Workshop on Efficient Solvers in Biomedical Applications, Graz, July 2-5, 2012
|
|
|
- Henry Baldwin
- 5 years ago
- Views:
Transcription

1 Workshop on Efficient Solvers in Biomedical Applications, Graz, July 2-5, 2012 This work was performed under the auspices of the U.S. Department of Energy by under contract DE-AC52-07NA Lawrence Livermore National Security, LLC

2 Allison Baker Rob Falgout Tzanio Kolev Jacob Schroder Martin Schulz Panayot Vassilevski University of Illinois at Urbana-Champaign: Hormozd Gahvari William Gropp Luke Olson IBM: Kirk Jordan 2



 computing We are developing")
3 The solution of linear systems is at the core of many scientific simulation codes Magnetohydrodynamics Elasticity / Plasticity Electromagnetics Facial surgery simulations High fidelity requires huge linear systems and largescale (e.g., petascale) computing We are developing parallel linear solvers and software (hypre), driven by applications 3

 Techniques for multicore (performance) Different programming model? Communication-reducing algorithms 4")
4 Time to Solution Diag-CG Multigrid-CG scalable Number of Processors (Problem Size) 10 5 Multigrid solvers are essential components of LLNL simulation State-of-the-art is hypre, with proven scalability to BG/L class machines Current solvers will break down on tomorrow s exascale machines Enormous core counts and fine-grain parallelism will degrade convergence New mathematics R&D (convergence) Effective smoothers that are also highly parallel (e.g., polynomial) Techniques for multicore (performance) Different programming model? Communication-reducing algorithms 4
5 Setup Phase Select coarse grids Define interpolation, P (m), m=1,2, Define restriction, R (m) = (P (m) ) T Define coarse-grid operators, A (m+1) = R (m) A (m) P (m) Solve Phase (level m) Smooth A (m) u m = f m Smooth A (m) u m = f m Compute r m = f m - A (m) u m Correct u m u m + e m Restrict r m+1 = R (m) r m Interpolate e m = P (m) e m+1 Solve A (m+1) e m+1 = r m+1 5
 Expect degraded convergence for exascale/multicore machines number of blocks increases with number of processors increased fine-grain parallelism (less memory, threading)")
6 Smoothers significantly affect AMG convergence and runtime solving: Ax=b, A SPD smoothing: x n+1 = x n + M -1 (b-a x n ) Gauss-Seidel highly sequential parallel smoothers: Jacobi hybrid Gauss-Seidel (default smoother in hypre) Expect degraded convergence for exascale/multicore machines number of blocks increases with number of processors increased fine-grain parallelism (less memory, threading) Objective M H = smooth Core 0 Core 1 Core p investigate/develop smoothers that are not affected by the parallelism 6
7 A = A 1 A 2 matrices are distributed across P processors in contiguous blocks of rows A p the smoother is threaded such that each thread works on a contiguous subset of the rows A p = t 1 t 2 t 3 t 4 Hybrid: GS within each thread, Jacobi on thread boundaries 7
 AMG determines thread")
 8")
8 partitions grid element-wise into nice subdomains for each processor 16 procs (colors indicate element numbering) AMG determines thread subdomains by splitting nodes (not elements) the application s numbering of the elements/nodes becomes relevant! (i.e., threaded domains dependent on colors) 8
9 Multiplicative weighted hybrid smoother: M ω = ω M H Convergent if M ω SPD and ω = λ max (M -1/2 A M -1/2 ) M H = Additive (l 1 Smoother) hybrid l 1 -GS: M = M l 1 H + D with D l 1 l1 = j i a ijo always convergent, when GS convergent Hybrid l 1 Jacobi: M = D + D l 1 l1 A = 9
10 Polynomial smoothers: I M -1 A = p(a), p(0)=1 Advantages: independent of parallelism MatVec kernel has been tuned low-degree polynomial sufficient Disadvantage: need extreme eigenvalue estimates (~10 CG iterations) note: only need to damp high-freq. (30% of spectrum) (see Adams et. al, 2003, for Smoothed Aggregation-AMG) 10
 T (D A O ) -1 (D+L D ) l 1 -SGS: M = (D l 1 +LD ) T (2D l D A O ) -1 (D 1 l 1 +LD ), Cheby(2): a")
11 o Test problem: -(a(x,y)u x ) x (a(x,y)u y ) y = f a(x,y) = 1 on inner domains a(x,y) =.001 on outer domain triangular FEM, 4 subdomains o Smoothers considered here: Hybrid-SGS: M = (D+L D ) T (D A O ) -1 (D+L D ) l 1 -SGS: M = (D l 1 +LD ) T (2D l D A O ) -1 (D 1 l 1 +LD ), Cheby(2): a polynomial smoother, where p(a) = I M -1 A, p(0) = 1, here p is the 2 nd order Chebyshev polynomial for D -1/2 AD -1/2 11
12 Polynomial smoothers and our new l1-smoothers are unaffected by poor partitioning (left) and decreasing block sizes (right) New smoothers now available in hypre Baker, Falgout, Kolev, Yang, Multigrid Smoothers for Ultra-Parallel Computing, SIAM Journal on Scientific Computing 12



13 36 racks with 1024 compute nodes each Quad-core 850 MHz PowerPC 450 Processor 147,456 cores 4GB main memory per node shared by all cores 3D torus network - isolated dedicated partitions 13
14 pfmg-1 pfmg-2 amg amg-bench

15 Multi-core/ multi-socket cluster 864 diskless nodes interconnected by DDR Infiniband AMD opteron quad core (2.3 GHz) Fat tree network 15

16 Multicore cluster details (Hera): Individual 512 KB L2 cache for each core 2 MB L3 cache shared by 4 cores 4 sockets per node,16 cores sharing the 32 GB main memory NUMA memory access 16

17 25 25 PFMG-1 20 PFMG-2 AMG
18 18




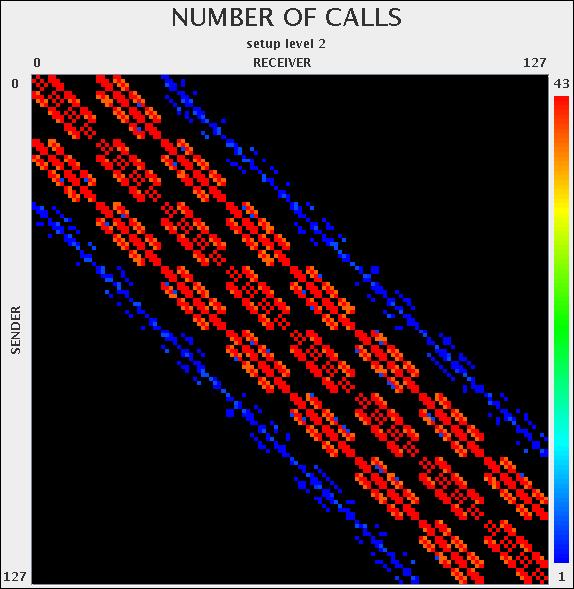
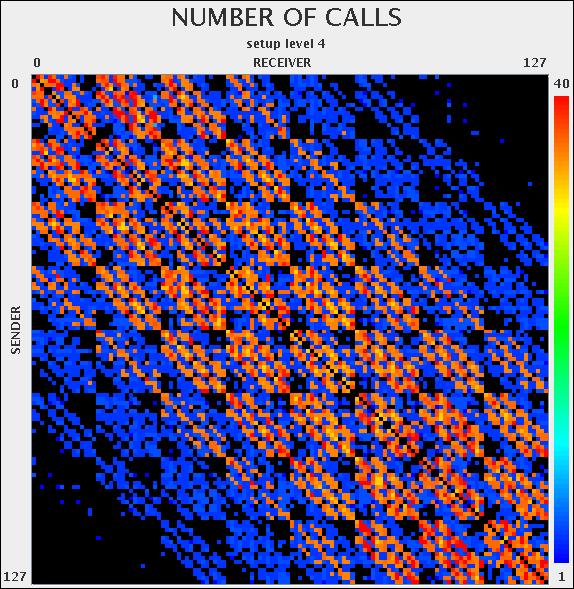
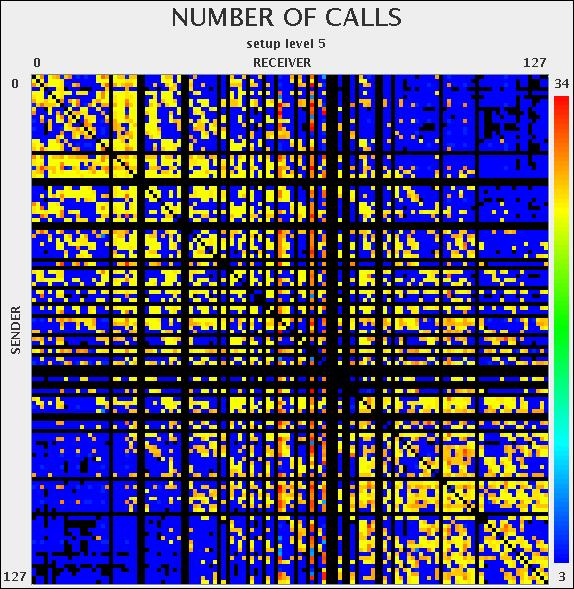
19 Communication plots for 128 core problem: Level 0 Level 1 Level 2 Level 3 Level 4 Level 5 Level 6 Level

20 Proc id Time computation idle time MPI calls 20
21 Baseline model: α-β (latency-inverse bandwidth) with parameters smooth, form residual restrict to level i+1 prolong to level i-1 smooth T i coarsen = T i prolong = T i smooth = 6(C i /P)s i t i + 3(p i α + n i β) { 2(C i+1 /P)s i t i + p i α + n i β if i < L 0 if i = L { 0 if i = 0 2(Ci-1 /P)s i-1 t i + p i-1 α + n i-1 β if i > 0 P number of processes C i number of grid points in level i L maximum grid index s i, s i average number of nonzeros per row (A i, P i ) p i, p i maximum number of sends per active process (A i, P i ) n i, n i maximum number of elements sent per active process (A i, P i ) t i time per floating-point operation on level i 21
22 Take architectural features into account with penalties Distance of communication: add time per hop γ Lower effective bandwidth: let m = # msgs, l = # links, B HW = hardware bandwidth, B MPI = MPI bandwidth BG/P: multiply β by B HW /B MPI Other machines: multiply β by (B HW /B MPI + m/l) Multicore penalties: let c = # cores (MPI tasks) per node, P i = # active processes on level i, P = # processes Multicore latency penalty: multiply α by cp i /P Multicore distance penalty: multiply γ by cp i /P 22

23 Model parameters: α latency, β inverse bandwidth, γ delay per extra hop We added penalties to the basic models based on machine constraints: distance effects, reduced per core bandwidth, number of cores per node BG/P AMG On BG/P, the simple α-β-γ model with bandwidth penalty leads to best fit. Gahvari, Appeared Baker, in Schulz, ICS11 Yang, Proceedings Jordan, Gropp, Modeling the Performance of an Newest Algebraic version Multigrid includes Cycle on OpenMP HPC Platforms, threads, ICS11 submitted Proceedings to ICPP12 AMG On Hera (fat tree network), distance penalty largest contributor to bad performance 23
24 24
25 Time (s) AMG Solve Cycle on Hera, 3456 Cores 1 16 MPI x 1 OMP 8 MPI x 2 OMP MPI x 4 OMP 2 MPI x 8 OMP 1 MPI x 16 OMP MPI/OMP Mix Cycle Time 16 MPI x 1 OMP 187 ms MPI x 2 OMP 116 ms 4 MPI x 4 OMP 67.7 ms MPI x 8 OMP 91.7 ms 1 MPI x 16 OMP 199 ms Level 3D 7-point Laplace model problem, 50 x 50 x 25 points/core 25
26 Seconds MPI 16x1 H 8x2 H 4x4 H 2x8 OMP 1x No. of cores 26
27 Seconds PFMG-1,MPI PFMG-1, 4x4 PFMG-1, 1x16 PFMG-2, MPI PFMG-2, 4x4 PFMG-2, 1x No. of cores 27
28 PFMG-1, MPI PFMG-1, 2x2 PFMG-1, 1x4 PFMG-2, MPI PFMG-2, 2x2 PFMG-2, 1x4 5 AMG, MPI AMG, 2x2 AMG, 1x
29 Non-Galerkin AMG (Schroder, Falgout) Redundant coarse grid solve (Gahvari, Gropp, Jordan, Schulz, Yang) Additive AMG methods (Gahvari, Olson, Vassilevski, Yang, ) 29
30 Choose non-galerkin coarse-grid for parallel efficiency Sparsify to yield a new coarse-grid operator Raises critical issues related to AMG theory Need good spectral equivalence Algorithm heuristic: Provably implies AMG convergence Choose sparsity pattern for A Initially T PAP P AP T I Add more if necessary Choose matrix entries Require accuracy for near nullspace A Remove edges in using stencil collapsing g I Collapse Edge 30
31 Results: 3D Diffusion Classical AMG: scenarios 1, 2 Proposed approach: scenarios 3, 4 Results: 3D anisotropy on unstructured grid Convergence for Scenario 4 comparable to classical AMG with substantially reduced stencil size 31

32 prolong to level i-1 smooth, form residual restrict to level i+1 smoot h all-gather at level i serial AMG coarse solve 32
33 7pt 3D Laplace problem 27pt stencil No. of cores Hera Atlas Coastal Hera Atlas Coastal Hera: AMD Opteron cluster Atlas: AMD Opteron cluster Coastal: Intel Xeon cluster More sophisticated version under development 33

34 all-gather at level i Illustration of chunk data distribution using 4 chunks Cores in each chunk perform the same operations Now use parallel AMG on k cores for each redundant coarse solve Communication across chunks Allows better use of cache Allows smart choice of cores 34
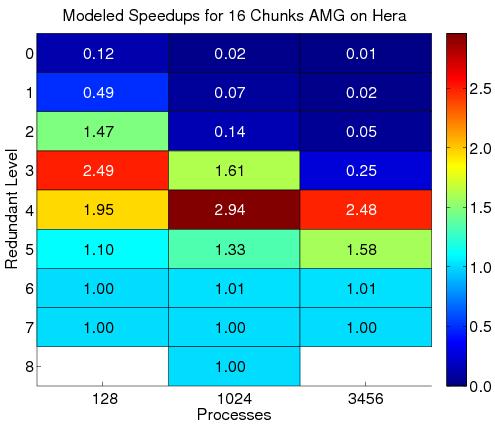

35 35
36 smooth smooth Perform in parallel smooth smooth smooth smooth smooth smooth smooth solve solve 36
37 Even with slower convergence, noticeable speedups possible on model problem: We are investigating now an additive version of multiplicative multigrid, which preserves convergence 37
38 l 1 and Polynomial smoothers are promising for smoothing on millions of cores Getting efficient use out of multi-core architectures is challenging! Reducing communication is crucial! New methods show promise for better performance. Use model to evaluate new algorithmic changes and to predict performance on much larger scale Continue work on reducing communication Approaches for more efficient implementation Optimized kernels New data structures? 38
39 This work was performed under the auspices of the U.S. Department of Energy by under Contract DE-AC52-07NA
Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang
 Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Multigrid Solvers Method of solving linear equation
Challenges of Scaling Algebraic Multigrid Across Modern Multicore Architectures. Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Multigrid Solvers Method of solving linear equation
Reducing Communication Costs Associated with Parallel Algebraic Multigrid
 Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
Reducing Communication Costs Associated with Parallel Algebraic Multigrid Amanda Bienz, Luke Olson (Advisor) University of Illinois at Urbana-Champaign Urbana, IL 11 I. PROBLEM AND MOTIVATION Algebraic
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid. Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014
 Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Automatic Generation of Algorithms and Data Structures for Geometric Multigrid Harald Köstler, Sebastian Kuckuk Siam Parallel Processing 02/21/2014 Introduction Multigrid Goal: Solve a partial differential
Challenges of Scaling Algebraic Multigrid across Modern Multicore Architectures
 Challenges of Scaling Algebraic Multigrid across Modern Multicore Architectures Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Center for Applied Scientific Computing, Lawrence Livermore
Challenges of Scaling Algebraic Multigrid across Modern Multicore Architectures Allison H. Baker, Todd Gamblin, Martin Schulz, and Ulrike Meier Yang Center for Applied Scientific Computing, Lawrence Livermore
Distributed NVAMG. Design and Implementation of a Scalable Algebraic Multigrid Framework for a Cluster of GPUs
 Distributed NVAMG Design and Implementation of a Scalable Algebraic Multigrid Framework for a Cluster of GPUs Istvan Reguly (istvan.reguly at oerc.ox.ac.uk) Oxford e-research Centre NVIDIA Summer Internship
Distributed NVAMG Design and Implementation of a Scalable Algebraic Multigrid Framework for a Cluster of GPUs Istvan Reguly (istvan.reguly at oerc.ox.ac.uk) Oxford e-research Centre NVIDIA Summer Internship
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
smooth coefficients H. Köstler, U. Rüde
 A robust multigrid solver for the optical flow problem with non- smooth coefficients H. Köstler, U. Rüde Overview Optical Flow Problem Data term and various regularizers A Robust Multigrid Solver Galerkin
A robust multigrid solver for the optical flow problem with non- smooth coefficients H. Köstler, U. Rüde Overview Optical Flow Problem Data term and various regularizers A Robust Multigrid Solver Galerkin
Lecture 15: More Iterative Ideas
 Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Ilya Lashuk, Merico Argentati, Evgenii Ovtchinnikov, Andrew Knyazev (speaker)
") Ilya Lashuk, Merico Argentati, Evgenii Ovtchinnikov, Andrew Knyazev (speaker) Department of Mathematics and Center for Computational Mathematics University of Colorado at Denver SIAM Conference on Parallel
Ilya Lashuk, Merico Argentati, Evgenii Ovtchinnikov, Andrew Knyazev (speaker) Department of Mathematics and Center for Computational Mathematics University of Colorado at Denver SIAM Conference on Parallel
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Efficient AMG on Hybrid GPU Clusters. ScicomP Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann. Fraunhofer SCAI
 Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Efficient AMG on Hybrid GPU Clusters ScicomP 2012 Jiri Kraus, Malte Förster, Thomas Brandes, Thomas Soddemann Fraunhofer SCAI Illustration: Darin McInnis Motivation Sparse iterative solvers benefit from
Ulrike M. Yang 1 and Bronis R. de Supinski 1
 Barna L. Bihari 1, James Cownie 2, Hansang Bae 2, Ulrike M. Yang 1 and Bronis R. de Supinski 1 1 Lawrence Livermore National Laboratory, Livermore, California 2 Intel Corporation, Santa Clara, California
Barna L. Bihari 1, James Cownie 2, Hansang Bae 2, Ulrike M. Yang 1 and Bronis R. de Supinski 1 1 Lawrence Livermore National Laboratory, Livermore, California 2 Intel Corporation, Santa Clara, California
Integrating GPUs as fast co-processors into the existing parallel FE package FEAST
 Integrating GPUs as fast co-processors into the existing parallel FE package FEAST Dipl.-Inform. Dominik Göddeke (dominik.goeddeke@math.uni-dortmund.de) Mathematics III: Applied Mathematics and Numerics
Integrating GPUs as fast co-processors into the existing parallel FE package FEAST Dipl.-Inform. Dominik Göddeke (dominik.goeddeke@math.uni-dortmund.de) Mathematics III: Applied Mathematics and Numerics
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
Highly Parallel Multigrid Solvers for Multicore and Manycore Processors
 Highly Parallel Multigrid Solvers for Multicore and Manycore Processors Oleg Bessonov (B) Institute for Problems in Mechanics of the Russian Academy of Sciences, 101, Vernadsky Avenue, 119526 Moscow, Russia
Highly Parallel Multigrid Solvers for Multicore and Manycore Processors Oleg Bessonov (B) Institute for Problems in Mechanics of the Russian Academy of Sciences, 101, Vernadsky Avenue, 119526 Moscow, Russia
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND
 Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Finite Element Multigrid Solvers for PDE Problems on GPUs and GPU Clusters
 Finite Element Multigrid Solvers for PDE Problems on GPUs and GPU Clusters Robert Strzodka Integrative Scientific Computing Max Planck Institut Informatik www.mpi-inf.mpg.de/ ~strzodka Dominik Göddeke
Finite Element Multigrid Solvers for PDE Problems on GPUs and GPU Clusters Robert Strzodka Integrative Scientific Computing Max Planck Institut Informatik www.mpi-inf.mpg.de/ ~strzodka Dominik Göddeke
Block-asynchronous Multigrid Smoothers for GPU-accelerated Systems
 Block-asynchronous Multigrid Smoothers for GPU-accelerated Systems Hartwig Anzt 1, Stanimire Tomov 2, Mark Gates 2, Jack Dongarra 2,3,4, and Vincent Heuveline 1 1 Karlsruhe Institute of Technology (KIT),
Block-asynchronous Multigrid Smoothers for GPU-accelerated Systems Hartwig Anzt 1, Stanimire Tomov 2, Mark Gates 2, Jack Dongarra 2,3,4, and Vincent Heuveline 1 1 Karlsruhe Institute of Technology (KIT),
Parallel Performance Studies for a Clustering Algorithm
 Parallel Performance Studies for a Clustering Algorithm Robin V. Blasberg and Matthias K. Gobbert Naval Research Laboratory, Washington, D.C. Department of Mathematics and Statistics, University of Maryland,
Parallel Performance Studies for a Clustering Algorithm Robin V. Blasberg and Matthias K. Gobbert Naval Research Laboratory, Washington, D.C. Department of Mathematics and Statistics, University of Maryland,
Multigrid Methods for Markov Chains
 Multigrid Methods for Markov Chains Hans De Sterck Department of Applied Mathematics, University of Waterloo collaborators Killian Miller Department of Applied Mathematics, University of Waterloo, Canada
Multigrid Methods for Markov Chains Hans De Sterck Department of Applied Mathematics, University of Waterloo collaborators Killian Miller Department of Applied Mathematics, University of Waterloo, Canada
Andrew V. Knyazev and Merico E. Argentati (speaker)
") 1 Andrew V. Knyazev and Merico E. Argentati (speaker) Department of Mathematics and Center for Computational Mathematics University of Colorado at Denver 2 Acknowledgement Supported by Lawrence Livermore
1 Andrew V. Knyazev and Merico E. Argentati (speaker) Department of Mathematics and Center for Computational Mathematics University of Colorado at Denver 2 Acknowledgement Supported by Lawrence Livermore
Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures
 Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
IMPLEMENTATION OF THE. Alexander J. Yee University of Illinois Urbana-Champaign
 SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
A Comparison of Algebraic Multigrid Preconditioners using Graphics Processing Units and Multi-Core Central Processing Units
 A Comparison of Algebraic Multigrid Preconditioners using Graphics Processing Units and Multi-Core Central Processing Units Markus Wagner, Karl Rupp,2, Josef Weinbub Institute for Microelectronics, TU
A Comparison of Algebraic Multigrid Preconditioners using Graphics Processing Units and Multi-Core Central Processing Units Markus Wagner, Karl Rupp,2, Josef Weinbub Institute for Microelectronics, TU
Bandwidth Avoiding Stencil Computations
 Bandwidth Avoiding Stencil Computations By Kaushik Datta, Sam Williams, Kathy Yelick, and Jim Demmel, and others Berkeley Benchmarking and Optimization Group UC Berkeley March 13, 2008 http://bebop.cs.berkeley.edu
Bandwidth Avoiding Stencil Computations By Kaushik Datta, Sam Williams, Kathy Yelick, and Jim Demmel, and others Berkeley Benchmarking and Optimization Group UC Berkeley March 13, 2008 http://bebop.cs.berkeley.edu
An Algebraic Multigrid Tutorial
 An Algebraic Multigrid Tutorial IMA Tutorial Fast Solution Techniques November 28-29, 2010 Robert D. Falgout Center for Applied Scientific Computing This work performed under the auspices of the U.S. Department
An Algebraic Multigrid Tutorial IMA Tutorial Fast Solution Techniques November 28-29, 2010 Robert D. Falgout Center for Applied Scientific Computing This work performed under the auspices of the U.S. Department
GPU-Accelerated Algebraic Multigrid for Commercial Applications. Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA
 GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
Performance of Multicore LUP Decomposition
 Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
GPU-Accelerated Asynchronous Error Correction for Mixed Precision Iterative Refinement
 GPU-Accelerated Asynchronous Error Correction for Mixed Precision Iterative Refinement Hartwig Anzt, Piotr Luszczek 2, Jack Dongarra 234, and Vincent Heuveline Karlsruhe Institute of Technology, Karlsruhe,
GPU-Accelerated Asynchronous Error Correction for Mixed Precision Iterative Refinement Hartwig Anzt, Piotr Luszczek 2, Jack Dongarra 234, and Vincent Heuveline Karlsruhe Institute of Technology, Karlsruhe,
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Tools and Primitives for High Performance Graph Computation
 Tools and Primitives for High Performance Graph Computation John R. Gilbert University of California, Santa Barbara Aydin Buluç (LBNL) Adam Lugowski (UCSB) SIAM Minisymposium on Analyzing Massive Real-World
Tools and Primitives for High Performance Graph Computation John R. Gilbert University of California, Santa Barbara Aydin Buluç (LBNL) Adam Lugowski (UCSB) SIAM Minisymposium on Analyzing Massive Real-World
MVAPICH2 vs. OpenMPI for a Clustering Algorithm
 MVAPICH2 vs. OpenMPI for a Clustering Algorithm Robin V. Blasberg and Matthias K. Gobbert Naval Research Laboratory, Washington, D.C. Department of Mathematics and Statistics, University of Maryland, Baltimore
MVAPICH2 vs. OpenMPI for a Clustering Algorithm Robin V. Blasberg and Matthias K. Gobbert Naval Research Laboratory, Washington, D.C. Department of Mathematics and Statistics, University of Maryland, Baltimore
Placement de processus (MPI) sur architecture multi-cœur NUMA
 sur architecture multi-cœur NUMA") Placement de processus (MPI) sur architecture multi-cœur NUMA Emmanuel Jeannot, Guillaume Mercier LaBRI/INRIA Bordeaux Sud-Ouest/ENSEIRB Runtime Team Lyon, journées groupe de calcul, november 2010 Emmanuel.Jeannot@inria.fr
Placement de processus (MPI) sur architecture multi-cœur NUMA Emmanuel Jeannot, Guillaume Mercier LaBRI/INRIA Bordeaux Sud-Ouest/ENSEIRB Runtime Team Lyon, journées groupe de calcul, november 2010 Emmanuel.Jeannot@inria.fr
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs
 3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
Preconditioning for large scale µfe analysis of 3D poroelasticity
 ECBA, Graz, July 2 5, 2012 1/38 Preconditioning for large scale µfe analysis of 3D poroelasticity Peter Arbenz, Cyril Flaig, Erhan Turan ETH Zurich Workshop on Efficient Solvers in Biomedical Applications
ECBA, Graz, July 2 5, 2012 1/38 Preconditioning for large scale µfe analysis of 3D poroelasticity Peter Arbenz, Cyril Flaig, Erhan Turan ETH Zurich Workshop on Efficient Solvers in Biomedical Applications
Case study: OpenMP-parallel sparse matrix-vector multiplication
 Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
A massively parallel solver for discrete Poisson-like problems
 A massively parallel solver for discrete Poisson-like problems Yvan Notay and Artem Napov Service de Métrologie Nucléaire Université Libre de Bruxelles (C.P. 165/84) 50, Av. F.D. Roosevelt, B-1050 Brussels,
A massively parallel solver for discrete Poisson-like problems Yvan Notay and Artem Napov Service de Métrologie Nucléaire Université Libre de Bruxelles (C.P. 165/84) 50, Av. F.D. Roosevelt, B-1050 Brussels,
A Parallel Solver for Laplacian Matrices. Tristan Konolige (me) and Jed Brown
 and Jed Brown") A Parallel Solver for Laplacian Matrices Tristan Konolige (me) and Jed Brown Graph Laplacian Matrices Covered by other speakers (hopefully) Useful in a variety of areas Graphs are getting very big Facebook
A Parallel Solver for Laplacian Matrices Tristan Konolige (me) and Jed Brown Graph Laplacian Matrices Covered by other speakers (hopefully) Useful in a variety of areas Graphs are getting very big Facebook
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
GPU Cluster Computing for FEM
 GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
c 2006 Society for Industrial and Applied Mathematics
 SIAM J. MATRIX ANAL. APPL. Vol. 27, No. 4, pp. 1019 1039 c 2006 Society for Industrial and Applied Mathematics REDUCING COMPLEXITY IN PARALLEL ALGEBRAIC MULTIGRID PRECONDITIONERS HANS DE STERCK, ULRIKE
SIAM J. MATRIX ANAL. APPL. Vol. 27, No. 4, pp. 1019 1039 c 2006 Society for Industrial and Applied Mathematics REDUCING COMPLEXITY IN PARALLEL ALGEBRAIC MULTIGRID PRECONDITIONERS HANS DE STERCK, ULRIKE
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation
 Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
ESPRESO ExaScale PaRallel FETI Solver. Hybrid FETI Solver Report
 ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
D036 Accelerating Reservoir Simulation with GPUs
 D036 Accelerating Reservoir Simulation with GPUs K.P. Esler* (Stone Ridge Technology), S. Atan (Marathon Oil Corp.), B. Ramirez (Marathon Oil Corp.) & V. Natoli (Stone Ridge Technology) SUMMARY Over the
D036 Accelerating Reservoir Simulation with GPUs K.P. Esler* (Stone Ridge Technology), S. Atan (Marathon Oil Corp.), B. Ramirez (Marathon Oil Corp.) & V. Natoli (Stone Ridge Technology) SUMMARY Over the
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Introduction to Multigrid and its Parallelization
 Introduction to Multigrid and its Parallelization! Thomas D. Economon Lecture 14a May 28, 2014 Announcements 2 HW 1 & 2 have been returned. Any questions? Final projects are due June 11, 5 pm. If you are
Introduction to Multigrid and its Parallelization! Thomas D. Economon Lecture 14a May 28, 2014 Announcements 2 HW 1 & 2 have been returned. Any questions? Final projects are due June 11, 5 pm. If you are
EXPOSING FINE-GRAINED PARALLELISM IN ALGEBRAIC MULTIGRID METHODS
 EXPOSING FINE-GRAINED PARALLELISM IN ALGEBRAIC MULTIGRID METHODS NATHAN BELL, STEVEN DALTON, AND LUKE N. OLSON Abstract. Algebraic multigrid methods for large, sparse linear systems are a necessity in
EXPOSING FINE-GRAINED PARALLELISM IN ALGEBRAIC MULTIGRID METHODS NATHAN BELL, STEVEN DALTON, AND LUKE N. OLSON Abstract. Algebraic multigrid methods for large, sparse linear systems are a necessity in
Communication-Avoiding Optimization of Geometric Multigrid on GPUs
 Communication-Avoiding Optimization of Geometric Multigrid on GPUs Amik Singh James Demmel, Ed. Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-258
Communication-Avoiding Optimization of Geometric Multigrid on GPUs Amik Singh James Demmel, Ed. Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2012-258
Contents. I The Basic Framework for Stationary Problems 1
 page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
Weighted Block-Asynchronous Iteration on GPU-Accelerated Systems
 Weighted Block-Asynchronous Iteration on GPU-Accelerated Systems Hartwig Anzt 1, Stanimire Tomov 2 Jack Dongarra 234, and Vincent Heuveline 1 1 Karlsruhe Institute of Technology (KIT), Karlsruhe, Germany
Weighted Block-Asynchronous Iteration on GPU-Accelerated Systems Hartwig Anzt 1, Stanimire Tomov 2 Jack Dongarra 234, and Vincent Heuveline 1 1 Karlsruhe Institute of Technology (KIT), Karlsruhe, Germany
Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development
 Development") Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Scalability of Elliptic Solvers in NWP. Weather and Climate- Prediction
 Background Scaling results Tensor product geometric multigrid Summary and Outlook 1/21 Scalability of Elliptic Solvers in Numerical Weather and Climate- Prediction Eike Hermann Müller, Robert Scheichl
Background Scaling results Tensor product geometric multigrid Summary and Outlook 1/21 Scalability of Elliptic Solvers in Numerical Weather and Climate- Prediction Eike Hermann Müller, Robert Scheichl
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
REDUCING COMPLEXITY IN PARALLEL ALGEBRAIC MULTIGRID PRECONDITIONERS
 SUBMITTED TO SIAM JOURNAL ON MATRIX ANALYSIS AND APPLICATIONS, SEPTEMBER 2004 REDUCING COMPLEXITY IN PARALLEL ALGEBRAIC MULTIGRID PRECONDITIONERS HANS DE STERCK, ULRIKE MEIER YANG, AND JEFFREY J. HEYS
SUBMITTED TO SIAM JOURNAL ON MATRIX ANALYSIS AND APPLICATIONS, SEPTEMBER 2004 REDUCING COMPLEXITY IN PARALLEL ALGEBRAIC MULTIGRID PRECONDITIONERS HANS DE STERCK, ULRIKE MEIER YANG, AND JEFFREY J. HEYS
PhD Student. Associate Professor, Co-Director, Center for Computational Earth and Environmental Science. Abdulrahman Manea.
 Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Abdulrahman Manea PhD Student Hamdi Tchelepi Associate Professor, Co-Director, Center for Computational Earth and Environmental Science Energy Resources Engineering Department School of Earth Sciences
Parallel Combinatorial BLAS and Applications in Graph Computations
 Parallel Combinatorial BLAS and Applications in Graph Computations Aydın Buluç John R. Gilbert University of California, Santa Barbara SIAM ANNUAL MEETING 2009 July 8, 2009 1 Primitives for Graph Computations
Parallel Combinatorial BLAS and Applications in Graph Computations Aydın Buluç John R. Gilbert University of California, Santa Barbara SIAM ANNUAL MEETING 2009 July 8, 2009 1 Primitives for Graph Computations
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Performance Engineering - Case study: Jacobi stencil
 Performance Engineering - Case study: Jacobi stencil The basics in two dimensions (2D) Layer condition in 2D From 2D to 3D OpenMP parallelization strategies and layer condition in 3D NT stores Prof. Dr.
Performance Engineering - Case study: Jacobi stencil The basics in two dimensions (2D) Layer condition in 2D From 2D to 3D OpenMP parallelization strategies and layer condition in 3D NT stores Prof. Dr.
Parallel Computing. Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides)
, A Grama book (chapter 3 slides)") Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
High Performance Computing for PDE Towards Petascale Computing
 High Performance Computing for PDE Towards Petascale Computing S. Turek, D. Göddeke with support by: Chr. Becker, S. Buijssen, M. Grajewski, H. Wobker Institut für Angewandte Mathematik, Univ. Dortmund
High Performance Computing for PDE Towards Petascale Computing S. Turek, D. Göddeke with support by: Chr. Becker, S. Buijssen, M. Grajewski, H. Wobker Institut für Angewandte Mathematik, Univ. Dortmund
Performances and Tuning for Designing a Fast Parallel Hemodynamic Simulator. Bilel Hadri
 Performances and Tuning for Designing a Fast Parallel Hemodynamic Simulator Bilel Hadri University of Tennessee Innovative Computing Laboratory Collaboration: Dr Marc Garbey, University of Houston, Department
Performances and Tuning for Designing a Fast Parallel Hemodynamic Simulator Bilel Hadri University of Tennessee Innovative Computing Laboratory Collaboration: Dr Marc Garbey, University of Houston, Department
Reconstruction of Trees from Laser Scan Data and further Simulation Topics
 Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators
 Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
Generation of Multigrid-based Numerical Solvers for FPGA Accelerators Christian Schmitt, Moritz Schmid, Frank Hannig, Jürgen Teich, Sebastian Kuckuk, Harald Köstler Hardware/Software Co-Design, System
Performance Comparison between Blocking and Non-Blocking Communications for a Three-Dimensional Poisson Problem
 Performance Comparison between Blocking and Non-Blocking Communications for a Three-Dimensional Poisson Problem Guan Wang and Matthias K. Gobbert Department of Mathematics and Statistics, University of
Performance Comparison between Blocking and Non-Blocking Communications for a Three-Dimensional Poisson Problem Guan Wang and Matthias K. Gobbert Department of Mathematics and Statistics, University of
Introduction to Parallel Programming for Multicore/Manycore Clusters Part II-3: Parallel FVM using MPI
 Introduction to Parallel Programming for Multi/Many Clusters Part II-3: Parallel FVM using MPI Kengo Nakajima Information Technology Center The University of Tokyo 2 Overview Introduction Local Data Structure
Introduction to Parallel Programming for Multi/Many Clusters Part II-3: Parallel FVM using MPI Kengo Nakajima Information Technology Center The University of Tokyo 2 Overview Introduction Local Data Structure
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
Implicit and Explicit Optimizations for Stencil Computations
 Implicit and Explicit Optimizations for Stencil Computations By Shoaib Kamil 1,2, Kaushik Datta 1, Samuel Williams 1,2, Leonid Oliker 2, John Shalf 2 and Katherine A. Yelick 1,2 1 BeBOP Project, U.C. Berkeley
Implicit and Explicit Optimizations for Stencil Computations By Shoaib Kamil 1,2, Kaushik Datta 1, Samuel Williams 1,2, Leonid Oliker 2, John Shalf 2 and Katherine A. Yelick 1,2 1 BeBOP Project, U.C. Berkeley
GPU Acceleration of Unmodified CSM and CFD Solvers
 GPU Acceleration of Unmodified CSM and CFD Solvers Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de
GPU Acceleration of Unmodified CSM and CFD Solvers Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de
A Case for High Performance Computing with Virtual Machines
 A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
A Case for High Performance Computing with Virtual Machines Wei Huang*, Jiuxing Liu +, Bulent Abali +, and Dhabaleswar K. Panda* *The Ohio State University +IBM T. J. Waston Research Center Presentation
Shape Optimizing Load Balancing for Parallel Adaptive Numerical Simulations Using MPI
 Parallel Adaptive Institute of Theoretical Informatics Karlsruhe Institute of Technology (KIT) 10th DIMACS Challenge Workshop, Feb 13-14, 2012, Atlanta 1 Load Balancing by Repartitioning Application: Large
Parallel Adaptive Institute of Theoretical Informatics Karlsruhe Institute of Technology (KIT) 10th DIMACS Challenge Workshop, Feb 13-14, 2012, Atlanta 1 Load Balancing by Repartitioning Application: Large
An algebraic multi-grid implementation in FEniCS for solving 3d fracture problems using XFEM
 An algebraic multi-grid implementation in FEniCS for solving 3d fracture problems using XFEM Axel Gerstenberger, Garth N. Wells, Chris Richardson, David Bernstein, and Ray Tuminaro FEniCS 14, Paris, France
An algebraic multi-grid implementation in FEniCS for solving 3d fracture problems using XFEM Axel Gerstenberger, Garth N. Wells, Chris Richardson, David Bernstein, and Ray Tuminaro FEniCS 14, Paris, France
 Multigrid solvers M. M. Sussman sussmanm@math.pitt.edu Office Hours: 11:10AM-12:10PM, Thack 622 May 12 June 19, 2014 1 / 43 Multigrid Geometrical multigrid Introduction Details of GMG Summary Algebraic
Multigrid solvers M. M. Sussman sussmanm@math.pitt.edu Office Hours: 11:10AM-12:10PM, Thack 622 May 12 June 19, 2014 1 / 43 Multigrid Geometrical multigrid Introduction Details of GMG Summary Algebraic
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Parallel solution for finite element linear systems of. equations on workstation cluster *
 Aug. 2009, Volume 6, No.8 (Serial No.57) Journal of Communication and Computer, ISSN 1548-7709, USA Parallel solution for finite element linear systems of equations on workstation cluster * FU Chao-jiang
Aug. 2009, Volume 6, No.8 (Serial No.57) Journal of Communication and Computer, ISSN 1548-7709, USA Parallel solution for finite element linear systems of equations on workstation cluster * FU Chao-jiang
First Experiences with Intel Cluster OpenMP
 First Experiences with Intel Christian Terboven, Dieter an Mey, Dirk Schmidl, Marcus Wagner surname@rz.rwth aachen.de Center for Computing and Communication RWTH Aachen University, Germany IWOMP 2008 May
First Experiences with Intel Christian Terboven, Dieter an Mey, Dirk Schmidl, Marcus Wagner surname@rz.rwth aachen.de Center for Computing and Communication RWTH Aachen University, Germany IWOMP 2008 May
A Hybrid Geometric+Algebraic Multigrid Method with Semi-Iterative Smoothers
 NUMERICAL LINEAR ALGEBRA WITH APPLICATIONS Numer. Linear Algebra Appl. 013; 00:1 18 Published online in Wiley InterScience www.interscience.wiley.com). A Hybrid Geometric+Algebraic Multigrid Method with
NUMERICAL LINEAR ALGEBRA WITH APPLICATIONS Numer. Linear Algebra Appl. 013; 00:1 18 Published online in Wiley InterScience www.interscience.wiley.com). A Hybrid Geometric+Algebraic Multigrid Method with
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Adaptive Smoothed Aggregation (αsa) Multigrid
 Multigrid") SIAM REVIEW Vol. 47,No. 2,pp. 317 346 c 2005 Society for Industrial and Applied Mathematics Adaptive Smoothed Aggregation (αsa) Multigrid M. Brezina R. Falgout S. MacLachlan T. Manteuffel S. McCormick
SIAM REVIEW Vol. 47,No. 2,pp. 317 346 c 2005 Society for Industrial and Applied Mathematics Adaptive Smoothed Aggregation (αsa) Multigrid M. Brezina R. Falgout S. MacLachlan T. Manteuffel S. McCormick
FOR P3: A monolithic multigrid FEM solver for fluid structure interaction
 FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow.
 Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Let s say I give you a homework assignment today with 100 problems. Each problem takes 2 hours to solve. The homework is due tomorrow. Big problems and Very Big problems in Science How do we live Protein
Performance Study of the MPI and MPI-CH Communication Libraries on the IBM SP
 Performance Study of the MPI and MPI-CH Communication Libraries on the IBM SP Ewa Deelman and Rajive Bagrodia UCLA Computer Science Department deelman@cs.ucla.edu, rajive@cs.ucla.edu http://pcl.cs.ucla.edu
Performance Study of the MPI and MPI-CH Communication Libraries on the IBM SP Ewa Deelman and Rajive Bagrodia UCLA Computer Science Department deelman@cs.ucla.edu, rajive@cs.ucla.edu http://pcl.cs.ucla.edu
fspai-1.0 Factorized Sparse Approximate Inverse Preconditioner
 fspai-1.0 Factorized Sparse Approximate Inverse Preconditioner Thomas Huckle Matous Sedlacek 2011 08 01 Technische Universität München Research Unit Computer Science V Scientific Computing in Computer
fspai-1.0 Factorized Sparse Approximate Inverse Preconditioner Thomas Huckle Matous Sedlacek 2011 08 01 Technische Universität München Research Unit Computer Science V Scientific Computing in Computer
Noise Injection Techniques to Expose Subtle and Unintended Message Races
 Noise Injection Techniques to Expose Subtle and Unintended Message Races PPoPP2017 February 6th, 2017 Kento Sato, Dong H. Ahn, Ignacio Laguna, Gregory L. Lee, Martin Schulz and Christopher M. Chambreau
Noise Injection Techniques to Expose Subtle and Unintended Message Races PPoPP2017 February 6th, 2017 Kento Sato, Dong H. Ahn, Ignacio Laguna, Gregory L. Lee, Martin Schulz and Christopher M. Chambreau
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces. Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S.
 Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Automatic Identification of Application I/O Signatures from Noisy Server-Side Traces Yang Liu Raghul Gunasekaran Xiaosong Ma Sudharshan S. Vazhkudai Instance of Large-Scale HPC Systems ORNL s TITAN (World
Recent developments for the multigrid scheme of the DLR TAU-Code
 www.dlr.de Chart 1 > 21st NIA CFD Seminar > Axel Schwöppe Recent development s for the multigrid scheme of the DLR TAU-Code > Apr 11, 2013 Recent developments for the multigrid scheme of the DLR TAU-Code
www.dlr.de Chart 1 > 21st NIA CFD Seminar > Axel Schwöppe Recent development s for the multigrid scheme of the DLR TAU-Code > Apr 11, 2013 Recent developments for the multigrid scheme of the DLR TAU-Code
New Features in LS-DYNA HYBRID Version
 11 th International LS-DYNA Users Conference Computing Technology New Features in LS-DYNA HYBRID Version Nick Meng 1, Jason Wang 2, Satish Pathy 2 1 Intel Corporation, Software and Services Group 2 Livermore
11 th International LS-DYNA Users Conference Computing Technology New Features in LS-DYNA HYBRID Version Nick Meng 1, Jason Wang 2, Satish Pathy 2 1 Intel Corporation, Software and Services Group 2 Livermore
10th August Part One: Introduction to Parallel Computing
 Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
f xx + f yy = F (x, y)
") Application of the 2D finite element method to Laplace (Poisson) equation; f xx + f yy = F (x, y) M. R. Hadizadeh Computer Club, Department of Physics and Astronomy, Ohio University 4 Nov. 2013 Domain
Application of the 2D finite element method to Laplace (Poisson) equation; f xx + f yy = F (x, y) M. R. Hadizadeh Computer Club, Department of Physics and Astronomy, Ohio University 4 Nov. 2013 Domain
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
The determination of the correct
 SPECIAL High-performance SECTION: H i gh-performance computing computing MARK NOBLE, Mines ParisTech PHILIPPE THIERRY, Intel CEDRIC TAILLANDIER, CGGVeritas (formerly Mines ParisTech) HENRI CALANDRA, Total
SPECIAL High-performance SECTION: H i gh-performance computing computing MARK NOBLE, Mines ParisTech PHILIPPE THIERRY, Intel CEDRIC TAILLANDIER, CGGVeritas (formerly Mines ParisTech) HENRI CALANDRA, Total
Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling
 Iterative Solvers Numerical Results Conclusion and outlook 1/22 Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling Part II: GPU Implementation and Scaling on Titan Eike
Iterative Solvers Numerical Results Conclusion and outlook 1/22 Efficient multigrid solvers for strongly anisotropic PDEs in atmospheric modelling Part II: GPU Implementation and Scaling on Titan Eike