CSE Data Mining Concepts and Techniques STATISTICAL METHODS (REGRESSION) Professor- Anita Wasilewska. Team 13
|
|
|
- Loreen Patrick
- 5 years ago
- Views:
Transcription
1 CSE Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13
2 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit Methods to prevent Overfitting Regularization Methods (Lasso and Ridge regression) Research Paper Harsha Neelaabh Dixita Dixita Ayush Ayush Rohan
3 References - Lecture Slides - Lecture Slides www3.cs.stonybrook.edu/~has/cse545/slides/ pdf
4 1 Regression Techniques

5 1 Linear Regression Method of Prediction
6 What is Linear Regression? Commonly used Predictive analysis technique Linear approach for modelling the relationship between a dependent variable y and one or more independent variables denoted by X Simple Linear Regression - 1 dependent variable, 1 independent variable Multiple Linear Regression - 1 dependent variable, 2 or more independent variables.
7 Therefore y= x Simple Regression- Calculating the regression line x y x- x y-y (x - x)² (x - x)(y-y) x = 3 y = PREDICTED y=b₀ + b₁x b₁ = 6/10 = 0.6 b₀ = y - b₁ x b₀ = 2.2
8 Finding the Line of Best Fit
9 Assessing the fit of Regression Models Residual Y - Predicted Y SSE (The sum of the squared residuals ) SST (Total sum of squares) SSR(Sum of Squares regression)
10 Model Evaluation Error Metrics 1. R squared (Coefficient of Determination) When R 2 value is 1, model perfectly fits the data. 1. Mean Squared Error When MSE is 0, model perfectly fits the data.

11 Logistic Regression Method of Classification
12 Background We re more often interested in making categorical assignments. Does this belong in the spam folder or the inbox? (Spam/Inbox) How likely is this customer to sign up for subscription service? (Yes/No) Does a patient have a particular disease? (Yes/No) When we are interested in either assigning data-points to categories we call this task classification. The simplest kind of classification problem is binary classification, when there are only two classes.
13 The convention for binary classification is to have two classes 0 and 1. We can t use a normal linear regression model on binary groups. It won t lead to a good fit.
14 A regular linear model is a poor choice here because it can output values greater than 1 or less than 0. Therefore, we can transform our linear regression to a logistic regression curve.
15 To build a correct classification model, we modify it slightly, by running the linear regression function through a sigmoid activation function σ. ŷ =σ(β 0 + β 1 x) The sigmoid function σ, sometimes called a squashing function or a logistic function - thus the name logistic regression - maps a real-valued input to the range 0 to 1. Specifically, it has the functional form:
16 This means we can take our Linear Regression Solution and place it into the Sigmoid Function. This results in a probability from 0 to 1 of belonging in a class.
17 We can set a cutoff point at 0.5, anything below it results in class 0, anything above is class 1. z We use the logistic function to output a value ranging from 0 to 1. Based off of this probability we assign a class.
18 Model Evaluation The following steps should be taken to create a Logistic Regression model to classify a feature in a dataset: 1. Divide the data into training and testing datasets. We can do this manually by keeping a certain amount (let s say 30%) of the data as test data. One good way of running the model is by using k-fold cross validation. 2. After you train a logistic regression model on some training data, we evaluate our model s performance on test data. 3. We can use a confusion matrix and some metrics like Precision, Recall, F- Score to evaluate classification models.
19 Confusion Matrix A confusion matrix is a table that is often used to describe the performance of a classification model (or "classifier") on a set of test data for which the true values are known. We can infer that: 1. There are two possible predicted classes: "yes" and "no". (having disease or not having disease) 2. The classifier made a total of 165 predictions 3. Out of those 165 cases, the classifier predicted "yes" 110 times, and "no" 55 times. 4. In reality, 105 patients in the sample have the disease, and 60 patients do not. Example:
20 Let s define the most basic terms: TP TN TRUE POSITIVES We predicted YES, and they do have the disease TRUE NEGATIVES We predicted NO, and they don t have the disease FP FN FALSE POSITIVES We predicted YES, but they don't actually have the disease. (Also known as a "Type I error.") FALSE NEGATIVES We predicted NO, but they actually do have the disease. (Also known as a "Type II error.")
21 Therefore, we can modify the confusion matrix as: Some important metrics can be calculated from the confusion matrix. False Positive Rate: When it's actually NO, how often does it predict yes? FP/actual NO = 10/60 = 0.17 Precision: When it predicts yes, how often is it correct? TP/predicted YES = 100/110 = 0.91 Accuracy: Overall, how often is the classifier correct? (TP+TN)/total = (100+50)/165 = 0.91 Misclassification Rate: Overall, how often is it wrong? (FP+FN)/total = (10+5)/165 = 0.09 equivalent to (1 - Accuracy) also known as "Error Rate" True Positive Rate: When it's actually YES, how often does it predict YES? TP/actual YES = 100/105 = 0.95 Also known as "Sensitivity" or "Recall"

22 Type I and Type II error in a nutshell...
23 ROC Curve The receiver operating characteristic (ROC) curve is another common tool used with binary classifiers. The dotted line represents the ROC curve of a purely random classifier; a good classifier stays as far away from that line as possible (toward the top-left corner).

24 Logistic Regression Example We have an advertising data set, indicating whether or not a particular internet user clicked on an Advertisement on a company website. We will try to create a model that will predict whether or not they will click on an ad (Class attribute) based off the features of that user.

25 Classification Model: Confusion Matrix: Classification Report Class Precision Recall F1-Score Support Average/Total

26 ROC Curve for the model: The ROC model is much far away from the dotted line. Thus, we ve built a pretty good classifier.

27 What about the Error?
28 Bias & Variance
=Bias 2 +Variance+Irreducible Error")
29 Error due to bias: Difference between the expected Bias prediction Error value of the model and the actual value Error due to variance: Variability of a model prediction from a given point Bias is how displaced a model's predictions are from correct values, while Variance is the degree to which these predictions vary between model iterations Err(x)=Bias 2 +Variance+Irreducible Error
30 Model Fit
31 Underfitting A statistical model or a machine learning algorithm is said to be underfitting when it cannot capture the underlying trend of the data. It usually happens when we have less data to build an accurate model and also when we try to build a linear model with a non-linear data. Underfitting can be avoided by using more data and also reducing the features by feature selection
32 Overfitting Overfitting occurs when a model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data Model is subject to low bias, but high variance Too much data and complex models result in overfitting
33 Methods to prevent Overfitting

34 Cross Validation This is a cross-validation used to prevent the overlap of the test sets First step: split data into k disjoint subsets : D1, Dk, of equal size, called folds Second step: use each subset in turn for testing, the remainder for training Training and testing is performed k times
35 Early Stopping Split the training data into a training set and a validation set, e.g. in a 2-to-1 proportion. Train only on the training set and evaluate the per-example error on the validation set once in a while, e.g. after every fifth epoch. Stop training as soon as the error on the validation set is higher than it was the last time it was checked. Use the weights the network had in that previous step as the result of the training run.

36 Pruning The process of adjusting decision trees to minimize Misclassification Error. The replacement takes place if a decision rule establishes that the expected error rate in the subtree is greater than in the single leaf.
37 Shrinkage/Regularization These methods constrain or shrink the coefficient estimates towards zero If there is noise in the training data, then the estimated coefficients won t generalize well to the future data Help to avoid overfitting and will perform at the same time feature selection for certain regularization norms
38 Ridge & LASSO Regression
39 Ridge Regression If all the weights are unconstrained, they are susceptible to high variance The Ridge Penalization will force the parameters to be relatively small The bigger the penalization, the smaller the coefficients are
40 Ordinary Least Squares objective: Bias Error Ridge Regression: where λ is the tuning parameter which controls the strength of the penalty term
41 Pros & Cons PROS CONS Ridge regression can reduce the variance Can improve predictive performance Mathematically simple computations Ridge regression is not able to shrink coefficients to exactly zero As a result, it cannot perform attribute selection Alternative: LASSO Regression
42 Lasso Regression L Least A Attribute S Selection and S Shrinkage O Operator Supervised Technique useful for attribute selection and to prevent overfitting training data Penalized regression method

43 How it works Penalizes the sum of absolute value of weights found by the regression. There are two methods to add constraints to add penalty: Constraints shrink some weights to zero λ is tuning parameter chosen by cross validation
44 Properties & Advantages of LASSO Properties Useful when number of classes is very less than number of attributes Makes the model sparser and reduces the possibility of overfitting Advantages Improves the prediction accuracy and interpretability of regression models For feature selection, LASSO uses convex optimization to find best features. So, it converges faster. Convenient when we want some automatic feature/variable selection
45 2 Miftar Application of Logistic Regression in the Study of Students Performance Level Ramosacaj, Dr. Vjollca Hasani, Dr. Alba Dumi Journal of Educational and Social Research MCSER Publishing, Rome- Italy, Vol. 5 No. 3 September 2015 Paper Link
46 Introduction Aim- Predict students performance level in first semester of studies Classification Method- Logistic Regression Analysis Assumption Made - 1. The number of credits gained after first semester signify the performance of the student 2. Class Attribute is based on the number of credits gained after first semester: a. Y=1 that is > 30 credits Good Performer b. Y=0 that is < 30 credits Low Performer
47 Identified Attributes Dependent/Class Attribute Independent/Classifier Attribute Attributes with insignificant impact (ignored in regression) Credits Gained (Binary) 1. > 30 Credits 0. < 30 Credits Social Environment (Non-Binary) 1. Stressful 2. Not Stressful 3. Very Stressful High School Points (Non-Binary) Gender (Binary) 1. Female 0. Male Student Location (Binary) 1. Urban Area 0. Village Type of School (Binary) 1. Private 0. Public School Location (Binary) 1. Urban Area 0. Village
48 Class/Dependent Attribute Distribution Data collected via Questionnaires filled by 240 Freshmen
 http://www.mcser.org/journal/index.")
49 Two Categories of Students Based on First Semester Results (Class/Dependent Attribute)
50 Few observations made on the Classifier Attributes Data collected via Questionnaires filled by 240 Freshmen


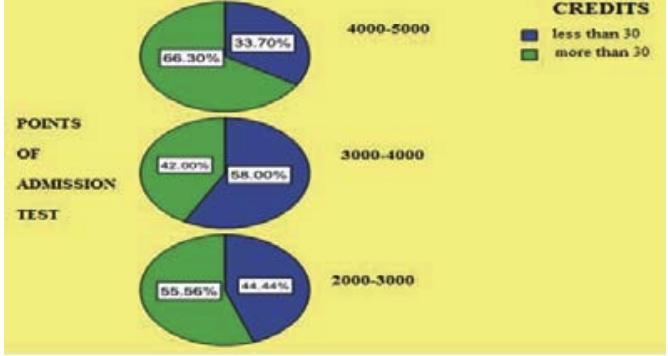
51 Gender Stress Level High School Points
52 Logistic Regression Process General form of Logistic Regression Equation: Logistic Regression equation for our problem after removal of insignificant attributes (using significant score): & α= 0.54
53 Logistic Regression Process & α= 0.54 Y=1 when θ > 0.5 => that is Passed credits > 30 (Student is a good performer) Y=0 when θ < 0.5 => that is Passed credits < 30 (Student is a bad performer) x 1 = Gender (β i = -0.91) x 5 = High School Points (β 5 = -0.47) x 6 = Student Location (β 6 = 0.62) x 7 = Stress Level (Social Environment) (β 7 = 0.45)

54 ...What we want is a Machine that can Learn from experience -Alan Turing (1947) What was their conclusion? Was it good enough? Let s look at some of their findings!








55 LOGISTIC REGRESSION ANALYSIS 01 Female Students perform better than male counterparts Environment where they live in is far from being appropriate for the research High school results positively affect the student performance in first semester Creating non stressful conditions positively contributes to increasing student performance

56
INTRODUCTION TO MACHINE LEARNING. Measuring model performance or error
 INTRODUCTION TO MACHINE LEARNING Measuring model performance or error Is our model any good? Context of task Accuracy Computation time Interpretability 3 types of tasks Classification Regression Clustering
INTRODUCTION TO MACHINE LEARNING Measuring model performance or error Is our model any good? Context of task Accuracy Computation time Interpretability 3 types of tasks Classification Regression Clustering
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University January 24 2019 Logistics HW 1 is due on Friday 01/25 Project proposal: due Feb 21 1 page description
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 20 2018 Review Solution for multiple linear regression can be computed in closed form
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 13: Model selection and regularization
 Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Introduction to Automated Text Analysis. bit.ly/poir599
 Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Evaluating Classifiers
 Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Evaluating Classifiers Reading for this topic: T. Fawcett, An introduction to ROC analysis, Sections 1-4, 7 (linked from class website) Evaluating Classifiers What we want: Classifier that best predicts
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation. Evaluate what? For really large amounts of data... A: Use a validation set.
 Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
DATA MINING AND MACHINE LEARNING. Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
CSE446: Linear Regression. Spring 2017
 CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
Performance Estimation and Regularization. Kasthuri Kannan, PhD. Machine Learning, Spring 2018
 Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
FMA901F: Machine Learning Lecture 3: Linear Models for Regression. Cristian Sminchisescu
 FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
FMA901F: Machine Learning Lecture 3: Linear Models for Regression Cristian Sminchisescu Machine Learning: Frequentist vs. Bayesian In the frequentist setting, we seek a fixed parameter (vector), with value(s)
Large Scale Data Analysis Using Deep Learning
 Large Scale Data Analysis Using Deep Learning Machine Learning Basics - 1 U Kang Seoul National University U Kang 1 In This Lecture Overview of Machine Learning Capacity, overfitting, and underfitting
Large Scale Data Analysis Using Deep Learning Machine Learning Basics - 1 U Kang Seoul National University U Kang 1 In This Lecture Overview of Machine Learning Capacity, overfitting, and underfitting
Classification. Instructor: Wei Ding
 Classification Part II Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1 Practical Issues of Classification Underfitting and Overfitting Missing Values Costs of Classification
Classification Part II Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1 Practical Issues of Classification Underfitting and Overfitting Missing Values Costs of Classification
5 Learning hypothesis classes (16 points)
") 5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
5 Learning hypothesis classes (16 points) Consider a classification problem with two real valued inputs. For each of the following algorithms, specify all of the separators below that it could have generated
Logistic Regression: Probabilistic Interpretation
 Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
Logistic Regression: Probabilistic Interpretation Approximate 0/1 Loss Logistic Regression Adaboost (z) SVM Solution: Approximate 0/1 loss with convex loss ( surrogate loss) 0-1 z = y w x SVM (hinge),
Model selection and validation 1: Cross-validation
 Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Evaluating Classifiers
 Evaluating Classifiers Charles Elkan elkan@cs.ucsd.edu January 18, 2011 In a real-world application of supervised learning, we have a training set of examples with labels, and a test set of examples with
Evaluating Classifiers Charles Elkan elkan@cs.ucsd.edu January 18, 2011 In a real-world application of supervised learning, we have a training set of examples with labels, and a test set of examples with
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Knowledge Discovery and Data Mining Lecture 10 - Classification trees Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey
Lecture 3: Linear Classification
 Lecture 3: Linear Classification Roger Grosse 1 Introduction Last week, we saw an example of a learning task called regression. There, the goal was to predict a scalar-valued target from a set of features.
Lecture 3: Linear Classification Roger Grosse 1 Introduction Last week, we saw an example of a learning task called regression. There, the goal was to predict a scalar-valued target from a set of features.
Evaluating Machine-Learning Methods. Goals for the lecture
 Evaluating Machine-Learning Methods Mark Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from
Evaluating Machine-Learning Methods Mark Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from
Lasso. November 14, 2017
 Lasso November 14, 2017 Contents 1 Case Study: Least Absolute Shrinkage and Selection Operator (LASSO) 1 1.1 The Lasso Estimator.................................... 1 1.2 Computation of the Lasso Solution............................
Lasso November 14, 2017 Contents 1 Case Study: Least Absolute Shrinkage and Selection Operator (LASSO) 1 1.1 The Lasso Estimator.................................... 1 1.2 Computation of the Lasso Solution............................
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation
 4 Model, Classification 4 Model, Regression 4 Representation") Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Weka ( )
") Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
Weka ( http://www.cs.waikato.ac.nz/ml/weka/ ) The phases in which classifier s design can be divided are reflected in WEKA s Explorer structure: Data pre-processing (filtering) and representation Supervised
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS
 DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes and a class attribute
DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes and a class attribute
CSE 158 Lecture 2. Web Mining and Recommender Systems. Supervised learning Regression
 CSE 158 Lecture 2 Web Mining and Recommender Systems Supervised learning Regression Supervised versus unsupervised learning Learning approaches attempt to model data in order to solve a problem Unsupervised
CSE 158 Lecture 2 Web Mining and Recommender Systems Supervised learning Regression Supervised versus unsupervised learning Learning approaches attempt to model data in order to solve a problem Unsupervised
CSE 446 Bias-Variance & Naïve Bayes
 CSE 446 Bias-Variance & Naïve Bayes Administrative Homework 1 due next week on Friday Good to finish early Homework 2 is out on Monday Check the course calendar Start early (midterm is right before Homework
CSE 446 Bias-Variance & Naïve Bayes Administrative Homework 1 due next week on Friday Good to finish early Homework 2 is out on Monday Check the course calendar Start early (midterm is right before Homework
Evaluation Metrics. (Classifiers) CS229 Section Anand Avati
 CS229 Section Anand Avati") Evaluation Metrics (Classifiers) CS Section Anand Avati Topics Why? Binary classifiers Metrics Rank view Thresholding Confusion Matrix Point metrics: Accuracy, Precision, Recall / Sensitivity, Specificity,
Evaluation Metrics (Classifiers) CS Section Anand Avati Topics Why? Binary classifiers Metrics Rank view Thresholding Confusion Matrix Point metrics: Accuracy, Precision, Recall / Sensitivity, Specificity,
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
ML4Bio Lecture #1: Introduc3on. February 24 th, 2016 Quaid Morris
 ML4Bio Lecture #1: Introduc3on February 24 th, 216 Quaid Morris Course goals Prac3cal introduc3on to ML Having a basic grounding in the terminology and important concepts in ML; to permit self- study,
ML4Bio Lecture #1: Introduc3on February 24 th, 216 Quaid Morris Course goals Prac3cal introduc3on to ML Having a basic grounding in the terminology and important concepts in ML; to permit self- study,
Machine Learning: Think Big and Parallel
 Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
Day 1 Inderjit S. Dhillon Dept of Computer Science UT Austin CS395T: Topics in Multicore Programming Oct 1, 2013 Outline Scikit-learn: Machine Learning in Python Supervised Learning day1 Regression: Least
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates?
 Model Evaluation Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates? Methods for Model Comparison How to
Model Evaluation Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates? Methods for Model Comparison How to
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
ECLT 5810 Evaluation of Classification Quality
 ECLT 5810 Evaluation of Classification Quality Reference: Data Mining Practical Machine Learning Tools and Techniques, by I. Witten, E. Frank, and M. Hall, Morgan Kaufmann Testing and Error Error rate:
ECLT 5810 Evaluation of Classification Quality Reference: Data Mining Practical Machine Learning Tools and Techniques, by I. Witten, E. Frank, and M. Hall, Morgan Kaufmann Testing and Error Error rate:
Chapter 7: Numerical Prediction
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 7: Numerical Prediction Lecture: Prof. Dr.
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Chapter 7: Numerical Prediction Lecture: Prof. Dr.
Leveling Up as a Data Scientist. ds/2014/10/level-up-ds.jpg
 Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
Linear Regression & Gradient Descent
 Linear Regression & Gradient Descent These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online.
Linear Regression & Gradient Descent These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online.
Cross-validation for detecting and preventing overfitting
 Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class
 Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
Mini-project 2 CMPSCI 689 Spring 2015 Due: Tuesday, April 07, in class Guidelines Submission. Submit a hardcopy of the report containing all the figures and printouts of code in class. For readability
CS4491/CS 7265 BIG DATA ANALYTICS
 CS4491/CS 7265 BIG DATA ANALYTICS EVALUATION * Some contents are adapted from Dr. Hung Huang and Dr. Chengkai Li at UT Arlington Dr. Mingon Kang Computer Science, Kennesaw State University Evaluation for
CS4491/CS 7265 BIG DATA ANALYTICS EVALUATION * Some contents are adapted from Dr. Hung Huang and Dr. Chengkai Li at UT Arlington Dr. Mingon Kang Computer Science, Kennesaw State University Evaluation for
Simple Model Selection Cross Validation Regularization Neural Networks
 Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS
 LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
Classification Part 4
 Classification Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Model Evaluation Metrics for Performance Evaluation How to evaluate
Classification Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Model Evaluation Metrics for Performance Evaluation How to evaluate
The Basics of Decision Trees
 Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Predict the Likelihood of Responding to Direct Mail Campaign in Consumer Lending Industry
 Predict the Likelihood of Responding to Direct Mail Campaign in Consumer Lending Industry Jincheng Cao, SCPD Jincheng@stanford.edu 1. INTRODUCTION When running a direct mail campaign, it s common practice
Predict the Likelihood of Responding to Direct Mail Campaign in Consumer Lending Industry Jincheng Cao, SCPD Jincheng@stanford.edu 1. INTRODUCTION When running a direct mail campaign, it s common practice
Variable Selection 6.783, Biomedical Decision Support
 6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
6.783, Biomedical Decision Support (lrosasco@mit.edu) Department of Brain and Cognitive Science- MIT November 2, 2009 About this class Why selecting variables Approaches to variable selection Sparsity-based
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Machine Learning / Jan 27, 2010
 Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Revisiting Logistic Regression & Naïve Bayes Aarti Singh Machine Learning 10-701/15-781 Jan 27, 2010 Generative and Discriminative Classifiers Training classifiers involves learning a mapping f: X -> Y,
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
CSC 411: Lecture 02: Linear Regression
 CSC 411: Lecture 02: Linear Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 16, 2015 Urtasun & Zemel (UofT) CSC 411: 02-Regression Sep 16, 2015 1 / 16 Today Linear regression problem continuous
CSC 411: Lecture 02: Linear Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 16, 2015 Urtasun & Zemel (UofT) CSC 411: 02-Regression Sep 16, 2015 1 / 16 Today Linear regression problem continuous
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Fast or furious? - User analysis of SF Express Inc
 CS 229 PROJECT, DEC. 2017 1 Fast or furious? - User analysis of SF Express Inc Gege Wen@gegewen, Yiyuan Zhang@yiyuan12, Kezhen Zhao@zkz I. MOTIVATION The motivation of this project is to predict the likelihood
CS 229 PROJECT, DEC. 2017 1 Fast or furious? - User analysis of SF Express Inc Gege Wen@gegewen, Yiyuan Zhang@yiyuan12, Kezhen Zhao@zkz I. MOTIVATION The motivation of this project is to predict the likelihood
CS294-1 Assignment 2 Report
 CS294-1 Assignment 2 Report Keling Chen and Huasha Zhao February 24, 2012 1 Introduction The goal of this homework is to predict a users numeric rating for a book from the text of the user s review. The
CS294-1 Assignment 2 Report Keling Chen and Huasha Zhao February 24, 2012 1 Introduction The goal of this homework is to predict a users numeric rating for a book from the text of the user s review. The
Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
CPSC 340: Machine Learning and Data Mining. More Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
Machine Learning and Bioinformatics 機器學習與生物資訊學
 Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Data Mining: Classifier Evaluation. CSCI-B490 Seminar in Computer Science (Data Mining)
") Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
SUPERVISED LEARNING METHODS. Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018
 SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
SUPERVISED LEARNING METHODS Stanley Liang, PhD Candidate, Lassonde School of Engineering, York University Helix Science Engagement Programs 2018 2 CHOICE OF ML You cannot know which algorithm will work
Lasso Regression: Regularization for feature selection
 Lasso Regression: Regularization for feature selection CSE 416: Machine Learning Emily Fox University of Washington April 12, 2018 Symptom of overfitting 2 Often, overfitting associated with very large
Lasso Regression: Regularization for feature selection CSE 416: Machine Learning Emily Fox University of Washington April 12, 2018 Symptom of overfitting 2 Often, overfitting associated with very large
Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
I211: Information infrastructure II
 Data Mining: Classifier Evaluation I211: Information infrastructure II 3-nearest neighbor labeled data find class labels for the 4 data points 1 0 0 6 0 0 0 5 17 1.7 1 1 4 1 7.1 1 1 1 0.4 1 2 1 3.0 0 0.1
Data Mining: Classifier Evaluation I211: Information infrastructure II 3-nearest neighbor labeled data find class labels for the 4 data points 1 0 0 6 0 0 0 5 17 1.7 1 1 4 1 7.1 1 1 1 0.4 1 2 1 3.0 0 0.1
Linear Model Selection and Regularization. especially usefull in high dimensions p>>100.
 Linear Model Selection and Regularization especially usefull in high dimensions p>>100. 1 Why Linear Model Regularization? Linear models are simple, BUT consider p>>n, we have more features than data records
Linear Model Selection and Regularization especially usefull in high dimensions p>>100. 1 Why Linear Model Regularization? Linear models are simple, BUT consider p>>n, we have more features than data records
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining and Knowledge Discovery Practice notes 2
 Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
Keywords Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si Data Attribute, example, attribute-value data, target variable, class, discretization Algorithms
DS Machine Learning and Data Mining I. Alina Oprea Associate Professor, CCIS Northeastern University
 DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 18 2018 Logistics HW 1 is on Piazza and Gradescope Deadline: Friday, Sept. 28, 2018 Office
DS 4400 Machine Learning and Data Mining I Alina Oprea Associate Professor, CCIS Northeastern University September 18 2018 Logistics HW 1 is on Piazza and Gradescope Deadline: Friday, Sept. 28, 2018 Office
Classification and Regression Trees
 Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
Classification and Regression Trees David S. Rosenberg New York University April 3, 2018 David S. Rosenberg (New York University) DS-GA 1003 / CSCI-GA 2567 April 3, 2018 1 / 51 Contents 1 Trees 2 Regression
EE 511 Linear Regression
 EE 511 Linear Regression Instructor: Hanna Hajishirzi hannaneh@washington.edu Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Announcements Hw1 due
EE 511 Linear Regression Instructor: Hanna Hajishirzi hannaneh@washington.edu Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Announcements Hw1 due
2. On classification and related tasks
 2. On classification and related tasks In this part of the course we take a concise bird s-eye view of different central tasks and concepts involved in machine learning and classification particularly.
2. On classification and related tasks In this part of the course we take a concise bird s-eye view of different central tasks and concepts involved in machine learning and classification particularly.
1) Give decision trees to represent the following Boolean functions:
 Give decision trees to represent the following Boolean functions:") 1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
1) Give decision trees to represent the following Boolean functions: 1) A B 2) A [B C] 3) A XOR B 4) [A B] [C Dl Answer: 1) A B 2) A [B C] 1 3) A XOR B = (A B) ( A B) 4) [A B] [C D] 2 2) Consider the following
CSE446: Linear Regression. Spring 2017
 CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
Pattern recognition (4)
") Pattern recognition (4) 1 Things we have discussed until now Statistical pattern recognition Building simple classifiers Supervised classification Minimum distance classifier Bayesian classifier (1D and
Pattern recognition (4) 1 Things we have discussed until now Statistical pattern recognition Building simple classifiers Supervised classification Minimum distance classifier Bayesian classifier (1D and
Evaluating Machine Learning Methods: Part 1
 Evaluating Machine Learning Methods: Part 1 CS 760@UW-Madison Goals for the lecture you should understand the following concepts bias of an estimator learning curves stratified sampling cross validation
Evaluating Machine Learning Methods: Part 1 CS 760@UW-Madison Goals for the lecture you should understand the following concepts bias of an estimator learning curves stratified sampling cross validation
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
Data Mining and Knowledge Discovery: Practice Notes
 Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 8.11.2017 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Data Mining and Knowledge Discovery: Practice Notes Petra Kralj Novak Petra.Kralj.Novak@ijs.si 8.11.2017 1 Keywords Data Attribute, example, attribute-value data, target variable, class, discretization
Model s Performance Measures
 Model s Performance Measures Evaluating the performance of a classifier Section 4.5 of course book. Taking into account misclassification costs Class imbalance problem Section 5.7 of course book. TNM033:
Model s Performance Measures Evaluating the performance of a classifier Section 4.5 of course book. Taking into account misclassification costs Class imbalance problem Section 5.7 of course book. TNM033:
DATA MINING OVERFITTING AND EVALUATION
 DATA MINING OVERFITTING AND EVALUATION 1 Overfitting Will cover mechanisms for preventing overfitting in decision trees But some of the mechanisms and concepts will apply to other algorithms 2 Occam s
DATA MINING OVERFITTING AND EVALUATION 1 Overfitting Will cover mechanisms for preventing overfitting in decision trees But some of the mechanisms and concepts will apply to other algorithms 2 Occam s
Evaluating generalization (validation) Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support") Evaluating generalization (validation) Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Topics Validation of biomedical models Data-splitting Resampling Cross-validation
Evaluating generalization (validation) Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Topics Validation of biomedical models Data-splitting Resampling Cross-validation
Machine Learning (CSE 446): Concepts & the i.i.d. Supervised Learning Paradigm
: Concepts & the i.i.d. Supervised Learning Paradigm") Machine Learning (CSE 446): Concepts & the i.i.d. Supervised Learning Paradigm Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 17 Review 1 / 17 Decision Tree: Making a
Machine Learning (CSE 446): Concepts & the i.i.d. Supervised Learning Paradigm Sham M Kakade c 2018 University of Washington cse446-staff@cs.washington.edu 1 / 17 Review 1 / 17 Decision Tree: Making a
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2016
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Machine Learning nearest neighbors classification. Luigi Cerulo Department of Science and Technology University of Sannio
 Machine Learning nearest neighbors classification Luigi Cerulo Department of Science and Technology University of Sannio Nearest Neighbors Classification The idea is based on the hypothesis that things
Machine Learning nearest neighbors classification Luigi Cerulo Department of Science and Technology University of Sannio Nearest Neighbors Classification The idea is based on the hypothesis that things
Probabilistic Classifiers DWML, /27
 Probabilistic Classifiers DWML, 2007 1/27 Probabilistic Classifiers Conditional class probabilities Id. Savings Assets Income Credit risk 1 Medium High 75 Good 2 Low Low 50 Bad 3 High Medium 25 Bad 4 Medium
Probabilistic Classifiers DWML, 2007 1/27 Probabilistic Classifiers Conditional class probabilities Id. Savings Assets Income Credit risk 1 Medium High 75 Good 2 Low Low 50 Bad 3 High Medium 25 Bad 4 Medium
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Linear Methods for Regression and Shrinkage Methods
 Linear Methods for Regression and Shrinkage Methods Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Linear Regression Models Least Squares Input vectors
Linear Methods for Regression and Shrinkage Methods Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Linear Regression Models Least Squares Input vectors
Fall 09, Homework 5
 5-38 Fall 09, Homework 5 Due: Wednesday, November 8th, beginning of the class You can work in a group of up to two people. This group does not need to be the same group as for the other homeworks. You
5-38 Fall 09, Homework 5 Due: Wednesday, November 8th, beginning of the class You can work in a group of up to two people. This group does not need to be the same group as for the other homeworks. You
Coding Categorical Variables in Regression: Indicator or Dummy Variables. Professor George S. Easton
 Coding Categorical Variables in Regression: Indicator or Dummy Variables Professor George S. Easton DataScienceSource.com This video is embedded on the following web page at DataScienceSource.com: DataScienceSource.com/DummyVariables
Coding Categorical Variables in Regression: Indicator or Dummy Variables Professor George S. Easton DataScienceSource.com This video is embedded on the following web page at DataScienceSource.com: DataScienceSource.com/DummyVariables
A Comparative Study of Locality Preserving Projection and Principle Component Analysis on Classification Performance Using Logistic Regression
 Journal of Data Analysis and Information Processing, 2016, 4, 55-63 Published Online May 2016 in SciRes. http://www.scirp.org/journal/jdaip http://dx.doi.org/10.4236/jdaip.2016.42005 A Comparative Study
Journal of Data Analysis and Information Processing, 2016, 4, 55-63 Published Online May 2016 in SciRes. http://www.scirp.org/journal/jdaip http://dx.doi.org/10.4236/jdaip.2016.42005 A Comparative Study
K- Nearest Neighbors(KNN) And Predictive Accuracy
 And Predictive Accuracy") Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.
Contact: mailto: Ammar@cu.edu.eg Drammarcu@gmail.com K- Nearest Neighbors(KNN) And Predictive Accuracy Dr. Ammar Mohammed Associate Professor of Computer Science ISSR, Cairo University PhD of CS ( Uni.