arxiv: v2 [cs.cv] 27 Nov 2015
|
|
|
- Harvey Shelton
- 5 years ago
- Views:
Transcription
1 Weakly Supervised Deep Detection Networks Hakan Bilen Andrea Vedaldi Department of Engineering Science, University of Oxford arxiv: v2 [cs.cv] 27 Nov 2015 Abstract Weakly supervised learning of object detection is an important problem in image understanding that still does not have a satisfactory solution. In this paper, we address this problem by exploiting the power of deep convolutional neural networks pre-trained on large-scale image-level classification tasks. We propose a weakly supervised deep detection architecture that modifies one such network to operate at the level of image regions, performing simultaneously region selection and classification. Trained as an image classifier, the architecture implicitly learns object detectors that are better than alternative weakly supervised detection systems on the PASCAL VOC data. The model, which is a simple and elegant end-to-end architecture, outperforms standard data augmentation and fine-tuning techniques for the task of image-level classification as well. 1. Introduction In recent years, Convolutional Neural Networks (CNN) [22] have emerged as the new state-of-the-art learning framework for image recognition. Key to their success is the ability to learn from large quantities of labelled data the complex appearance of real-world objects. One of the most striking aspects of CNNs is their ability to learn generic visual features that generalize to many tasks. In particular, CNNs pre-trained on datasets such as ImageNet ILSVRC have been shown to obtain excellent results in recognition in other domains [8], in object detection [13], in semantic segmentation [14], in human pose estimation [34], and in many other tasks. In this paper we look at how the power of CNNs can be leveraged in weakly supervised detection (WSD), which is the problem of learning object detectors using only imagelevel labels. The ability of learning from weak annotations is very important for two reasons: first, image understanding aims at learning an growing body of complex visual concepts (e.g. hundred thousands object categories in ImageNet). Second, CNN training is data-hungry. Therefore, being able to learn complex concepts using only light supervision can reduce significantly the cost of data annotation in ImageNet pre-trained CNN Weakly-supervised detection network recognition pooling SPP convolutional features detection region proposals Figure 1. Weakly Supervised Deep Detection Network. Our method starts from a CNN pre-trained for image classification on a large dataset, e.g. ImageNet. It then modifies to reason efficiently about regions, branching off a recognition and a detection data streams. The resulting architecture can be fine-tuned on a target dataset to achieve state-of-the-art weakly supervised object detection using only image-level annotations. tasks such as image segmentation, image captioning, or object detection. We are motivated in our research by the hypothesis that, since pre-trained CNNs generalize so well to a large number of tasks, they should contain meaningful representations of the data. For example, there exists evidence that CNNs trained for image classification learn proxies to objects and objects parts [38]. Remarkably, these concepts are acquired implicitly, without ever providing the network with information about the location of such structures in images. Hence, CNNs trained for image classification may already contain implicitly most of the information required to perform object detection. We are not the first to address the problem of WSD with CNNs. The method of Wang et al. [37], for example, uses a pre-trained CNN to describe image regions and then learn object categories as corresponding visual topics. While this method is currently state-of-the-art in weakly supervised object detection, it comprises several components beyond the CNN and requires signifiant tuning. In this paper we contribute a novel end-to-end method for weakly supervised object detection using pre-trained CNNs which we call a weakly supervised deep detection network (Section 1). Our method (Section 2) starts from 1
2 an existing network, such as AlexNet pre-trained on ImageNet data, and extends it to reason explicitly and efficiently about image regions R. In order to do so, given an image x, the first step is to efficiently extract region-level descriptors φ(x; R) by inserting a spatial pyramid pooling layer on top of the convolutional layers of the CNN [15, 11]. Next, the network is branched to extract two data streams from the pooled region-level features. The first stream associates a class score φ c (x; R) to each region individually, performing recognition. The second stream, instead, compares regions by computing a probability distribution φ d (x; R) over them; the latter represents the belief that, among all the candidate regions in the image, R is the one that contains the most salient image structure, and is therefore a proxy to detection. The recognition and detection scores computed for all the image regions are finally aggregated in order to predict the class of the image as a whole, which is then used to inject image-level supervision in learning. It is interesting to compare our method to the most common weakly supervised object detection technique, namely multiple instance learning (MIL) [7]. MIL alternates between selecting which regions in images look like the object of interest and estimating an appearance model of the object using the selected regions. Hence, MIL uses the appearance model itself to perform region selection. Our technique differs from MIL in a fundamental way as regions are selected by a dedicated parallel detection branch in the network, which is independent of the recognition branch. In this manner, our approach helps avoiding one of the pitfalls of MIL, namely the tendency of the method to get stuck in local optima. Our two-stream CNN is also weakly related to the recent work of Lin et al. [23]. They propose a bilinear architecture where the output of two parallel network streams are combined by taking the outer product of feature vectors at corresponding spatial locations. The authors state that this construction is inspired by the ventral and dorsal streams of the human visual system, one focusing on recognition and the other one on localization. While our architecture contains two such streams, the similarity is only superficial. A key difference is that in Lin et al. the two streams are perfectly symmetric, and therefore there is no reason to believe that one should perform localization and the other detection; in our scheme, instead, the detection branch is explicitly designed to compare regions, breaking the symmetry. Note also that Lin et al. [23] do not perform WSD nor evaluate object detection performance. Once the modifications have been applied, the network is ready to be fine-tuned on a target dataset, using only imagelevel labels and back-propagation. In Section 3 we show that, when fine-tuned on the PASCAL VOC training set, this architecture achieves state-of-the-art weakly supervised object detection on the PASCAL data, achieving similar or superior results to the current state-of-the-art [37] but using only CNN machinery. Since the system can be trained endto-end using standard CNN packages, it is also as efficient as the recent fully-supervised Fast R-CNN detector of Girshick et al. [12], both in training and in testing. Finally, as a byproduct of our construction we also obtain a powerful image classifier that performs better than standard fine-tuning techniques on the target data. Our findings are summarized in Section Related Work The majority of existing approaches to WSD formulate this task as MIL. In this formulation an image is interpreted as a bag of regions. If the image labelled as positive, then one of the regions is assume to tightly contain the object of interest. If the image is labelled as negative, then no region contains the object. Learning alternates between estimating a model of the object appearance and selecting which regions in the positive bags correspond to the object using the appearance model. The MIL strategy results in a non-convex optimization problem; in practice, solvers tend to get stuck in local optima such that the quality of the solution strongly depends on the initialization. Several papers have focused on developing various initialization strategies [20, 5, 4, 33] and on regularizing the optimization problem [32, 1]. Kumar et al. [20] propose a self-paced learning strategy that progressively includes harder samples to a small set of initial ones at training. Deselaers et al. [5] initialize object locations based on the objectness score. Cinbis et al. [4] propose a multi-fold split of the training data to escape local optima. Song et al. [32] apply Nesterov s smoothing technique [24] to the latent SVM formulation [10] to be more robust against poor initializations. Bilen et al. [1] propose a smoothed version of MIL that softly labels object instances instead of choosing the highest scoring ones. Additionally, their method regularizes the latent object locations by penalizing unlikely configurations based on symmetry and mutual exclusion principles. Another line of research in WSD [32, 33, 37] is based on the idea of identifying the similarity between image parts. Song et al. [32] propose a discriminative graph-based algorithm that selects a subset of windows such that each window is connected to its nearest neighbors in positive images. In [33], the same authors extend this method to discover multiple co-occurring part configurations. Wang et al. [37] propose an interative technique that applies a latent semantic clustering via latent Semantic Analysis (plsa) on the windows of positive samples and selects the most discriminative cluster for each class based on its classification performance. Bilen et al. [2] propose a formulation that jointly learns a discriminative model and enforces the similarity of the selected object regions via a discriminative convex clus-
3 tering algorithm. Recently a number of researchers [26, 27] have proposed weakly supervised localization principles to improve classification performance of CNNs without providing any annotation for the location of objects in images. Oquab et al. [26] employ a pre-trained CNN to compute a mid-level image representation for images of PASCAL VOC. In their follow-up work, Oquab et al. [27] modify a CNN architecture to coarsely localize object instances in image while predicting its label. Jaderberg et al. [17] proposed a CNN architecture in which a subnetwork automatically pre-transforms an image in order to optimize the classification accuracy of a second subnetwork. This transformer network, which is trained in an end-to-end fashion from image-level labels, is shown to align objects to a common reference frame, which is a proxy to detection. Our architecture contains a mechanism that pre-select image regions that are likely to contain the object, also trained in an end-to-end fashion; while this may seem very different, this mechanism can also be thought as learning transformations (as the ones that map the detected regions to a canonical reference frame). However, the nature of the selection process in in our and their networks are very different. 2. Method In this section we introduce our weakly supervised deep detection network (WSDDN) method. The overall idea consists of three steps. First, we obtain a CNN pre-trained on a large-scale image classification task (Section 2.1). Second, we construct the WSDDN as an architectural modification of this CNN (Section 2.2). Third, we train/fine-tune the WSDDN on a target dataset, once more using only imagelevel annotations (Section 2.3). The remainder of this section discusses these three steps in detail Pre-trained network As a pre-trained CNN, we use the standard AlexNet model from [19] in the variant trained by [18]. This network consists of 5 convolutional and three fully-connected layers. Each layer comprises a bank of linear filters, a ReLU activation function, and, in some cases, a max pooling layer as well as a normalization layer Weakly supervised deep detection network Given the pre-trained CNN, we transform it in a WS- DDN by introducing three modifications (see also Figure 2). First, we replace the last pooling layer immediately following the ReLU layer in the last convolutional block (also known as relu5 and pool5, respectively) with a layer implementing spatial pyramid pooling (SPP) [21, 16]. This results in a function that takes as input an image x and a region (bounding box) R and produces as output a feature vector or representation φ(x; R). Importantly, the function decomposes as φ(x; R) = φ SPP ( ; R) φ relu5 (x) where φ relu5 (x) needs to be computed only once for the whole image and φ SPP ( ; R) is fast to compute for any given region R. In practice, SPP is configured to contain 6 6 spatial subdivisions; since φ relu5 (x) has 256 feature channels, the representations φ(x; R) R has 9,216 components overall. Note that SPP is implemented as a network layer as in [12] to allow to train the system end-to-end (and for efficiency). Given an image x, a shortlist of candidate object regions R = (R 1,..., R n ) are obtained by a region proposal mechanism. Here we use in particular Selective Search Windows (SSW) [35], which is a standard choice for proposal generation. As in [11], we then modify the SPP layer to take as input not a single region, but rather the full list R; in particular, φ(x; R) is defined as the concatenation of φ(x; R 1 ),..., φ(x; R n ) along the fourth dimension (since each individual φ(x; R 1 ) is a 3D tensor). At this point in the architecture, region-level features are further processed by one or more fully connected layers. For example, in a variant of the architecture, SPP is followed by layers φ fc6 and φ fc7, each comprising a linear map followed by ReLU as in AlexNet. Out of the output of the last such layer, we branch off two data streams, described next. Classification and detection data streams. The first data stream performs classification of the individual regions, by mapping each of them to a C-dimensional vector of class scores, assuming that the system is trained to detect C different object classes. This is achieved by evaluating a linear map φ fc8c and results in a matrix of data x c R C R, containing the class prediction scores for each region. The second data stream performs instead detection, by scoring regions relative to one another. This is done on a class-specific basis by using a second linear map φ fc8d, also resulting in a matrix of scores x d R C R. The latter is then passed through a softmax operator, which is defined as follows: [σ det (x d e xd ij )] ij = R. (1) r=1 exd ir While the two streams are remarkably similar, the introduction of the σ det non-linearity in the detection stream is a key difference which allows to interpret them as performing classification and detection, respectively. In the first case, in fact, class scores are computed for each region independently, whereas in the second case the softmax operator compares, for each class independently, the scores of different regions. Hence, the first branch predicts which class to
4 x φ pool5 φ SPP φ fc6 φ fc7 φ fc8c SSW R φ fc8d x d σ det x c x R Σ y φ fc7d σ det φ fc6d σ det Figure 2. Weakly supervised deep detection network. The figure illustrates the architecture of WSDDN. There are three variants, depending on the layer used to branch off the detection subnetwork. associate to a region (or background), whereas the second branch selects which regions are more likely to contain an informative image fragment. Combined region scores and detection. The final score of each region is obtained by taking the element-wise (Hadamard) product x R = x c σ det (x d ) of the two scoring matrices. The region scores are then used to rank image regions by likelihood of centering an object (for each class independently); standard non-maxima suppression is then performed (by iteratively removing regions with Intersection over Union (IoU) larger than 50% with regions already selected) to obtain the final list of class-specific detections in an image. The way the two streams scores are combined is reminiscent of the bilinear networks of [23], but there are three key differences. The first difference is that the introduction of the σ det non-linearity explicitly breaks the symmetry of the two streams. The second one is that, instead of computing the outer product of the two feature vectors x c r σ det (x d r), we compute the element-wise product x c r σ det (x d r) (generating quadratically less parameters). The third difference is that scores x c r σ det (x d r) are computed for specific image regions r rather than a fixed set of image locations on a grid. Together, these three differences mean that we can interpret σ det (x d ) as a term that ranks regions, whereas x c classifies them. It is more difficult to clearly assess the nature of the two streams in [23]. Image-level classification scores. So far, WSDDN has computed region-level scores x R. This is transformed in an image-level class prediction score by summation over regions: R y c = x R cr. r=1 Softmax is not performed at this stage as images are allowed to contain more than one object class (whereas regions should contain a single class) Training WSDDN Having discussed the WSDDN architecture in the previous section, here we explain how the model is trained. The data is a collection of images x i, i = 1,..., n with image level labels y i { 1, 1} C. We denote by φ y (x w) the complete architecture, mapping an image x to a vector of class-scores y R C. The parameters w of the model lump together the coefficients of all the filters and biases in the convolutional and fully-connected layers. Then, stochastic gradient descent with momentum is used to optimize the energy function E(w) = λ 2 w nc n i=1 k=1 C max{0, 1 y ki φ y k (x i w)}, hence optimising an average of C hinge-loss terms, one per class. Initialization and learning rates. The convolutional layers are initialized from the AlexNet architecture trained on the ImageNet ILSVRC 2012 classification challenge data (in practice we use the pre-trained Caffe reference model as it is standard). The last fully connected layers (i.e. φ fc8c and φ fcxd ) are randomly initialized with gaussian noise. The experiments are run for 20 epochs. The learning rates are set to for the first ten epochs and lowered to for the last ten epochs. 3. Experiments In this section we conduct a thorough investigation of WSDDN and its component on weakly supervised detection and image classification. Benchmark data. We evaluate our method on the PAS- CAL VOC 2007 dataset [9], as it is the most widely-used benchmark in weakly supervised object detection. This dataset consists of 2501 training, 2510 validation, and 5011 test images containing bounding box annotations for 20 object categories. We use the suggested training and validation
5 Method aero bike bird boat bottle bus car cat chair cow table dog hors mbik pers plnt shp sofa train tv mean WSDDN-S WSDDN WSDDN WSDDN WSDDN-ens Cinbis et al. [4] Song et al. [32] Song et al. [33] Bilen et al. [1] Bilen et al. [2] Wang et al. [37] Table 1. Comparison of our WSDDN on PASCAL VOC 2007 to the state-of-the-art in terms of AP in the test set. Method aero bike bird boat bottle bus car cat chair cow table dog hors mbik pers plnt shp sofa train tv mean WSDDN-ens Shi et al. [31] Shi et al. [30] Cinbis et al. [4] Bilen et al. [2] Wang et al. [37] Table 2. Comparison of our method (WSDDN) on PASCAL VOC 2007 in terms of correct localization (CorLoc [6]) on positive trainval images. splits and report results evaluated on test split. We report performance of our method on both the object detection and the image classification tasks of PASCAL VOC. For detection, we use two performance measures. The first one follows the standard PASCAL VOC protocol and reports average precision (AP) at 50% intersection-overunion of the detected boxes with the ground truth ones (Table 1). We also report CorLoc (Table 2), a commonly-used weakly supervised detection measure [6]. CorLoc is the percentage of images that contain at least one instance of the target object class for which the most confident detected bounding box overlaps by at least 50% with one of these instances. Differently from AP, which is measured on the PASCAL test set, CorLoc is evaluated on the union of the training and validation subset of PASCAL. For classification, we use the standard PASCAL VOC protocol and report AP. Experimental setup. We build WSDDN starting from a standard CNN architecture similar to AlexNet [19]; in particular, we use the pre-trained Caffe reference CNN model of [18]. This model, which is pre-trained on the ImageNet ILSVRC 2012 challenge data, attains 19.6% top-5 accuracy (using a single center-crop) on ILSVRC (importantly no bounding box information is provided during pre-training). As explained in Section 2.1, we apply the following modifications to the network. First, we replace the last pooling layer pool5 with a 6 6 SPP layer [16]. Second, we add a parallel detection branch to the classification one that contains a fully-connected layer followed by a soft-max layer. The detection stream can be branched off at different layer positions starting from the SPP layer (see Figure 2). Thus we compare three variants of the model, WSDDN- 6, WSDDN-7 and WSDDN-8, which are branched off before the fully-connected layers fc6, fc7 and fc8c, respectively. Third, we combine the classification and detection streams by element-wise product followed by summing scores across regions, and feed the latter to a binary hingeloss layer. Note that this layer assesses the classification performance for the 20 classes together, but each of them is treated as a different binary classification problem; the reason is that classes can co-occur in PASCAL VOC, such that the softmax log loss used in AlexNet is not appropriate. The WSDNNs are trained on the PASCAL VOC training and validation data by using fine-tuning, a widely-adopted technique to improve the performance of a CNN on a target domain [3]. Here, however, fine tuning performs the essential function of learning the classification and detection streams, effectively causing the network to learn to detect objects, but using only weak image-level supervision. In order to generate candidate regions to use with our networks, we use Selective Search Windows [35] using its fast setting, resulting in approximately 1500 windows per image. Since we use a SPP layer to aggregate descriptors for each region, images do not need to be resized to a particular size as in the original AlexNet model. Instead, we keep the original aspect ratio of images fixed and resize them to five different scales (setting their maximum of
6 Method aero bike bird boat bottle bus car cat chair cow table dog hors mbik pers plnt shp sofa train tv mean Our method Oquab et al. [25] SPP [16] Chatfield [3] Table 3. Comparison of WSL object detectors on PASCAL VOC 2007 in terms of classification accuracy (map). width or height to {480, 576, 688, 864, 1200} respectively). During training, we apply random horizontal flips to the images and select a scale at random as a from of jittering or data augmentation. At test time we average the outputs of 10 images (i.e. the 5 scales and their flips). We use the publicly available CNN toolbox MatConvNet [36] to conduct our experiments. When evaluated on an image, WSDDN produces, for each target class c and image x, a score x R r = S c (x; r) for each region r and an aggregated score y c = S c (x) for each image. As explained earlier, non-maxima suppression is applied to the regions and then the scored regions and images are pooled together to compute detection AP and CorLoc and classification AP Detection results Baseline method. As an alternative baseline to WSDDN, we design a single stream classification-detection network (referred to as WSDDN-S in Table 1). Part of the construction is similar to WSDDN, as we replace pool5 layer with an SPP. However, we do not branch off two streams, but simply append to the last fully connected layer (φ fc8c ) the following loss layer 1 nc n i=1 k=1 R C max{0, 1 y ki log exp(x R cr)}. r=1 The term log R r=1 exp(xr cr) is a soft approximation of the max operator max r x R cr and was found to yield better performance than using the max scoring region. This observation is also reported in [1]. Note that the non-linearity is necessary as otherwise aggregating region-based scores would sum over the scores of a majority of regions that are uninformative. The loss function is once more a sum of C binary hinge-losses, one for each class. WSDDN-S obtains 21.6% map detection score on the PASCAL VOC test set, which is well below the state-of-the-art. Architecture variants. Next, we compare different variants of WSDDN (Table 1). First, we notice that all variants perform noticeably better than the baseline, with a jump of +7% map points. Although WSDDN-8 achieves the best detection score among all (28.7% map), there is no clear winner when results are broken down class-by-class. For example, WSDDN-6 is branched right after SPP layer and before fc6. Hence, its dimensional input is not as geometrically invariant as for the other branching points that are preceded by several fully-connected layers. Thus WSDDN-6 works better than WSDDN-7 and WSDDN-8 for rigid object classes such as aeroplane, bicycle, motorbike and train, and worse for more flexible ones. WSDDN- 8, which is branched off after the deep fc7 layer, receives features that capture higher level information, are more invariant, but also contain less geometric information. Furthermore, the receptive fields of these deep neurons are very large, capturing a lot of context in the image. As expected, this model outperforms WSDDN-6 and WSDDN-7 on difficult classes where context is important such as dining-table and sofa. As these models have different characteristics, they should be complementary. We verified this conjecture by combining their outputs in an ensemble predictor WSDDNens (also in Table 1). The combination is obtained simply by averaging the region scores produced by each model. The ensemble achieves 30.6% map, and 51.0% CorLoc, improving the individual networks by 2 3 percentage points. Classification and detection streams. We also assess the detection performances of the region scores obtained from the individual classification and detection streams. To do so, we score regions using the values x c and x d directly, as produced by the last fully connected layers in the classification and detection branches. The classification and detection branches obtain respectively a map of 14.5% and 9.9%, which is well below the performance of their combination. This shows that by jointly training the two branches they learn very complementary information. Comparison with the state of the art. We compare our ensemble WSDDN to the state of the art in weakly supervised detection literature in Table 1 and 2. The results show that our method achieves overall better or comparable performance to these alternatives. While Cinbis et al. [4] use Fisher Vectors [28] along with SSW, the majority of previous work [32, 33, 1, 37, 2] use the Caffe reference CNN model [18] as a black box to extract features over SSW proposals. Compared to these, it is based on a simple modification of the original CNN architecture fine-tuned on the target data using back-propagation.




































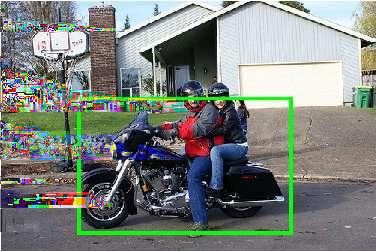











7 Figure 3. This figure depicts success (in green) and failure cases (in red) of our detector. Majority of false detections contains two kinds of error: i) group multiple object instances with a single bounding box, ii) focus on (discriminative) parts (e.g. faces ) rather than whole object.
8 Next, we investigate the results in more detail. While our method significantly outperforms the alternatives for aeroplane, bicycle, bus, car, dining-table and train, is not as strong in more deformable object categories such as cat, dog and person. Failure and success case are illustrated in Figure 3. It can be noted that, by far, the most important failure modality for our system is that an object part (e.g. cat face) is detected instead as the object as a whole. This can be explained by the fact that parts such as face are very often much more discriminative and with a less variable appearance than the rest of the object. Note that the root cause for this failure modality is that we, as many other authors, define objects as image regions that are most predictive for a given object class, and these may not include the object as a whole. Addressing this issue will therefore require incorporating additional cue in the model to try to learn the whole object. We also further analyze the ranking quality of the top scoring detections of our method. To do so, we use an oracle that re-ranks the highest scoring 2 and 5 detections according to the ground truth annotations, searching for the one with best overlap. The oracle ranking boost map to 35.3% and 43.2% respectively, therefore increasing the average detection performance by 5% and 12%. This shows, while object parts can be more discriminative than object as a whole, many correct detections are still ranked among the top scoring regions. The output of our model could also be used as input to one of the existing methods for weakly-supervised detection that use a CNN as a black-box for feature extraction. Investigating this option is left to future work Classification Results While our WSDDN is primarily designed for weaklysupervised object detection, ultimately it is trained to perform image classification. Hence, it is interesting to evaluate its performance on this task as well. To this end, we use once more the PASCAL VOC 2007 benchmark and contrast it to standard fine-tuning techniques that are often used in combination with CNNs. These techniques have been thoroughly investigated in [3, 16, 25]. Chatfield et al. [3], in particular, analyse many variants of fine-tuning, including extensive data augmentation, on PASCAL VOC. They experiment with three architectures, VGG-F, VGG-M, and VGG- S; their fastest model VGG-F is comparable in speed and performance the Caffe reference model that we use here, whereas the other two networks are slower but more accurate. Their best result with VGG-S is 79.74% map on the PASCAL VOC 2007 test set before fine-tuning, and 82.44% with fine-tuning. The baseline Caffe model achieves 77.4% before fine-tuning and with the same fine-tuning of Chatfield et al.; however, when fine-tuned in the WSDDN configuration performance increases to 83.89% map, i.e. +1.5% better than the best fine-tuned model of Chatfield et al., which is based on a significantly better CNN. Most importantly, where traditional fine-tuning adds 2 3% points to the classification performance, fine-tuning with WSDDN improves twice as much, by 6.5% We finally compare WSDDN to the SPP-net [16] which uses the Overfeat-7 [29] with a 4-level spatial pyramid pooling layer {6 6, 3 3, 2 2, 1 1} for supervised object detection. While they do not perform fine-tuning, they include a spatial pooling layer. Applied to image classification, their best performance on PASCAL VOC 2007 is 80.10%, i.e. 3.84%. 4. Conclusions In this paper, we have presented WSDDN, a simple modification of a pre-trained CNN for image classification that allows it to perform weakly supervised detection. It achieves comparable or better performance than existing methods on weakly supervised detection, while requiring only fine-tuning on a target dataset using back-propagation and image-level labels. Since it works on top of a SPP layer, it is also efficient at training and test time. WS- DDN was also shown to perform better than traditional fine-tuning techniques to improve the performance of a pretrained CNN on the problem of image classification. We have identified the detection of object parts as a failure modality of the method, damaging its performance in selected object categories, and imputed that to the main criterion used to identify objects, namely the selection of highly-distinctive image regions. We are currently exploring complementary cues that would favor detecting complete objects instead. References [1] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with posterior regularization. In BMVC, [2] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with convex clustering. In CVPR. IEEE, [3] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In BMVC, [4] R.G. Cinbis, J. Verbeek, and C. Schmid. Multi-fold mil training for weakly supervised object localization. In CVPR, [5] T. Deselaers, B. Alexe, and V. Ferrari. Localizing objects while learning their appearance. In ECCV, pages Springer, [6] T. Deselaers, B. Alexe, and V. Ferrari. Weakly supervised localization and learning with generic knowledge. IJCV, 100(3): , 2012.
9 [7] Thomas G Dietterich, Richard H Lathrop, and Tomás Lozano-Pérez. Solving the multiple instance problem with axis-parallel rectangles. Artificial intelligence, 89(1):31 71, [8] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. Decaf: A deep convolutional activation feature for generic visual recognition [9] M. Everingham, A. Zisserman, C. K. I. Williams, and L. Van Gool. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. [10] P.F. Felzenszwalb, R.B. Girshick, D.A. McAllester, and D. Ramanan. Object detection with discriminatively trained part-based models. TPAMI, 32(9): , [11] R. Girshick. Fast RCNN. In arxiv, number arxiv: , [12] Ross Girshick. Fast r-cnn. arxiv preprint arxiv: , [13] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, pages IEEE, [14] Bharath Hariharan, Pablo Arbeláez, Ross Girshick, and Jitendra Malik. Simultaneous detection and segmentation. In Computer Vision ECCV 2014, pages Springer International Publishing, [15] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Computer Vision ECCV 2014, pages Springer, [17] Max Jaderberg, Karen Simonyan, Andrew Zisserman, and Koray Kavukcuoglu. Spatial transformer networks. NIPS 2015, [18] Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, pages ACM, [19] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C.J.C. Burges, L. Bottou, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages Curran Associates, Inc., [20] M.P. Kumar, B. Packer, and D. Koller. Self-paced learning for latent variable models. In NIPS, pages , [21] Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In CVPR, pages , [22] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11): , [23] Tsung-Yu Lin, Aruni RoyChowdhury, and Subhransu Maji. Bilinear cnn models for fine-grained visual recognition. In ICCV, [24] Y. Nesterov. Smooth minimization of non-smooth functions. Mathematical programming, 103(1): , [25] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Learning and transferring mid-level image representations using convolutional neural networks. In CVPR, [26] Maxime Oquab, Léon Bottou, Ivan Laptev, and Josef Sivic. Weakly supervised object recognition with convolutional neural networks [27] Maxime Oquab, Léon Bottou, Ivan Laptev, and Josef Sivic. Is object localization for free? weakly-supervised learning with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [28] F. Perronnin, J. Sánchez, and T. Mensink. Improving the fisher kernel for large-scale image classification. In ECCV, pages , [29] Pierre Sermanet, David Eigen, Xiang Zhang, Michaël Mathieu, Rob Fergus, and Yann LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arxiv preprint arxiv: , [30] Zhiyuan Shi, Timothy M Hospedales, and Tao Xiang. Bayesian joint topic modelling for weakly supervised object localisation. In ICCV, pages IEEE, [31] Zhiyuan Shi, Parthipan Siva, and Tony Xiang. Transfer learning by ranking for weakly supervised object annotation. In BMVC, volume 2, page 5, [32] Hyun O Song, Ross Girshick, Stefanie Jegelka, Julien Mairal, Zaid Harchaoui, and Trevor Darrell. On learning to localize objects with minimal supervision. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), pages , [33] Hyun Oh Song, Yong Jae Lee, Stefanie Jegelka, and Trevor Darrell. Weakly-supervised discovery of visual pattern configurations. In Advances in Neural Information Processing Systems, pages , [34] Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages IEEE, [35] JRR Uijlings, KEA van de Sande, T Gevers, and AWM Smeulders. Selective search for object recognition. International journal of computer vision, 104(2): , [36] A. Vedaldi and K. Lenc. Matconvnet convolutional neural networks for matlab [37] Chong Wang, Weiqiang Ren, Kaiqi Huang, and Tieniu Tan. Weakly supervised object localization with latent category learning. In ECCV 2014, volume 8694, pages , [38] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Object detectors emerge in deep scene CNNs
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
arxiv: v1 [cs.cv] 1 Apr 2017
![arxiv: v1 [cs.cv] 1 Apr 2017](/thumbs/88/117758340.jpg "arxiv: v1 [cs.cv] 1 Apr 2017") Multiple Instance Detection Network with Online Instance Classifier Refinement Peng Tang Xinggang Wang Xiang Bai Wenyu Liu School of EIC, Huazhong University of Science and Technology {pengtang,xgwang,xbai,liuwy}@hust.edu.cn
Multiple Instance Detection Network with Online Instance Classifier Refinement Peng Tang Xinggang Wang Xiang Bai Wenyu Liu School of EIC, Huazhong University of Science and Technology {pengtang,xgwang,xbai,liuwy}@hust.edu.cn
Weakly Supervised Object Detection with Convex Clustering
 Weakly Supervised Object Detection with Convex Clustering Hakan Bilen Marco Pedersoli Tinne Tuytelaars ESAT-PSI / iminds, VGG, Dept. of Eng. Sci. KU Leuven, Belgium University of Oxford firstname.lastname@esat.kuleuven.be
Weakly Supervised Object Detection with Convex Clustering Hakan Bilen Marco Pedersoli Tinne Tuytelaars ESAT-PSI / iminds, VGG, Dept. of Eng. Sci. KU Leuven, Belgium University of Oxford firstname.lastname@esat.kuleuven.be
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
CNN BASED REGION PROPOSALS FOR EFFICIENT OBJECT DETECTION. Jawadul H. Bappy and Amit K. Roy-Chowdhury
 CNN BASED REGION PROPOSALS FOR EFFICIENT OBJECT DETECTION Jawadul H. Bappy and Amit K. Roy-Chowdhury Department of Electrical and Computer Engineering, University of California, Riverside, CA 92521 ABSTRACT
CNN BASED REGION PROPOSALS FOR EFFICIENT OBJECT DETECTION Jawadul H. Bappy and Amit K. Roy-Chowdhury Department of Electrical and Computer Engineering, University of California, Riverside, CA 92521 ABSTRACT
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
arxiv: v3 [cs.cv] 13 Apr 2016 Abstract
![arxiv: v3 [cs.cv] 13 Apr 2016 Abstract](/thumbs/94/121926594.jpg "arxiv: v3 [cs.cv] 13 Apr 2016 Abstract") ProNet: Learning to Propose Object-specific Boxes for Cascaded Neural Networks Chen Sun 1,2 Manohar Paluri 2 Ronan Collobert 2 Ram Nevatia 1 Lubomir Bourdev 3 1 USC 2 Facebook AI Research 3 UC Berkeley
ProNet: Learning to Propose Object-specific Boxes for Cascaded Neural Networks Chen Sun 1,2 Manohar Paluri 2 Ronan Collobert 2 Ram Nevatia 1 Lubomir Bourdev 3 1 USC 2 Facebook AI Research 3 UC Berkeley
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Weakly Supervised Object Recognition with Convolutional Neural Networks
 GDR-ISIS, Paris March 20, 2015 Weakly Supervised Object Recognition with Convolutional Neural Networks Ivan Laptev ivan.laptev@inria.fr WILLOW, INRIA/ENS/CNRS, Paris Joint work with: Maxime Oquab Leon
GDR-ISIS, Paris March 20, 2015 Weakly Supervised Object Recognition with Convolutional Neural Networks Ivan Laptev ivan.laptev@inria.fr WILLOW, INRIA/ENS/CNRS, Paris Joint work with: Maxime Oquab Leon
Comparison of Fine-tuning and Extension Strategies for Deep Convolutional Neural Networks
 Comparison of Fine-tuning and Extension Strategies for Deep Convolutional Neural Networks Nikiforos Pittaras 1, Foteini Markatopoulou 1,2, Vasileios Mezaris 1, and Ioannis Patras 2 1 Information Technologies
Comparison of Fine-tuning and Extension Strategies for Deep Convolutional Neural Networks Nikiforos Pittaras 1, Foteini Markatopoulou 1,2, Vasileios Mezaris 1, and Ioannis Patras 2 1 Information Technologies
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Yiqi Yan. May 10, 2017
 Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
Yiqi Yan May 10, 2017 P a r t I F u n d a m e n t a l B a c k g r o u n d s Convolution Single Filter Multiple Filters 3 Convolution: case study, 2 filters 4 Convolution: receptive field receptive field
arxiv: v1 [cs.cv] 14 Sep 2016
![arxiv: v1 [cs.cv] 14 Sep 2016](/thumbs/83/87070407.jpg "arxiv: v1 [cs.cv] 14 Sep 2016") arxiv:1609.04331v1 [cs.cv] 14 Sep 2016 ContextLocNet: Context-Aware Deep Network Models for Weakly Supervised Localization Vadim Kantorov, Maxime Oquab, Minsu Cho, and Ivan Laptev WILLOW project team,
arxiv:1609.04331v1 [cs.cv] 14 Sep 2016 ContextLocNet: Context-Aware Deep Network Models for Weakly Supervised Localization Vadim Kantorov, Maxime Oquab, Minsu Cho, and Ivan Laptev WILLOW project team,
PASCAL VOC Classification: Local Features vs. Deep Features. Shuicheng YAN, NUS
 PASCAL VOC Classification: Local Features vs. Deep Features Shuicheng YAN, NUS PASCAL VOC Why valuable? Multi-label, Real Scenarios! Visual Object Recognition Object Classification Object Detection Object
PASCAL VOC Classification: Local Features vs. Deep Features Shuicheng YAN, NUS PASCAL VOC Why valuable? Multi-label, Real Scenarios! Visual Object Recognition Object Classification Object Detection Object
Fewer is More: Image Segmentation Based Weakly Supervised Object Detection with Partial Aggregation
 GE, WANG, QI: FEWER IS MORE 1 Fewer is More: Image Segmentation Based Weakly Supervised Object Detection with Partial Aggregation Ce Ge nwlgc@bupt.edu.cn Jingyu Wang wangjingyu@bupt.edu.cn Qi Qi qiqi@ebupt.com
GE, WANG, QI: FEWER IS MORE 1 Fewer is More: Image Segmentation Based Weakly Supervised Object Detection with Partial Aggregation Ce Ge nwlgc@bupt.edu.cn Jingyu Wang wangjingyu@bupt.edu.cn Qi Qi qiqi@ebupt.com
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Return of the Devil in the Details: Delving Deep into Convolutional Nets
 Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Category-level localization
 Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation
 Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation Md Atiqur Rahman and Yang Wang Department of Computer Science, University of Manitoba, Canada {atique, ywang}@cs.umanitoba.ca
Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation Md Atiqur Rahman and Yang Wang Department of Computer Science, University of Manitoba, Canada {atique, ywang}@cs.umanitoba.ca
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Actions and Attributes from Wholes and Parts
 Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Adapting Object Detectors from Images to Weakly Labeled Videos
 CHANDA, TEH, ROCHAN, GUO, WANG: ADAPTING OBJECT DETECTORS 1 Adapting Object Detectors from Images to Weakly Labeled Videos Omit Chanda 1 omitum@cs.umanitoba.ca Eu Wern Teh 1 umteht@cs.umanitoba.ca Mrigank
CHANDA, TEH, ROCHAN, GUO, WANG: ADAPTING OBJECT DETECTORS 1 Adapting Object Detectors from Images to Weakly Labeled Videos Omit Chanda 1 omitum@cs.umanitoba.ca Eu Wern Teh 1 umteht@cs.umanitoba.ca Mrigank
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Rare Chinese Character Recognition by Radical Extraction Network
 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC) Banff Center, Banff, Canada, October 5-8, 2017 Rare Chinese Character Recognition by Radical Extraction Network Ziang Yan, Chengzhe
2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC) Banff Center, Banff, Canada, October 5-8, 2017 Rare Chinese Character Recognition by Radical Extraction Network Ziang Yan, Chengzhe
Bilinear Models for Fine-Grained Visual Recognition
 Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Bilinear Models for Fine-Grained Visual Recognition Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst Fine-grained visual recognition Example: distinguish
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Rich feature hierarchies for accurate object detection and semantic segmentation Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik Presented by Pandian Raju and Jialin Wu Last class SGD for Document
Groupout: A Way to Regularize Deep Convolutional Neural Network
 Groupout: A Way to Regularize Deep Convolutional Neural Network Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Groupout is a new technique
Groupout: A Way to Regularize Deep Convolutional Neural Network Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Groupout is a new technique
A Novel Representation and Pipeline for Object Detection
 A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
A Novel Representation and Pipeline for Object Detection Vishakh Hegde Stanford University vishakh@stanford.edu Manik Dhar Stanford University dmanik@stanford.edu Abstract Object detection is an important
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v2 [cs.cv] 28 Jul 2017
![arxiv: v2 [cs.cv] 28 Jul 2017](/thumbs/95/125841841.jpg "arxiv: v2 [cs.cv] 28 Jul 2017") Exploiting Web Images for Weakly Supervised Object Detection Qingyi Tao Hao Yang Jianfei Cai Nanyang Technological University, Singapore arxiv:1707.08721v2 [cs.cv] 28 Jul 2017 Abstract In recent years,
Exploiting Web Images for Weakly Supervised Object Detection Qingyi Tao Hao Yang Jianfei Cai Nanyang Technological University, Singapore arxiv:1707.08721v2 [cs.cv] 28 Jul 2017 Abstract In recent years,
Multiple Instance Detection Network with Online Instance Classifier Refinement
 Multiple Instance Detection Network with Online Instance Classifier Refinement Peng Tang Xinggang Wang Xiang Bai Wenyu Liu School of EIC, Huazhong University of Science and Technology {pengtang,xgwang,xbai,liuwy}@hust.edu.cn
Multiple Instance Detection Network with Online Instance Classifier Refinement Peng Tang Xinggang Wang Xiang Bai Wenyu Liu School of EIC, Huazhong University of Science and Technology {pengtang,xgwang,xbai,liuwy}@hust.edu.cn
arxiv: v1 [cs.cv] 4 Jun 2015
![arxiv: v1 [cs.cv] 4 Jun 2015](/thumbs/92/109659580.jpg "arxiv: v1 [cs.cv] 4 Jun 2015") Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Weakly Supervised Object Localization with Progressive Domain Adaptation
 Weakly Supervised Object Localization with Progressive Domain Adaptation Dong Li 1, Jia-Bin Huang 2, Yali Li 1, Shengjin Wang 1, and Ming-Hsuan Yang 3 1 Tsinghua University, 2 University of Illinois, Urbana-Champaign,
Weakly Supervised Object Localization with Progressive Domain Adaptation Dong Li 1, Jia-Bin Huang 2, Yali Li 1, Shengjin Wang 1, and Ming-Hsuan Yang 3 1 Tsinghua University, 2 University of Illinois, Urbana-Champaign,
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
G-CNN: an Iterative Grid Based Object Detector
 G-CNN: an Iterative Grid Based Object Detector Mahyar Najibi 1, Mohammad Rastegari 1,2, Larry S. Davis 1 1 University of Maryland, College Park 2 Allen Institute for Artificial Intelligence najibi@cs.umd.edu
G-CNN: an Iterative Grid Based Object Detector Mahyar Najibi 1, Mohammad Rastegari 1,2, Larry S. Davis 1 1 University of Maryland, College Park 2 Allen Institute for Artificial Intelligence najibi@cs.umd.edu
LSDA: Large Scale Detection through Adaptation
 LSDA: Large Scale Detection through Adaptation Judy Hoffman, Sergio Guadarrama, Eric Tzeng, Ronghang Hu, Jeff Donahue, EECS, UC Berkeley, EE, Tsinghua University {jhoffman, sguada, tzeng, jdonahue}@eecs.berkeley.edu
LSDA: Large Scale Detection through Adaptation Judy Hoffman, Sergio Guadarrama, Eric Tzeng, Ronghang Hu, Jeff Donahue, EECS, UC Berkeley, EE, Tsinghua University {jhoffman, sguada, tzeng, jdonahue}@eecs.berkeley.edu
Object Detection. TA : Young-geun Kim. Biostatistics Lab., Seoul National University. March-June, 2018
 Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Object Detection TA : Young-geun Kim Biostatistics Lab., Seoul National University March-June, 2018 Seoul National University Deep Learning March-June, 2018 1 / 57 Index 1 Introduction 2 R-CNN 3 YOLO 4
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Object Recognition II
 Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Learning From Weakly Supervised Data by The Expectation Loss SVM (e-svm) algorithm
 algorithm") Learning From Weakly Supervised Data by The Expectation Loss SVM (e-svm) algorithm Jun Zhu Department of Statistics University of California, Los Angeles jzh@ucla.edu Junhua Mao Department of Statistics
Learning From Weakly Supervised Data by The Expectation Loss SVM (e-svm) algorithm Jun Zhu Department of Statistics University of California, Los Angeles jzh@ucla.edu Junhua Mao Department of Statistics
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b
 5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) An Object Detection Algorithm based on Deformable Part Models with Bing Features Chunwei Li1, a and Youjun Bu1, b 1
Robust Scene Classification with Cross-level LLC Coding on CNN Features
 Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Learning the Structure of Deep Architectures Using l 1 Regularization
 KULKARNI ET AL.: LEARNING THE STRUCTURE OF DEEP ARCHITECTURES 1 Learning the Structure of Deep Architectures Using l 1 Regularization Praveen Kulkarni 1 Praveen.Kulkarni@technicolor.com Joaquin Zepeda
KULKARNI ET AL.: LEARNING THE STRUCTURE OF DEEP ARCHITECTURES 1 Learning the Structure of Deep Architectures Using l 1 Regularization Praveen Kulkarni 1 Praveen.Kulkarni@technicolor.com Joaquin Zepeda
Visual features detection based on deep neural network in autonomous driving tasks
 430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
430 Fomin I., Gromoshinskii D., Stepanov D. Visual features detection based on deep neural network in autonomous driving tasks Ivan Fomin, Dmitrii Gromoshinskii, Dmitry Stepanov Computer vision lab Russian
Segmentation as Selective Search for Object Recognition in ILSVRC2011
 Segmentation as Selective Search for Object Recognition in ILSVRC2011 Koen van de Sande Jasper Uijlings Arnold Smeulders Theo Gevers Nicu Sebe Cees Snoek University of Amsterdam, University of Trento ILSVRC2011
Segmentation as Selective Search for Object Recognition in ILSVRC2011 Koen van de Sande Jasper Uijlings Arnold Smeulders Theo Gevers Nicu Sebe Cees Snoek University of Amsterdam, University of Trento ILSVRC2011
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Weakly Supervised Region Proposal Network and Object Detection
 Weakly Supervised Region Proposal Network and Object Detection Peng Tang, Xinggang Wang, Angtian Wang, Yongluan Yan, Wenyu Liu ( ), Junzhou Huang 2,3, Alan Yuille 4 School of EIC, Huazhong University of
Weakly Supervised Region Proposal Network and Object Detection Peng Tang, Xinggang Wang, Angtian Wang, Yongluan Yan, Wenyu Liu ( ), Junzhou Huang 2,3, Alan Yuille 4 School of EIC, Huazhong University of
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
arxiv: v2 [cs.cv] 1 Oct 2014
![arxiv: v2 [cs.cv] 1 Oct 2014](/thumbs/76/73373319.jpg "arxiv: v2 [cs.cv] 1 Oct 2014") Deformable Part Models are Convolutional Neural Networks Tech report Ross Girshick Forrest Iandola Trevor Darrell Jitendra Malik UC Berkeley {rbg,forresti,trevor,malik}@eecsberkeleyedu arxiv:14095403v2
Deformable Part Models are Convolutional Neural Networks Tech report Ross Girshick Forrest Iandola Trevor Darrell Jitendra Malik UC Berkeley {rbg,forresti,trevor,malik}@eecsberkeleyedu arxiv:14095403v2
TS 2 C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection
 TS 2 C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection Yunchao Wei 1, Zhiqiang Shen 1,2, Bowen Cheng 1, Honghui Shi 3, Jinjun Xiong 3, Jiashi Feng 4, and
TS 2 C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection Yunchao Wei 1, Zhiqiang Shen 1,2, Bowen Cheng 1, Honghui Shi 3, Jinjun Xiong 3, Jiashi Feng 4, and
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
arxiv: v1 [cs.cv] 13 Jul 2018
![arxiv: v1 [cs.cv] 13 Jul 2018](/thumbs/93/114369399.jpg "arxiv: v1 [cs.cv] 13 Jul 2018") arxiv:1807.04897v1 [cs.cv] 13 Jul 2018 TS 2 C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection Yunchao Wei 1, Zhiqiang Shen 1,2, Bowen Cheng 1, Honghui Shi
arxiv:1807.04897v1 [cs.cv] 13 Jul 2018 TS 2 C: Tight Box Mining with Surrounding Segmentation Context for Weakly Supervised Object Detection Yunchao Wei 1, Zhiqiang Shen 1,2, Bowen Cheng 1, Honghui Shi
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset
 Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Bag-of-features. Cordelia Schmid
 Bag-of-features for category classification Cordelia Schmid Visual search Particular objects and scenes, large databases Category recognition Image classification: assigning a class label to the image
Bag-of-features for category classification Cordelia Schmid Visual search Particular objects and scenes, large databases Category recognition Image classification: assigning a class label to the image
Final Report: Smart Trash Net: Waste Localization and Classification
 Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Final Report: Smart Trash Net: Waste Localization and Classification Oluwasanya Awe oawe@stanford.edu Robel Mengistu robel@stanford.edu December 15, 2017 Vikram Sreedhar vsreed@stanford.edu Abstract Given
Deep Learning for Object detection & localization
 Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
CS 1674: Intro to Computer Vision. Object Recognition. Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018
 CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
CS 1674: Intro to Computer Vision Object Recognition Prof. Adriana Kovashka University of Pittsburgh April 3, 5, 2018 Different Flavors of Object Recognition Semantic Segmentation Classification + Localization
How hard can it be? Estimating the difficulty of visual search in an image
 How hard can it be? Estimating the difficulty of visual search in an image Radu Tudor Ionescu 1, Bogdan Alexe 1,4, Marius Leordeanu 3, Marius Popescu 1, Dim P. Papadopoulos 2, Vittorio Ferrari 2 1 University
How hard can it be? Estimating the difficulty of visual search in an image Radu Tudor Ionescu 1, Bogdan Alexe 1,4, Marius Leordeanu 3, Marius Popescu 1, Dim P. Papadopoulos 2, Vittorio Ferrari 2 1 University
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Subspace Alignment Based Domain Adaptation for RCNN Detector
 RAJ, NAMBOODIRI, TUYTELAARS: ADAPTING RCNN DETECTOR 1 Subspace Alignment Based Domain Adaptation for RCNN Detector Anant Raj anantraj@iitk.ac.in Vinay P. Namboodiri vinaypn@iitk.ac.in Tinne Tuytelaars
RAJ, NAMBOODIRI, TUYTELAARS: ADAPTING RCNN DETECTOR 1 Subspace Alignment Based Domain Adaptation for RCNN Detector Anant Raj anantraj@iitk.ac.in Vinay P. Namboodiri vinaypn@iitk.ac.in Tinne Tuytelaars
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
OBJECT detection is one of the most important problems
 JOURNAL OF L A T E X CLASS FILES 1 PCL: Proposal Cluster Learning for Weakly Supervised Object Detection Peng Tang, Xinggang Wang, Member, IEEE, Song Bai, Wei Shen, Xiang Bai, Senior Member, IEEE, Wenyu
JOURNAL OF L A T E X CLASS FILES 1 PCL: Proposal Cluster Learning for Weakly Supervised Object Detection Peng Tang, Xinggang Wang, Member, IEEE, Song Bai, Wei Shen, Xiang Bai, Senior Member, IEEE, Wenyu
DD2427 Final Project Report. Human face attributes prediction with Deep Learning
 DD2427 Final Project Report Human face attributes prediction with Deep Learning Abstract moaah@kth.se We explore using deep Convolutional Neural Networks (CNN) to predict human attributes like skin tune,
DD2427 Final Project Report Human face attributes prediction with Deep Learning Abstract moaah@kth.se We explore using deep Convolutional Neural Networks (CNN) to predict human attributes like skin tune,
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Convolutional Neural Network Layer Reordering for Acceleration
 R1-15 SASIMI 2016 Proceedings Convolutional Neural Network Layer Reordering for Acceleration Vijay Daultani Subhajit Chaudhury Kazuhisa Ishizaka System Platform Labs Value Co-creation Center System Platform
R1-15 SASIMI 2016 Proceedings Convolutional Neural Network Layer Reordering for Acceleration Vijay Daultani Subhajit Chaudhury Kazuhisa Ishizaka System Platform Labs Value Co-creation Center System Platform