Lecture 05 Additive Models
|
|
|
- Gervase Francis
- 6 years ago
- Views:
Transcription


1 Lecture 05 Additive Models 01 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/52
2 Problem set notes: Problem set 1 is due on Friday at 1pm! brute force okay for implementation question can use other libraries in the prediction and data analysis questions consider FNN (R) or or sklearn.neighbors (Python) Office hours: Taylor Arnold Mondays, 13:00-14:15, HH 24, Office 206 (by appointment) Elena Khusainova Tuesdays, 13:00-15:00, HH 24, Basement Yu Lu Tuesdays, 19:00-20:30, HH 24, Basement Jason Klusowski Thursdays, 19:00-20:30, HH 24 If you have any questions on the problem set, please ask or send them prior to Thursday night 2/52
3 Factors Canada USA USA Mexico Canada Canada USA. Mexico Canada Mexico USA /52
4 Higherdimensionalproblems So far, we have only considered non-parametric estimators where the predictor variable x i is one dimensional. How can we extend this to higher dimensional models? 4/52
5 Higherdimensionalproblems So far, we have only considered non-parametric estimators where the predictor variable x i is one dimensional. How can we extend this to higher dimensional models? Well, the knn and kernel smoother estimators only depend on the distance matrix between points. Our efficient computational methods breakdown in higher dimensions, but the theoretical idea of these need no modification. 4/52
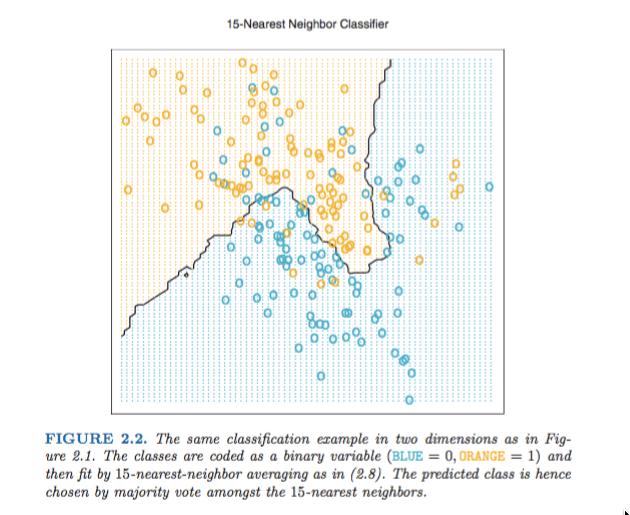
6 5/52

7 6/52
8 Higherdimensionalproblems, cont. What happens if we try to do basis expansion for linear regression in higher dimensions? 7/52
9 Higherdimensionalproblems, cont. What happens if we try to do basis expansion for linear regression in higher dimensions? For clarity, let s assume we just have two dimensions labeled x and z. We need a basis that looks like: y i = m j=0 k=0 m β j+m k x j i zk i + ϵ i So the number of coordinates grows to m 2 coefficients in order to fit arbitrary m dimensional polynomials. 7/52
10 Higherdimensionalproblems, cont. What happens if we try to do basis expansion for linear regression in higher dimensions? For clarity, let s assume we just have two dimensions labeled x and z. We need a basis that looks like: y i = m j=0 k=0 m β j+m k x j i zk i + ϵ i So the number of coordinates grows to m 2 coefficients in order to fit arbitrary m dimensional polynomials. For p dimensions, we ll need a total m p coefficients; a quickly unfeasible task. Regularization and keeping m small can help, but still makes this task hard for anything that would approximate a reasonably complex non-linear surface. 7/52
11 Higherdimensionalproblems, cont. Lowess, local polynomial regression, can be fit in the same manor as the linear model in higher dimensions. We can fix the order of the polynomial to be m = 1 while still capturing global non-linearity; therefore we can still use this technique in higher dimensions. 8/52
12 Additivemodels One way to deal with the problem of basis expansion in higher dimensions is to assume that there are no interaction between the variables. This leads to a model such as: These are known as additive models. y i = g 1 (x i,1 ) + g 2 (x i,2 ) + + g p (x i,p ) + ϵ i 9/52
13 Additivemodels, cont. Notice that the additive model cannot be defined uniquely as we can add a constant to one of the g j ( ) functions and subtract the same constant from another function g k ( ). In order to remedy this, one usually instead writes an explicit intercept term: y i = α + g 1 (x i,1 ) + g 2 (x i,2 ) + + g p (x i,p ) + ϵ i And constrains: g k (x i,k ) = 0 k For all values of k. 10/52
14 ComputingAdditivemodels The primary algorithm used for computing additive models is called the backfitting algorithm. It was originally used for additive models by Leo Breiman and Jerome Friedman: Breiman, Leo, and Jerome H. Friedman. Estimating optimal transformations for multiple regression and correlation. Journal of the American statistical Association (1985): /52
15 ComputingAdditivemodels, cont. The algorithm can be compactly described as: Data: pairs of data {(X i, y i )} n i=1 Result: Estimates α and ĝ j, j = {1, 2,..., p} i y i, ĝ j = 0 ; initialize α = 1 n while not converged do for j=1 to p do end end r ij y i â k j ĝk(x ik ) ĝ j S ( {(x ij, r ij )} n ) i=1 ĝ j ĝ j 1 n i ĝj(x ij ) For some smoother function S and stopping criterion. 12/52
16 ComputingAdditivemodels, cont. For the smoothing function S, we can use any of the algorithms we have already studied. Local polynomial regression is a popular choice. 13/52
17 ComputingAdditivemodels, cont. For the smoothing function S, we can use any of the algorithms we have already studied. Local polynomial regression is a popular choice. Notice that we can also blend the additive model with higher dimensional smoothers, particularly if we know that a small set of variables may have interactions with each other even though most variables do not: y i = α + g 1 (x i,1, x i,2 ) + g 3 (x i,3 ) + + g p (x i,p ) + ϵ i. 13/52
18 ComputingAdditivemodels, cont. There are two popular R packages for fitting additive models. Either mgcv: Or gam: /52
19 ComputingAdditivemodels, cont. There are two popular R packages for fitting additive models. Either mgcv: Or gam: There are not as many options for python. The best I know of is in statsmodels.sandbox.gam as AdditiveModel. 14/52
20 What swrongwithlinearregression? At this point you may wonder why linear regression seems to have trouble in higher dimensions compared to the local methods. In truth, all of these techniques have trouble with high dimensional spaces; it is just that the others hide this fact in their definitions. 15/52
21 What swrongwithlinearregression? At this point you may wonder why linear regression seems to have trouble in higher dimensions compared to the local methods. In truth, all of these techniques have trouble with high dimensional spaces; it is just that the others hide this fact in their definitions. The problem is the curse of dimensionality: When we have high dimensional spaces, datasets look sparse even when the number of samples is very large. 15/52
22 What swrongwithlinearregression? At this point you may wonder why linear regression seems to have trouble in higher dimensions compared to the local methods. In truth, all of these techniques have trouble with high dimensional spaces; it is just that the others hide this fact in their definitions. The problem is the curse of dimensionality: When we have high dimensional spaces, datasets look sparse even when the number of samples is very large. Dealing with this is going to be the motivating problem in machine learning for the remainder of the course. 15/52
23 Data analysis 16/52
24 Description Today we are going to look at housing price data, taking from the American Community Survey and prepared by Cosma Shalizi: The data list aggregate statistics for census tracts. 17/52
25 Let s first read in the data and look at all of the available variables. > x <- read.csv("data/capa.csv", as.is=true) > names(x) <- tolower(names(x)) > str(x) 'data.frame': obs. of 34 variables: $ x : int $ geo.id2 : num 6e+09 6e+09 6e+09 6e+09 6e $ statefp : int $ countyfp : int $ tractce : int $ population : int $ latitude : num $ longitude : num $ geo.display.label : chr "Census Tract 4001, Alameda County, California"... $ median_house_value : int NA $ total_units : int $ vacant_units : int $ median_rooms : num /52
26 $ mean_household_size_owners : num $ mean_household_size_renters: num $ built_2005_or_later : num $ built_2000_to_2004 : num $ built_1990s : num $ built_1980s : num $ built_1970s : num $ built_1960s : num $ built_1950s : num $ built_1940s : num $ built_1939_or_earlier : num $ bedrooms_0 : num $ bedrooms_1 : num $ bedrooms_2 : num $ bedrooms_3 : num $ bedrooms_4 : num $ bedrooms_5_or_more : num $ owners : num $ renters : num $ median_household_income : int $ mean_household_income : int /52
27 There are a few bad rows of data, but we can safely clean them out: > badrows <- (apply(is.na(x),1,sum)!= 0) > table(badrows) badrows FALSE TRUE > tapply(x$median_household_income, badrows, median, na.rm=true) FALSE TRUE > tapply(x$median_house_value, badrows, median, na.rm=true) FALSE TRUE > tapply(x$vacant_units, badrows, median, na.rm=true) FALSE TRUE > x <- na.omit(x) 20/52
28 As you may have guessed from the file name, the housing prices cover two distinct regions: > plot(x$longitude, x$latitude, pch=19, cex=0.5) 21/52
29 x$latitude x$longitude 22/52
30 Let s split these two states up into two separate datasets. I ll use the California set to start, but hopefully we will have time to go back to the Pennsylvania set. > ca <- x[x$statefp==6,] > pa <- x[x$statefp==42,] 23/52
31 As a warm-up to additive models, let s fit and tune simple knn model for whether the majority of residents in a census tract. > testflag <- (runif(nrow(ca)) > 0.8) > trainflag <-!testflag > cl <- as.numeric(ca$owners < 50) For the training set, we will use cross-validation to select the optimal k: > X <- cbind(ca$latitude,ca$longitude)[trainflag,] > y <- cl[trainflag] > foldid <- sample(1:5, nrow(x),replace=true) 24/52
32 Here is the main validation code, using misclassification error: > kvals <- 1:25 > res <- matrix(ncol=5, nrow=25) > for (i in 1:5) { + trainset <- which(foldid!= i) + validset <- which(foldid == i) + for (k in 1:25) { + pred <- knn(x[trainset,],x[validset,],y[trainset], + k=kvals[k]) + yhat <- (as.numeric(pred) - 1) + res[k,i] <- mean((y[validset]!= yhat)) + print(k) + } + } 25/52
33 Taking the results for each fold, I can calculate the cross validated mis-classification rate as well as the standard errors of these rates: > head(res) [,1] [,2] [,3] [,4] [,5] [1,] [2,] [3,] [4,] [5,] [6,] > cverror <- apply(res,1,mean) > cvse <- apply(res,1,sd) / sqrt(5) 26/52
34 cverror :25 27/52
35 If we set the tuning parameter to 4, we can then check how well this performs on the test set. > Xtest <- cbind(ca$latitude,ca$longitude)[testflag,] > ytest <- cl[testflag] > yhat <- (as.numeric(knn(x,xtest,y,k=4)) - 1) > mean((yhat!= ytest)) [1] 0.22 > round(table(yhat, ytest) / length(yhat) * 100) ytest yhat The table at the bottom is called a confusion matrix, and gives more granularity than the raw misclassification rate. 28/52
36 If we set the tuning parameter to 4, we can then check how well this performs on the test set. > Xtest <- cbind(ca$latitude,ca$longitude)[testflag,] > ytest <- cl[testflag] > yhat <- (as.numeric(knn(x,xtest,y,k=4)) - 1) > mean((yhat!= ytest)) [1] 0.22 > round(table(yhat, ytest) / length(yhat) * 100) ytest yhat The table at the bottom is called a confusion matrix, and gives more granularity than the raw misclassification rate. 29/52
37 Now, I want to understand the variables that effect the median house value in a census tract. Here is a linear model that would be a good starting point (after some exploratory plots, preferably): > ca.lm <- lm(log(median_house_value) ~ median_household_income + + mean_household_income + population + total_units vacant_units + owners + median_rooms mean_household_size_owners + mean_household_size_renters + + latitude + longitude, data = ca, subset=trainflag) 30/52
38 > summary(ca.lm) Estimate Std. Error t value Pr(> t ) (Intercept) -5.78e e < 2e-16 *** median_household_income 1.20e e * mean_household_income 1.08e e < 2e-16 *** population -4.15e e e-13 *** total_units 8.37e e e-06 *** vacant_units -1.06e e owners -3.83e e < 2e-16 *** median_rooms -1.49e e mean_household_size_owners 5.40e e e-11 *** mean_household_size_renters -7.46e e < 2e-16 *** latitude -2.15e e < 2e-16 *** longitude -2.15e e < 2e-16 *** --- Signif. codes: 0 *** ** 0.01 * Residual standard error: 0.32 on 5995 degrees of freedom Multiple R-squared: 0.636, Adjusted R-squared: F-statistic: 953 on 11 and 5995 DF, p-value: <2e-16 31/52
39 To fit an additive model in R, we can use the mgcv package. It uses cross-validation by default, making it very easy to use in place of linear regression. > library(mgcv) Loading required package: nlme This is mgcv For overview type 'help("mgcv -package")'. > ca.gam <- gam(log(median_house_value) + ~ s(median_household_income) + s(mean_household_income) + + s(population) + s(total_units) + s(vacant_units) + + s(owners) + s(median_rooms) + s(mean_household_size_owners) + + s(mean_household_size_renters) + s(latitude) + + s(longitude), data=ca, subset=trainflag) 32/52
40 To see the coefficients in the additive model, we can plot the output object. These options work well when working locally: > plot(ca.gam2,scale=0,se=2,shade=true,resid=false,pages=1) For class, I add the option select=i to only show the contribution of the i th variable. 33/52
41 s(median_household_income,4.9) median_household_income 34/52
42 s(mean_household_income,6.16) mean_household_income 35/52
43 s(population,1.88) population 36/52
44 s(total_units,4.21) total_units 37/52
45 s(vacant_units,5.95) vacant_units 38/52
46 s(owners,3.87) owners 39/52
47 s(median_rooms,7.73) median_rooms 40/52
48 s(mean_household_size_owners,7.66) mean_household_size_owners 41/52
49 s(mean_household_size_renters,2.03) mean_household_size_renters 42/52
50 s(latitude,8.86) latitude 43/52
51 s(longitude,8.88) longitude 44/52
52 It actually makes more sense to allow and interaction between latitude and longitude. This is also easy to include in mgcv: > ca.gam2 <- gam(log(median_house_value) + ~ s(median_household_income) + s(mean_household_income) + + s(population) + s(total_units) + s(vacant_units) + + s(owners) + s(median_rooms) + s(mean_household_size_owners) + + s(mean_household_size_renters) + + s(longitude,latitude), data=ca, subset=trainflag) 45/52



53 /52
54 How well does these methods do in terms of prediction? We can predict using the predict function just as with linear models: > y <- log(ca$median_house_value) > ca.lm.pred <- predict(ca.lm, ca) > ca.gam.pred <- predict(ca.gam, ca) > ca.gam2.pred <- predict(ca.gam2, ca) And then check the mean squared error on both the training set and testing set: > tapply((ca.lm.pred - y)^2, trainflag, mean) FALSE TRUE > tapply((ca.gam.pred - y)^2, trainflag, mean) FALSE TRUE > tapply((ca.gam2.pred - y)^2, trainflag, mean) FALSE TRUE /52
55 In machine learning, you ll often hear the caveat that everything depend on future values following the same underlying model. I think we say that a lot, but forget to really think about it. To illustrate, let s re-fit the model on the California data without the latitude and longitude components. We can then see how well the model trained on California data generalizes to Pennsylvania data. 48/52
56 Here are the two linear models fit on the two different datasets. > ca.lm2 <- lm(log(median_house_value) ~ median_household_income + + mean_household_income + population + total_units vacant_units + owners + median_rooms mean_household_size_owners + mean_household_size_renters, + data = ca, subset=trainflag) > > pa.lm3 <- lm(log(median_house_value) ~ median_household_income + + mean_household_income + population + total_units vacant_units + owners + median_rooms mean_household_size_owners + mean_household_size_renters, + data = pa, subset=trainflag) 49/52
57 And here are the two additive models fit on the data: > ca.gam3 <- gam(log(median_house_value) + ~ s(median_household_income) + s(mean_household_income) + + s(population) + s(total_units) + s(vacant_units) + + s(owners) + s(median_rooms) + s(mean_household_size_owners) + + s(mean_household_size_renters), data=ca, subset=trainflagpa) > > pa.gam4 <- gam(log(median_house_value) + ~ s(median_household_income) + s(mean_household_income) + + s(population) + s(total_units) + s(vacant_units) + + s(owners) + s(median_rooms) + s(mean_household_size_owners) + + s(mean_household_size_renters), data=pa, subset=trainflagpa) 50/52
58 Fitting these models all on the PA data: > y.pa <- log(pa$median_house_value) > pa.lm2.pred <- predict(ca.lm2, pa) > pa.gam3.pred <- predict(ca.gam3, pa) > pa.lm3.pred <- predict(pa.lm3, pa) > pa.gam4.pred <- predict(pa.gam4, pa) We see that the California ones yield very poor MSE scores for PA: > tapply((pa.lm2.pred - y.pa)^2,trainflagpa,mean) FALSE TRUE > tapply((pa.gam3.pred - y.pa)^2,trainflagpa,mean) FALSE TRUE > tapply((pa.lm3.pred - y.pa)^2,trainflagpa,mean) FALSE TRUE > tapply((pa.gam4.pred - y.pa)^2,trainflagpa,mean) FALSE TRUE /52
59 If we account for the overall means being different, we see that the California models perform reasonably well on the Pennsylvania data: > tapply((pa.lm2.pred - y.pa),trainflagpa,var) FALSE TRUE > tapply((pa.gam3.pred - y.pa),trainflagpa,var) FALSE TRUE > tapply((pa.lm3.pred - y.pa),trainflagpa,var) FALSE TRUE > tapply((pa.gam4.pred - y.pa),trainflagpa,var) FALSE TRUE /52
Lecture 06 Decision Trees I
 Lecture 06 Decision Trees I 08 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/33 Problem Set #2 Posted Due February 19th Piazza site https://piazza.com/ 2/33 Last time we starting fitting
Lecture 06 Decision Trees I 08 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/33 Problem Set #2 Posted Due February 19th Piazza site https://piazza.com/ 2/33 Last time we starting fitting
Lecture 03 Linear classification methods II
 Lecture 03 Linear classification methods II 25 January 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/35 Office hours Taylor Arnold Mondays, 13:00-14:15, HH 24, Office 203 (by appointment) Yu Lu
Lecture 03 Linear classification methods II 25 January 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/35 Office hours Taylor Arnold Mondays, 13:00-14:15, HH 24, Office 203 (by appointment) Yu Lu
Lecture 22 The Generalized Lasso
 Lecture 22 The Generalized Lasso 07 December 2015 Taylor B. Arnold Yale Statistics STAT 312/612 Class Notes Midterm II - Due today Problem Set 7 - Available now, please hand in by the 16th Motivation Today
Lecture 22 The Generalized Lasso 07 December 2015 Taylor B. Arnold Yale Statistics STAT 312/612 Class Notes Midterm II - Due today Problem Set 7 - Available now, please hand in by the 16th Motivation Today
Lecture 24: Generalized Additive Models Stat 704: Data Analysis I, Fall 2010
 Lecture 24: Generalized Additive Models Stat 704: Data Analysis I, Fall 2010 Tim Hanson, Ph.D. University of South Carolina T. Hanson (USC) Stat 704: Data Analysis I, Fall 2010 1 / 26 Additive predictors
Lecture 24: Generalized Additive Models Stat 704: Data Analysis I, Fall 2010 Tim Hanson, Ph.D. University of South Carolina T. Hanson (USC) Stat 704: Data Analysis I, Fall 2010 1 / 26 Additive predictors
STENO Introductory R-Workshop: Loading a Data Set Tommi Suvitaival, Steno Diabetes Center June 11, 2015
 STENO Introductory R-Workshop: Loading a Data Set Tommi Suvitaival, tsvv@steno.dk, Steno Diabetes Center June 11, 2015 Contents 1 Introduction 1 2 Recap: Variables 2 3 Data Containers 2 3.1 Vectors................................................
STENO Introductory R-Workshop: Loading a Data Set Tommi Suvitaival, tsvv@steno.dk, Steno Diabetes Center June 11, 2015 Contents 1 Introduction 1 2 Recap: Variables 2 3 Data Containers 2 3.1 Vectors................................................
Generalized Additive Models
 Generalized Additive Models Statistics 135 Autumn 2005 Copyright c 2005 by Mark E. Irwin Generalized Additive Models GAMs are one approach to non-parametric regression in the multiple predictor setting.
Generalized Additive Models Statistics 135 Autumn 2005 Copyright c 2005 by Mark E. Irwin Generalized Additive Models GAMs are one approach to non-parametric regression in the multiple predictor setting.
Lecture 27: Review. Reading: All chapters in ISLR. STATS 202: Data mining and analysis. December 6, 2017
 Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Lecture 27: Review Reading: All chapters in ISLR. STATS 202: Data mining and analysis December 6, 2017 1 / 16 Final exam: Announcements Tuesday, December 12, 8:30-11:30 am, in the following rooms: Last
Stat 8053, Fall 2013: Additive Models
 Stat 853, Fall 213: Additive Models We will only use the package mgcv for fitting additive and later generalized additive models. The best reference is S. N. Wood (26), Generalized Additive Models, An
Stat 853, Fall 213: Additive Models We will only use the package mgcv for fitting additive and later generalized additive models. The best reference is S. N. Wood (26), Generalized Additive Models, An
Non-Linear Regression. Business Analytics Practice Winter Term 2015/16 Stefan Feuerriegel
 Non-Linear Regression Business Analytics Practice Winter Term 2015/16 Stefan Feuerriegel Today s Lecture Objectives 1 Understanding the need for non-parametric regressions 2 Familiarizing with two common
Non-Linear Regression Business Analytics Practice Winter Term 2015/16 Stefan Feuerriegel Today s Lecture Objectives 1 Understanding the need for non-parametric regressions 2 Familiarizing with two common
Stat 4510/7510 Homework 4
 Stat 45/75 1/7. Stat 45/75 Homework 4 Instructions: Please list your name and student number clearly. In order to receive credit for a problem, your solution must show sufficient details so that the grader
Stat 45/75 1/7. Stat 45/75 Homework 4 Instructions: Please list your name and student number clearly. In order to receive credit for a problem, your solution must show sufficient details so that the grader
STAT 705 Introduction to generalized additive models
 STAT 705 Introduction to generalized additive models Timothy Hanson Department of Statistics, University of South Carolina Stat 705: Data Analysis II 1 / 22 Generalized additive models Consider a linear
STAT 705 Introduction to generalized additive models Timothy Hanson Department of Statistics, University of South Carolina Stat 705: Data Analysis II 1 / 22 Generalized additive models Consider a linear
Among those 14 potential explanatory variables,non-dummy variables are:
 Among those 14 potential explanatory variables,non-dummy variables are: Size: 2nd column in the dataset Land: 14th column in the dataset Bed.Rooms: 5th column in the dataset Fireplace: 7th column in the
Among those 14 potential explanatory variables,non-dummy variables are: Size: 2nd column in the dataset Land: 14th column in the dataset Bed.Rooms: 5th column in the dataset Fireplace: 7th column in the
Lecture 7: Linear Regression (continued)
") Lecture 7: Linear Regression (continued) Reading: Chapter 3 STATS 2: Data mining and analysis Jonathan Taylor, 10/8 Slide credits: Sergio Bacallado 1 / 14 Potential issues in linear regression 1. Interactions
Lecture 7: Linear Regression (continued) Reading: Chapter 3 STATS 2: Data mining and analysis Jonathan Taylor, 10/8 Slide credits: Sergio Bacallado 1 / 14 Potential issues in linear regression 1. Interactions
Package nodeharvest. June 12, 2015
 Type Package Package nodeharvest June 12, 2015 Title Node Harvest for Regression and Classification Version 0.7-3 Date 2015-06-10 Author Nicolai Meinshausen Maintainer Nicolai Meinshausen
Type Package Package nodeharvest June 12, 2015 Title Node Harvest for Regression and Classification Version 0.7-3 Date 2015-06-10 Author Nicolai Meinshausen Maintainer Nicolai Meinshausen
STAT Statistical Learning. Predictive Modeling. Statistical Learning. Overview. Predictive Modeling. Classification Methods.
 STAT 48 - STAT 48 - December 5, 27 STAT 48 - STAT 48 - Here are a few questions to consider: What does statistical learning mean to you? Is statistical learning different from statistics as a whole? What
STAT 48 - STAT 48 - December 5, 27 STAT 48 - STAT 48 - Here are a few questions to consider: What does statistical learning mean to you? Is statistical learning different from statistics as a whole? What
Generalized Additive Model
 Generalized Additive Model by Huimin Liu Department of Mathematics and Statistics University of Minnesota Duluth, Duluth, MN 55812 December 2008 Table of Contents Abstract... 2 Chapter 1 Introduction 1.1
Generalized Additive Model by Huimin Liu Department of Mathematics and Statistics University of Minnesota Duluth, Duluth, MN 55812 December 2008 Table of Contents Abstract... 2 Chapter 1 Introduction 1.1
( ) = Y ˆ. Calibration Definition A model is calibrated if its predictions are right on average: ave(response Predicted value) = Predicted value.
 = Y ˆ. Calibration Definition A model is calibrated if its predictions are right on average: ave(response Predicted value) = Predicted value.") Calibration OVERVIEW... 2 INTRODUCTION... 2 CALIBRATION... 3 ANOTHER REASON FOR CALIBRATION... 4 CHECKING THE CALIBRATION OF A REGRESSION... 5 CALIBRATION IN SIMPLE REGRESSION (DISPLAY.JMP)... 5 TESTING
Calibration OVERVIEW... 2 INTRODUCTION... 2 CALIBRATION... 3 ANOTHER REASON FOR CALIBRATION... 4 CHECKING THE CALIBRATION OF A REGRESSION... 5 CALIBRATION IN SIMPLE REGRESSION (DISPLAY.JMP)... 5 TESTING
Generalized additive models I
 I Patrick Breheny October 6 Patrick Breheny BST 764: Applied Statistical Modeling 1/18 Introduction Thus far, we have discussed nonparametric regression involving a single covariate In practice, we often
I Patrick Breheny October 6 Patrick Breheny BST 764: Applied Statistical Modeling 1/18 Introduction Thus far, we have discussed nonparametric regression involving a single covariate In practice, we often
ES-2 Lecture: Fitting models to data
 ES-2 Lecture: Fitting models to data Outline Motivation: why fit models to data? Special case (exact solution): # unknowns in model =# datapoints Typical case (approximate solution): # unknowns in model
ES-2 Lecture: Fitting models to data Outline Motivation: why fit models to data? Special case (exact solution): # unknowns in model =# datapoints Typical case (approximate solution): # unknowns in model
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Orange Juice data. Emanuele Taufer. 4/12/2018 Orange Juice data (1)
") Orange Juice data Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/5%20qmma%20-%20mim/0%20labs/l10-oj-data.html#(1) 1/31 Orange Juice Data The data contain weekly sales of refrigerated
Orange Juice data Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/5%20qmma%20-%20mim/0%20labs/l10-oj-data.html#(1) 1/31 Orange Juice Data The data contain weekly sales of refrigerated
CPSC 340: Machine Learning and Data Mining. Non-Parametric Models Fall 2016
 CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
CPSC 340: Machine Learning and Data Mining Non-Parametric Models Fall 2016 Assignment 0: Admin 1 late day to hand it in tonight, 2 late days for Wednesday. Assignment 1 is out: Due Friday of next week.
Cross-Validation Alan Arnholt 3/22/2016
 Cross-Validation Alan Arnholt 3/22/2016 Note: Working definitions and graphs are taken from Ugarte, Militino, and Arnholt (2016) The Validation Set Approach The basic idea behind the validation set approach
Cross-Validation Alan Arnholt 3/22/2016 Note: Working definitions and graphs are taken from Ugarte, Militino, and Arnholt (2016) The Validation Set Approach The basic idea behind the validation set approach
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
NEURAL NETWORKS. Cement. Blast Furnace Slag. Fly Ash. Water. Superplasticizer. Coarse Aggregate. Fine Aggregate. Age
 NEURAL NETWORKS As an introduction, we ll tackle a prediction task with a continuous variable. We ll reproduce research from the field of cement and concrete manufacturing that seeks to model the compressive
NEURAL NETWORKS As an introduction, we ll tackle a prediction task with a continuous variable. We ll reproduce research from the field of cement and concrete manufacturing that seeks to model the compressive
HW3: Multiple Linear Regression
 STAT 391 - INTRO STAT DATA SCI UW Spring Quarter 2017 Néhémy Lim HW3: Multiple Linear Regression Programming assignment. Directions. Comment all functions to receive full credit. Provide a single Python
STAT 391 - INTRO STAT DATA SCI UW Spring Quarter 2017 Néhémy Lim HW3: Multiple Linear Regression Programming assignment. Directions. Comment all functions to receive full credit. Provide a single Python
Statistics & Analysis. Fitting Generalized Additive Models with the GAM Procedure in SAS 9.2
 Fitting Generalized Additive Models with the GAM Procedure in SAS 9.2 Weijie Cai, SAS Institute Inc., Cary NC July 1, 2008 ABSTRACT Generalized additive models are useful in finding predictor-response
Fitting Generalized Additive Models with the GAM Procedure in SAS 9.2 Weijie Cai, SAS Institute Inc., Cary NC July 1, 2008 ABSTRACT Generalized additive models are useful in finding predictor-response
GAMs semi-parametric GLMs. Simon Wood Mathematical Sciences, University of Bath, U.K.
 GAMs semi-parametric GLMs Simon Wood Mathematical Sciences, University of Bath, U.K. Generalized linear models, GLM 1. A GLM models a univariate response, y i as g{e(y i )} = X i β where y i Exponential
GAMs semi-parametric GLMs Simon Wood Mathematical Sciences, University of Bath, U.K. Generalized linear models, GLM 1. A GLM models a univariate response, y i as g{e(y i )} = X i β where y i Exponential
Goals of the Lecture. SOC6078 Advanced Statistics: 9. Generalized Additive Models. Limitations of the Multiple Nonparametric Models (2)
") SOC6078 Advanced Statistics: 9. Generalized Additive Models Robert Andersen Department of Sociology University of Toronto Goals of the Lecture Introduce Additive Models Explain how they extend from simple
SOC6078 Advanced Statistics: 9. Generalized Additive Models Robert Andersen Department of Sociology University of Toronto Goals of the Lecture Introduce Additive Models Explain how they extend from simple
Lab #13 - Resampling Methods Econ 224 October 23rd, 2018
 Lab #13 - Resampling Methods Econ 224 October 23rd, 2018 Introduction In this lab you will work through Section 5.3 of ISL and record your code and results in an RMarkdown document. I have added section
Lab #13 - Resampling Methods Econ 224 October 23rd, 2018 Introduction In this lab you will work through Section 5.3 of ISL and record your code and results in an RMarkdown document. I have added section
Predicting housing price
 Predicting housing price Shu Niu Introduction The goal of this project is to produce a model for predicting housing prices given detailed information. The model can be useful for many purpose. From estimating
Predicting housing price Shu Niu Introduction The goal of this project is to produce a model for predicting housing prices given detailed information. The model can be useful for many purpose. From estimating
Lecture 17: Smoothing splines, Local Regression, and GAMs
 Lecture 17: Smoothing splines, Local Regression, and GAMs Reading: Sections 7.5-7 STATS 202: Data mining and analysis November 6, 2017 1 / 24 Cubic splines Define a set of knots ξ 1 < ξ 2 < < ξ K. We want
Lecture 17: Smoothing splines, Local Regression, and GAMs Reading: Sections 7.5-7 STATS 202: Data mining and analysis November 6, 2017 1 / 24 Cubic splines Define a set of knots ξ 1 < ξ 2 < < ξ K. We want
Distribution-free Predictive Approaches
 Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Distribution-free Predictive Approaches The methods discussed in the previous sections are essentially model-based. Model-free approaches such as tree-based classification also exist and are popular for
Lecture 07 Dimensionality Reduction with PCA
 Lecture 07 Dimensionality Reduction with PCA 10 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/9 As we have started to see, the curse of dimensionality stops us from being able to fit arbitrarily
Lecture 07 Dimensionality Reduction with PCA 10 February 2016 Taylor B. Arnold Yale Statistics STAT 365/665 1/9 As we have started to see, the curse of dimensionality stops us from being able to fit arbitrarily
Introduction to Mixed Models: Multivariate Regression
 Introduction to Mixed Models: Multivariate Regression EPSY 905: Multivariate Analysis Spring 2016 Lecture #9 March 30, 2016 EPSY 905: Multivariate Regression via Path Analysis Today s Lecture Multivariate
Introduction to Mixed Models: Multivariate Regression EPSY 905: Multivariate Analysis Spring 2016 Lecture #9 March 30, 2016 EPSY 905: Multivariate Regression via Path Analysis Today s Lecture Multivariate
Nina Zumel and John Mount Win-Vector LLC
 SUPERVISED LEARNING IN R: REGRESSION Evaluating a model graphically Nina Zumel and John Mount Win-Vector LLC "line of perfect prediction" Systematic errors DataCamp Plotting Ground Truth vs. Predictions
SUPERVISED LEARNING IN R: REGRESSION Evaluating a model graphically Nina Zumel and John Mount Win-Vector LLC "line of perfect prediction" Systematic errors DataCamp Plotting Ground Truth vs. Predictions
Introduction to R, Github and Gitlab
 Introduction to R, Github and Gitlab 27/11/2018 Pierpaolo Maisano Delser mail: maisanop@tcd.ie ; pm604@cam.ac.uk Outline: Why R? What can R do? Basic commands and operations Data analysis in R Github and
Introduction to R, Github and Gitlab 27/11/2018 Pierpaolo Maisano Delser mail: maisanop@tcd.ie ; pm604@cam.ac.uk Outline: Why R? What can R do? Basic commands and operations Data analysis in R Github and
Weighted Sample. Weighted Sample. Weighted Sample. Training Sample
 Final Classifier [ M ] G(x) = sign m=1 α mg m (x) Weighted Sample G M (x) Weighted Sample G 3 (x) Weighted Sample G 2 (x) Training Sample G 1 (x) FIGURE 10.1. Schematic of AdaBoost. Classifiers are trained
Final Classifier [ M ] G(x) = sign m=1 α mg m (x) Weighted Sample G M (x) Weighted Sample G 3 (x) Weighted Sample G 2 (x) Training Sample G 1 (x) FIGURE 10.1. Schematic of AdaBoost. Classifiers are trained
Practice in R. 1 Sivan s practice. 2 Hetroskadasticity. January 28, (pdf version)
") Practice in R January 28, 2010 (pdf version) 1 Sivan s practice Her practice file should be (here), or check the web for a more useful pointer. 2 Hetroskadasticity ˆ Let s make some hetroskadastic data:
Practice in R January 28, 2010 (pdf version) 1 Sivan s practice Her practice file should be (here), or check the web for a more useful pointer. 2 Hetroskadasticity ˆ Let s make some hetroskadastic data:
Bayes Estimators & Ridge Regression
 Bayes Estimators & Ridge Regression Readings ISLR 6 STA 521 Duke University Merlise Clyde October 27, 2017 Model Assume that we have centered (as before) and rescaled X o (original X) so that X j = X o
Bayes Estimators & Ridge Regression Readings ISLR 6 STA 521 Duke University Merlise Clyde October 27, 2017 Model Assume that we have centered (as before) and rescaled X o (original X) so that X j = X o
Lab 10 - Ridge Regression and the Lasso in Python
 Lab 10 - Ridge Regression and the Lasso in Python March 9, 2016 This lab on Ridge Regression and the Lasso is a Python adaptation of p. 251-255 of Introduction to Statistical Learning with Applications
Lab 10 - Ridge Regression and the Lasso in Python March 9, 2016 This lab on Ridge Regression and the Lasso is a Python adaptation of p. 251-255 of Introduction to Statistical Learning with Applications
CH5: CORR & SIMPLE LINEAR REFRESSION =======================================
 STAT 430 SAS Examples SAS5 ===================== ssh xyz@glue.umd.edu, tap sas913 (old sas82), sas https://www.statlab.umd.edu/sasdoc/sashtml/onldoc.htm CH5: CORR & SIMPLE LINEAR REFRESSION =======================================
STAT 430 SAS Examples SAS5 ===================== ssh xyz@glue.umd.edu, tap sas913 (old sas82), sas https://www.statlab.umd.edu/sasdoc/sashtml/onldoc.htm CH5: CORR & SIMPLE LINEAR REFRESSION =======================================
CPSC 340: Machine Learning and Data Mining. Principal Component Analysis Fall 2016
 CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
CPSC 340: Machine Learning and Data Mining Principal Component Analysis Fall 2016 A2/Midterm: Admin Grades/solutions will be posted after class. Assignment 4: Posted, due November 14. Extra office hours:
K-Nearest Neighbors. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 K-Nearest Neighbors Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Check out review materials Probability Linear algebra Python and NumPy Start your HW 0 On your Local machine:
K-Nearest Neighbors Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Check out review materials Probability Linear algebra Python and NumPy Start your HW 0 On your Local machine:
CSE 446 Bias-Variance & Naïve Bayes
 CSE 446 Bias-Variance & Naïve Bayes Administrative Homework 1 due next week on Friday Good to finish early Homework 2 is out on Monday Check the course calendar Start early (midterm is right before Homework
CSE 446 Bias-Variance & Naïve Bayes Administrative Homework 1 due next week on Friday Good to finish early Homework 2 is out on Monday Check the course calendar Start early (midterm is right before Homework
Handling Missing Values
 Handling Missing Values STAT 133 Gaston Sanchez Department of Statistics, UC Berkeley gastonsanchez.com github.com/gastonstat/stat133 Course web: gastonsanchez.com/stat133 Missing Values 2 Introduction
Handling Missing Values STAT 133 Gaston Sanchez Department of Statistics, UC Berkeley gastonsanchez.com github.com/gastonstat/stat133 Course web: gastonsanchez.com/stat133 Missing Values 2 Introduction
Regression Analysis and Linear Regression Models
 Regression Analysis and Linear Regression Models University of Trento - FBK 2 March, 2015 (UNITN-FBK) Regression Analysis and Linear Regression Models 2 March, 2015 1 / 33 Relationship between numerical
Regression Analysis and Linear Regression Models University of Trento - FBK 2 March, 2015 (UNITN-FBK) Regression Analysis and Linear Regression Models 2 March, 2015 1 / 33 Relationship between numerical
Moving Beyond Linearity
 Moving Beyond Linearity Basic non-linear models one input feature: polynomial regression step functions splines smoothing splines local regression. more features: generalized additive models. Polynomial
Moving Beyond Linearity Basic non-linear models one input feature: polynomial regression step functions splines smoothing splines local regression. more features: generalized additive models. Polynomial
Section 2.3: Simple Linear Regression: Predictions and Inference
 Section 2.3: Simple Linear Regression: Predictions and Inference Jared S. Murray The University of Texas at Austin McCombs School of Business Suggested reading: OpenIntro Statistics, Chapter 7.4 1 Simple
Section 2.3: Simple Linear Regression: Predictions and Inference Jared S. Murray The University of Texas at Austin McCombs School of Business Suggested reading: OpenIntro Statistics, Chapter 7.4 1 Simple
This is called a linear basis expansion, and h m is the mth basis function For example if X is one-dimensional: f (X) = β 0 + β 1 X + β 2 X 2, or
 = β 0 + β 1 X + β 2 X 2, or") STA 450/4000 S: February 2 2005 Flexible modelling using basis expansions (Chapter 5) Linear regression: y = Xβ + ɛ, ɛ (0, σ 2 ) Smooth regression: y = f (X) + ɛ: f (X) = E(Y X) to be specified Flexible
STA 450/4000 S: February 2 2005 Flexible modelling using basis expansions (Chapter 5) Linear regression: y = Xβ + ɛ, ɛ (0, σ 2 ) Smooth regression: y = f (X) + ɛ: f (X) = E(Y X) to be specified Flexible
An introduction to SPSS
 An introduction to SPSS To open the SPSS software using U of Iowa Virtual Desktop... Go to https://virtualdesktop.uiowa.edu and choose SPSS 24. Contents NOTE: Save data files in a drive that is accessible
An introduction to SPSS To open the SPSS software using U of Iowa Virtual Desktop... Go to https://virtualdesktop.uiowa.edu and choose SPSS 24. Contents NOTE: Save data files in a drive that is accessible
Math 263 Excel Assignment 3
 ath 263 Excel Assignment 3 Sections 001 and 003 Purpose In this assignment you will use the same data as in Excel Assignment 2. You will perform an exploratory data analysis using R. You shall reproduce
ath 263 Excel Assignment 3 Sections 001 and 003 Purpose In this assignment you will use the same data as in Excel Assignment 2. You will perform an exploratory data analysis using R. You shall reproduce
k-nn classification with R QMMA
 k-nn classification with R QMMA Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/5%20qmma%20-%20mim/0%20labs/l1-knn-eng.html#(1) 1/16 HW (Height and weight) of adults Statistics
k-nn classification with R QMMA Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/5%20qmma%20-%20mim/0%20labs/l1-knn-eng.html#(1) 1/16 HW (Height and weight) of adults Statistics
Economics Nonparametric Econometrics
 Economics 217 - Nonparametric Econometrics Topics covered in this lecture Introduction to the nonparametric model The role of bandwidth Choice of smoothing function R commands for nonparametric models
Economics 217 - Nonparametric Econometrics Topics covered in this lecture Introduction to the nonparametric model The role of bandwidth Choice of smoothing function R commands for nonparametric models
Statistical Pattern Recognition
 Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Statistical Pattern Recognition Features and Feature Selection Hamid R. Rabiee Jafar Muhammadi Spring 2012 http://ce.sharif.edu/courses/90-91/2/ce725-1/ Agenda Features and Patterns The Curse of Size and
Lab 9 - Linear Model Selection in Python
 Lab 9 - Linear Model Selection in Python March 7, 2016 This lab on Model Validation using Validation and Cross-Validation is a Python adaptation of p. 248-251 of Introduction to Statistical Learning with
Lab 9 - Linear Model Selection in Python March 7, 2016 This lab on Model Validation using Validation and Cross-Validation is a Python adaptation of p. 248-251 of Introduction to Statistical Learning with
Final Exam. Advanced Methods for Data Analysis (36-402/36-608) Due Thursday May 8, 2014 at 11:59pm
 Due Thursday May 8, 2014 at 11:59pm") Final Exam Advanced Methods for Data Analysis (36-402/36-608) Due Thursday May 8, 2014 at 11:59pm Instructions: you will submit this take-home final exam in three parts. 1. Writeup. This will be a complete
Final Exam Advanced Methods for Data Analysis (36-402/36-608) Due Thursday May 8, 2014 at 11:59pm Instructions: you will submit this take-home final exam in three parts. 1. Writeup. This will be a complete
CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp
 CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp Chris Guthrie Abstract In this paper I present my investigation of machine learning as
CS 229 Final Project - Using machine learning to enhance a collaborative filtering recommendation system for Yelp Chris Guthrie Abstract In this paper I present my investigation of machine learning as
PS 6: Regularization. PART A: (Source: HTF page 95) The Ridge regression problem is:
 The Ridge regression problem is:") Economics 1660: Big Data PS 6: Regularization Prof. Daniel Björkegren PART A: (Source: HTF page 95) The Ridge regression problem is: : β "#$%& = argmin (y # β 2 x #4 β 4 ) 6 6 + λ β 4 #89 Consider the
Economics 1660: Big Data PS 6: Regularization Prof. Daniel Björkegren PART A: (Source: HTF page 95) The Ridge regression problem is: : β "#$%& = argmin (y # β 2 x #4 β 4 ) 6 6 + λ β 4 #89 Consider the
Contents Cont Hypothesis testing
 Lecture 5 STATS/CME 195 Contents Hypothesis testing Hypothesis testing Exploratory vs. confirmatory data analysis Two approaches of statistics to analyze data sets: Exploratory: use plotting, transformations
Lecture 5 STATS/CME 195 Contents Hypothesis testing Hypothesis testing Exploratory vs. confirmatory data analysis Two approaches of statistics to analyze data sets: Exploratory: use plotting, transformations
CSE Data Mining Concepts and Techniques STATISTICAL METHODS (REGRESSION) Professor- Anita Wasilewska. Team 13
 Professor- Anita Wasilewska. Team 13") CSE 634 - Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit
CSE 634 - Data Mining Concepts and Techniques STATISTICAL METHODS Professor- Anita Wasilewska (REGRESSION) Team 13 Contents Linear Regression Logistic Regression Bias and Variance in Regression Model Fit
Your Name: Section: INTRODUCTION TO STATISTICAL REASONING Computer Lab #4 Scatterplots and Regression
 Your Name: Section: 36-201 INTRODUCTION TO STATISTICAL REASONING Computer Lab #4 Scatterplots and Regression Objectives: 1. To learn how to interpret scatterplots. Specifically you will investigate, using
Your Name: Section: 36-201 INTRODUCTION TO STATISTICAL REASONING Computer Lab #4 Scatterplots and Regression Objectives: 1. To learn how to interpret scatterplots. Specifically you will investigate, using
Lecture 16: High-dimensional regression, non-linear regression
 Lecture 16: High-dimensional regression, non-linear regression Reading: Sections 6.4, 7.1 STATS 202: Data mining and analysis November 3, 2017 1 / 17 High-dimensional regression Most of the methods we
Lecture 16: High-dimensional regression, non-linear regression Reading: Sections 6.4, 7.1 STATS 202: Data mining and analysis November 3, 2017 1 / 17 High-dimensional regression Most of the methods we
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
STA 490H1S Initial Examination of Data
 Initial Examination of Data Alison L. Department of Statistics University of Toronto Winter 2011 Course mantra It s OK not to know. Expressing ignorance is encouraged. It s not OK to not have a willingness
Initial Examination of Data Alison L. Department of Statistics University of Toronto Winter 2011 Course mantra It s OK not to know. Expressing ignorance is encouraged. It s not OK to not have a willingness
Lecture 19: Decision trees
 Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Lecture 19: Decision trees Reading: Section 8.1 STATS 202: Data mining and analysis November 10, 2017 1 / 17 Decision trees, 10,000 foot view R2 R5 t4 1. Find a partition of the space of predictors. X2
Generalized Additive Models
 :p Texts in Statistical Science Generalized Additive Models An Introduction with R Simon N. Wood Contents Preface XV 1 Linear Models 1 1.1 A simple linear model 2 Simple least squares estimation 3 1.1.1
:p Texts in Statistical Science Generalized Additive Models An Introduction with R Simon N. Wood Contents Preface XV 1 Linear Models 1 1.1 A simple linear model 2 Simple least squares estimation 3 1.1.1
Solution to Series 7
 Dr. Marcel Dettling Applied Statistical Regression AS 2015 Solution to Series 7 1. a) We begin the analysis by plotting histograms and barplots for all variables. > ## load data > load("customerwinback.rda")
Dr. Marcel Dettling Applied Statistical Regression AS 2015 Solution to Series 7 1. a) We begin the analysis by plotting histograms and barplots for all variables. > ## load data > load("customerwinback.rda")
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
A popular method for moving beyond linearity. 2. Basis expansion and regularization 1. Examples of transformations. Piecewise-polynomials and splines
 A popular method for moving beyond linearity 2. Basis expansion and regularization 1 Idea: Augment the vector inputs x with additional variables which are transformation of x use linear models in this
A popular method for moving beyond linearity 2. Basis expansion and regularization 1 Idea: Augment the vector inputs x with additional variables which are transformation of x use linear models in this
Statistical Analysis in R Guest Lecturer: Maja Milosavljevic January 28, 2015
 Statistical Analysis in R Guest Lecturer: Maja Milosavljevic January 28, 2015 Data Exploration Import Relevant Packages: library(grdevices) library(graphics) library(plyr) library(hexbin) library(base)
Statistical Analysis in R Guest Lecturer: Maja Milosavljevic January 28, 2015 Data Exploration Import Relevant Packages: library(grdevices) library(graphics) library(plyr) library(hexbin) library(base)
Simulating power in practice
 Simulating power in practice Author: Nicholas G Reich This material is part of the statsteachr project Made available under the Creative Commons Attribution-ShareAlike 3.0 Unported License: http://creativecommons.org/licenses/by-sa/3.0/deed.en
Simulating power in practice Author: Nicholas G Reich This material is part of the statsteachr project Made available under the Creative Commons Attribution-ShareAlike 3.0 Unported License: http://creativecommons.org/licenses/by-sa/3.0/deed.en
Nonparametric Regression
 Nonparametric Regression John Fox Department of Sociology McMaster University 1280 Main Street West Hamilton, Ontario Canada L8S 4M4 jfox@mcmaster.ca February 2004 Abstract Nonparametric regression analysis
Nonparametric Regression John Fox Department of Sociology McMaster University 1280 Main Street West Hamilton, Ontario Canada L8S 4M4 jfox@mcmaster.ca February 2004 Abstract Nonparametric regression analysis
An MM Algorithm for Multicategory Vertex Discriminant Analysis
 An MM Algorithm for Multicategory Vertex Discriminant Analysis Tong Tong Wu Department of Epidemiology and Biostatistics University of Maryland, College Park May 22, 2008 Joint work with Professor Kenneth
An MM Algorithm for Multicategory Vertex Discriminant Analysis Tong Tong Wu Department of Epidemiology and Biostatistics University of Maryland, College Park May 22, 2008 Joint work with Professor Kenneth
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
Data Mining: Classifier Evaluation. CSCI-B490 Seminar in Computer Science (Data Mining)
") Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
STAT:5201 Applied Statistic II
 STAT:5201 Applied Statistic II Two-Factor Experiment (one fixed blocking factor, one fixed factor of interest) Randomized complete block design (RCBD) Primary Factor: Day length (short or long) Blocking
STAT:5201 Applied Statistic II Two-Factor Experiment (one fixed blocking factor, one fixed factor of interest) Randomized complete block design (RCBD) Primary Factor: Day length (short or long) Blocking
PSY 9556B (Feb 5) Latent Growth Modeling
 Latent Growth Modeling") PSY 9556B (Feb 5) Latent Growth Modeling Fixed and random word confusion Simplest LGM knowing how to calculate dfs How many time points needed? Power, sample size Nonlinear growth quadratic Nonlinear growth
PSY 9556B (Feb 5) Latent Growth Modeling Fixed and random word confusion Simplest LGM knowing how to calculate dfs How many time points needed? Power, sample size Nonlinear growth quadratic Nonlinear growth
Last time... Bias-Variance decomposition. This week
 Machine learning, pattern recognition and statistical data modelling Lecture 4. Going nonlinear: basis expansions and splines Last time... Coryn Bailer-Jones linear regression methods for high dimensional
Machine learning, pattern recognition and statistical data modelling Lecture 4. Going nonlinear: basis expansions and splines Last time... Coryn Bailer-Jones linear regression methods for high dimensional
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Fundamentals of learning (continued) and the k-nearest neighbours classifier Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart.
CPSC 340: Machine Learning and Data Mining Fundamentals of learning (continued) and the k-nearest neighbours classifier Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart.
Predictive Analytics: Demystifying Current and Emerging Methodologies. Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA
 Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Predictive Analytics: Demystifying Current and Emerging Methodologies Tom Kolde, FCAS, MAAA Linda Brobeck, FCAS, MAAA May 18, 2017 About the Presenters Tom Kolde, FCAS, MAAA Consulting Actuary Chicago,
Gelman-Hill Chapter 3
 Gelman-Hill Chapter 3 Linear Regression Basics In linear regression with a single independent variable, as we have seen, the fundamental equation is where ŷ bx 1 b0 b b b y 1 yx, 0 y 1 x x Bivariate Normal
Gelman-Hill Chapter 3 Linear Regression Basics In linear regression with a single independent variable, as we have seen, the fundamental equation is where ŷ bx 1 b0 b b b y 1 yx, 0 y 1 x x Bivariate Normal
The linear mixed model: modeling hierarchical and longitudinal data
 The linear mixed model: modeling hierarchical and longitudinal data Analysis of Experimental Data AED The linear mixed model: modeling hierarchical and longitudinal data 1 of 44 Contents 1 Modeling Hierarchical
The linear mixed model: modeling hierarchical and longitudinal data Analysis of Experimental Data AED The linear mixed model: modeling hierarchical and longitudinal data 1 of 44 Contents 1 Modeling Hierarchical
Decision trees. For this lab, we will use the Carseats data set from the ISLR package. (install and) load the package with the data set
 load the package with the data set") Decision trees For this lab, we will use the Carseats data set from the ISLR package. (install and) load the package with the data set # install.packages('islr') library(islr) Carseats is a simulated data
Decision trees For this lab, we will use the Carseats data set from the ISLR package. (install and) load the package with the data set # install.packages('islr') library(islr) Carseats is a simulated data
Lecture 26: Missing data
 Lecture 26: Missing data Reading: ESL 9.6 STATS 202: Data mining and analysis December 1, 2017 1 / 10 Missing data is everywhere Survey data: nonresponse. 2 / 10 Missing data is everywhere Survey data:
Lecture 26: Missing data Reading: ESL 9.6 STATS 202: Data mining and analysis December 1, 2017 1 / 10 Missing data is everywhere Survey data: nonresponse. 2 / 10 Missing data is everywhere Survey data:
22s:152 Applied Linear Regression
 22s:152 Applied Linear Regression Chapter 22: Model Selection In model selection, the idea is to find the smallest set of variables which provides an adequate description of the data. We will consider
22s:152 Applied Linear Regression Chapter 22: Model Selection In model selection, the idea is to find the smallest set of variables which provides an adequate description of the data. We will consider
Classification and Regression Trees
 Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Introduction to Automated Text Analysis. bit.ly/poir599
 Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
DATA MINING AND MACHINE LEARNING. Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
DATA MINING AND MACHINE LEARNING Lecture 6: Data preprocessing and model selection Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Data preprocessing Feature normalization Missing
Salary 9 mo : 9 month salary for faculty member for 2004
 22s:52 Applied Linear Regression DeCook Fall 2008 Lab 3 Friday October 3. The data Set In 2004, a study was done to examine if gender, after controlling for other variables, was a significant predictor
22s:52 Applied Linear Regression DeCook Fall 2008 Lab 3 Friday October 3. The data Set In 2004, a study was done to examine if gender, after controlling for other variables, was a significant predictor
22s:152 Applied Linear Regression
 22s:152 Applied Linear Regression Chapter 22: Model Selection In model selection, the idea is to find the smallest set of variables which provides an adequate description of the data. We will consider
22s:152 Applied Linear Regression Chapter 22: Model Selection In model selection, the idea is to find the smallest set of variables which provides an adequate description of the data. We will consider
EXST 7014, Lab 1: Review of R Programming Basics and Simple Linear Regression
 EXST 7014, Lab 1: Review of R Programming Basics and Simple Linear Regression OBJECTIVES 1. Prepare a scatter plot of the dependent variable on the independent variable 2. Do a simple linear regression
EXST 7014, Lab 1: Review of R Programming Basics and Simple Linear Regression OBJECTIVES 1. Prepare a scatter plot of the dependent variable on the independent variable 2. Do a simple linear regression
Week 4: Simple Linear Regression II
 Week 4: Simple Linear Regression II Marcelo Coca Perraillon University of Colorado Anschutz Medical Campus Health Services Research Methods I HSMP 7607 2017 c 2017 PERRAILLON ARR 1 Outline Algebraic properties
Week 4: Simple Linear Regression II Marcelo Coca Perraillon University of Colorado Anschutz Medical Campus Health Services Research Methods I HSMP 7607 2017 c 2017 PERRAILLON ARR 1 Outline Algebraic properties
Going nonparametric: Nearest neighbor methods for regression and classification
 Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
Going nonparametric: Nearest neighbor methods for regression and classification STAT/CSE 46: Machine Learning Emily Fox University of Washington May 3, 208 Locality sensitive hashing for approximate NN
Statistics 202: Statistical Aspects of Data Mining
 Statistics 202: Statistical Aspects of Data Mining Professor Rajan Patel Lecture 9 = More of Chapter 5 Agenda: 1) Lecture over more of Chapter 5 1 Introduction to Data Mining by Tan, Steinbach, Kumar Chapter
Statistics 202: Statistical Aspects of Data Mining Professor Rajan Patel Lecture 9 = More of Chapter 5 Agenda: 1) Lecture over more of Chapter 5 1 Introduction to Data Mining by Tan, Steinbach, Kumar Chapter
Chapter 6: Linear Model Selection and Regularization
 Chapter 6: Linear Model Selection and Regularization As p (the number of predictors) comes close to or exceeds n (the sample size) standard linear regression is faced with problems. The variance of the
Chapter 6: Linear Model Selection and Regularization As p (the number of predictors) comes close to or exceeds n (the sample size) standard linear regression is faced with problems. The variance of the
Chuck Cartledge, PhD. 23 September 2017
 Introduction K-Nearest Neighbors Na ıve Bayes Hands-on Q&A Conclusion References Files Misc. Big Data: Data Analysis Boot Camp Classification with K-Nearest Neighbors and Na ıve Bayes Chuck Cartledge,
Introduction K-Nearest Neighbors Na ıve Bayes Hands-on Q&A Conclusion References Files Misc. Big Data: Data Analysis Boot Camp Classification with K-Nearest Neighbors and Na ıve Bayes Chuck Cartledge,
Nonparametric Approaches to Regression
 Nonparametric Approaches to Regression In traditional nonparametric regression, we assume very little about the functional form of the mean response function. In particular, we assume the model where m(xi)
Nonparametric Approaches to Regression In traditional nonparametric regression, we assume very little about the functional form of the mean response function. In particular, we assume the model where m(xi)