One-Shot Learning with a Hierarchical Nonparametric Bayesian Model
|
|
|
- Rosamund Robertson
- 5 years ago
- Views:
Transcription
1 One-Shot Learning with a Hierarchical Nonparametric Bayesian Model R. Salakhutdinov, J. Tenenbaum and A. Torralba MIT Technical Report, 2010 Presented by Esther Salazar Duke University June 10, 2011 E. Salazar (Reading group) June 10, / 13
2 Summary Contribution: The authors develop a hierarchical nonparametric Bayesian model for learning a novel category based on a single training example. The mode discovers how to group categories into meaningful super-categories that express different priors for new classes. Given a single example of a novel category, the model is able to quickly infer which super-category the new basic-level category should belong to.
3 Motivation Categorizing an object requires information about the category s mean and variance in an appropriate feature space Similarity-based approach: - the mean represents the category prototype - the inverse variances (precisions) correspond to the dimensional weights in a category-specific similarity metric In this context, a one-shot learning is not possible because a single example can provide information about the mean but not about the variances (or similarity metric) Proposal: The proposed model leverages higher-order knowledge abstracted from previously learned categories to estimate the new category s prototype (mean) as well as an appropriate similarity metric (variance) from just one single example or more E. Salazar (Reading group) June 10, / 13
4 Hierarchical Bayesian model Consider observing a set of N input features {x 1,..., x n }, x n R D Features derived from high-dimensional data such images, (e.g. D = 50, 000). Assumption: fixed two-level category hierarchy. Suppose that N objects are partitioned into C basic-level (level-1) categories. That partition is represented by a vector z b = (z b 1,..., zb N ) such that zb n {1,..., C} The C basic-level categories are partitioned into K super-categories (level-2) represented by z s = (z s 1,..., zs C ) such that zs c {1,..., K} E. Salazar (Reading group) June 10, / 13
5 For any basic-level category c, the distribution over the observed feature vectors is D P (x n zn b = c, θ1 ) = N (x n d µc d, 1/τ d c ) (1) d=1 where θ 1 = {µ c, τ c } C c=1 denotes the level-1 category parameters Let k = zc, s the level-1 category c belong to level-2 category k and θ 2 = {µ k, τ k, α k } K k=1 the level-2 parameters D P (µ c, τ c θ 2, z s ) = P (µ c d, τ d c θ2, z s ) d=1 P (µ c d, τ c d θ2 ) = P (µ c d τ c d, θ2 )P (τ c d θ2 ) (2) = N (µ c d µk d, 1/(ντ c d ))Γ(τ c d αk d, αk d /τ k d )
6 P (µ c d, τ c d θ2 ) = P (µ c d τ c d, θ2 )P (τ c d θ2 ) = N (µ c d µk d, 1/(ντ c d ))Γ(τ c d αk d, αk d /τ k d ) It can be easily derived that E[µ c ] = µ k, E[τ c ] = τ k That means: the expected values of the basic level-1 parameters θ 1 are given by the corresponding level-2 parameters θ 2 The parameters α k controls the variability of τ c around its mean For the level-2 parameters θ 2 they assume: E. Salazar (Reading group) June 10, / 13
7 Modeling the number of super-categories The model is presented with a two-level partition z = {z s, z b } that assumes a fixed hierarchy for sharing parameters Aim: To infer the distribution over the possible categories z Proposal: The authors place a nonparametric two-level nested Chinese Restaurant Prior (ncrp) (Blei et al. 2003, 2010) over z The ncrp(γ) extends CRP to nested sequence of partitions, one for each level of the tree (prior: γ Γ(1, 1)) In this case, each observation n is first assigned to the super category z s n using Eq. 4 Its assignment to the basic-level category z b n (under a super category z s n) is again recursively drawn from Eq. 4 Full generative model in Fig. 1 right panel E. Salazar (Reading group) June 10, / 13
8 Inference Sampling level-1 parameters: Given θ 2 and z the conditional distribution P (µ c, τ c θ 2, z, x) is Normal-Gamma also Sampling level-2 parameters: Given z and θ 1 the conditional distributions over the mean µ k and precision τ k take Gaussian and Inverse-Gamma forms. Also, for α k Sampling assignments z: Given model parameters θ = {θ 1, θ 2 }, combining the likelihood term with the ncrp(γ) prior, the posterior over the assignment z n can be calculated as follows: E. Salazar (Reading group) June 10, / 13
9 One-shot learning Consider observing a single new instance x of a novel category c Conditioned on the level-2 parameters θ 2 and the tree structure z. - Compute the posterior distribution over the assignments z c using Eq. 5 (which super-category the novel category belong to) - The new category can either be placed under one of the existing super-categories or create its own super-category Given an inferred assignment z c and using Eq. 2, we can infer the posterior mean and precisions terms {µ, τ } for the novel category Also, the conditional probability that a new test input x t belongs to a novel category c is: E. Salazar (Reading group) June 10, / 13
10 Experimental results The authors present experimental results on the MNIST handwritten digit and MSR Cambridge object recognition image datasets. The proposed model was compared with four base-line models Euclidean: use Euclidean metric, i.e. all precision terms are set to one and are never updated HB-Flat: always uses a single super-category HB-Var: is based on clustering only covariance matrices without taking into account the means of the super-categories MLE: ignores hierarchical Bayes altogether and estimates a category-specific mean and precision from sample averages Oracle: model that always uses the correct, instead of inferred, similarity metric E. Salazar (Reading group) June 10, / 13
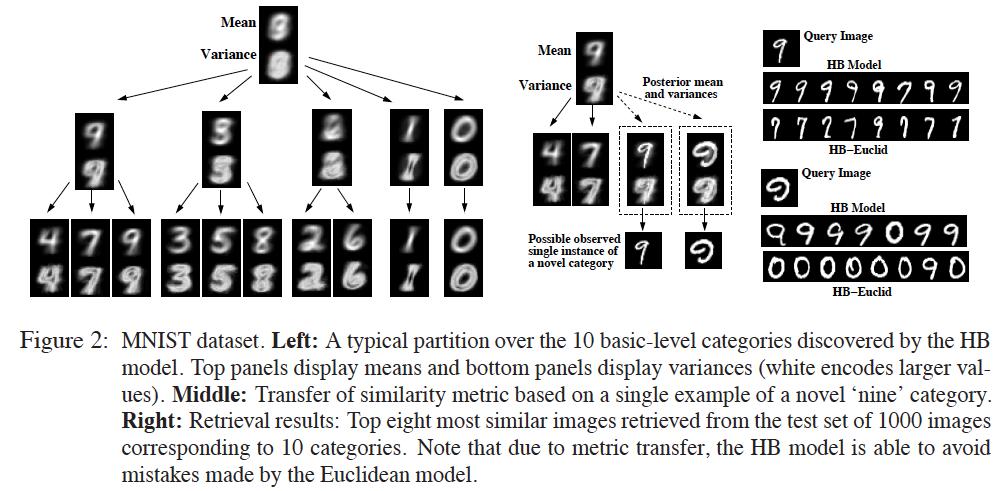
11
12 MSR Cambridge Dataset The Cambridge Dataset contains images of 24 different categories The figure shows 24 basic-level categories along with a typical partition that the model discovers, where many super-categories contain semantically similar basic-level categories E. Salazar (Reading group) June 10, / 13

13
Scalable Bayes Clustering for Outlier Detection Under Informative Sampling
 Scalable Bayes Clustering for Outlier Detection Under Informative Sampling Based on JMLR paper of T. D. Savitsky Terrance D. Savitsky Office of Survey Methods Research FCSM - 2018 March 7-9, 2018 1 / 21
Scalable Bayes Clustering for Outlier Detection Under Informative Sampling Based on JMLR paper of T. D. Savitsky Terrance D. Savitsky Office of Survey Methods Research FCSM - 2018 March 7-9, 2018 1 / 21
An Efficient Model Selection for Gaussian Mixture Model in a Bayesian Framework
 IEEE SIGNAL PROCESSING LETTERS, VOL. XX, NO. XX, XXX 23 An Efficient Model Selection for Gaussian Mixture Model in a Bayesian Framework Ji Won Yoon arxiv:37.99v [cs.lg] 3 Jul 23 Abstract In order to cluster
IEEE SIGNAL PROCESSING LETTERS, VOL. XX, NO. XX, XXX 23 An Efficient Model Selection for Gaussian Mixture Model in a Bayesian Framework Ji Won Yoon arxiv:37.99v [cs.lg] 3 Jul 23 Abstract In order to cluster
Machine Learning A W 1sst KU. b) [1 P] Give an example for a probability distributions P (A, B, C) that disproves
![Machine Learning A W 1sst KU. b) [1 P] Give an example for a probability distributions P (A, B, C) that disproves](/thumbs/93/111796408.jpg "Machine Learning A W 1sst KU. b) [1 P] Give an example for a probability distributions P (A, B, C) that disproves") Machine Learning A 708.064 11W 1sst KU Exercises Problems marked with * are optional. 1 Conditional Independence I [2 P] a) [1 P] Give an example for a probability distribution P (A, B, C) that disproves
Machine Learning A 708.064 11W 1sst KU Exercises Problems marked with * are optional. 1 Conditional Independence I [2 P] a) [1 P] Give an example for a probability distribution P (A, B, C) that disproves
ALTERNATIVE METHODS FOR CLUSTERING
 ALTERNATIVE METHODS FOR CLUSTERING K-Means Algorithm Termination conditions Several possibilities, e.g., A fixed number of iterations Objects partition unchanged Centroid positions don t change Convergence
ALTERNATIVE METHODS FOR CLUSTERING K-Means Algorithm Termination conditions Several possibilities, e.g., A fixed number of iterations Objects partition unchanged Centroid positions don t change Convergence
COMS 4771 Clustering. Nakul Verma
 COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
Hierarchical Multiclass Object Classification
 Hierarchical Multiclass Object Classification Fereshte Khani Massachusetts Institute of Technology fereshte@mit.edu Anurag Mukkara Massachusetts Institute of Technology anurag m@mit.edu Abstract Humans
Hierarchical Multiclass Object Classification Fereshte Khani Massachusetts Institute of Technology fereshte@mit.edu Anurag Mukkara Massachusetts Institute of Technology anurag m@mit.edu Abstract Humans
Randomized Algorithms for Fast Bayesian Hierarchical Clustering
 Randomized Algorithms for Fast Bayesian Hierarchical Clustering Katherine A. Heller and Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College ondon, ondon, WC1N 3AR, UK {heller,zoubin}@gatsby.ucl.ac.uk
Randomized Algorithms for Fast Bayesian Hierarchical Clustering Katherine A. Heller and Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College ondon, ondon, WC1N 3AR, UK {heller,zoubin}@gatsby.ucl.ac.uk
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
08 An Introduction to Dense Continuous Robotic Mapping
 NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
NAVARCH/EECS 568, ROB 530 - Winter 2018 08 An Introduction to Dense Continuous Robotic Mapping Maani Ghaffari March 14, 2018 Previously: Occupancy Grid Maps Pose SLAM graph and its associated dense occupancy
K-means and Hierarchical Clustering
 K-means and Hierarchical Clustering Xiaohui Xie University of California, Irvine K-means and Hierarchical Clustering p.1/18 Clustering Given n data points X = {x 1, x 2,, x n }. Clustering is the partitioning
K-means and Hierarchical Clustering Xiaohui Xie University of California, Irvine K-means and Hierarchical Clustering p.1/18 Clustering Given n data points X = {x 1, x 2,, x n }. Clustering is the partitioning
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Inference and Representation
 Inference and Representation Rachel Hodos New York University Lecture 5, October 6, 2015 Rachel Hodos Lecture 5: Inference and Representation Today: Learning with hidden variables Outline: Unsupervised
Inference and Representation Rachel Hodos New York University Lecture 5, October 6, 2015 Rachel Hodos Lecture 5: Inference and Representation Today: Learning with hidden variables Outline: Unsupervised
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 43 K-Means Clustering Example: Old Faithful Geyser
K-Means and Gaussian Mixture Models David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 43 K-Means Clustering Example: Old Faithful Geyser
Mixture Models and the EM Algorithm
 Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Finite Mixture Models Say we have a data set D = {x 1,..., x N } where x i is
Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Finite Mixture Models Say we have a data set D = {x 1,..., x N } where x i is
Spatial Latent Dirichlet Allocation
 Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Homework. Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression Pod-cast lecture on-line. Next lectures:
 Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Warped Mixture Models
 Warped Mixture Models Tomoharu Iwata, David Duvenaud, Zoubin Ghahramani Cambridge University Computational and Biological Learning Lab March 11, 2013 OUTLINE Motivation Gaussian Process Latent Variable
Warped Mixture Models Tomoharu Iwata, David Duvenaud, Zoubin Ghahramani Cambridge University Computational and Biological Learning Lab March 11, 2013 OUTLINE Motivation Gaussian Process Latent Variable
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Text Document Clustering Using DPM with Concept and Feature Analysis
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 2, Issue. 10, October 2013,
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 2, Issue. 10, October 2013,
Chapter 6 Continued: Partitioning Methods
 Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Chapter 6 Continued: Partitioning Methods Partitioning methods fix the number of clusters k and seek the best possible partition for that k. The goal is to choose the partition which gives the optimal
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Computer Vision. Exercise Session 10 Image Categorization
 Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Deep Generative Models Variational Autoencoders
 Deep Generative Models Variational Autoencoders Sudeshna Sarkar 5 April 2017 Generative Nets Generative models that represent probability distributions over multiple variables in some way. Directed Generative
Deep Generative Models Variational Autoencoders Sudeshna Sarkar 5 April 2017 Generative Nets Generative models that represent probability distributions over multiple variables in some way. Directed Generative
Pattern Recognition ( , RIT) Exercise 1 Solution
 Exercise 1 Solution") Pattern Recognition (4005-759, 20092 RIT) Exercise 1 Solution Instructor: Prof. Richard Zanibbi The following exercises are to help you review for the upcoming midterm examination on Thursday of Week 5
Pattern Recognition (4005-759, 20092 RIT) Exercise 1 Solution Instructor: Prof. Richard Zanibbi The following exercises are to help you review for the upcoming midterm examination on Thursday of Week 5
A Nonparametric Bayesian Approach to Detecting Spatial Activation Patterns in fmri Data
 A Nonparametric Bayesian Approach to Detecting Spatial Activation Patterns in fmri Data Seyoung Kim, Padhraic Smyth, and Hal Stern Bren School of Information and Computer Sciences University of California,
A Nonparametric Bayesian Approach to Detecting Spatial Activation Patterns in fmri Data Seyoung Kim, Padhraic Smyth, and Hal Stern Bren School of Information and Computer Sciences University of California,
Note Set 4: Finite Mixture Models and the EM Algorithm
 Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Global modelling of air pollution using multiple data sources
 Global modelling of air pollution using multiple data sources Matthew Thomas M.L.Thomas@bath.ac.uk Supervised by Dr. Gavin Shaddick In collaboration with IHME and WHO June 14, 2016 1/ 1 MOTIVATION Air
Global modelling of air pollution using multiple data sources Matthew Thomas M.L.Thomas@bath.ac.uk Supervised by Dr. Gavin Shaddick In collaboration with IHME and WHO June 14, 2016 1/ 1 MOTIVATION Air
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques.
 . Non-Parameteric Techniques University of Cambridge Engineering Part IIB Paper 4F: Statistical Pattern Processing Handout : Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 23 Introduction
. Non-Parameteric Techniques University of Cambridge Engineering Part IIB Paper 4F: Statistical Pattern Processing Handout : Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 23 Introduction
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2015 11. Non-Parameteric Techniques
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2015 11. Non-Parameteric Techniques
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Lecture 11: Classification
 Lecture 11: Classification 1 2009-04-28 Patrik Malm Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University 2 Reading instructions Chapters for this lecture 12.1 12.2 in
Lecture 11: Classification 1 2009-04-28 Patrik Malm Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University 2 Reading instructions Chapters for this lecture 12.1 12.2 in
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Learning to Segment Document Images
 Learning to Segment Document Images K.S. Sesh Kumar, Anoop Namboodiri, and C.V. Jawahar Centre for Visual Information Technology, International Institute of Information Technology, Hyderabad, India Abstract.
Learning to Segment Document Images K.S. Sesh Kumar, Anoop Namboodiri, and C.V. Jawahar Centre for Visual Information Technology, International Institute of Information Technology, Hyderabad, India Abstract.
Cluster Analysis. Debashis Ghosh Department of Statistics Penn State University (based on slides from Jia Li, Dept. of Statistics)
") Cluster Analysis Debashis Ghosh Department of Statistics Penn State University (based on slides from Jia Li, Dept. of Statistics) Summer School in Statistics for Astronomers June 1-6, 9 Clustering: Intuition
Cluster Analysis Debashis Ghosh Department of Statistics Penn State University (based on slides from Jia Li, Dept. of Statistics) Summer School in Statistics for Astronomers June 1-6, 9 Clustering: Intuition
Mixture models and clustering
 1 Lecture topics: Miture models and clustering, k-means Distance and clustering Miture models and clustering We have so far used miture models as fleible ays of constructing probability models for prediction
1 Lecture topics: Miture models and clustering, k-means Distance and clustering Miture models and clustering We have so far used miture models as fleible ays of constructing probability models for prediction
Problem 1 (20 pt) Answer the following questions, and provide an explanation for each question.
 Answer the following questions, and provide an explanation for each question.") Problem 1 Answer the following questions, and provide an explanation for each question. (5 pt) Can linear regression work when all X values are the same? When all Y values are the same? (5 pt) Can linear
Problem 1 Answer the following questions, and provide an explanation for each question. (5 pt) Can linear regression work when all X values are the same? When all Y values are the same? (5 pt) Can linear
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Cluster Analysis. Jia Li Department of Statistics Penn State University. Summer School in Statistics for Astronomers IV June 9-14, 2008
 Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
A GENERAL GIBBS SAMPLING ALGORITHM FOR ANALYZING LINEAR MODELS USING THE SAS SYSTEM
 A GENERAL GIBBS SAMPLING ALGORITHM FOR ANALYZING LINEAR MODELS USING THE SAS SYSTEM Jayawant Mandrekar, Daniel J. Sargent, Paul J. Novotny, Jeff A. Sloan Mayo Clinic, Rochester, MN 55905 ABSTRACT A general
A GENERAL GIBBS SAMPLING ALGORITHM FOR ANALYZING LINEAR MODELS USING THE SAS SYSTEM Jayawant Mandrekar, Daniel J. Sargent, Paul J. Novotny, Jeff A. Sloan Mayo Clinic, Rochester, MN 55905 ABSTRACT A general
arxiv: v1 [stat.ap] 1 May 2018
![arxiv: v1 [stat.ap] 1 May 2018](/thumbs/85/91731815.jpg "arxiv: v1 [stat.ap] 1 May 2018") A Discrete View of the Indian Monsoon to Identify Spatial Patterns of Rainfall Adway Mitra 1, Amit Apte 2, Rama Govindarajan 2, Vishal Vasan 2, and Sreekar Vadlamani 3,4 arxiv:1805.00414v1 [stat.ap] 1
A Discrete View of the Indian Monsoon to Identify Spatial Patterns of Rainfall Adway Mitra 1, Amit Apte 2, Rama Govindarajan 2, Vishal Vasan 2, and Sreekar Vadlamani 3,4 arxiv:1805.00414v1 [stat.ap] 1
Clustering Relational Data using the Infinite Relational Model
 Clustering Relational Data using the Infinite Relational Model Ana Daglis Supervised by: Matthew Ludkin September 4, 2015 Ana Daglis Clustering Data using the Infinite Relational Model September 4, 2015
Clustering Relational Data using the Infinite Relational Model Ana Daglis Supervised by: Matthew Ludkin September 4, 2015 Ana Daglis Clustering Data using the Infinite Relational Model September 4, 2015
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class
 Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
GAMs semi-parametric GLMs. Simon Wood Mathematical Sciences, University of Bath, U.K.
 GAMs semi-parametric GLMs Simon Wood Mathematical Sciences, University of Bath, U.K. Generalized linear models, GLM 1. A GLM models a univariate response, y i as g{e(y i )} = X i β where y i Exponential
GAMs semi-parametric GLMs Simon Wood Mathematical Sciences, University of Bath, U.K. Generalized linear models, GLM 1. A GLM models a univariate response, y i as g{e(y i )} = X i β where y i Exponential
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 3 Parametric Distribu>ons We want model the probability
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! h0p://www.cs.toronto.edu/~rsalakhu/ Lecture 3 Parametric Distribu>ons We want model the probability
A Distance-Based Classifier Using Dissimilarity Based on Class Conditional Probability and Within-Class Variation. Kwanyong Lee 1 and Hyeyoung Park 2
 A Distance-Based Classifier Using Dissimilarity Based on Class Conditional Probability and Within-Class Variation Kwanyong Lee 1 and Hyeyoung Park 2 1. Department of Computer Science, Korea National Open
A Distance-Based Classifier Using Dissimilarity Based on Class Conditional Probability and Within-Class Variation Kwanyong Lee 1 and Hyeyoung Park 2 1. Department of Computer Science, Korea National Open
Chapter 4: Non-Parametric Techniques
 Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule Supervised Learning How to fit a density
Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule Supervised Learning How to fit a density
Recursive Similarity-Based Algorithm for Deep Learning
 Recursive Similarity-Based Algorithm for R Tomasz Maszczyk & W lodzis law Duch Nicolaus Copernicus University Toruń, Poland ICONIP 2012 {tmaszczyk,wduch}@is.umk.pl 1 / 21 R Similarity-Based Learning ()
Recursive Similarity-Based Algorithm for R Tomasz Maszczyk & W lodzis law Duch Nicolaus Copernicus University Toruń, Poland ICONIP 2012 {tmaszczyk,wduch}@is.umk.pl 1 / 21 R Similarity-Based Learning ()
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Fisher vector image representation
 Fisher vector image representation Jakob Verbeek January 13, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.11.12.php Fisher vector representation Alternative to bag-of-words image representation
Fisher vector image representation Jakob Verbeek January 13, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.11.12.php Fisher vector representation Alternative to bag-of-words image representation
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Methods for Intelligent Systems
 Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Feature LDA: a Supervised Topic Model for Automatic Detection of Web API Documentations from the Web
 Feature LDA: a Supervised Topic Model for Automatic Detection of Web API Documentations from the Web Chenghua Lin, Yulan He, Carlos Pedrinaci, and John Domingue Knowledge Media Institute, The Open University
Feature LDA: a Supervised Topic Model for Automatic Detection of Web API Documentations from the Web Chenghua Lin, Yulan He, Carlos Pedrinaci, and John Domingue Knowledge Media Institute, The Open University
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Summer School in Statistics for Astronomers & Physicists June 15-17, Cluster Analysis
 Summer School in Statistics for Astronomers & Physicists June 15-17, 2005 Session on Computational Algorithms for Astrostatistics Cluster Analysis Max Buot Department of Statistics Carnegie-Mellon University
Summer School in Statistics for Astronomers & Physicists June 15-17, 2005 Session on Computational Algorithms for Astrostatistics Cluster Analysis Max Buot Department of Statistics Carnegie-Mellon University
Package clusternomics
 Type Package Package clusternomics March 14, 2017 Title Integrative Clustering for Heterogeneous Biomedical Datasets Version 0.1.1 Author Evelina Gabasova Maintainer Evelina Gabasova
Type Package Package clusternomics March 14, 2017 Title Integrative Clustering for Heterogeneous Biomedical Datasets Version 0.1.1 Author Evelina Gabasova Maintainer Evelina Gabasova
Clustering & Dimensionality Reduction. 273A Intro Machine Learning
 Clustering & Dimensionality Reduction 273A Intro Machine Learning What is Unsupervised Learning? In supervised learning we were given attributes & targets (e.g. class labels). In unsupervised learning
Clustering & Dimensionality Reduction 273A Intro Machine Learning What is Unsupervised Learning? In supervised learning we were given attributes & targets (e.g. class labels). In unsupervised learning
International Journal of Scientific Research & Engineering Trends Volume 4, Issue 6, Nov-Dec-2018, ISSN (Online): X
: X") Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Analysis about Classification Techniques on Categorical Data in Data Mining Assistant Professor P. Meena Department of Computer Science Adhiyaman Arts and Science College for Women Uthangarai, Krishnagiri,
Trajectory Analysis and Semantic Region Modeling Using A Nonparametric Bayesian Model
 Trajectory Analysis and Semantic Region Modeling Using A Nonparametric Bayesian Model Xiaogang Wang 1 Keng Teck Ma 2 Gee-Wah Ng 2 W. Eric L. Grimson 1 1 CS and AI Lab, MIT, 77 Massachusetts Ave., Cambridge,
Trajectory Analysis and Semantic Region Modeling Using A Nonparametric Bayesian Model Xiaogang Wang 1 Keng Teck Ma 2 Gee-Wah Ng 2 W. Eric L. Grimson 1 1 CS and AI Lab, MIT, 77 Massachusetts Ave., Cambridge,
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Model-based Clustering With Probabilistic Constraints
 To appear in SIAM data mining Model-based Clustering With Probabilistic Constraints Martin H. C. Law Alexander Topchy Anil K. Jain Abstract The problem of clustering with constraints is receiving increasing
To appear in SIAM data mining Model-based Clustering With Probabilistic Constraints Martin H. C. Law Alexander Topchy Anil K. Jain Abstract The problem of clustering with constraints is receiving increasing
Expectation Maximization (EM) and Gaussian Mixture Models
 and Gaussian Mixture Models") Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Clustering Sequences with Hidden. Markov Models. Padhraic Smyth CA Abstract
 Clustering Sequences with Hidden Markov Models Padhraic Smyth Information and Computer Science University of California, Irvine CA 92697-3425 smyth@ics.uci.edu Abstract This paper discusses a probabilistic
Clustering Sequences with Hidden Markov Models Padhraic Smyth Information and Computer Science University of California, Irvine CA 92697-3425 smyth@ics.uci.edu Abstract This paper discusses a probabilistic
Machine Learning A W 1sst KU. b) [1 P] For the probability distribution P (A, B, C, D) with the factorization
![Machine Learning A W 1sst KU. b) [1 P] For the probability distribution P (A, B, C, D) with the factorization](/thumbs/90/103659720.jpg "Machine Learning A W 1sst KU. b) [1 P] For the probability distribution P (A, B, C, D) with the factorization") Machine Learning A 708.064 13W 1sst KU Exercises Problems marked with * are optional. 1 Conditional Independence a) [1 P] For the probability distribution P (A, B, C, D) with the factorization P (A, B,
Machine Learning A 708.064 13W 1sst KU Exercises Problems marked with * are optional. 1 Conditional Independence a) [1 P] For the probability distribution P (A, B, C, D) with the factorization P (A, B,
CS839: Probabilistic Graphical Models. Lecture 10: Learning with Partially Observed Data. Theo Rekatsinas
 CS839: Probabilistic Graphical Models Lecture 10: Learning with Partially Observed Data Theo Rekatsinas 1 Partially Observed GMs Speech recognition 2 Partially Observed GMs Evolution 3 Partially Observed
CS839: Probabilistic Graphical Models Lecture 10: Learning with Partially Observed Data Theo Rekatsinas 1 Partially Observed GMs Speech recognition 2 Partially Observed GMs Evolution 3 Partially Observed
Today. Lecture 4: Last time. The EM algorithm. We examine clustering in a little more detail; we went over it a somewhat quickly last time
 Today Lecture 4: We examine clustering in a little more detail; we went over it a somewhat quickly last time The CAD data will return and give us an opportunity to work with curves (!) We then examine
Today Lecture 4: We examine clustering in a little more detail; we went over it a somewhat quickly last time The CAD data will return and give us an opportunity to work with curves (!) We then examine
Lecture 21 : A Hybrid: Deep Learning and Graphical Models
 10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
10-708: Probabilistic Graphical Models, Spring 2018 Lecture 21 : A Hybrid: Deep Learning and Graphical Models Lecturer: Kayhan Batmanghelich Scribes: Paul Liang, Anirudha Rayasam 1 Introduction and Motivation
Nonparametric Bayesian Texture Learning and Synthesis
 Appears in Advances in Neural Information Processing Systems (NIPS) 2009. Nonparametric Bayesian Texture Learning and Synthesis Long (Leo) Zhu 1 Yuanhao Chen 2 William Freeman 1 Antonio Torralba 1 1 CSAIL,
Appears in Advances in Neural Information Processing Systems (NIPS) 2009. Nonparametric Bayesian Texture Learning and Synthesis Long (Leo) Zhu 1 Yuanhao Chen 2 William Freeman 1 Antonio Torralba 1 1 CSAIL,
arxiv: v1 [cs.cv] 17 Nov 2016
![arxiv: v1 [cs.cv] 17 Nov 2016](/thumbs/86/93859848.jpg "arxiv: v1 [cs.cv] 17 Nov 2016") Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Image analysis. Computer Vision and Classification Image Segmentation. 7 Image analysis
 7 Computer Vision and Classification 413 / 458 Computer Vision and Classification The k-nearest-neighbor method The k-nearest-neighbor (knn) procedure has been used in data analysis and machine learning
7 Computer Vision and Classification 413 / 458 Computer Vision and Classification The k-nearest-neighbor method The k-nearest-neighbor (knn) procedure has been used in data analysis and machine learning
Convex Optimizations for Distance Metric Learning and Pattern Classification
 Convex Optimizations for Distance Metric Learning and Pattern Classification Kilian Q. Weinberger Department of Computer Science and Engineering Washington University, St. Louis, MO 63130 kilian@seas.wustl.edu
Convex Optimizations for Distance Metric Learning and Pattern Classification Kilian Q. Weinberger Department of Computer Science and Engineering Washington University, St. Louis, MO 63130 kilian@seas.wustl.edu
More Learning. Ensembles Bayes Rule Neural Nets K-means Clustering EM Clustering WEKA
 More Learning Ensembles Bayes Rule Neural Nets K-means Clustering EM Clustering WEKA 1 Ensembles An ensemble is a set of classifiers whose combined results give the final decision. test feature vector
More Learning Ensembles Bayes Rule Neural Nets K-means Clustering EM Clustering WEKA 1 Ensembles An ensemble is a set of classifiers whose combined results give the final decision. test feature vector
arxiv: v2 [cs.lg] 25 Aug 2017
![arxiv: v2 [cs.lg] 25 Aug 2017](/thumbs/85/91922859.jpg "arxiv: v2 [cs.lg] 25 Aug 2017") Nonparametric Variational Auto-encoders for Hierarchical Representation Learning Prasoon Goyal Zhiting Hu,2 Xiaodan Liang Carnegie Mellon University Chenyu Wang2 2 Petuum Inc. Eric P. Xing,2 arxiv:703.07027v2
Nonparametric Variational Auto-encoders for Hierarchical Representation Learning Prasoon Goyal Zhiting Hu,2 Xiaodan Liang Carnegie Mellon University Chenyu Wang2 2 Petuum Inc. Eric P. Xing,2 arxiv:703.07027v2
Multi-Modal Generative Adversarial Networks
 Multi-Modal Generative Adversarial Networks By MATAN BEN-YOSEF Under the supervision of PROF. DAPHNA WEINSHALL Faculty of Computer Science and Engineering THE HEBREW UNIVERSITY OF JERUSALEM A thesis submitted
Multi-Modal Generative Adversarial Networks By MATAN BEN-YOSEF Under the supervision of PROF. DAPHNA WEINSHALL Faculty of Computer Science and Engineering THE HEBREW UNIVERSITY OF JERUSALEM A thesis submitted
Recap: Gaussian (or Normal) Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach
 Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach") Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
10. MLSP intro. (Clustering: K-means, EM, GMM, etc.)
") 10. MLSP intro. (Clustering: K-means, EM, GMM, etc.) Rahil Mahdian 01.04.2016 LSV Lab, Saarland University, Germany What is clustering? Clustering is the classification of objects into different groups,
10. MLSP intro. (Clustering: K-means, EM, GMM, etc.) Rahil Mahdian 01.04.2016 LSV Lab, Saarland University, Germany What is clustering? Clustering is the classification of objects into different groups,
SD 372 Pattern Recognition
 SD 372 Pattern Recognition Lab 2: Model Estimation and Discriminant Functions 1 Purpose This lab examines the areas of statistical model estimation and classifier aggregation. Model estimation will be
SD 372 Pattern Recognition Lab 2: Model Estimation and Discriminant Functions 1 Purpose This lab examines the areas of statistical model estimation and classifier aggregation. Model estimation will be
Expectation Maximization: Inferring model parameters and class labels
 Expectation Maximization: Inferring model parameters and class labels Emily Fox University of Washington February 27, 2017 Mixture of Gaussian recap 1 2/26/17 Jumble of unlabeled images HISTOGRAM blue
Expectation Maximization: Inferring model parameters and class labels Emily Fox University of Washington February 27, 2017 Mixture of Gaussian recap 1 2/26/17 Jumble of unlabeled images HISTOGRAM blue
Additive hedonic regression models for the Austrian housing market ERES Conference, Edinburgh, June
 for the Austrian housing market, June 14 2012 Ao. Univ. Prof. Dr. Fachbereich Stadt- und Regionalforschung Technische Universität Wien Dr. Strategic Risk Management Bank Austria UniCredit, Wien Inhalt
for the Austrian housing market, June 14 2012 Ao. Univ. Prof. Dr. Fachbereich Stadt- und Regionalforschung Technische Universität Wien Dr. Strategic Risk Management Bank Austria UniCredit, Wien Inhalt
Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013
 Your Name: Your student id: Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013 Problem 1 [5+?]: Hypothesis Classes Problem 2 [8]: Losses and Risks Problem 3 [11]: Model Generation
Your Name: Your student id: Solution Sketches Midterm Exam COSC 6342 Machine Learning March 20, 2013 Problem 1 [5+?]: Hypothesis Classes Problem 2 [8]: Losses and Risks Problem 3 [11]: Model Generation
A noninformative Bayesian approach to small area estimation
 A noninformative Bayesian approach to small area estimation Glen Meeden School of Statistics University of Minnesota Minneapolis, MN 55455 glen@stat.umn.edu September 2001 Revised May 2002 Research supported
A noninformative Bayesian approach to small area estimation Glen Meeden School of Statistics University of Minnesota Minneapolis, MN 55455 glen@stat.umn.edu September 2001 Revised May 2002 Research supported
Spatial Outlier Detection
 Spatial Outlier Detection Chang-Tien Lu Department of Computer Science Northern Virginia Center Virginia Tech Joint work with Dechang Chen, Yufeng Kou, Jiang Zhao 1 Spatial Outlier A spatial data point
Spatial Outlier Detection Chang-Tien Lu Department of Computer Science Northern Virginia Center Virginia Tech Joint work with Dechang Chen, Yufeng Kou, Jiang Zhao 1 Spatial Outlier A spatial data point
Sampling Table Configulations for the Hierarchical Poisson-Dirichlet Process
 Sampling Table Configulations for the Hierarchical Poisson-Dirichlet Process Changyou Chen,, Lan Du,, Wray Buntine, ANU College of Engineering and Computer Science The Australian National University National
Sampling Table Configulations for the Hierarchical Poisson-Dirichlet Process Changyou Chen,, Lan Du,, Wray Buntine, ANU College of Engineering and Computer Science The Australian National University National
Clustering. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Clustering Robert M. Haralick Computer Science, Graduate Center City University of New York Outline K-means 1 K-means 2 3 4 5 Clustering K-means The purpose of clustering is to determine the similarity
Mixtures of Gaussians and Advanced Feature Encoding
 Mixtures of Gaussians and Advanced Feature Encoding Computer Vision Ali Borji UWM Many slides from James Hayes, Derek Hoiem, Florent Perronnin, and Hervé Why do good recognition systems go bad? E.g. Why
Mixtures of Gaussians and Advanced Feature Encoding Computer Vision Ali Borji UWM Many slides from James Hayes, Derek Hoiem, Florent Perronnin, and Hervé Why do good recognition systems go bad? E.g. Why
Some questions of consensus building using co-association
 Some questions of consensus building using co-association VITALIY TAYANOV Polish-Japanese High School of Computer Technics Aleja Legionow, 4190, Bytom POLAND vtayanov@yahoo.com Abstract: In this paper
Some questions of consensus building using co-association VITALIY TAYANOV Polish-Japanese High School of Computer Technics Aleja Legionow, 4190, Bytom POLAND vtayanov@yahoo.com Abstract: In this paper
Bayesian Spherical Wavelet Shrinkage: Applications to Shape Analysis
 Bayesian Spherical Wavelet Shrinkage: Applications to Shape Analysis Xavier Le Faucheur a, Brani Vidakovic b and Allen Tannenbaum a a School of Electrical and Computer Engineering, b Department of Biomedical
Bayesian Spherical Wavelet Shrinkage: Applications to Shape Analysis Xavier Le Faucheur a, Brani Vidakovic b and Allen Tannenbaum a a School of Electrical and Computer Engineering, b Department of Biomedical
9.1. K-means Clustering
 424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Automatic Tracking of Moving Objects in Video for Surveillance Applications
 Automatic Tracking of Moving Objects in Video for Surveillance Applications Manjunath Narayana Committee: Dr. Donna Haverkamp (Chair) Dr. Arvin Agah Dr. James Miller Department of Electrical Engineering
Automatic Tracking of Moving Objects in Video for Surveillance Applications Manjunath Narayana Committee: Dr. Donna Haverkamp (Chair) Dr. Arvin Agah Dr. James Miller Department of Electrical Engineering
Fuzzy Segmentation. Chapter Introduction. 4.2 Unsupervised Clustering.
 Chapter 4 Fuzzy Segmentation 4. Introduction. The segmentation of objects whose color-composition is not common represents a difficult task, due to the illumination and the appropriate threshold selection
Chapter 4 Fuzzy Segmentation 4. Introduction. The segmentation of objects whose color-composition is not common represents a difficult task, due to the illumination and the appropriate threshold selection
Probabilistic multi-resolution scanning for cross-sample differences
 Probabilistic multi-resolution scanning for cross-sample differences Li Ma (joint work with Jacopo Soriano) Duke University 10th Conference on Bayesian Nonparametrics Li Ma (Duke) Multi-resolution scanning
Probabilistic multi-resolution scanning for cross-sample differences Li Ma (joint work with Jacopo Soriano) Duke University 10th Conference on Bayesian Nonparametrics Li Ma (Duke) Multi-resolution scanning
Accelerating the Relevance Vector Machine via Data Partitioning
 Accelerating the Relevance Vector Machine via Data Partitioning David Ben-Shimon and Armin Shmilovici Department of Information Systems Engineering, Ben-Gurion University, P.O.Box 653 8405 Beer-Sheva,
Accelerating the Relevance Vector Machine via Data Partitioning David Ben-Shimon and Armin Shmilovici Department of Information Systems Engineering, Ben-Gurion University, P.O.Box 653 8405 Beer-Sheva,