Chapter 4: Non-Parametric Techniques
|
|
|
- Maurice Blankenship
- 6 years ago
- Views:
Transcription
1 Chapter 4: Non-Parametric Techniques Introduction Density Estimation Parzen Windows Kn-Nearest Neighbor Density Estimation K-Nearest Neighbor (KNN) Decision Rule
2 Supervised Learning
3 How to fit a density function to 1-D data? * * * * * * * * * ** * * * * * * * * ** * ** * * * ** *
4 Fitting a Normal density using MLE


5 20 bins 15 bins 10 bins How many bins? 5 bins
6 Parzen Windows Width = 1.25 Width = 2.5
7 Parzen Windows Width = 5 Width = 10
8 Gaussian Mixture Model A weighted combination of a small but unknown no. of Gaussians Can one recover the parameters of Gaussians from unlabeled data?
9 Introduction 8 All parametric densities are unimodal (have a single local maximum), whereas many practical problems involve multi-modal densities (subgroups) Nonparametric procedures can be used with arbitrary distributions and without the assumption that the form of the underlying densities is known Two types of nonparametric methods: Estimating class conditional densities, P(x w j ) Bypass class-conditional density estimation and directly estimate the a-posteriori probability Pattern Classification, Ch4 (Part 1)
10 Density Estimation 9 Basic idea: Probability that a vector x will fall in region R is: P = p( x' )dx' (1) ò Â P is a smoothed (or averaged) version of the density function p(x). How do we estimate P? If we have a sample of size n (i.i.d from p(x)), the probability that k of the n points fall in R is (binomial law): P k æ nö = ç P è k ø k ( 1 - P ) n-k (2) and the expected value for k is: E(k) = np (3) Pattern Classification, Ch4 (Part 1)
 Assume p(x) is continuous and region R is so small that p does not vary significantly within it.")
11 ML estimation of unknown P = q 10 Max( P k q ) is achieved when q ˆ q = k P Ratio k/n is a good estimate for the probability P and can be used to estimate density fn. p (x) Assume p(x) is continuous and region R is so small that p does not vary significantly within it. Then ò Â p( x' x )V where x is a point in R and V the volume enclosed by R p( (4)
12 Combining equations (1), (3) and (4) yields: 11 p ( x k / V n Pattern Classification, Ch4 (Part 1)
 (if fixed) This is the case where no samples are included in R = 0 n = lim V 0, k¹ 0 p( x ) = In this case, the estimate diverges Pattern")
13 Conditions for convergence 12 The fraction k/(nv) is a space averaged value of p(x). Convergence to true p(x) is obtained only if V approaches zero. lim V 0, k= 0 p( x ) (if fixed) This is the case where no samples are included in R = 0 n = lim V 0, k¹ 0 p( x ) = In this case, the estimate diverges Pattern Classification, Ch4 (Part 1)
14 The volume V needs to approach 0 if we want to obtain p(x) rather than just an averaged version of it. 13 In practice, V cannot be allowed to become small since the number of samples, n, is always limited We have to accept a certain amount of averaging in p(x) Theoretically, if an unlimited number of samples is available, we can circumvent this difficulty as follows: To estimate the density of x, we form a sequence of regions R 1, R 2, containing x: the first region contains one sample, the second two samples and so on. Let V n be the volume of R n, k n be the number of samples falling in R n and p n (x) be the n th estimate for p(x): p n (x) = (k n /n)/v n (7) Pattern Classification, Ch4 (Part 1)
15 Necessary conditions for p n (x) to converge to p(x): 14 1 ) limv n 2 ) lim k n 3 ) lim k n n n n = 0 = / n = 0 Two ways of defining sequences of regions that satisfy these conditions: (a) Shrink an initial region where V n = 1/Ön ; it can be shown that p n ( x ) n p( x ) This is called the Parzen-window estimation method (b) Specify k n as some function of n, such as k n = Ön; the volume V n is grown until it encloses k n neighbors of x. This is called the k n -nearest neighbor estimation method Pattern Classification, Ch4 (Part 1)

16 15 Pattern Classification, Ch4 (Part 1)
17 Parzen Windows 16 For simplicity, let us assume that the region R n is a d- dimensional hypercube V n = h d n (h Let j(u)be the ì ï1 j(u) = í ï î0 n : length of following window 1 u j j 2 otherwise the edge of = 1,...,d  n ) function : j((x-x i )/h n ) is equal to unity if x i falls within the hypercube of volume V n centered at x and equal to zero otherwise. Pattern Classification, Ch4 (Part 1)
18 The number of samples in this hypercube is: 17 k n = i = n å i= 1 æ x - j ç è h n x i ö ø By substituting k n in equation (7), we obtain the following estimate: p n (x) i = n 1 1 æ x - x = å jç n i= 1 Vn è hn i ö ø P n (x) estimates p(x) as an average of functions of x and the samples x i, i = 1,,n. These functions j can be of any form, e.g., Gaussian. Pattern Classification, Ch4 (Part 1)
19 18 The behavior of the Parzen-window method Case where p(x) àn(0,1) Let j(u) = (1/Ö(2p) exp(-u 2 /2) and h n = h 1 /Ön (n>1) Thus: (h 1 : known parameter) p n ( x ) i = n 1 1 æ x - x = å j ç n i= 1 hn è hn i ö ø is an average of normal densities centered at the samples x i. Pattern Classification, Ch4 (Part 1)

20 Parzen Window Density Estimate
21 20 Numerical results: For n = 1 and h 1 =1 1-1 / 2 2 p1 ( x ) = j( x - x1 ) = e ( x - x1 ) N( x1 2p,1 ) For n = 10 and h = 0.1, the contributions of the individual samples are clearly observable! Pattern Classification, Ch4 (Part 1)
22 21 Pattern Classification, Ch4 (Part 1)
23 22 Pattern Classification, Ch4 (Part 1)

24 Analogous results are also obtained in two dimensions: 23 Pattern Classification, Ch4 (Part 1)

25 24 Pattern Classification, Ch4 (Part 1)
 is a mixture of a uniform and a triangle density 25 Pattern")
26 Unknown density p(x) = l 1.U(a,b) + l 2.T(c,d) is a mixture of a uniform and a triangle density 25 Pattern Classification, Ch4 (Part 1)
27 26 Pattern Classification, Ch4 (Part 1)

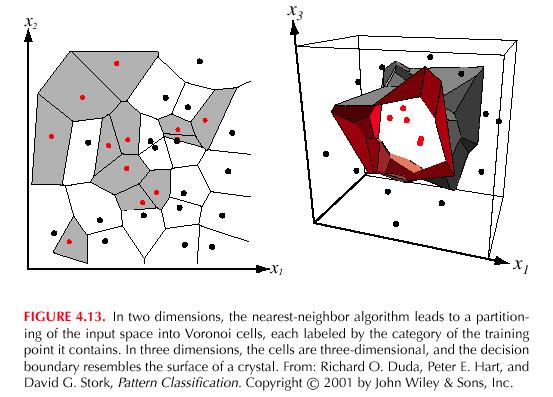
28 Parzen-window density estimates
29 28 Classification example How do we design classifiers based on Parzen-window density estimation? Estimate the class-conditional densities for each class; classify a test sample by the label corresponding to the maximum a posteriori density Decision region for a Parzen-window classifier depends upon the choice of window function and the window width; in practice window function chosen is Gaussian Pattern Classification, Ch4 (Part 1)

30 29 Pattern Classification, Ch4 (Part 1)
31 K n - Nearest Neighbor Density Estimation 30 Let the region volume be a function of the training data Center a region about x and let it grows until it captures k n samples (k n = f(n)) k n denotes the k n nearest-neighbors of x Two possibilities can occur: If the true density is high near x, the region will be small which provides a good resolution If the true density at x is low, the region will grow large to capture k n samples We can obtain a family of estimates by setting k n =k 1 /Ön and choosing different values for k 1
32

33 32 Illustration For k n = Ön = 1 ; the estimate becomes: P n (x) = k n / n.v n = 1 / V 1 =1 / 2 x-x 1 Pattern Classification, Chapter 4 (Part 2)
34 33 Pattern Classification, Chapter 4 (Part 2)
35 34 Pattern Classification, Chapter 4 (Part 2)
36 35 Estimation of a-posteriori probabilities Goal: estimate P(w i x) from a set of n labeled samples Place a cell of volume V around x and capture k samples Suppose k i samples amongst k are labeled w i then: p n (x, w i ) = k i /n.v An estimate for p n (w i x) is: pn( x, wi ) pn ( wi x ) = = j c p ( x, w ) = å j= 1 n j ki k
37 36 k i /k is the fraction of the samples within the cell that are labeled w i For minimum error rate, the most frequently represented category within the cell is selected If k is large and the cell is sufficiently small, the performance will approach the optimal Bayes rule Pattern Classification, Chapter 4 (Part 2)
38 Nearest neighbor Decision Rule 37 Let D n = {x 1, x 2,, x n } be a set of n labeled prototypes Let x Î D n be the closest prototype to a test point x then the nearest-neighbor rule for classifying x is to assign it the label associated with x The nearest-neighbor rule leads to an error rate greater than the minimum possible, namely the Bayes error rate If the number of prototypes is large (unlimited), the error rate of the nearest-neighbor classifier is never worse than twice the Bayes rate (it can be proved!) Pattern Classification, Chapter 4 (Part 2)
39 38
40 Bound on the Nearest Neighbor Error Rate
41 k Nearest Neighbor (k-nn) Decision Rule 40 Classify the test sample x by assigning it the label most frequently represented among the k nearest samples of x Pattern Classification, Chapter 4 (Part 2)
42 41 Pattern Classification, Chapter 4 (Part 2)
43 The k-nearest Neighbor Rule The bounds on k-nn error rate for different values of k. As k increases, the upper bounds get progressively closer to the lower bound the Bayes Error rate. When k goes to infinity, the two bounds meet and k-nn rule becomes optimal.
 is a function that takes two vectors a and b as arguments,")
44 Metric Nearest neighbor rule relies on a metric or a distance function between the patterns A metric D(.,.) is a function that takes two vectors a and b as arguments, and returns a scalar function. For a function D(.,.) to be called a metric, it needs to satisfy the following properties for any given vectors a, b and c.
45 Metrics and Nearest-neighbors A metric remains a metric even when each dimension is scaled (in fact, under any positive definite linear transformation). Left plot shows a scenario where the black point is closer to x. Scaling the x 1 axis by 1/3, however, brings the red point closer to x than the black point.
46 Minkowski metric Example Metrics K = 1 gives the Manhattan distance K = 2 gives the Euclidean distance K = µ gives the max-distance (maximum value of the absolute differences between the elements of the two vectors) Tanimoto metric: used for finding distance between sets

47 Computational Complexity of K-NN Rule 46 Complexity both in terms of time (search) and space (storage of prototypes) has received a lot of attention Suppose we are given n labeled samples in d dimensions and we seek the sample closest to a test point x. Naïve approach would require calculating the distance of x to each stored point and then find the closest. Three general algorithmic techniques for reducing the computational burden computing partial distances Pre-structuring editing the stored prototypes Pattern Classification, Chapter 4 (Part 2)
48 Nearest-Neighbor Editing For each given test point, k-nn has to make N distance computations, followed by selection of k-closest neighbors. Imagine a billion web-pages, or a million images. Different ways to reduce search complexity Pre-structuring the data. (Eg. Divide 2D data uniformly distributed in [-1 1] 2 into quadrants and compare the given example to points only in that quadrant) Build search trees Nearest neighbor editing Nearest-neighbor editing eliminates useless prototypes Eliminate prototypes that are surrounded by training examples of the same category label Leaves the decision boundaries intact
49 Nearest neighbor editing: Algorithm The complexity of this algorithm is O(d 3 n [d/2] ln n), where [d/2] is the floor of d/2.
50 A Branch and Bound Algorithm for Computing k-nearest Neighbors K. Fukunga & P. Narendra, IEEE Trans. Computers, July 1975
51 KNN K-NN generally requires large number of computations for large n (number of training samples) Several solutions to reduce complexity Hart s method: condense the training dataset size while retaining most of the samples that provide sufficient discriminatory information between classes Fischer and Patrick: re-order the examples such that many distance computations can be eliminated Fukunaga and Narendra: hierarchically decompose the design samples into disjoint subsets and apply a branch-and-bound algorithm for searching through the hierarchy.
52 Stage 1: Hierarchical Decomposition Given a dataset of n samples, divide it into l groups, and recursively divide each of the l-groups further into l-groups each. Partitioning must be done such that similar samples are placed in the same group. K-means algorithm is used to divide the dataset, since it scales well to large datasets.
53 Searching the Tree For each node in the tree, evaluate the following quantities S p N p M p Set of samples associated with node p Number of samples at node p Sample mean of samples at node p r p Farthest distance from mean M p Use two rules for eliminating examples for nearest neighbor computation.
54 Rule 1 Rule 1: No sample x i in S p can be nearest neighbor to test point x if where B is the distance to the current nearest neighbor. Proof: For any point x i in S p if test point x is in the same node, by triangle inequality, we have Since d(x i,m p ) < r p by definition, Therefore x i cannot be nearest neighbor to x if
55 Rule 2 Rule 2: A sample x i in S p cannot be a nearest neighbor to x if Proof: On similar lines as the previous proof using triangle inequality. This rule is applied only on the leaf nodes. The distances d(x i,m p ) are computed for all the points in the leaf nodes; only requires additional storage of n real numbers.
56 Branch and Bound Search Algorithm 1. Set B =. Current level L = 1, and Node = Expansion: Place all nodes that are immediate successors of current node in the active set of nodes. 3. For each node, test Rule 1. Remove nodes that fail. 4. Pick the closest node to the test point x and expand using step 2. If you are at the final level, go to step Apply Rule 2 to all the points in the last node. 1. For all the points that fail, do not compute the distance to x. 2. For points that succeed, compute the distances. 6. Pick the closest point using the computed distances.
57 Extension to k-nearest Neighbors The same algorithm may be applied with B representing the distance to the k-th closest point in the dataset. When a distance is actually calculated in Step 5, it is compared against distances to its current k-nearest neighbors, and the current k-nearest neighbor table is updated as necessary.
Non-Parametric Modeling
 Non-Parametric Modeling CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Non-Parametric Density Estimation Parzen Windows Kn-Nearest Neighbor
Non-Parametric Modeling CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Non-Parametric Density Estimation Parzen Windows Kn-Nearest Neighbor
Instance-based Learning CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2015
 Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
Instance-based Learning CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2015 Outline Non-parametric approach Unsupervised: Non-parametric density estimation Parzen Windows K-Nearest
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Machine Learning Algorithms (IFT6266 A7) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Machine Learning Algorithms (IFT6266 A7) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Nonparametric Methods
 Nonparametric Methods Jason Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Nonparametric Methods 1 / 49 Nonparametric Methods Overview Previously, we ve assumed that the forms of the underlying densities
Nonparametric Methods Jason Corso SUNY at Buffalo J. Corso (SUNY at Buffalo) Nonparametric Methods 1 / 49 Nonparametric Methods Overview Previously, we ve assumed that the forms of the underlying densities
Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions
 Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551,
Non-Bayesian Classifiers Part I: k-nearest Neighbor Classifier and Distance Functions Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2017 CS 551,
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques.
 . Non-Parameteric Techniques University of Cambridge Engineering Part IIB Paper 4F: Statistical Pattern Processing Handout : Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 23 Introduction
. Non-Parameteric Techniques University of Cambridge Engineering Part IIB Paper 4F: Statistical Pattern Processing Handout : Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 23 Introduction
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2015 11. Non-Parameteric Techniques
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2015 11. Non-Parameteric Techniques
Machine Learning. Nonparametric methods for Classification. Eric Xing , Fall Lecture 2, September 12, 2016
 Machine Learning 10-701, Fall 2016 Nonparametric methods for Classification Eric Xing Lecture 2, September 12, 2016 Reading: 1 Classification Representing data: Hypothesis (classifier) 2 Clustering 3 Supervised
Machine Learning 10-701, Fall 2016 Nonparametric methods for Classification Eric Xing Lecture 2, September 12, 2016 Reading: 1 Classification Representing data: Hypothesis (classifier) 2 Clustering 3 Supervised
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques
 University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2011 11. Non-Parameteric Techniques
University of Cambridge Engineering Part IIB Paper 4F10: Statistical Pattern Processing Handout 11: Non-Parametric Techniques Mark Gales mjfg@eng.cam.ac.uk Michaelmas 2011 11. Non-Parameteric Techniques
COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING
 COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING Luca Bortolussi Department of Mathematics and Geosciences University of Trieste Office 238, third floor, H2bis luca@dmi.units.it Trieste, Winter Semester
COMPUTATIONAL STATISTICS UNSUPERVISED LEARNING Luca Bortolussi Department of Mathematics and Geosciences University of Trieste Office 238, third floor, H2bis luca@dmi.units.it Trieste, Winter Semester
We use non-bold capital letters for all random variables in these notes, whether they are scalar-, vector-, matrix-, or whatever-valued.
 The Bayes Classifier We have been starting to look at the supervised classification problem: we are given data (x i, y i ) for i = 1,..., n, where x i R d, and y i {1,..., K}. In this section, we suppose
The Bayes Classifier We have been starting to look at the supervised classification problem: we are given data (x i, y i ) for i = 1,..., n, where x i R d, and y i {1,..., K}. In this section, we suppose
Machine Learning Lecture 3
 Many slides adapted from B. Schiele Machine Learning Lecture 3 Probability Density Estimation II 26.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course
Many slides adapted from B. Schiele Machine Learning Lecture 3 Probability Density Estimation II 26.04.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course
Nonparametric Classification. Prof. Richard Zanibbi
 Nonparametric Classification Prof. Richard Zanibbi What to do when feature distributions (likelihoods) are not normal Don t Panic! While they may be suboptimal, LDC and QDC may still be applied, even though
Nonparametric Classification Prof. Richard Zanibbi What to do when feature distributions (likelihoods) are not normal Don t Panic! While they may be suboptimal, LDC and QDC may still be applied, even though
Machine Learning and Pervasive Computing
 Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Machine Learning Lecture 3
 Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 26.04.206 Discriminative Approaches (5 weeks) Linear
Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 26.04.206 Discriminative Approaches (5 weeks) Linear
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Recap: Gaussian (or Normal) Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach
 Distribution. Recap: Minimizing the Expected Loss. Topics of This Lecture. Recap: Maximum Likelihood Approach") Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Truth Course Outline Machine Learning Lecture 3 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Probability Density Estimation II 2.04.205 Discriminative Approaches (5 weeks)
Machine Learning. Supervised Learning. Manfred Huber
 Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Machine Learning Supervised Learning Manfred Huber 2015 1 Supervised Learning Supervised learning is learning where the training data contains the target output of the learning system. Training data D
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Generative and discriminative classification techniques Machine Learning and Category Representation 2014-2015 Jakob Verbeek, November 28, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Homework. Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression Pod-cast lecture on-line. Next lectures:
 Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
Homework Gaussian, Bishop 2.3 Non-parametric, Bishop 2.5 Linear regression 3.0-3.2 Pod-cast lecture on-line Next lectures: I posted a rough plan. It is flexible though so please come with suggestions Bayes
MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11. Nearest Neighbour Classifier. Keywords: K Neighbours, Weighted, Nearest Neighbour
 MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11 Nearest Neighbour Classifier Keywords: K Neighbours, Weighted, Nearest Neighbour 1 Nearest neighbour classifiers This is amongst the simplest
MODULE 7 Nearest Neighbour Classifier and its variants LESSON 11 Nearest Neighbour Classifier Keywords: K Neighbours, Weighted, Nearest Neighbour 1 Nearest neighbour classifiers This is amongst the simplest
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Machine Learning: k-nearest Neighbors. Lecture 08. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning: k-nearest Neighbors Lecture 08 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Nonparametric Methods: k-nearest Neighbors Input: A training dataset
Machine Learning: k-nearest Neighbors Lecture 08 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Nonparametric Methods: k-nearest Neighbors Input: A training dataset
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Pattern Recognition ( , RIT) Exercise 1 Solution
 Exercise 1 Solution") Pattern Recognition (4005-759, 20092 RIT) Exercise 1 Solution Instructor: Prof. Richard Zanibbi The following exercises are to help you review for the upcoming midterm examination on Thursday of Week 5
Pattern Recognition (4005-759, 20092 RIT) Exercise 1 Solution Instructor: Prof. Richard Zanibbi The following exercises are to help you review for the upcoming midterm examination on Thursday of Week 5
Optimal Time Bounds for Approximate Clustering
 Optimal Time Bounds for Approximate Clustering Ramgopal R. Mettu C. Greg Plaxton Department of Computer Science University of Texas at Austin Austin, TX 78712, U.S.A. ramgopal, plaxton@cs.utexas.edu Abstract
Optimal Time Bounds for Approximate Clustering Ramgopal R. Mettu C. Greg Plaxton Department of Computer Science University of Texas at Austin Austin, TX 78712, U.S.A. ramgopal, plaxton@cs.utexas.edu Abstract
Nearest Neighbor Classification
 Nearest Neighbor Classification Charles Elkan elkan@cs.ucsd.edu October 9, 2007 The nearest-neighbor method is perhaps the simplest of all algorithms for predicting the class of a test example. The training
Nearest Neighbor Classification Charles Elkan elkan@cs.ucsd.edu October 9, 2007 The nearest-neighbor method is perhaps the simplest of all algorithms for predicting the class of a test example. The training
Nearest neighbor classification DSE 220
 Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Nearest neighbor classification DSE 220 Decision Trees Target variable Label Dependent variable Output space Person ID Age Gender Income Balance Mortgag e payment 123213 32 F 25000 32000 Y 17824 49 M 12000-3000
Empirical risk minimization (ERM) A first model of learning. The excess risk. Getting a uniform guarantee
 A first model of learning. The excess risk. Getting a uniform guarantee") A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk We observe the
A first model of learning Let s restrict our attention to binary classification our labels belong to (or ) Empirical risk minimization (ERM) Recall the definitions of risk/empirical risk We observe the
High Dimensional Indexing by Clustering
 Yufei Tao ITEE University of Queensland Recall that, our discussion so far has assumed that the dimensionality d is moderately high, such that it can be regarded as a constant. This means that d should
Yufei Tao ITEE University of Queensland Recall that, our discussion so far has assumed that the dimensionality d is moderately high, such that it can be regarded as a constant. This means that d should
k-nearest Neighbors + Model Selection
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
CS 340 Lec. 4: K-Nearest Neighbors
 CS 340 Lec. 4: K-Nearest Neighbors AD January 2011 AD () CS 340 Lec. 4: K-Nearest Neighbors January 2011 1 / 23 K-Nearest Neighbors Introduction Choice of Metric Overfitting and Underfitting Selection
CS 340 Lec. 4: K-Nearest Neighbors AD January 2011 AD () CS 340 Lec. 4: K-Nearest Neighbors January 2011 1 / 23 K-Nearest Neighbors Introduction Choice of Metric Overfitting and Underfitting Selection
Today. Lecture 4: Last time. The EM algorithm. We examine clustering in a little more detail; we went over it a somewhat quickly last time
 Today Lecture 4: We examine clustering in a little more detail; we went over it a somewhat quickly last time The CAD data will return and give us an opportunity to work with curves (!) We then examine
Today Lecture 4: We examine clustering in a little more detail; we went over it a somewhat quickly last time The CAD data will return and give us an opportunity to work with curves (!) We then examine
Data mining. Classification k-nn Classifier. Piotr Paszek. (Piotr Paszek) Data mining k-nn 1 / 20
 Data mining k-nn 1 / 20") Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
Data mining Piotr Paszek Classification k-nn Classifier (Piotr Paszek) Data mining k-nn 1 / 20 Plan of the lecture 1 Lazy Learner 2 k-nearest Neighbor Classifier 1 Distance (metric) 2 How to Determine
SFU CMPT Lecture: Week 8
 SFU CMPT-307 2008-2 1 Lecture: Week 8 SFU CMPT-307 2008-2 Lecture: Week 8 Ján Maňuch E-mail: jmanuch@sfu.ca Lecture on June 24, 2008, 5.30pm-8.20pm SFU CMPT-307 2008-2 2 Lecture: Week 8 Universal hashing
SFU CMPT-307 2008-2 1 Lecture: Week 8 SFU CMPT-307 2008-2 Lecture: Week 8 Ján Maňuch E-mail: jmanuch@sfu.ca Lecture on June 24, 2008, 5.30pm-8.20pm SFU CMPT-307 2008-2 2 Lecture: Week 8 Universal hashing
Clustering. Mihaela van der Schaar. January 27, Department of Engineering Science University of Oxford
 Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Department of Engineering Science University of Oxford January 27, 2017 Many datasets consist of multiple heterogeneous subsets. Cluster analysis: Given an unlabelled data, want algorithms that automatically
Introduction to Pattern Recognition Part II. Selim Aksoy Bilkent University Department of Computer Engineering
 Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Introduction to Pattern Recognition Part II Selim Aksoy Bilkent University Department of Computer Engineering saksoy@cs.bilkent.edu.tr RETINA Pattern Recognition Tutorial, Summer 2005 Overview Statistical
Data Mining and Machine Learning: Techniques and Algorithms
 Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Instance based classification Data Mining and Machine Learning: Techniques and Algorithms Eneldo Loza Mencía eneldo@ke.tu-darmstadt.de Knowledge Engineering Group, TU Darmstadt International Week 2019,
Nearest Neighbor Classification. Machine Learning Fall 2017
 Nearest Neighbor Classification Machine Learning Fall 2017 1 This lecture K-nearest neighbor classification The basic algorithm Different distance measures Some practical aspects Voronoi Diagrams and Decision
Nearest Neighbor Classification Machine Learning Fall 2017 1 This lecture K-nearest neighbor classification The basic algorithm Different distance measures Some practical aspects Voronoi Diagrams and Decision
Nearest Neighbor Classification
 Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Nearest Neighbor Classification Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms January 11, 2017 1 / 48 Outline 1 Administration 2 First learning algorithm: Nearest
Geometric data structures:
 Geometric data structures: Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade Sham Kakade 2017 1 Announcements: HW3 posted Today: Review: LSH for Euclidean distance Other
Geometric data structures: Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade Sham Kakade 2017 1 Announcements: HW3 posted Today: Review: LSH for Euclidean distance Other
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
MS1b Statistical Data Mining Part 3: Supervised Learning Nonparametric Methods
 MS1b Statistical Data Mining Part 3: Supervised Learning Nonparametric Methods Yee Whye Teh Department of Statistics Oxford http://www.stats.ox.ac.uk/~teh/datamining.html Outline Supervised Learning: Nonparametric
MS1b Statistical Data Mining Part 3: Supervised Learning Nonparametric Methods Yee Whye Teh Department of Statistics Oxford http://www.stats.ox.ac.uk/~teh/datamining.html Outline Supervised Learning: Nonparametric
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Online Facility Location
 Online Facility Location Adam Meyerson Abstract We consider the online variant of facility location, in which demand points arrive one at a time and we must maintain a set of facilities to service these
Online Facility Location Adam Meyerson Abstract We consider the online variant of facility location, in which demand points arrive one at a time and we must maintain a set of facilities to service these
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
COMS 4771 Clustering. Nakul Verma
 COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
COMS 4771 Clustering Nakul Verma Supervised Learning Data: Supervised learning Assumption: there is a (relatively simple) function such that for most i Learning task: given n examples from the data, find
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Nearest neighbors classifiers
 Nearest neighbors classifiers James McInerney Adapted from slides by Daniel Hsu Sept 11, 2017 1 / 25 Housekeeping We received 167 HW0 submissions on Gradescope before midnight Sept 10th. From a random
Nearest neighbors classifiers James McInerney Adapted from slides by Daniel Hsu Sept 11, 2017 1 / 25 Housekeeping We received 167 HW0 submissions on Gradescope before midnight Sept 10th. From a random
Nearest Neighbors Classifiers
 Nearest Neighbors Classifiers Raúl Rojas Freie Universität Berlin July 2014 In pattern recognition we want to analyze data sets of many different types (pictures, vectors of health symptoms, audio streams,
Nearest Neighbors Classifiers Raúl Rojas Freie Universität Berlin July 2014 In pattern recognition we want to analyze data sets of many different types (pictures, vectors of health symptoms, audio streams,
Section 4 Matching Estimator
 Section 4 Matching Estimator Matching Estimators Key Idea: The matching method compares the outcomes of program participants with those of matched nonparticipants, where matches are chosen on the basis
Section 4 Matching Estimator Matching Estimators Key Idea: The matching method compares the outcomes of program participants with those of matched nonparticipants, where matches are chosen on the basis
Statistical Learning Part 2 Nonparametric Learning: The Main Ideas. R. Moeller Hamburg University of Technology
 Statistical Learning Part 2 Nonparametric Learning: The Main Ideas R. Moeller Hamburg University of Technology Instance-Based Learning So far we saw statistical learning as parameter learning, i.e., given
Statistical Learning Part 2 Nonparametric Learning: The Main Ideas R. Moeller Hamburg University of Technology Instance-Based Learning So far we saw statistical learning as parameter learning, i.e., given
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 9, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 9, 2014 1 / 47
CSCI567 Machine Learning (Fall 2014) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu September 9, 2014 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 2014) September 9, 2014 1 / 47
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions
 Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Computational Statistics The basics of maximum likelihood estimation, Bayesian estimation, object recognitions Thomas Giraud Simon Chabot October 12, 2013 Contents 1 Discriminant analysis 3 1.1 Main idea................................
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Data Mining in Bioinformatics Day 1: Classification
 Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Parametrizing the easiness of machine learning problems. Sanjoy Dasgupta, UC San Diego
 Parametrizing the easiness of machine learning problems Sanjoy Dasgupta, UC San Diego Outline Linear separators Mixture models Nonparametric clustering Nonparametric classification and regression Nearest
Parametrizing the easiness of machine learning problems Sanjoy Dasgupta, UC San Diego Outline Linear separators Mixture models Nonparametric clustering Nonparametric classification and regression Nearest
This chapter explains two techniques which are frequently used throughout
 Chapter 2 Basic Techniques This chapter explains two techniques which are frequently used throughout this thesis. First, we will introduce the concept of particle filters. A particle filter is a recursive
Chapter 2 Basic Techniques This chapter explains two techniques which are frequently used throughout this thesis. First, we will introduce the concept of particle filters. A particle filter is a recursive
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Overview Citation. ML Introduction. Overview Schedule. ML Intro Dataset. Introduction to Semi-Supervised Learning Review 10/4/2010
 INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
Nearest Neighbor Predictors
 Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Statistical Methods in AI
 Statistical Methods in AI Distance Based and Linear Classifiers Shrenik Lad, 200901097 INTRODUCTION : The aim of the project was to understand different types of classification algorithms by implementing
Statistical Methods in AI Distance Based and Linear Classifiers Shrenik Lad, 200901097 INTRODUCTION : The aim of the project was to understand different types of classification algorithms by implementing
Pruning Nearest Neighbor Cluster Trees
 Pruning Nearest Neighbor Cluster Trees Samory Kpotufe Max Planck Institute for Intelligent Systems Tuebingen, Germany Joint work with Ulrike von Luxburg We ll discuss: An interesting notion of clusters
Pruning Nearest Neighbor Cluster Trees Samory Kpotufe Max Planck Institute for Intelligent Systems Tuebingen, Germany Joint work with Ulrike von Luxburg We ll discuss: An interesting notion of clusters
TECHNICAL REPORT NO Random Forests and Adaptive Nearest Neighbors 1
 DEPARTMENT OF STATISTICS University of Wisconsin 1210 West Dayton St. Madison, WI 53706 TECHNICAL REPORT NO. 1055 May 29, 2002 Random Forests and Adaptive Nearest Neighbors 1 by Yi Lin and Yongho Jeon
DEPARTMENT OF STATISTICS University of Wisconsin 1210 West Dayton St. Madison, WI 53706 TECHNICAL REPORT NO. 1055 May 29, 2002 Random Forests and Adaptive Nearest Neighbors 1 by Yi Lin and Yongho Jeon
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
SD 372 Pattern Recognition
 SD 372 Pattern Recognition Lab 2: Model Estimation and Discriminant Functions 1 Purpose This lab examines the areas of statistical model estimation and classifier aggregation. Model estimation will be
SD 372 Pattern Recognition Lab 2: Model Estimation and Discriminant Functions 1 Purpose This lab examines the areas of statistical model estimation and classifier aggregation. Model estimation will be
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Notes and Announcements
 Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Notes and Announcements Midterm exam: Oct 20, Wednesday, In Class Late Homeworks Turn in hardcopies to Michelle. DO NOT ask Michelle for extensions. Note down the date and time of submission. If submitting
Lecture 5 Finding meaningful clusters in data. 5.1 Kleinberg s axiomatic framework for clustering
 CSE 291: Unsupervised learning Spring 2008 Lecture 5 Finding meaningful clusters in data So far we ve been in the vector quantization mindset, where we want to approximate a data set by a small number
CSE 291: Unsupervised learning Spring 2008 Lecture 5 Finding meaningful clusters in data So far we ve been in the vector quantization mindset, where we want to approximate a data set by a small number
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Instance-based Learning
 Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
Instance-based Learning Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 19 th, 2007 2005-2007 Carlos Guestrin 1 Why not just use Linear Regression? 2005-2007 Carlos Guestrin
SUPERVISED LEARNING METHODS. Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018
 SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
Cluster Analysis. Jia Li Department of Statistics Penn State University. Summer School in Statistics for Astronomers IV June 9-14, 2008
 Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Note Set 4: Finite Mixture Models and the EM Algorithm
 Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
Note Set 4: Finite Mixture Models and the EM Algorithm Padhraic Smyth, Department of Computer Science University of California, Irvine Finite Mixture Models A finite mixture model with K components, for
10701 Machine Learning. Clustering
 171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
171 Machine Learning Clustering What is Clustering? Organizing data into clusters such that there is high intra-cluster similarity low inter-cluster similarity Informally, finding natural groupings among
Machine Learning A W 1sst KU. b) [1 P] Give an example for a probability distributions P (A, B, C) that disproves
![Machine Learning A W 1sst KU. b) [1 P] Give an example for a probability distributions P (A, B, C) that disproves](/thumbs/93/111796408.jpg "Machine Learning A W 1sst KU. b) [1 P] Give an example for a probability distributions P (A, B, C) that disproves") Machine Learning A 708.064 11W 1sst KU Exercises Problems marked with * are optional. 1 Conditional Independence I [2 P] a) [1 P] Give an example for a probability distribution P (A, B, C) that disproves
Machine Learning A 708.064 11W 1sst KU Exercises Problems marked with * are optional. 1 Conditional Independence I [2 P] a) [1 P] Give an example for a probability distribution P (A, B, C) that disproves
Stanford University CS359G: Graph Partitioning and Expanders Handout 1 Luca Trevisan January 4, 2011
 Stanford University CS359G: Graph Partitioning and Expanders Handout 1 Luca Trevisan January 4, 2011 Lecture 1 In which we describe what this course is about. 1 Overview This class is about the following
Stanford University CS359G: Graph Partitioning and Expanders Handout 1 Luca Trevisan January 4, 2011 Lecture 1 In which we describe what this course is about. 1 Overview This class is about the following
1) Give decision trees to represent the following Boolean functions:
 Give decision trees to represent the following Boolean functions:") 1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
Sampling-based Planning 2
 RBE MOTION PLANNING Sampling-based Planning 2 Jane Li Assistant Professor Mechanical Engineering & Robotics Engineering http://users.wpi.edu/~zli11 Problem with KD-tree RBE MOTION PLANNING Curse of dimension
RBE MOTION PLANNING Sampling-based Planning 2 Jane Li Assistant Professor Mechanical Engineering & Robotics Engineering http://users.wpi.edu/~zli11 Problem with KD-tree RBE MOTION PLANNING Curse of dimension
PATTERN CLASSIFICATION AND SCENE ANALYSIS
 PATTERN CLASSIFICATION AND SCENE ANALYSIS RICHARD O. DUDA PETER E. HART Stanford Research Institute, Menlo Park, California A WILEY-INTERSCIENCE PUBLICATION JOHN WILEY & SONS New York Chichester Brisbane
PATTERN CLASSIFICATION AND SCENE ANALYSIS RICHARD O. DUDA PETER E. HART Stanford Research Institute, Menlo Park, California A WILEY-INTERSCIENCE PUBLICATION JOHN WILEY & SONS New York Chichester Brisbane
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Clustering web search results
 Clustering K-means Machine Learning CSE546 Emily Fox University of Washington November 4, 2013 1 Clustering images Set of Images [Goldberger et al.] 2 1 Clustering web search results 3 Some Data 4 2 K-means
Clustering K-means Machine Learning CSE546 Emily Fox University of Washington November 4, 2013 1 Clustering images Set of Images [Goldberger et al.] 2 1 Clustering web search results 3 Some Data 4 2 K-means
Task Description: Finding Similar Documents. Document Retrieval. Case Study 2: Document Retrieval
 Case Study 2: Document Retrieval Task Description: Finding Similar Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 11, 2017 Sham Kakade 2017 1 Document
Case Study 2: Document Retrieval Task Description: Finding Similar Documents Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 11, 2017 Sham Kakade 2017 1 Document
Treewidth and graph minors
 Treewidth and graph minors Lectures 9 and 10, December 29, 2011, January 5, 2012 We shall touch upon the theory of Graph Minors by Robertson and Seymour. This theory gives a very general condition under
Treewidth and graph minors Lectures 9 and 10, December 29, 2011, January 5, 2012 We shall touch upon the theory of Graph Minors by Robertson and Seymour. This theory gives a very general condition under
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Learning with minimal supervision
 Learning with minimal supervision Sanjoy Dasgupta University of California, San Diego Learning with minimal supervision There are many sources of almost unlimited unlabeled data: Images from the web Speech
Learning with minimal supervision Sanjoy Dasgupta University of California, San Diego Learning with minimal supervision There are many sources of almost unlimited unlabeled data: Images from the web Speech
Nearest Neighbor Search by Branch and Bound
 Nearest Neighbor Search by Branch and Bound Algorithmic Problems Around the Web #2 Yury Lifshits http://yury.name CalTech, Fall 07, CS101.2, http://yury.name/algoweb.html 1 / 30 Outline 1 Short Intro to
Nearest Neighbor Search by Branch and Bound Algorithmic Problems Around the Web #2 Yury Lifshits http://yury.name CalTech, Fall 07, CS101.2, http://yury.name/algoweb.html 1 / 30 Outline 1 Short Intro to
Constructive floorplanning with a yield objective
 Constructive floorplanning with a yield objective Rajnish Prasad and Israel Koren Department of Electrical and Computer Engineering University of Massachusetts, Amherst, MA 13 E-mail: rprasad,koren@ecs.umass.edu
Constructive floorplanning with a yield objective Rajnish Prasad and Israel Koren Department of Electrical and Computer Engineering University of Massachusetts, Amherst, MA 13 E-mail: rprasad,koren@ecs.umass.edu
9881 Project Deliverable #1
 Memorial University of Newfoundland Pattern Recognition Lecture 3 May 9, 2006 http://www.engr.mun.ca/~charlesr Office Hours: Tuesdays & Thursdays 8:30-9:30 PM EN-3026 9881 Project Deliverable #1 Report
Memorial University of Newfoundland Pattern Recognition Lecture 3 May 9, 2006 http://www.engr.mun.ca/~charlesr Office Hours: Tuesdays & Thursdays 8:30-9:30 PM EN-3026 9881 Project Deliverable #1 Report
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Admin Course add/drop deadline tomorrow. Assignment 1 is due Friday. Setup your CS undergrad account ASAP to use Handin: https://www.cs.ubc.ca/getacct
Theorem 2.9: nearest addition algorithm
 There are severe limits on our ability to compute near-optimal tours It is NP-complete to decide whether a given undirected =(,)has a Hamiltonian cycle An approximation algorithm for the TSP can be used
There are severe limits on our ability to compute near-optimal tours It is NP-complete to decide whether a given undirected =(,)has a Hamiltonian cycle An approximation algorithm for the TSP can be used
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask