Overview on Automatic Tuning of Hyperparameters
|
|
|
- Emma Gibson
- 6 years ago
- Views:
Transcription
1 Overview on Automatic Tuning of Hyperparameters Alexander Fonarev
2 Outline Introduction to the problem and examples Introduction to Bayesian optimization Overview of surrogate models Additional modifications Existing implementations
3 Hyperparameter examples Tree depth decision trees Regularization coefficient linear models Gradient descend step size neural networks Normalization coefficient data preprocessing
4 Examples of problems Training of the ranking in Yandex days Parameters in NNs tens
5 Popular and easy approaches Experience of experts Grid search Random search Manual coordinate-descend "Random Search for Hyper-Parameter Optimization." James Bergstra and Yoshua Bengio. Journal of Machine Learning Research,
6 Gradient-free and global optimization Genetic algorithms Simulated annealing Response surfaces etc Response surfaces
7 Stochastic functions How to optimize such functions?
8 How to choose the next point to evaluate? Brochu, Eric, Vlad M. Cora, and Nando De Freitas. "A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning." arxiv preprint arxiv: (2010).
9 Probability of improvement

10 Acquisition function Hutter, Frank, Jörg Lücke, and Lars Schmidt-Thieme. "Beyond Manual Tuning of Hyperparameters Shahriari, Bobak, et al. "Taking the Human Out of the Loop: A Review of Bayesian Optimization
11 Different acquisition strategies Built surrogate Probability of improvement (PI) Expected improvement (EI) Upper Confidence Bound (UCB)

12 Comparison of acquisition functions Shahriari, Bobak, et al. "Taking the Human Out of the Loop: A Review of Bayesian Optimization
13 Common algorithm 1. Initial design evaluate the black box in some points 2. Adaptive design a) Build a surrogate b) Find the argmax of Expected Improvement c) Evaluate the black box in this point d) Go to step 2
14 How to perform the initial design? Best from previous experiments Ask for experts Random Grid Several optimal design criteria
15 Types of surrogates Gaussian Processes (GP) Tree of Parzen Estimators (TPE) Sequential Model-based Algorithm Configuration (SMAC)

16 Gaussian Process (GP) (Spearmint)
")


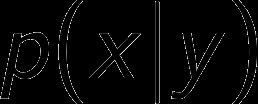

17 Tree of Parzen Estimators (TPE) Estimates and instead of. The core idea nonparametric density approximations of x. (Hyperopt)

18 Reminder: Random Forest Not robust (has high variance)
19 Reminder: Random Forest Average of slightly different trees: Tree Tree N
20 Sequential Model-based Algorithm Configuration (SMAC) Mean in each point prediction of RF Variance in each point variance of predictions of separate trees from RF (SMAC)
21 How to find the maximum of EI? Use global optimization. Some options: Random search Genetic algorithms Simulated annealing Response surfaces
22 Parallelization Batch Asynchronous adaptive design
23 What else? Data structures for fast optimum search Cold start problem Different parameters require different learning time Labels transformation Different parameter types

24 Open source implementations Hutter, Frank, Jörg Lücke, and Lars Schmidt-Thieme. "Beyond Manual Tuning of Hyperparameters
25 How to evaluate method? Use real data Use synthetic data
26 Comparison of different approaches we also provide results for half the function evaluation budget to quantify the improvement over time. SMAC Spearmint TPE Experiment #evals Valid. loss Best loss Valid. loss Best loss Valid. loss Best loss branin (0.398) ± ± ± har6 (-3.322) ± ± ± Log.Regression ± ± ± LDA ongrid ± ± ± SVM ongrid ± ± ± HP-NNET convex ± ± ± HP-NNET convex ± ± ± HP-NNET MRBI ± ± ± HP-NNET MRBI ± ± ± HP-DBNET convex ± ± ± HP-DBNET convex ± ± ± Auto-WEKA 30h 27.5± ± ± Log.Regression 5CV 500 folds 8.1± ± ± HP-NNET convex 5CV 500 folds 18.2± ± ± HP-NNET MRBI 5CV 500 folds 47.9± ± ±
27 Terminology Bayesian optimization Reinforcement learning Surrogate model Kriging
28 What else? Data structures for fast optimum search Cold start problem Different parameters require different learning time Labels transformation
29 Summary We usually need to optimize stochastic functions Surrogate model should be fit to the data Several good implementations already exist Random search is much better than you thought!
30 Thank you! Alexander Fonarev
2. Blackbox hyperparameter optimization and AutoML
 AutoML 2017. Automatic Selection, Configuration & Composition of ML Algorithms. at ECML PKDD 2017, Skopje. 2. Blackbox hyperparameter optimization and AutoML Pavel Brazdil, Frank Hutter, Holger Hoos, Joaquin
AutoML 2017. Automatic Selection, Configuration & Composition of ML Algorithms. at ECML PKDD 2017, Skopje. 2. Blackbox hyperparameter optimization and AutoML Pavel Brazdil, Frank Hutter, Holger Hoos, Joaquin
Traditional Acquisition Functions for Bayesian Optimization
 Traditional Acquisition Functions for Bayesian Optimization Jungtaek Kim (jtkim@postech.edu) Machine Learning Group, Department of Computer Science and Engineering, POSTECH, 77-Cheongam-ro, Nam-gu, Pohang-si
Traditional Acquisition Functions for Bayesian Optimization Jungtaek Kim (jtkim@postech.edu) Machine Learning Group, Department of Computer Science and Engineering, POSTECH, 77-Cheongam-ro, Nam-gu, Pohang-si
Bayesian Optimization Nando de Freitas
 Bayesian Optimization Nando de Freitas Eric Brochu, Ruben Martinez-Cantin, Matt Hoffman, Ziyu Wang, More resources This talk follows the presentation in the following review paper available fro Oxford
Bayesian Optimization Nando de Freitas Eric Brochu, Ruben Martinez-Cantin, Matt Hoffman, Ziyu Wang, More resources This talk follows the presentation in the following review paper available fro Oxford
Efficient Benchmarking of Hyperparameter Optimizers via Surrogates
 Efficient Benchmarking of Hyperparameter Optimizers via Surrogates Katharina Eggensperger and Frank Hutter University of Freiburg {eggenspk, fh}@cs.uni-freiburg.de Holger H. Hoos and Kevin Leyton-Brown
Efficient Benchmarking of Hyperparameter Optimizers via Surrogates Katharina Eggensperger and Frank Hutter University of Freiburg {eggenspk, fh}@cs.uni-freiburg.de Holger H. Hoos and Kevin Leyton-Brown
arxiv: v1 [cs.lg] 29 May 2014
![arxiv: v1 [cs.lg] 29 May 2014](/thumbs/91/105440169.jpg "arxiv: v1 [cs.lg] 29 May 2014") BayesOpt: A Bayesian Optimization Library for Nonlinear Optimization, Experimental Design and Bandits arxiv:1405.7430v1 [cs.lg] 29 May 2014 Ruben Martinez-Cantin rmcantin@unizar.es May 30, 2014 Abstract
BayesOpt: A Bayesian Optimization Library for Nonlinear Optimization, Experimental Design and Bandits arxiv:1405.7430v1 [cs.lg] 29 May 2014 Ruben Martinez-Cantin rmcantin@unizar.es May 30, 2014 Abstract
Efficient Hyper-parameter Optimization for NLP Applications
 Efficient Hyper-parameter Optimization for NLP Applications Lidan Wang 1, Minwei Feng 1, Bowen Zhou 1, Bing Xiang 1, Sridhar Mahadevan 2,1 1 IBM Watson, T. J. Watson Research Center, NY 2 College of Information
Efficient Hyper-parameter Optimization for NLP Applications Lidan Wang 1, Minwei Feng 1, Bowen Zhou 1, Bing Xiang 1, Sridhar Mahadevan 2,1 1 IBM Watson, T. J. Watson Research Center, NY 2 College of Information
Learning to Transfer Initializations for Bayesian Hyperparameter Optimization
 Learning to Transfer Initializations for Bayesian Hyperparameter Optimization Jungtaek Kim, Saehoon Kim, and Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and
Learning to Transfer Initializations for Bayesian Hyperparameter Optimization Jungtaek Kim, Saehoon Kim, and Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and
Efficient Hyperparameter Optimization of Deep Learning Algorithms Using Deterministic RBF Surrogates
 Efficient Hyperparameter Optimization of Deep Learning Algorithms Using Deterministic RBF Surrogates Ilija Ilievski Graduate School for Integrative Sciences and Engineering National University of Singapore
Efficient Hyperparameter Optimization of Deep Learning Algorithms Using Deterministic RBF Surrogates Ilija Ilievski Graduate School for Integrative Sciences and Engineering National University of Singapore
Black-Box Hyperparameter Optimization for Nuclei Segmentation in Prostate Tissue Images
 Black-Box Hyperparameter Optimization for Nuclei Segmentation in Prostate Tissue Images Thomas Wollmann 1, Patrick Bernhard 1,ManuelGunkel 2, Delia M. Braun 3, Jan Meiners 4, Ronald Simon 4, Guido Sauter
Black-Box Hyperparameter Optimization for Nuclei Segmentation in Prostate Tissue Images Thomas Wollmann 1, Patrick Bernhard 1,ManuelGunkel 2, Delia M. Braun 3, Jan Meiners 4, Ronald Simon 4, Guido Sauter
Practical Machine Learning in R
 Practical Machine Learning in R Tuning Lars Kotthoff 12 larsko@uwo.edu 1 with slides from Bernd Bischl and Michel Lang 2 slides available at http://www.cs.uwo.edu/~larsko/ml-fac 1 Tuning Frank Hutter and
Practical Machine Learning in R Tuning Lars Kotthoff 12 larsko@uwo.edu 1 with slides from Bernd Bischl and Michel Lang 2 slides available at http://www.cs.uwo.edu/~larsko/ml-fac 1 Tuning Frank Hutter and
Towards efficient Bayesian Optimization for Big Data
 Towards efficient Bayesian Optimization for Big Data Aaron Klein 1 Simon Bartels Stefan Falkner 1 Philipp Hennig Frank Hutter 1 1 Department of Computer Science University of Freiburg, Germany {kleinaa,sfalkner,fh}@cs.uni-freiburg.de
Towards efficient Bayesian Optimization for Big Data Aaron Klein 1 Simon Bartels Stefan Falkner 1 Philipp Hennig Frank Hutter 1 1 Department of Computer Science University of Freiburg, Germany {kleinaa,sfalkner,fh}@cs.uni-freiburg.de
Otto Group Product Classification Challenge
 Otto Group Product Classification Challenge Hoang Duong May 19, 2015 1 Introduction The Otto Group Product Classification Challenge is the biggest Kaggle competition to date with 3590 participating teams.
Otto Group Product Classification Challenge Hoang Duong May 19, 2015 1 Introduction The Otto Group Product Classification Challenge is the biggest Kaggle competition to date with 3590 participating teams.
Advancing Bayesian Optimization: The Mixed-Global-Local (MGL) Kernel and Length-Scale Cool Down
 Kernel and Length-Scale Cool Down") Advancing Bayesian Optimization: The Mixed-Global-Local (MGL) Kernel and Length-Scale Cool Down Kim P. Wabersich Machine Learning and Robotics Lab University of Stuttgart, Germany wabersich@kimpeter.de
Advancing Bayesian Optimization: The Mixed-Global-Local (MGL) Kernel and Length-Scale Cool Down Kim P. Wabersich Machine Learning and Robotics Lab University of Stuttgart, Germany wabersich@kimpeter.de
arxiv: v1 [cs.cv] 5 Jan 2018
![arxiv: v1 [cs.cv] 5 Jan 2018](/thumbs/93/111846177.jpg "arxiv: v1 [cs.cv] 5 Jan 2018") Combination of Hyperband and Bayesian Optimization for Hyperparameter Optimization in Deep Learning arxiv:1801.01596v1 [cs.cv] 5 Jan 2018 Jiazhuo Wang Blippar jiazhuo.wang@blippar.com Jason Xu Blippar
Combination of Hyperband and Bayesian Optimization for Hyperparameter Optimization in Deep Learning arxiv:1801.01596v1 [cs.cv] 5 Jan 2018 Jiazhuo Wang Blippar jiazhuo.wang@blippar.com Jason Xu Blippar
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D.
 PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
PSU Student Research Symposium 2017 Bayesian Optimization for Refining Object Proposals, with an Application to Pedestrian Detection Anthony D. Rhodes 5/10/17 What is Machine Learning? Machine learning
Bayesian Optimization for Parameter Selection of Random Forests Based Text Classifier
 Bayesian Optimization for Parameter Selection of Random Forests Based Text Classifier 1 2 3 4 Anonymous Author(s) Affiliation Address email 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
Bayesian Optimization for Parameter Selection of Random Forests Based Text Classifier 1 2 3 4 Anonymous Author(s) Affiliation Address email 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
arxiv: v3 [cs.lg] 24 Jun 2016
![arxiv: v3 [cs.lg] 24 Jun 2016](/thumbs/93/113331789.jpg "arxiv: v3 [cs.lg] 24 Jun 2016") FLASH: Fast Bayesian Optimization for Data Analytic Pipelines arxiv:1602.06468v3 [cs.lg] 24 Jun 2016 Yuyu Zhang Mohammad Taha Bahadori Hang Su Jimeng Sun Georgia Institute of Technology {yuyu,bahadori,hangsu}@gatech.edu,jsun@cc.gatech.edu
FLASH: Fast Bayesian Optimization for Data Analytic Pipelines arxiv:1602.06468v3 [cs.lg] 24 Jun 2016 Yuyu Zhang Mohammad Taha Bahadori Hang Su Jimeng Sun Georgia Institute of Technology {yuyu,bahadori,hangsu}@gatech.edu,jsun@cc.gatech.edu
AI-Augmented Algorithms
 AI-Augmented Algorithms How I Learned to Stop Worrying and Love Choice Lars Kotthoff University of Wyoming larsko@uwyo.edu Warsaw, 17 April 2019 Outline Big Picture Motivation Choosing Algorithms Tuning
AI-Augmented Algorithms How I Learned to Stop Worrying and Love Choice Lars Kotthoff University of Wyoming larsko@uwyo.edu Warsaw, 17 April 2019 Outline Big Picture Motivation Choosing Algorithms Tuning
Supplementary material for the paper: Bayesian Optimization with Robust Bayesian Neural Networks
 Supplementary material for the paper: Bayesian Optimization with Robust Bayesian Neural Networks Jost Tobias Springenberg Aaron Klein Stefan Falkner Frank Hutter Department of Computer Science University
Supplementary material for the paper: Bayesian Optimization with Robust Bayesian Neural Networks Jost Tobias Springenberg Aaron Klein Stefan Falkner Frank Hutter Department of Computer Science University
Structure Optimization for Deep Multimodal Fusion Networks using Graph-Induced Kernels
 Structure Optimization for Deep Multimodal Fusion Networks using Graph-Induced Kernels Dhanesh Ramachandram 1, Michal Lisicki 1, Timothy J. Shields, Mohamed R. Amer and Graham W. Taylor1 1- Machine Learning
Structure Optimization for Deep Multimodal Fusion Networks using Graph-Induced Kernels Dhanesh Ramachandram 1, Michal Lisicki 1, Timothy J. Shields, Mohamed R. Amer and Graham W. Taylor1 1- Machine Learning
Sequential Model-based Optimization for General Algorithm Configuration
 Sequential Model-based Optimization for General Algorithm Configuration Frank Hutter, Holger Hoos, Kevin Leyton-Brown University of British Columbia LION 5, Rome January 18, 2011 Motivation Most optimization
Sequential Model-based Optimization for General Algorithm Configuration Frank Hutter, Holger Hoos, Kevin Leyton-Brown University of British Columbia LION 5, Rome January 18, 2011 Motivation Most optimization
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Think Globally, Act Locally: a Local Strategy for Bayesian Optimization
 Think Globally, Act Locally: a Local Strategy for Bayesian Optimization Vu Nguyen, Sunil Gupta, Santu Rana, Cheng Li, Svetha Venkatesh Centre of Pattern Recognition and Data Analytic (PraDa), Deakin University
Think Globally, Act Locally: a Local Strategy for Bayesian Optimization Vu Nguyen, Sunil Gupta, Santu Rana, Cheng Li, Svetha Venkatesh Centre of Pattern Recognition and Data Analytic (PraDa), Deakin University
Data-Driven Evolutionary Optimization of Complex Systems: Big vs Small Data
 Data-Driven Evolutionary Optimization of Complex Systems: Big vs Small Data Yaochu Jin Head, Nature Inspired Computing and Engineering (NICE) Department of Computer Science, University of Surrey, United
Data-Driven Evolutionary Optimization of Complex Systems: Big vs Small Data Yaochu Jin Head, Nature Inspired Computing and Engineering (NICE) Department of Computer Science, University of Surrey, United
DATA MINING AND MACHINE LEARNING. Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
Supplementary material for: BO-HB: Robust and Efficient Hyperparameter Optimization at Scale
 Supplementary material for: BO-: Robust and Efficient Hyperparameter Optimization at Scale Stefan Falkner 1 Aaron Klein 1 Frank Hutter 1 A. Available Software To promote reproducible science and enable
Supplementary material for: BO-: Robust and Efficient Hyperparameter Optimization at Scale Stefan Falkner 1 Aaron Klein 1 Frank Hutter 1 A. Available Software To promote reproducible science and enable
Experienced Optimization with Reusable Directional Model for Hyper-Parameter Search
 Experienced Optimization with Reusable Directional Model for Hyper-Parameter Search Yi-Qi Hu and Yang Yu and Zhi-Hua Zhou National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing
Experienced Optimization with Reusable Directional Model for Hyper-Parameter Search Yi-Qi Hu and Yang Yu and Zhi-Hua Zhou National Key Laboratory for Novel Software Technology, Nanjing University, Nanjing
GRADIENT-BASED OPTIMIZATION OF NEURAL
 Workshop track - ICLR 28 GRADIENT-BASED OPTIMIZATION OF NEURAL NETWORK ARCHITECTURE Will Grathwohl, Elliot Creager, Seyed Kamyar Seyed Ghasemipour, Richard Zemel Department of Computer Science University
Workshop track - ICLR 28 GRADIENT-BASED OPTIMIZATION OF NEURAL NETWORK ARCHITECTURE Will Grathwohl, Elliot Creager, Seyed Kamyar Seyed Ghasemipour, Richard Zemel Department of Computer Science University
Efficient Transfer Learning Method for Automatic Hyperparameter Tuning
 Efficient Transfer Learning Method for Automatic Hyperparameter Tuning Dani Yogatama Carnegie Mellon University Pittsburgh, PA 1513, USA dyogatama@cs.cmu.edu Gideon Mann Google Research New York, NY 111,
Efficient Transfer Learning Method for Automatic Hyperparameter Tuning Dani Yogatama Carnegie Mellon University Pittsburgh, PA 1513, USA dyogatama@cs.cmu.edu Gideon Mann Google Research New York, NY 111,
Hyperopt: a Python library for model selection and hyperparameter optimization
 Computational Science & Discovery PAPER Hyperopt: a Python library for model selection and hyperparameter optimization To cite this article: James Bergstra et al Comput. Sci. Disc. 000 Manuscript version:
Computational Science & Discovery PAPER Hyperopt: a Python library for model selection and hyperparameter optimization To cite this article: James Bergstra et al Comput. Sci. Disc. 000 Manuscript version:
Scalable Meta-Learning for Bayesian Optimization using Ranking-Weighted Gaussian Process Ensembles
 ICML 2018 AutoML Workshop Scalable Meta-Learning for Bayesian Optimization using Ranking-Weighted Gaussian Process Ensembles Matthias Feurer University of Freiburg Benjamin Letham Facebook Eytan Bakshy
ICML 2018 AutoML Workshop Scalable Meta-Learning for Bayesian Optimization using Ranking-Weighted Gaussian Process Ensembles Matthias Feurer University of Freiburg Benjamin Letham Facebook Eytan Bakshy
Classification: Linear Discriminant Functions
 Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
arxiv: v1 [stat.ml] 14 Aug 2015
![arxiv: v1 [stat.ml] 14 Aug 2015](/thumbs/81/82859502.jpg "arxiv: v1 [stat.ml] 14 Aug 2015") Unbounded Bayesian Optimization via Regularization arxiv:1508.03666v1 [stat.ml] 14 Aug 2015 Bobak Shahriari University of British Columbia bshahr@cs.ubc.ca Alexandre Bouchard-Côté University of British
Unbounded Bayesian Optimization via Regularization arxiv:1508.03666v1 [stat.ml] 14 Aug 2015 Bobak Shahriari University of British Columbia bshahr@cs.ubc.ca Alexandre Bouchard-Côté University of British
BAYESIAN GLOBAL OPTIMIZATION
 BAYESIAN GLOBAL OPTIMIZATION Using Optimal Learning to Tune Deep Learning Pipelines Scott Clark scott@sigopt.com OUTLINE 1. Why is Tuning AI Models Hard? 2. Comparison of Tuning Methods 3. Bayesian Global
BAYESIAN GLOBAL OPTIMIZATION Using Optimal Learning to Tune Deep Learning Pipelines Scott Clark scott@sigopt.com OUTLINE 1. Why is Tuning AI Models Hard? 2. Comparison of Tuning Methods 3. Bayesian Global
Auto-WEKA: Combined Selection and Hyperparameter Optimization of Supervised Machine Learning Algorithms
 Auto-WEKA: Combined Selection and Hyperparameter Optimization of Supervised Machine Learning Algorithms by Chris Thornton B.Sc, University of Calgary, 2011 a thesis submitted in partial fulfillment of
Auto-WEKA: Combined Selection and Hyperparameter Optimization of Supervised Machine Learning Algorithms by Chris Thornton B.Sc, University of Calgary, 2011 a thesis submitted in partial fulfillment of
arxiv: v1 [cs.lg] 31 Mar 2016
![arxiv: v1 [cs.lg] 31 Mar 2016](/thumbs/79/80110045.jpg "arxiv: v1 [cs.lg] 31 Mar 2016") arxiv:1603.09441v1 [cs.lg] 31 Mar 2016 Ian Dewancker Michael McCourt Scott Clark Patrick Hayes Alexandra Johnson George Ke SigOpt, San Francisco, CA 94108 USA Abstract Empirical analysis serves as an important
arxiv:1603.09441v1 [cs.lg] 31 Mar 2016 Ian Dewancker Michael McCourt Scott Clark Patrick Hayes Alexandra Johnson George Ke SigOpt, San Francisco, CA 94108 USA Abstract Empirical analysis serves as an important
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Combining Hyperband and Bayesian Optimization
 Combining Hyperband and Bayesian Optimization Stefan Falkner Aaron Klein Frank Hutter Department of Computer Science University of Freiburg {sfalkner, kleinaa, fh}@cs.uni-freiburg.de Abstract Proper hyperparameter
Combining Hyperband and Bayesian Optimization Stefan Falkner Aaron Klein Frank Hutter Department of Computer Science University of Freiburg {sfalkner, kleinaa, fh}@cs.uni-freiburg.de Abstract Proper hyperparameter
Automatic Machine Learning (AutoML): A Tutorial
: A Tutorial") Automatic Machine Learning (AutoML): A Tutorial Frank Hutter University of Freiburg fh@cs.uni-freiburg.de Joaquin Vanschoren Eindhoven University of Technology j.vanschoren@tue.nl Slides available at automl.org/events
Automatic Machine Learning (AutoML): A Tutorial Frank Hutter University of Freiburg fh@cs.uni-freiburg.de Joaquin Vanschoren Eindhoven University of Technology j.vanschoren@tue.nl Slides available at automl.org/events
AI-Augmented Algorithms
 AI-Augmented Algorithms How I Learned to Stop Worrying and Love Choice Lars Kotthoff University of Wyoming larsko@uwyo.edu Boulder, 16 January 2019 Outline Big Picture Motivation Choosing Algorithms Tuning
AI-Augmented Algorithms How I Learned to Stop Worrying and Love Choice Lars Kotthoff University of Wyoming larsko@uwyo.edu Boulder, 16 January 2019 Outline Big Picture Motivation Choosing Algorithms Tuning
arxiv: v1 [cs.lg] 6 Jun 2016
![arxiv: v1 [cs.lg] 6 Jun 2016](/thumbs/86/94931464.jpg "arxiv: v1 [cs.lg] 6 Jun 2016") Learning to Optimize arxiv:1606.01885v1 [cs.lg] 6 Jun 2016 Ke Li Jitendra Malik Department of Electrical Engineering and Computer Sciences University of California, Berkeley Berkeley, CA 94720 United States
Learning to Optimize arxiv:1606.01885v1 [cs.lg] 6 Jun 2016 Ke Li Jitendra Malik Department of Electrical Engineering and Computer Sciences University of California, Berkeley Berkeley, CA 94720 United States
Scalable Automated Model Search
 Scalable Automated Model Search Evan Sparks Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2014-122 http://www.eecs.berkeley.edu/pubs/techrpts/2014/eecs-2014-122.html
Scalable Automated Model Search Evan Sparks Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2014-122 http://www.eecs.berkeley.edu/pubs/techrpts/2014/eecs-2014-122.html
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Speed-Constrained Tuning for Statistical Machine Translation Using Bayesian Optimization
 Speed-Constrained Tuning for Statistical Machine Translation Using Bayesian Optimization Daniel Beck Adrià de Gispert Gonzalo Iglesias Aurelien Waite Bill Byrne Department of Computer Science, University
Speed-Constrained Tuning for Statistical Machine Translation Using Bayesian Optimization Daniel Beck Adrià de Gispert Gonzalo Iglesias Aurelien Waite Bill Byrne Department of Computer Science, University
7. Metalearning for Automated Workflow Design
 AutoML 2017. at ECML PKDD 2017, Skopje. Automatic Selection, Configuration & Composition of ML Algorithms 7. Metalearning for Automated Workflow Design by. Pavel Brazdil, Frank Hutter, Holger Hoos, Joaquin
AutoML 2017. at ECML PKDD 2017, Skopje. Automatic Selection, Configuration & Composition of ML Algorithms 7. Metalearning for Automated Workflow Design by. Pavel Brazdil, Frank Hutter, Holger Hoos, Joaquin
Multi-Fidelity Automatic Hyper-Parameter Tuning via Transfer Series Expansion
 Multi-Fidelity Automatic Hyper-Parameter Tuning via Transfer Series Expansion Yi-Qi Hu 1,2, Yang Yu 1, Wei-Wei Tu 2, Qiang Yang 3, Yuqiang Chen 2, Wenyuan Dai 2 1 National Key aboratory for Novel Software
Multi-Fidelity Automatic Hyper-Parameter Tuning via Transfer Series Expansion Yi-Qi Hu 1,2, Yang Yu 1, Wei-Wei Tu 2, Qiang Yang 3, Yuqiang Chen 2, Wenyuan Dai 2 1 National Key aboratory for Novel Software
SpySMAC: Automated Configuration and Performance Analysis of SAT Solvers
 SpySMAC: Automated Configuration and Performance Analysis of SAT Solvers Stefan Falkner, Marius Lindauer, and Frank Hutter University of Freiburg {sfalkner,lindauer,fh}@cs.uni-freiburg.de Abstract. Most
SpySMAC: Automated Configuration and Performance Analysis of SAT Solvers Stefan Falkner, Marius Lindauer, and Frank Hutter University of Freiburg {sfalkner,lindauer,fh}@cs.uni-freiburg.de Abstract. Most
arxiv: v2 [cs.lg] 15 Mar 2015
![arxiv: v2 [cs.lg] 15 Mar 2015](/thumbs/88/117792029.jpg "arxiv: v2 [cs.lg] 15 Mar 2015") apsis Framework for Automated Optimization of Machine Learning Hyper Parameters Frederik Diehl and Andreas Jauch arxiv:1503.02946v2 [cs.lg] 15 Mar 2015 1 Introduction Technische Universität München frederik.diehl@tum.de
apsis Framework for Automated Optimization of Machine Learning Hyper Parameters Frederik Diehl and Andreas Jauch arxiv:1503.02946v2 [cs.lg] 15 Mar 2015 1 Introduction Technische Universität München frederik.diehl@tum.de
GPflowOpt: A Bayesian Optimization Library using TensorFlow
 GPflowOpt: A Bayesian Optimization Library using TensorFlow Nicolas Knudde Joachim van der Herten Tom Dhaene Ivo Couckuyt Ghent University imec IDLab Department of Information Technology {nicolas.knudde,
GPflowOpt: A Bayesian Optimization Library using TensorFlow Nicolas Knudde Joachim van der Herten Tom Dhaene Ivo Couckuyt Ghent University imec IDLab Department of Information Technology {nicolas.knudde,
k-nearest Neighbors + Model Selection
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
arxiv: v3 [stat.ml] 14 Feb 2018
![arxiv: v3 [stat.ml] 14 Feb 2018](/thumbs/80/82087718.jpg "arxiv: v3 [stat.ml] 14 Feb 2018") Open Loop Hyperparameter Optimization and Determinantal Point Processes Jesse Dodge 1 Kevin Jamieson 2 Noah A. Smith 2 arxiv:1706.01566v3 [stat.ml] 14 Feb 2018 Abstract Driven by the need for parallelizable
Open Loop Hyperparameter Optimization and Determinantal Point Processes Jesse Dodge 1 Kevin Jamieson 2 Noah A. Smith 2 arxiv:1706.01566v3 [stat.ml] 14 Feb 2018 Abstract Driven by the need for parallelizable
hyperspace: Automated Optimization of Complex Processing Pipelines for pyspace
 hyperspace: Automated Optimization of Complex Processing Pipelines for pyspace Torben Hansing, Mario Michael Krell, Frank Kirchner Robotics Research Group University of Bremen Robert-Hooke-Str. 1, 28359
hyperspace: Automated Optimization of Complex Processing Pipelines for pyspace Torben Hansing, Mario Michael Krell, Frank Kirchner Robotics Research Group University of Bremen Robert-Hooke-Str. 1, 28359
New developments in LS-OPT
 7. LS-DYNA Anwenderforum, Bamberg 2008 Optimierung II New developments in LS-OPT Nielen Stander, Tushar Goel, Willem Roux Livermore Software Technology Corporation, Livermore, CA94551, USA Summary: This
7. LS-DYNA Anwenderforum, Bamberg 2008 Optimierung II New developments in LS-OPT Nielen Stander, Tushar Goel, Willem Roux Livermore Software Technology Corporation, Livermore, CA94551, USA Summary: This
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
On Classification: An Empirical Study of Existing Algorithms Based on Two Kaggle Competitions
 On Classification: An Empirical Study of Existing Algorithms Based on Two Kaggle Competitions CAMCOS Report Day December 9th, 2015 San Jose State University Project Theme: Classification The Kaggle Competition
On Classification: An Empirical Study of Existing Algorithms Based on Two Kaggle Competitions CAMCOS Report Day December 9th, 2015 San Jose State University Project Theme: Classification The Kaggle Competition
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
arxiv: v1 [cs.lg] 6 Dec 2017
![arxiv: v1 [cs.lg] 6 Dec 2017](/thumbs/80/81219573.jpg "arxiv: v1 [cs.lg] 6 Dec 2017") This paper will appear in the proceedings of DATE 2018. Pre-print version, for personal use only. HyperPower: Power- and Memory-Constrained Hyper-Parameter Optimization for Neural Networks Dimitrios Stamoulis,
This paper will appear in the proceedings of DATE 2018. Pre-print version, for personal use only. HyperPower: Power- and Memory-Constrained Hyper-Parameter Optimization for Neural Networks Dimitrios Stamoulis,
Algorithms for Hyper-Parameter Optimization
 Algorithms for Hyper-Parameter Optimization James Bergstra, R. Bardenet, Yoshua Bengio, Balázs Kégl To cite this version: James Bergstra, R. Bardenet, Yoshua Bengio, Balázs Kégl. Algorithms for Hyper-Parameter
Algorithms for Hyper-Parameter Optimization James Bergstra, R. Bardenet, Yoshua Bengio, Balázs Kégl To cite this version: James Bergstra, R. Bardenet, Yoshua Bengio, Balázs Kégl. Algorithms for Hyper-Parameter
Index. Umberto Michelucci 2018 U. Michelucci, Applied Deep Learning,
 A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
A Acquisition function, 298, 301 Adam optimizer, 175 178 Anaconda navigator conda command, 3 Create button, 5 download and install, 1 installing packages, 8 Jupyter Notebook, 11 13 left navigation pane,
Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms
 Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms Chris Thornton Frank Hutter Holger H. Hoos Kevin Leyton-Brown Department of Computer Science, University of British
Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms Chris Thornton Frank Hutter Holger H. Hoos Kevin Leyton-Brown Department of Computer Science, University of British
Feature Selection. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
Feature Selection CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Dimensionality reduction Feature selection vs. feature extraction Filter univariate
HYPERBAND: BANDIT-BASED CONFIGURATION EVAL-
 HYPERBAND: BANDIT-BASED CONFIGURATION EVAL- UATION FOR HYPERPARAMETER OPTIMIZATION Lisha Li UCLA lishal@cs.ucla.edu Kevin Jamieson UC Berkeley kjamieson@berkeley.edu Giulia DeSalvo NYU desalvo@cims.nyu.edu
HYPERBAND: BANDIT-BASED CONFIGURATION EVAL- UATION FOR HYPERPARAMETER OPTIMIZATION Lisha Li UCLA lishal@cs.ucla.edu Kevin Jamieson UC Berkeley kjamieson@berkeley.edu Giulia DeSalvo NYU desalvo@cims.nyu.edu
Logistic Regression. Abstract
 Logistic Regression Tsung-Yi Lin, Chen-Yu Lee Department of Electrical and Computer Engineering University of California, San Diego {tsl008, chl60}@ucsd.edu January 4, 013 Abstract Logistic regression
Logistic Regression Tsung-Yi Lin, Chen-Yu Lee Department of Electrical and Computer Engineering University of California, San Diego {tsl008, chl60}@ucsd.edu January 4, 013 Abstract Logistic regression
The Mathematics Behind Neural Networks
 The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
Software Documentation of the Potential Support Vector Machine
 Software Documentation of the Potential Support Vector Machine Tilman Knebel and Sepp Hochreiter Department of Electrical Engineering and Computer Science Technische Universität Berlin 10587 Berlin, Germany
Software Documentation of the Potential Support Vector Machine Tilman Knebel and Sepp Hochreiter Department of Electrical Engineering and Computer Science Technische Universität Berlin 10587 Berlin, Germany
Batch Bayesian Optimization via Multi-objective Acquisition Ensemble for Automated Analog Circuit Design
 Batch Bayesian Optimization via Multi-objective Acquisition Ensemble for Automated Analog Circuit Design Wenlong Lyu 1 Fan Yang 1 Changhao Yan 1 Dian Zhou 1 2 Xuan Zeng 1 Abstract Bayesian optimization
Batch Bayesian Optimization via Multi-objective Acquisition Ensemble for Automated Analog Circuit Design Wenlong Lyu 1 Fan Yang 1 Changhao Yan 1 Dian Zhou 1 2 Xuan Zeng 1 Abstract Bayesian optimization
Hyperparameter optimization. CS6787 Lecture 6 Fall 2017
 Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR
 3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
3D Convolutional Neural Networks for Landing Zone Detection from LiDAR Daniel Mataruna and Sebastian Scherer Presented by: Sabin Kafle Outline Introduction Preliminaries Approach Volumetric Density Mapping
Bayesian Optimization without Acquisition Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Multidisciplinary System Design Optimization (MSDO) Course Summary
 Course Summary") Multidisciplinary System Design Optimization (MSDO) Course Summary Lecture 23 Prof. Olivier de Weck Prof. Karen Willcox 1 Outline Summarize course content Present some emerging research directions Interactive
Multidisciplinary System Design Optimization (MSDO) Course Summary Lecture 23 Prof. Olivier de Weck Prof. Karen Willcox 1 Outline Summarize course content Present some emerging research directions Interactive
An Empirical Study of Hyperparameter Importance Across Datasets
 An Empirical Study of Hyperparameter Importance Across Datasets Jan N. van Rijn and Frank Hutter University of Freiburg, Germany {vanrijn,fh}@cs.uni-freiburg.de Abstract. With the advent of automated machine
An Empirical Study of Hyperparameter Importance Across Datasets Jan N. van Rijn and Frank Hutter University of Freiburg, Germany {vanrijn,fh}@cs.uni-freiburg.de Abstract. With the advent of automated machine
Information theory methods for feature selection
 Information theory methods for feature selection Zuzana Reitermanová Department of Computer Science Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Diplomový a doktorandský
Information theory methods for feature selection Zuzana Reitermanová Department of Computer Science Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Diplomový a doktorandský
CS281 Section 3: Practical Optimization
 CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Machine learning and black-box expensive optimization
 Machine learning and black-box expensive optimization Sébastien Verel Laboratoire d Informatique, Signal et Image de la Côte d opale (LISIC) Université du Littoral Côte d Opale, Calais, France http://www-lisic.univ-littoral.fr/~verel/
Machine learning and black-box expensive optimization Sébastien Verel Laboratoire d Informatique, Signal et Image de la Côte d opale (LISIC) Université du Littoral Côte d Opale, Calais, France http://www-lisic.univ-littoral.fr/~verel/
MULTIVARIATE ANALYSIS AND ITS USE IN HIGH ENERGY PHYSICS
 1 DR ADRIAN BEVAN MULTIVARIATE ANALYSIS AND ITS USE IN HIGH ENERGY PHYSICS 4) OPTIMISATION Lectures given at the department of Physics at CINVESTAV, Instituto Politécnico Nacional, Mexico City 28th August
1 DR ADRIAN BEVAN MULTIVARIATE ANALYSIS AND ITS USE IN HIGH ENERGY PHYSICS 4) OPTIMISATION Lectures given at the department of Physics at CINVESTAV, Instituto Politécnico Nacional, Mexico City 28th August
Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008.
 Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008. Introduction There is much that is unknown regarding
Mapping of Hierarchical Activation in the Visual Cortex Suman Chakravartula, Denise Jones, Guillaume Leseur CS229 Final Project Report. Autumn 2008. Introduction There is much that is unknown regarding
An Empirical Evaluation of Deep Architectures on Problems with Many Factors of Variation
 An Empirical Evaluation of Deep Architectures on Problems with Many Factors of Variation Hugo Larochelle, Dumitru Erhan, Aaron Courville, James Bergstra, and Yoshua Bengio Université de Montréal 13/06/2007
An Empirical Evaluation of Deep Architectures on Problems with Many Factors of Variation Hugo Larochelle, Dumitru Erhan, Aaron Courville, James Bergstra, and Yoshua Bengio Université de Montréal 13/06/2007
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Bayesian Optimization for Learning Gaits under Uncertainty
 Noname manuscript No. (will be inserted by the editor) Bayesian Optimization for Learning Gaits under Uncertainty An experimental comparison on a dynamic bipedal walker Roberto Calandra André Seyfarth
Noname manuscript No. (will be inserted by the editor) Bayesian Optimization for Learning Gaits under Uncertainty An experimental comparison on a dynamic bipedal walker Roberto Calandra André Seyfarth
CS 179 Lecture 16. Logistic Regression & Parallel SGD
 CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
arxiv: v2 [cs.lg] 8 Nov 2017
![arxiv: v2 [cs.lg] 8 Nov 2017](/thumbs/77/75379241.jpg "arxiv: v2 [cs.lg] 8 Nov 2017") ACCELERATING NEURAL ARCHITECTURE SEARCH US- ING PERFORMANCE PREDICTION Bowen Baker 1, Otkrist Gupta 1, Ramesh Raskar 1, Nikhil Naik 2 (* - indicates equal contribution) 1 MIT Media Laboratory, Cambridge,
ACCELERATING NEURAL ARCHITECTURE SEARCH US- ING PERFORMANCE PREDICTION Bowen Baker 1, Otkrist Gupta 1, Ramesh Raskar 1, Nikhil Naik 2 (* - indicates equal contribution) 1 MIT Media Laboratory, Cambridge,
Logistic Regression
 Logistic Regression ddebarr@uw.edu 2016-05-26 Agenda Model Specification Model Fitting Bayesian Logistic Regression Online Learning and Stochastic Optimization Generative versus Discriminative Classifiers
Logistic Regression ddebarr@uw.edu 2016-05-26 Agenda Model Specification Model Fitting Bayesian Logistic Regression Online Learning and Stochastic Optimization Generative versus Discriminative Classifiers
arxiv: v3 [math.oc] 18 Mar 2015
![arxiv: v3 [math.oc] 18 Mar 2015](/thumbs/72/66721791.jpg "arxiv: v3 [math.oc] 18 Mar 2015") A warped kernel improving robustness in Bayesian optimization via random embeddings arxiv:1411.3685v3 [math.oc] 18 Mar 2015 Mickaël Binois 1,2 David Ginsbourger 3 Olivier Roustant 1 1 Mines Saint-Étienne,
A warped kernel improving robustness in Bayesian optimization via random embeddings arxiv:1411.3685v3 [math.oc] 18 Mar 2015 Mickaël Binois 1,2 David Ginsbourger 3 Olivier Roustant 1 1 Mines Saint-Étienne,
Auto-Extraction of Modelica Code from Finite Element Analysis or Measurement Data
 Auto-Extraction of Modelica Code from Finite Element Analysis or Measurement Data The-Quan Pham, Alfred Kamusella, Holger Neubert OptiY ek, Aschaffenburg Germany, e-mail: pham@optiyeu Technische Universität
Auto-Extraction of Modelica Code from Finite Element Analysis or Measurement Data The-Quan Pham, Alfred Kamusella, Holger Neubert OptiY ek, Aschaffenburg Germany, e-mail: pham@optiyeu Technische Universität
Keras: Handwritten Digit Recognition using MNIST Dataset
 Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Machine Learning for Professional Tennis Match Prediction and Betting
 Machine Learning for Professional Tennis Match Prediction and Betting Andre Cornman, Grant Spellman, Daniel Wright Abstract Our project had two main objectives. First, we wanted to use historical tennis
Machine Learning for Professional Tennis Match Prediction and Betting Andre Cornman, Grant Spellman, Daniel Wright Abstract Our project had two main objectives. First, we wanted to use historical tennis
Bayesian Adaptive Direct Search: Hybrid Bayesian Optimization for Model Fitting
 Bayesian Adaptive Direct Search: Hybrid Bayesian Optimization for Model Fitting Luigi Acerbi Center for Neural Science New Yor University luigi.acerbi@nyu.edu Wei Ji Ma Center for Neural Science & Dept.
Bayesian Adaptive Direct Search: Hybrid Bayesian Optimization for Model Fitting Luigi Acerbi Center for Neural Science New Yor University luigi.acerbi@nyu.edu Wei Ji Ma Center for Neural Science & Dept.
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Slides credited from Dr. David Silver & Hung-Yi Lee
 Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
Slides credited from Dr. David Silver & Hung-Yi Lee Review Reinforcement Learning 2 Reinforcement Learning RL is a general purpose framework for decision making RL is for an agent with the capacity to
One-Pass Ranking Models for Low-Latency Product Recommendations
 One-Pass Ranking Models for Low-Latency Product Recommendations Martin Saveski @msaveski MIT (Amazon Berlin) One-Pass Ranking Models for Low-Latency Product Recommendations Amazon Machine Learning Team,
One-Pass Ranking Models for Low-Latency Product Recommendations Martin Saveski @msaveski MIT (Amazon Berlin) One-Pass Ranking Models for Low-Latency Product Recommendations Amazon Machine Learning Team,
BOHB: Robust and Efficient Hyperparameter Optimization at Scale
 Stefan Falkner 1 Aaron Klein 1 Frank Hutter 1 Abstract Modern deep learning methods are very sensitive to many hyperparameters, and, due to the long training times of state-of-the-art models, vanilla Bayesian
Stefan Falkner 1 Aaron Klein 1 Frank Hutter 1 Abstract Modern deep learning methods are very sensitive to many hyperparameters, and, due to the long training times of state-of-the-art models, vanilla Bayesian
Multivariate Data Analysis and Machine Learning in High Energy Physics (V)
") Multivariate Data Analysis and Machine Learning in High Energy Physics (V) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline last lecture Rule Fitting Support Vector
Multivariate Data Analysis and Machine Learning in High Energy Physics (V) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline last lecture Rule Fitting Support Vector
Probabilistic Matrix Factorization for Automated Machine Learning
 Probabilistic Matrix Factorization for Automated Machine Learning Nicolo Fusi, Rishit Sheth Microsoft Research, New England {nfusi,rishet}@microsoft.com Melih Elibol EECS, University of California, Berkeley
Probabilistic Matrix Factorization for Automated Machine Learning Nicolo Fusi, Rishit Sheth Microsoft Research, New England {nfusi,rishet}@microsoft.com Melih Elibol EECS, University of California, Berkeley
Vulnerability of machine learning models to adversarial examples
 ITAT 216 Proceedings, CEUR Workshop Proceedings Vol. 1649, pp. 187 194 http://ceur-ws.org/vol-1649, Series ISSN 1613-73, c 216 P. Vidnerová, R. Neruda Vulnerability of machine learning models to adversarial
ITAT 216 Proceedings, CEUR Workshop Proceedings Vol. 1649, pp. 187 194 http://ceur-ws.org/vol-1649, Series ISSN 1613-73, c 216 P. Vidnerová, R. Neruda Vulnerability of machine learning models to adversarial
IE598 Big Data Optimization Summary Nonconvex Optimization
 IE598 Big Data Optimization Summary Nonconvex Optimization Instructor: Niao He April 16, 2018 1 This Course Big Data Optimization Explore modern optimization theories, algorithms, and big data applications
IE598 Big Data Optimization Summary Nonconvex Optimization Instructor: Niao He April 16, 2018 1 This Course Big Data Optimization Explore modern optimization theories, algorithms, and big data applications
ACCELERATING NEURAL ARCHITECTURE SEARCH US-
 ACCELERATING NEURAL ARCHITECTURE SEARCH US- ING PERFORMANCE PREDICTION Bowen Baker, Otkrist Gupta, Ramesh Raskar Media Laboratory Massachusetts Institute of Technology Cambridge, MA 02142, USA {bowen,otkrist,raskar}@mit.edu
ACCELERATING NEURAL ARCHITECTURE SEARCH US- ING PERFORMANCE PREDICTION Bowen Baker, Otkrist Gupta, Ramesh Raskar Media Laboratory Massachusetts Institute of Technology Cambridge, MA 02142, USA {bowen,otkrist,raskar}@mit.edu
MLCC 2018 Local Methods and Bias Variance Trade-Off. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 Local Methods and Bias Variance Trade-Off Lorenzo Rosasco UNIGE-MIT-IIT About this class 1. Introduce a basic class of learning methods, namely local methods. 2. Discuss the fundamental concept
MLCC 2018 Local Methods and Bias Variance Trade-Off Lorenzo Rosasco UNIGE-MIT-IIT About this class 1. Introduce a basic class of learning methods, namely local methods. 2. Discuss the fundamental concept
arxiv: v4 [stat.ml] 22 Apr 2018
![arxiv: v4 [stat.ml] 22 Apr 2018](/thumbs/88/115135946.jpg "arxiv: v4 [stat.ml] 22 Apr 2018") The Parallel Knowledge Gradient Method for Batch Bayesian Optimization arxiv:1606.04414v4 [stat.ml] 22 Apr 2018 Jian Wu, Peter I. Frazier Cornell University Ithaca, NY, 14853 {jw926, pf98}@cornell.edu
The Parallel Knowledge Gradient Method for Batch Bayesian Optimization arxiv:1606.04414v4 [stat.ml] 22 Apr 2018 Jian Wu, Peter I. Frazier Cornell University Ithaca, NY, 14853 {jw926, pf98}@cornell.edu