Feature LDA: a Supervised Topic Model for Automatic Detection of Web API Documentations from the Web
|
|
|
- Luke Horton
- 5 years ago
- Views:
Transcription


1 Feature LDA: a Supervised Topic Model for Automatic Detection of Web API Documentations from the Web Chenghua Lin, Yulan He, Carlos Pedrinaci, and John Domingue Knowledge Media Institute, The Open University Milton Keynes, United Kingdom 11 th International Semantic Web Conference. Boston, USA, 2012
2 Outline Introduction The Feature LDA model Data Experimental Results Conclusion
3 Introduction What are Web APIs? New Web Services based on a simple stack of technologies, URL+HTTP+XML/JSON Known as RESTful service when conforming the REST principles Why Web APIs? Light technology stack VS. classical Web services (WSDL, SOAP, WS-*) Enable easy access and aggregation of collection of resources Widely used and reused
4 Finding a Web API Dedicated registries, e.g. ProgrammableWeb Contain out of date or incorrect information, e.g. invalid pages or incorrect links to APIs documentation pages Only a limited number of Web APIs listed, left out a large number of third party Web APIs General search engine, e.g. Google Not optimized for Web API discovery Mix up with pages that are not (so) relevant, e.g. blogs and advertisement about Web APIs.



5 Motivating Example Suppose we use Google to search sentiment analysis APIs
6 Our Goal Goal: To build a customized search engine for detecting third party Web APIs on the Web scale Assume every Web API provides public documentation page(s) These pages provide the most relevant information for developers Approached as a binary classification problem, i.e. distinguishing API documentation VS. normal pages
7 Easy Task? Issues No simple way to effectively and uniquely identify Web APIs described in plain and unstructured HTML highly heterogeneous in format and contents, i.e. NO Gold standard People hardly follow even there is!!! More than 99% of pages on the Web are NOT relevant to Web API Need a high precision classifier yet maintaining good accuracy
8 Our Approach The Feature LDA model
9 Latent Dirichlet Allocation (LDA) LDA: the simplest form of topic models gene A fully unsupervised Bayesian model dna Assumes that documents exhibit multiple topics cell (also known as theme or gist ) sequence genetics Each topic is a distribution over words which have mapping tight semantic relation with one another human molecular
10 Graphical Model Dirichlet parameter Topic assignment Dirichlet parameter Per-document Topic proportions Observed word Topic distributions Intuition: Each document exhibit multiple topics Each topic is a distribution over words Each word is drawn from one of those topics

11 ????? A Colorful Example Generating a document with a LDA model Generate a document with a bulk of words What we know: the model parameters and distributions, i.e. (α, β, Θ, Φ) What we don t know: the WORDS of each document, which needs to be generated Per-word topic assignment Per-doc topic proportion Topics: gene 0.04 dna 0.02 cell 0.01 life 0.02 evolve 0.01 organism 0.01 brain 0.04 neuron 0.02 nerve 0.01 d a t a number 0.04 computer 0.04

12 In a real-world setting Inverse the entire process, to estimate the LDA model parameters given observation, i.e. a collection of documents What we know: the WORDS of each document, which we can observe What we don t know: the model parameters and distributions, i.e. (α, β, Θ, Φ) Topics:????

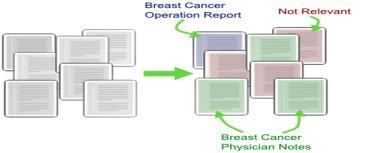


13 Applications Classification LDA Posterior inference Information retrieval Data Recommendation Data exploration
14 Feature LDA Feature LDA model: a generic probabilistic framework for text classification. A supervised four-layer hierarchical Bayesian model Accommodate supervisions from both labelled instance and labelled features for training Able to extract meaningful class specific topics Labelled features In baseball vs. hockey text classification pitcher baseball, puck hockey learned automatically from training data using any feature selection method, e.g. Info Gain
15 Dirichlet parameter Per-doc class label specific topic proportions Feature LDA Graphical Model Topic assignment Observed word Labelled features Dirichlet parameter Document class labels Per-doc class proportions Class label assignment Class label specific topic distributions
16 Generative Process For each document d Draw π d ~Dir(γ ε d ) For each class label k, draw θ d,k ~Dir(α k ) For each word w in d Draw a class label l i ~ Mult(π d ) Draw a topic z i ~ Mult(Θ d,li ) Draw a word w i ~ Mult(Φ li,zi )
17 Inference Collapse Gibbs sampling for model posterior estimation Approximating model parameters
18 Data and Setup The API dataset: 1,547 Web pages crawled from the API Home URLs of ProgrammableWeb (manually labelled, training/testing split: 80%-20%) 622 pages are API documentations 925 pages are normal Web pages Preprocessing Extract content from HTMLs by discarding tags and java scripts that are not relevant to classification remove wildcards, non-alphanumeric characters and stop-words, followed by Porter stemming. Setup Class label k = 2 Topic number T=1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20 29,000 labelled features (Info Gain)
19 Experimental Results We report fealda classification results on the API dataset with different model settings: Training with labelled instances Training with both labelled instances and labelled features fealda performance feature selection on labeled features fealda vs. baselines (NB, SVM, MaxEnt) and other supervised topic models (labellda, plda) Topic extraction
20 Training with labelled Instances fealda = 80.5% T = 2 MaxEnt = 79.3%
21 Labelled instances + labelled features fealda = 81.8% T = 3 MaxEnt = 79.3%
22 Feature Selection fealda = 82.7% 3.4% > MaxEnt fealda classification accuracy vs. different feature class probability threshold τ.

23 Overall comparison fealda vs. the state-of-the-art models outperforms three strong supervised baselines better than labeledlda and plda for more than 3% in accuracy gives very high precision: essential for reducing false positives when mining from the Web

24 Topic Extraction Topics with true API label Terms are fairly technical, e.g. json, statu, paramet, element, valu, request and string, etc. Topics with false API label Terms are less technical and more diverse, e.g. contact, support, custom, flight, school
25 Conclusions Discovering Web APIs is becoming increasingly important and existing support is not optimal Treat Web API discovery as a classification problem Presented a supervised topic model called fealda offers a generic framework for text classification Capable to encode supervision from both labelled instance and labelled features Offers very high precision which is crucial for reducing false positive when mining from the Web Able to extract class label specific topics
26 Questions? 26
Feature LDA: A Supervised Topic Model for Automatic Detection of Web API Documentations from the Web
 Feature LDA: A Supervised Topic Model for Automatic Detection of Web API Documentations from the Web Chenghua Lin, Yulan He, Carlos Pedrinaci, and John Domingue Knowledge Media Institute, The Open University
Feature LDA: A Supervised Topic Model for Automatic Detection of Web API Documentations from the Web Chenghua Lin, Yulan He, Carlos Pedrinaci, and John Domingue Knowledge Media Institute, The Open University
A Measurement Design for the Comparison of Expert Usability Evaluation and Mobile App User Reviews
 A Measurement Design for the Comparison of Expert Usability Evaluation and Mobile App User Reviews Necmiye Genc-Nayebi and Alain Abran Department of Software Engineering and Information Technology, Ecole
A Measurement Design for the Comparison of Expert Usability Evaluation and Mobile App User Reviews Necmiye Genc-Nayebi and Alain Abran Department of Software Engineering and Information Technology, Ecole
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Harnessing the Crowds for Automating the Identification of Web APIs
 AAAI Technical Report SS-12-04 Intelligent Web Services Meet Social Computing Harnessing the Crowds for Automating the Identification of Web APIs Carlos Pedrinaci and Dong Liu and Chenghua Lin and John
AAAI Technical Report SS-12-04 Intelligent Web Services Meet Social Computing Harnessing the Crowds for Automating the Identification of Web APIs Carlos Pedrinaci and Dong Liu and Chenghua Lin and John
Liangjie Hong*, Dawei Yin*, Jian Guo, Brian D. Davison*
 Tracking Trends: Incorporating Term Volume into Temporal Topic Models Liangjie Hong*, Dawei Yin*, Jian Guo, Brian D. Davison* Dept. of Computer Science and Engineering, Lehigh University, Bethlehem, PA,
Tracking Trends: Incorporating Term Volume into Temporal Topic Models Liangjie Hong*, Dawei Yin*, Jian Guo, Brian D. Davison* Dept. of Computer Science and Engineering, Lehigh University, Bethlehem, PA,
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Using Semantic Similarity in Crawling-based Web Application Testing. (National Taiwan Univ.)
") Using Semantic Similarity in Crawling-based Web Application Testing Jun-Wei Lin Farn Wang Paul Chu (UC-Irvine) (National Taiwan Univ.) (QNAP, Inc) Crawling-based Web App Testing the web app under test
Using Semantic Similarity in Crawling-based Web Application Testing Jun-Wei Lin Farn Wang Paul Chu (UC-Irvine) (National Taiwan Univ.) (QNAP, Inc) Crawling-based Web App Testing the web app under test
LDA for Big Data - Outline
 LDA FOR BIG DATA 1 LDA for Big Data - Outline Quick review of LDA model clustering words-in-context Parallel LDA ~= IPM Fast sampling tricks for LDA Sparsified sampler Alias table Fenwick trees LDA for
LDA FOR BIG DATA 1 LDA for Big Data - Outline Quick review of LDA model clustering words-in-context Parallel LDA ~= IPM Fast sampling tricks for LDA Sparsified sampler Alias table Fenwick trees LDA for
CS281 Section 9: Graph Models and Practical MCMC
 CS281 Section 9: Graph Models and Practical MCMC Scott Linderman November 11, 213 Now that we have a few MCMC inference algorithms in our toolbox, let s try them out on some random graph models. Graphs
CS281 Section 9: Graph Models and Practical MCMC Scott Linderman November 11, 213 Now that we have a few MCMC inference algorithms in our toolbox, let s try them out on some random graph models. Graphs
A Deep Relevance Matching Model for Ad-hoc Retrieval
 A Deep Relevance Matching Model for Ad-hoc Retrieval Jiafeng Guo 1, Yixing Fan 1, Qingyao Ai 2, W. Bruce Croft 2 1 CAS Key Lab of Web Data Science and Technology, Institute of Computing Technology, Chinese
A Deep Relevance Matching Model for Ad-hoc Retrieval Jiafeng Guo 1, Yixing Fan 1, Qingyao Ai 2, W. Bruce Croft 2 1 CAS Key Lab of Web Data Science and Technology, Institute of Computing Technology, Chinese
Applications of admixture models
 Applications of admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price Applications of admixture models 1 / 27
Applications of admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price Applications of admixture models 1 / 27
Automatically Extracting Polarity-Bearing Topics for Cross-Domain Sentiment Classification
 Automatically Extracting Polarity-Bearing Topics for Cross-Domain Sentiment Classification Yulan He Chenghua Lin Harith Alani Knowledge Media Institute, The Open University Milton Keynes MK7 6AA, UK {y.he,h.alani}@open.ac.uk
Automatically Extracting Polarity-Bearing Topics for Cross-Domain Sentiment Classification Yulan He Chenghua Lin Harith Alani Knowledge Media Institute, The Open University Milton Keynes MK7 6AA, UK {y.he,h.alani}@open.ac.uk
Spatial Latent Dirichlet Allocation
 Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Pre-Requisites: CS2510. NU Core Designations: AD
 DS4100: Data Collection, Integration and Analysis Teaches how to collect data from multiple sources and integrate them into consistent data sets. Explains how to use semi-automated and automated classification
DS4100: Data Collection, Integration and Analysis Teaches how to collect data from multiple sources and integrate them into consistent data sets. Explains how to use semi-automated and automated classification
Multi-label classification using rule-based classifier systems
 Multi-label classification using rule-based classifier systems Shabnam Nazmi (PhD candidate) Department of electrical and computer engineering North Carolina A&T state university Advisor: Dr. A. Homaifar
Multi-label classification using rule-based classifier systems Shabnam Nazmi (PhD candidate) Department of electrical and computer engineering North Carolina A&T state university Advisor: Dr. A. Homaifar
Tag-based Social Interest Discovery
 Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Tag-based Social Interest Discovery Xin Li / Lei Guo / Yihong (Eric) Zhao Yahoo!Inc 2008 Presented by: Tuan Anh Le (aletuan@vub.ac.be) 1 Outline Introduction Data set collection & Pre-processing Architecture
Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques
 24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
24 Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Enhancing Forecasting Performance of Naïve-Bayes Classifiers with Discretization Techniques Ruxandra PETRE
Recommendation of APIs for Mashup creation
 Recommendation of APIs for Mashup creation Priyanka Samanta (ps7723@cs.rit.edu) Advisor: Dr. Xumin Liu (xl@cs.rit.edu) B. Thomas Golisano College of Computing and Information Sciences Rochester Institute
Recommendation of APIs for Mashup creation Priyanka Samanta (ps7723@cs.rit.edu) Advisor: Dr. Xumin Liu (xl@cs.rit.edu) B. Thomas Golisano College of Computing and Information Sciences Rochester Institute
Data Mining Course Overview
 Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Data Mining Course Overview 1 Data Mining Overview Understanding Data Classification: Decision Trees and Bayesian classifiers, ANN, SVM Association Rules Mining: APriori, FP-growth Clustering: Hierarchical
Scalable Object Classification using Range Images
 Scalable Object Classification using Range Images Eunyoung Kim and Gerard Medioni Institute for Robotics and Intelligent Systems University of Southern California 1 What is a Range Image? Depth measurement
Scalable Object Classification using Range Images Eunyoung Kim and Gerard Medioni Institute for Robotics and Intelligent Systems University of Southern California 1 What is a Range Image? Depth measurement
jldadmm: A Java package for the LDA and DMM topic models
 jldadmm: A Java package for the LDA and DMM topic models Dat Quoc Nguyen School of Computing and Information Systems The University of Melbourne, Australia dqnguyen@unimelb.edu.au Abstract: In this technical
jldadmm: A Java package for the LDA and DMM topic models Dat Quoc Nguyen School of Computing and Information Systems The University of Melbourne, Australia dqnguyen@unimelb.edu.au Abstract: In this technical
Metadata Topic Harmonization and Semantic Search for Linked-Data-Driven Geoportals -- A Case Study Using ArcGIS Online
 Metadata Topic Harmonization and Semantic Search for Linked-Data-Driven Geoportals -- A Case Study Using ArcGIS Online Yingjie Hu 1, Krzysztof Janowicz 1, Sathya Prasad 2, and Song Gao 1 1 STKO Lab, Department
Metadata Topic Harmonization and Semantic Search for Linked-Data-Driven Geoportals -- A Case Study Using ArcGIS Online Yingjie Hu 1, Krzysztof Janowicz 1, Sathya Prasad 2, and Song Gao 1 1 STKO Lab, Department
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Classication of Corporate and Public Text
 Classication of Corporate and Public Text Kevin Nguyen December 16, 2011 1 Introduction In this project we try to tackle the problem of classifying a body of text as a corporate message (text usually sent
Classication of Corporate and Public Text Kevin Nguyen December 16, 2011 1 Introduction In this project we try to tackle the problem of classifying a body of text as a corporate message (text usually sent
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
One-Shot Learning with a Hierarchical Nonparametric Bayesian Model
 One-Shot Learning with a Hierarchical Nonparametric Bayesian Model R. Salakhutdinov, J. Tenenbaum and A. Torralba MIT Technical Report, 2010 Presented by Esther Salazar Duke University June 10, 2011 E.
One-Shot Learning with a Hierarchical Nonparametric Bayesian Model R. Salakhutdinov, J. Tenenbaum and A. Torralba MIT Technical Report, 2010 Presented by Esther Salazar Duke University June 10, 2011 E.
Hebei University of Technology A Text-Mining-based Patent Analysis in Product Innovative Process
 A Text-Mining-based Patent Analysis in Product Innovative Process Liang Yanhong, Tan Runhua Abstract Hebei University of Technology Patent documents contain important technical knowledge and research results.
A Text-Mining-based Patent Analysis in Product Innovative Process Liang Yanhong, Tan Runhua Abstract Hebei University of Technology Patent documents contain important technical knowledge and research results.
Collective Intelligence in Action
 Collective Intelligence in Action SATNAM ALAG II MANNING Greenwich (74 w. long.) contents foreword xv preface xvii acknowledgments xix about this book xxi PART 1 GATHERING DATA FOR INTELLIGENCE 1 "1 Understanding
Collective Intelligence in Action SATNAM ALAG II MANNING Greenwich (74 w. long.) contents foreword xv preface xvii acknowledgments xix about this book xxi PART 1 GATHERING DATA FOR INTELLIGENCE 1 "1 Understanding
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
An Unsupervised Approach for Discovering Relevant Tutorial Fragments for APIs
 An Unsupervised Approach for Discovering Relevant Tutorial Fragments for APIs He Jiang 1, 2, 3 Jingxuan Zhang 1 Zhilei Ren 1 Tao Zhang 4 jianghe@dlut.edu.cn jingxuanzhang@mail.dlut.edu.cn zren@dlut.edu.cn
An Unsupervised Approach for Discovering Relevant Tutorial Fragments for APIs He Jiang 1, 2, 3 Jingxuan Zhang 1 Zhilei Ren 1 Tao Zhang 4 jianghe@dlut.edu.cn jingxuanzhang@mail.dlut.edu.cn zren@dlut.edu.cn
Application of rough ensemble classifier to web services categorization and focused crawling
 With the expected growth of the number of Web services available on the web, the need for mechanisms that enable the automatic categorization to organize this vast amount of data, becomes important. A
With the expected growth of the number of Web services available on the web, the need for mechanisms that enable the automatic categorization to organize this vast amount of data, becomes important. A
PTE : Predictive Text Embedding through Large-scale Heterogeneous Text Networks
 PTE : Predictive Text Embedding through Large-scale Heterogeneous Text Networks Pramod Srinivasan CS591txt - Text Mining Seminar University of Illinois, Urbana-Champaign April 8, 2016 Pramod Srinivasan
PTE : Predictive Text Embedding through Large-scale Heterogeneous Text Networks Pramod Srinivasan CS591txt - Text Mining Seminar University of Illinois, Urbana-Champaign April 8, 2016 Pramod Srinivasan
Scalable Bayes Clustering for Outlier Detection Under Informative Sampling
 Scalable Bayes Clustering for Outlier Detection Under Informative Sampling Based on JMLR paper of T. D. Savitsky Terrance D. Savitsky Office of Survey Methods Research FCSM - 2018 March 7-9, 2018 1 / 21
Scalable Bayes Clustering for Outlier Detection Under Informative Sampling Based on JMLR paper of T. D. Savitsky Terrance D. Savitsky Office of Survey Methods Research FCSM - 2018 March 7-9, 2018 1 / 21
Knowledge-based Word Sense Disambiguation using Topic Models Devendra Singh Chaplot
 Knowledge-based Word Sense Disambiguation using Topic Models Devendra Singh Chaplot Ruslan Salakhutdinov Word Sense Disambiguation Word sense disambiguation (WSD) is defined as the problem of computationally
Knowledge-based Word Sense Disambiguation using Topic Models Devendra Singh Chaplot Ruslan Salakhutdinov Word Sense Disambiguation Word sense disambiguation (WSD) is defined as the problem of computationally
Text Document Clustering Using DPM with Concept and Feature Analysis
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 2, Issue. 10, October 2013,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 2, Issue. 10, October 2013,
A Navigation-log based Web Mining Application to Profile the Interests of Users Accessing the Web of Bidasoa Turismo
 A Navigation-log based Web Mining Application to Profile the Interests of Users Accessing the Web of Bidasoa Turismo Olatz Arbelaitz, Ibai Gurrutxaga, Aizea Lojo, Javier Muguerza, Jesús M. Pérez and Iñigo
A Navigation-log based Web Mining Application to Profile the Interests of Users Accessing the Web of Bidasoa Turismo Olatz Arbelaitz, Ibai Gurrutxaga, Aizea Lojo, Javier Muguerza, Jesús M. Pérez and Iñigo
Classification. 1 o Semestre 2007/2008
 Classification Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 Single-Class
Classification Departamento de Engenharia Informática Instituto Superior Técnico 1 o Semestre 2007/2008 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 Single-Class
Lecture 21 : A Hybrid: Deep Learning and Graphical Models
 10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
Probabilistic Dialogue Models with Prior Domain Knowledge
 Probabilistic Dialogue Models with Prior Domain Knowledge Pierre Lison Language Technology Group University of Oslo July 6, 2012 SIGDIAL Introduction The use of statistical models is getting increasingly
Probabilistic Dialogue Models with Prior Domain Knowledge Pierre Lison Language Technology Group University of Oslo July 6, 2012 SIGDIAL Introduction The use of statistical models is getting increasingly
Studying the Impact of Text Summarization on Contextual Advertising
 Studying the Impact of Text Summarization on Contextual Advertising G. Armano, A. Giuliani, and E. Vargiu Intelligent Agents and Soft-Computing Group Dept. of Electrical and Electronic Engineering University
Studying the Impact of Text Summarization on Contextual Advertising G. Armano, A. Giuliani, and E. Vargiu Intelligent Agents and Soft-Computing Group Dept. of Electrical and Electronic Engineering University
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Ontology based Model and Procedure Creation for Topic Analysis in Chinese Language
 Ontology based Model and Procedure Creation for Topic Analysis in Chinese Language Dong Han and Kilian Stoffel Information Management Institute, University of Neuchâtel Pierre-à-Mazel 7, CH-2000 Neuchâtel,
Ontology based Model and Procedure Creation for Topic Analysis in Chinese Language Dong Han and Kilian Stoffel Information Management Institute, University of Neuchâtel Pierre-à-Mazel 7, CH-2000 Neuchâtel,
Warped Mixture Models
 Warped Mixture Models Tomoharu Iwata, David Duvenaud, Zoubin Ghahramani Cambridge University Computational and Biological Learning Lab March 11, 2013 OUTLINE Motivation Gaussian Process Latent Variable
Warped Mixture Models Tomoharu Iwata, David Duvenaud, Zoubin Ghahramani Cambridge University Computational and Biological Learning Lab March 11, 2013 OUTLINE Motivation Gaussian Process Latent Variable
Event: PASS SQL Saturday - DC 2018 Presenter: Jon Tupitza, CTO Architect
 Event: PASS SQL Saturday - DC 2018 Presenter: Jon Tupitza, CTO Architect BEOP.CTO.TP4 Owner: OCTO Revision: 0001 Approved by: JAT Effective: 08/30/2018 Buchanan & Edwards Proprietary: Printed copies of
Event: PASS SQL Saturday - DC 2018 Presenter: Jon Tupitza, CTO Architect BEOP.CTO.TP4 Owner: OCTO Revision: 0001 Approved by: JAT Effective: 08/30/2018 Buchanan & Edwards Proprietary: Printed copies of
Estimating Labels from Label Proportions
 Estimating Labels from Label Proportions Novi Quadrianto Novi.Quad@gmail.com The Australian National University, Australia NICTA, Statistical Machine Learning Program, Australia Joint work with Alex Smola,
Estimating Labels from Label Proportions Novi Quadrianto Novi.Quad@gmail.com The Australian National University, Australia NICTA, Statistical Machine Learning Program, Australia Joint work with Alex Smola,
K Nearest Neighbor Wrap Up K- Means Clustering. Slides adapted from Prof. Carpuat
 K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
K Nearest Neighbor Wrap Up K- Means Clustering Slides adapted from Prof. Carpuat K Nearest Neighbor classification Classification is based on Test instance with Training Data K: number of neighbors that
Sampling Table Configulations for the Hierarchical Poisson-Dirichlet Process
 Sampling Table Configulations for the Hierarchical Poisson-Dirichlet Process Changyou Chen,, Lan Du,, Wray Buntine, ANU College of Engineering and Computer Science The Australian National University National
Sampling Table Configulations for the Hierarchical Poisson-Dirichlet Process Changyou Chen,, Lan Du,, Wray Buntine, ANU College of Engineering and Computer Science The Australian National University National
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
INTRODUCTION TO DATA MINING. Daniel Rodríguez, University of Alcalá
 INTRODUCTION TO DATA MINING Daniel Rodríguez, University of Alcalá Outline Knowledge Discovery in Datasets Model Representation Types of models Supervised Unsupervised Evaluation (Acknowledgement: Jesús
INTRODUCTION TO DATA MINING Daniel Rodríguez, University of Alcalá Outline Knowledge Discovery in Datasets Model Representation Types of models Supervised Unsupervised Evaluation (Acknowledgement: Jesús
Parallelism for LDA Yang Ruan, Changsi An
 Parallelism for LDA Yang Ruan, Changsi An (yangruan@indiana.edu, anch@indiana.edu) 1. Overview As parallelism is very important for large scale of data, we want to use different technology to parallelize
Parallelism for LDA Yang Ruan, Changsi An (yangruan@indiana.edu, anch@indiana.edu) 1. Overview As parallelism is very important for large scale of data, we want to use different technology to parallelize
Hierarchical Document Clustering
 Hierarchical Document Clustering Benjamin C. M. Fung, Ke Wang, and Martin Ester, Simon Fraser University, Canada INTRODUCTION Document clustering is an automatic grouping of text documents into clusters
Hierarchical Document Clustering Benjamin C. M. Fung, Ke Wang, and Martin Ester, Simon Fraser University, Canada INTRODUCTION Document clustering is an automatic grouping of text documents into clusters
DATA MINING AND MACHINE LEARNING. Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
Randomized Algorithms for Fast Bayesian Hierarchical Clustering
 Randomized Algorithms for Fast Bayesian Hierarchical Clustering Katherine A. Heller and Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College ondon, ondon, WC1N 3AR, UK {heller,zoubin}@gatsby.ucl.ac.uk
Randomized Algorithms for Fast Bayesian Hierarchical Clustering Katherine A. Heller and Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College ondon, ondon, WC1N 3AR, UK {heller,zoubin}@gatsby.ucl.ac.uk
Introduction to Information Retrieval
 Introduction to Information Retrieval Mohsen Kamyar چهارمین کارگاه ساالنه آزمایشگاه فناوری و وب بهمن ماه 1391 Outline Outline in classic categorization Information vs. Data Retrieval IR Models Evaluation
Introduction to Information Retrieval Mohsen Kamyar چهارمین کارگاه ساالنه آزمایشگاه فناوری و وب بهمن ماه 1391 Outline Outline in classic categorization Information vs. Data Retrieval IR Models Evaluation
A novel supervised learning algorithm and its use for Spam Detection in Social Bookmarking Systems
 A novel supervised learning algorithm and its use for Spam Detection in Social Bookmarking Systems Anestis Gkanogiannis and Theodore Kalamboukis Department of Informatics Athens University of Economics
A novel supervised learning algorithm and its use for Spam Detection in Social Bookmarking Systems Anestis Gkanogiannis and Theodore Kalamboukis Department of Informatics Athens University of Economics
Clustering Relational Data using the Infinite Relational Model
 Clustering Relational Data using the Infinite Relational Model Ana Daglis Supervised by: Matthew Ludkin September 4, 2015 Ana Daglis Clustering Data using the Infinite Relational Model September 4, 2015
Clustering Relational Data using the Infinite Relational Model Ana Daglis Supervised by: Matthew Ludkin September 4, 2015 Ana Daglis Clustering Data using the Infinite Relational Model September 4, 2015
COMS 4771 Clustering. Nakul Verma
 COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
An Approach To Web Content Mining
 An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
An Approach To Web Content Mining Nita Patil, Chhaya Das, Shreya Patanakar, Kshitija Pol Department of Computer Engg. Datta Meghe College of Engineering, Airoli, Navi Mumbai Abstract-With the research
A modified and fast Perceptron learning rule and its use for Tag Recommendations in Social Bookmarking Systems
 A modified and fast Perceptron learning rule and its use for Tag Recommendations in Social Bookmarking Systems Anestis Gkanogiannis and Theodore Kalamboukis Department of Informatics Athens University
A modified and fast Perceptron learning rule and its use for Tag Recommendations in Social Bookmarking Systems Anestis Gkanogiannis and Theodore Kalamboukis Department of Informatics Athens University
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Observe novel applicability of DL techniques in Big Data Analytics. Applications of DL techniques for common Big Data Analytics problems. Semantic indexing
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2
 A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
A Survey Of Different Text Mining Techniques Varsha C. Pande 1 and Dr. A.S. Khandelwal 2 1 Department of Electronics & Comp. Sc, RTMNU, Nagpur, India 2 Department of Computer Science, Hislop College, Nagpur,
Semantic Estimation for Texts in Software Engineering
 Semantic Estimation for Texts in Software Engineering 汇报人 : Reporter:Xiaochen Li Dalian University of Technology, China 大连理工大学 2016 年 11 月 29 日 Oscar Lab 2 Ph.D. candidate at OSCAR Lab, in Dalian University
Semantic Estimation for Texts in Software Engineering 汇报人 : Reporter:Xiaochen Li Dalian University of Technology, China 大连理工大学 2016 年 11 月 29 日 Oscar Lab 2 Ph.D. candidate at OSCAR Lab, in Dalian University
SCALABLE KNOWLEDGE BASED AGGREGATION OF COLLECTIVE BEHAVIOR
 SCALABLE KNOWLEDGE BASED AGGREGATION OF COLLECTIVE BEHAVIOR P.SHENBAGAVALLI M.E., Research Scholar, Assistant professor/cse MPNMJ Engineering college Sspshenba2@gmail.com J.SARAVANAKUMAR B.Tech(IT)., PG
SCALABLE KNOWLEDGE BASED AGGREGATION OF COLLECTIVE BEHAVIOR P.SHENBAGAVALLI M.E., Research Scholar, Assistant professor/cse MPNMJ Engineering college Sspshenba2@gmail.com J.SARAVANAKUMAR B.Tech(IT)., PG
Knowledge Discovery and Data Mining 1 (VO) ( )
 ( )") Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Knowledge Discovery and Data Mining 1 (VO) (707.003) Data Matrices and Vector Space Model Denis Helic KTI, TU Graz Nov 6, 2014 Denis Helic (KTI, TU Graz) KDDM1 Nov 6, 2014 1 / 55 Big picture: KDDM Probability
Representation/Indexing (fig 1.2) IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s
 IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s") Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
3D RECONSTRUCTION OF BRAIN TISSUE
 3D RECONSTRUCTION OF BRAIN TISSUE Hylke Buisman, Manuel Gomez-Rodriguez, Saeed Hassanpour {hbuisman, manuelgr, saeedhp}@stanford.edu Department of Computer Science, Department of Electrical Engineering
3D RECONSTRUCTION OF BRAIN TISSUE Hylke Buisman, Manuel Gomez-Rodriguez, Saeed Hassanpour {hbuisman, manuelgr, saeedhp}@stanford.edu Department of Computer Science, Department of Electrical Engineering
Link Prediction for Social Network
 Link Prediction for Social Network Ning Lin Computer Science and Engineering University of California, San Diego Email: nil016@eng.ucsd.edu Abstract Friendship recommendation has become an important issue
Link Prediction for Social Network Ning Lin Computer Science and Engineering University of California, San Diego Email: nil016@eng.ucsd.edu Abstract Friendship recommendation has become an important issue
Using PageRank in Feature Selection
 Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy {ienco,meo,botta}@di.unito.it Abstract. Feature selection is an important
Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy {ienco,meo,botta}@di.unito.it Abstract. Feature selection is an important
Collective classification in network data
 1 / 50 Collective classification in network data Seminar on graphs, UCSB 2009 Outline 2 / 50 1 Problem 2 Methods Local methods Global methods 3 Experiments Outline 3 / 50 1 Problem 2 Methods Local methods
1 / 50 Collective classification in network data Seminar on graphs, UCSB 2009 Outline 2 / 50 1 Problem 2 Methods Local methods Global methods 3 Experiments Outline 3 / 50 1 Problem 2 Methods Local methods
University of Virginia Department of Computer Science. CS 4501: Information Retrieval Fall 2015
 University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 5:00pm-6:15pm, Monday, October 26th Name: ComputingID: This is a closed book and closed notes exam. No electronic
University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 5:00pm-6:15pm, Monday, October 26th Name: ComputingID: This is a closed book and closed notes exam. No electronic
A REALM-BASED QUESTION ANSWERING SYSTEM USING PROBABILISTIC MODELING
 A REALM-BASED QUESTION ANSWERING SYSTEM USING PROBABILISTIC MODELING By CLINT PAZHAYIDAM GEORGE A THESIS PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS
A REALM-BASED QUESTION ANSWERING SYSTEM USING PROBABILISTIC MODELING By CLINT PAZHAYIDAM GEORGE A THESIS PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS
Web Mining TEAM 8. Professor Anita Wasilewska CSE 634 Data Mining
 Web Mining TEAM 8 Paper - You Are What You Tweet : Analyzing Twitter for Public Health Authors : Paul, Michael J., and Mark Dredze. Conference : AAAI Publications, Fifth International AAAI Conference on
Web Mining TEAM 8 Paper - You Are What You Tweet : Analyzing Twitter for Public Health Authors : Paul, Michael J., and Mark Dredze. Conference : AAAI Publications, Fifth International AAAI Conference on
Using PageRank in Feature Selection
 Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy fienco,meo,bottag@di.unito.it Abstract. Feature selection is an important
Using PageRank in Feature Selection Dino Ienco, Rosa Meo, and Marco Botta Dipartimento di Informatica, Università di Torino, Italy fienco,meo,bottag@di.unito.it Abstract. Feature selection is an important
Classifying Bug Reports to Bugs and Other Requests Using Topic Modeling
 Classifying Bug Reports to Bugs and Other Requests Using Topic Modeling Natthakul Pingclasai Department of Computer Engineering Kasetsart University Bangkok, Thailand Email: b5310547207@ku.ac.th Hideaki
Classifying Bug Reports to Bugs and Other Requests Using Topic Modeling Natthakul Pingclasai Department of Computer Engineering Kasetsart University Bangkok, Thailand Email: b5310547207@ku.ac.th Hideaki
Science 2.0 VU Processing Science 2.0 Data, Content Mining
 W I S S E N n T E C H N I K n L E I D E N S C H A F T Science 2.0 VU Processing Science 2.0 Data, Content Mining Elisabeth Lex KTI, TU Graz WS 2015/16 u www.tugraz.at Agenda Repetition from last time:
W I S S E N n T E C H N I K n L E I D E N S C H A F T Science 2.0 VU Processing Science 2.0 Data, Content Mining Elisabeth Lex KTI, TU Graz WS 2015/16 u www.tugraz.at Agenda Repetition from last time:
A Neuro Probabilistic Language Model Bengio et. al. 2003
 A Neuro Probabilistic Language Model Bengio et. al. 2003 Class Discussion Notes Scribe: Olivia Winn February 1, 2016 Opening thoughts (or why this paper is interesting): Word embeddings currently have
A Neuro Probabilistic Language Model Bengio et. al. 2003 Class Discussion Notes Scribe: Olivia Winn February 1, 2016 Opening thoughts (or why this paper is interesting): Word embeddings currently have
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Outline. Possible solutions. The basic problem. How? How? Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity
 Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University
 Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University NIPS 2008: E. Sudderth & M. Jordan, Shared Segmentation of Natural
Applied Bayesian Nonparametrics 5. Spatial Models via Gaussian Processes, not MRFs Tutorial at CVPR 2012 Erik Sudderth Brown University NIPS 2008: E. Sudderth & M. Jordan, Shared Segmentation of Natural
Multi-Label Classification with Conditional Tree-structured Bayesian Networks
 Multi-Label Classification with Conditional Tree-structured Bayesian Networks Original work: Batal, I., Hong C., and Hauskrecht, M. An Efficient Probabilistic Framework for Multi-Dimensional Classification.
Multi-Label Classification with Conditional Tree-structured Bayesian Networks Original work: Batal, I., Hong C., and Hauskrecht, M. An Efficient Probabilistic Framework for Multi-Dimensional Classification.
PlantSimLab An Innovative Web Application Tool for Plant Biologists
 PlantSimLab An Innovative Web Application Tool for Plant Biologists Feb. 17, 2014 Sook S. Ha, PhD Postdoctoral Associate Virginia Bioinformatics Institute (VBI) 1 Outline PlantSimLab Project A NSF proposal
PlantSimLab An Innovative Web Application Tool for Plant Biologists Feb. 17, 2014 Sook S. Ha, PhD Postdoctoral Associate Virginia Bioinformatics Institute (VBI) 1 Outline PlantSimLab Project A NSF proposal
Context Change and Versatile Models in Machine Learning
 Context Change and Versatile s in Machine Learning José Hernández-Orallo Universitat Politècnica de València jorallo@dsic.upv.es ECML Workshop on Learning over Multiple Contexts Nancy, 19 September 2014
Context Change and Versatile s in Machine Learning José Hernández-Orallo Universitat Politècnica de València jorallo@dsic.upv.es ECML Workshop on Learning over Multiple Contexts Nancy, 19 September 2014
D B M G Data Base and Data Mining Group of Politecnico di Torino
 DataBase and Data Mining Group of Data mining fundamentals Data Base and Data Mining Group of Data analysis Most companies own huge databases containing operational data textual documents experiment results
DataBase and Data Mining Group of Data mining fundamentals Data Base and Data Mining Group of Data analysis Most companies own huge databases containing operational data textual documents experiment results
Statistical Machine Learning for Text Mining with Markov Chain Monte Carlo Inference
 RICE UNIVERSITY Statistical Machine Learning for Text Mining with Markov Chain Monte Carlo Inference by Anna Drummond AThesisSubmitted in Partial Fulfillment of the Requirements for the Degree Doctor of
RICE UNIVERSITY Statistical Machine Learning for Text Mining with Markov Chain Monte Carlo Inference by Anna Drummond AThesisSubmitted in Partial Fulfillment of the Requirements for the Degree Doctor of
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
QMiner is a data analytics platform for processing large-scale real-time streams containing structured and unstructured data.
 Data analytics with QMiner This topic provides a practical insights on data analytics using QMiner. QMiner implements a comprehensive set of techniques for supervised, unsupervised and active learning
Data analytics with QMiner This topic provides a practical insights on data analytics using QMiner. QMiner implements a comprehensive set of techniques for supervised, unsupervised and active learning
Visualization and text mining of patent and non-patent data
 of patent and non-patent data Anton Heijs Information Solutions Delft, The Netherlands http://www.treparel.com/ ICIC conference, Nice, France, 2008 Outline Introduction Applications on patent and non-patent
of patent and non-patent data Anton Heijs Information Solutions Delft, The Netherlands http://www.treparel.com/ ICIC conference, Nice, France, 2008 Outline Introduction Applications on patent and non-patent
How SPICE Language Modeling Works
 How SPICE Language Modeling Works Abstract Enhancement of the Language Model is a first step towards enhancing the performance of an Automatic Speech Recognition system. This report describes an integrated
How SPICE Language Modeling Works Abstract Enhancement of the Language Model is a first step towards enhancing the performance of an Automatic Speech Recognition system. This report describes an integrated
Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers
 Conditional Data-Mining Classifiers") Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers James P. Biagioni Piotr M. Szczurek Peter C. Nelson, Ph.D. Abolfazl Mohammadian, Ph.D. Agenda Background
Tour-Based Mode Choice Modeling: Using An Ensemble of (Un-) Conditional Data-Mining Classifiers James P. Biagioni Piotr M. Szczurek Peter C. Nelson, Ph.D. Abolfazl Mohammadian, Ph.D. Agenda Background
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
Automatic Labeling of Issues on Github A Machine learning Approach
 Automatic Labeling of Issues on Github A Machine learning Approach Arun Kalyanasundaram December 15, 2014 ABSTRACT Companies spend hundreds of billions in software maintenance every year. Managing and
Automatic Labeling of Issues on Github A Machine learning Approach Arun Kalyanasundaram December 15, 2014 ABSTRACT Companies spend hundreds of billions in software maintenance every year. Managing and
Predicting Messaging Response Time in a Long Distance Relationship
 Predicting Messaging Response Time in a Long Distance Relationship Meng-Chen Shieh m3shieh@ucsd.edu I. Introduction The key to any successful relationship is communication, especially during times when
Predicting Messaging Response Time in a Long Distance Relationship Meng-Chen Shieh m3shieh@ucsd.edu I. Introduction The key to any successful relationship is communication, especially during times when
Automatically Constructing a Directory of Molecular Biology Databases
 Automatically Constructing a Directory of Molecular Biology Databases Luciano Barbosa Sumit Tandon Juliana Freire School of Computing University of Utah {lbarbosa, sumitt, juliana}@cs.utah.edu Online Databases
Automatically Constructing a Directory of Molecular Biology Databases Luciano Barbosa Sumit Tandon Juliana Freire School of Computing University of Utah {lbarbosa, sumitt, juliana}@cs.utah.edu Online Databases
LSHTC: A Benchmark for Large-Scale Classification
 LSHTC: A Benchmark for Large-Scale Classification I. Partalas, A. Kosmopoulos,, G. Paliouras, E. Gaussier, I. Androutsopoulos, T. Artières, P. Gallinari, Massih-Reza Amini, Nicolas Baskiotis Lab. d Informatique
LSHTC: A Benchmark for Large-Scale Classification I. Partalas, A. Kosmopoulos,, G. Paliouras, E. Gaussier, I. Androutsopoulos, T. Artières, P. Gallinari, Massih-Reza Amini, Nicolas Baskiotis Lab. d Informatique
A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING
 A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING Sumit Goswami 1 and Mayank Singh Shishodia 2 1 Indian Institute of Technology-Kharagpur, Kharagpur, India sumit_13@yahoo.com 2 School of Computer
A FUZZY BASED APPROACH TO TEXT MINING AND DOCUMENT CLUSTERING Sumit Goswami 1 and Mayank Singh Shishodia 2 1 Indian Institute of Technology-Kharagpur, Kharagpur, India sumit_13@yahoo.com 2 School of Computer
BUPT at TREC 2009: Entity Track
 BUPT at TREC 2009: Entity Track Zhanyi Wang, Dongxin Liu, Weiran Xu, Guang Chen, Jun Guo Pattern Recognition and Intelligent System Lab, Beijing University of Posts and Telecommunications, Beijing, China,
BUPT at TREC 2009: Entity Track Zhanyi Wang, Dongxin Liu, Weiran Xu, Guang Chen, Jun Guo Pattern Recognition and Intelligent System Lab, Beijing University of Posts and Telecommunications, Beijing, China,
Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels
 Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels Richa Jain 1, Namrata Sharma 2 1M.Tech Scholar, Department of CSE, Sushila Devi Bansal College of Engineering, Indore (M.P.),
Classifying Twitter Data in Multiple Classes Based On Sentiment Class Labels Richa Jain 1, Namrata Sharma 2 1M.Tech Scholar, Department of CSE, Sushila Devi Bansal College of Engineering, Indore (M.P.),