Introduction to Information Retrieval
|
|
|
- Primrose Tate
- 6 years ago
- Views:
Transcription
1 Introduction to Information Retrieval IIR 6: Flat Clustering Hinrich Schütze Center for Information and Language Processing, University of Munich /86
2 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? /86
3 Outline Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? 3/86
4 Learning to rank for zone scoring Given query q and document d, weighted zone scoring assigns to the pair (q,d) a score in the interval [0,] by computing a linear combination of document zone scores, where each zone contributes a value. Consider a set of documents, which have l zones Let g,...,g l [0,], such that l i= g i = For i l, let s i be the Boolean score denoting a match (or non-match) between q and the i th zone s i = if a query term occurs in zone i, 0 otherwise Weighted zone scoring aka ranked Boolean retrieval Rank documents according to l i= g is i Learning to rank approach: learn the weights g i from training data 4/86
5 Training set for learning to rank Φ j d j q j s T s B r(d j,q j ) Φ 37 linux Relevant Φ 37 penguin 0 Nonrelevant Φ 3 38 system 0 Relevant Φ 4 38 penguin 0 0 Nonrelevant Φ 5 74 kernel Relevant Φ driver 0 Relevant Φ driver 0 Nonrelevant 5/86
6 Summary of learning to rank approach The problem of making a binary relevant/nonrelevant judgment is cast as a classification or regression problem, based on a training set of query-document pairs and associated relevance judgments. In principle, any method learning a classifier (including least squares regression) can be used to find this line. Big advantage of learning to rank: we can avoid hand-tuning scoring functions and simply learn them from training data. Bottleneck of learning to rank: the cost of maintaining a representative set of training examples whose relevance assessments must be made by humans. 6/86
7 LTR features used by Microsoft Research () Zones: body, anchor, title, url, whole document Features derived from standard IR models: query term number, query term ratio, length, idf, sum of term frequency, min of term frequency, max of term frequency, mean of term frequency, variance of term frequency, sum of length normalized term frequency, min of length normalized term frequency, max of length normalized term frequency, mean of length normalized term frequency, variance of length normalized term frequency, sum of tf-idf, min of tf-idf, max of tf-idf, mean of tf-idf, variance of tf-idf, boolean model, BM5 7/86
8 LTR features used by Microsoft Research () Language model features: LMIR.ABS, LMIR.DIR, LMIR.JM Web-specific features: number of slashes in url, length of url, inlink number, outlink number, PageRank, SiteRank Spam features: QualityScore Usage-based features: query-url click count, url click count, url dwell time 8/86
9 Ranking SVMs Vector of feature differences: Φ(d i,d j,q) = ψ(d i,q) ψ(d j,q) By hypothesis, one of d i and d j has been judged more relevant. Notation: We write d i d j for d i precedes d j in the results ordering. If d i is judged more relevant than d j, then we will assign the vector Φ(d i,d j,q) the class y ijq = +; otherwise. This gives us a training set of pairs of vectors and precedence indicators. Each of the vectors is computed as the difference of two document-query vectors. We can then train an SVM on this training set with the goal of obtaining a classifier that returns w T Φ(d i,d j,q) > 0 iff d i d j 9/86
10 Take-away today What is clustering? Applications of clustering in information retrieval K-means algorithm Evaluation of clustering How many clusters? 0/86
11 Outline Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? /86
12 Clustering: Definition (Document) clustering is the process of grouping a set of documents into clusters of similar documents. Documents within a cluster should be similar. Documents from different clusters should be dissimilar. Clustering is the most common form of unsupervised learning. Unsupervised = there are no labeled or annotated data. /86
13 Data set with clear cluster structure Propose algorithm for finding the cluster structure in this example /86
14 Classification vs. Clustering Classification: supervised learning Clustering: unsupervised learning Classification: Classes are human-defined and part of the input to the learning algorithm. Clustering: Clusters are inferred from the data without human input. However, there are many ways of influencing the outcome of clustering: number of clusters, similarity measure, representation of documents,... 4/86
15 Outline Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? 5/86
16 The cluster hypothesis Cluster hypothesis. Documents in the same cluster behave similarly with respect to relevance to information needs. All applications of clustering in IR are based (directly or indirectly) on the cluster hypothesis. Van Rijsbergen s original wording (979): closely associated documents tend to be relevant to the same requests. 6/86
17 Applications of clustering in IR application what is benefit clustered? search result clustering search results Scatter-Gather (subsets of) collection more effective information presentation to user alternative user interface: search without typing collection clustering collection effective information presentation for exploratory browsing cluster-based retrieval collection higher efficiency: faster search 7/86

18 Search result clustering for better navigation 8/86
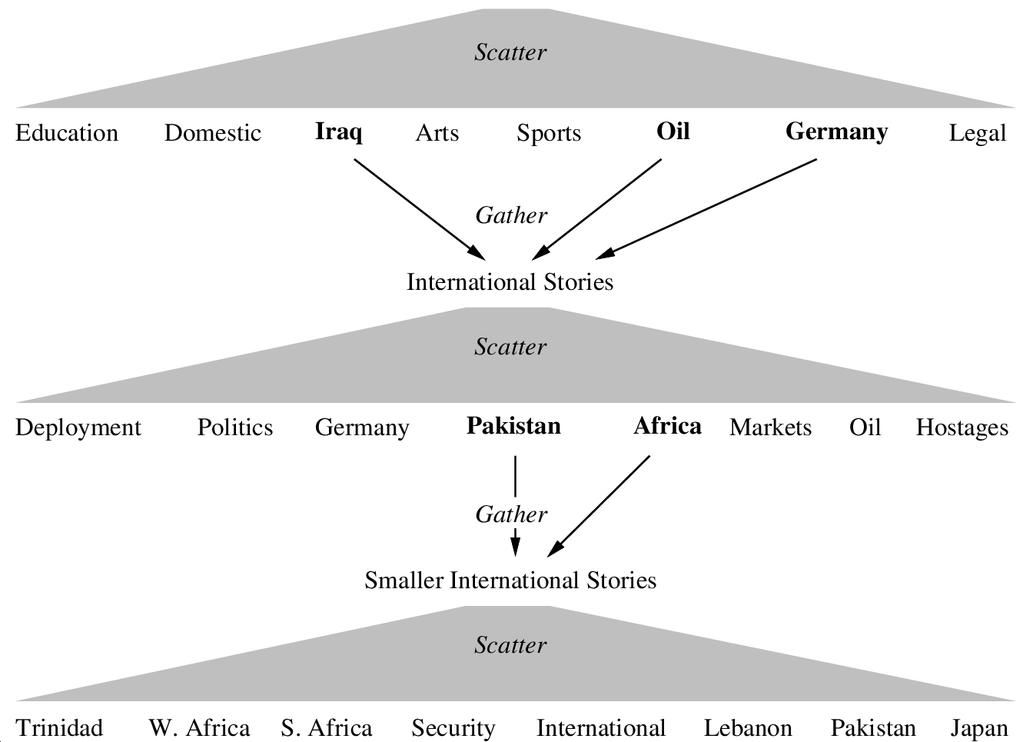
19 Scatter-Gather 9/86

20 Global navigation: Yahoo 0/86
")
21 Global navigation: MESH (upper level) /86
")
22 Global navigation: MESH (lower level) /86
23 Navigational hierarchies: Manual vs. automatic creation Note: Yahoo/MESH are not examples of clustering. But they are well known examples for using a global hierarchy for navigation. Some examples for global navigation/exploration based on clustering: Cartia Themescapes Google News 3/86
 4/86")
24 Global navigation combined with visualization () 4/86
 5/86")
25 Global navigation combined with visualization () 5/86
26 Global clustering for navigation: Google News 6/86
27 Clustering for improving recall To improve search recall: Cluster docs in collection a priori When a query matches a doc d, also return other docs in the cluster containing d Hope: if we do this: the query car will also return docs containing automobile Because the clustering algorithm groups together docs containing car with those containing automobile. Both types of documents contain words like parts, dealer, mercedes, road trip. 7/86
28 Data set with clear cluster structure Propose algorithm for finding the cluster structure in this example /86
29 Desiderata for clustering General goal: put related docs in the same cluster, put unrelated docs in different clusters. We ll see different ways of formalizing this. The number of clusters should be appropriate for the data set we are clustering. Initially, we will assume the number of clusters K is given. Later: Semiautomatic methods for determining K Secondary goals in clustering Avoid very small and very large clusters Define clusters that are easy to explain to the user Many others... 9/86
30 Flat vs. Hierarchical clustering Flat algorithms Usually start with a random (partial) partitioning of docs into groups Refine iteratively Main algorithm: K-means Hierarchical algorithms Create a hierarchy Bottom-up, agglomerative Top-down, divisive 30/86
31 Hard vs. Soft clustering Hard clustering: Each document belongs to exactly one cluster. More common and easier to do Soft clustering: A document can belong to more than one cluster. Makes more sense for applications like creating browsable hierarchies You may want to put sneakers in two clusters: sports apparel shoes You can only do that with a soft clustering approach. This class: flat, hard clustering Next time: hierarchical, hard clustering Next week: latent semantic indexing, a form of soft clustering 3/86
32 Flat algorithms Flat algorithms compute a partition of N documents into a set of K clusters. Given: a set of documents and the number K Find: a partition into K clusters that optimizes the chosen partitioning criterion Global optimization: exhaustively enumerate partitions, pick optimal one Not tractable Effective heuristic method: K-means algorithm 3/86
33 Outline Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? 33/86
34 K-means Perhaps the best known clustering algorithm Simple, works well in many cases Use as default / baseline for clustering documents 34/86
35 Document representations in clustering Vector space model As in vector space classification, we measure relatedness between vectors by Euclidean distance......which is almost equivalent to cosine similarity. Almost: centroids are not length-normalized. 35/86
36 K-means: Basic idea Each cluster in K-means is defined by a centroid. Objective/partitioning criterion: minimize the average squared difference from the centroid Recall definition of centroid: µ(ω) = ω x x ω where we use ω to denote a cluster. We try to find the minimum average squared difference by iterating two steps: reassignment: assign each vector to its closest centroid recomputation: recompute each centroid as the average of the vectors that were assigned to it in reassignment 36/86
37 K-means pseudocode (µ k is centroid of ω k ) K-means({ x,..., x N },K) ( s, s,..., s K ) SelectRandomSeeds({ x,..., x N },K) for k to K 3 do µ k s k 4 while stopping criterion has not been met 5 do for k to K 6 do ω k {} 7 for n to N 8 do j argmin j µ j x n 9 ω j ω j { x n } (reassignment of vectors) 0 for k to K do µ k ω k return { µ,..., µ K } x ω k x (recomputation of centroids) 37/86
38 Worked Example : Set of points to be clustered Exercise: (i) Guess what the optimal clustering into two clusters is in this case; (ii) compute the centroids of the clusters 38/86
39 Worked Example: Random selection of initial centroids 39/86
40 Worked Example: Assign points to closest center 40/86
41 Worked Example: Assignment 4/86
42 Worked Example: Recompute cluster centroids 4/86
43 Worked Example: Assign points to closest centroid 43/86
44 Worked Example: Assignment 44/86
45 Worked Example: Recompute cluster centroids 45/86
46 Worked Example: Assign points to closest centroid 46/86
47 Worked Example: Assignment 47/86
48 Worked Example: Recompute cluster centroids 48/86
49 Worked Example: Assign points to closest centroid 49/86
50 Worked Example: Assignment 50/86
51 Worked Example: Recompute cluster centroids 5/86
52 Worked Example: Assign points to closest centroid 5/86
53 Worked Example: Assignment 53/86
54 Worked Example: Recompute cluster centroids 54/86
55 Worked Example: Assign points to closest centroid 55/86
56 Worked Example: Assignment 56/86
57 Worked Example: Recompute cluster centroids 57/86
58 Worked Example: Assign points to closest centroid 58/86
59 Worked Example: Assignment 59/86
60 Worked Example: Recompute cluster centroids 60/86
61 Worked Ex.: Centroids and assignments after convergence 6/86
62 K-means is guaranteed to converge: Proof RSS = sum of all squared distances between document vector and closest centroid RSS decreases during each reassignment step. because each vector is moved to a closer centroid RSS decreases during each recomputation step. see next slide There is only a finite number of clusterings. Thus: We must reach a fixed point. Assumption: Ties are broken consistently. Finite set & monotonically decreasing convergence 6/86
63 Recomputation decreases average distance RSS = K k= RSS k the residual sum of squares (the goodness measure) RSS k ( v) = v x = x ω k x ω k RSS k ( v) = (v m x m ) = 0 v m x ω k v m = ω k x ω k x m M (v m x m ) m= The last line is the componentwise definition of the centroid! We minimize RSS k when the old centroid is replaced with the new centroid. RSS, the sum of the RSS k, must then also decrease during recomputation. 63/86
64 K-means is guaranteed to converge But we don t know how long convergence will take! If we don t care about a few docs switching back and forth, then convergence is usually fast (< 0-0 iterations). However, complete convergence can take many more iterations. 64/86
65 Optimality of K-means Convergence optimality Convergence does not mean that we converge to the optimal clustering! This is the great weakness of K-means. If we start with a bad set of seeds, the resulting clustering can be horrible. 65/86
66 Exercise: Suboptimal clustering 3 0 d d d d 4 d 5 d 6 What is the optimal clustering for K =? Do we converge on this clustering for arbitrary seeds d i,d j? 66/86
67 Initialization of K-means Random seed selection is just one of many ways K-means can be initialized. Random seed selection is not very robust: It s easy to get a suboptimal clustering. Better ways of computing initial centroids: Select seeds not randomly, but using some heuristic (e.g., filter out outliers or find a set of seeds that has good coverage of the document space) Use hierarchical clustering to find good seeds Select i (e.g., i = 0) different random sets of seeds, do a K-means clustering for each, select the clustering with lowest RSS 67/86
68 Time complexity of K-means Computing one distance of two vectors is O(M). Reassignment step: O(KNM) (we need to compute KN document-centroid distances) Recomputation step: O(NM) (we need to add each of the document s < M values to one of the centroids) Assume number of iterations bounded by I Overall complexity: O(IKNM) linear in all important dimensions However: This is not a real worst-case analysis. In pathological cases, complexity can be worse than linear. 68/86
69 Outline Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? 69/86
70 What is a good clustering? Internal criteria Example of an internal criterion: RSS in K-means But an internal criterion often does not evaluate the actual utility of a clustering in the application. Alternative: External criteria Evaluate with respect to a human-defined classification 70/86
71 External criteria for clustering quality Based on a gold standard data set, e.g., the Reuters collection we also used for the evaluation of classification Goal: Clustering should reproduce the classes in the gold standard (But we only want to reproduce how documents are divided into groups, not the class labels.) First measure for how well we were able to reproduce the classes: purity 7/86
72 External criterion: Purity purity(ω,c) = N k max ω k c j j Ω = {ω,ω,...,ω K } is the set of clusters and C = {c,c,...,c J } is the set of classes. For each cluster ω k : find class c j with most members n kj in ω k Sum all n kj and divide by total number of points 7/86
73 Example for computing purity cluster cluster cluster 3 x o x x x x x o o o o x x To compute purity: 5 = max j ω c j (class x, cluster ); 4 = max j ω c j (class o, cluster ); and 3 = max j ω 3 c j (class, cluster 3). Purity is (/7) (5+4+3) /86
74 Another external criterion: Rand index Purity can be increased easily by increasing K a measure that does not have this problem: Rand index. Definition: RI = TP+TN TP+FP+FN+TN Based on x contingency table of all pairs of documents: same cluster different clusters same class true positives (TP) false negatives (FN) different classes false positives (FP) true negatives (TN) TP+FN+FP+TN is the total number of pairs. TP+FN+FP+TN = ( N ) for N documents. Example: ( 7 ) = 36 in o/ /x example Each pair is either positive or negative (the clustering puts the two documents in the same or in different clusters) and either true (correct) or false (incorrect): the clustering decision is correct or incorrect. 74/86
75 Rand Index: Example As an example, we compute RI for the o/ /x example. We first compute TP+FP. The three clusters contain 6, 6, and 5 points, respectively, so the total number of positives or pairs of documents that are in the same cluster is: TP+FP = ( 6 ) + ( 6 ) + ( 5 ) = 40 Of these, the x pairs in cluster, the o pairs in cluster, the pairs in cluster 3, and the x pair in cluster 3 are true positives: ( ) ( ) ( ) ( ) TP = = 0 Thus, FP = 40 0 = 0. FN and TN are computed similarly. 75/86
76 Rand measure for the o/ /x example same cluster different clusters same class TP = 0 FN = 4 different classes FP = 0 TN = 7 RI is then (0+7)/( ) /86
77 Two other external evaluation measures Two other measures Normalized mutual information (NMI) How much information does the clustering contain about the classification? Singleton clusters (number of clusters = number of docs) have maximum MI Therefore: normalize by entropy of clusters and classes F measure Like Rand, but precision and recall can be weighted 77/86
78 Evaluation results for the o/ /x example purity NMI RI F 5 lower bound maximum value for example All four measures range from 0 (really bad clustering) to (perfect clustering). 78/86
79 Outline Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? 79/86
80 How many clusters? Number of clusters K is given in many applications. E.g., there may be an external constraint on K. Example: In the case of Scatter-Gather, it was hard to show more than 0 0 clusters on a monitor in the 90s. What if there is no external constraint? Is there a right number of clusters? One way to go: define an optimization criterion Given docs, find K for which the optimum is reached. What optimization criterion can we use? We can t use RSS or average squared distance from centroid as criterion: always chooses K = N clusters. 80/86
81 Exercise Your job is to develop the clustering algorithms for a competitor to news.google.com You want to use K-means clustering. How would you determine K? 8/86
82 Simple objective function for K: Basic idea Start with cluster (K = ) Keep adding clusters (= keep increasing K) Add a penalty for each new cluster Then trade off cluster penalties against average squared distance from centroid Choose the value of K with the best tradeoff 8/86
83 Simple objective function for K: Formalization Given a clustering, define the cost for a document as (squared) distance to centroid Define total distortion RSS(K) as sum of all individual document costs (corresponds to average distance) Then: penalize each cluster with a cost λ Thus for a clustering with K clusters, total cluster penalty is Kλ Define the total cost of a clustering as distortion plus total cluster penalty: RSS(K) + Kλ Select K that minimizes (RSS(K) + Kλ) Still need to determine good value for λ... 83/86
84 Finding the knee in the curve residual sum of squares number of clusters curve flattens. Here: 4 or 9. Pick the number of clusters where 84/86
85 Take-away today What is clustering? Applications of clustering in information retrieval K-means algorithm Evaluation of clustering How many clusters? 85/86
86 Resources Chapter 6 of IIR Resources at Keith van Rijsbergen on the cluster hypothesis (he was one of the originators) Bing/Carrot/Clusty: search result clustering systems Stirling number: the number of distinct k-clusterings of n items 86/86
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
Introduction to Information Retrieval http://informationretrieval.org IIR 6: Flat Clustering Wiltrud Kessler & Hinrich Schütze Institute for Natural Language Processing, University of Stuttgart 0-- / 83
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16)
") CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
CSE 7/5337: Information Retrieval and Web Search Document clustering I (IIR 16) Michael Hahsler Southern Methodist University These slides are largely based on the slides by Hinrich Schütze Institute for
Flat Clustering. Slides are mostly from Hinrich Schütze. March 27, 2017
 Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
Flat Clustering Slides are mostly from Hinrich Schütze March 7, 07 / 79 Overview Recap Clustering: Introduction 3 Clustering in IR 4 K-means 5 Evaluation 6 How many clusters? / 79 Outline Recap Clustering:
PV211: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv211
 PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
PV: Introduction to Information Retrieval https://www.fi.muni.cz/~sojka/pv IIR 6: Flat Clustering Handout version Petr Sojka, Hinrich Schütze et al. Faculty of Informatics, Masaryk University, Brno Center
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 1/ 64 Overview
MI example for poultry/export in Reuters. Overview. Introduction to Information Retrieval. Outline.
 Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 16: Flat Clustering Hinrich Schütze Institute for Natural Language Processing, Universität Stuttgart 2009.06.16 Outline 1 Recap
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University
 Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Cluster Evaluation and Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University Kinds of Clustering Sequential Fast Cost Optimization Fixed number of clusters Hierarchical
Clustering CE-324: Modern Information Retrieval Sharif University of Technology
 Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
Clustering CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Ch. 16 What
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Expectation Maximization!
 Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University and http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Steps in Clustering Select Features
Expectation Maximization! adapted from: Doug Downey and Bryan Pardo, Northwestern University and http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Steps in Clustering Select Features
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Administrative. Machine learning code. Supervised learning (e.g. classification) Machine learning: Unsupervised learning" BANANAS APPLES
 Machine learning: Unsupervised learning BANANAS APPLES") Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Administrative Machine learning: Unsupervised learning" Assignment 5 out soon David Kauchak cs311 Spring 2013 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
CS490W. Text Clustering. Luo Si. Department of Computer Science Purdue University
 CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Text Documents clustering using K Means Algorithm
 Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Text Clustering Prof. Chris Clifton 19 October 2018 Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti Document clustering Motivations Document
CS47300: Web Information Search and Management Text Clustering Prof. Chris Clifton 19 October 2018 Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti Document clustering Motivations Document
Clustering (COSC 416) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 416) Nazli Goharian nazli@cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
CLUSTERING. Quiz information. today 11/14/13% ! The second midterm quiz is on Thursday (11/21) ! In-class (75 minutes!)
 ! In-class (75 minutes!)") CLUSTERING Quiz information! The second midterm quiz is on Thursday (11/21)! In-class (75 minutes!)! Allowed one two-sided (8.5x11) cheat sheet! Solutions for optional problems to HW5 posted today 1% Quiz
CLUSTERING Quiz information! The second midterm quiz is on Thursday (11/21)! In-class (75 minutes!)! Allowed one two-sided (8.5x11) cheat sheet! Solutions for optional problems to HW5 posted today 1% Quiz
Clustering (COSC 488) Nazli Goharian. Document Clustering.
 Nazli Goharian. Document Clustering.") Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
Clustering (COSC 488) Nazli Goharian nazli@ir.cs.georgetown.edu 1 Document Clustering. Cluster Hypothesis : By clustering, documents relevant to the same topics tend to be grouped together. C. J. van Rijsbergen,
DD2475 Information Retrieval Lecture 10: Clustering. Document Clustering. Recap: Classification. Today
 Sec.14.1! Recap: Classification DD2475 Information Retrieval Lecture 10: Clustering Hedvig Kjellström hedvig@kth.se www.csc.kth.se/dd2475 Data points have labels Classification task: Finding good separators
Sec.14.1! Recap: Classification DD2475 Information Retrieval Lecture 10: Clustering Hedvig Kjellström hedvig@kth.se www.csc.kth.se/dd2475 Data points have labels Classification task: Finding good separators
Data Clustering. Danushka Bollegala
 Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Today s topic CS347. Results list clustering example. Why cluster documents. Clustering documents. Lecture 8 May 7, 2001 Prabhakar Raghavan
 Today s topic CS347 Clustering documents Lecture 8 May 7, 2001 Prabhakar Raghavan Why cluster documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics
Today s topic CS347 Clustering documents Lecture 8 May 7, 2001 Prabhakar Raghavan Why cluster documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
What to come. There will be a few more topics we will cover on supervised learning
 Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Summary so far Supervised learning learn to predict Continuous target regression; Categorical target classification Linear Regression Classification Discriminative models Perceptron (linear) Logistic regression
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu Clustering Overview Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements,
Lecture on Modeling Tools for Clustering & Regression
 Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Lecture on Modeling Tools for Clustering & Regression CS 590.21 Analysis and Modeling of Brain Networks Department of Computer Science University of Crete Data Clustering Overview Organizing data into
Big Data Analytics! Special Topics for Computer Science CSE CSE Feb 9
 Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Big Data Analytics! Special Topics for Computer Science CSE 4095-001 CSE 5095-005! Feb 9 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Clustering I What
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval Clustering Chris Manning, Pandu Nayak, and Prabhakar Raghavan Today s Topic: Clustering Document clustering Mo*va*ons Document representa*ons Success criteria Clustering
Introduc*on to Informa(on Retrieval Clustering Chris Manning, Pandu Nayak, and Prabhakar Raghavan Today s Topic: Clustering Document clustering Mo*va*ons Document representa*ons Success criteria Clustering
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
CSE 158. Web Mining and Recommender Systems. Midterm recap
 CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
CSE 158 Web Mining and Recommender Systems Midterm recap Midterm on Wednesday! 5:10 pm 6:10 pm Closed book but I ll provide a similar level of basic info as in the last page of previous midterms CSE 158
Gene Clustering & Classification
 BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
BINF, Introduction to Computational Biology Gene Clustering & Classification Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Introduction to Gene Clustering
Lecture 8 May 7, Prabhakar Raghavan
 Lecture 8 May 7, 2001 Prabhakar Raghavan Clustering documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics Given the set of docs from the results of
Lecture 8 May 7, 2001 Prabhakar Raghavan Clustering documents Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics Given the set of docs from the results of
INF 4300 Classification III Anne Solberg The agenda today:
 INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
INF 4300 Classification III Anne Solberg 28.10.15 The agenda today: More on estimating classifier accuracy Curse of dimensionality and simple feature selection knn-classification K-means clustering 28.10.15
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 12: Clustering Today s Topic: Clustering Document clustering Mo*va*ons Document
Introduc*on to Informa(on Retrieval CS276: Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 12: Clustering Today s Topic: Clustering Document clustering Mo*va*ons Document
Using Machine Learning to Optimize Storage Systems
 Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Using Machine Learning to Optimize Storage Systems Dr. Kiran Gunnam 1 Outline 1. Overview 2. Building Flash Models using Logistic Regression. 3. Storage Object classification 4. Storage Allocation recommendation
Clustering Algorithms for general similarity measures
 Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Natural Language Processing
 Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Natural Language Processing Machine Learning Potsdam, 26 April 2012 Saeedeh Momtazi Information Systems Group Introduction 2 Machine Learning Field of study that gives computers the ability to learn without
Clustering. Partition unlabeled examples into disjoint subsets of clusters, such that:
 Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
Text Clustering 1 Clustering Partition unlabeled examples into disjoint subsets of clusters, such that: Examples within a cluster are very similar Examples in different clusters are very different Discover
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Artificial Intelligence. Programming Styles
 Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Artificial Intelligence Intro to Machine Learning Programming Styles Standard CS: Explicitly program computer to do something Early AI: Derive a problem description (state) and use general algorithms to
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology
 Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
Text classification II CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2015 Some slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford)
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Exploratory Analysis: Clustering
 Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Exploratory Analysis: Clustering (some material taken or adapted from slides by Hinrich Schutze) Heejun Kim June 26, 2018 Clustering objective Grouping documents or instances into subsets or clusters Documents
Evaluation. Evaluate what? For really large amounts of data... A: Use a validation set.
 Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Evaluate what? Evaluation Charles Sutton Data Mining and Exploration Spring 2012 Do you want to evaluate a classifier or a learning algorithm? Do you want to predict accuracy or predict which one is better?
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Information Retrieval
 Introduction to Information Retrieval SCCS414: Information Storage and Retrieval Christopher Manning and Prabhakar Raghavan Lecture 10: Text Classification; Vector Space Classification (Rocchio) Relevance
Introduction to Information Retrieval SCCS414: Information Storage and Retrieval Christopher Manning and Prabhakar Raghavan Lecture 10: Text Classification; Vector Space Classification (Rocchio) Relevance
Unsupervised Learning Partitioning Methods
 Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Unsupervised Learning Partitioning Methods Road Map 1. Basic Concepts 2. K-Means 3. K-Medoids 4. CLARA & CLARANS Cluster Analysis Unsupervised learning (i.e., Class label is unknown) Group data to form
Ranking and Learning. Table of Content. Weighted scoring for ranking Learning to rank: A simple example Learning to ranking as classification.
 Table of Content anking and Learning Weighted scoring for ranking Learning to rank: A simple example Learning to ranking as classification 290 UCSB, Tao Yang, 2013 Partially based on Manning, aghavan,
Table of Content anking and Learning Weighted scoring for ranking Learning to rank: A simple example Learning to ranking as classification 290 UCSB, Tao Yang, 2013 Partially based on Manning, aghavan,
Clustering. Bruno Martins. 1 st Semester 2012/2013
 Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 Motivation Basic Concepts
Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 Motivation Basic Concepts
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Unsupervised Data Mining: Clustering. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Unsupervised Data Mining: Clustering Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 1. Supervised Data Mining Classification Regression Outlier detection
Search Engines and Learning to Rank
 Search Engines and Learning to Rank Joseph (Yossi) Keshet Query processor Ranker Cache Forward index Inverted index Link analyzer Indexer Parser Web graph Crawler Representations TF-IDF To get an effective
Search Engines and Learning to Rank Joseph (Yossi) Keshet Query processor Ranker Cache Forward index Inverted index Link analyzer Indexer Parser Web graph Crawler Representations TF-IDF To get an effective
Lecture 7: Clustering
 Lecture 7: Clustering Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2016 1 Adapted from Simone
Lecture 7: Clustering Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2016 1 Adapted from Simone
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
CSE 494/598 Lecture-11: Clustering & Classification
 CSE 494/598 Lecture-11: Clustering & Classification LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **With permission, content adapted from last year s slides and from Intro to DM dmbook@cs.umn.edu
CSE 494/598 Lecture-11: Clustering & Classification LYDIA MANIKONDA HT TP://WWW.PUBLIC.ASU.EDU/~LMANIKON / **With permission, content adapted from last year s slides and from Intro to DM dmbook@cs.umn.edu
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
CSE 494 Project C. Garrett Wolf
 CSE 494 Project C Garrett Wolf Introduction The main purpose of this project task was for us to implement the simple k-means and buckshot clustering algorithms. Once implemented, we were asked to vary
CSE 494 Project C Garrett Wolf Introduction The main purpose of this project task was for us to implement the simple k-means and buckshot clustering algorithms. Once implemented, we were asked to vary
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Clustering Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu November 7, 2017 Learnt Clustering Methods Vector Data Set Data Sequence Data Text
CS145: INTRODUCTION TO DATA MINING Clustering Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu November 7, 2017 Learnt Clustering Methods Vector Data Set Data Sequence Data Text
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Information Retrieval. Lecture 7
 Information Retrieval Lecture 7 Recap of the last lecture Vector space scoring Efficiency considerations Nearest neighbors and approximations This lecture Evaluating a search engine Benchmarks Precision
Information Retrieval Lecture 7 Recap of the last lecture Vector space scoring Efficiency considerations Nearest neighbors and approximations This lecture Evaluating a search engine Benchmarks Precision
Document Clustering: Comparison of Similarity Measures
 Document Clustering: Comparison of Similarity Measures Shouvik Sachdeva Bhupendra Kastore Indian Institute of Technology, Kanpur CS365 Project, 2014 Outline 1 Introduction The Problem and the Motivation
Document Clustering: Comparison of Similarity Measures Shouvik Sachdeva Bhupendra Kastore Indian Institute of Technology, Kanpur CS365 Project, 2014 Outline 1 Introduction The Problem and the Motivation
Web Information Retrieval. Exercises Evaluation in information retrieval
 Web Information Retrieval Exercises Evaluation in information retrieval Evaluating an IR system Note: information need is translated into a query Relevance is assessed relative to the information need
Web Information Retrieval Exercises Evaluation in information retrieval Evaluating an IR system Note: information need is translated into a query Relevance is assessed relative to the information need
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Multivariate Analysis (slides 9)
") Multivariate Analysis (slides 9) Today we consider k-means clustering. We will address the question of selecting the appropriate number of clusters. Properties and limitations of the algorithm will be
Multivariate Analysis (slides 9) Today we consider k-means clustering. We will address the question of selecting the appropriate number of clusters. Properties and limitations of the algorithm will be
Chapter 4: Text Clustering
 4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
4.1 Introduction to Text Clustering Clustering is an unsupervised method of grouping texts / documents in such a way that in spite of having little knowledge about the content of the documents, we can
Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification/clustering are classical pattern recognition/ machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification/clustering are classical pattern recognition/ machine learning problems Classification, also referred to as categorization
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Evaluation Measures. Sebastian Pölsterl. April 28, Computer Aided Medical Procedures Technische Universität München
 Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Evaluation Measures Sebastian Pölsterl Computer Aided Medical Procedures Technische Universität München April 28, 2015 Outline 1 Classification 1. Confusion Matrix 2. Receiver operating characteristics
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Administrative. Machine learning code. Machine learning: Unsupervised learning
 Machine learning: Unsupervised learning http://www.youtube.com/watch?v=or_-y-eilqo David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Machine learning: Unsupervised learning http://www.youtube.com/watch?v=or_-y-eilqo David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Machine
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation
 4 Model, Classification 4 Model, Regression 4 Representation") Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
Contents Machine Learning concepts 4 Learning Algorithm 4 Predictive Model (Model) 4 Model, Classification 4 Model, Regression 4 Representation Learning 4 Supervised Learning 4 Unsupervised Learning 4
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CS 8520: Artificial Intelligence. Machine Learning 2. Paula Matuszek Fall, CSC 8520 Fall Paula Matuszek
 CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Fall, 2015!1 Regression Classifiers We said earlier that the task of a supervised learning system can be viewed as learning a function
CS 8520: Artificial Intelligence Machine Learning 2 Paula Matuszek Fall, 2015!1 Regression Classifiers We said earlier that the task of a supervised learning system can be viewed as learning a function
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
CCRMA MIR Workshop 2014 Evaluating Information Retrieval Systems. Leigh M. Smith Humtap Inc.
 CCRMA MIR Workshop 2014 Evaluating Information Retrieval Systems Leigh M. Smith Humtap Inc. leigh@humtap.com Basic system overview Segmentation (Frames, Onsets, Beats, Bars, Chord Changes, etc) Feature
CCRMA MIR Workshop 2014 Evaluating Information Retrieval Systems Leigh M. Smith Humtap Inc. leigh@humtap.com Basic system overview Segmentation (Frames, Onsets, Beats, Bars, Chord Changes, etc) Feature
Chapter 8. Evaluating Search Engine
 Chapter 8 Evaluating Search Engine Evaluation Evaluation is key to building effective and efficient search engines Measurement usually carried out in controlled laboratory experiments Online testing can
Chapter 8 Evaluating Search Engine Evaluation Evaluation is key to building effective and efficient search engines Measurement usually carried out in controlled laboratory experiments Online testing can
CSE494 Information Retrieval Project C Report
 CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering
CSE494 Information Retrieval Project C Report By: Jianchun Fan Introduction In project C we implement several different clustering methods on the query results given by pagerank algorithms. The clustering