPROVING DOCUMENT BINARIZATION VIA ADVERSARIAL NOISE-TEXTURE AUGMENTATION Ankan Kumar Bhunia 1, Ayan Kumar Bhunia 2, Aneeshan Sain 3, Partha Pratim Roy 4 1 Jadavpur University, India 2 Nanyang Technological
IMPROVING DOCUMENT BINARIZATION VIA ADVERSARIAL NOISE-TEXTURE AUGMENTATION Ankan Kumar Bhunia 1, Ayan Kumar Bhunia 2, Aneeshan Sain 3, Partha Pratim Roy 4 1 Jadavpur University, India 2 Nanyang Technological
Stereo Computation for a Single Mixture Image
 Stereo Computation for a Single Mixture Image Yiran Zhong 1,3,4, Yuchao Dai 2, and Hongdong Li 1,4 1 Australian National University 2 Northwestern Polytechnical University 3 Data61 CSIRO 4 Australian Centre
Stereo Computation for a Single Mixture Image Yiran Zhong 1,3,4, Yuchao Dai 2, and Hongdong Li 1,4 1 Australian National University 2 Northwestern Polytechnical University 3 Data61 CSIRO 4 Australian Centre
Convolutional-Recursive Deep Learning for 3D Object Classification
 Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Convolutional-Recursive Deep Learning for 3D Object Classification Richard Socher, Brody Huval, Bharath Bhat, Christopher D. Manning, Andrew Y. Ng NIPS 2012 Iro Armeni, Manik Dhar Motivation Hand-designed
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Supplementary Material
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Supplementary Material Xintao Wang 1 Ke Yu 1 Chao Dong 2 Chen Change Loy 1 1 CUHK - SenseTime Joint Lab, The Chinese
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Supplementary Material Xintao Wang 1 Ke Yu 1 Chao Dong 2 Chen Change Loy 1 1 CUHK - SenseTime Joint Lab, The Chinese
Toward Scale-Invariance and Position-Sensitive Region Proposal Networks
 Toward Scale-Invariance and Position-Sensitive Region Proposal Networks Hsueh-Fu Lu [0000 0003 1885 3805], Xiaofei Du [0000 0002 0071 8093], and Ping-Lin Chang [0000 0002 3341 8425] Umbo Computer Vision
Toward Scale-Invariance and Position-Sensitive Region Proposal Networks Hsueh-Fu Lu [0000 0003 1885 3805], Xiaofei Du [0000 0002 0071 8093], and Ping-Lin Chang [0000 0002 3341 8425] Umbo Computer Vision
UNSUPERVISED STEREO MATCHING USING CORRESPONDENCE CONSISTENCY. Sunghun Joung Seungryong Kim Bumsub Ham Kwanghoon Sohn
 UNSUPERVISED STEREO MATCHING USING CORRESPONDENCE CONSISTENCY Sunghun Joung Seungryong Kim Bumsub Ham Kwanghoon Sohn School of Electrical and Electronic Engineering, Yonsei University, Seoul, Korea E-mail:
UNSUPERVISED STEREO MATCHING USING CORRESPONDENCE CONSISTENCY Sunghun Joung Seungryong Kim Bumsub Ham Kwanghoon Sohn School of Electrical and Electronic Engineering, Yonsei University, Seoul, Korea E-mail:
arxiv: v1 [cs.cv] 22 Jan 2019
![arxiv: v1 [cs.cv] 22 Jan 2019](/thumbs/88/116253383.jpg "arxiv: v1 [cs.cv] 22 Jan 2019") Unsupervised Learning-based Depth Estimation aided Visual SLAM Approach Mingyang Geng 1, Suning Shang 1, Bo Ding 1, Huaimin Wang 1, Pengfei Zhang 1, and Lei Zhang 2 National Key Laboratory of Parallel
Unsupervised Learning-based Depth Estimation aided Visual SLAM Approach Mingyang Geng 1, Suning Shang 1, Bo Ding 1, Huaimin Wang 1, Pengfei Zhang 1, and Lei Zhang 2 National Key Laboratory of Parallel
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis Supplementary
 EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis Supplementary Mehdi S. M. Sajjadi Bernhard Schölkopf Michael Hirsch Max Planck Institute for Intelligent Systems Spemanstr.
EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis Supplementary Mehdi S. M. Sajjadi Bernhard Schölkopf Michael Hirsch Max Planck Institute for Intelligent Systems Spemanstr.
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
DeepPose & Convolutional Pose Machines
 DeepPose & Convolutional Pose Machines Main Concepts 1. 2. 3. 4. CNN with regressor head. Object Localization. Bigger to smaller or Smaller to bigger view. Deep Supervised learning to prevent Vanishing
DeepPose & Convolutional Pose Machines Main Concepts 1. 2. 3. 4. CNN with regressor head. Object Localization. Bigger to smaller or Smaller to bigger view. Deep Supervised learning to prevent Vanishing
Introduction to Neural Networks
 Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
RTSR: Enhancing Real-time H.264 Video Streaming using Deep Learning based Video Super Resolution Spring 2017 CS570 Project Presentation June 8, 2017
 RTSR: Enhancing Real-time H.264 Video Streaming using Deep Learning based Video Super Resolution Spring 2017 CS570 Project Presentation June 8, 2017 Team 16 Soomin Kim Leslie Tiong Youngki Kwon Insu Jang
RTSR: Enhancing Real-time H.264 Video Streaming using Deep Learning based Video Super Resolution Spring 2017 CS570 Project Presentation June 8, 2017 Team 16 Soomin Kim Leslie Tiong Youngki Kwon Insu Jang
Supplementary Material for Learning 3D Shape Completion from Laser Scan Data with Weak Supervision
 Supplementary Material for Learning 3D Shape Completion from Laser Scan Data with Weak Supervision David Stutz 1,2 Andreas Geiger 1,3 1 Autonomous Vision Group, MPI for Intelligent Systems and University
Supplementary Material for Learning 3D Shape Completion from Laser Scan Data with Weak Supervision David Stutz 1,2 Andreas Geiger 1,3 1 Autonomous Vision Group, MPI for Intelligent Systems and University
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization
 Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
Hide-and-Seek: Forcing a network to be Meticulous for Weakly-supervised Object and Action Localization Krishna Kumar Singh and Yong Jae Lee University of California, Davis ---- Paper Presentation Yixian
arxiv: v2 [cs.cv] 6 Jan 2017
![arxiv: v2 [cs.cv] 6 Jan 2017](/thumbs/72/67202418.jpg "arxiv: v2 [cs.cv] 6 Jan 2017") Single-Image Depth Perception in the Wild Weifeng Chen Zhao Fu Dawei Yang Jia Deng University of Michigan, Ann Arbor {wfchen,zhaofu,ydawei,jiadeng}@umich.edu arxiv:1604.03901v2 [cs.cv] 6 Jan 2017 Abstract
Single-Image Depth Perception in the Wild Weifeng Chen Zhao Fu Dawei Yang Jia Deng University of Michigan, Ann Arbor {wfchen,zhaofu,ydawei,jiadeng}@umich.edu arxiv:1604.03901v2 [cs.cv] 6 Jan 2017 Abstract
Unsupervised Deep Learning. James Hays slides from Carl Doersch and Richard Zhang
 Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Unsupervised Deep Learning James Hays slides from Carl Doersch and Richard Zhang Recap from Previous Lecture We saw two strategies to get structured output while using deep learning With object detection,
Auto-encoder with Adversarially Regularized Latent Variables
 Information Engineering Express International Institute of Applied Informatics 2017, Vol.3, No.3, P.11 20 Auto-encoder with Adversarially Regularized Latent Variables for Semi-Supervised Learning Ryosuke
Information Engineering Express International Institute of Applied Informatics 2017, Vol.3, No.3, P.11 20 Auto-encoder with Adversarially Regularized Latent Variables for Semi-Supervised Learning Ryosuke
Depth Estimation from a Single Image Using a Deep Neural Network Milestone Report
 Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D.
 PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
THERMAL TEXTURE GENERATION AND 3D MODEL RECONSTRUCTION USING SFM AND GAN
 THERMAL TEXTURE GENERATION AND 3D MODEL RECONSTRUCTION USING SFM AND GAN V. V. Kniaz a,b, V. A. Mizginov a a State Res. Institute of Aviation Systems (GosNIIAS), 125319, 7, Victorenko str., Moscow, Russia
THERMAL TEXTURE GENERATION AND 3D MODEL RECONSTRUCTION USING SFM AND GAN V. V. Kniaz a,b, V. A. Mizginov a a State Res. Institute of Aviation Systems (GosNIIAS), 125319, 7, Victorenko str., Moscow, Russia
Monocular Depth Estimation Using Whole Strip Masking and Reliability-Based Refinement
 Monocular Depth Estimation Using Whole Strip Masking and Reliability-Based Refinement Minhyeok Heo 1, Jaehan Lee 2, Kyung-Rae Kim 2, Han-Ul Kim 2, and Chang-Su Kim 2 1 NAVER LABS heo.minhyeok@naverlabs.com
Monocular Depth Estimation Using Whole Strip Masking and Reliability-Based Refinement Minhyeok Heo 1, Jaehan Lee 2, Kyung-Rae Kim 2, Han-Ul Kim 2, and Chang-Su Kim 2 1 NAVER LABS heo.minhyeok@naverlabs.com
Face Recognition A Deep Learning Approach
 Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison
Face Recognition A Deep Learning Approach Lihi Shiloh Tal Perl Deep Learning Seminar 2 Outline What about Cat recognition? Classical face recognition Modern face recognition DeepFace FaceNet Comparison