Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University
|
|
|
- Shauna Underwood
- 6 years ago
- Views:
Transcription
1 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University
2 Project3 Cache Race Games night Monday, May 4 th, 5pm Come, eat, drink, have fun and be merry! Location: B17 Upson Hall Prelim2: Thursday, April 30 th in evening Time and Location: 7:30pm sharp in Statler Auditorium Old prelims are online in CMS Prelim Review Session: TODAY, Tuesday, April 28, 7 9pm in B14 Hollister Hall Project4: Design Doc due May 5 th, bring design doc to mtg May 4 6 Demos: May 12 and 13 Will not be able to use slip days
3 Prelim2 Topics Lecture: Lectures 10 to 24 Data and Control Hazards (Chapters ) RISC/CISC (Chapters , 2.21) Calling conventions and linkers (Chapters 2.8, 2.12, Appendix A.1 6) Caching and Virtual Memory (Chapter 5) Multicore/parallelism (Chapter 6) Synchronization (Chapter 2.11) Traps, Exceptions, OS (Chapter 4.9, Appendix A.7, pp ) HW2, Labs 3/4, C Labs 2/3, PA2/3 Topics from Prelim1 (not the focus, but some possible questions)
4
5 GPU: Graphics processing unit Very basic till about 1999 Specialized device to accelerate display Then started changing into a full processor 2000 : Frontier times



6 CPU: Central Processing Unit GPU: Graphics Processing Unit
7 GPU parallelism is similar to multicore parallelism Key: How to gang schedule thousands of threads on thousands of cores? Hardware multithreading with thousands of register sets GPU Hardware multithreads (like multicore Hyperthreads) MultiIssue + extra PCs and registers dependency logic Illusion of thousands of cores Fine grain hardware multithreading Easier to keep pipelines full
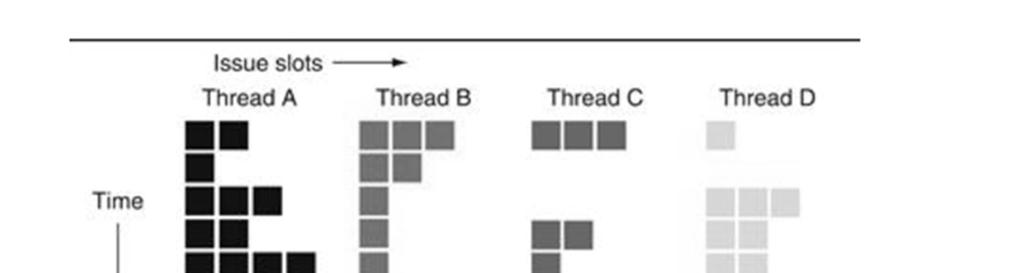

8
9 Processing is highly data parallel GPUs are highly multithreaded Use thread switching to hide memory latency Less reliance on multi level caches Graphics memory is wide and high bandwidth Trend toward general purpose GPUs Heterogeneous CPU/GPU systems CPU for sequential code, GPU for parallel code Programming languages/apis DirectX, OpenGL C for Graphics (Cg), High Level Shader Language (HLSL) Compute Unified Device Architecture (CUDA)



10
11 10 9 One-pixel polygons (~10M 30Hz) nvidia G Peak Performance (polygon s s/sec) UNC Pxpl4 HP CRX 10 4 Flat shading SGI Iris HP VRX SGI GT Slope ~2.4x/year (Moore's Law ~ 1.7x/year) UNC Pxpl5 SGI SkyWriter SGI VGX HP TVRX Stellar GS1000 Gouraud shading SGI RE1 E&S F Year SGI RE2 Antialiasing UNC/HP PixelFlow SGI IR ATI SGI Radeon 256 R-Monster E&S Nvidia TNT GeForce Division 3DLabs Harmony SGI Pxpl6 Glint Cobalt Accel/VSIS Voodoo Megatek E&S Freedom Textures Division VPX PC Graphics Graph courtesy of Professor John Poulton (from Eric Haines)
12 Started in 1999 Flexible, programmable Vertex, Geometry, Fragment Shaders And much faster, of course 1999 GeForce256: 0.35 Gigapixel peak fill rate 2001 GeForce3: 0.8 Gigapixel peak fill rate 2003 GeForceFX Ultra: 2.0 Gigapixel peak fill rate ATI Radeon 9800 Pro : 3.0 Gigapixel peak fill rate 2006 NV60:... Gigapixel peak fill rate 2009 GeForce GTX 285: 10 Gigapixel peak fill rate 2011 GeForce GTC 590: 56 Gigapixel peak fill rate Radeon HD 6990: 2x GeForce GTC 690: 62 Gigapixel/s peak fill rate



13

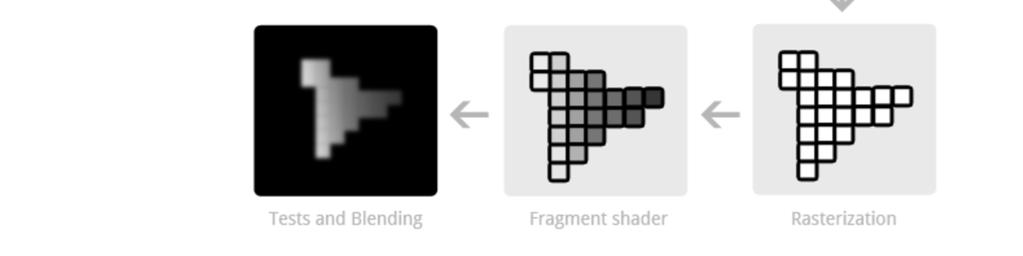
14 Fixed function pipeline



15 Programmable vertex and pixel processors
16 nvidia Kepler

17 Parallelism: thousands of cores Pipelining Hardware multithreading Not multiscale caching Streaming caches Throughput, not latency
18 Single Instruction Single Data (SISD) Single Instruction Multiple Data (SIMD) Multiple Instruction Single Data (MISD) Multiple Instruction Multiple Data (MIMD)



19 nvidia Kepler

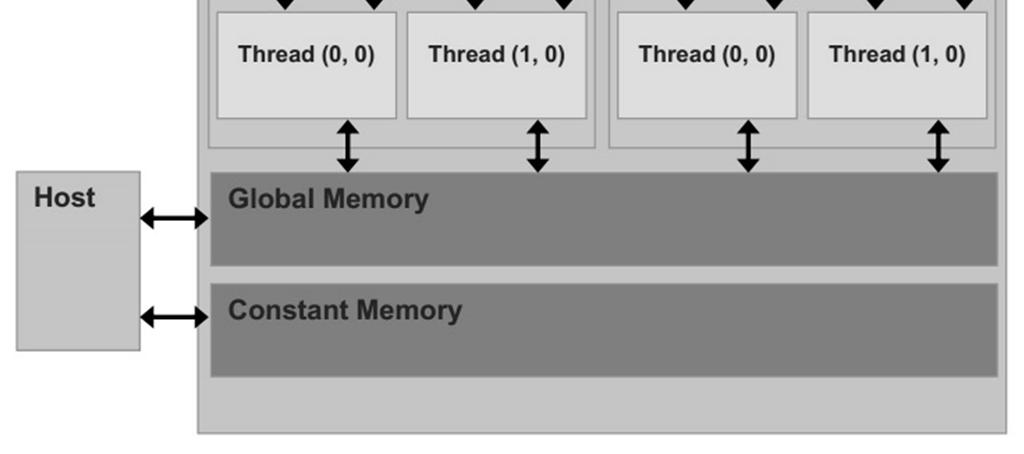
20 Shuang Zhao, Cornell University, 2014
21 Faster, per block Fastest, per thread Slower, global Read only, cached Shuang Zhao, Cornell University, 2014

22 Host: the CPU and its memory Device: the GPU and its memory Shuang Zhao, Cornell University, 2014
; do_something_else_on_host(); Highly parallel Shuang Zhao, Cornell")
23 Compute Unified Device Architecture do_something_on_host(); kernel<<<nblk, ntid>>>(args); cudadevicesynchronize(); do_something_else_on_host(); Highly parallel Shuang Zhao, Cornell University, 2014
24 Threads in a block are partitioned into warps All threads in a warp execute in a Single Instruction Multiple Data, or SIMD, fashion All paths of conditional branches will be taken Warp size varies, many graphics cards have 32 NO guaranteed execution ordering between warps Shuang Zhao, Cornell University, 2014
25 Threads in one warp execute very different branches Significantly harms the performance! Simple solution: Reordering the threads so that all threads in each block are more likely to take the same branch Not always possible Shuang Zhao, Cornell University, 2014


26 Streaming multiprocessor Chapter 6 Parallel Processors from Client to Cloud 26 8 Streaming processors

27 Streaming Processors Single precision FP and integer units Each SP is fine grained multithreaded Warp: group of 32 threads Executed in parallel, SIMD style 8 SPs 4 clock cycles Hardware contexts for 24 warps Registers, PCs, Chapter 6 Parallel Processors from Client to Cloud 27

28
29
What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University. * slides thanks to Kavita Bala & many others
 What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University * slides thanks to Kavita Bala & many others Final Project Demo Sign-Up: Will be posted outside my office after lecture today.
What Next? Kevin Walsh CS 3410, Spring 2010 Computer Science Cornell University * slides thanks to Kavita Bala & many others Final Project Demo Sign-Up: Will be posted outside my office after lecture today.
Computer Graphics. Hardware Pipeline. Visual Imaging in the Electronic Age Prof. Donald P. Greenberg October 23, 2014 Lecture 16
 Computer Graphics Hardware Pipeline Visual Imaging in the Electronic Age Prof. Donald P. Greenberg October 23, 2014 Lecture 16 Moore s Law Chip density doubles every 18 months. Processing Power (P) in
Computer Graphics Hardware Pipeline Visual Imaging in the Electronic Age Prof. Donald P. Greenberg October 23, 2014 Lecture 16 Moore s Law Chip density doubles every 18 months. Processing Power (P) in
CS 316: Multicore/GPUs
 CS 316: Multicore/GPUs Kavita Bala Fall 2007 Computer Science Cornell University Announcements Core Wars will be out in the next couple of days Aim at having fun! Number of points allocated to it is small
CS 316: Multicore/GPUs Kavita Bala Fall 2007 Computer Science Cornell University Announcements Core Wars will be out in the next couple of days Aim at having fun! Number of points allocated to it is small
CS 316: Multicore/GPUs-II
 CS 316: Multicore/GPUs-II Kavita Bala Fall 2007 Computer Science Cornell University Announcements PA 4 graded Corewars due next Tuesday: Nov 27 Corewars party next Friday: Nov 30 Prelim 2: Thursday Nov
CS 316: Multicore/GPUs-II Kavita Bala Fall 2007 Computer Science Cornell University Announcements PA 4 graded Corewars due next Tuesday: Nov 27 Corewars party next Friday: Nov 30 Prelim 2: Thursday Nov
What does the Future Hold? Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University
 What does the Future Hold? Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University Announcements How to improve your grade? Submit a course evaluation and drop lowest homework score
What does the Future Hold? Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University Announcements How to improve your grade? Submit a course evaluation and drop lowest homework score
Computer Graphics Software & Hardware. NBAY 6120 Lecture 6 Donald P. Greenberg March 16, 2016
 Computer Graphics Software & Hardware NBAY 6120 Lecture 6 Donald P. Greenberg March 16, 2016 Recommended Readings for Lecture 6 Mike Seymour. The State of Rendering, Part 1, fxguide.com, July 15, 2013.
Computer Graphics Software & Hardware NBAY 6120 Lecture 6 Donald P. Greenberg March 16, 2016 Recommended Readings for Lecture 6 Mike Seymour. The State of Rendering, Part 1, fxguide.com, July 15, 2013.
Computer Graphics Software & Hardware. NBAY 6120 Lecture 6 Donald P. Greenberg March 16, 2017
 Computer Graphics Software & Hardware NBAY 6120 Lecture 6 Donald P. Greenberg March 16, 2017 Recommended Readings for Lecture 6 Mike Seymour. The State of Rendering, Part 1, fxguide.com, July 15, 2013.
Computer Graphics Software & Hardware NBAY 6120 Lecture 6 Donald P. Greenberg March 16, 2017 Recommended Readings for Lecture 6 Mike Seymour. The State of Rendering, Part 1, fxguide.com, July 15, 2013.
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Multicore and Parallel Processing
 Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. See: Online P&H Chapter 6.5 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University See: Online P&H Chapter 6.5 6 Project3 submit souped up bot to CMS Project3 Cache Race Games night Monday, May 4 th, 5pm
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University See: Online P&H Chapter 6.5 6 Project3 submit souped up bot to CMS Project3 Cache Race Games night Monday, May 4 th, 5pm
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. P & H Chapter 4.10, 1.7, 1.8, 5.10, 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
CS 179: GPU Programming
 CS 179: GPU Programming Introduction Lecture originally written by Luke Durant, Tamas Szalay, Russell McClellan What We Will Cover Programming GPUs, of course: OpenGL Shader Language (GLSL) Compute Unified
CS 179: GPU Programming Introduction Lecture originally written by Luke Durant, Tamas Szalay, Russell McClellan What We Will Cover Programming GPUs, of course: OpenGL Shader Language (GLSL) Compute Unified
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. See: Online P&H Chapter 6.5 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University See: Online P&H Chapter 6.5 6 Prelim2 Topics Lecture: Lectures 10 to 24 Data and Control Hazards (Chapters 4.7 4.8) RISC/CISC
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University See: Online P&H Chapter 6.5 6 Prelim2 Topics Lecture: Lectures 10 to 24 Data and Control Hazards (Chapters 4.7 4.8) RISC/CISC
Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary
![Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary](/thumbs/95/124913402.jpg "Cornell University CS 569: Interactive Computer Graphics. Introduction. Lecture 1. [John C. Stone, UIUC] NASA. University of Calgary") Cornell University CS 569: Interactive Computer Graphics Introduction Lecture 1 [John C. Stone, UIUC] 2008 Steve Marschner 1 2008 Steve Marschner 2 NASA University of Calgary 2008 Steve Marschner 3 2008
Cornell University CS 569: Interactive Computer Graphics Introduction Lecture 1 [John C. Stone, UIUC] 2008 Steve Marschner 1 2008 Steve Marschner 2 NASA University of Calgary 2008 Steve Marschner 3 2008
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
GPU Architecture. Michael Doggett Department of Computer Science Lund university
 GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
Real-Time Graphics Architecture
 Real-Time Graphics Architecture Lecture 4: Parallelism and Communication Kurt Akeley Pat Hanrahan http://graphics.stanford.edu/cs448-07-spring/ Topics 1. Frame buffers 2. Types of parallelism 3. Communication
Real-Time Graphics Architecture Lecture 4: Parallelism and Communication Kurt Akeley Pat Hanrahan http://graphics.stanford.edu/cs448-07-spring/ Topics 1. Frame buffers 2. Types of parallelism 3. Communication
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
GPU Architecture and Function. Michael Foster and Ian Frasch
 GPU Architecture and Function Michael Foster and Ian Frasch Overview What is a GPU? How is a GPU different from a CPU? The graphics pipeline History of the GPU GPU architecture Optimizations GPU performance
GPU Architecture and Function Michael Foster and Ian Frasch Overview What is a GPU? How is a GPU different from a CPU? The graphics pipeline History of the GPU GPU architecture Optimizations GPU performance
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Graphics Architectures and OpenCL. Michael Doggett Department of Computer Science Lund university
 Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Specific applications Video game, virtual reality, training programs, Human-robot-interaction, human-computerinteraction.
 Volume 4, Issue 4, April 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Parallel Processing
Volume 4, Issue 4, April 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Parallel Processing
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
Lecture 7: The Programmable GPU Core. Kayvon Fatahalian CMU : Graphics and Imaging Architectures (Fall 2011)
") Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
X. GPU Programming. Jacobs University Visualization and Computer Graphics Lab : Advanced Graphics - Chapter X 1
 X. GPU Programming 320491: Advanced Graphics - Chapter X 1 X.1 GPU Architecture 320491: Advanced Graphics - Chapter X 2 GPU Graphics Processing Unit Parallelized SIMD Architecture 112 processing cores
X. GPU Programming 320491: Advanced Graphics - Chapter X 1 X.1 GPU Architecture 320491: Advanced Graphics - Chapter X 2 GPU Graphics Processing Unit Parallelized SIMD Architecture 112 processing cores
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
GPU-Based Volume Rendering of. Unstructured Grids. João L. D. Comba. Fábio F. Bernardon UFRGS
 GPU-Based Volume Rendering of João L. D. Comba Cláudio T. Silva Steven P. Callahan Unstructured Grids UFRGS University of Utah University of Utah Fábio F. Bernardon UFRGS Natal - RN - Brazil XVIII Brazilian
GPU-Based Volume Rendering of João L. D. Comba Cláudio T. Silva Steven P. Callahan Unstructured Grids UFRGS University of Utah University of Utah Fábio F. Bernardon UFRGS Natal - RN - Brazil XVIII Brazilian
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
GPU Programming and Architecture: Course Overview
 Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Monday and Wednesday 9-10:30am Moore 212 Lectures will be recorded Image from http://pinoytutorial.com/techtorial/geforce-gtx-580-vs-amd-radeon-hd-6870-review-and-comparison-conclusion/
Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Monday and Wednesday 9-10:30am Moore 212 Lectures will be recorded Image from http://pinoytutorial.com/techtorial/geforce-gtx-580-vs-amd-radeon-hd-6870-review-and-comparison-conclusion/
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Standard Graphics Pipeline
 Graphics Architecture Software implementations of rendering are slow. OpenGL on Sparc workstations. Performance can be improved using sophisticated algorithms and faster machines. Real-time large-scale
Graphics Architecture Software implementations of rendering are slow. OpenGL on Sparc workstations. Performance can be improved using sophisticated algorithms and faster machines. Real-time large-scale
GPU! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017!
 Advanced Topics on Heterogeneous System Architectures GPU! Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Introduction!
Advanced Topics on Heterogeneous System Architectures GPU! Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Introduction!
Chapter 7. Multicores, Multiprocessors, and Clusters
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
NVIDIA Fermi Architecture
 Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Vector Processing. Computer Organization Architectures for Embedded Computing. Friday, 13 December 13
 Vector Processing Computer Organization Architectures for Embedded Computing Friday, 13 December 13 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Vector Processing Computer Organization Architectures for Embedded Computing Friday, 13 December 13 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
GPGPU. Peter Laurens 1st-year PhD Student, NSC
 GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
Lecture 1: Introduction and Basics
 CS 515 Programming Language and Compilers I Lecture 1: Introduction and Basics Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/5/2017 Class Information Instructor: Zheng (Eddy) Zhang Email: eddyzhengzhang@gmailcom
CS 515 Programming Language and Compilers I Lecture 1: Introduction and Basics Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/5/2017 Class Information Instructor: Zheng (Eddy) Zhang Email: eddyzhengzhang@gmailcom
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
CSCI-GA Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs
: Architecture and Programming Lecture 2: Hardware Perspective of GPUs") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
Real - Time Rendering. Graphics pipeline. Michal Červeňanský Juraj Starinský
 Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Graphics Processing Unit Architecture (GPU Arch)
") Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Graphics Processing Unit Architecture (GPU Arch) With a focus on NVIDIA GeForce 6800 GPU 1 What is a GPU From Wikipedia : A specialized processor efficient at manipulating and displaying computer graphics
Bifurcation Between CPU and GPU CPUs General purpose, serial GPUs Special purpose, parallel CPUs are becoming more parallel Dual and quad cores, roadm
 XMT-GPU A PRAM Architecture for Graphics Computation Tom DuBois, Bryant Lee, Yi Wang, Marc Olano and Uzi Vishkin Bifurcation Between CPU and GPU CPUs General purpose, serial GPUs Special purpose, parallel
XMT-GPU A PRAM Architecture for Graphics Computation Tom DuBois, Bryant Lee, Yi Wang, Marc Olano and Uzi Vishkin Bifurcation Between CPU and GPU CPUs General purpose, serial GPUs Special purpose, parallel
Graphics Processor Acceleration and YOU
 Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Introduction to Modern GPU Hardware
 The following content are extracted from the material in the references on last page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This
The following content are extracted from the material in the references on last page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
General Purpose Computing on Graphical Processing Units (GPGPU(
 General Purpose Computing on Graphical Processing Units (GPGPU( / GPGP /GP 2 ) By Simon J.K. Pedersen Aalborg University, Oct 2008 VGIS, Readings Course Presentation no. 7 Presentation Outline Part 1:
General Purpose Computing on Graphical Processing Units (GPGPU( / GPGP /GP 2 ) By Simon J.K. Pedersen Aalborg University, Oct 2008 VGIS, Readings Course Presentation no. 7 Presentation Outline Part 1:
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
EE 4702 GPU Programming
 fr 1 Final Exam Review When / Where EE 4702 GPU Programming fr 1 Tuesday, 4 December 2018, 12:30-14:30 (12:30 PM - 2:30 PM) CST Room 226 Tureaud Hall (Here) Conditions Closed Book, Closed Notes Bring one
fr 1 Final Exam Review When / Where EE 4702 GPU Programming fr 1 Tuesday, 4 December 2018, 12:30-14:30 (12:30 PM - 2:30 PM) CST Room 226 Tureaud Hall (Here) Conditions Closed Book, Closed Notes Bring one
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
CMSC 611: Advanced. Parallel Systems
 CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
3D Computer Games Technology and History. Markus Hadwiger VRVis Research Center
 3D Computer Games Technology and History VRVis Research Center Lecture Outline Overview of the last ten years A look at seminal 3D computer games Most important techniques employed Graphics research and
3D Computer Games Technology and History VRVis Research Center Lecture Outline Overview of the last ten years A look at seminal 3D computer games Most important techniques employed Graphics research and
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Administrivia. Administrivia. Administrivia. CIS 565: GPU Programming and Architecture. Meeting
 CIS 565: GPU Programming and Architecture Original Slides by: Suresh Venkatasubramanian Updates by Joseph Kider and Patrick Cozzi Meeting Monday and Wednesday 6:00 7:30pm Moore 212 Recorded lectures upon
CIS 565: GPU Programming and Architecture Original Slides by: Suresh Venkatasubramanian Updates by Joseph Kider and Patrick Cozzi Meeting Monday and Wednesday 6:00 7:30pm Moore 212 Recorded lectures upon
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation