William Stallings Computer Organization and Architecture 8 th Edition. Chapter 14 Instruction Level Parallelism and Superscalar Processors
|
|
|
- Anthony Cain
- 5 years ago
- Views:
Transcription
1 William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors
2 What is Superscalar? Common instructions (arithmetic, load/store, conditional branch) can be initiated and executed independently Equally applicable to RISC & CISC In practice usually RISC
3 Why Superscalar? Most operations are on scalar quantities (see RISC notes) Improve these operations to get an overall improvement

4 General Superscalar Organization
5 Superpipelined Many pipeline stages need less than half a clock cycle Double internal clock speed gets two tasks per external clock cycle Superscalar allows parallel fetch execute

6 Superscalar v Superpipeline
7 Limitations Instruction level parallelism Compiler based optimisation Hardware techniques Limited by True data dependency Procedural dependency Resource conflicts Output dependency Antidependency
8 True Data Dependency ADD r1, r2 (r1 := r1+r2;) MOVE r3,r1 (r3 := r1;) Can fetch and decode second instruction in parallel with first Can NOT execute second instruction until first is finished
9 Procedural Dependency Can not execute instructions after a branch in parallel with instructions before a branch Also, if instruction length is not fixed, instructions have to be decoded to find out how many fetches are needed This prevents simultaneous fetches
10 Resource Conflict Two or more instructions requiring access to the same resource at the same time e.g. two arithmetic instructions Can duplicate resources e.g. have two arithmetic units
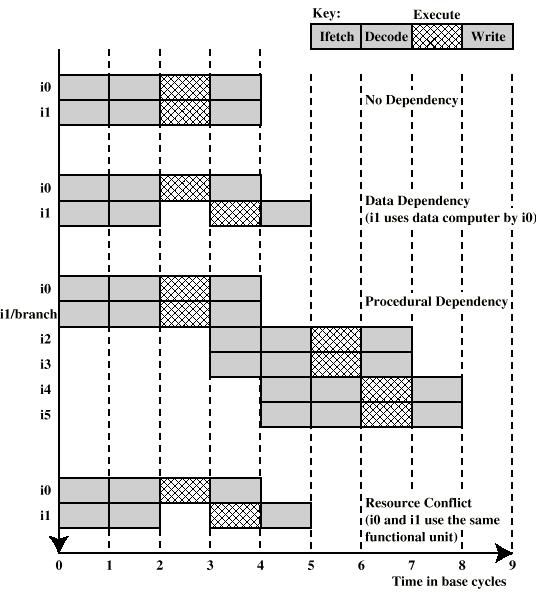
11 Effect of Dependencies
12 Design Issues Instruction level parallelism Instructions in a sequence are independent Execution can be overlapped Governed by data and procedural dependency Machine Parallelism Ability to take advantage of instruction level parallelism Governed by number of parallel pipelines
13 Instruction Issue Policy Order in which instructions are fetched Order in which instructions are executed Order in which instructions change registers and memory
14 In-Order Issue In-Order Completion Issue instructions in the order they occur Not very efficient May fetch >1 instruction Instructions must stall if necessary

15 In-Order Issue In-Order Completion (Diagram)
16 In-Order Issue Out-of-Order Completion Output dependency R3:= R3 + R5; (I1) R4:= R3 + 1; (I2) R3:= R5 + 1; (I3) I2 depends on result of I1 - data dependency If I3 completes before I1, the result from I1 will be wrong - output (read-write) dependency

17 In-Order Issue Out-of-Order Completion (Diagram)
18 Out-of-Order Issue Out-of-Order Completion Decouple decode pipeline from execution pipeline Can continue to fetch and decode until this pipeline is full When a functional unit becomes available an instruction can be executed Since instructions have been decoded, processor can look ahead

19 Out-of-Order Issue Out-of-Order Completion (Diagram)
20 Antidependency Write-write dependency R3:=R3 + R5; (I1) R4:=R3 + 1; R3:=R5 + 1; (I2) (I3) R7:=R3 + R4; (I4) I3 can not complete before I2 starts as I2 needs a value in R3 and I3 changes R3
21 Reorder Buffer Temporary storage for results Commit to register file in program order
22 Register Renaming Output and antidependencies occur because register contents may not reflect the correct ordering from the program May result in a pipeline stall Registers allocated dynamically i.e. registers are not specifically named
23 Register Renaming example R3b:=R3a + R5a R4b:=R3b + 1 R3c:=R5a + 1 R7b:=R3c + R4b (I1) (I2) (I3) (I4) Without subscript refers to logical register in instruction With subscript is hardware register allocated Note R3a R3b R3c Alternative: Scoreboarding Bookkeeping technique Allow instruction execution whenever not dependent on previous instructions and no structural hazards
24 Machine Parallelism Duplication of Resources Out of order issue Renaming Not worth duplication functions without register renaming Need instruction window large enough (more than 8)

25 Speedups of Machine Organizations Without Procedural Dependencies
26 Branch Prediction fetches both next sequential instruction after branch and branch target instruction Gives two cycle delay if branch taken
27 RISC - Delayed Branch Calculate result of branch before unusable instructions pre-fetched Always execute single instruction immediately following branch Keeps pipeline full while fetching new instruction stream Not as good for superscalar Multiple instructions need to execute in delay slot Instruction dependence problems Revert to branch prediction
28 Superscalar Execution
29 Superscalar Implementation Simultaneously fetch multiple instructions Logic to determine true dependencies involving register values Mechanisms to communicate these values Mechanisms to initiate multiple instructions in parallel Resources for parallel execution of multiple instructions Mechanisms for committing process state in correct order
30 Pentium CISC Pentium some superscalar components Two separate integer execution units Pentium Pro Full blown superscalar Subsequent models refine & enhance superscalar design

31 Pentium 4 Block Diagram
32 Pentium 4 Operation Fetch instructions form memory in order of static program Translate instruction into one or more fixed length RISC instructions (micro-operations) Execute micro-ops on superscalar pipeline micro-ops may be executed out of order Commit results of micro-ops to register set in original program flow order Outer CISC shell with inner RISC core Inner RISC core pipeline at least 20 stages Some micro-ops require multiple execution stages Longer pipeline c.f. five stage pipeline on x86 up to Pentium

33 Pentium 4 Pipeline

34 Pentium 4 Pipeline Operation (1)

35 Pentium 4 Pipeline Operation (2)

36 Pentium 4 Pipeline Operation (3)

37 Pentium 4 Pipeline Operation (4)
38 Pentium 4 Pipeline Operation (5)

39 Pentium 4 Pipeline Operation (6)
40 ARM CORTEX-A8 ARM refers to Cortex-A8 as application processors Embedded processor running complex operating system Wireless, consumer and imaging applications Mobile phones, set-top boxes, gaming consoles automotive navigation/entertainment systems Three functional units Dual, in-order-issue, 13-stage pipeline Keep power required to a minimum Out-of-order issue needs extra logic consuming extra power Figure shows the details of the main Cortex-A8 pipeline Separate SIMD (single-instruction-multiple-data) unit 10-stage pipeline

41 ARM Cortex-A8 Block Diagram
42 Instruction Fetch Unit Predicts instruction stream Fetches instructions from the L1 instruction cache Up to four instructions per cycle Into buffer for decode pipeline Fetch unit includes L1 instruction cache Speculative instruction fetches Branch or exceptional instruction cause pipeline flush Stages: F0 address generation unit generates virtual address Normally next sequentially Can also be branch target address F1 Used to fetch instructions from L1 instruction cache In parallel fetch address used to access branch prediction arrays F3 Instruction data are placed in instruction queue If branch prediction, new target address sent to address generation unit Two-level global history branch predictor Branch Target Buffer (BTB) and Global History Buffer (GHB) Return stack to predict subroutine return addresses Can fetch and queue up to 12 instructions Issues instructions two at a time
43 Instruction Decode Unit Decodes and sequences all instructions Dual pipeline structure, pipe0 and pipe1 Two instructions can progress at a time Pipe0 contains older instruction in program order If instruction in pipe0 cannot issue, pipe1 will not issue Instructions progress in order Results written back to register file at end of execution pipeline Prevents WAR hazards Keeps tracking of WAW hazards and recovery from flush conditions straightforward Main concern of decode pipeline is prevention of RAW hazards
44 Instruction Processing Stages D0 Thumb instructions decompressed and preliminary decode is performed D1 Instruction decode is completed D2 Write instruction to and read instructions from pending/replay queue D3 Contains the instruction scheduling logic Scoreboard predicts register availability using static scheduling Hazard checking D4 Final decode for control signals for integer execute load/store units
45 Integer Execution Unit Two symmetric (ALU) pipelines, an address generator for load and store instructions, and multiply pipeline Pipeline stages: E0 Access register file Up to six registers for two instructions E1 Barrel shifter if needed. E2 ALU function E3 If needed, completes saturation arithmetic E4 Change in control flow prioritized and processed E5 Results written back to register file Multiply unit instructions routed to pipe0 Performed in stages E1 through E3 Multiply accumulate operation in E4
46 Load/store pipeline Parallel to integer pipeline E1 Memory address generated from base and index register E2 address applied to cache arrays E3 load, data returned and formatted E3 store, data are formatted and ready to be written to cache E4 Updates L2 cache, if required E5 Results are written to register file

47 ARM Cortex-A8 Integer Pipeline
48 SIMD and Floating-Point Pipeline SIMD and floating-point instructions pass through integer pipeline Processed in separate 10-stage pipeline NEON unit Handles packed SIMD instructions Provides two types of floating-point support If implemented, vector floating-point (VFP) coprocessor performs IEEE 754 floating-point operations If not, separate multiply and add pipelines implement floating-point operations

49 ARM Cortex-A8 NEON & Floating Point Pipeline
50 Required Reading Stallings chapter 14 Manufacturers web sites IMPACT web site research on predicated execution
TECH. CH14 Instruction Level Parallelism and Superscalar Processors. What is Superscalar? Why Superscalar? General Superscalar Organization
 CH14 Instruction Level Parallelism and Superscalar Processors Decode and issue more and one instruction at a time Executing more than one instruction at a time More than one Execution Unit What is Superscalar?
CH14 Instruction Level Parallelism and Superscalar Processors Decode and issue more and one instruction at a time Executing more than one instruction at a time More than one Execution Unit What is Superscalar?
Organisasi Sistem Komputer
 LOGO Organisasi Sistem Komputer OSK 11 Superscalar Pendidikan Teknik Elektronika FT UNY What is Superscalar? Common instructions (arithmetic, load/store, conditional branch) can be initiated and executed
LOGO Organisasi Sistem Komputer OSK 11 Superscalar Pendidikan Teknik Elektronika FT UNY What is Superscalar? Common instructions (arithmetic, load/store, conditional branch) can be initiated and executed
Lecture 9: Superscalar processing
 Lecture 9 Superscalar processors Superscalar- processing Stallings: Ch 14 Instruction dependences Register renaming Pentium / PowerPC Goal Concurrent execution of scalar instructions Several independent
Lecture 9 Superscalar processors Superscalar- processing Stallings: Ch 14 Instruction dependences Register renaming Pentium / PowerPC Goal Concurrent execution of scalar instructions Several independent
A superscalar machine is one in which multiple instruction streams allow completion of more than one instruction per cycle.
 CS 320 Ch. 16 SuperScalar Machines A superscalar machine is one in which multiple instruction streams allow completion of more than one instruction per cycle. A superpipelined machine is one in which a
CS 320 Ch. 16 SuperScalar Machines A superscalar machine is one in which multiple instruction streams allow completion of more than one instruction per cycle. A superpipelined machine is one in which a
What is Superscalar? CSCI 4717 Computer Architecture. Why the drive toward Superscalar? What is Superscalar? (continued) In class exercise
 In class exercise") CSCI 4717/5717 Computer Architecture Topic: Instruction Level Parallelism Reading: Stallings, Chapter 14 What is Superscalar? A machine designed to improve the performance of the execution of scalar instructions.
CSCI 4717/5717 Computer Architecture Topic: Instruction Level Parallelism Reading: Stallings, Chapter 14 What is Superscalar? A machine designed to improve the performance of the execution of scalar instructions.
RISC & Superscalar. COMP 212 Computer Organization & Architecture. COMP 212 Fall Lecture 12. Instruction Pipeline no hazard.
 COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
Superscalar Processors Ch 13. Superscalar Processing (5) Computer Organization II 10/10/2001. New dependency for superscalar case? (8) Name dependency
 Computer Organization II 10/10/2001. New dependency for superscalar case? (8) Name dependency") Superscalar Processors Ch 13 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction 1 New dependency for superscalar case? (8) Name dependency (nimiriippuvuus) two use the same
Superscalar Processors Ch 13 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction 1 New dependency for superscalar case? (8) Name dependency (nimiriippuvuus) two use the same
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors
 Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Superscalar Machines. Characteristics of superscalar processors
 Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Superscalar Machines Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any performance
Superscalar Processors
 Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
Superscalar Processors Increasing pipeline length eventually leads to diminishing returns longer pipelines take longer to re-fill data and control hazards lead to increased overheads, removing any a performance
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
Lecture 19: Instruction Level Parallelism
 Lecture 19: Instruction Level Parallelism Administrative: Homework #5 due Homework #6 handed out today Last Time: DRAM organization and implementation Today Static and Dynamic ILP Instruction windows Register
Lecture 19: Instruction Level Parallelism Administrative: Homework #5 due Homework #6 handed out today Last Time: DRAM organization and implementation Today Static and Dynamic ILP Instruction windows Register
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Lecture 8: Branch Prediction, Dynamic ILP. Topics: static speculation and branch prediction (Sections )
") Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Computer Systems Architecture I. CSE 560M Lecture 10 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
Computer Systems Architecture I CSE 560M Lecture 10 Prof. Patrick Crowley Plan for Today Questions Dynamic Execution III discussion Multiple Issue Static multiple issue (+ examples) Dynamic multiple issue
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 12 Processor Structure and Function
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data
William Stallings Computer Organization and Architecture 8 th Edition Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
SUPERSCALAR AND VLIW PROCESSORS
 Datorarkitektur I Fö 10-1 Datorarkitektur I Fö 10-2 What is a Superscalar Architecture? SUPERSCALAR AND VLIW PROCESSORS A superscalar architecture is one in which several instructions can be initiated
Datorarkitektur I Fö 10-1 Datorarkitektur I Fö 10-2 What is a Superscalar Architecture? SUPERSCALAR AND VLIW PROCESSORS A superscalar architecture is one in which several instructions can be initiated
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Ti Parallel Computing PIPELINING. Michał Roziecki, Tomáš Cipr
 Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
ASSEMBLY LANGUAGE MACHINE ORGANIZATION
 ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Lecture: Out-of-order Processors. Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ
 Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Chapter 9. Pipelining Design Techniques
 Chapter 9 Pipelining Design Techniques 9.1 General Concepts Pipelining refers to the technique in which a given task is divided into a number of subtasks that need to be performed in sequence. Each subtask
Chapter 9 Pipelining Design Techniques 9.1 General Concepts Pipelining refers to the technique in which a given task is divided into a number of subtasks that need to be performed in sequence. Each subtask
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
UNIT- 5. Chapter 12 Processor Structure and Function
 UNIT- 5 Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data Write data CPU With Systems Bus CPU Internal Structure Registers
UNIT- 5 Chapter 12 Processor Structure and Function CPU Structure CPU must: Fetch instructions Interpret instructions Fetch data Process data Write data CPU With Systems Bus CPU Internal Structure Registers
CS311 Lecture: Pipelining, Superscalar, and VLIW Architectures revised 10/18/07
 CS311 Lecture: Pipelining, Superscalar, and VLIW Architectures revised 10/18/07 Objectives ---------- 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as
CS311 Lecture: Pipelining, Superscalar, and VLIW Architectures revised 10/18/07 Objectives ---------- 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Like scalar processor Processes individual data items Item may be single integer or floating point number. - 1 of 15 - Superscalar Architectures
 Superscalar Architectures Have looked at examined basic architecture concepts Starting with simple machines Introduced concepts underlying RISC machines From characteristics of RISC instructions Found
Superscalar Architectures Have looked at examined basic architecture concepts Starting with simple machines Introduced concepts underlying RISC machines From characteristics of RISC instructions Found
Lecture 8: Instruction Fetch, ILP Limits. Today: advanced branch prediction, limits of ILP (Sections , )
") Lecture 8: Instruction Fetch, ILP Limits Today: advanced branch prediction, limits of ILP (Sections 3.4-3.5, 3.8-3.14) 1 1-Bit Prediction For each branch, keep track of what happened last time and use
Lecture 8: Instruction Fetch, ILP Limits Today: advanced branch prediction, limits of ILP (Sections 3.4-3.5, 3.8-3.14) 1 1-Bit Prediction For each branch, keep track of what happened last time and use
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
Chapter 06: Instruction Pipelining and Parallel Processing. Lesson 14: Example of the Pipelined CISC and RISC Processors
 Chapter 06: Instruction Pipelining and Parallel Processing Lesson 14: Example of the Pipelined CISC and RISC Processors 1 Objective To understand pipelines and parallel pipelines in CISC and RISC Processors
Chapter 06: Instruction Pipelining and Parallel Processing Lesson 14: Example of the Pipelined CISC and RISC Processors 1 Objective To understand pipelines and parallel pipelines in CISC and RISC Processors
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
") Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections 3.8-3.14) 1 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
Lecture 9: Multiple Issue (Superscalar and VLIW)
") Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Lecture 9: Multiple Issue (Superscalar and VLIW) Iakovos Mavroidis Computer Science Department University of Crete Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU
 1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CS 152 Computer Architecture and Engineering. Lecture 12 - Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
In embedded systems there is a trade off between performance and power consumption. Using ILP saves power and leads to DECREASING clock frequency.
 Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
CS146 Computer Architecture. Fall Midterm Exam
 CS146 Computer Architecture Fall 2002 Midterm Exam This exam is worth a total of 100 points. Note the point breakdown below and budget your time wisely. To maximize partial credit, show your work and state
CS146 Computer Architecture Fall 2002 Midterm Exam This exam is worth a total of 100 points. Note the point breakdown below and budget your time wisely. To maximize partial credit, show your work and state
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Architectural Performance. Superscalar Processing. 740 October 31, i486 Pipeline. Pipeline Stage Details. Page 1
 Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5
 EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
Lecture: Out-of-order Processors
 Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Pipelined Processor Design. EE/ECE 4305: Computer Architecture University of Minnesota Duluth By Dr. Taek M. Kwon
 Pipelined Processor Design EE/ECE 4305: Computer Architecture University of Minnesota Duluth By Dr. Taek M. Kwon Concept Identification of Pipeline Segments Add Pipeline Registers Pipeline Stage Control
Pipelined Processor Design EE/ECE 4305: Computer Architecture University of Minnesota Duluth By Dr. Taek M. Kwon Concept Identification of Pipeline Segments Add Pipeline Registers Pipeline Stage Control
6.823 Computer System Architecture
 6.823 Computer System Architecture Problem Set #4 Spring 2002 Students are encouraged to collaborate in groups of up to 3 people. A group needs to hand in only one copy of the solution to a problem set.
6.823 Computer System Architecture Problem Set #4 Spring 2002 Students are encouraged to collaborate in groups of up to 3 people. A group needs to hand in only one copy of the solution to a problem set.
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Complex Pipelining COE 501. Computer Architecture Prof. Muhamed Mudawar
 Complex Pipelining COE 501 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Diversified Pipeline Detecting
Complex Pipelining COE 501 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Diversified Pipeline Detecting
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Processing Unit CS206T
 Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
CS311 Lecture: Pipelining and Superscalar Architectures
 Objectives: CS311 Lecture: Pipelining and Superscalar Architectures Last revised July 10, 2013 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as a result
Objectives: CS311 Lecture: Pipelining and Superscalar Architectures Last revised July 10, 2013 1. To introduce the basic concept of CPU speedup 2. To explain how data and branch hazards arise as a result
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Branch Prediction & Speculative Execution. Branch Penalties in Modern Pipelines
 6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Lecture 5: Instruction Pipelining. Pipeline hazards. Sequential execution of an N-stage task: N Task 2
 Lecture 5: Instruction Pipelining Basic concepts Pipeline hazards Branch handling and prediction Zebo Peng, IDA, LiTH Sequential execution of an N-stage task: 3 N Task 3 N Task Production time: N time
Lecture 5: Instruction Pipelining Basic concepts Pipeline hazards Branch handling and prediction Zebo Peng, IDA, LiTH Sequential execution of an N-stage task: 3 N Task 3 N Task Production time: N time
CS 152, Spring 2011 Section 8
 CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS433 Homework 2 (Chapter 3)
") CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
COSC 243. Computer Architecture 2. Lecture 12 Computer Architecture 2. COSC 243 (Computer Architecture)
") COSC 243 1 Overview This Lecture Architectural topics CISC RISC Multi-core processors Source: Chapter 15,16 and 17(10 th edition) 2 Moore s Law Gordon E. Moore Co-founder of Intel April 1965 The complexity
COSC 243 1 Overview This Lecture Architectural topics CISC RISC Multi-core processors Source: Chapter 15,16 and 17(10 th edition) 2 Moore s Law Gordon E. Moore Co-founder of Intel April 1965 The complexity
Lecture 18: Instruction Level Parallelism -- Dynamic Superscalar, Advanced Techniques,
 Lecture 18: Instruction Level Parallelism -- Dynamic Superscalar, Advanced Techniques, ARM Cortex-A53, and Intel Core i7 CSCE 513 Computer Architecture Department of Computer Science and Engineering Yonghong
Lecture 18: Instruction Level Parallelism -- Dynamic Superscalar, Advanced Techniques, ARM Cortex-A53, and Intel Core i7 CSCE 513 Computer Architecture Department of Computer Science and Engineering Yonghong
Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1
![Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1](/thumbs/92/108067849.jpg "Load1 no Load2 no Add1 Y Sub Reg[F2] Reg[F6] Add2 Y Add Reg[F2] Add1 Add3 no Mult1 Y Mul Reg[F2] Reg[F4] Mult2 Y Div Reg[F6] Mult1") Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
Instruction Issue Execute Write result L.D F6, 34(R2) L.D F2, 45(R3) MUL.D F0, F2, F4 SUB.D F8, F2, F6 DIV.D F10, F0, F6 ADD.D F6, F8, F2 Name Busy Op Vj Vk Qj Qk A Load1 no Load2 no Add1 Y Sub Reg[F2]
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25
 CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
Adapted from David Patterson s slides on graduate computer architecture
 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Basic Compiler Techniques for Exposing ILP Advanced Branch Prediction Dynamic Scheduling Hardware-Based Speculation
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Control Hazards. Branch Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional