Data Science Tutorial
|
|
|
- Austin Greene
- 6 years ago
- Views:
Transcription

1 Eliezer Kanal Technical Manager, CERT Daniel DeCapria Data Scientist, ETC Software Engineering Institute Carnegie Mellon University Pittsburgh, PA SEI SEI Data Science in in Cybersecurity Symposium Approved for for Public Release; Distribution is Unlimited 1


2 About us Eliezer Kanal Technical Manager, CERT Recent projects: ML-based Malware Classifier Network traffic analysis Cybersecurity questionnaire optimization Recent projects: Daniel DeCapria Data Scientist, ETC Cyber risk situational dashboard Big Learning benchmarks 2
3 Today s presentation a tale of two roles The call center manager Introduction to data science capabilities The master carpenter Overview of the data science toolkit 3
4 Call center manager First day on job welcome! Goal: Reduce costs Task: Keep calls short! Data: Average call time: 5.14 minutes (5:08) very long! Number of employees: 300 Average calls per day: ~28,000 4
5 Call center manager Gather data Get the data! Where is it? What will you use to analyze it? How accurate it is? How complete is it? Is it too big to easily read? 5
6 Data cleaning = 90% of the work 2 weeks (10 days) = 9 cleaning, 1 analyzing 6
7 Cleaning the Data Structuring the Data Goal: Organize data in a table, where Columns = descriptor (age, weight, height) Row = individual, complete records How can you get data out of these documents? Less structure More structure 7

8 Cleaning the Data Even when you think your data should be clean, it might not be 8
9 Cleaning the Data Call Center Example Name Mgr Dir Call Length Phone Line Problem solved? Comment Beth Jones Dan Thomas Anne Kim 1:30 1 Y ❺ Beth Jones Dan Thomas Anne Kim 1:52 3 Y ❶ Jones, Beth Dan Thomas Anne Kim ❶ 90 2 Y Tom Keane Mark Ryan Tim Pike 88 2 N ❶ Tom Keane Mark Ryan Tim Pike No ❷ Tom Keane Kevin Wood Tim Pike 200 ❹ Yes Tom Keane Kevin Wood Tim Pike No ❸ ❻ Tom Keane Kevin Wood Tim Pike Yes String Integer Nominal Unstructured 9

10 Call Center manager Exploring data 10

11 Exploratory Data Analysis (EDA) Mean Median Standard deviation Histograms! 11

12 Distributions The majority of data will follow SOME distribution o Weight of all Americans: Gaussian o phone call length: Exponential Determining distribution is a common Data Science task Multidimensional outliers: Insider Threat example Image Copyright The Apache Software Foundation. See Copyright slide for more details. 12
13 EDA Smart visualizations 13
14 14
15 15

16 16
17 Brief interruption Skeptics in the audience 17
18 Brief interruption Data Science helps you use data to get results. This is it. 18


19 Call center manager call duration histogram Average (5:08) 19
20 Call Center manager Insights! Strategy update: Goodbye reduce call time Hello reduce callbacks How to measure? callbacks isn t currently captured 20
21 Feature Engineering Need more useful data? Create it yourself! 21
22 Feature Engineering Feature Engineering: coming up with new, useful (i.e., informative) data o mean, sums, medians, etc. o x 2, xy, sqrt(xy), etc. Our case: o # of callbacks o Call during peak time? o Overall agent performance? (combination of factors) 22

23 The role of Listening in Data Science Data science finds hidden patterns in data Experts know what data & patterns are important Talk to subject matter experts 23
24 Call Center manager Predictive analytics Can we predict staffing levels one day ahead? one week ahead? one month ahead? Can we determine what types of calls to expect for a product we haven t had before? for a market we ve never seen before? 24
25 Example Predictive Analytics Questions Predicting Current Unknowns Online: Security: Which ads are malicious? Is the bank transaction fraudulent? IC: Which names map to the same person (entity resolution)? Predicting Future Events Retail: Security: What will be the new trend of merchandise that a company should stock? Where will a hacker next attack our network? IC: Who will become the next insider threat? Determining Future Actions Sales: Health: IC: How can a company increase sales revenues? What actions can be taken to prevent the spread of flu? How will a vulnerability patch affect our knowledge/preparedness for future attacks? 25
26 Call Center manager Predictive analytics Many techniques available, explored in next section 26


27 Call Center manager Review Get data Clean data EDA, Visualization Interpretation Action! Prediction 27
28 Because we know our data, we can ask more intelligent questions action-oriented questions questions that can be answered 28
29 This slide intentionally left blank 29
30 The master carpenter The right tool for the job 30
31 Feature Engineering Part 2 With the wrong wood, I can make nothing The fuel of data science is data Data preparation is critical Data quality algorithm choice That will come up 31
32 Types of Machine Learning Algorithms Classification Naïve Bayes Logistic Regression Decision Trees K-Nearest Neighbors Support Vector Machines Regression Linear Regression Support Vector Machines Clustering K-Means Clustering 32
33 Types of Machine Learning Algorithms Applications: Everywhere Banking Weather Sports scores Economics Environmental science Cybersecurity 33
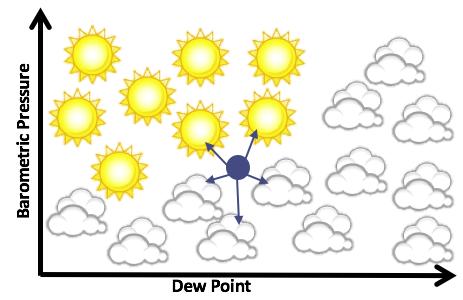
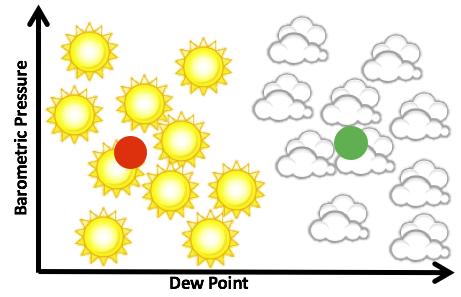
34 Linear Regression Prediction Problem: If I have examples of X and Y, when I learn a new X, can I predict Y? 34
35 Linear Regression Prediction Solution: Find the line that is closest to every point Said differently: Find the line that the SUM of all errors is smallest 35
36 Linear Regression Prediction Three dimensions, same concept HUNDREDS of dimensions, same concept 36
37 Linear Regression Very widely used Simple to implement Quick to run Easy to interpret Works for many problems First identified in early 1800 s; very well studied When applicable: Works best with numeric data (usually) Works for predicting specific numeric outcome 37
38 Logistic Regression Classification Idea: Classification using a discriminative model Predict future behavior based on existing labeled data Draws a line to assign labels Mainly used for binary classification: either red or blue 38
39 Logistic Regression Classification Look at distribution, what s likely based on current data Probably blue Probably red 39
40 Logistic Regression Three dimensions, same concept HUNDREDS of dimensions, same concept 40
41 Classification: Support Vector Machine Idea: The optimal classifier is the one that is the farthest from both classes Barometric Pressure Dew Point 41
42 Classification: Support Vector Machine Idea: The optimal classifier is the one that is the farthest from both classes Barometric Pressure Dew Point 42
43 Classification: Support Vector Machine Algorithm: Find lines like before Assign a cost to misclassified data points based on distance from the classification line Barometric Pressure ξ 1 ξ 2 Dew Point 43
44 Classification: Decision Trees Idea: Instead of drawing a single complicated line through the data, draw many simpler lines. Algorithm: Scan through all values of all features to find the one that helps the most to determine what data gets what label. Divide the data based on that value, and then repeat recursively on each part. Barometric Pressure Dew Point 44
45 Classification: Decision Trees Idea: Instead of drawing a single complicated line through the data, draw many simpler lines. Algorithm: Scan through all values of all features to find the one that helps the most to determine what data gets what label. Divide the data based on that value, and then repeat recursively on each part. DP > 60 Barometric Pressure Dew Point 45
46 Classification: Decision Trees Idea: Instead of drawing a single complicated line through the data, draw many simpler lines. Algorithm: Scan through all values of all features to find the one that helps the most to determine what data gets what label ( information gain ). Divide the data based on that value, and then repeat recursively on each part. DP > 60 Barometric Pressure B > 760 Dew Point 46
47 Classification: Decision Trees Benefits: Works well when small. Very easy to understand! Challenges: Trees overfit easily Very sensitive to data; Random Forests DP > 60 Barometric Pressure DP > 55 B > 760 Dew Point 47
48 Classification: K-Nearest Neighbors Idea: A new point is likely to share the same label as points around it. Algorithm: Pick constant k as number of neighbors to look at. For each new point, vote on new label using the k neighbor labels. Barometric Pressure Dew Point 48
49 Classification: K-Nearest Neighbors Idea: A new point is likely to share the same label as points around it. Algorithm: Pick constant k as number of neighbors to look at. For each new point, vote on new label using the k neighbor labels. Barometric Pressure Dew Point 49
50 Classification: K-Nearest Neighbors Idea: A new point is likely to share the same label as points around it. Algorithm: Pick constant k as number of neighbors to look at. For each new point, vote on new label using the k neighbor labels. Barometric Pressure Dew Point 50
51 Classification: K-Nearest Neighbors Works well when there is a good distance metric and weighting function to vote on classification Challenges: Not a smooth classifier; points near each other may get classified differently Must search all your data every time you want to classify a new point When k is small (1,2,3,4), essentially it is overfitting to the data points 51

52 Clustering Unsupervised learning Structure of un-labled data Organize records into groups based on some similarity measure Cluster is the collection of records which are similar 52
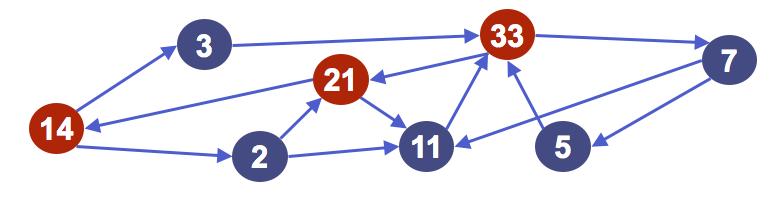
53 Clustering: K-means Idea: Find the clusters by minimizing distances of cluster centers to data. Algorithm: Instantiate k distinct random guesses μ - of the cluster centers Each data point classifies itself as the μ - it is closest to it Each μ - finds the centroid of the points that were closest to it and jumps there Repeat until centroids don t move Barometric Pressure Dew Point 53
54 Clustering: K-means Idea: Find the clusters by minimizing distances of cluster centers to data. Algorithm: Instantiate k distinct random guesses μ - of the cluster centers Each data point classifies itself as the μ - it is closest to it Each μ - finds the centroid of the points that were closest to it and jumps there Repeat until centroids don t move Barometric Pressure Dew Point 54
55 Clustering: K-means Idea: Find the clusters by minimizing distances of cluster centers to data. Algorithm: Instantiate k distinct random guesses μ - of the cluster centers Each data point classifies itself as the μ - it is closest to it Each μ - finds the centroid of the points that were closest to it and jumps there Repeat until centroids don t move Barometric Pressure Dew Point 55
56 Clustering: K-means Idea: Find the clusters by minimizing distances of cluster centers to data. Algorithm: Instantiate k distinct random guesses μ - of the cluster centers Each data point classifies itself as the μ - it is closest to it Each μ - finds the centroid of the points that were closest to it and jumps there Repeat until centroids don t move Barometric Pressure Dew Point 56
57 Clustering: K-means Idea: Find the clusters by minimizing distances of cluster centers to data. Algorithm: Instantiate k random guesses μ - of the clusters Each data point classifies itself as the μ - it is closest to it Each μ - finds the centroid of the points that were closest to it and jumps there Repeat until centroids don t move Barometric Pressure Dew Point 57
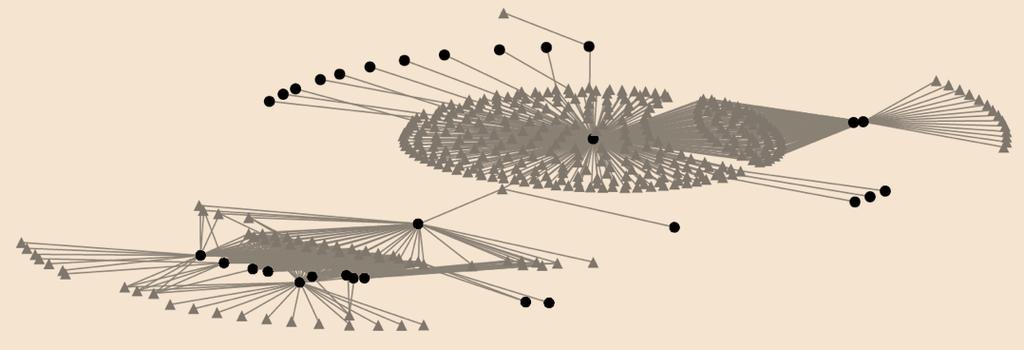
58 Clustering: K-means Works well when there is a good distance metric between the points the number of clusters is known in advance Challenges: Clusters that overlap or are not separable are difficult to cluster correctly. Barometric Pressure Dew Point 58
59 Influencers Goal: Detect the people who control or distribute information through a network. 59
60 Influencers: Degree Centrality Idea: Influential people have a lot of people watching them. Equation Degree centrality = number of directed edges to the node - High degree centrality people are those with large numbers of followers. If undirected graph, transform to bi-directional and compute 60
61 Influencers: Degree Centrality Idea: Influential people have a lot of people watching them. Equation Degree centrality = number of directed edges to the node - High degree centrality people are those with large numbers of followers. If undirected graph, transform to bi-directional and compute
62 Influencers: Betweenness Centrality Idea: Influential people are information brokers who connect different groups of people. Algorithm Find all shortest paths from all nodes to all other nodes in the graph. Betweenness centrality for a node = sum over all start and end nodes of the number of shortest paths in the graph that include the node 62
63 Influencers: Betweenness Centrality Idea: Influential people are information brokers who connect different groups of people. Algorithm Find all shortest paths from all nodes to all other nodes in the graph. Betweenness centrality for a node = sum over all start and end nodes of the number of shortest paths in the graph that include the node
64 Indicator communities But what if we aren t starting with a reference indicator? We assume that indicators generated by a coherent real world process will be more likely to co-occur in tickets than arbitrary pairs of indicators. Find groups of highly similar indicators in complete indicatorticket graph. 64

65 Indicator-ticket graph A subset of the ticket-indicator graph (for a small set of selected indicators) Tickets are grey triangles Indicators are black circles Edges connect tickets to the indicators they contain 65
66 Machine Learning Is Growing Preferred approach for many problems Speech recognition Natural language processing Medical diagnosis Robot control Sensor networks Computer vision Weather prediction Social network analysis AlphaGO, Watson Jeopardy! 66
67 This slide also intentionally left blank, just like the earlier one 67




68 What we did today Name Mgr Dir Beth Jones Dan Thomas Anne Kim Beth Jones Dan Thomas Anne Kim Jones, Beth Dan Thomas Anne Kim ❶ Tom Keane Mark Ryan Tim Pike Length Line Solved? Comment 1:30 1 Y ❺ 1:52 3 Y 90 2 Y 88 2 N ❶ Average (5:08) 68


69 What we did today 69
70 Data Science helps you use data to get results. 70
71 Eliezer Kanal Technical Manager (412) Daniel DeCapria Data Scientist (412)
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Analytical model A structure and process for analyzing a dataset. For example, a decision tree is a model for the classification of a dataset.
 Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Glossary of data mining terms: Accuracy Accuracy is an important factor in assessing the success of data mining. When applied to data, accuracy refers to the rate of correct values in the data. When applied
Data Preprocessing. Slides by: Shree Jaswal
 Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
Data Preprocessing Slides by: Shree Jaswal Topics to be covered Why Preprocessing? Data Cleaning; Data Integration; Data Reduction: Attribute subset selection, Histograms, Clustering and Sampling; Data
6.034 Quiz 2, Spring 2005
 6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
Data Mining: Models and Methods
 Data Mining: Models and Methods Author, Kirill Goltsman A White Paper July 2017 --------------------------------------------------- www.datascience.foundation Copyright 2016-2017 What is Data Mining? Data
Data Mining: Models and Methods Author, Kirill Goltsman A White Paper July 2017 --------------------------------------------------- www.datascience.foundation Copyright 2016-2017 What is Data Mining? Data
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
K-Means Clustering 3/3/17
 K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
The data science behind Vectra threat detections. White paper
 The data science behind Vectra threat detections White paper TABLE OF CONTENTS The Vectra model of threat detection.... 3 Global learning.... 4 The human element.... 4 Supervised machine learning.... 4
The data science behind Vectra threat detections White paper TABLE OF CONTENTS The Vectra model of threat detection.... 3 Global learning.... 4 The human element.... 4 Supervised machine learning.... 4
CPSC 340: Machine Learning and Data Mining. More Linear Classifiers Fall 2017
 CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
Nearest Neighbor Predictors
 Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Nearest Neighbor Predictors September 2, 2018 Perhaps the simplest machine learning prediction method, from a conceptual point of view, and perhaps also the most unusual, is the nearest-neighbor method,
Jarek Szlichta
 Jarek Szlichta http://data.science.uoit.ca/ Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns
Jarek Szlichta http://data.science.uoit.ca/ Approximate terminology, though there is some overlap: Data(base) operations Executing specific operations or queries over data Data mining Looking for patterns
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
7. Boosting and Bagging Bagging
 Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
Group Prof. Daniel Cremers 7. Boosting and Bagging Bagging Bagging So far: Boosting as an ensemble learning method, i.e.: a combination of (weak) learners A different way to combine classifiers is known
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Machine Learning with Python
 DEVNET-2163 Machine Learning with Python Dmitry Figol, SE WW Enterprise Sales @dmfigol Cisco Spark How Questions? Use Cisco Spark to communicate with the speaker after the session 1. Find this session
DEVNET-2163 Machine Learning with Python Dmitry Figol, SE WW Enterprise Sales @dmfigol Cisco Spark How Questions? Use Cisco Spark to communicate with the speaker after the session 1. Find this session
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Introduction to Machine Learning. Xiaojin Zhu
 Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
Introduction to Machine Learning Xiaojin Zhu jerryzhu@cs.wisc.edu Read Chapter 1 of this book: Xiaojin Zhu and Andrew B. Goldberg. Introduction to Semi- Supervised Learning. http://www.morganclaypool.com/doi/abs/10.2200/s00196ed1v01y200906aim006
ECG782: Multidimensional Digital Signal Processing
 ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
ECG782: Multidimensional Digital Signal Processing Object Recognition http://www.ee.unlv.edu/~b1morris/ecg782/ 2 Outline Knowledge Representation Statistical Pattern Recognition Neural Networks Boosting
Classification and Regression
 Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Classification and Regression Announcements Study guide for exam is on the LMS Sample exam will be posted by Monday Reminder that phase 3 oral presentations are being held next week during workshops Plan
Introduction to Data Mining and Data Analytics
 1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
1/28/2016 MIST.7060 Data Analytics 1 Introduction to Data Mining and Data Analytics What Are Data Mining and Data Analytics? Data mining is the process of discovering hidden patterns in data, where Patterns
Build a system health check for Db2 using IBM Machine Learning for z/os
 Build a system health check for Db2 using IBM Machine Learning for z/os Jonathan Sloan Senior Analytics Architect, IBM Analytics Agenda A brief machine learning overview The Db2 ITOA model solutions template
Build a system health check for Db2 using IBM Machine Learning for z/os Jonathan Sloan Senior Analytics Architect, IBM Analytics Agenda A brief machine learning overview The Db2 ITOA model solutions template
CPSC 340: Machine Learning and Data Mining. Multi-Class Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Multi-Class Classification Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation
CPSC 340: Machine Learning and Data Mining Multi-Class Classification Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]
![CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]](/thumbs/89/100746783.jpg "CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, :59pm, PDF to Canvas [100 points]") CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
CIS 520, Machine Learning, Fall 2015: Assignment 7 Due: Mon, Nov 16, 2015. 11:59pm, PDF to Canvas [100 points] Instructions. Please write up your responses to the following problems clearly and concisely.
Nearest Neighbors Classifiers
 Nearest Neighbors Classifiers Raúl Rojas Freie Universität Berlin July 2014 In pattern recognition we want to analyze data sets of many different types (pictures, vectors of health symptoms, audio streams,
Nearest Neighbors Classifiers Raúl Rojas Freie Universität Berlin July 2014 In pattern recognition we want to analyze data sets of many different types (pictures, vectors of health symptoms, audio streams,
THE CYBERSECURITY LITERACY CONFIDENCE GAP
 CONFIDENCE: SECURED WHITE PAPER THE CYBERSECURITY LITERACY CONFIDENCE GAP ADVANCED THREAT PROTECTION, SECURITY AND COMPLIANCE Despite the fact that most organizations are more aware of cybersecurity risks
CONFIDENCE: SECURED WHITE PAPER THE CYBERSECURITY LITERACY CONFIDENCE GAP ADVANCED THREAT PROTECTION, SECURITY AND COMPLIANCE Despite the fact that most organizations are more aware of cybersecurity risks
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS
 DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes and a class attribute
DATA MINING INTRODUCTION TO CLASSIFICATION USING LINEAR CLASSIFIERS 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes and a class attribute
R (2) Data analysis case study using R for readily available data set using any one machine learning algorithm.
 Data analysis case study using R for readily available data set using any one machine learning algorithm.") Assignment No. 4 Title: SD Module- Data Science with R Program R (2) C (4) V (2) T (2) Total (10) Dated Sign Data analysis case study using R for readily available data set using any one machine learning
Assignment No. 4 Title: SD Module- Data Science with R Program R (2) C (4) V (2) T (2) Total (10) Dated Sign Data analysis case study using R for readily available data set using any one machine learning
Security analytics: From data to action Visual and analytical approaches to detecting modern adversaries
 Security analytics: From data to action Visual and analytical approaches to detecting modern adversaries Chris Calvert, CISSP, CISM Director of Solutions Innovation Copyright 2013 Hewlett-Packard Development
Security analytics: From data to action Visual and analytical approaches to detecting modern adversaries Chris Calvert, CISSP, CISM Director of Solutions Innovation Copyright 2013 Hewlett-Packard Development
Machine Learning Department School of Computer Science Carnegie Mellon University. K- Means + GMMs
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University K- Means + GMMs Clustering Readings: Murphy 25.5 Bishop 12.1, 12.3 HTF 14.3.0 Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University K- Means + GMMs Clustering Readings: Murphy 25.5 Bishop 12.1, 12.3 HTF 14.3.0 Mitchell
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Machine Learning. Classification
 10-701 Machine Learning Classification Inputs Inputs Inputs Where we are Density Estimator Probability Classifier Predict category Today Regressor Predict real no. Later Classification Assume we want to
10-701 Machine Learning Classification Inputs Inputs Inputs Where we are Density Estimator Probability Classifier Predict category Today Regressor Predict real no. Later Classification Assume we want to
Supervised Learning: The Setup. Spring 2018
 Supervised Learning: The Setup Spring 2018 1 Homework 0 will be released today through Canvas Due: Jan. 19 (next Friday) midnight 2 Last lecture We saw What is learning? Learning as generalization The
Supervised Learning: The Setup Spring 2018 1 Homework 0 will be released today through Canvas Due: Jan. 19 (next Friday) midnight 2 Last lecture We saw What is learning? Learning as generalization The
CPSC 340: Machine Learning and Data Mining. More Regularization Fall 2017
 CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
CPSC 340: Machine Learning and Data Mining More Regularization Fall 2017 Assignment 3: Admin Out soon, due Friday of next week. Midterm: You can view your exam during instructor office hours or after class
MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018
![MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018](/thumbs/77/76295965.jpg "MIT 801. Machine Learning I. [Presented by Anna Bosman] 16 February 2018") MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
MIT 801 [Presented by Anna Bosman] 16 February 2018 Machine Learning What is machine learning? Artificial Intelligence? Yes as we know it. What is intelligence? The ability to acquire and apply knowledge
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
Boosting Simple Model Selection Cross Validation Regularization
 Boosting: (Linked from class website) Schapire 01 Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 8 th,
Boosting: (Linked from class website) Schapire 01 Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 8 th,
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
DATA MINING AND WAREHOUSING
 DATA MINING AND WAREHOUSING Qno Question Answer 1 Define data warehouse? Data warehouse is a subject oriented, integrated, time-variant, and nonvolatile collection of data that supports management's decision-making
DATA MINING AND WAREHOUSING Qno Question Answer 1 Define data warehouse? Data warehouse is a subject oriented, integrated, time-variant, and nonvolatile collection of data that supports management's decision-making
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
PV211: Introduction to Information Retrieval
 PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 15-1: Support Vector Machines Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
PV211: Introduction to Information Retrieval http://www.fi.muni.cz/~sojka/pv211 IIR 15-1: Support Vector Machines Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University,
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]
![Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]](/thumbs/85/91370094.jpg "Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]") Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 3 rd, 2007 1 Boosting [Schapire, 1989] Idea: given a weak
Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 3 rd, 2007 1 Boosting [Schapire, 1989] Idea: given a weak
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Project 4 Machine Learning: Optical Character Recognition
 Project 4 Machine Learning: Optical Character Recognition Due: Noon Friday, 8/13/10 The goal of this project is to become familiar with a simple Machine Learning system. Statistics and machine learning
Project 4 Machine Learning: Optical Character Recognition Due: Noon Friday, 8/13/10 The goal of this project is to become familiar with a simple Machine Learning system. Statistics and machine learning
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Machine Learning and Pervasive Computing
 Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Stephan Sigg Georg-August-University Goettingen, Computer Networks 17.12.2014 Overview and Structure 22.10.2014 Organisation 22.10.3014 Introduction (Def.: Machine learning, Supervised/Unsupervised, Examples)
Beyond Firewalls: The Future Of Network Security
 Beyond Firewalls: The Future Of Network Security XChange University: IT Security Jennifer Blatnik 20 August 2016 Security Trends Today Network security landscape has expanded CISOs Treading Water Pouring
Beyond Firewalls: The Future Of Network Security XChange University: IT Security Jennifer Blatnik 20 August 2016 Security Trends Today Network security landscape has expanded CISOs Treading Water Pouring
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Rapid growth of massive datasets
 Overview Rapid growth of massive datasets E.g., Online activity, Science, Sensor networks Data Distributed Clusters are Pervasive Data Distributed Computing Mature Methods for Common Problems e.g., classification,
Overview Rapid growth of massive datasets E.g., Online activity, Science, Sensor networks Data Distributed Clusters are Pervasive Data Distributed Computing Mature Methods for Common Problems e.g., classification,
Excel Basics Rice Digital Media Commons Guide Written for Microsoft Excel 2010 Windows Edition by Eric Miller
 Excel Basics Rice Digital Media Commons Guide Written for Microsoft Excel 2010 Windows Edition by Eric Miller Table of Contents Introduction!... 1 Part 1: Entering Data!... 2 1.a: Typing!... 2 1.b: Editing
Excel Basics Rice Digital Media Commons Guide Written for Microsoft Excel 2010 Windows Edition by Eric Miller Table of Contents Introduction!... 1 Part 1: Entering Data!... 2 1.a: Typing!... 2 1.b: Editing
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /10/2017
 3/0/207 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/0/207 Perceptron as a neural
3/0/207 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/0/207 Perceptron as a neural
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
turning data into dollars
 turning data into dollars Tom s Ten Data Tips November 2008 Neural Networks Neural Networks (NNs) are sometimes considered the epitome of data mining algorithms. Loosely modeled after the human brain (hence
turning data into dollars Tom s Ten Data Tips November 2008 Neural Networks Neural Networks (NNs) are sometimes considered the epitome of data mining algorithms. Loosely modeled after the human brain (hence
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
Simple Model Selection Cross Validation Regularization Neural Networks
 Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Data Mining Concepts. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
Nowcasting. D B M G Data Base and Data Mining Group of Politecnico di Torino. Big Data: Hype or Hallelujah? Big data hype?
 Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Big data hype? Big Data: Hype or Hallelujah? Data Base and Data Mining Group of 2 Google Flu trends On the Internet February 2010 detected flu outbreak two weeks ahead of CDC data Nowcasting http://www.internetlivestats.com/
Mathematics of Data. INFO-4604, Applied Machine Learning University of Colorado Boulder. September 5, 2017 Prof. Michael Paul
 Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
Mathematics of Data INFO-4604, Applied Machine Learning University of Colorado Boulder September 5, 2017 Prof. Michael Paul Goals In the intro lecture, every visualization was in 2D What happens when we
CS 584 Data Mining. Classification 1
 CS 584 Data Mining Classification 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for
CS 584 Data Mining Classification 1 Classification: Definition Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2017
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2017 Assignment 3: 2 late days to hand in tonight. Admin Assignment 4: Due Friday of next week. Last Time: MAP Estimation MAP
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2017 Assignment 3: 2 late days to hand in tonight. Admin Assignment 4: Due Friday of next week. Last Time: MAP Estimation MAP
Overview. Data Mining for Business Intelligence. Shmueli, Patel & Bruce
 Overview Data Mining for Business Intelligence Shmueli, Patel & Bruce Galit Shmueli and Peter Bruce 2010 Core Ideas in Data Mining Classification Prediction Association Rules Data Reduction Data Exploration
Overview Data Mining for Business Intelligence Shmueli, Patel & Bruce Galit Shmueli and Peter Bruce 2010 Core Ideas in Data Mining Classification Prediction Association Rules Data Reduction Data Exploration
Feature Descriptors. CS 510 Lecture #21 April 29 th, 2013
 Feature Descriptors CS 510 Lecture #21 April 29 th, 2013 Programming Assignment #4 Due two weeks from today Any questions? How is it going? Where are we? We have two umbrella schemes for object recognition
Feature Descriptors CS 510 Lecture #21 April 29 th, 2013 Programming Assignment #4 Due two weeks from today Any questions? How is it going? Where are we? We have two umbrella schemes for object recognition
Announcements. CS 188: Artificial Intelligence Spring Generative vs. Discriminative. Classification: Feature Vectors. Project 4: due Friday.
 CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
CS 188: Artificial Intelligence Spring 2011 Lecture 21: Perceptrons 4/13/2010 Announcements Project 4: due Friday. Final Contest: up and running! Project 5 out! Pieter Abbeel UC Berkeley Many slides adapted
Exploratory Analysis: Clustering
 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
The Data Science Process. Polong Lin Big Data University Leader & Data Scientist IBM
 The Data Science Process Polong Lin Big Data University Leader & Data Scientist IBM polong@ca.ibm.com Every day, we create 2.5 quintillion bytes of data so much that 90% of the data in the world today
The Data Science Process Polong Lin Big Data University Leader & Data Scientist IBM polong@ca.ibm.com Every day, we create 2.5 quintillion bytes of data so much that 90% of the data in the world today
Security Automation Best Practices
 WHITEPAPER Security Automation Best Practices A guide to making your security team successful with automation TABLE OF CONTENTS Introduction 3 What Is Security Automation? 3 Security Automation: A Tough
WHITEPAPER Security Automation Best Practices A guide to making your security team successful with automation TABLE OF CONTENTS Introduction 3 What Is Security Automation? 3 Security Automation: A Tough
Machine Learning Lecture 3
 Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Machine Learning Lecture 3 Probability Density Estimation II 19.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Exam dates We re in the process
Tips and Guidance for Analyzing Data. Executive Summary
 Tips and Guidance for Analyzing Data Executive Summary This document has information and suggestions about three things: 1) how to quickly do a preliminary analysis of time-series data; 2) key things to
Tips and Guidance for Analyzing Data Executive Summary This document has information and suggestions about three things: 1) how to quickly do a preliminary analysis of time-series data; 2) key things to
Advanced Threat Intelligence to Detect Advanced Malware Jim Deerman
 Advanced Threat Intelligence to Detect Advanced Malware Jim Deerman jdeerman@isc8.com Safe Harbor Statement All statements included or incorporated by reference in these slides, other than statements or
Advanced Threat Intelligence to Detect Advanced Malware Jim Deerman jdeerman@isc8.com Safe Harbor Statement All statements included or incorporated by reference in these slides, other than statements or
Football result prediction using simple classification algorithms, a comparison between k-nearest Neighbor and Linear Regression
 EXAMENSARBETE INOM TEKNIK, GRUNDNIVÅ, 15 HP STOCKHOLM, SVERIGE 2016 Football result prediction using simple classification algorithms, a comparison between k-nearest Neighbor and Linear Regression PIERRE
EXAMENSARBETE INOM TEKNIK, GRUNDNIVÅ, 15 HP STOCKHOLM, SVERIGE 2016 Football result prediction using simple classification algorithms, a comparison between k-nearest Neighbor and Linear Regression PIERRE
VECTOR SPACE CLASSIFICATION
 VECTOR SPACE CLASSIFICATION Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. Chapter 14 Wei Wei wwei@idi.ntnu.no Lecture
VECTOR SPACE CLASSIFICATION Christopher D. Manning, Prabhakar Raghavan and Hinrich Schütze, Introduction to Information Retrieval, Cambridge University Press. Chapter 14 Wei Wei wwei@idi.ntnu.no Lecture
k-nearest Neighbors + Model Selection
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University k-nearest Neighbors + Model Selection Matt Gormley Lecture 5 Jan. 30, 2019 1 Reminders
Data Mining. Lecture 03: Nearest Neighbor Learning
 Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F. Provost
Data Mining Lecture 03: Nearest Neighbor Learning Theses slides are based on the slides by Tan, Steinbach and Kumar (textbook authors) Prof. R. Mooney (UT Austin) Prof E. Keogh (UCR), Prof. F. Provost
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
(Refer Slide Time: 0:51)
") Introduction to Remote Sensing Dr. Arun K Saraf Department of Earth Sciences Indian Institute of Technology Roorkee Lecture 16 Image Classification Techniques Hello everyone welcome to 16th lecture in
Introduction to Remote Sensing Dr. Arun K Saraf Department of Earth Sciences Indian Institute of Technology Roorkee Lecture 16 Image Classification Techniques Hello everyone welcome to 16th lecture in
Problems 1 and 5 were graded by Amin Sorkhei, Problems 2 and 3 by Johannes Verwijnen and Problem 4 by Jyrki Kivinen. Entropy(D) = Gini(D) = 1
 = Gini(D) = 1") Problems and were graded by Amin Sorkhei, Problems and 3 by Johannes Verwijnen and Problem by Jyrki Kivinen.. [ points] (a) Gini index and Entropy are impurity measures which can be used in order to measure
Problems and were graded by Amin Sorkhei, Problems and 3 by Johannes Verwijnen and Problem by Jyrki Kivinen.. [ points] (a) Gini index and Entropy are impurity measures which can be used in order to measure
Expectation Maximization (EM) and Gaussian Mixture Models
 and Gaussian Mixture Models") Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Bayes Risk. Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Discriminative vs Generative Models. Loss functions in classifiers
 Discriminative vs Generative Models. Loss functions in classifiers") Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Example: A Classification Problem Categorize
Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Example: A Classification Problem Categorize
Data Mining Classification - Part 1 -
 Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
Data Mining Classification - Part 1 - Universität Mannheim Bizer: Data Mining I FSS2019 (Version: 20.2.2018) Slide 1 Outline 1. What is Classification? 2. K-Nearest-Neighbors 3. Decision Trees 4. Model
CP365 Artificial Intelligence
 CP365 Artificial Intelligence Example Problem Problem: Does a given image contain cats? Input vector: RGB/BW pixels of the image. Output: Yes or No. Example Problem Problem: What category is a news story?
CP365 Artificial Intelligence Example Problem Problem: Does a given image contain cats? Input vector: RGB/BW pixels of the image. Output: Yes or No. Example Problem Problem: What category is a news story?
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS664 Lecture #21: SIFT, object recognition, dynamic programming
 CS664 Lecture #21: SIFT, object recognition, dynamic programming Some material taken from: Sebastian Thrun, Stanford http://cs223b.stanford.edu/ Yuri Boykov, Western Ontario David Lowe, UBC http://www.cs.ubc.ca/~lowe/keypoints/
CS664 Lecture #21: SIFT, object recognition, dynamic programming Some material taken from: Sebastian Thrun, Stanford http://cs223b.stanford.edu/ Yuri Boykov, Western Ontario David Lowe, UBC http://www.cs.ubc.ca/~lowe/keypoints/
Data Mining. Part 2. Data Understanding and Preparation. 2.4 Data Transformation. Spring Instructor: Dr. Masoud Yaghini. Data Transformation
 Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
Data Mining Part 2. Data Understanding and Preparation 2.4 Spring 2010 Instructor: Dr. Masoud Yaghini Outline Introduction Normalization Attribute Construction Aggregation Attribute Subset Selection Discretization
A GUIDE TO CYBERSECURITY METRICS YOUR VENDORS (AND YOU) SHOULD BE WATCHING
 SHOULD BE WATCHING") A GUIDE TO 12 CYBERSECURITY METRICS YOUR VENDORS (AND YOU) SHOULD BE WATCHING There is a major difference between perceived and actual security. Perceived security is what you believe to be in place at
A GUIDE TO 12 CYBERSECURITY METRICS YOUR VENDORS (AND YOU) SHOULD BE WATCHING There is a major difference between perceived and actual security. Perceived security is what you believe to be in place at
Ensemble Methods, Decision Trees
 CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
CS 1675: Intro to Machine Learning Ensemble Methods, Decision Trees Prof. Adriana Kovashka University of Pittsburgh November 13, 2018 Plan for This Lecture Ensemble methods: introduction Boosting Algorithm
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Computational Statistics and Mathematics for Cyber Security
 and Mathematics for Cyber Security David J. Marchette Sept, 0 Acknowledgment: This work funded in part by the NSWC In-House Laboratory Independent Research (ILIR) program. NSWCDD-PN--00 Topics NSWCDD-PN--00
and Mathematics for Cyber Security David J. Marchette Sept, 0 Acknowledgment: This work funded in part by the NSWC In-House Laboratory Independent Research (ILIR) program. NSWCDD-PN--00 Topics NSWCDD-PN--00
Data analysis case study using R for readily available data set using any one machine learning Algorithm
 Assignment-4 Data analysis case study using R for readily available data set using any one machine learning Algorithm Broadly, there are 3 types of Machine Learning Algorithms.. 1. Supervised Learning
Assignment-4 Data analysis case study using R for readily available data set using any one machine learning Algorithm Broadly, there are 3 types of Machine Learning Algorithms.. 1. Supervised Learning
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Classifiers for Recognition Reading: Chapter 22 (skip 22.3)
") Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Slide credits for this chapter: Frank
Classifiers for Recognition Reading: Chapter 22 (skip 22.3) Examine each window of an image Classify object class within each window based on a training set images Slide credits for this chapter: Frank
AMP-Based Flow Collection. Greg Virgin - RedJack
 AMP-Based Flow Collection Greg Virgin - RedJack AMP- Based Flow Collection AMP - Analytic Metadata Producer : Patented US Government flow / metadata producer AMP generates data including Flows Host metadata
AMP-Based Flow Collection Greg Virgin - RedJack AMP- Based Flow Collection AMP - Analytic Metadata Producer : Patented US Government flow / metadata producer AMP generates data including Flows Host metadata
Data Mining Algorithms: Basic Methods
 Algorithms: The basic methods Inferring rudimentary rules Data Mining Algorithms: Basic Methods Chapter 4 of Data Mining Statistical modeling Constructing decision trees Constructing rules Association
Algorithms: The basic methods Inferring rudimentary rules Data Mining Algorithms: Basic Methods Chapter 4 of Data Mining Statistical modeling Constructing decision trees Constructing rules Association
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2